12.2 文本分类微调
在前面的章节中,我们已经了解了预训练语言模型如何获得通用的语言理解能力。但预训练模型本身并不直接解决具体任务——要让它判断一封邮件是否为垃圾信息、分析一条评论的情感倾向,或者将新闻文章归类到不同主题,我们需要在预训练模型的基础上进行分类微调(Classification Fine-tuning)。
分类微调的核心思路可以用一句话概括:在预训练模型的顶部添加一个轻量的分类头(Classification Head),冻结或部分冻结原有参数,然后在标注数据上训练。这种方式既保留了预训练阶段学到的丰富语言知识,又以极小的代价让模型适应特定的分类任务。
图 12-2-1:分类微调与指令微调是两种不同的微调范式。分类微调的产出是一个专用的分类器,而指令微调产出的是一个通用的任务助手。
12.2.1 GPT 与 BERT:两种分类微调范式
文本分类微调在不同架构的模型上有不同的实现方式。理解它们的差异,是掌握分类微调的第一步。
GPT 类模型(Decoder-only)的分类微调。 GPT-1 在论文中就展示了一种极简的下游任务适配方式:将输入文本包裹在特殊标记之间,送入预训练好的 Transformer Decoder,取最后一个 Token 的输出向量,接上一个线性分类层完成预测。由于因果注意力掩码(Causal Attention Mask)的存在,最后一个 Token 是唯一能"看到"所有前面 Token 的位置,因此它的隐藏状态天然地编码了整个输入序列的语义信息。
图 12-2-2:分类微调在整个大模型训练流水线中的位置。在 BERT 时代,传统 SFT 主要就是在特定任务上添加任务头进行微调。
BERT 类模型(Encoder-only)的分类微调。 BERT 的做法略有不同。它在输入序列的开头插入一个特殊的 [CLS](Classification)Token,经过双向 Transformer 编码后,[CLS] 位置的输出向量就被视为整个序列的聚合表示。将这个向量送入一个全连接层即可得到分类结果。由于 BERT 是双向注意力,[CLS] Token 从一开始就能同时关注输入中的所有位置,因此它可以放在序列的最前面而非最后面。
两种范式的核心思想是一致的:从预训练模型中提取一个固定长度的序列级表示向量,然后通过一个线性映射将其投射到类别空间。区别仅在于"用哪个位置的输出"作为这个序列级表示。
12.2.2 添加分类头
下面我们以一个 GPT-2 风格的 Decoder-only 模型为例,完整演示如何为预训练模型添加分类头。假设我们要做一个二分类任务(如垃圾邮件检测)。
预训练 GPT 模型的输出层(out_head)原本将隐藏状态映射到词表大小(如 50,257 维),用于预测下一个 Token。分类微调时,我们需要将这个输出层替换为一个新的线性层,输出维度等于类别数:
import torch
import torch.nn as nn
# 假设已经加载了预训练的 GPT 模型
# model = GPTModel(config)
# load_pretrained_weights(model, ...)
# 第一步:冻结所有预训练参数
for param in model.parameters():
param.requires_grad = False
# 第二步:替换输出层为分类头
num_classes = 2 # 二分类:spam / not spam
model.out_head = nn.Linear(
in_features=model.config["emb_dim"], # 如 768
out_features=num_classes
)
# 新创建的层默认 requires_grad=True,无需额外设置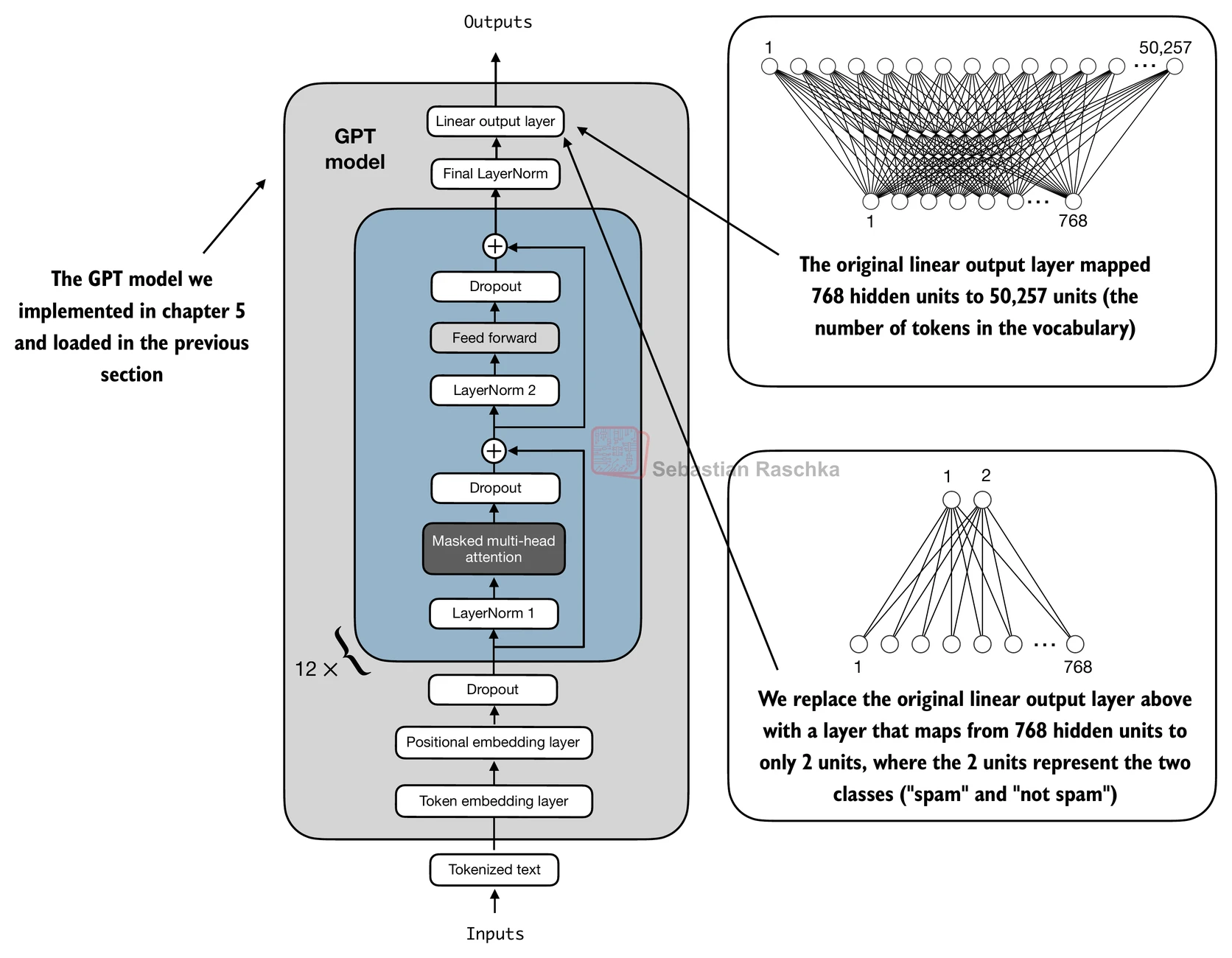
图 12-2-3:分类头的添加方式——将原有的语言模型头(映射到词表维度)替换为一个新的线性层(映射到类别数维度)。
仅训练分类头够吗? 从理论上讲,如果预训练模型的表示足够好,只训练最后的线性层就能取得不错的效果。但实践表明,同时解冻最后一个 Transformer 层和最终的 LayerNorm 可以显著提升分类性能——这些层的参数被微调后,能更好地适配分类任务所需的特征。
# 第三步:解冻最后一个 Transformer 块和最终的 LayerNorm
for param in model.transformer_blocks[-1].parameters():
param.requires_grad = True
for param in model.final_norm.parameters():
param.requires_grad = True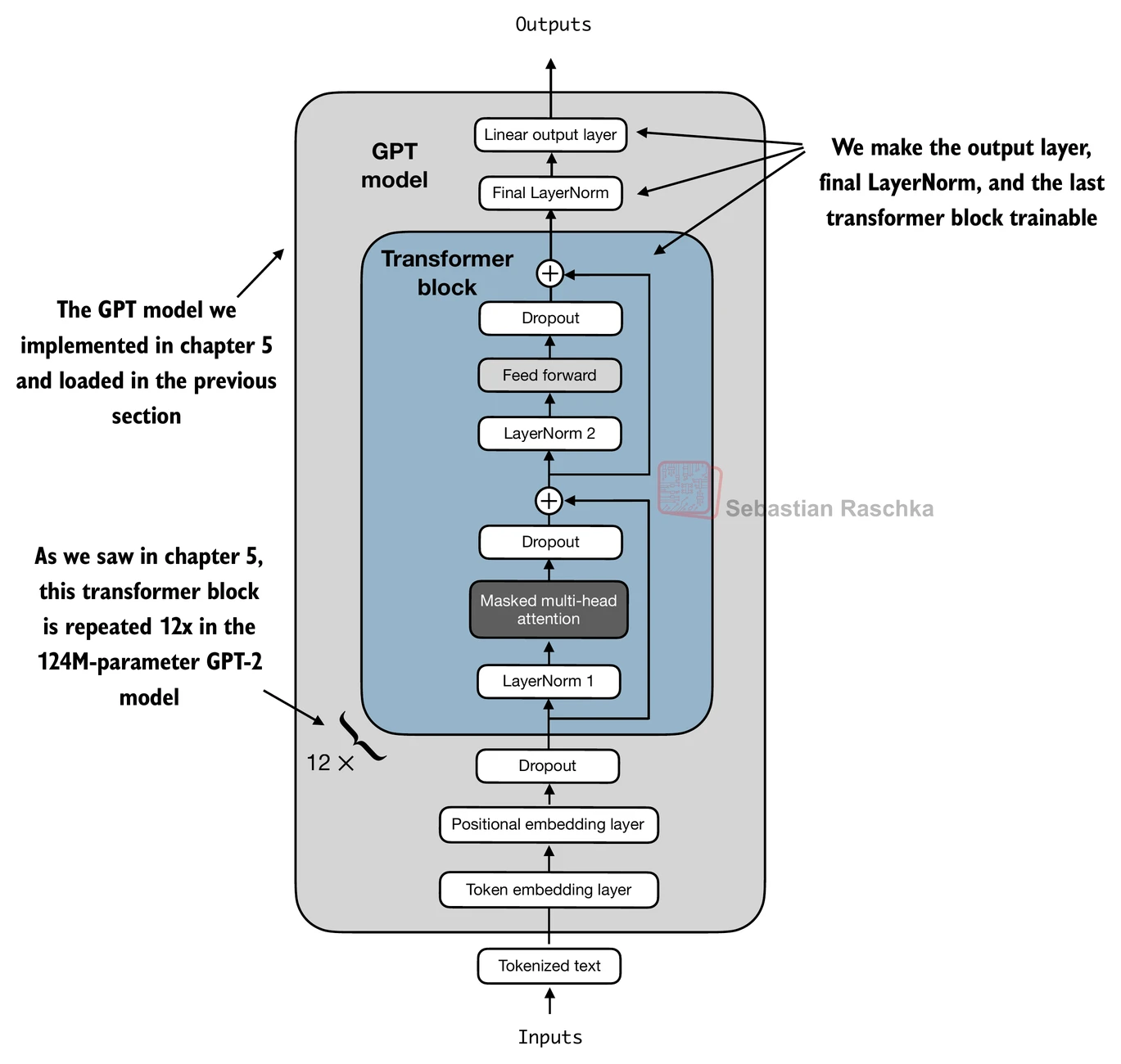
图 12-2-4:选择性解冻策略。冻结前面的层保留预训练知识,解冻最后一个 Transformer 块和 LayerNorm 使模型能适配分类任务。
这种"冻结主体 + 解冻顶部"的策略有两个重要好处:
- 训练效率高:需要计算梯度和更新的参数量极小,显存占用和训练时间大幅减少。
- 防止灾难性遗忘:冻结的低层保留了预训练阶段学到的通用语言特征,不会因为小规模标注数据而被破坏。
12.2.3 提取序列级表示
模型前向传播后,每个输入 Token 位置都会产生一个输出向量。对于分类任务,我们只需要一个能代表整个序列语义的向量。在 GPT 类模型中,我们取最后一个 Token 的输出:
# 前向传播
with torch.no_grad():
outputs = model(input_ids) # shape: (batch_size, seq_len, num_classes)
# 提取最后一个 Token 的输出作为序列级表示
logits = outputs[:, -1, :] # shape: (batch_size, num_classes)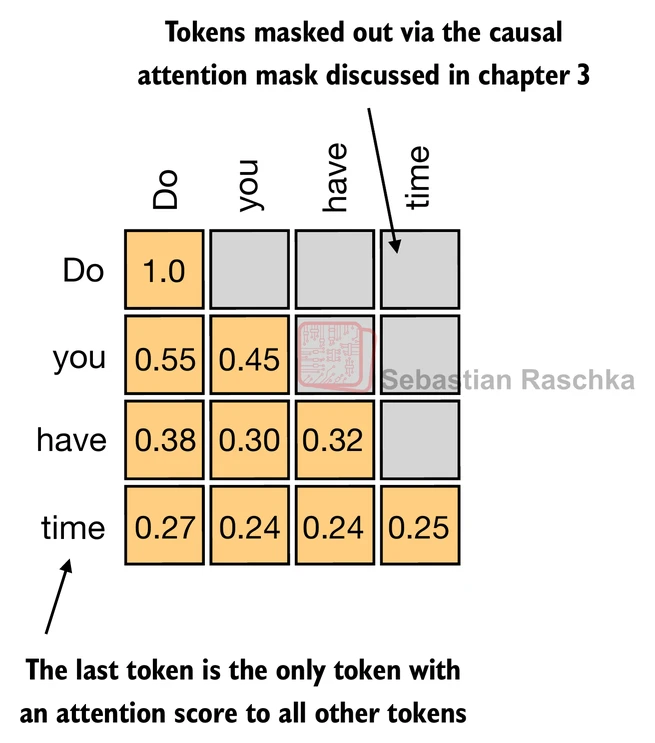
图 12-2-5:在因果注意力机制下,最后一个 Token 位置是唯一能聚合所有前面 Token 信息的位置,因此它的输出向量是最佳的序列级表示。
得到 logits 后,通过 softmax 转换为概率分布,再用 argmax 获取预测类别:
probas = torch.softmax(logits, dim=-1)
predicted_label = torch.argmax(probas, dim=-1)
print(f"预测类别: {predicted_label.item()}")
# 输出: 预测类别: 1 (对应 "spam")
图 12-2-6:分类预测流程——模型输出 logits 经过 softmax 归一化后,选择概率最高的类别作为预测结果。
在推理时 softmax 其实是可选的——因为 softmax 是单调函数,logits 中的最大值对应的类别与 softmax 后概率最大的类别一定相同。但在训练时计算交叉熵损失时,PyTorch 的 CrossEntropyLoss 内部已经集成了 softmax 操作,因此我们应该直接传入原始 logits 而非 softmax 后的概率。
12.2.4 数据准备与 DataLoader
在开始训练之前,需要将文本数据转化为模型能接受的格式。核心步骤包括:分词编码、填充/截断到统一长度、构建 Dataset 和 DataLoader。
以下是一个完整的分类数据集实现,核心逻辑是在 __init__ 中一次性完成分词、截断和填充:
import torch
from torch.utils.data import Dataset, DataLoader
class TextClassificationDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_length=128, pad_token_id=0):
self.labels = labels
self.encoded_texts = [
(tokenizer.encode(text)[:max_length] # 截断
+ [pad_token_id] * max_length)[:max_length] # 填充后再截断到精确长度
for text in texts
]
def __getitem__(self, index):
return (
torch.tensor(self.encoded_texts[index], dtype=torch.long),
torch.tensor(self.labels[index], dtype=torch.long),
)
def __len__(self):
return len(self.labels)构建 DataLoader 时,训练集应打乱顺序并丢弃不完整的末尾 batch(drop_last=True,避免小 batch 导致梯度方差过大),验证集和测试集则保留所有样本:
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True, drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=8, shuffle=False, drop_last=False)12.2.5 损失函数与评估指标
损失函数。 文本分类微调使用标准的交叉熵损失(Cross-Entropy Loss)。对于
其中 CrossEntropyLoss 将 softmax 和负对数似然合并在一起计算,数值稳定且高效:
def calc_loss_batch(input_ids, targets, model, device):
"""计算一个 batch 的分类损失"""
input_ids = input_ids.to(device)
targets = targets.to(device)
# 前向传播,提取最后一个 Token 的 logits
logits = model(input_ids)[:, -1, :] # (batch_size, num_classes)
# 计算交叉熵损失
loss = torch.nn.functional.cross_entropy(logits, targets)
return loss评估指标。 分类任务最直接的评估指标是准确率(Accuracy)。在批量计算时,我们将预测类别与真实标签逐一比对:
def calc_accuracy_loader(data_loader, model, device, num_batches=None):
"""在数据加载器上计算分类准确率"""
model.eval()
correct, total = 0, 0
# 关闭梯度计算,逐 batch 统计预测正确的样本数
with torch.no_grad():
for i, (input_ids, targets) in enumerate(data_loader):
if num_batches is not None and i >= num_batches:
break
input_ids = input_ids.to(device)
targets = targets.to(device)
# 取最后一个 Token 的 logits,用 argmax 得到预测类别
logits = model(input_ids)[:, -1, :]
predicted = torch.argmax(logits, dim=-1)
correct += (predicted == targets).sum().item()
total += targets.size(0)
return correct / total if total > 0 else 0.0对于类别不平衡的场景,还应关注精确率(Precision)、**召回率(Recall)**和 F1 分数,它们提供了更细粒度的性能评价:
12.2.6 训练循环
有了损失函数和评估指标,就可以编写完整的训练循环了。分类微调的训练循环与预训练几乎相同,主要区别在于:(1)跟踪的是分类样本数而非 Token 数;(2)每个 Epoch 结束后计算分类准确率。
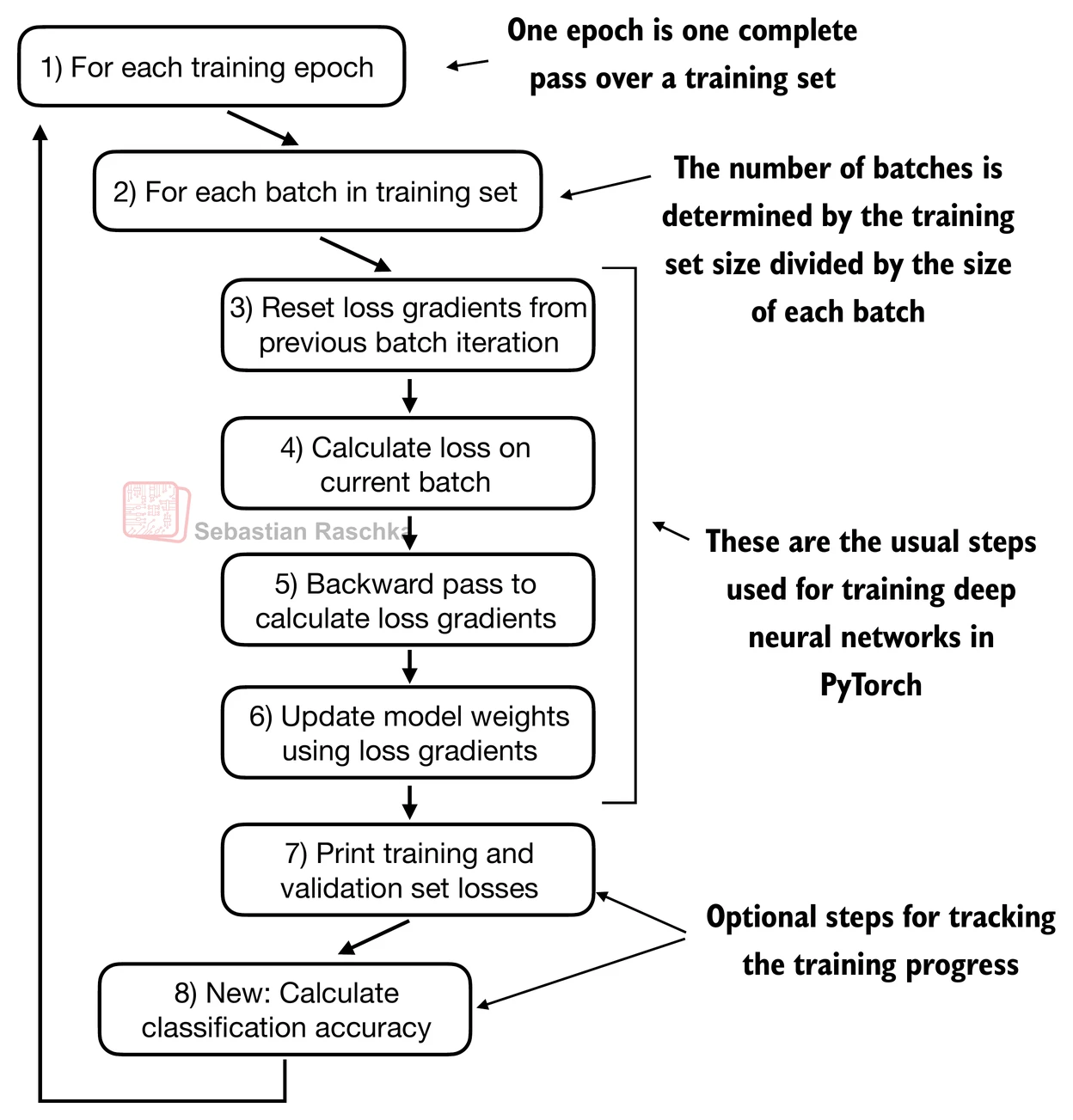
图 12-2-7:分类微调的训练流程。与预训练的主要区别在于损失函数(交叉熵 vs 语言模型损失)和评估方式(准确率 vs 困惑度)。
def train_classifier(model, train_loader, val_loader, optimizer,
device, num_epochs, eval_freq=50):
"""完整的分类微调训练循环"""
train_losses, val_losses = [], []
train_accs, val_accs = [], []
global_step = 0
for epoch in range(num_epochs):
model.train()
for input_ids, targets in train_loader:
# 梯度清零
optimizer.zero_grad()
# 前向传播 + 计算损失
loss = calc_loss_batch(input_ids, targets, model, device)
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
global_step += 1
# 定期打印训练状态
if global_step % eval_freq == 0:
train_loss = evaluate_loss(model, train_loader, device)
val_loss = evaluate_loss(model, val_loader, device)
train_losses.append(train_loss)
val_losses.append(val_loss)
print(f"Epoch {epoch+1} | Step {global_step:05d} | "
f"Train Loss: {train_loss:.3f} | "
f"Val Loss: {val_loss:.3f}")
# 每个 Epoch 结束后计算准确率
train_acc = calc_accuracy_loader(train_loader, model, device)
val_acc = calc_accuracy_loader(val_loader, model, device)
train_accs.append(train_acc)
val_accs.append(val_acc)
print(f" → Train Acc: {train_acc*100:.2f}% | "
f"Val Acc: {val_acc*100:.2f}%")
return train_losses, val_losses, train_accs, val_accs
def evaluate_loss(model, data_loader, device, num_batches=5):
"""快速估算数据集上的平均损失"""
model.eval()
total_loss = 0.0
with torch.no_grad():
for i, (input_ids, targets) in enumerate(data_loader):
if i >= num_batches:
break
total_loss += calc_loss_batch(
input_ids, targets, model, device
).item()
model.train()
return total_loss / min(num_batches, len(data_loader))启动训练时,通常使用 AdamW 优化器配合较小的学习率和适当的权重衰减。微调的学习率一般比预训练低一到两个数量级(如
optimizer = torch.optim.AdamW(
model.parameters(),
lr=5e-5, # 微调常用的学习率
weight_decay=0.1 # 权重衰减,防止过拟合
)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
train_losses, val_losses, train_accs, val_accs = train_classifier(
model, train_loader, val_loader, optimizer,
device, num_epochs=5, eval_freq=50
)一个典型的训练日志可能如下所示:
Epoch 1 | Step 00050 | Train Loss: 0.617 | Val Loss: 0.637
Epoch 1 | Step 00100 | Train Loss: 0.523 | Val Loss: 0.557
→ Train Acc: 70.00% | Val Acc: 72.50%
Epoch 2 | Step 00200 | Train Loss: 0.419 | Val Loss: 0.397
→ Train Acc: 82.50% | Val Acc: 85.00%
Epoch 3 | Step 00300 | Train Loss: 0.333 | Val Loss: 0.320
→ Train Acc: 90.00% | Val Acc: 90.00%
Epoch 4 | Step 00450 | Train Loss: 0.153 | Val Loss: 0.132
→ Train Acc: 100.00% | Val Acc: 97.50%
Epoch 5 | Step 00600 | Train Loss: 0.083 | Val Loss: 0.074
→ Train Acc: 100.00% | Val Acc: 97.50%从日志中可以观察到几个关键信号:
- 损失持续下降:训练和验证损失同步下降,说明模型在有效学习。
- 训练与验证损失接近:二者差距很小,表明没有严重的过拟合。
- 准确率快速上升:仅 5 个 Epoch 就达到了 97.5% 的验证准确率,充分体现了预训练模型在分类任务上的迁移能力。
12.2.7 模型使用与保存
训练完成后,推理时的流程与训练类似——分词、填充、前向传播、取 argmax:
def classify_text(text, model, tokenizer, device,
max_length=128, pad_token_id=0):
"""对单条文本进行分类预测"""
model.eval()
input_ids = tokenizer.encode(text)[:max_length]
input_ids += [pad_token_id] * (max_length - len(input_ids))
input_tensor = torch.tensor(input_ids, device=device).unsqueeze(0)
with torch.no_grad():
logits = model(input_tensor)[:, -1, :]
predicted = torch.argmax(logits, dim=-1).item()
return {0: "正常", 1: "垃圾邮件"}[predicted]
print(classify_text("Click here to claim your $1000 prize!", model, tokenizer, device))
# 输出: 垃圾邮件
print(classify_text("Hey, are we still on for dinner tonight?", model, tokenizer, device))
# 输出: 正常训练好的模型参数可通过 torch.save / torch.load 保存和恢复:
torch.save(model.state_dict(), "text_classifier.pth") # 保存
state = torch.load("text_classifier.pth", map_location=device) # 加载
model.load_state_dict(state)12.2.8 BERT 的分类微调
前面以 GPT 类模型为例进行了详细演示。对于 BERT 类模型,整体流程几乎一致,只有两处关键差异:
第一,使用 [CLS] Token 而非最后一个 Token。 BERT 在输入序列开头插入一个特殊的 [CLS] Token,双向 Transformer 编码后,该位置的输出向量被用作整个序列的表示:
# BERT 风格的分类头
cls_output = bert_model(input_ids)[0][:, 0, :] # 取第 0 个位置([CLS])
logits = classifier_head(cls_output) # 线性分类层第二,文本对分类。 BERT 天然支持文本对(Text Pair)输入,通过 [SEP] Token 分隔两段文本。这使得 BERT 能够处理自然语言推理(NLI)、语义相似度计算等需要理解两段文本关系的任务。输入格式为 [CLS] 句子A [SEP] 句子B [SEP],同样取 [CLS] 位置的输出进行分类。
这两种范式背后的统一原则是:预训练模型提供强大的上下文表示能力,分类微调只需在此基础上添加极少的新参数。无论是 GPT 的最后一个 Token 还是 BERT 的 [CLS] Token,它们都起到"信息汇聚点"的作用,将变长的输入序列压缩为固定维度的向量,为下游分类任务提供统一的接口。
12.2.9 实践建议
在实际应用中,以下几点经验可以帮助你获得更好的分类微调效果:
学习率选择:微调学习率通常在
到 之间。过大会破坏预训练参数,过小则收敛缓慢。 解冻策略:从只训练分类头开始尝试;如果效果不足,逐步解冻更多层。一般解冻最后 1-2 个 Transformer 块即可取得良好效果。
数据平衡:如果类别分布严重不平衡(如正常邮件远多于垃圾邮件),应通过欠采样(Undersampling)、过采样或加权损失函数来处理,否则模型可能偏向多数类。
Epoch 数量:分类微调通常只需 3-5 个 Epoch。训练过久容易导致过拟合,尤其是在小数据集上。
正则化手段:Dropout 和权重衰减(Weight Decay)是防止过拟合的两道重要防线。可以适当增大 Dropout 率(如从 0.1 到 0.2)或加大权重衰减系数。
多任务联合训练:GPT-1 的论文提出了一种有效的策略——在微调阶段同时保留语言模型损失作为辅助目标。总损失为
,其中 是一个较小的权重(如 0.5)。这种做法可以让模型在学习分类任务的同时维持其语言建模能力,有助于提升泛化性能。
本节小结
- 分类微调的核心操作是在预训练模型上添加分类头(一个线性层),将语言模型的输出映射到类别空间。
- GPT 类模型取最后一个 Token 的输出作为序列表示,BERT 类模型取
[CLS]Token 的输出。 - 冻结策略至关重要:冻结大部分预训练参数以保护语言知识,只解冻顶部几层和分类头以适配下游任务。
- 训练使用交叉熵损失和 AdamW 优化器,学习率通常在
量级。 - 评估指标包括准确率、精确率、召回率和 F1 分数,对于不平衡数据集尤其需要关注后三者。
- 整个训练流程(数据准备 → 模型修改 → 训练循环 → 评估推理)已形成成熟的工程范式,通常只需 3-5 个 Epoch 即可获得高质量的分类器。