1.3 优化算法
深度学习模型的训练,本质上是一个在高维参数空间中寻找损失函数最小值的优化过程。优化器(Optimizer)决定了参数在每一步中如何更新,直接影响训练的收敛速度、稳定性和最终性能。从最朴素的随机梯度下降开始,研究者们沿着三条相互交织的演进轴线不断改进优化算法:
- 梯度方向优化:通过引入历史梯度信息来修正更新方向,抑制震荡、加速收敛(Momentum、NAG)。
- 学习率自适应:为每个参数独立调整学习率,使梯度大的参数步长小、梯度小的参数步长大(AdaGrad、RMSProp)。
- 二者结合与进一步改进:将方向优化与学习率自适应统一到一个框架中,并处理正则化耦合等问题(Adam、AdamW)。
本节将沿着这条演进脉络,从 SGD 出发,逐步推导到当前大模型训练的事实标准 AdamW,再介绍新兴的 Muon 优化器与学习率调度策略。
1.3.1 随机梯度下降(SGD)
假设我们有
批量梯度下降(Batch Gradient Descent)在每一步计算全部样本的平均梯度
随机梯度下降(Stochastic Gradient Descent, SGD)的核心思路是:每步只随机选取一个(或一小批)样本来估计梯度。其更新公式为:
其中
实践中更常使用的是小批量 SGD(Mini-batch SGD),每步从训练集中抽取一个大小为
小批量 SGD 在计算效率(充分利用 GPU 并行)和梯度估计方差之间取得了平衡,是深度学习训练的基础范式。然而,SGD 有两个显著的缺陷:
- 震荡问题:在损失曲面呈狭长"峡谷"形状时(不同参数方向的曲率差异很大),SGD 会在陡峭方向上来回震荡,而在平缓方向上前进缓慢。
- 统一学习率的局限:所有参数共享同一个学习率
,无法针对不同参数的梯度特征做差异化调整。
接下来的优化器演进,正是围绕这两个问题展开的。
1.3.2 动量法(Momentum)
第一维演进:梯度方向优化。 动量法(Momentum)由 Polyak 于 1964 年提出,其灵感来源于物理学中的动量概念:一个从山坡滚下的小球,其运动方向不仅取决于当前所受的力(梯度),还受到自身惯性(历史速度)的影响。

动量法引入一个速度向量(velocity)
其中
这意味着
动量法的两个核心优势恰好对应 SGD 的两个缺陷:
- 抑制震荡:在峡谷地形中,梯度在陡峭方向上正负交替。指数加权平均使得相反方向的分量相互抵消,有效抑制了震荡。
- 加速前进:在平缓方向上,梯度方向一致,动量项不断累积同向分量,使得速度越来越大,从而加速收敛。
一句话概括动量法的作用:抑制震荡,惯性加速。
1.3.3 Nesterov 加速梯度(NAG)
标准动量法存在一个微妙的问题:小球凭借惯性可能"冲过"最优点,在接近谷底时产生不必要的振荡。Nesterov 加速梯度(Nesterov Accelerated Gradient, NAG)对此做了一个巧妙的改进——"先走一步再看路"。
NAG 的思路是:既然动量项
这种"前瞻"机制使得优化器在接近最优解时能够提前"刹车",避免冲过头,从而在收敛末期比标准动量法更加稳定。对于凸函数,NAG 具有理论上更优的收敛速率。在 PyTorch 中,只需在 torch.optim.SGD 中设置 nesterov=True 即可启用。
小结: Momentum 和 NAG 完成了优化算法演进的第一维——梯度方向优化。它们通过累积历史梯度信息来获得更稳定的更新方向,但所有参数仍然共享同一个学习率
。接下来我们进入第二维——学习率自适应。
1.3.4 AdaGrad
第二维演进:学习率自适应。 前面的所有方法中,每个参数都使用相同的学习率。但在实际训练中,不同参数的梯度尺度可能差异巨大——有些参数的梯度持续很大(对应陡峭方向),有些则很小(对应平缓方向或稀疏特征)。
AdaGrad(Adaptive Gradient)由 Duchi 等人于 2011 年提出,其核心思想是:用历史梯度的平方和来为每个参数独立调整学习率。
这里所有运算都是逐元素的(element-wise):
AdaGrad 的自适应机制非常直观:
- 对于梯度持续较大的参数,
增长快,有效学习率 迅速减小,抑制了该方向上的大步更新。 - 对于梯度较小的参数,
增长慢,有效学习率保持较大,使该方向上的更新不至于停滞。
从预条件(Preconditioning)的视角来看,AdaGrad 实际上是用梯度的历史幅度作为 Hessian 矩阵对角线的廉价近似,对优化问题做了一个自适应的坐标缩放,从而缓解了病态条件数带来的困难。
然而,AdaGrad 有一个严重的缺陷:
1.3.5 RMSProp
RMSProp(Root Mean Square Propagation)由 Hinton 在 Coursera 课程中提出(未正式发表论文),是对 AdaGrad 的直接修复。问题的根源在于
其中
RMSProp 和 Momentum 分别在不同维度上解决了 SGD 的问题:
| 方法 | 作用维度 | 核心机制 |
|---|---|---|
| Momentum | 梯度方向 | 对梯度本身做指数加权移动平均 |
| RMSProp | 学习率 | 对梯度平方做指数加权移动平均 |
这自然引出一个问题:能否将二者结合?答案就是 Adam。
1.3.6 Adam
第三维演进:方向优化 + 学习率自适应的统一。 Adam(Adaptive Moment Estimation)由 Kingma 和 Ba 于 2014 年提出,将 Momentum(一阶矩估计)和 RMSProp(二阶矩估计)融合到一个框架中。它是深度学习领域最具影响力的优化器之一。
Adam 维护两个状态变量——一阶矩
默认超参数为
偏差修正(Bias Correction):由于
最终的参数更新公式为:
Adam 的结构可以清晰地分解为两部分:
- 分子
:来自 Momentum,提供了经过方向优化的梯度估计。 - 分母
:来自 RMSProp,为每个参数提供自适应的学习率缩放。
内存开销:Adam 需要为每个参数额外存储
1.3.7 AdamW:解耦的权重衰减
Adam 在实践中虽然广受欢迎,但研究者们发现它在泛化能力上有时不如简单的 SGD with Momentum。Loshchilov 和 Hutter (2019) 在论文 Decoupled Weight Decay Regularization 中揭示了问题的根源:Adam 中权重衰减(Weight Decay)与自适应学习率的耦合。
权重衰减是一种重要的正则化技术,其原始形式是在每步更新时让参数按比例缩小:
在传统 SGD 中,这等价于在损失函数中添加
- 对于梯度历史较大的参数,
大,权重衰减的实际效果被削弱。 - 对于梯度历史较小的参数,
小,权重衰减的实际效果被放大。
这种耦合导致权重衰减的正则化效果变得不均匀和不可预测,削弱了模型的泛化能力。
AdamW 的解决方案非常简洁:将权重衰减从梯度更新中分离出来,使其不经过自适应缩放,直接作用于参数。完整的 AdamW 更新步骤为:
关键区别在于最后一行:权重衰减项
AdamW 已经取代 Adam,成为训练大语言模型(如 LLaMA、GPT 系列)和其他现代神经网络的事实标准。在 PyTorch 中可通过 torch.optim.AdamW 直接使用。
1.3.8 Muon 优化器:矩阵视角与谱范数约束
前述所有优化器——无论是 SGD、Momentum 还是 Adam/AdamW——都有一个共同的隐含假设:它们将参数矩阵(如线性层的权重
Muon(Momentum + Orthogonalization)优化器在 2024 年底由 Keller Jordan 等人提出,代表了一种全新的思路:将参数矩阵真正作为矩阵来处理,在谱范数约束下寻找最优更新方向。
要理解 Muon 的动机,需要回顾两种矩阵范数的区别:
- Frobenius 范数:
,将矩阵当作向量,等价于所有元素的 范数。 - 谱范数(Spectral Norm):
,即矩阵最大奇异值,衡量矩阵作为线性映射时的最大放大倍数。
对于神经网络中的线性层
因此,在谱范数约束下优化,比在 Frobenius 范数下更能反映参数更新对网络行为的真实影响。
Muon 的核心思想可以简洁地表述为:SGD 是在 Frobenius 范数约束下的最速下降(steepest descent),Muon 是在谱范数约束下的最速下降。
具体而言,最速下降问题是:在给定的范数约束
- 若约束为 Frobenius 范数:
,即标准梯度下降。 - 若约束为谱范数:
,其中 是梯度 的 SVD 分解。
也就是说,Muon 的更新方向是梯度矩阵的符号奇异值分解——保留奇异向量的方向但将所有奇异值统一为 1。这可以通过对动量累积后的梯度矩阵进行 Newton-Schulz 迭代(一种高效的近似正交化方法)来实现,避免了显式 SVD 的高昂计算开销。
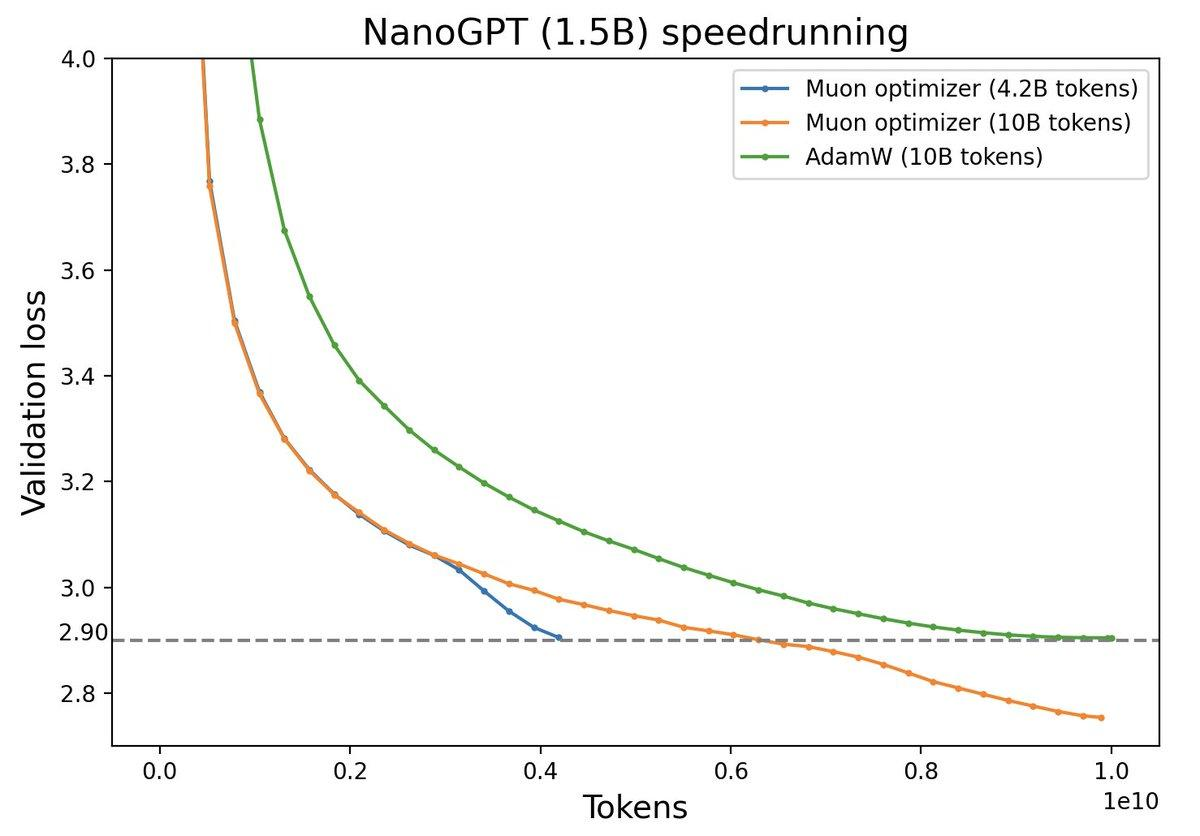
实验表明,Muon 在语言模型训练上表现出显著的收敛优势。如上图所示,在 NanoGPT (1.5B) 的 speedrunning 实验中,Muon 仅使用 4.2B Token 就达到了 AdamW 使用 10B Token 才能达到的验证损失。Kimi K2 模型更是率先在大规模训练中采用了基于 Muon 改进的 MuonClip 优化器。
需要注意的是,Muon 目前主要用于优化矩阵形状的参数(如线性层权重),对于向量形状的参数(如归一化层的缩放因子、嵌入层等),通常仍然使用 AdamW。因此实践中 Muon 往往与 AdamW 混合使用。
图 1-7:Muon 优化器在 NanoGPT (1.5B) 上的训练效率对比。Muon 利用谱范数约束下的最速下降方向,仅用约 4.2B Token 即达到 AdamW 使用 10B Token 的最终验证损失,展现了矩阵视角优化的显著优势。
1.3.9 学习率调度
选择了合适的优化器之后,学习率调度(Learning Rate Schedule)是另一个对训练效果至关重要的因素。学习率决定了每步参数更新的幅度:太大则训练不稳定甚至发散,太小则收敛过慢。现代大模型训练通常采用分阶段的学习率调度策略。
Warmup(预热)
训练初期,模型参数处于随机初始化状态,梯度的方向和幅度都很不稳定。如果此时直接使用较大的学习率,容易导致训练发散。Warmup 策略在训练开始的若干步中,将学习率从接近零线性增加到目标峰值
这给了优化器一个"热身"阶段,让 Adam/AdamW 的一阶矩和二阶矩估计有时间积累到合理的值,从而稳定后续训练。在使用 Pre-Norm 的 Transformer 结构中,Warmup 的重要性有所降低,但仍是大模型训练的标准实践。
Cosine Decay(余弦退火)
Warmup 结束后,学习率需要逐渐衰减以实现精细收敛。余弦退火(Cosine Annealing)是最经典的衰减策略,它将学习率按余弦曲线从峰值平滑降至接近零:
Cosine Decay 的特点是前期衰减较慢(学习率在峰值附近停留较久),中期加速衰减,后期再次减缓趋近于零。这种"慢-快-慢"的节奏在实践中被证明非常有效。
然而,Cosine Decay 有一个显著的工程缺点:衰减曲线依赖于训练总步数
WSD Scheduler(Warmup-Stable-Decay)
WSD 调度器由 MiniCPM 等工作引入,旨在解决 Cosine Decay 的灵活性问题。它将训练分为三个阶段:
- Warmup:学习率线性预热到峰值。
- Stable:学习率保持恒定,持续训练大部分时间(通常占 80%-90% 的 Token)。
- Decay:在训练末期(通常是最后 10%-20%),学习率急剧下降到零或极小值。
WSD 的设计带来两个关键优势:
- 工程灵活性:由于 Stable 阶段的学习率是恒定的,不依赖于训练总步数。可以在训练过程中随时决定"够了",然后执行一个短期 Decay 就能得到收敛良好的模型。
- Scaling Law 研究友好:想要测试不同数据量下的模型性能时,只需训练一个完整的 Stable 主干,然后从不同的 Checkpoint 分叉执行 Decay,即可低成本获取多个数据点。传统的 Cosine Decay 则需要为每个数据量从头训练一遍。
实验表明,WSD 最终达到的收敛效果通常不逊于经过精心调参的 Cosine Decay。一个有趣的现象是:在 Stable 阶段,WSD 的 Loss 下降比 Cosine 慢(因为学习率保持较高),但一进入 Decay 阶段,Loss 就会急剧下坠,在很短时间内追上甚至超越 Cosine 的最终性能。DeepSeek 系列模型也采用了类似的分段衰减策略。
下表总结了三种调度策略的比较:
| 策略 | 形状 | 是否需要预设总步数 | 灵活性 | 典型应用 |
|---|---|---|---|---|
| Cosine Decay | 余弦曲线 | 是 | 低 | BERT、GPT-3 等早期模型 |
| WSD | 梯形 | 否 | 高 | MiniCPM、DeepSeek |
| Linear Decay | 直线 | 是 | 低 | 较少使用 |
1.3.10 小结:优化器演进的全景
回顾本节的内容,优化器的发展遵循了清晰的"三维演进"逻辑:
SGD
│
┌──────────┼──────────┐
▼ ▼
梯度方向优化 学习率自适应
Momentum AdaGrad
│ │
▼ ▼
NAG RMSProp
└──────────┬──────────┘
▼
Adam
│
▼
AdamW(解耦权重衰减)
│
▼
Muon(矩阵视角 + 谱范数约束)每一步改进都在解决前一个方法的具体痛点:
| 优化器 | 解决的问题 | 核心机制 |
|---|---|---|
| SGD | 全量梯度计算代价过高 | 随机采样估计梯度 |
| Momentum | SGD 在峡谷地形中震荡 | 指数加权平均累积梯度方向 |
| NAG | Momentum 在谷底附近冲过头 | "前瞻"机制提前刹车 |
| AdaGrad | 统一学习率不适应不同参数 | 历史梯度平方累加调节学习率 |
| RMSProp | AdaGrad 学习率单调衰减至零 | 指数加权平均替代累加 |
| Adam | 需要同时优化方向和学习率 | Momentum + RMSProp + 偏差修正 |
| AdamW | Adam 中权重衰减与自适应耦合 | 权重衰减从梯度中解耦 |
| Muon | 将矩阵视为向量丢失了结构信息 | 谱范数约束下的最速下降 |
在学习率调度方面,Warmup 解决了训练初期的稳定性问题,Cosine Decay 和 WSD 分别提供了不同工程需求下的衰减方案。对于大模型预训练,当前的标准配置是 AdamW(或 Muon + AdamW 混合) 搭配 Warmup + Cosine Decay 或 WSD 调度器。理解这些优化算法的设计逻辑和演进脉络,是深入理解大模型训练的重要基础。