26.7 批处理与吞吐量优化
在前面几节中,无论是文本生成(26.1)、MATH-500 评测(26.2)、自一致性采样(26.3)、GRPO 训练(26.4)还是蒸馏(26.6),所有代码都采用逐条处理的方式——每次只处理一个提示词、一个样本。这种方式代码简洁、便于调试,但当我们需要评估 500 道数学题、为每道题采样多条推理路径、或在强化学习中生成大量 rollout 时,逐条处理的总耗时就变得难以接受。
本节聚焦批处理(Batching) 这一核心工程技巧。我们将依次解答三个问题:为什么批处理能提升吞吐量?不同长度的序列如何打包到同一个批次中?实际场景下批处理能带来多大的加速?学完本节后,你将掌握从零实现批量文本生成的完整方法,包括左填充(Left Padding)、注意力掩码构建、已完成序列的提前退出(Early-Stop),以及在评测、采样、训练三大场景中应用批处理的工程模式。
一、延迟与吞吐量:两种性能目标
在优化推理性能时,我们需要区分两个本质不同的目标:
- 延迟(Latency):完成单个请求所需的时间。用户交互场景追求低延迟——用户提问后希望尽快看到回答。
- 吞吐量(Throughput):单位时间内能处理的请求总数。离线批量评测、数据生成等场景追求高吞吐。
逐条生成是延迟最优的策略(没有填充开销、没有批次协调),但吞吐量很低——GPU 在处理单条短序列时,大量计算单元处于空闲状态。批处理的核心思想是将多条请求打包到一次前向传播中,让 GPU 的并行计算单元得到充分利用,从而在相同时间内处理更多请求。
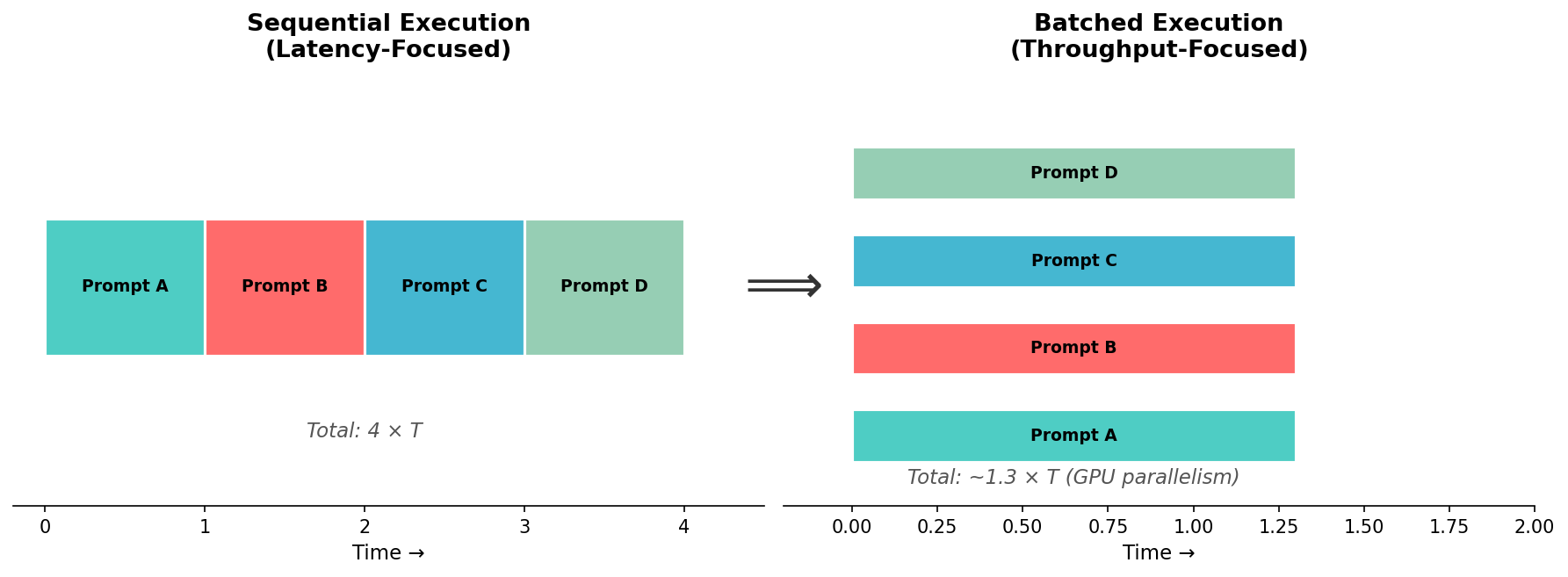
上图对比了两种执行模式:左侧逐条处理四个提示词需要
何时不该用批处理? 如果模型很小且运行在 CPU 上,填充和掩码的额外开销可能抵消并行收益。实际使用前应先做基准测试(benchmark)。
二、核心挑战:不等长序列的填充与掩码
2.1 问题:PyTorch 张量必须是矩形的
批处理的主要技术障碍在于:不同的提示词通常有不同的长度。一道简单的加法题可能只需 40 个 token,而一道复杂的几何题可能需要 120 个 token。但 PyTorch 张量要求每个维度的大小一致,因此必须对较短的序列进行填充(Padding)。
2.2 左填充(Left Padding)
对于自回归生成场景,我们采用左填充——在序列的左侧插入填充 token,使所有序列的右端对齐。这样做的好处是:所有序列在最后一个位置都是真实的 token,模型可以从同一个位置开始生成,无需额外处理生成起点。
import torch
def left_pad_batch(token_id_lists, pad_id):
"""将不等长的 token 列表左填充为统一长度的批次张量
Args:
token_id_lists: 分词后的 token ID 列表的列表
pad_id: 填充 token 的 ID(通常是 <|endoftext|> 的 ID)
Returns:
input_ids: 形状为 (batch_size, max_len) 的张量
attn_mask: 形状为 (batch_size, max_len) 的布尔掩码
True 表示真实 token,False 表示填充位置
"""
max_len = max(len(t) for t in token_id_lists)
padded = [
[pad_id] * (max_len - len(t)) + t # 左侧填充
for t in token_id_lists
]
input_ids = torch.tensor(padded, dtype=torch.long)
attn_mask = (input_ids != pad_id) # True = 真实 token
return input_ids, attn_mask示例:假设有两条序列 "2+2?" 和 "3+3=6?",分词后分别为 4 和 6 个 token。左填充后:
Seq 0: [PAD] [PAD] T₁ T₂ T₃ T₄ ← 填充 2 个 PAD
Seq 1: T₁ T₂ T₃ T₄ T₅ T₆ ← 无需填充2.3 注意力掩码的构建
标准的因果注意力掩码(Causal Mask)只需保证"每个 token 只能看到自己和之前的 token"。引入填充后,需要在因果掩码的基础上额外屏蔽填充位置,确保填充 token 不参与注意力计算。
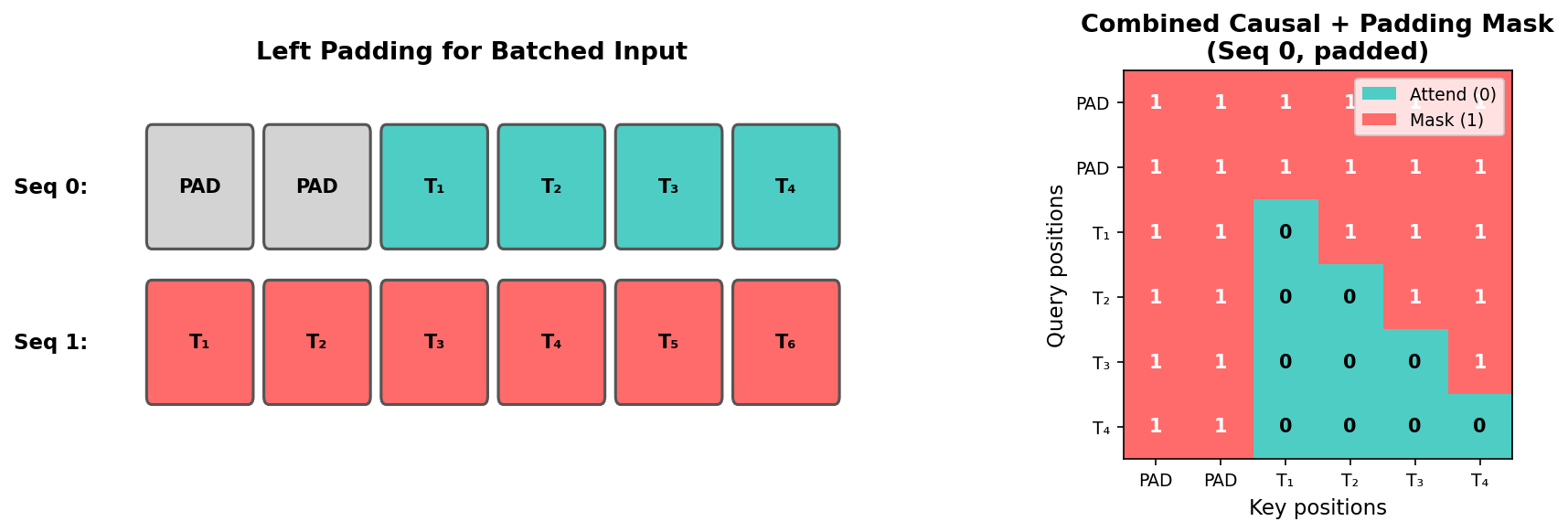
上图左侧展示了左填充的结果,右侧展示了对应的组合掩码(Combined Mask)。掩码中 1 表示被屏蔽,0 表示允许注意。可以观察到:
- 前两列(PAD 位置)全部被屏蔽——任何 query 都不会关注 PAD 位置的 key
- 对角线以上全部被屏蔽——标准因果掩码,禁止"看未来"
- 只有左下角的三角区域(真实 token 之间的因果关系)才是允许注意的
在模型的前向传播中,这个掩码被应用于注意力分数矩阵:
def build_batched_causal_mask(attn_mask, seq_len, device):
"""构建结合因果约束和填充屏蔽的 4D 注意力掩码
Args:
attn_mask: (B, L) 布尔掩码,True=真实 token
seq_len: 序列总长度 L
device: 计算设备
Returns:
mask: (B, 1, L, L) 布尔掩码,True=屏蔽
"""
B = attn_mask.shape[0]
# 1. 标准因果掩码:上三角为 True(屏蔽未来位置)
causal = torch.triu(
torch.ones(seq_len, seq_len, device=device, dtype=torch.bool),
diagonal=1
) # (L, L)
causal_4d = causal[None, None, :, :] # (1, 1, L, L)
# 2. 填充掩码:PAD 位置的 key 被屏蔽
key_pad_mask = (~attn_mask).view(B, 1, 1, seq_len) # (B, 1, 1, L)
# 3. 合并:只要有一个说屏蔽,就屏蔽
combined = causal_4d | key_pad_mask # (B, 1, L, L)
return combined此外,还需要将填充位置的 query 向量归零——即使填充 token 的 query 不应该影响输出,如果不归零,它可能通过 KV Cache 污染后续生成步骤:
# 在模型前向传播中
if attn_mask is not None:
query_mask = attn_mask[:, pos_start:pos_end].unsqueeze(-1) # (B, L, 1)
x = x * query_mask.to(x.dtype) # 填充位置的嵌入归零2.4 数值稳定性
将掩码位置设为
# 标准做法:attn_scores.masked_fill(mask, -inf) 后直接 softmax
# 稳健做法:手动 log-sum-exp
attn_scores = attn_scores.masked_fill(mask, float('-inf'))
row_max = attn_scores.amax(dim=-1, keepdim=True)
row_max = torch.where(
torch.isfinite(row_max), row_max, torch.zeros_like(row_max)
)
exp_scores = torch.exp(attn_scores - row_max)
exp_scores = exp_scores.masked_fill(mask, 0.0)
denom = exp_scores.sum(dim=-1, keepdim=True).clamp(min=1e-38)
attn_weights = exp_scores / denom对于批处理场景,建议在注意力计算路径中使用 float32 精度(即使模型参数用 bfloat16),以避免严重填充情况下的精度损失。
三、批量生成的完整实现
有了左填充和注意力掩码,就可以实现批量文本生成。下面的代码展示了完整的批量生成函数,支持 KV Cache 和 EOS 检测:
import torch
@torch.inference_mode()
def generate_batched(model, input_ids, max_new_tokens, eos_id, pad_id):
"""批量文本生成(带 KV Cache 和 EOS 检测)
Args:
model: 支持批处理的语言模型(接受 attn_mask 参数)
input_ids: (B, L) 左填充后的输入张量
max_new_tokens: 最大生成长度
eos_id: 结束 token 的 ID
pad_id: 填充 token 的 ID
Returns:
generated: (B, T) 生成的 token 张量
"""
device = input_ids.device
B = input_ids.shape[0]
# 构建注意力掩码:True = 真实 token
attn_mask = (input_ids != pad_id).to(torch.bool)
# Prefill 阶段:一次性处理所有输入 token
logits = model(input_ids, attn_mask=attn_mask)
next_logits = logits[:, -1, :] # 取最后一个位置的 logits
finished = torch.zeros(B, dtype=torch.bool, device=device)
generated_tokens = []
# Decode 阶段:逐 token 生成
for _ in range(max_new_tokens):
if finished.all():
break
next_token = torch.argmax(next_logits, dim=-1, keepdim=True) # (B, 1)
# 已完成的序列强制输出 EOS(保持形状一致)
eos_tensor = torch.full_like(next_token, eos_id)
next_token = torch.where(
finished.unsqueeze(1), eos_tensor, next_token
)
generated_tokens.append(next_token)
# 更新注意力掩码(新 token 一定是真实 token)
ones = torch.ones(B, 1, dtype=torch.bool, device=device)
attn_mask = torch.cat([attn_mask, ones], dim=1)
# 前向传播(利用 KV Cache 只计算新 token)
next_logits = model(next_token, attn_mask=attn_mask)[:, -1, :]
# 更新完成标记
finished = finished | (next_token.squeeze(1) == eos_id)
return torch.cat(generated_tokens, dim=1) if generated_tokens else input_ids[:, 0:0]生成完成后,需要对结果进行后处理——截断 EOS 之后的内容并解码:
def decode_batch(generated, tokenizer, eos_id):
"""解码批量生成结果,在 EOS 处截断"""
results = []
for row in generated:
eos_positions = (row == eos_id).nonzero(as_tuple=True)[0]
if len(eos_positions) > 0:
row = row[:eos_positions[0]] # 截断到第一个 EOS
results.append(tokenizer.decode(row.tolist()))
return results四、进阶优化:已完成序列提前退出
上面的基础实现有一个效率问题:即使某条序列已经生成了 EOS,它仍然占据批次中的一个位置,参与每一步的前向传播。当批次中不同序列的生成长度差异很大时(例如一条 50 token,另一条 500 token),这会造成大量无效计算。
提前退出(Early-Stop) 策略在每步解码后将已完成的序列从活跃批次中移除,收缩 KV Cache 和注意力掩码,只对仍在生成的序列执行前向传播。
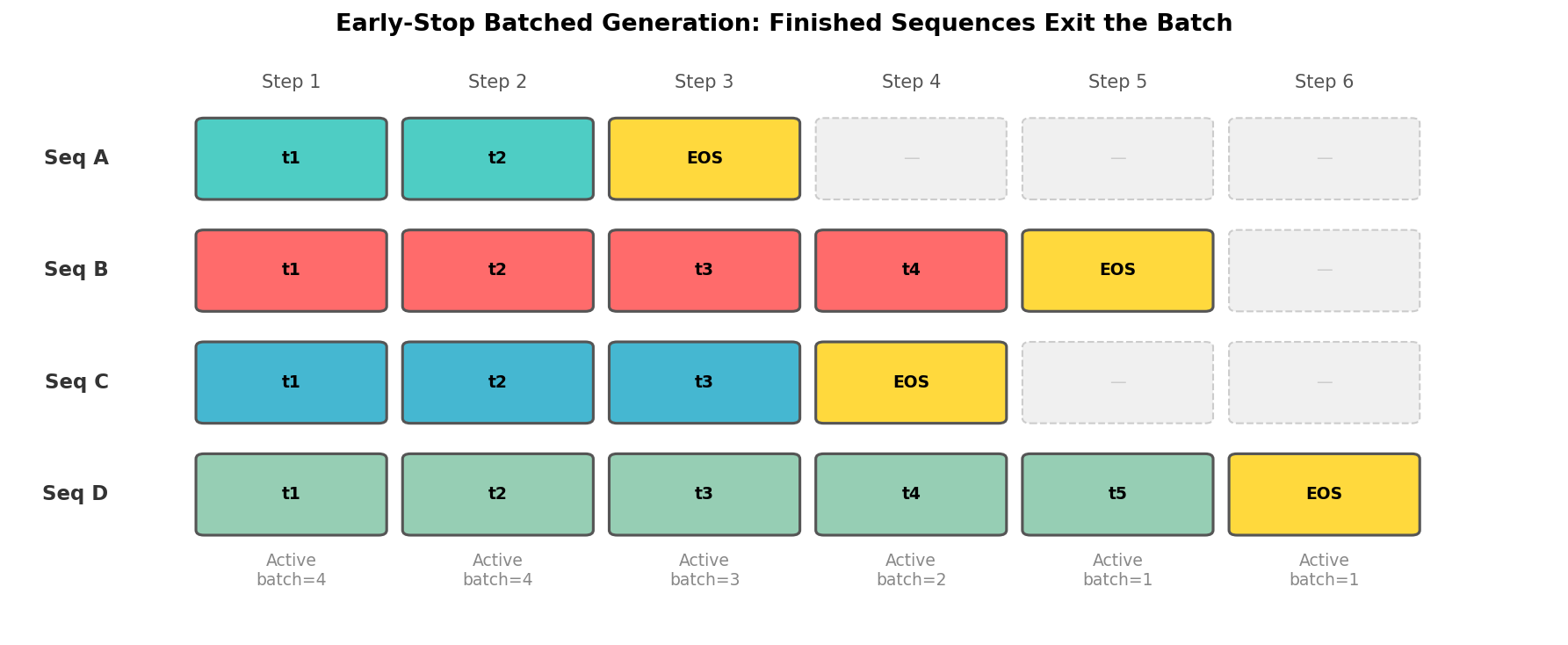
上图展示了 4 条序列的生成过程:Seq A 在第 3 步生成 EOS 后退出,Seq C 在第 4 步退出,活跃批次逐步缩小。关键操作是收缩 KV Cache:
def shrink_kv_cache(cache, keep_mask, n_layers):
"""按布尔掩码收缩 KV Cache 的 batch 维度
Args:
cache: KV Cache 对象
keep_mask: (B,) 布尔张量,True = 保留
n_layers: Transformer 层数
"""
for layer_idx in range(n_layers):
k, v = cache.get(layer_idx) # (B, H, L, D)
cache.update(layer_idx, (k[keep_mask], v[keep_mask]))完整的 Early-Stop 生成循环在基础版本上增加了三个关键步骤:
- 检测新完成的序列:
newly_finished = (next_token == eos_id) - 计算存活掩码并收缩:
keep_mask = ~newly_finished,然后对 KV Cache、注意力掩码、活跃索引执行索引筛选 - 将生成结果散射回全尺寸张量:用
index_copy_将活跃子批次的 token 写入完整的(B, 1)张量
这种实现更复杂,但在序列长度差异大的场景中能显著减少无效计算。
五、应用场景:评测、采样与训练
批处理在推理模型的三大核心工作流中都有应用,但具体模式有所不同:
5.1 批量评测(MATH-500)
评测任务需要对数百道题目生成答案并评分。不同题目的提示词长度不同,因此需要左填充和注意力掩码(即使用完整的批处理模型)。
def evaluate_math500_batched(model, tokenizer, problems, batch_size=64):
"""批量评测 MATH-500"""
num_correct = 0
for start in range(0, len(problems), batch_size):
batch = problems[start:start + batch_size]
# 编码并左填充
prompts = [render_prompt(p["problem"]) for p in batch]
tokenized = [tokenizer.encode(p) for p in prompts]
input_ids, attn_mask = left_pad_batch(tokenized, tokenizer.pad_token_id)
input_ids = input_ids.to(device)
# 批量生成
generated = generate_batched(
model, input_ids, max_new_tokens=2048,
eos_id=tokenizer.eos_token_id,
pad_id=tokenizer.pad_token_id
)
# 逐条评分
texts = decode_batch(generated, tokenizer, tokenizer.eos_token_id)
for text, problem in zip(texts, batch):
extracted = extract_final_answer(text)
num_correct += int(grade_answer(extracted, problem["answer"]))
return num_correct / len(problems)5.2 批量自一致性采样
自一致性采样(26.3 节)为同一道题生成多条推理路径。由于所有路径共享同一个提示词,序列长度完全相同,不需要填充。这是最简单的批处理场景——直接将同一个 input_ids 重复 num_samples 次即可:
def batch_self_consistency(model, tokenizer, prompt, num_samples=8, temperature=0.9):
"""批量自一致性采样(同一提示,无需填充)"""
input_ids = torch.tensor(
tokenizer.encode(prompt), dtype=torch.long, device=device
).unsqueeze(0)
# 重复 num_samples 次,所有行完全相同
input_ids = input_ids.expand(num_samples, -1) # (num_samples, L)
# 带温度的采样生成(非贪心)
generated = generate_with_sampling(
model, input_ids, max_new_tokens=2048,
temperature=temperature, top_p=0.9,
eos_id=tokenizer.eos_token_id
)
# 多数投票
answers = [extract_final_answer(decode(row)) for row in generated]
return majority_vote(answers)5.3 批量 GRPO Rollout
GRPO 训练(26.4 节)中,每步需要为同一道题生成多个 rollout。与自一致性采样类似,所有 rollout 共享同一个提示词,不需要填充。批处理 GRPO 的 --batch_size 参数控制每次并行生成多少个 rollout:
# 命令行示例(非代码运行)
# python rlvr_grpo_batched.py --num_rollouts 8 --batch_size 4 --max_new_tokens 1024
#
# 含义:每步生成 8 个 rollout,分 2 批,每批 4 个并行生成注意:batch_size 增大会显著增加显存压力。如果 num_rollouts=8 且 batch_size=8,所有 rollout 同时在 GPU 上,显存需求可能翻倍。实际使用中需要在 batch_size、num_rollouts 和 max_new_tokens 之间权衡。
5.4 批量蒸馏训练
蒸馏训练(26.6 节)中,每条训练样本的提示词和回答长度都不同,因此需要左填充和注意力掩码,与评测场景类似。关键区别在于训练场景需要计算梯度,因此显存占用更高:
def train_distill_batched(model, train_data, batch_size=4, max_seq_len=1024):
"""批量蒸馏训练的核心循环"""
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
for epoch in range(num_epochs):
random.shuffle(train_data)
for start in range(0, len(train_data), batch_size):
batch = train_data[start:start + batch_size]
# 左填充并截断到 max_seq_len
padded_ids, attn_mask = left_pad_batch(
[ex["token_ids"][:max_seq_len] for ex in batch],
pad_id=tokenizer.pad_token_id
)
# 前向传播 + 损失计算(只计算回答部分)
logits = model(padded_ids[:, :-1], attn_mask=attn_mask[:, :-1])
targets = padded_ids[:, 1:]
loss = masked_cross_entropy(logits, targets, attn_mask[:, 1:])
# 反向传播
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()六、性能对比:单序列 vs 批处理
以下数据基于 Qwen3 0.6B 模型,在 H100 GPU 和 DGX Spark 两种硬件上的实测结果:
| 任务 | 模式 | 批大小 | 显存 | H100 耗时 | DGX Spark 耗时 |
|---|---|---|---|---|---|
| MATH-500 评测 | 逐条 | — | 1.8 GB | 90.0 min | 174.7 min |
| MATH-500 评测 | 批处理 | 64 | 23.4 GB | 16.0 min | 108.4 min |
| 自一致性采样 | 逐条 | — | 1.8 GB | 252.0 min | 340.8 min |
| 自一致性采样 | 批处理 | 3 | 2.5 GB | 129.0 min | 243.3 min |
| GRPO 训练 | 逐条 | — | 43.4 GB | 68.0 min | 63.7 min |
| GRPO 训练 | 批处理 | 4 | 44.9 GB | 19.0 min | 23.1 min |
| 蒸馏训练 | 逐条 | — | 8.3 GB | 10.9 min | 32.8 min |
| 蒸馏训练 | 批处理 | 4 | 8.3 GB | 9.1 min | 28.2 min |
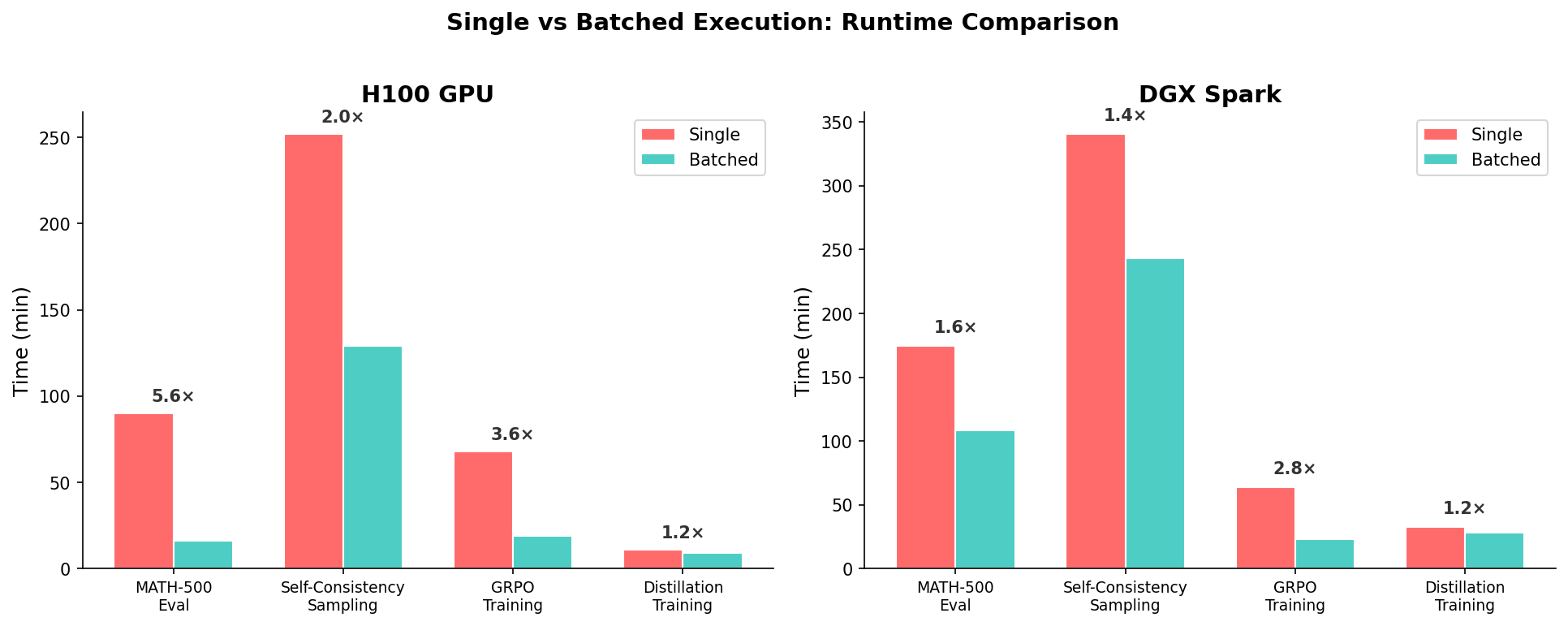
从数据中可以读出几个关键结论:
1. 在高端 GPU(H100)上批处理加速非常显著。 MATH-500 评测从 90 分钟降到 16 分钟(5.6 倍加速),GRPO 训练从 68 分钟降到 19 分钟(3.6 倍加速)。这是因为 H100 拥有大量并行计算单元,单条序列根本"喂不饱"GPU。
2. 在较慢的硬件上加速比降低。 DGX Spark 上 MATH-500 评测的加速比只有 1.6 倍(对比 H100 的 5.6 倍)。这说明批处理的收益高度依赖硬件的并行能力。
3. 显存是主要约束。 MATH-500 评测的批大小从 1 增加到 64 时,显存从 1.8 GB 暴增到 23.4 GB(13 倍)。实际使用中需要根据显存预算选择合适的批大小。
4. 不需要填充的场景开销更低。 自一致性采样(batch_size=3)和 GRPO(batch_size=4)的显存增长很小(因为同一提示词不需要填充),但加速仍然可观。
5. 蒸馏训练的加速最小。 从 10.9 降到 9.1 分钟(1.2 倍),因为蒸馏训练中前向传播只占总时间的一部分,反向传播和参数更新无法通过简单批处理加速。
七、小结
批处理是将推理模型工程从"能跑"提升到"能用"的关键一步。本节的核心要点可以归纳为三点:
填充与掩码是批处理的基础设施。左填充保证生成起点对齐,组合掩码(因果 + 填充)保证注意力计算的正确性,query 归零防止填充 token 污染 KV Cache。
不同场景的批处理复杂度不同。同一提示词的多路采样(自一致性、GRPO rollout)最简单——不需要填充;不同提示词的批量生成(评测、蒸馏)需要完整的填充和掩码机制。
加速效果取决于硬件和任务特性。高端 GPU 上推理密集型任务(评测、采样)的加速最为显著,而训练任务因为反向传播瓶颈,批处理的收益相对有限。选择合适的批大小需要在吞吐量和显存之间找到平衡点。