7.8 LLM 训练速度优化(9 步实战)
前几节关注的是模型架构的设计与差异。但在实际工程中,一个好的模型架构只有搭配高效的训练流程才能发挥作用。本节以 GPT-2 124M 模型在 A100 GPU 上的训练为实验平台,展示一条从 12.5K tokens/sec 到 142K tokens/sec 的 9 步渐进优化路径(11.3 倍加速),最终扩展到 4 卡 DDP 达到 419K tokens/sec。每一步修改都是独立可验证的,读者可以逐步叠加以理解各优化手段的贡献。

图 7-27:9 步训练优化路径。从 12.5K tokens/sec 到 142K tokens/sec 的渐进优化,展示每一步的加速贡献。
7.8.1 实验基线
基线代码直接使用第 5 章的标准训练流程,唯一的改动是增大上下文长度(256 → 1024)、增大批量大小(4 → 8)并使用更大的训练语料,以便在单卡上产生足够的计算负载来暴露性能瓶颈。基线模型的关键配置如下:
GPT_CONFIG_124M = {
"vocab_size": 50257,
"context_length": 1024,
"emb_dim": 768,
"n_heads": 12,
"n_layers": 12,
"drop_rate": 0.1,
"qkv_bias": False
}基线性能(单卡 A100):
| 指标 | 值 |
|---|---|
| Avg tok/sec | 12,525 |
| Reserved memory | 26.26 GB |
此时模型使用 float32 精度,注意力采用手写的缩放点积实现(显式构造因果掩码矩阵、手动 softmax),LayerNorm 和 GELU 也是从零实现的 Python 版本。这些"教学友好"的实现方式恰恰是性能优化的切入点。
7.8.2 九步优化详解
以下每一步均在前一步的基础上叠加,表中展示各步的绝对性能和相对增益。
| 步骤 | 优化手段 | tok/sec | 显存 (GB) | 相对上一步加速 | 累计加速 |
|---|---|---|---|---|---|
| 0 | 基线(float32, 手写算子) | 12,525 | 26.26 | — | 1.0x |
| 1 | 动态生成因果掩码 | 12,526 | 26.24 | ~1.0x | 1.0x |
| 2 | 启用 Tensor Core | 27,648 | 26.24 | 2.2x | 2.2x |
| 3 | Fused AdamW | 28,399 | 26.24 | 1.03x | 2.3x |
| 4 | DataLoader pin_memory | 28,402 | 26.24 | ~1.0x | 2.3x |
| 5 | bfloat16 混合精度 | 45,486 | 13.79 | 1.6x | 3.6x |
| 6 | PyTorch 原生 LayerNorm + GELU | 55,256 | 11.56 | 1.2x | 4.4x |
| 7 | FlashAttention | 91,901 | 5.90 | 1.7x | 7.3x |
| 8 | torch.compile | 112,046* | 6.19 | 1.2x | 8.9x |
| 9 | 词表填充 + 增大 batch_size | 142,156* | 22.51 | 1.3x | 11.3x |
表 7-9:9 步优化的性能增量。步骤 0-7 的 tok/sec 为 Avg tok/sec(第一个 epoch 的滑动平均),步骤 8-9 因 torch.compile 编译预热的影响改用 Step tok/sec(epoch 末尾单步值)。
下面逐步展开。
步骤 1:动态生成因果掩码
原始代码在模型初始化时将因果掩码作为 buffer 注册到模型中:
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length), diagonal=1)
)这个 (context_length, context_length) 的矩阵会常驻显存。对于 1024 的上下文长度,这只有 4 MB(float32),影响微乎其微。但在 Llama 3.2 等支持 131K 上下文的模型中,该矩阵占用高达 64 GB(131072² × 4 字节),完全不可接受。改为在 forward 中动态构造:
mask_bool = torch.triu(
torch.ones(num_tokens, num_tokens, device=x.device),
diagonal=1
).bool()性能变化可忽略,但这是一个良好的工程习惯——永远不要将与序列长度平方成正比的张量作为静态 buffer 保存。
步骤 2:启用 Tensor Core(2.2 倍加速)
这是 9 步中收益最大的单一改动。NVIDIA 从 Volta 架构(V100)起在 GPU 中内置了 Tensor Core——专门为矩阵乘法设计的硬件单元,吞吐量远高于通用 CUDA Core。默认情况下 PyTorch 使用最高精度的 float32 矩阵乘法,不会调用 Tensor Core 的 TF32 模式。一行代码即可启用:
torch.set_float32_matmul_precision("high")设为 "high" 后,PyTorch 会在 float32 矩阵乘法中自动使用 TF32 格式(8 位指数 + 10 位尾数,而非 float32 的 23 位尾数),允许 Tensor Core 以接近 float16 的吞吐量执行计算,同时保持 float32 的数值范围。在 A100 上,TF32 矩阵乘法的理论吞吐量是 float32 的约 8 倍,实测 2.2 倍的加速已经相当显著(剩余差距被访存和非矩阵运算消耗)。
图 7-28:Tensor Core 的 TF32 计算模式。通过降低浮点尾数位宽(23 位 → 10 位),在保持数值范围的同时获得接近 float16 的吞吐量。
需要注意的是,Tensor Core 仅在 GPU 计算能力 ≥ 7.0(Volta 及以后)时可用:
capability = torch.cuda.get_device_capability()
if capability[0] >= 7:
torch.set_float32_matmul_precision("high")步骤 3:Fused AdamW(1.03 倍加速)
标准 AdamW 优化器的 step() 方法会对每个参数分别执行一系列逐元素操作(计算一阶矩、二阶矩、偏差校正、权重衰减、参数更新),每次操作都要从显存加载数据并写回。Fused 版本将这些操作合并为单个 CUDA kernel,大幅减少显存访问次数:
optimizer = torch.optim.AdamW(
model.parameters(),
lr=5e-4,
weight_decay=0.1,
fused=True # 启用融合 kernel
)对于 124M 模型,优化器步骤占总训练时间的比例较低,因此加速不显著(约 3%)。但在更大模型上(参数量越大,优化器逐元素操作越多),fused AdamW 的收益会更明显。
步骤 4:DataLoader pin_memory(微弱加速)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
pin_memory=True # 预分配页锁定内存
)pin_memory=True 使 DataLoader 在 CPU 端将数据分配到页锁定(pinned)内存区域。页锁定内存不会被操作系统换出到磁盘,可以通过 DMA 直接传输到 GPU 显存,避免了一次从可分页内存到页锁定内存的中间拷贝。在本实验中数据量不大、CPU-GPU 传输不是瓶颈,因此加速几乎不可见。但在大规模训练中(尤其是图像/音频等大批量数据),pin_memory 是必开选项。
步骤 5:bfloat16 混合精度(1.6 倍加速,显存减半)
这一步将模型参数和计算从 float32 切换到 bfloat16:
model.to(device).to(torch.bfloat16)bfloat16(brain floating point 16)使用 8 位指数 + 7 位尾数,与 float32 共享相同的数值范围(约 ±3.4×10³⁸),但精度较低(有效位数从 24 位降至 8 位)。其优势在于:
- 显存减半:每个参数从 4 字节降为 2 字节,26 GB → 14 GB。
- 计算加速:Tensor Core 对 bfloat16 的吞吐量是 TF32 的 2 倍。
- 数值稳定性优于 float16:float16 的指数位只有 5 位,数值范围为 ±65504,大模型训练中极易溢出。bfloat16 保留了 float32 的全部指数位,训练中几乎不需要 loss scaling 等额外措施。
这也是为什么当代 LLM 训练几乎全部使用 bfloat16 而非 float16 的原因。
步骤 6:替换手写算子为 PyTorch 原生实现(1.2 倍加速)
将教学用的手写 LayerNorm 和 GELU 替换为 PyTorch 内置版本:
# 手写 LayerNorm(替换前)
class LayerNorm(nn.Module):
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
return self.scale * (x - mean) / torch.sqrt(var + self.eps) + self.shift
# PyTorch 原生版本(替换后)
self.norm1 = nn.LayerNorm(cfg["emb_dim"])
# 手写 GELU(替换前)
class GELU(nn.Module):
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
# PyTorch 原生版本(替换后)
nn.GELU(approximate="tanh")PyTorch 的 nn.LayerNorm 底层调用 C++/CUDA 编写的融合 kernel,将均值计算、方差计算、归一化、缩放和偏移五个操作合并为一次显存读写。手写版本则产生多个独立的逐元素操作,每次都要往返显存。nn.GELU 同理——原生版本用单个 kernel 完成整个激活函数计算,避免了手写版本中 tanh、pow、sqrt 等多次中间张量的分配和回收。
这一步的加速(1.2 倍)和显存节省(13.79 → 11.56 GB)可能出乎意料——"仅仅"替换两个小模块竟有如此效果。原因在于 LayerNorm 和 GELU 在每个 Transformer 块中各出现两次,12 层模型意味着总共 48 次调用,累积效应不可忽视。
步骤 7:FlashAttention(1.7 倍加速,显存再减半)
这是 9 步中显存收益最大的改动。将手写的多头注意力替换为 PyTorch 的 scaled_dot_product_attention(底层调用 FlashAttention 算法):
class PyTorchMultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out, num_heads, dropout=0.0, qkv_bias=False):
super().__init__()
self.num_heads = num_heads
self.head_dim = d_out // num_heads
self.d_out = d_out
# 将 Q/K/V 三个投影合并为一个矩阵乘法
self.qkv = nn.Linear(d_in, 3 * d_out, bias=qkv_bias)
self.proj = nn.Linear(d_out, d_out)
self.dropout = dropout
def forward(self, x):
batch_size, num_tokens, embed_dim = x.shape
qkv = self.qkv(x)
qkv = qkv.view(batch_size, num_tokens, 3, self.num_heads, self.head_dim)
qkv = qkv.permute(2, 0, 3, 1, 4)
queries, keys, values = qkv
use_dropout = 0. if not self.training else self.dropout
# 核心:使用 PyTorch 原生接口,底层自动调用 FlashAttention
context_vec = nn.functional.scaled_dot_product_attention(
queries, keys, values,
attn_mask=None,
dropout_p=use_dropout,
is_causal=True # 自动处理因果掩码
)
context_vec = context_vec.transpose(1, 2).contiguous().view(
batch_size, num_tokens, self.d_out
)
return self.proj(context_vec)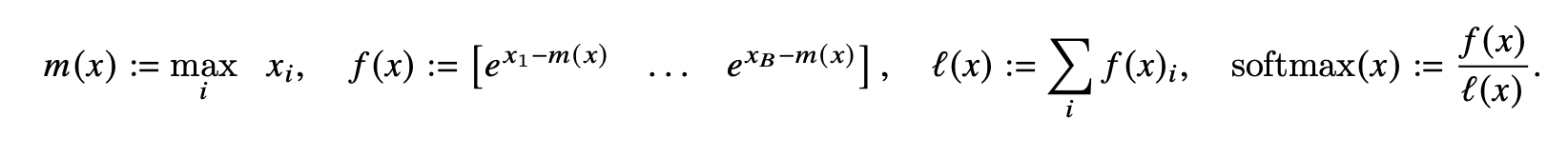
图 7-29:FlashAttention 的分块计算策略。将 Q/K/V 矩阵分成小块在 SRAM 中完成注意力计算,避免将完整注意力矩阵写入 HBM 显存。
FlashAttention 的核心思想是分块计算 + IO 感知(tiling + IO-aware):
- 避免具现化完整注意力矩阵。 标准注意力需要分配
(batch, heads, seq_len, seq_len)的中间矩阵,对于 batch_size=8、seq_len=1024、heads=12,这个矩阵占用约 384 MB。FlashAttention 将 Q/K/V 分成小块(tile),在 GPU 的片上 SRAM(约 20 MB)中完成每块的注意力计算,从不将完整注意力矩阵写入显存。 - 在线 softmax。 通过数学恒等变换(安全 softmax + 增量更新),FlashAttention 可以在单次遍历中完成 softmax 归一化,无需两遍扫描(第一遍求最大值、第二遍求指数和)。
实测效果惊人:显存从 11.56 GB 降至 5.90 GB(几乎减半),速度从 55K 提升到 92K tok/sec。此外,is_causal=True 参数让 FlashAttention 自动跳过因果掩码中被屏蔽的位置,计算量进一步减少约一半。
还有一个容易忽视的优化:将 Q、K、V 三个独立的 nn.Linear 合并为一个 nn.Linear(d_in, 3 * d_out),用一次矩阵乘法同时计算三个投影,减少了 kernel 启动次数和显存访问。
步骤 8:torch.compile(1.2 倍加速)
model = torch.compile(model)torch.compile 是 PyTorch 2.0 引入的图编译机制。它在第一次 forward 时捕获计算图,通过 TorchInductor 后端将其编译为高度优化的 Triton/CUDA kernel。主要优化包括:
- 算子融合(operator fusion):将多个逐元素操作合并为单个 kernel,减少显存往返。
- 内存规划(memory planning):预先分配所有中间张量的显存,避免运行时动态分配和碎片化。
- 自动向量化和循环展开:针对具体硬件生成最优的指令序列。
需要注意的是,torch.compile 有一定的编译预热开销——首次运行时需要 tracing 和编译,可能比未编译版本慢 2-10 倍。因此在短训练任务上反而不合算,编译带来的加速需要在足够多的训练步数上摊销。这也是步骤 8-9 改用 Step tok/sec(epoch 末尾值)而非 Avg tok/sec(含预热)来衡量性能的原因。
步骤 9:词表填充 + 增大批量大小(1.3 倍加速)
最后一步包含两个互补的优化。
词表填充(vocabulary padding): 将词表大小从 50,257 微调到 50,304——最接近的 64 的倍数:
GPT_CONFIG_124M = {
"vocab_size": 50304, # 原为 50257,填充到 64 的倍数
# ... 其他配置同前
}为什么 64 的倍数如此重要?Tensor Core 执行矩阵乘法时,以固定大小的 tile(通常为 8×8、16×16 或 32×32)为单位处理数据。如果矩阵维度不是 tile 大小的整数倍,GPU 需要对最后一个不完整的 tile 进行 padding 和掩码处理,浪费计算资源。词表大小直接决定了 embedding 层和 output head 的矩阵维度——这两个层在 GPT 模型中占据了相当比例的计算量。将 50,257 填充到 50,304(增加 47 个未使用的"虚拟"token),使矩阵维度对齐 Tensor Core 的最优 tile 大小,即可获得免费的加速。该技巧最早由 NVIDIA Megatron 团队在 2019 年的 Megatron-LM 论文中提出。
增大批量大小: 将 batch_size 从 8 提高到 GPU 显存允许的最大 2 的幂次(本实验中为 32):
OTHER_SETTINGS = {
"batch_size": 32, # 原为 8
# ... 其他配置同前
}更大的 batch_size 使每次矩阵乘法的规模更大,能更充分地利用 GPU 的数千个计算核心。但代价是显存消耗大幅增加(5.89 → 22.51 GB),需要在速度和显存之间权衡。经验法则:将 batch_size 设为 GPU 显存允许的最大 2 的幂次(2 的幂次同样有利于 Tensor Core 对齐)。
7.8.3 多 GPU 扩展:DDP
完成 9 步单卡优化后,自然的下一步是多卡并行。对于 124M 这种能在单卡显存内完整容纳的模型,数据并行(Data Parallelism) 是最简单高效的策略。PyTorch 的 DistributedDataParallel(DDP)实现了高效的数据并行:
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group
# 初始化进程组(每个 GPU 一个进程)
init_process_group(backend="nccl", rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
# 包装模型
model = GPTModel(gpt_config)
model = torch.compile(model)
model = model.to(device).to(torch.bfloat16)
model = DDP(model, device_ids=[rank])DDP 的工作流程:
- 数据分片:使用
DistributedSampler将训练数据均匀分配到各 GPU,每个 GPU 看到不同的 mini-batch。 - 独立前向传播:每个 GPU 独立计算自己的 mini-batch 的 loss。
- 梯度全归约:反向传播后,所有 GPU 通过 NCCL 的 AllReduce 操作平均梯度,确保每个 GPU 持有相同的梯度。
- 同步参数更新:每个 GPU 用相同的平均梯度独立执行优化器步骤,保持参数同步。
DataLoader 的修改同样关键——必须使用 DistributedSampler 替代常规的随机采样,并在每个 epoch 开始时调用 sampler.set_epoch(epoch) 以保证不同 epoch 的 shuffle 顺序不同:
from torch.utils.data.distributed import DistributedSampler
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=False, # 由 DistributedSampler 控制
sampler=DistributedSampler(dataset),
pin_memory=True,
num_workers=4
)
# 训练循环中
for epoch in range(num_epochs):
train_loader.sampler.set_epoch(epoch) # 确保每个 epoch 的数据顺序不同
...启动方式使用 torchrun:
torchrun --nproc_per_node=4 train_ddp.py4 卡 A100 DDP 的结果:
| 配置 | Step tok/sec | Reserved memory (per GPU) |
|---|---|---|
| 单卡(步骤 9 之后) | 142,156 | 22.51 GB |
| 4×A100 DDP | 419,259 | 22.80 GB |
4 卡的吞吐量约为单卡的 2.95 倍——未达到理论上限 4 倍,损耗主要来自梯度 AllReduce 的通信开销和 epoch 级别的同步等待。在 NVLink 直连拓扑下(如 DGX A100),DDP 的扩展效率通常可达 90% 以上。
7.8.4 优化策略的层次结构
回顾 9 步优化,可以将其按收益大小分为三个层次:
第一层:算法/精度级优化(贡献 ~80% 加速)。 包括启用 Tensor Core(步骤 2)、bfloat16(步骤 5)、FlashAttention(步骤 7)。这三步合计将 12.5K 提升到 92K,贡献了 79K 的增量。它们的共同特征是改变了计算的数学精度或算法复杂度——TF32/bfloat16 降低了每次浮点运算的比特宽度,FlashAttention 改变了注意力计算的 IO 复杂度。
第二层:编译/融合级优化(贡献 ~15% 加速)。 包括 Fused AdamW(步骤 3)、替换原生算子(步骤 6)、torch.compile(步骤 8)。这三步的共同特征是减少了 GPU kernel 的启动次数和显存往返次数,但没有改变底层的数学运算。
第三层:硬件对齐级优化(贡献 ~5% 加速)。 包括动态掩码(步骤 1)、pin_memory(步骤 4)、词表填充 + batch_size(步骤 9 的词表部分)。这些优化的收益较小但"几乎免费"——一行代码即可启用,没有任何精度或正确性上的代价。
实践建议: 优先完成第一层的三个优化(Tensor Core、bfloat16、FlashAttention),它们的投入产出比最高。在此基础上加上 torch.compile 和 fused optimizer 可以再获得约 20% 的边际加速。硬件对齐级优化作为"最后一英里"的微调,在追求极致吞吐量时才有必要逐一调优。
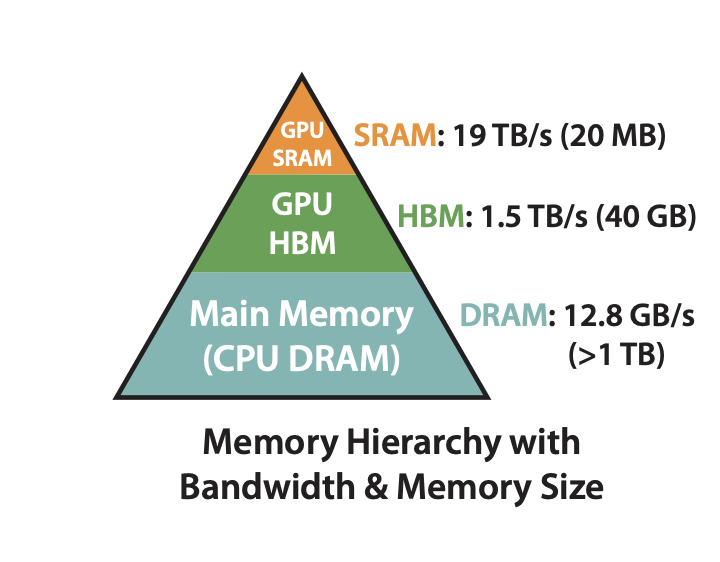
图 7-30:FlashAttention 的显存优化效果。通过分块计算和 IO 感知的算法设计,FlashAttention 将注意力计算的显存占用从 26 GB 降至 6 GB。
7.8.5 总结
本节通过 9 步可复现的实验,展示了单卡 A100 上从 12.5K 到 142K tokens/sec 的完整优化路径。几个关键结论:
Tensor Core + bfloat16 + FlashAttention 是三大支柱。 这三项优化合计贡献了 80% 以上的加速,是任何 LLM 训练项目的必备配置。其中 FlashAttention 同时带来了最大的显存节省(26 GB → 6 GB),使得同一 GPU 可以训练更大的模型或使用更大的批量大小。
torch.compile 是"免费午餐",但有预热代价。 一行代码即可获得约 20% 的加速,无需修改模型逻辑。代价是首次运行的编译时间和偶尔的兼容性问题——动态 shape、自定义 autograd function 等场景可能需要额外适配。
硬件对齐不可忽视。 词表填充到 64 的倍数、batch_size 选择 2 的幂次——这些看似琐碎的细节,在 Tensor Core 的 tile 计算模式下可以带来 10-30% 的额外加速。
DDP 是最简单的多卡扩展方案。 对于单卡能容纳的模型,DDP 的代码改动量极小(约 20 行),4 卡扩展效率接近线性。当模型大到单卡放不下时,则需要进入模型并行(Tensor Parallelism)或流水线并行(Pipeline Parallelism)的领域,复杂度将急剧上升。
优化有正确的顺序。 先确保使用正确的数值精度和注意力算法(第一层),再考虑算子融合和编译优化(第二层),最后微调硬件对齐(第三层)。反过来做——在 float32 下反复调优 batch_size 和 pin_memory——将事倍功半。