3.2 核心组件逐一拆解
上一节从宏观视角勾勒了 Transformer 的整体架构和数据流。然而,仅仅知道"注意力子层后面跟着前馈网络"是不够的——魔鬼藏在细节中。从原始 Transformer 到 LLaMA、Mistral、Qwen 等现代大语言模型,架构的核心骨架几乎没有变化,真正改变的是三个看似不起眼却至关重要的组件:层归一化、前馈网络和残差连接。这三者的设计选择直接决定了模型能否在数千层深度和万亿参数规模下稳定训练。
本节将逐一拆解这三个组件:先讲清楚它们"做什么"、"为什么要这么做",再给出数学公式和 PyTorch 实现,最后揭示它们在现代 LLM 中的演进方向。
3.2.1 层归一化
深层网络训练面临的首要挑战是内部协变量偏移(Internal Covariate Shift):随着梯度更新,每一层的输入分布不断漂移,导致后续层需要反复适应新的输入统计量。归一化技术通过在每一层强制将激活值映射到稳定的分布,从根本上缓解了这一问题,使得优化过程更加平滑,允许使用更高的学习率。
LayerNorm
层归一化(Layer Normalization)对单个样本的隐藏维度计算均值和方差,然后进行标准化。设输入向量
其中
与 BatchNorm 的区别。 BatchNorm 沿 batch 维度计算统计量,隐含假设同一特征在不同样本间服从相似分布,这在 CNN 的空间特征中是合理的。但在序列建模中,不同样本的序列长度和内容差异巨大,batch 维度的统计量噪声过高。LayerNorm 沿隐藏维度计算,每个样本独立归一化,不依赖 batch 内的其他样本,因此天然适合 Transformer 架构。
import torch
import torch.nn as nn
class LayerNorm(nn.Module):
def __init__(self, dim: int, eps: float = 1e-5):
super().__init__()
self.eps = eps
self.gamma = nn.Parameter(torch.ones(dim))
self.beta = nn.Parameter(torch.zeros(dim))
def forward(self, x: torch.Tensor) -> torch.Tensor:
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
x_norm = (x - mean) / torch.sqrt(var + self.eps)
return self.gamma * x_norm + self.betaRMSNorm
Zhang 和 Sennrich(2019)在论文"Root Mean Square Layer Normalization"中提出了一个关键假设:LayerNorm 的成功主要归功于重新缩放的不变性,而非均值居中操作。基于这一洞察,RMSNorm 直接移除了均值减法步骤和偏置参数
移除均值居中的直觉在于:在深层网络中,经过多层变换后的激活值均值本就趋近于零,显式减去均值带来的收益有限,反而增加了一次全局归约操作。从计算角度看,RMSNorm 省去了均值计算和方差计算中的减法步骤,只需要一个可学习参数
RMSNorm 已成为 LLaMA、PaLM、Qwen 等现代大语言模型的标准归一化方法。
class RMSNorm(nn.Module):
def __init__(self, dim: int, eps: float = 1e-5):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x: torch.Tensor) -> torch.Tensor:
# rsqrt = 1 / sqrt(x),避免先 sqrt 再除法的两步操作
return x * torch.rsqrt(x.pow(2).mean(dim=-1, keepdim=True) + self.eps)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 先转 float32 计算以避免半精度下溢,再转回原始 dtype
return self.weight * self._norm(x.float()).type_as(x)代码解读。 _norm 方法使用 torch.rsqrt(倒数平方根)一步完成归一化,避免了先 sqrt 再除法的两步操作。x.float() 将输入临时提升到 float32 精度进行归一化计算,再通过 type_as(x) 转回原始精度(如 bfloat16)。这是因为半精度浮点数的最小正数约为
Pre-Norm vs Post-Norm
归一化"用什么"只是问题的一半,"放在哪里"同样关键。
Post-Norm(原始 Transformer)。 原始 Transformer 将归一化放在残差连接之后:
这意味着 LayerNorm 直接位于残差主路径上。从梯度流的角度看,反向传播时梯度必须穿过 LayerNorm 层才能回传到更早的层,而 LayerNorm 的 Jacobian 矩阵会对梯度进行非平凡的缩放和旋转,这在深层网络中逐层累积,可能导致梯度爆炸或消失。因此 Post-Norm 的训练往往需要精细的学习率预热(Warmup)策略,否则容易发散。
Pre-Norm(现代标准)。 Pre-Norm 将归一化移到子层的输入端:
这一看似微小的调整带来了本质性的改善。注意此时 LayerNorm 位于子层的分支路径上,而残差主路径
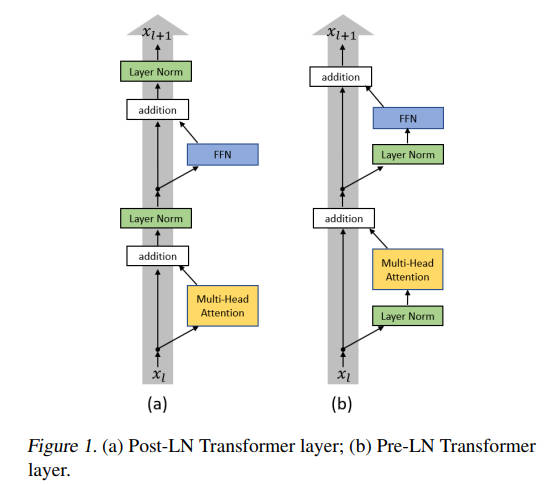
图 3-3:Pre-Norm 与 Post-Norm 结构对比。Post-Norm 中归一化位于残差加法之后的主路径上;Pre-Norm 中归一化位于子层输入端的分支路径上,残差主路径保持干净的恒等连接。几乎所有现代 LLM 均采用 Pre-Norm 结构。
几乎所有现代大语言模型都采用 Pre-Norm 结构。 在 LLaMA 系列中,具体配置为 Pre-RMSNorm——在每个注意力子层和前馈网络子层之前分别施加 RMSNorm。值得一提的是,Grok、Gemma 2 等最新模型甚至引入了 Double Norm:在 Pre-Norm 的基础上,于子层输出端再增加一次归一化,提供额外的数值稳定性保障。
3.2.2 前馈网络
Transformer 中的每个注意力子层后面都紧跟一个位置逐点前馈网络(Position-wise Feed-Forward Network, FFN)。注意力子层负责在序列维度上聚合上下文信息,而 FFN 则在每个位置独立地进行特征变换——可以将其理解为对每个 token 的表示施加一次非线性特征提取。
标准 FFN
原始 Transformer 中的 FFN 由两个线性变换和一个 ReLU 激活函数组成:
其中
激活函数的演进:ReLU -> GELU -> Swish
ReLU
GELU(Gaussian Error Linear Unit)是 ReLU 的平滑近似,被 GPT 和 BERT 系列广泛采用:
其中
Swish 函数是另一种平滑激活:nn.SiLU() 的默认实现。Swish 与 GELU 的形状非常接近,但计算上仅依赖 sigmoid,无需误差函数。
SwiGLU:门控机制的引入
标准 FFN 中的激活函数是"静态"的——对每个维度施加相同的非线性变换,不考虑输入的内容。Dauphin 等人(2017)提出的门控线性单元(Gated Linear Unit, GLU)引入了一种全新的思路:让网络根据输入内容动态决定每个维度的信息通过量。
GLU 的一般形式为:
其中
SwiGLU 是 GLU 家族中性能最优的变体(Shazeer, 2020),它使用 Swish 作为门控激活函数。完整的 SwiGLU FFN 公式为:
其中
图 3-4:SwiGLU FFN 的结构示意图。输入
参数量的平衡。 三个矩阵意味着比标准 FFN 多出 50% 的参数量。为了在总参数量不变的前提下使用 SwiGLU,通常将中间维度
以下代码同时包含从 T5 开始普遍采用的去偏置设计(bias=False):
import torch.nn.functional as F
class SwiGLUFFN(nn.Module):
def __init__(self, dim: int, multiple_of: int = 256):
super().__init__()
# 中间维度: 8d/3,对齐到 multiple_of 的整数倍
mid_dim = int(8 * dim / 3)
mid_dim = multiple_of * ((mid_dim + multiple_of - 1) // multiple_of)
self.w_gate = nn.Linear(dim, mid_dim, bias=False)
self.w_up = nn.Linear(dim, mid_dim, bias=False)
self.w_down = nn.Linear(mid_dim, dim, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# Swish(x @ W_gate) ⊙ (x @ W_up),再降维
return self.w_down(F.silu(self.w_gate(x)) * self.w_up(x))代码解读。 F.silu 即 Swish 函数(w_gate 和 w_up 并行地对输入进行线性变换,前者经 Swish 激活后作为门控信号,与后者逐元素相乘,最终由 w_down 降维输出。整个前向过程只有三次矩阵乘法和一次逐元素乘法,计算模式对 GPU 非常友好。
自 LLaMA 以来,SwiGLU 已取代 GELU 成为大语言模型 FFN 层的事实标准。GeGLU(将 Swish 替换为 GELU)是另一个有竞争力的变体,被 T5-v1.1、Phi-3 等模型采用。论文作者坦诚地表示"我们无法为这一改进提供单一的解释"——但实验数据一致表明,门控机制在各种基准上均带来了可观的困惑度下降。
3.2.3 残差连接
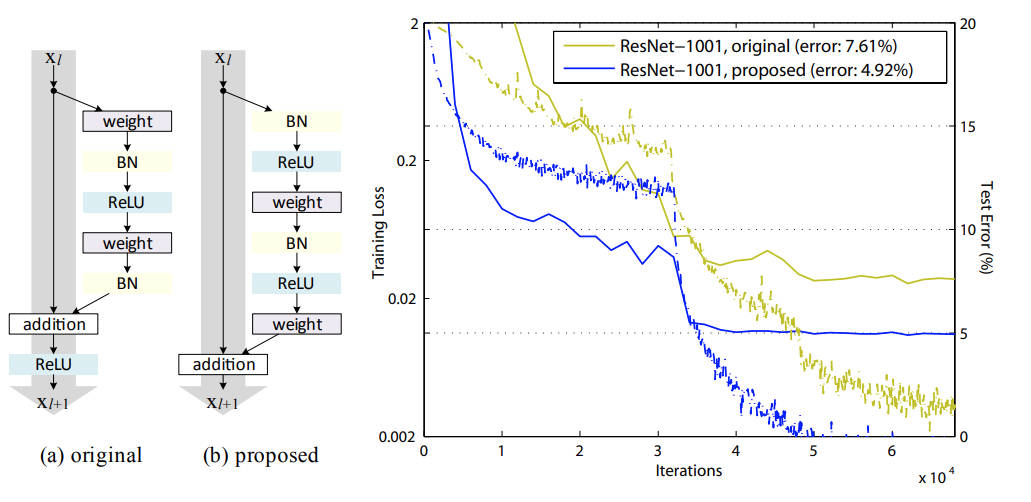
图 3-5:残差连接的两种设计及其训练效果对比。(a) 原始残差块(Post-Activation):weight → BN → ReLU 顺序,归一化在残差加法之前;(b) Pre-Activation 残差块:BN → ReLU → weight 顺序,归一化放在变换之前,残差主路径更干净。右图展示了在 1001 层 ResNet 上的训练曲线——Pre-Activation(蓝色)显著优于原始设计(黄色),这一原理直接延伸为 Transformer 中 Pre-Norm 的设计动机。
残差连接可能是深度学习中最简单却影响最深远的设计。它的形式只有一行公式:
其中
退化问题与残差学习
1.2 节曾从 CNN 的视角介绍了残差连接的起源。这里我们从 Transformer 的语境出发,给出一个更深入的理论分析。
深层网络面临的核心困境是退化问题(Degradation Problem):随着网络层数增加,训练误差反而上升——不是过拟合,而是优化本身失败了。这个现象的一个思想实验可以揭示问题的本质:假设一个 56 层网络的最优解恰好等价于某个 20 层网络——多出来的 36 层只需要学会恒等映射即可。但实验表明,SGD 很难将一个带有非线性激活和归一化的层训练成恒等映射。
残差连接将问题巧妙地转换了:子层不再需要学习完整的目标映射
残差块的结构可参见图 1-7(§1.2)。在 Transformer 的 Pre-Norm 配置下,子层路径为
函数族论证:更大模型必覆盖更小模型
残差连接赋予深层网络一个优雅的理论性质,可以用函数族嵌套的视角来理解。
设
如果第
这意味着
这一嵌套性质保证了:增加网络深度只会扩大(或至少不缩小)模型的表达能力。更大的模型永远能够覆盖更小模型所能表达的全部函数,因为它可以简单地将多余的层"关闭"。在没有残差连接的网络中,这一性质不成立——一个更深但没有跳连的网络,其函数族可能与浅层网络不具有包含关系,因为学习恒等映射本身就是困难的。
这也是为什么我们可以放心地将 Transformer 从 12 层扩展到 96 层乃至数百层:残差连接在理论上保证了深层网络至少不会比浅层网络差——即使某些层学到的变换接近于零,模型的整体表达能力也不会退化。
梯度高速公路
残差连接在优化层面的贡献同样深远。考虑一个
对损失
关键在于那个
以下代码展示了 Transformer 块中残差连接与 Pre-RMSNorm 的标准组合:
class TransformerBlock(nn.Module):
def __init__(self, dim: int, num_heads: int, multiple_of: int = 256):
super().__init__()
self.attn_norm = RMSNorm(dim)
self.attn = MultiHeadAttention(dim, num_heads) # 参见 §2.3
self.ffn_norm = RMSNorm(dim)
self.ffn = SwiGLUFFN(dim, multiple_of)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 残差 + Pre-RMSNorm + 注意力
x = x + self.attn(self.attn_norm(x))
# 残差 + Pre-RMSNorm + SwiGLU FFN
x = x + self.ffn(self.ffn_norm(x))
return x代码解读。 这个 TransformerBlock 浓缩了本节介绍的三个核心组件:RMSNorm 实现层归一化,SwiGLUFFN 实现门控前馈网络,而 x = x + ... 就是残差连接。每个子层遵循相同的模式——先归一化、再变换、最后加回残差——简洁而统一。整个现代 Transformer 就是将这样的块堆叠数十至数百层。
本节小结
本节拆解了 Transformer 架构中三个看似简单却至关重要的核心组件:
- 层归一化 通过稳定每一层的输入分布来保障训练稳定性。从 LayerNorm 到 RMSNorm,去掉均值居中在几乎不损失性能的前提下显著提升了计算效率。从 Post-Norm 到 Pre-Norm,归一化位置的调整保证了残差主路径的梯度畅通无阻。
- 前馈网络 在每个位置独立地进行特征变换。从 ReLU 到 GELU 再到 SwiGLU,激活函数的演进方向是引入门控机制实现内容自适应的特征选择,使 FFN 从静态非线性变换升级为动态信息过滤器。
- 残差连接 以
这一极简形式,同时解决了函数族嵌套(更深的模型表达能力不退化)和梯度传播(提供从损失到任意层的直达通道)两大根本性问题。
这三个组件的协同构成了现代 LLM 的"基本粒子"。理解它们各自的设计动机和演进逻辑,是深入理解下一节将介绍的旋转位置编码(RoPE)以及后续章节中各类大语言模型架构变体的必要前提。