25.5 效果对比与反思
经过前面几节对 SFT、DPO、PPO、GRPO 等训练方法的详细拆解,读者已经掌握了这些算法的数学原理和工程实现。本节将回到最关键的问题:在同一个极小模型上,不同对齐算法的实际效果究竟如何? 我们将从训练曲线、生成质量、客观基准三个维度展开系统对比,并深入讨论小模型强化学习面临的核心难题——奖励稀疏问题,最后总结各算法的适用场景与工程选型建议。
25.5.1 训练曲线对比
为了公平比较,我们基于 MiniMind2(768 维、104M 参数)在相同数据集(从 SFT 数据中随机采样的 1 万条高质量对话 rlaif-mini.jsonl)和相同训练步数下,分别运行 PPO、GRPO 和 SPO 三种在线 RL 算法。奖励模型统一使用 InternLM2-1.8B-Reward,所有实验均在单卡 NVIDIA 3090 上完成。
PPO 训练曲线
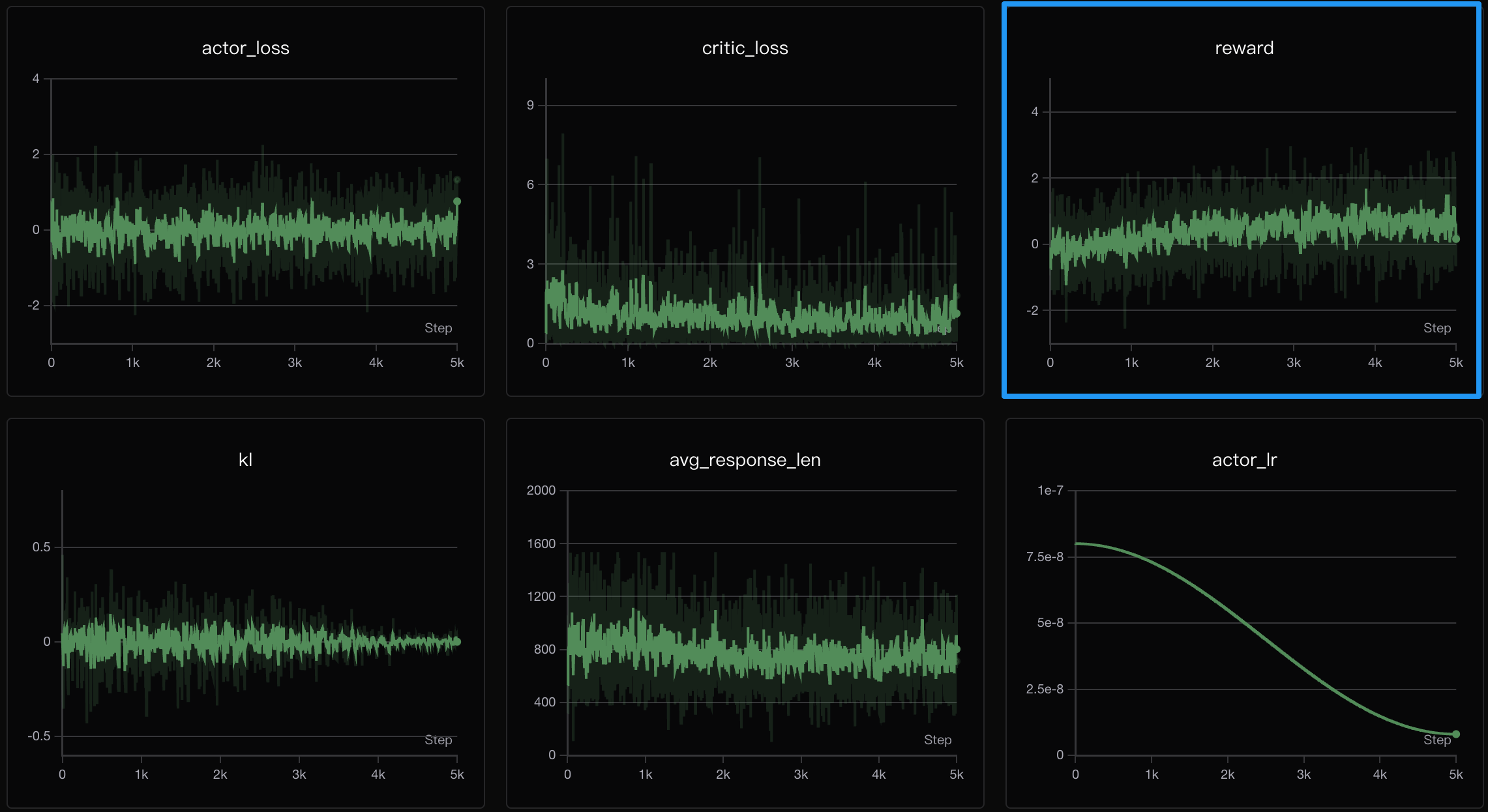
PPO 的训练面板包含 6 个关键指标:actor_loss、critic_loss、reward、kl、avg_response_len 和 actor_lr。几个值得关注的现象:
- reward 曲线:从约
缓慢爬升至 附近,波动剧烈且天花板较低。与 GRPO 最终达到 左右的 reward 相比,差距悬殊。 - critic_loss:初始约
至 ,在训练过程中缓慢下降至 至 ,说明 Critic 网络始终未能很好地拟合价值函数。 - kl 散度:整体维持在
的较小范围,说明 KL 正则化有效阻止了策略崩溃,但也限制了探索空间。 - avg_response_len:在 800 至 1200 之间波动,无明显趋势。
PPO 表现不佳的根源在于 双网络联合优化机制:
- Critic 冷启动问题:训练初期 Critic 的价值估计极不准确,Actor 依赖 Critic 提供的优势函数
来更新策略,不准确的 直接导致梯度方向偏差。在 MiniMind 的简化实现中,Critic 只取序列最后一个 token 的 value 作为整句价值估计,而非逐 token 的 GAE 估计,进一步放大了估计误差。 - 双网络耦合:Actor 和 Critic 相互依赖——Actor 的策略改变影响 Critic 的训练数据分布,Critic 的估计质量又反过来决定 Actor 的梯度方向。这种耦合在小模型上尤其脆弱,因为模型容量有限,两个网络的表示能力都捉襟见肘。
- 显存开销翻倍:PPO 需同时维护 Actor、Critic、Reference Model 和 Reward Model 四个网络,显存占用约为单网络方法的 1.5 至 2 倍。对于只有 26M 参数的 MiniMind2-Small,这一开销尚可接受;但对于任何实际规模的模型,这都是一个沉重的负担。
GRPO 训练曲线
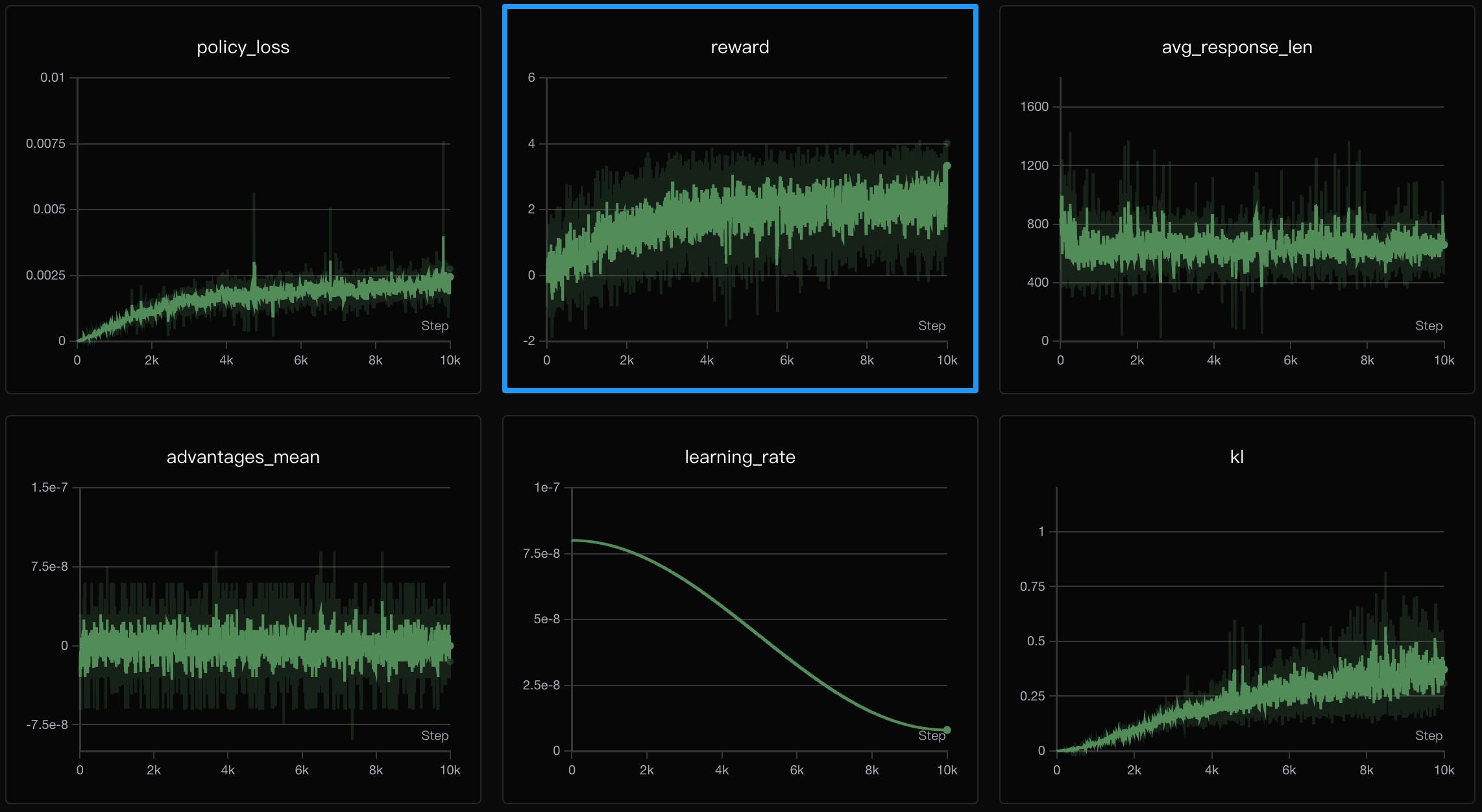
GRPO 的训练面板更为简洁,仅包含 policy_loss、reward、avg_response_len、advantages_mean、learning_rate 和 kl 六个指标(无 critic_loss)。关键观察:
- reward 曲线:呈现出明显且稳定的上升趋势,从初始的
附近上升至 左右,收敛上限远高于 PPO。这说明 GRPO 能更有效地利用 RLAIF 的奖励信号。 - policy_loss:整体下降平稳,无剧烈震荡。
- kl 散度:从接近
平稳上升至约 ,说明模型在逐渐偏离 Reference Model——但这种偏离带来了 reward 的实质性提升,是有益的。 - advantages_mean:在
附近波动,符合归一化后的预期。
GRPO 之所以表现更优,核心在于其用分组统计替代了 Critic 网络:
对同一个 Prompt 生成
SPO 训练曲线
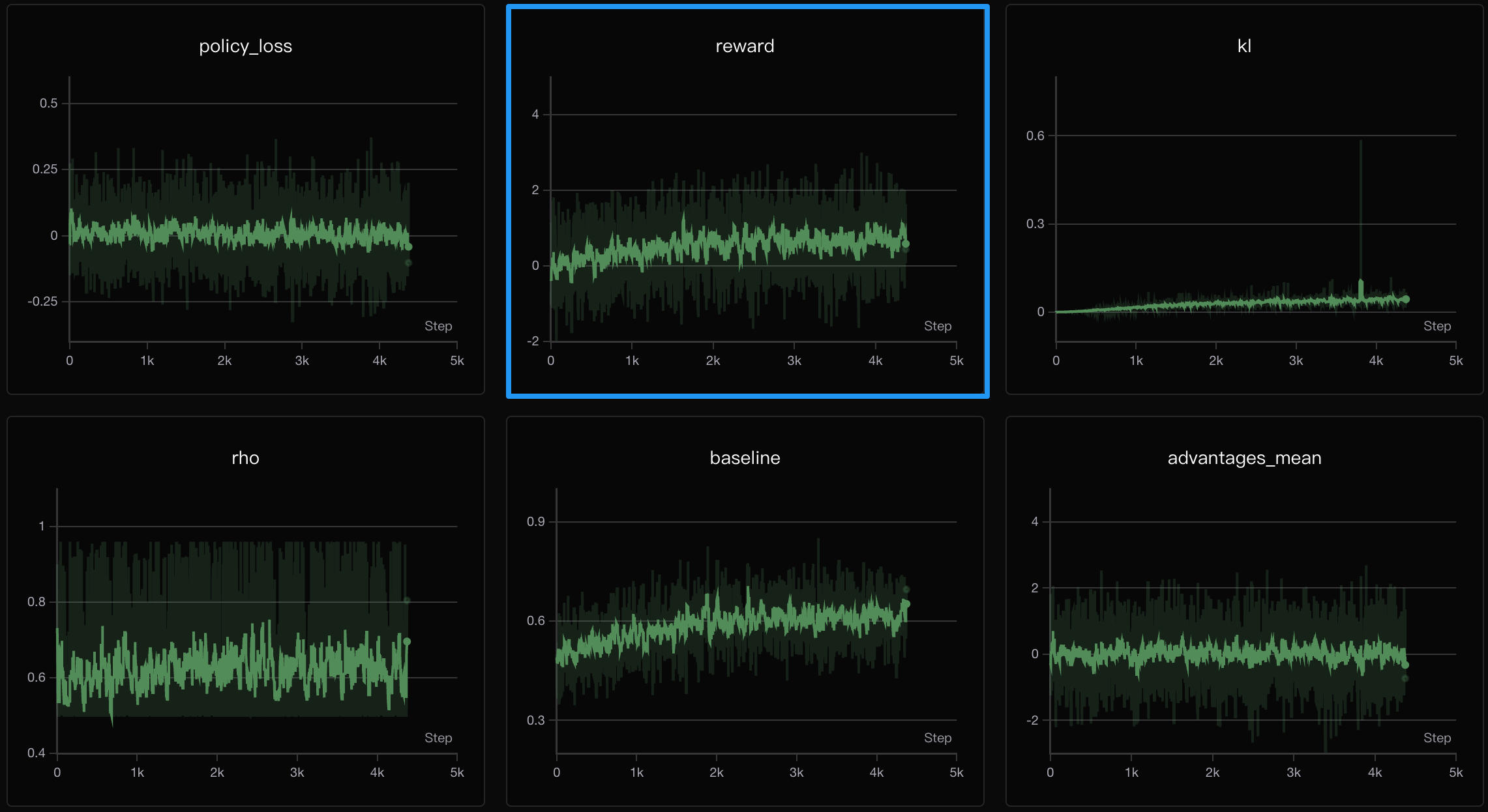
SPO(Single-stream Policy Optimization)是 2025 年 9 月腾讯提出的 RL 算法,针对 GRPO 的退化组问题进行改进。其核心思路是回到策略梯度的基本公式——1 个输入、1 个输出,就是 1 个训练样本,用持久化的 KL 自适应 value tracker 替代组内基线,为每个样本提供独立的、跨 batch 持久化的基线参照。
然而从训练曲线来看,SPO 在 MiniMind 量级上的表现不尽如人意:
- reward 曲线:波动较大,在
到 之间震荡,无明显上升趋势,整体水平与 PPO 接近。 - baseline:value tracker 的基线估计缓慢上升,但收敛不够充分。
- rho 参数:动态调整因子在
间波动,说明自适应机制在工作但不够稳定。
这说明 SPO 的优势需要在更大参数量级上才能显现。SPO 论文使用 Qwen3-8B 在 5 个困难数学数据集上取得了超越 GRPO 3.4 个百分点的提升,但在 0.1B 量级的超小模型上,算法的精细设计难以弥补模型容量的不足。当模型本身的生成质量普遍很低时,无论采用组内相对基线(GRPO)还是跨 batch 自适应基线(SPO),学习信号都趋近于零。
DPO 训练曲线
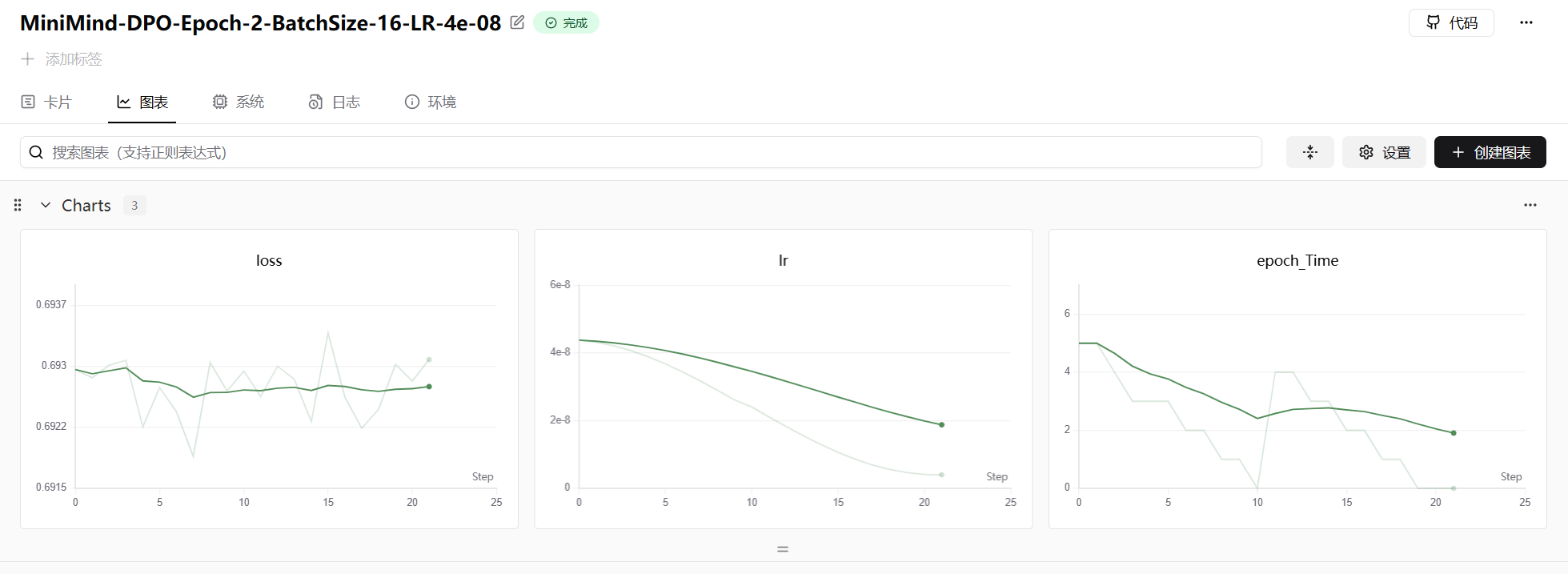
DPO 作为离线方法,其训练曲线的核心指标是 loss 和 learning rate。DPO 的 loss 从约 0.693(即
DPO 训练的核心特点是简洁高效:无需实时采样、无需 Reward Model、无需 Critic 网络,只需一个 Policy 模型和一个冻结的 Reference 模型。这使得 DPO 成为资源受限场景下最实用的对齐方法。
25.5.2 RLHF 主观效果对比:SFT vs DPO
下面展示基于 MiniMind2(640 维 MoE 版本)的 SFT 模型与 DPO 模型在相同问题上的回答对比,测试随机种子固定。
示例一:"你叫什么名字?"
SFT 模型给出了简洁的回答:"我是一个大型语言模型,可以回答各种问题"。DPO 模型则回答更长:"我是一种基于文本的AI模型,我并没有个人经历或情感...如果您有任何问题或需要帮助,请随时告诉我!" DPO 模型的回答更加"圆滑",但核心信息并未增加。
示例二:"鲁迅的《狂人日记》如何批判封建礼教?"
两个模型都出现了显著的幻觉问题,但表现形式不同。SFT 模型虽然存在事实错误,但至少围绕"封建礼教"、"社会不平等"等主题展开论述,基本框架尚可。DPO 模型则出现了更荒诞的幻觉——提到了"弗雷德里克·约翰逊"、"贝克汉姆"等完全无关的西方人名。
效果汇总:
| 维度 | SFT 模型 | DPO 模型 |
|---|---|---|
| 回答长度 | 中等,偶有重复 | 更长,更详细 |
| 信息准确性 | 较好 | 有轻微下降 |
| 语气风格 | 直接 | 更礼貌、更委婉 |
| 幻觉程度 | 存在但可控 | 偶尔更严重 |
| 格式规范 | 一般 | 更规范 |
效果总结:SFT 模型在简洁性和信息准确性方面表现更好;DPO 模型倾向于回答更长、更礼貌,但信息准确性有轻微损失。总的来说,RLHF 后的模型倾向于"说更多有礼貌但无用的废话来讨好对话本身",而对信息准确性则有轻微损失。天下没有免费的午餐——还需要继续提升 RLHF 数据集的质量,也要接受模型能力不可避免的损失。
这一现象的深层原因在于 Off-Policy 和 On-Policy 的根本差异。DPO 使用的离线偏好数据(chosen vs rejected)是由其他模型(或人工)预先准备的,与 MiniMind 当前策略的输出分布存在较大差距。用一个比喻来说:DPO 相当于让模型观看乒乓球世界冠军的打法录像来学习,而 PPO/GRPO 则是请教练手把手纠正自己的每一个动作。前者学到的可能是"优雅的姿势"而非"有效的击球"。
25.5.3 RLAIF 主观效果对比:蒸馏 vs PPO vs GRPO
在推理模型(Reasoning Model)场景下,我们对比了三种训练路径。三者均基于 MiniMind2(768 维)模型,使用相同的推理格式模板(<think>...</think><answer>...</answer>),随机种子固定为 2026。
典型回答对比("请介绍一下自己"):
- 蒸馏模型:
<think>部分简短精炼(约 40 字),直接给出身份信息,格式完全符合模板规范。但思考内容与回答高度重复,缺乏真正的推理深度——本质上是"复读"而非"思考"。 - PPO 模型:
<think>部分极其冗长(约 500 字),充斥着大量无关分析:"用户可能是一个学生"、"需要考虑用户的身份"、"应该保持简洁明了"。最终<answer>反而空洞无物:"请告诉我你想了解哪方面的内容"。模型学会了"装作在思考"但并未产生有效推理。 - GRPO 模型:
<think>部分同样冗长(约 400 字),但最终<answer>能正确给出身份信息:"我是由中国的个人开发者开发的智能助手小型AI推理模型-R1"。不过回答中夹杂了不少无关内容:"知识图谱构建"、"复杂系统的推理与分析"。
更深层的观察:三种方法在知识类问题(如《狂人日记》的分析)上都出现了严重的事实性错误——蒸馏模型将作者误认为曹雪芹,PPO 模型将作者误认为毛泽东。这并非对齐算法的问题,而是基础模型能力的天花板:0.1B 参数量的模型在预训练阶段就没有充分学习这些知识,后续的 RL 训练无法凭空创造知识,只能在已有知识的基础上调整表达策略。
25.5.4 客观基准评测
在 C-Eval、CMMLU、A-CLUE、TMMLU+ 四个纯中文选择题榜单上,MiniMind 系列与同量级模型的对比如下。评测使用 lm-evaluation-harness 框架,取 A/B/C/D 四个 token 的预测概率最大者作为答案。
| 模型 | 来源 | 参数量 | C-Eval | CMMLU | A-CLUE | TMMLU+ |
|---|---|---|---|---|---|---|
| MiniMind2 | JingyaoGong | 104M | 26.52 | 24.42 | 24.97 | 25.27 |
| MiniMind2-Small | JingyaoGong | 26M | 26.37 | 24.97 | 25.39 | 24.63 |
| MiniMind2-MoE | JingyaoGong | 145M | 26.60 | 25.01 | 24.83 | 25.01 |
| Steel-LLM | ZhanShiJin | 1121M | 24.81 | 25.32 | 26.00 | 24.39 |
| GPT2-medium | OpenAI | 360M | 23.18 | 25.00 | 18.60 | 25.19 |
| TinyLlama-1.1B-Chat | TinyLlama | 1100M | 25.48 | 25.00 | 25.40 | 25.13 |
| SmolLM2 | HuggingFace | 135M | 24.37 | 25.02 | 25.37 | 25.06 |
| Aquila-Instruct | BAAI | 135M | 25.11 | 25.10 | 24.43 | 25.05 |
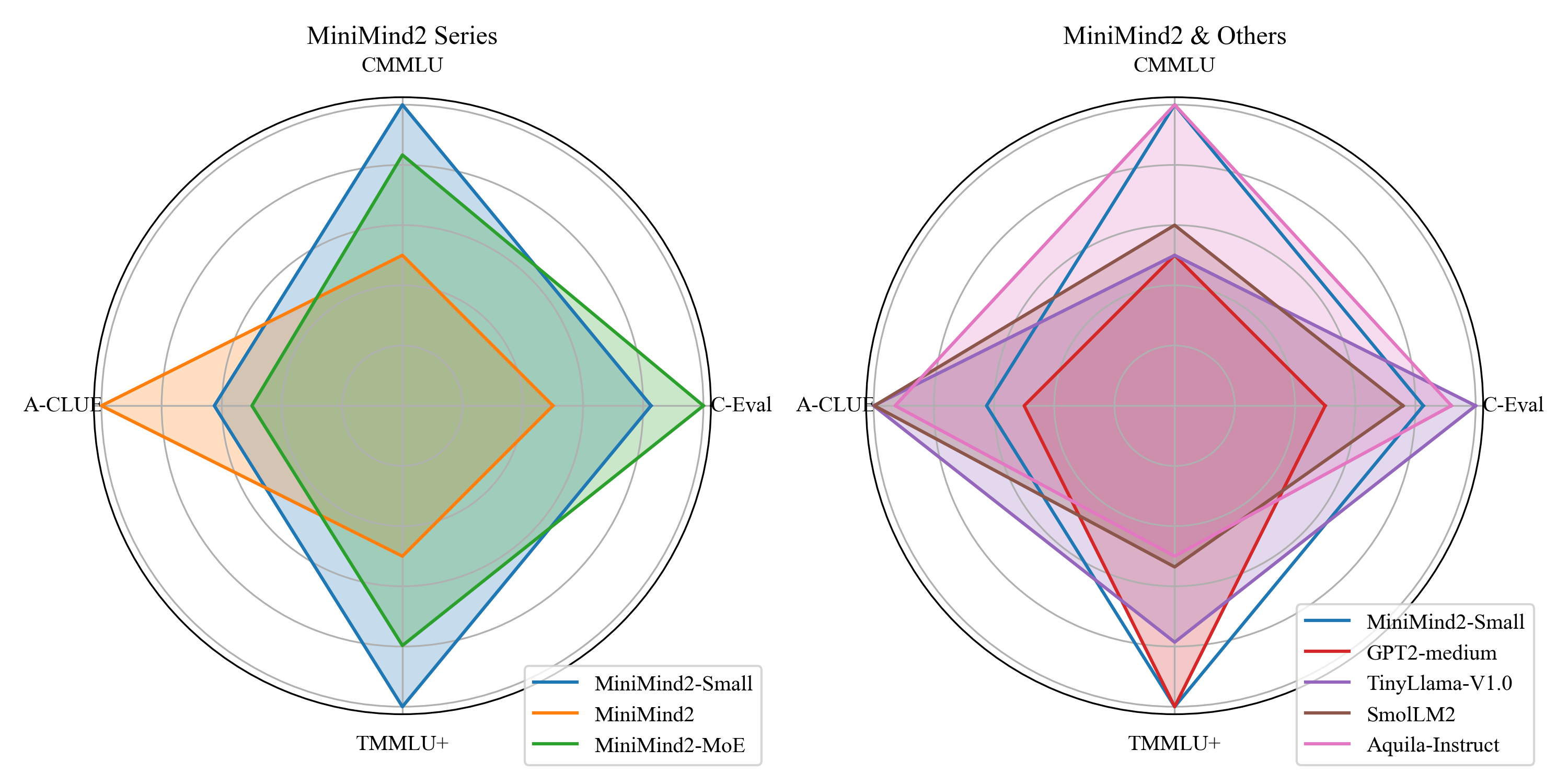
所有模型的得分都集中在 25 分(四选一随机概率)附近。在这个参数量级上,选择题评测本质上接近随机猜测——正如原作者所言,"像极了高中完形填空的滑铁卢正确率"。但两个细节值得注意:
- MiniMind2 系列整体表现优于参数量大 10 倍的模型:104M 的 MiniMind2 在 C-Eval 上得到 26.52,高于 1121M 的 Steel-LLM(24.81)和 1100M 的 TinyLlama(25.48)。这说明高质量训练数据和完整训练流程的价值可以超越单纯的参数量堆叠。
- GPT2-medium 在 A-CLUE 上表现异常差(18.60),远低于随机水平,说明该模型在中文上几乎没有有效知识,选择的 token 概率分布与中文选项不匹配。
25.5.5 小模型 RL 的核心难题:奖励稀疏
在前面的对比中我们反复看到一个现象:无论使用哪种 RL 算法,0.1B 量级的小模型在复杂任务上的提升都非常有限。这背后隐藏着一个 RL 的根本性问题——奖励稀疏(Reward Sparsity)。
问题的本质
以 DeepSeek-R1 风格的数学推理任务为例,如果使用规则奖励(答案正确得 1 分,否则 0 分),对于 0.1B 的模型:
- 现象:模型生成的候选回答几乎全部错误,导致所有奖励
- 后果:优势函数
,策略梯度信号消失,参数 无法有效更新
这如同让小学生做高考数学题——无论尝试多少次都得零分,无法通过分数差异学习改进策略。这是 RL 算法的原理性限制,而非工程实现的问题。事实上,DeepSeek-R1 论文也明确指出,只有
GRPO 的退化组问题是奖励稀疏的特殊表现
GRPO 虽然不依赖 Critic 网络,但它依赖组内的奖励差异来计算优势函数。当问题超出模型能力时,同一 Prompt 的
这就是所谓的**退化组(Degenerate Groups)**问题——整组样本提供不了任何学习信号。在 MiniMind 这种超小模型上,求解数学问题时 99.99% 的情况下整组回答质量都很差,退化组现象极为普遍。
MiniMind 的缓解策略
为了在小模型上仍能获得有效的 RL 训练信号,MiniMind 采用了基于模型的连续性奖励信号(model-based continuous reward):
连续分数替代二元判定:使用 InternLM2-1.8B-Reward 输出连续分数(范围约
到 ),而非正确/错误的 判定。即使所有回答质量都差,Reward Model 仍能区分"更差"( )和"没那么差"( ),为优势函数提供非零梯度。这种稠密且连续的奖励信号使策略网络得以渐进式优化。 混合奖励源:将模型打分与规则奖励(如推理格式标签检测)组合:
例如,格式奖励检测 <think>、</think>、<answer>、</answer> 四个标签是否齐全,每个标签出现给
限制任务难度在能力边界内:避免直接使用超纲数据集(如 MATH500),选择模型有一定概率给出合理回答的通用对话数据。训练数据必须处于模型的"最近发展区"——太简单则没有提升空间,太难则完全学不到东西。
监控奖励方差:训练过程中持续观察
,若持续接近 则说明当前数据或奖励机制需要调整。这是一个实用的早停信号。
Agentic RL 场景的延伸思考
值得一提的是,在生产级大模型的 Agentic RL 场景中,奖励稀疏以另一种形式出现——延迟奖励(Delayed Reward)。在真实 Agent 系统(代码生成、工具调用、检索-规划-执行的多轮链路)中,LLM 需要逐 token 生成工具调用指令,经历解析、执行、上下文拼接等多个步骤,循环往复直到任务完成。一次完整的任务链路可能包含多次调用和思考,只有在终止条件满足时才计算一次总 reward(如代码是否通过测试、API 是否返回成功)。
这意味着 Agentic RL 更接近稀疏/延迟奖励设定,与非 Agentic RL 在对话单轮上"即时评分即时更新"有很大不同。因此,Agent 任务更偏向环境反馈(environment-based reward)而非 Reward Model 的静态打分——最终以执行结果为准(代码是否跑通、API 是否返回成功),而 model-based 奖励对长链路、可执行语义的全貌捕捉有限。
25.5.6 RL 算法统一框架与选型建议
回顾本章介绍的所有对齐算法,它们可以被统一到同一个框架中——策略项、优势项和正则项的三要素组合:
| 算法 | 策略项 | 优势项 | 正则项 | 所需模型数 |
|---|---|---|---|---|
| DPO | 隐式(偏好对比) | 隐含在 | 2 | |
| PPO | 4 | |||
| GRPO | 2 | |||
| SPO | 2 |
四种算法的本质差异在于如何估计"当前动作到底有多好"(优势项)以及如何防止策略跑偏(正则项)。DPO 通过偏好对隐式地获得优势信号;PPO 训练一个专门的 Critic 网络来估计价值函数;GRPO 用同组样本的统计量替代 Critic;SPO 则用跨 batch 持久化的 value tracker 替代分组。
选型建议:
资源有限、追求稳定:选 DPO。只需 2 个模型(Policy + Reference),训练数据可离线准备并反复使用,实现最简单,收敛最稳定。缺点是依赖偏好数据质量,且离线数据与当前模型分布可能存在较大偏差。适合小团队快速对齐已有模型。
追求效果上限、有一定算力:选 GRPO。同样只需 2 个模型(无 Critic),但通过在线采样获得更贴近当前策略分布的训练信号,reward 上限显著高于 DPO 和 PPO。缺点是需要对每个 Prompt 生成
个回答(通常 ),计算开销约为 DPO 的 倍。这是当前工业界最主流的 RL 对齐方案。 教学或复现经典流程:选 PPO。PPO 是 RLHF 领域的经典基线,理解其 Actor-Critic 架构、GAE 优势估计、Clipping 机制对于深入理解后续改进算法不可或缺。但在实际项目中,其高显存开销(4 个网络)和缓慢的收敛速度使其性价比偏低。
大模型前沿探索:关注 SPO 及其后续演进(DAPO、GSPO、CISPO 等)。2025 年初 GRPO 随 DeepSeek-R1 爆火后,半年内已演变为各种变体大战的基线。这些新算法在 8B 以上模型的数学推理等困难任务上展现了超越 GRPO 的潜力,但在小模型上优势尚不明显。
25.5.7 关键反思
反思一:RL 不是万能药
强化学习能做的是在模型已有能力的基础上进行策略优化——让模型学会在已经会的事情中选择更好的做法。它无法凭空赋予模型新知识。如果基础模型在预训练阶段就没有学到某个知识点,后续无论用多精妙的 RL 算法都无法"训练"出这个知识。这也解释了为什么业界共识是
反思二:蒸馏 vs RL 的务实选择
对于小模型而言,知识蒸馏(从大模型的输出中学习)在效果上往往显著优于 RL 训练。蒸馏本质上是让小模型直接模仿大模型的行为分布,绕过了小模型自身探索能力不足的问题。从 MiniMind 的实验可以看出,蒸馏得到的推理模型在格式规范性和回答简洁性上明显优于 PPO 和 GRPO 训练的版本。虽然蒸馏派在学术上被 RL 派视为"技术含量较低",但在工程实践中,对于参数量有限的模型,蒸馏是性价比最高的对齐策略。
反思三:数据质量 > 算法选择
贯穿所有实验的一个隐含结论是:对齐效果的上限由数据质量决定,而非算法。DPO 的偏好数据质量、GRPO 的 Prompt 数据分布、Reward Model 的打分准确性——这些数据层面的因素对最终效果的影响远大于 PPO 和 GRPO 之间的算法差异。在实际项目中,花 80% 的精力在数据清洗和奖励设计上,比在算法细节上反复调参更有价值。
反思四:Scaling Law 依然是最硬的规律
MiniMind 系列的实验完美印证了 Scaling Law:在 MiniMind 家族内部,参数越大、训练数据越充分的模型,幻觉和错误都肉眼可见地减少。26M 的 MiniMind2-Small 在知识类问题上频繁胡编乱造,而 104M 的 MiniMind2 虽然仍有不足,但已经能给出基本合理的回答框架。在与第三方模型的对比中,MiniMind2 的排名也严格遵循"参数量 + 数据量"的规律——参数更大且训练更充分的模型评分越高。这提醒我们:不要期望对齐技术能弥补模型容量的根本不足。
反思五:On-Policy vs Off-Policy 的取舍
DPO 和 PPO/GRPO 的核心区别在于数据的"新鲜度"。DPO 的偏好数据是预先收集的,与当前模型的输出分布可能差距很大(distribution shift);而在线 RL 方法使用当前策略实时采样,训练数据始终与模型状态同步。这一区别在小模型上更加显著——小模型的能力边界窄,预收集的偏好数据很容易超出其表达范围,导致 DPO 学到的是"模仿它做不到的行为"。理想的工程实践是先用 DPO 做初步对齐(成本低、见效快),再用 GRPO 做精细调优(在线探索、上限更高)。
本节从训练曲线、生成质量和客观基准三个维度系统对比了 SFT、DPO、PPO、GRPO 四种对齐方法的实际效果,揭示了小模型 RL 面临的奖励稀疏核心难题,并给出了算法选型的实践建议。核心结论可以概括为:GRPO 在在线 RL 中表现最优,DPO 是资源受限场景的最佳选择,而模型容量和数据质量才是对齐效果的真正天花板。