15.7 熵管理与训练崩溃
在大模型强化学习中,数据、模型与超参数构成一个高度耦合的动态系统。系统的不稳定性是常态,而不是例外——调整学习率、温度参数或模型规模中的任何一个环节,都可能引发连锁反应。本节聚焦两种最致命的训练病理:熵崩溃(Entropy Collapse) 和 奖励崩溃(Reward Collapse)。我们将从数学机制出发,理解它们"为什么会发生",然后逐一介绍业界验证有效的解决方案。
15.7.1 策略熵:大模型 RL 的生命体征 [必读]
策略熵(Policy Entropy) 衡量模型输出的"不确定性"或"多样性"。对于词表大小为
- 高熵:输出分布平坦,Token 选择多样,模型处于探索状态(Exploration)。
- 低熵:分布集中在少数 Token 上,模型输出确定,处于利用状态(Exploitation)。
熵的变化趋势没有绝对好坏,必须结合任务场景和生成长度(Response Length)联合解读:
| 场景 | 合理的熵变趋势 | 解读 |
|---|---|---|
| 简单任务(短回答、直接对齐) | 熵稳步下降 | 优化方向明确,模型收敛到正确模式 |
| 复杂推理(长思维链 CoT) | 熵持平或微升,同时生成长度上升 | 模型通过扩大搜索空间试错,属于健康探索 |
需要警惕的异常信号:
- 熵下降过快 + 生成长度暴增:模型陷入"复读机"死循环,反复重复相同模式来凑长度。可通过监控重复率(Repetition Rate)交叉验证。
- 熵加速暴涨 + 远快于长度增速:策略被破坏,模型开始输出无意义的乱码。
工程经验:在训练看板上,奖励曲线(Reward Curve) 的优先级应高于损失曲线(Loss Curve)。Loss 可能在数值上持续下降,但如果 Reward 停滞或下跌,往往说明模型已经在 Reward Hacking 或正处于崩溃边缘。
15.7.2 熵崩溃的数学机制 [必读]
在 RL 训练初期,我们常常观察到策略熵在极短的步数内骤降至接近零——这就是熵崩溃。模型变得过于"自信",不再尝试新的推理路径,准确率随之停滞。
单步熵变分析。 考察连续两次参数更新之间的熵变化量
其中
这个公式揭示了一个关键事实:当协方差恒正时,每一步更新都会压缩熵。而在实际训练中,"结构性恒正"几乎不可避免,其机制如下:
第一步:SFT 遗留偏差。 经过监督微调的模型,天然倾向于输出高概率的"安全"Token。这些 Token 已经是模型认为最好的选择。
第二步:奖励模型的共谋。 这些高概率 Token 在奖励模型眼中,往往也被判定为较优动作,获得较高的优势值
第三步:正相关锁定。 当前策略认为概率高的动作(
第四步:单向压缩。 代入公式,当
反过来,即使某些低概率动作偶尔获得高优势值,由于其采样权重极小,对协方差的贡献也微乎其微,无法逆转这一趋势。
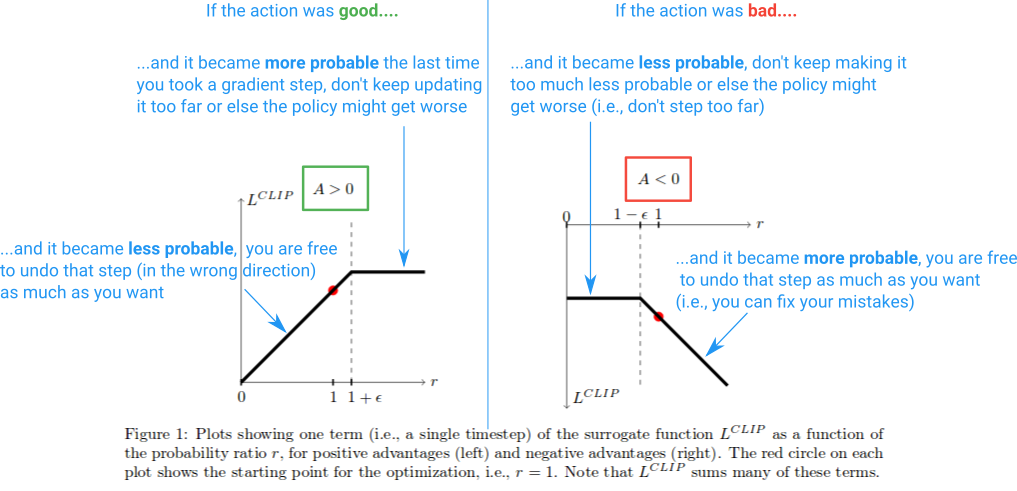
图 15-16:PPO 裁剪函数示意。左图(
15.7.3 解法一:DAPO 非对称裁剪 [必读]
DAPO(Decoupled clip and dynamic sampling Policy Optimization) 是字节跳动在 GRPO 基础上提出的一系列改进,其中最核心的思想之一是非对称裁剪(Clip-Shifting)。
问题根源。 在标准 PPO/GRPO 中,概率比率(Ratio)的裁剪边界是对称的:
- 如果旧策略概率
已经很大(比如 0.6),则新策略概率最多升到 ,绝对提升 0.12。 - 如果
很小(比如 0.01),则新策略概率最多升到 ,绝对提升仅 0.002。
高概率 Token 的绝对提升空间远大于低概率 Token——马太效应由此产生。
非对称裁剪。 DAPO 将上下边界解耦为
- 放宽上界:
,为低概率 Token "逆袭"提供更大空间。当一个罕见 Token 偶获正向奖励时,它的概率可以成倍提升,打破"高概率垄断"的格局。 - 收紧下界:
,避免过度抑制 Token 概率,防止采样空间急剧萎缩。
以下代码展示了非对称裁剪的核心实现:
import torch
def dapo_clipped_loss(
log_probs: torch.Tensor, # 当前策略 log π_θ, [B, T]
old_log_probs: torch.Tensor, # 旧策略 log π_old, [B, T]
advantages: torch.Tensor, # 优势值, [B, T]
mask: torch.Tensor, # 有效 token 掩码, [B, T]
eps_low: float = 0.1,
eps_high: float = 0.28,
) -> torch.Tensor:
"""DAPO 非对称裁剪策略梯度损失(Token-Level)"""
ratio = torch.exp(log_probs - old_log_probs) # r = π_θ / π_old
surr1 = ratio * advantages
surr2 = torch.clamp(
ratio, 1.0 - eps_low, 1.0 + eps_high # 非对称边界
) * advantages
token_loss = -torch.min(surr1, surr2) # PPO 目标取 min
# Token-level 平均:所有有效 token 权重相等
loss = (token_loss * mask).sum() / mask.sum().clamp(min=1)
return loss代码要点:(1)
eps_low和eps_high分开控制,而非共用一个epsilon;(2) 损失在 Token 级别做平均(除以mask.sum()),而不是先对每个样本做序列平均再汇总,这是 DAPO 的 Token-Level Loss 设计,能避免长序列中每个 Token 的梯度信号被过度稀释。
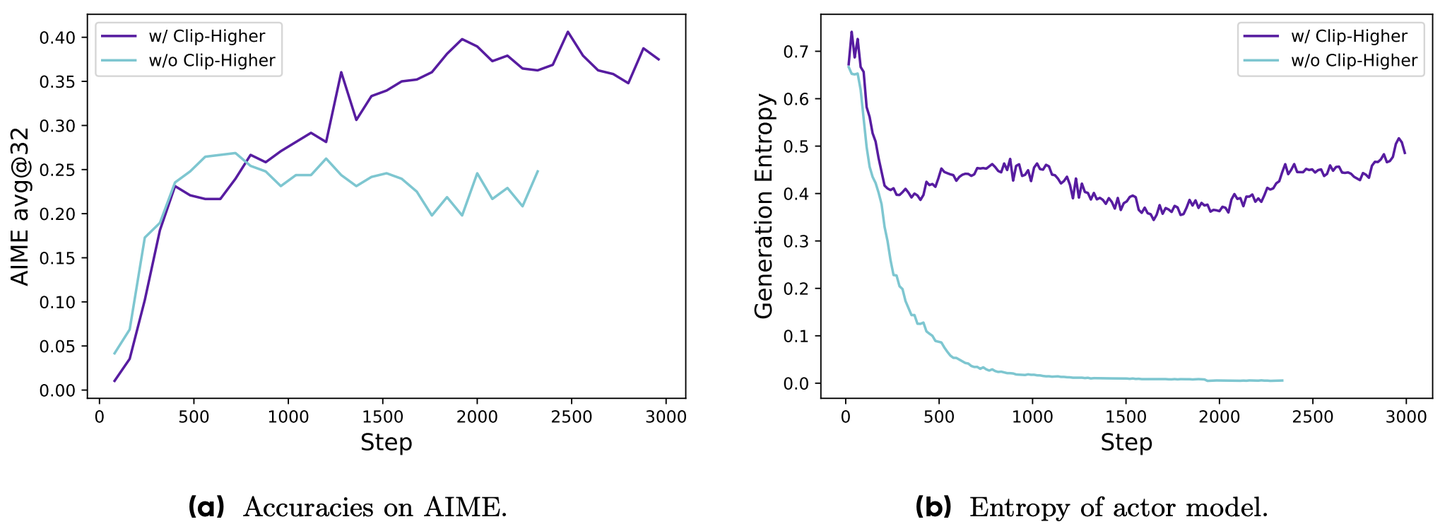
图 15-17:Qwen2.5-32B 在 AIME 数学竞赛上的消融实验。左图为准确率曲线,右图为策略熵曲线。不使用 Clip-Higher 时(浅蓝色),熵在训练早期迅速崩溃至接近零,准确率随之停滞;采用 Clip-Higher 后(紫色),熵稳定在 0.4-0.5 区间,准确率持续攀升。
15.7.4 解法二:动态温度与梯度掩码 [必读]
非对称裁剪从算法层面缓解了熵崩溃,而动态温度调度 + 梯度掩码则从另一个角度切入:并非所有 Token 都需要探索。
高熵 Token 与低熵 Token。 语言生成中的 Token 天然分为两类:
| Token 类型 | 典型示例 | 特征 |
|---|---|---|
| 高熵(分岔点 Forking Token) | 逻辑连接词(however, thus)、假设词(suppose, assume)、修正词(wait, unless) | 模型面临推理方向的选择,不确定性高 |
| 低熵(顺延点 Follow Token) | 词缀(-ing, -ed)、代码语法符号、数学公式中的固定符号 | 机械性输出,几乎完全可预测 |
对低熵 Token 强行增加探索毫无意义——你不需要在写完 prin 之后对 t 进行"探索"。
动态温度调度。 在生成(Rollout)阶段,对每个 Token 位置的采样温度做自适应调整:
2/8 梯度掩码(Top-Entropy Masking)。 在计算策略梯度时,引入 top_entropy_quantile 参数(典型值 0.2):只保留输出序列中平均熵最高的前 20% Token 的梯度,丢弃其余 80% 低熵 Token 的梯度。
import torch
def top_entropy_mask(
logits: torch.Tensor, # 模型输出 logits, [B, T, V]
mask: torch.Tensor, # 有效 token 掩码, [B, T]
quantile: float = 0.2, # 保留比例(即 "2/8 法则")
) -> torch.Tensor:
"""计算 Top-Entropy 梯度掩码:只保留高熵 Token 的梯度"""
with torch.no_grad():
probs = torch.softmax(logits, dim=-1)
log_probs = torch.log_softmax(logits, dim=-1)
# 逐 Token 计算熵: H = -sum(p * log p)
token_entropy = -(probs * log_probs).sum(dim=-1) # [B, T]
# 将无效位置的熵设为 -inf,排除在排名之外
token_entropy = token_entropy.masked_fill(~mask.bool(), float('-inf'))
# 对每个样本独立计算阈值:取 top quantile 的分位点
k = max(1, int(mask.sum(dim=-1).float().mean().item() * quantile))
topk_vals, _ = token_entropy.topk(k, dim=-1)
threshold = topk_vals[:, -1:] # [B, 1]
# 高于阈值的位置保留梯度
entropy_mask = (token_entropy >= threshold).float() # [B, T]
return entropy_mask * mask这种做法的好处是双重的:(1) 屏蔽了机械化表达对策略更新的干扰,使梯度信号聚焦于真正影响推理方向的关键节点;(2) 在复杂推理任务中,高熵分岔点恰好是"推理转折处",集中优化这些位置能显著提升整体推理质量。
15.7.5 奖励崩溃的机制与场景还原 [必读]
在 RLHF 的实际应用中,我们往往同时设置多个维度的奖励信号,例如"答案正确性(Accuracy)"和"输出格式合规性(Format)"。GRPO 等算法默认采用组内归一化(Group-wise Normalization) 来计算优势值。奖励崩溃(Reward Collapse) 正是在这一归一化过程中发生的。
场景还原。 假设某个 Prompt 下模型生成了 4 个回答,正确性奖励权重为 2,格式奖励权重为 1:
| 回答 | 正确性 | 格式 | 总奖励 = 2 |
|---|---|---|---|
| A | 4 | 0 | 8 |
| B | 2 | 3 | 7 |
| C | 1 | 0 | 2 |
| D | 0 | 3 | 3 |
按照标准流程,对总奖励
问题暴露:A 的正确性遥遥领先(满分 4),但其归一化后的优势值(+1.10)与 B(+0.71)的差距被大幅压缩。模型无法从这个信号中学习到"正确性远比格式重要"的优先级关系。多目标优先级被抹平——如同将各色颜料混在一起搅成了灰色。
崩溃后果。 当梯度信号变"灰"时,模型会出现两种典型症状:(1) 各项指标在训练中途突然断崖式下跌;(2) 模型学会用"格式正确但内容错误"的策略骗取奖励(Reward Hacking),因为格式奖励和正确性奖励在归一化后权重相当。
15.7.6 解法:GDPO 分组奖励解耦归一化 [必读]
GDPO(Group reward-Decoupled normalization Policy Optimization,分组奖励解耦归一化策略优化) 的核心思想极为直接:先独立归一化,再加权求和(Normalize-then-Sum),而不是先求和后归一化。
数学形式。 设有
每个奖励维度首先在组内独立标准化为零均值、单位方差的标准分数,然后再乘以各自的权重求和。这确保了每个维度的归一化量纲一致,权重
回到场景还原。 对正确性和格式分别独立归一化,再按 (2:1) 权重求和:
| 回答 | 正确性归一化 | 格式归一化 | |
|---|---|---|---|
| A | +1.34 | -0.71 | |
| B | -0.18 | +0.71 | |
| C | -0.58 | -0.71 | |
| D | -0.58 | +0.71 |
A 的优势值从 +1.10(标准 GRPO)跃升至 +1.97(GDPO),而 D 从 -0.71 降至 -0.45——"正确性优先"的信号被极大地放大了。模型能够接收到清晰的梯度指引:优先追求高正确性,即使牺牲部分格式规范。
以下是 GDPO 的核心实现:
import torch
def gdpo_advantage(
rewards: torch.Tensor, # [B, G, J] 多维奖励,J 个维度
weights: torch.Tensor, # [J] 各维度权重
eps: float = 1e-8,
) -> torch.Tensor:
"""GDPO 分组奖励解耦归一化:先独立归一化,再加权求和"""
# 对每个奖励维度独立做组内归一化
# rewards: [B, G, J]
mean_j = rewards.mean(dim=1, keepdim=True) # [B, 1, J]
std_j = rewards.std(dim=1, keepdim=True) + eps # [B, 1, J]
normalized = (rewards - mean_j) / std_j # [B, G, J]
# 加权求和得到最终优势值
# weights: [J] -> [1, 1, J] 广播
advantages = (normalized * weights.view(1, 1, -1)).sum(dim=-1) # [B, G]
return advantages
# ---------- 使用示例 ----------
if __name__ == "__main__":
# 4 个回答,2 个奖励维度(正确性、格式)
rewards = torch.tensor([[[4, 0], [2, 3], [1, 0], [0, 3]]],
dtype=torch.float) # [1, 4, 2]
weights = torch.tensor([2.0, 1.0]) # 正确性:格式 = 2:1
adv = gdpo_advantage(rewards, weights)
print("GDPO Advantages:", adv)
# 输出类似: tensor([[ 1.97, 0.35, -1.87, -0.45]])15.7.7 训练监控:熵与奖励的联合解读 [必读]
防范崩溃的最后一道防线是有效的监控体系。下表汇总了 RL 训练中最关键的监控指标及其解读方法:
| 指标 | 健康信号 | 危险信号 | 交叉验证 |
|---|---|---|---|
| 策略熵 | 稳步下降(简单任务)或保持稳定(复杂推理) | 骤降至接近 0(熵崩溃)或暴涨(策略崩坏) | 结合生成长度判断 |
| 生成长度 | 与任务需求匹配的稳定增长 | 失控暴增(复读机)或急剧缩短 | 结合重复率监控 |
| 奖励曲线 | 训练集/验证集同步上升 | 训练集上升但验证集停滞(过拟合)或断崖下跌 | 优先于 Loss 曲线 |
| 各维度奖励 | 各维度按预期优先级提升 | 低优先级维度压制高优先级维度 | 独立绘制各维度曲线 |
以下代码展示了一个实用的熵监控工具:
import torch
from typing import Dict
def compute_entropy_stats(
logits: torch.Tensor, # [B, T, V]
mask: torch.Tensor, # [B, T]
) -> Dict[str, float]:
"""计算策略熵的统计量,用于训练监控"""
with torch.no_grad():
probs = torch.softmax(logits, dim=-1)
log_probs = torch.log_softmax(logits, dim=-1)
token_entropy = -(probs * log_probs).sum(dim=-1) # [B, T]
# 仅统计有效位置
valid_entropy = token_entropy[mask.bool()]
stats = {
"entropy/mean": valid_entropy.mean().item(),
"entropy/std": valid_entropy.std().item(),
"entropy/min": valid_entropy.min().item(),
"entropy/max": valid_entropy.max().item(),
# 低熵 Token 占比——当此值超过 90% 时需警惕
"entropy/low_ratio": (valid_entropy < 0.1).float().mean().item(),
}
return stats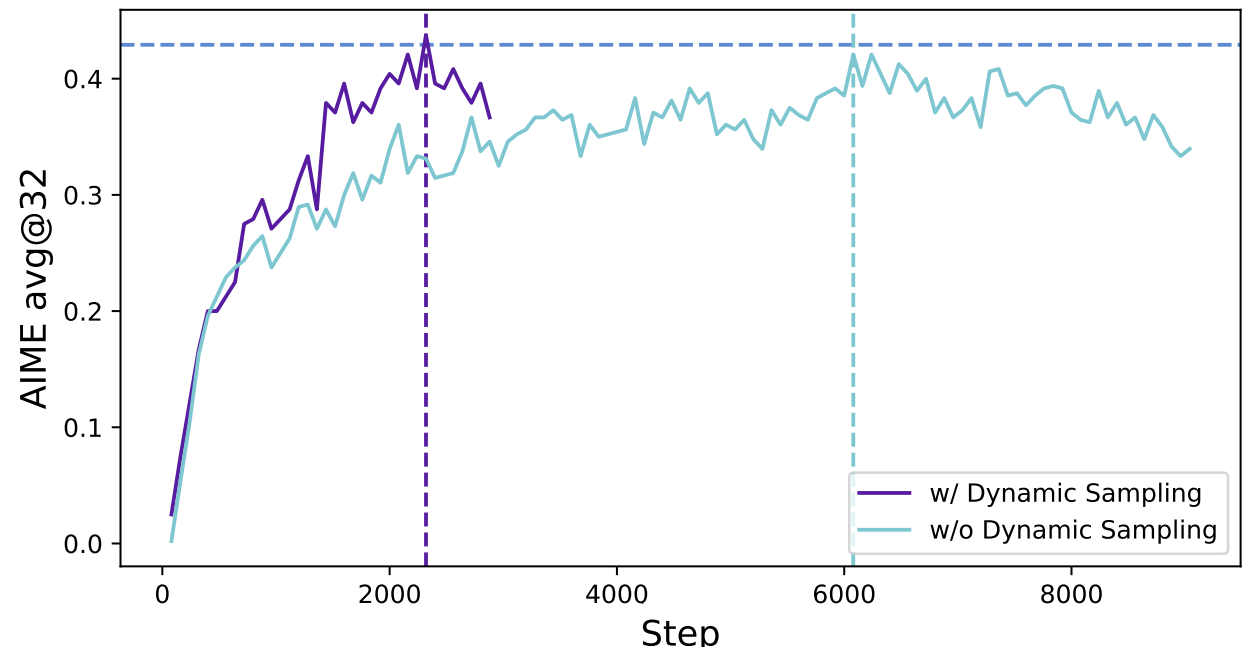
图 15-18:Dynamic Sampling 消融实验。紫色曲线(w/ Dynamic Sampling)以不到一半的训练步数达到了浅蓝色曲线(w/o Dynamic Sampling)的最终水平。过滤掉全对或全错的样本后,每一步都有有效梯度信号,收敛效率显著提高。
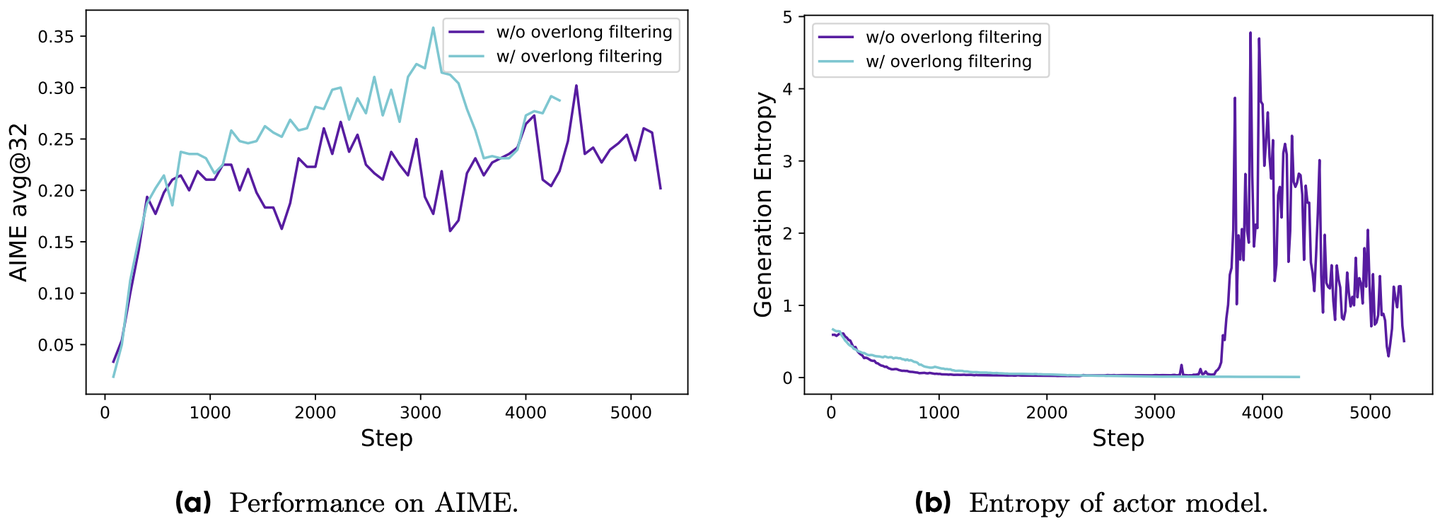
图 15-19:Overlong Reward Shaping 消融实验。不使用超长过滤(紫色)时,熵在训练后期出现剧烈震荡甚至暴涨至 4.0 以上,伴随准确率的不稳定波动;使用超长过滤(浅蓝色)后,熵保持平稳,准确率稳步上升。
15.7.8 综合视角:崩溃解法速查表
本节介绍的各种崩溃机制与解法可以用下表做一个全局梳理:
| 崩溃类型 | 根本原因 | 核心公式/机制 | 解法 | 关键超参数 |
|---|---|---|---|---|
| 熵崩溃 | 对称裁剪导致马太效应 | DAPO 非对称裁剪 | ||
| 熵崩溃 | 低熵 Token 稀释梯度 | 所有 Token 等权计算梯度 | 2/8 梯度掩码 | quantile=0.2 |
| 奖励崩溃 | 多维奖励全局归一化 | 先求和后归一化抹平优先级 | GDPO 解耦归一化 | 各维度权重 |
| 样本效率低 | 全对/全错样本无梯度 | 优势值全为零 | Dynamic Sampling | 过滤 acc=0 或 acc=1 的 prompt |
| 长度崩溃 | 截断样本引入噪声奖励 | 被截断的回答参与奖励计算 | Overlong Reward Shaping |
本节小结
大模型 RL 训练中的崩溃并非不可预防。核心要点可以归结为三条:
- 盯紧熵:策略熵是 RL 训练最重要的生命体征。必须结合生成长度联合解读,单看熵值没有意义。
- 防范熵崩溃:利用 DAPO 非对称裁剪打破"高概率 Token 垄断"的马太效应,或利用 2/8 梯度掩码将优化资源集中在真正关键的分岔点上。
- 防范奖励崩溃:在多目标奖励场景中,切忌先求和后归一化。采用 GDPO 的"先独立归一化、再加权求和"策略,保持各奖励维度的真实优先级。