7.7 模型家族架构差异对比表
前几节分别剖析了 Llama 3.2、Qwen3、Gemma 3、OLMo 3、Tiny Aya 和 Qwen3.5 六个模型家族的架构实现。它们共享 Transformer 解码器的整体框架,却在归一化、注意力机制、前馈网络、位置编码、并行块设计和稀疏化策略等维度上做出了截然不同的选择。本节将这些差异汇总为一张对比表,随后深入分析其背后的设计趋势与工程取舍。
图 7-24:六大模型家族核心架构对比。Llama、Qwen3、Gemma 3、OLMo 3、Tiny Aya 和 Qwen3.5 在归一化、注意力、FFN 等维度上的选择差异。
7.7.1 六大家族核心架构对比
| 特性 | Llama 3.2 | Qwen3 | Gemma 3 | OLMo 3 | Tiny Aya | Qwen3.5 |
|---|---|---|---|---|---|---|
| 归一化 | Pre-Norm RMSNorm | Pre-Norm RMSNorm | Pre-Norm RMSNorm | Post-Norm RMSNorm | Pre-Norm LayerNorm | Pre-Norm RMSNorm |
| 注意力机制 | GQA | MHA | SWA + GQA (5:1) | SWA / GQA | SWA + Full (3:1) | DeltaNet + Full |
| 前馈网络 | SwiGLU | SwiGLU | SwiGLU | SwiGLU | SwiGLU | SwiGLU |
| 位置编码 | RoPE | RoPE | RoPE | RoPE | RoPE | RoPE |
| 并行块 | 否 | 否 | 否 | 否 | 是 | 否 |
| MoE | 否 | 可选 | 否 | 否 | 否 | 否 |
表 7-8:六大模型家族的核心架构差异对比。加粗项表示与多数模型不同的非主流选择。
这张表浓缩了大量架构决策,以下从六个维度逐一展开分析。
7.7.2 归一化:Pre-Norm vs. Post-Norm,RMSNorm vs. LayerNorm
主流共识:Pre-Norm + RMSNorm。 六个家族中有五个采用 Pre-Norm RMSNorm,这一组合已成为当代大语言模型的事实标准。Pre-Norm(归一化置于子层输入之前)相比 Post-Norm(归一化置于残差连接之后)具有更好的梯度传播特性:残差路径上不经过归一化层,梯度可以无衰减地回传到浅层,从而缓解深层网络的训练不稳定问题。RMSNorm 相比 LayerNorm 省去了减均值和偏置项,计算量更低且实践中效果相当。
OLMo 3 的逆向选择:Post-Norm。 OLMo 3 是六个家族中唯一采用 Post-Norm 的模型。这一选择并非出于疏忽,而是 AI2 团队在大规模消融实验中的有意为之。Post-Norm 的理论优势在于:归一化作用于残差连接的输出,使每一层的输出分布更稳定,有助于模型在推理时保持更均匀的表征分布。其代价是训练初期可能出现梯度爆炸,需要配合学习率预热(warmup)和梯度裁剪等策略。OLMo 3 的实验表明,在精心调优的训练策略下,Post-Norm 可以在某些下游任务上略优于 Pre-Norm,尤其是在需要深层特征均匀性的场景中。
Tiny Aya 的保守选择:LayerNorm。 Tiny Aya 是唯一保留经典 LayerNorm 的模型。LayerNorm 包含减均值和偏置项(
设计启示。 归一化策略的选择并非孤立决策,而是与模型规模、训练策略和目标场景耦合。大模型倾向于用 RMSNorm 减少计算开销(省去均值计算在百亿参数规模下可节省可观的 FLOPs),小模型可以更自由地保留 LayerNorm 的额外参数。Pre-Norm 是"安全默认值"——降低训练难度、简化超参搜索;Post-Norm 是"高风险高回报"选项——需要更精细的训练策略,但可能解锁更好的表征质量。
7.7.3 注意力机制:从全局统一到异构混合
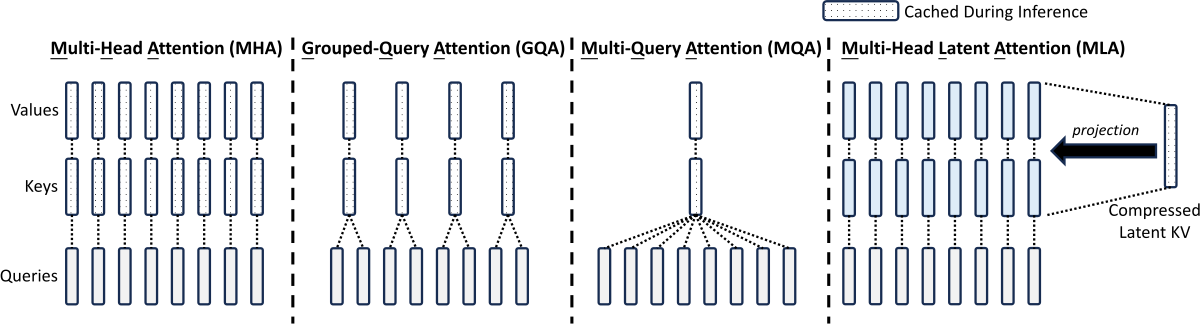
图 7-25:注意力机制变体对比。从 MHA 到 GQA、MQA,再到滑动窗口混合与线性注意力混合,展示各家族在注意力设计上的分化路径。
注意力机制是六个家族分化最显著的维度,可以归纳为四种策略:
策略一:全局统一 GQA(Llama 3.2)。 所有层使用相同的分组查询注意力,Query 头分为固定数量的 KV 组。这是最简洁的设计:实现简单、推理逻辑统一、KV 缓存管理直观。Llama 3.2 的 1B 模型使用 32 个 Query 头和 8 个 KV 组(4:1 分组比),相比 MHA 将 KV 缓存压缩为原来的
策略二:全局统一 MHA(Qwen3)。 Qwen3 的稠密版本在所有层使用标准多头注意力,每个头拥有独立的 Q、K、V 投影。虽然 MHA 的 KV 缓存最大,但 Qwen3 通过 QKNorm(Query-Key 归一化)和独立 head_dim 来增强训练稳定性和表达能力,弥补了效率上的不足。在配合量化推理(如 GPTQ、AWQ)时,MHA 的冗余 KV 参数可以被大幅压缩,实际部署中的效率差距会缩小。
策略三:混合滑动窗口 + 全局注意力(Gemma 3、OLMo 3、Tiny Aya)。 这三个家族都采用了"大部分层用局部注意力、少数层用全局注意力"的混合策略,但比例和实现各不相同:
- Gemma 3 采用 5:1 的 SWA:GQA 混合,窗口大小仅 512。18 层中 15 层是局部注意力,3 层是全局注意力。这是最激进的局部化设计——消融实验表明,绝大多数层学到的注意力模式本质上是局部的,全局注意力层只需极少即可。
- OLMo 3 同样混合使用滑动窗口和 GQA,但比例更保守,全局注意力层的占比更高。其设计重心在于与 Post-Norm 归一化的协同——Post-Norm 使每层输出更均匀,局部注意力层即使看不到远处的 token,也能从已被全局层整合过的"摘要表征"中间接获取全局信息。
- Tiny Aya 采用 3:1 的 SWA:Full 混合。相比 Gemma 3 的 5:1,Tiny Aya 保留了更多的全局注意力层,这与其多语言场景相关——跨语言的对齐信号往往需要在较长的上下文范围内建立,过于激进的局部化可能损害多语言能力。
策略四:线性注意力 + 全局注意力混合(Qwen3.5)。 Qwen3.5 引入了 DeltaNet——一种基于线性注意力的高效机制——与全局注意力混合使用。DeltaNet 的核心思想是将注意力计算从
趋势总结。 注意力机制的演化路径清晰可见:MHA → GQA(压缩 KV)→ 混合 SWA+Full(局部化)→ 线性注意力+Full(去 Softmax 化)。每一步都在追求一个核心目标——在不显著损失质量的前提下,降低注意力计算和内存的复杂度。但没有一个家族完全放弃全局注意力,即使是最激进的混合策略也会保留少量全局层。这说明全局信息整合仍然是不可替代的能力,局部注意力只能"减轻"而非"取代"全局注意力的负担。
7.7.4 前馈网络:SwiGLU 的绝对统治
这是六个家族唯一完全一致的维度——所有模型都使用 SwiGLU 作为前馈网络。SwiGLU 自 PaLM(2022)和 Llama 1(2023)以来迅速成为行业标准,其优势在于:
- 门控机制增强表达能力。 SwiGLU 的
结构引入了输入相关的门控信号,使网络能够动态选择性地激活或抑制不同维度的信息流。相比无门控的 GELU FFN,SwiGLU 在同等参数量下具有更强的函数拟合能力。 - SiLU 激活的平滑性。 SiLU(
)在零点附近平滑可导,避免了 ReLU 的"死神经元"问题,也避免了 GELU tanh 近似在极端值处的数值不稳定。 - 三投影结构的参数效率。 SwiGLU 虽然比标准 FFN 多一个线性投影(三投影 vs. 两投影),但通过适当缩小 hidden_dim(从 4x 降至约 2.67x 或 3x),可以在总参数量可比的条件下获得更好的性能。
SwiGLU 的统治地位也意味着:前馈网络不再是架构差异化的竞争维度。各家族的创新精力集中在注意力机制、归一化策略和整体拓扑结构上,前馈网络被视为"已解决的问题"。
需要特别指出的是,Gemma 3 的 FFN 严格来说使用的是 GeGLU(GELU 激活的门控变体),而非 SiLU 激活的 SwiGLU。但 GeGLU 与 SwiGLU 在结构上完全同构(仅激活函数不同),性能差异极小,本对比表将两者归入同一类别。
7.7.5 位置编码:RoPE 一统天下
六个家族全部使用 RoPE,无一例外。RoPE(Rotary Position Embedding)通过对 Query 和 Key 向量施加位置相关的旋转变换来编码相对位置信息,具有三大不可替代的优势:
- 天然的相对位置编码。 两个 token 的注意力分数仅取决于它们之间的相对距离,而非绝对位置。这使得模型在推理时可以自然地处理超出训练长度的序列。
- 长度外推能力。 通过调整基频
(如 Llama 3 的 500K、Qwen3 的 1M、Gemma 3 的 1M),RoPE 可以支持远超训练长度的上下文窗口。更大的 使低频维度的旋转更缓慢,有效延长最大可区分的相对距离。 - 与注意力机制的无缝兼容。 RoPE 作用于 Q/K 向量,不修改 V 向量,不引入额外参数,可以与 MHA、GQA、MQA、线性注意力等任意注意力变体组合使用。
各家族在 RoPE 的具体配置上有所不同——
7.7.6 并行块:Tiny Aya 的独特选择
并行块(Parallel Block) 指将注意力子层和前馈子层并行计算后相加,而非串行的"先注意力再前馈"。标准串行块的计算流程为:
并行块将其改为:
六个家族中只有 Tiny Aya 采用了并行块设计。并行块的优势在于:
- 更高的硬件利用率。 注意力和 FFN 可以在不同的计算单元上同时执行(如分别调度到不同的 GPU SM 或流水线段),减少串行等待时间。
- 更简单的梯度路径。 注意力和 FFN 的梯度独立回传到同一个归一化输入,不存在 FFN 梯度需要穿过注意力层的依赖关系,训练时梯度流更均匀。
- 训练速度提升。 GPT-J 和 PaLM 的实验表明,并行块可以在不损失收敛质量的前提下,将训练吞吐量提升 15-25%。
Tiny Aya 采用并行块的原因与其多语言低资源定位密切相关:在参数预算极为有限的条件下,并行块通过结构并行化弥补了模型容量的不足,使得同一计算预算内可以处理更多的 token。然而,多数家族(包括参数量更大的 Llama、Qwen3、Gemma 3)仍坚持串行块,原因在于:(1)串行块的注意力输出可以影响 FFN 的输入,信息流更丰富;(2)现代 GPU 的算力已经足够高,串行开销的绝对值并不大;(3)串行块的行为更易预测和调试。
7.7.7 MoE:Qwen3 的可选稀疏化路径
六个家族中只有 Qwen3 提供了 MoE(Mixture of Experts)变体。Qwen3 的 MoE 版本(30B-A3B)在每个 Transformer 块中将单个 SwiGLU FFN 替换为 128 个专家 FFN,每个 token 仅激活其中 8 个(Top-8 路由)。总参数量达到 305 亿,但每个 token 的激活参数量仅约 30 亿,推理计算量与稠密 3B 模型相当。
为什么其他家族不用 MoE? 这反映了 MoE 技术的现状——优势显著但工程门槛极高:
- 路由不均衡。 如果某些专家被持续选中而其他专家被冷落,模型的有效容量远低于总参数量。缓解手段包括辅助负载均衡损失、专家容量限制等,但这些技术增加了训练复杂度。
- 通信开销。 MoE 的分布式训练需要将不同 token 路由到持有对应专家的设备上(Expert Parallelism),All-to-All 通信的延迟可能成为瓶颈,尤其是在跨节点场景下。
- 推理内存占用。 虽然每个 token 只激活少量专家,但所有专家的权重都必须常驻显存。30B-A3B 模型在 bfloat16 下需要约 60 GB 显存加载全部权重,远超稠密 3B 模型的约 6 GB。
- 批量推理效率。 不同 token 可能被路由到不同专家,导致每个专家处理的 token 数量不均,GPU 利用率下降。
Qwen3 将 MoE 设为"可选"而非"默认",正是对这些权衡的务实回应:需要极致知识容量(如多语言覆盖、代码生成)时启用 MoE,追求部署简洁性时使用稠密版本。
7.7.8 设计趋势与深层取舍
纵观六个家族的架构选择,可以提炼出四条宏观趋势:
趋势一:注意力层是创新主战场,FFN 和位置编码趋于收敛。 SwiGLU 和 RoPE 已成为"基础设施级"组件,各家族在此维度上几乎没有差异。注意力机制则呈现百花齐放的局面——从纯 GQA 到混合 SWA、从 Softmax 注意力到线性注意力(DeltaNet),创新密度远高于其他维度。这一现象的深层原因是:注意力层的计算复杂度为
趋势二:异构化设计逐渐成为主流。 Gemma 3、OLMo 3、Tiny Aya、Qwen3.5 都采用了"同一模型中不同层使用不同注意力类型"的异构策略。这与早期"所有层结构完全相同"的同构设计形成鲜明对比。异构化的核心洞察是:不同层在模型中承担不同角色——浅层捕获局部语法模式、中层建立语义表征、深层进行全局推理——因此给予不同层不同的"计算预算"是合理的。
趋势三:模型规模决定了非主流选择的可行性。 OLMo 3 的 Post-Norm、Tiny Aya 的 LayerNorm 和并行块——这些"非主流"选择集中出现在中小规模模型上。大模型倾向于采用经过充分验证的"安全"组合(Pre-Norm RMSNorm + GQA + SwiGLU + RoPE),因为在百亿参数规模上进行消融实验的成本极高,试错容错率很低。小模型的训练成本低,可以更自由地探索非常规设计空间。
趋势四:效率-质量权衡的帕累托前沿不断右移。 从 Llama 3.2 的纯 GQA 到 Gemma 3 的 5:1 混合再到 Qwen3.5 的 DeltaNet 混合,同一质量水平下的推理效率在持续提升。这一趋势的驱动力不仅来自架构创新,还来自对"注意力资源应如何分配"这一问题的持续深入理解——消融实验反复证明,大多数层不需要全局注意力,大多数位置不需要精确的远程匹配,将注意力预算集中在真正需要的地方,就能以最小的质量代价获得最大的效率提升。
7.7.9 总结
本节通过一张六维对比表,系统梳理了 Llama 3.2、Qwen3、Gemma 3、OLMo 3、Tiny Aya 和 Qwen3.5 六个模型家族的核心架构差异。几个关键结论值得铭记:
高度收敛的组件:SwiGLU 和 RoPE。 这两个组件已经"赢得"了架构竞争,成为当代大语言模型不可动摇的标准配置。未来的创新不太可能发生在前馈网络和位置编码维度上。
活跃创新的维度:注意力机制。 从 MHA 到 GQA、从全局到混合局部-全局、从 Softmax 到线性注意力,注意力层的设计空间仍在快速扩展。Qwen3.5 的 DeltaNet 混合设计可能预示着下一代架构的方向——用线性注意力处理常规 token、用全局注意力处理关键决策点。
没有"最优架构",只有"最优权衡"。 每个家族的非主流选择都有其合理的场景依据——OLMo 3 的 Post-Norm 服务于表征均匀性、Tiny Aya 的并行块服务于低资源效率、Qwen3 的 MoE 服务于知识容量扩展。架构设计的本质不是寻找唯一正确答案,而是在效率、质量、可训练性、部署简洁性之间找到适合自身场景的最优平衡点。
异构化是不可逆的趋势。 随着对注意力资源分配规律理解的深入,"所有层结构相同"的同构设计正在让位于"按需分配计算预算"的异构设计。这一趋势将从注意力层扩展到归一化、FFN 乃至整个 Transformer 块的拓扑结构。
图 7-26:LLM 架构设计全景。从组件收敛(SwiGLU、RoPE)到异构化趋势(混合注意力、线性注意力),展示当代大语言模型架构的演进方向。
对于实践者而言,上述对比表可以作为架构选型的速查手册:如果目标是快速落地且稳定可靠,选择 Llama 3.2 的"标准组合";如果追求长序列效率,参考 Gemma 3 的混合注意力策略;如果面向多语言低资源场景,Tiny Aya 的并行块 + LayerNorm 组合值得考虑;如果需要在固定推理预算下最大化知识容量,Qwen3 的 MoE 路径是当前最成熟的方案。