18.1 从 RLHF 到 RLVR
在第 17 章中,我们已经了解了强化学习从人类反馈(RLHF)如何让语言模型学会"听话"——通过训练一个奖励模型来量化人类偏好,再用 PPO 等算法优化策略。这套流程在 ChatGPT 等产品中大获成功,但它有一个根本性的瓶颈:奖励模型本身的质量上限,就是整条训练链路的天花板。奖励模型从人类标注中学习,而人类标注不可避免地带有主观性、不一致性和标注成本的限制。
2025 年初,DeepSeek-R1 的发布引爆了一场范式转换。研究者们发现,对于数学、代码等存在客观正确性标准的任务,完全可以绕过奖励模型,直接用可验证的规则来提供奖励信号。这种方法被称为 RLVR(Reinforcement Learning with Verifiable Rewards,可验证奖励的强化学习)。更令人惊叹的是,在 RLVR 训练过程中,模型自发涌现出了"深度思考"的能力——它学会了在回答前进行长链条的自我推理和反思。
本节将从 RLHF 的局限出发,讲清 RLVR 的核心思想、数学验证器的工程实现,以及"深度思考"涌现背后的机制。
18.1.1 RLHF 的瓶颈:奖励模型不是万能的
回顾 RLHF 的三步流程:(1)用人类标注数据进行监督微调(SFT),得到初始策略;(2)收集人类偏好对比数据,训练奖励模型(Reward Model);(3)用 PPO 算法,以奖励模型的打分为优化目标,进一步训练策略模型。
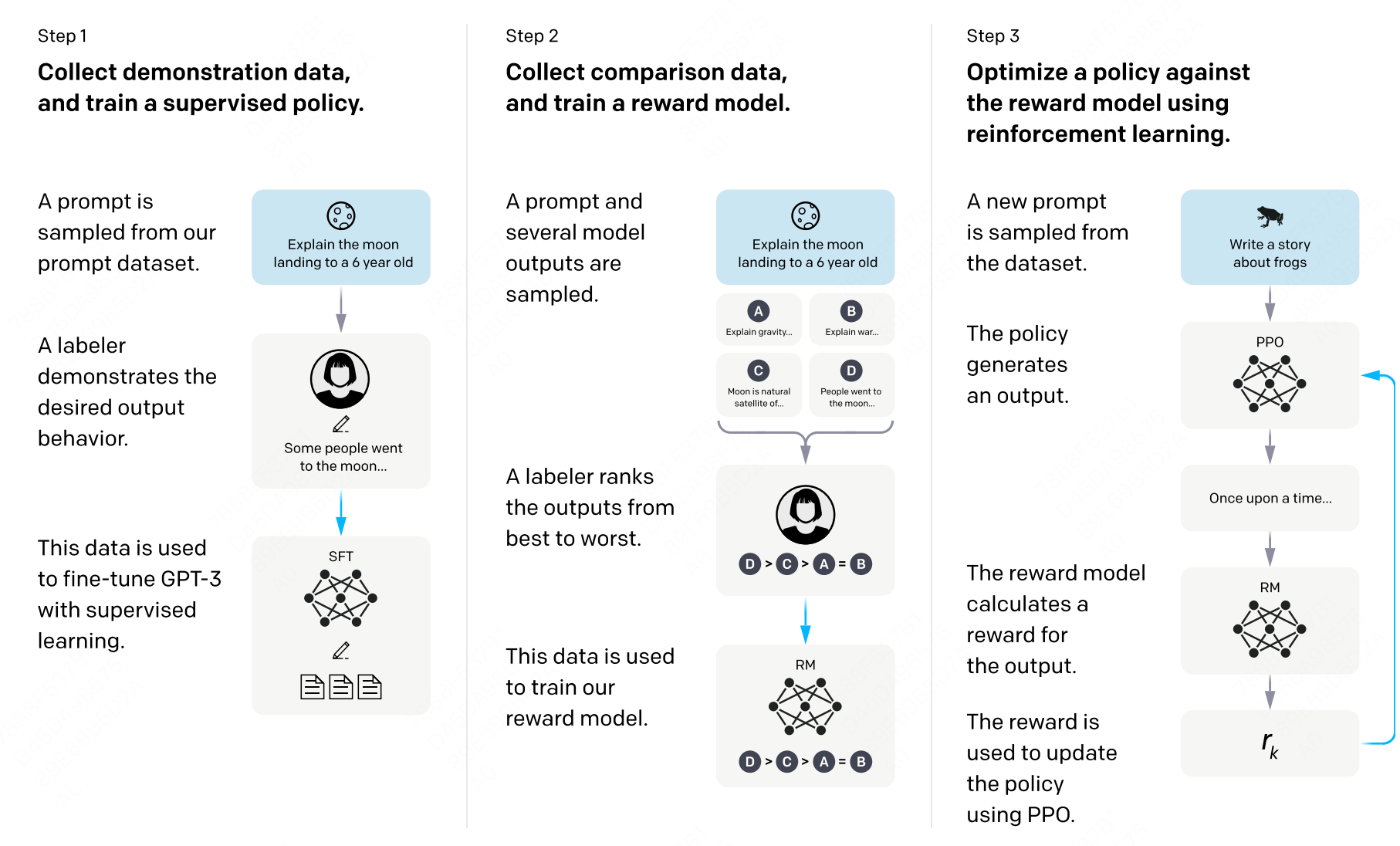
图 18-1:InstructGPT 提出的经典 RLHF 三步流程。Step 1 收集示范数据做 SFT;Step 2 收集偏好对比数据训练奖励模型;Step 3 用 PPO 优化策略。
这套流程在开放域对话、文本创作等任务上效果显著,但在数学推理和代码生成等领域暴露出几个深层问题:
奖励模型的能力天花板。 奖励模型本质上是从有限的人类标注数据中学习的"偏好近似器"。对于
奖励劫持(Reward Hacking)。 策略模型擅长发现奖励模型的"评分漏洞"。例如,模型可能学会生成冗长但看似专业的回答来骗取高分,或者用特定的语言模式迎合奖励模型的偏好,而实际推理质量并未提升。
训练复杂度高。 RLHF 需要同时维护四个模型——策略模型(Actor)、参考模型(Reference)、奖励模型(Reward)和价值模型(Critic),显存和算力开销巨大。PPO 算法中的广义优势估计(GAE)虽然有效,但实现复杂且调参困难。
这些问题促使研究者重新思考:对于存在客观答案的任务,能否直接用"对不对"作为奖励信号,跳过奖励模型?
18.1.2 RLVR:删去奖励模型的新范式
RLVR 的核心思想极为简洁——如果答案可以被程序自动验证,就不需要奖励模型来打分。它的概念最早在 Tulu 3 项目中被明确提出,而 DeepSeek-R1 则将其推向了工业级应用。
可验证奖励的定义。 奖励函数
其中
| 任务类型 | 验证方式 | 奖励信号 |
|---|---|---|
| 数学推理 | 提取 \boxed{} 中的答案,与标准答案做符号等价判断 | 正确 +1,错误 0 |
| 代码生成 | 执行生成的代码,检查是否通过所有测试用例 | 全通过 +1,部分失败 -1,无效代码 -0.2 |
| 指令遵循 | 检查输出是否符合指定格式(如 JSON 结构) | 符合 +1,不符合 0 |
与 RLHF 的关键区别。 RLHF 使用一个参数化的神经网络来近似人类偏好,这个近似器自身需要训练、会引入偏差、且难以泛化。RLVR 则用硬编码的规则直接计算奖励,没有近似误差,也不会被"劫持"。代价是它只适用于答案可验证的任务——对于"写一首诗"或"给出建议"这类开放性任务,RLVR 无法提供有效信号。
从 PPO 到 GRPO 的算法简化。 既然删去了奖励模型,算法层面能否进一步精简?DeepSeek-Math 提出的 GRPO(Group Relative Policy Optimization,组相对策略优化) 给出了肯定的答案。GRPO 的关键创新是同时删去了价值模型(Critic),用"组内对比"来估计优势函数。
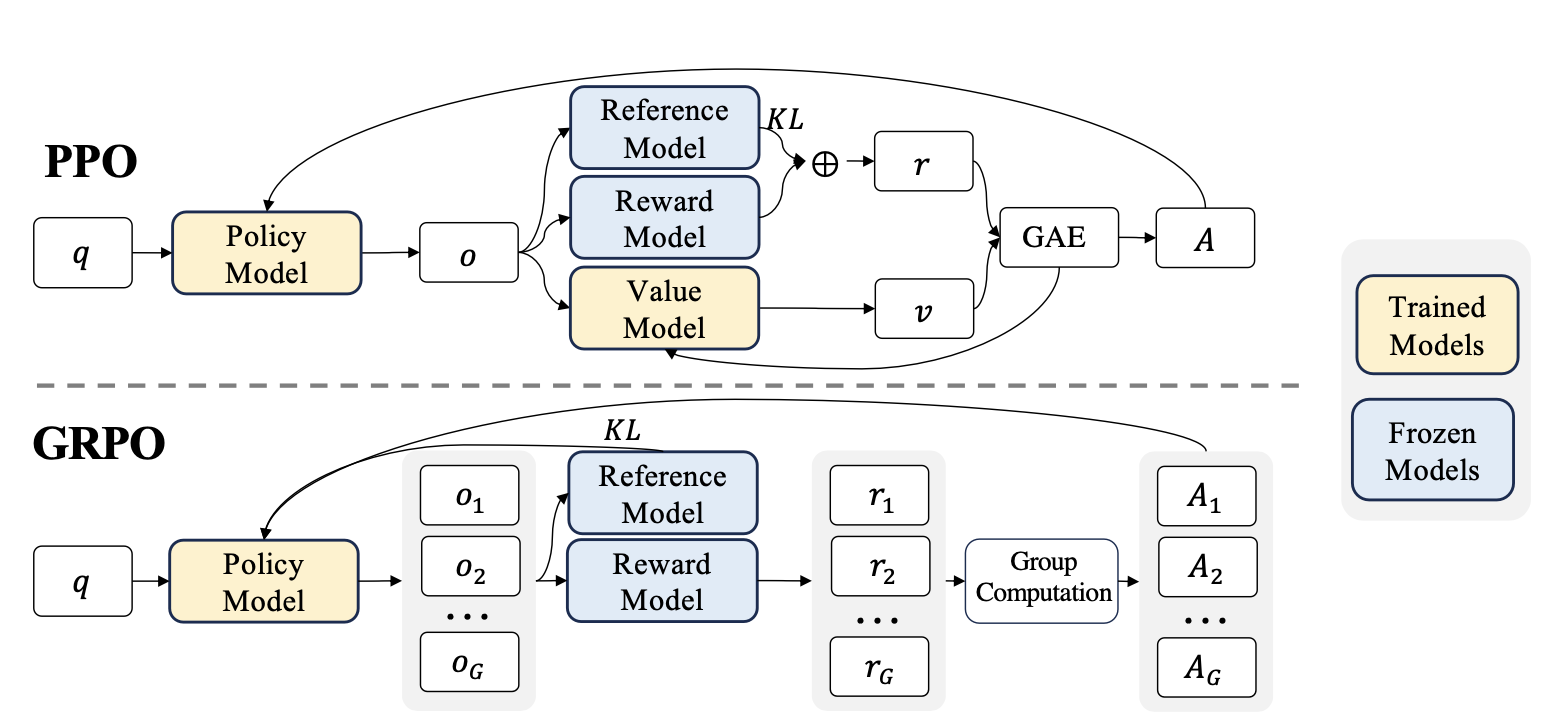
图 18-2:PPO 与 GRPO 的架构对比。PPO 需要策略模型、参考模型、奖励模型和价值模型四个组件;GRPO 删去了价值模型,通过组内多个回复的奖励对比直接计算优势函数。
GRPO 的工作流程如下:对于同一个问题
直觉上,如果一组回答中有的对、有的错,正确回答就获得正优势(被强化),错误回答获得负优势(被抑制)。如果全对或全错,则所有优势趋近于零,这道题对本轮梯度更新贡献极小——这恰好符合"只从有信息量的对比中学习"的直觉。
GRPO 的损失函数继承了 PPO 的截断策略比率机制,但不再需要 GAE 来估计优势值:
其中
18.1.3 数学验证器的工程实现
RLVR 的效果完全取决于验证器的质量。一个好的数学验证器需要解决三个层次的问题:从模型输出中提取答案、将答案标准化为可比较的形式、以及判断两个数学表达式是否等价。
第一步:答案提取。 推理模型通常被训练为将最终答案放在 \boxed{} 中。提取器需要处理嵌套大括号的情况:
def get_last_boxed(text: str) -> str | None:
"""从模型输出中提取最后一个 \\boxed{} 的内容,支持嵌套大括号。"""
boxed_start = text.rfind(r"\boxed")
if boxed_start == -1:
return None
idx = boxed_start + len(r"\boxed")
# 跳过空白字符
while idx < len(text) and text[idx].isspace():
idx += 1
if idx >= len(text) or text[idx] != "{":
return None
# 用栈的思想匹配嵌套大括号
idx += 1
depth = 1
content_start = idx
while idx < len(text) and depth > 0:
if text[idx] == "{":
depth += 1
elif text[idx] == "}":
depth -= 1
idx += 1
if depth != 0:
return None
return text[content_start : idx - 1]如果模型没有生成 \boxed{},还可以退回到提取文本中最后一个数字作为备选。
第二步:答案标准化。 数学答案的表达形式极为多样——1/2、0.5、\frac{1}{2}、50\% 都是同一个值。标准化函数需要统一处理 LaTeX 格式、Unicode 上标、分数、根号等:
import re
from sympy.parsing import sympy_parser as spp
from sympy import simplify
# LaTeX 清理规则
LATEX_FIXES = [
(r"\\left\s*", ""), (r"\\right\s*", ""),
(r"\\cdot", "*"), (r"\\dfrac", r"\\frac"),
(r"\\tfrac", r"\\frac"),
]
def normalize_math(text: str) -> str:
"""将各种数学表达形式标准化为可解析的字符串。"""
if not text:
return ""
# 去除 LaTeX 修饰
for pattern, replacement in LATEX_FIXES:
text = re.sub(pattern, replacement, text)
# 将 \frac{a}{b} 转换为 (a)/(b)
text = re.sub(
r"\\frac\s*\{([^{}]+)\}\s*\{([^{}]+)\}",
lambda m: f"({m.group(1)})/({m.group(2)})", text,
)
# 将 \sqrt{x} 转换为 sqrt(x)
text = re.sub(
r"\\sqrt\s*\{([^}]*)\}",
lambda m: f"sqrt({m.group(1)})", text,
)
# 清理百分号、美元符号等
text = text.replace("\\%", "").replace("$", "").replace("%", "")
text = text.replace("^", "**") # LaTeX 指数 -> Python 指数
# 去除千分位逗号:1,234 -> 1234
text = re.sub(r"(?<=\d),(?=\d{3}(\D|$))", "", text)
return text.replace("{", "").replace("}", "").strip().lower()第三步:符号等价判断。 标准化后的字符串仍然可能形式不同但数学等价(如 2*x + 1 与 1 + 2*x)。这里引入 SymPy 做符号化等价判断:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
def math_equivalent(expr_a: str, expr_b: str) -> bool:
"""判断两个数学表达式是否等价。先比字符串,再做符号化验证。"""
# 快速路径:字符串完全相同
if expr_a == expr_b:
return True
# 尝试解析为 SymPy 表达式
try:
parsed_a = spp.parse_expr(
expr_a,
transformations=(
*spp.standard_transformations,
spp.implicit_multiplication_application,
),
evaluate=True,
)
parsed_b = spp.parse_expr(
expr_b,
transformations=(
*spp.standard_transformations,
spp.implicit_multiplication_application,
),
evaluate=True,
)
except Exception:
return False
# 符号化判断:差为零则等价
try:
return simplify(parsed_a - parsed_b) == 0
except Exception:
return False完整的 RLVR 奖励函数。 将上述三步串联起来,就得到了一个生产级的数学验证器:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
def reward_rlvr(model_output: str, ground_truth: str) -> float:
"""RLVR 奖励函数:可验证的二元奖励。"""
# 提取 \boxed{} 中的答案
extracted = get_last_boxed(model_output)
if not extracted:
return 0.0 # 格式不正确,零奖励
# 标准化并判断等价
pred = normalize_math(extracted)
gold = normalize_math(ground_truth)
return 1.0 if math_equivalent(pred, gold) else 0.0这个验证器虽然代码量不大,但每一步都经过了工程打磨——处理嵌套括号、多种 LaTeX 变体、Unicode 字符、元组型答案(如坐标
18.1.4 GRPO 训练循环的完整实现
有了验证器,我们就可以构建完整的 RLVR-GRPO 训练循环。以下代码展示了核心的单步训练逻辑:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import torch
def compute_grpo_loss(
model, tokenizer, example, device,
num_rollouts=4, max_new_tokens=256,
temperature=0.8, top_p=0.9,
):
"""计算单个训练样本的 GRPO 损失。"""
prompt = render_math_prompt(example["problem"])
# ---- Stage 1: 生成多个候选回答(Rollout)----
model.eval()
rollout_logps, rollout_rewards = [], []
for _ in range(num_rollouts):
token_ids, prompt_len, text = sample_response(
model, tokenizer, prompt, device,
max_new_tokens=max_new_tokens,
temperature=temperature, top_p=top_p,
)
# ---- Stage 2: 计算可验证奖励 ----
reward = reward_rlvr(text, example["answer"])
# ---- Stage 3: 计算序列对数概率 ----
logp = sequence_logprob(model, token_ids, prompt_len)
rollout_logps.append(logp)
rollout_rewards.append(reward)
model.train()
# ---- Stage 4: 组内归一化计算优势 ----
rewards = torch.tensor(rollout_rewards, device=device)
advantages = (rewards - rewards.mean()) / (rewards.std() + 1e-4)
# ---- Stage 5: 策略梯度损失 ----
logps = torch.stack(rollout_logps)
loss = -(advantages.detach() * logps).mean()
return loss, rollout_rewards训练主循环则按标准流程进行:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
for step, example in enumerate(math_data):
optimizer.zero_grad()
loss, rewards = compute_grpo_loss(
model, tokenizer, example, device,
num_rollouts=4,
)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
reward_avg = sum(rewards) / len(rewards)
print(f"Step {step}: loss={loss.item():.4f}, reward={reward_avg:.3f}")几个关键的工程细节值得注意:
- 梯度裁剪是必须的。GRPO 的梯度方差天然比监督学习大(因为优势函数本身就来自随机采样),不裁剪容易导致参数爆炸。
num_rollouts的选择直接影响优势估计的质量。太少(如 2 个)时方差极大,太多(如 64 个)则推理成本过高。实践中 4~8 个是常见选择。- 全对或全错的 Batch不产生梯度信号(优势归一化后全为零)。这意味着题目的难度匹配至关重要——太简单或太难的题都浪费算力。
18.1.5 "深度思考"的自发涌现
RLVR 最令人兴奋的发现不是算法本身,而是它带来的涌现行为(emergent behavior)。DeepSeek-R1-Zero 的实验揭示了一个惊人的现象:仅使用 RLVR 训练(不经过 SFT),模型自发学会了长链条推理——在给出最终答案之前,先进行大量的自我验证、反思和纠错。
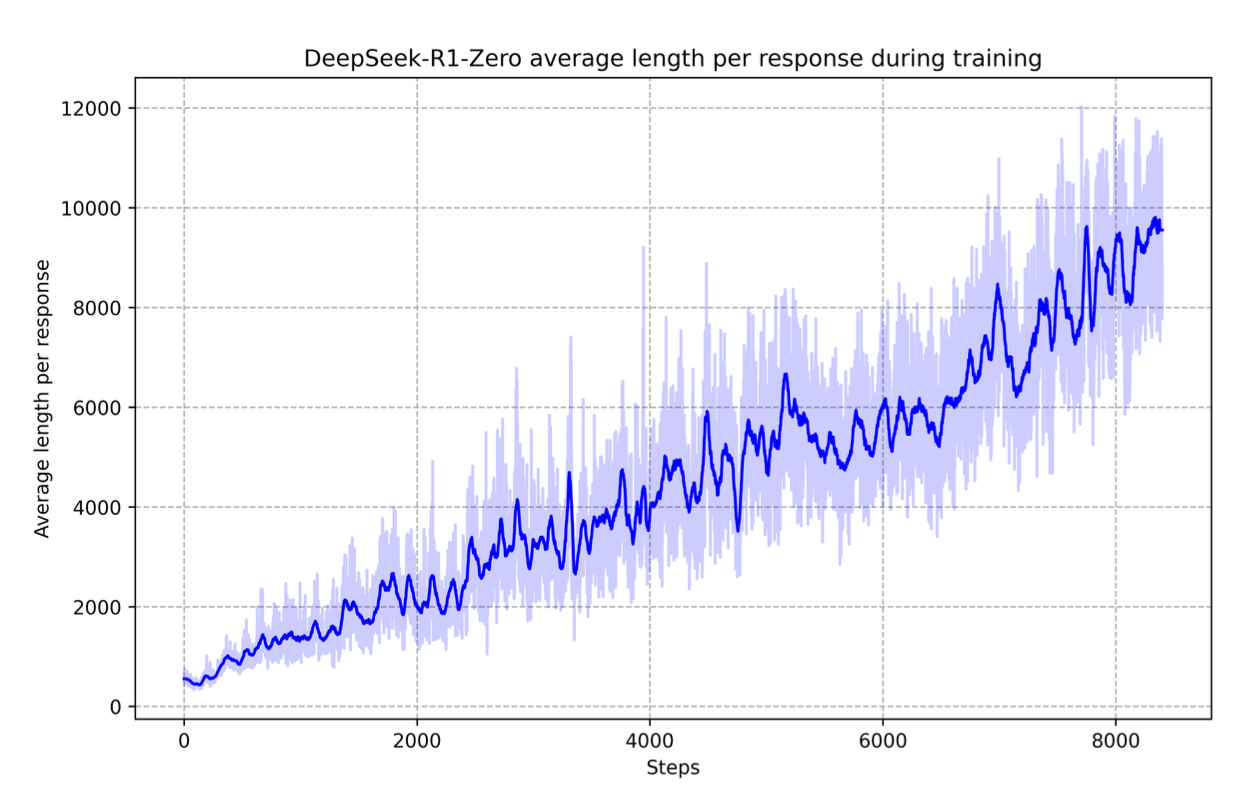
图 18-3:DeepSeek-R1-Zero 训练过程中平均回复长度的变化。随着训练推进,模型自发学会了生成越来越长的推理链,从初始的几百 token 增长到近万 token。
涌现的机制。 为什么"多想想再回答"会自发出现?回到 RLVR 的优化目标:模型唯一的激励是让最终答案正确。对于复杂问题,直接给出答案的正确率很低(奖励接近 0);但如果模型"碰巧"生成了更长的中间推理步骤,正确率就会提升,从而获得更高的奖励。GRPO 的组内对比机制会放大这种差异——在同一组回答中,那些包含更多推理步骤且最终答案正确的回答会获得正优势被强化。经过数千步迭代,"先推理再回答"的行为模式被系统性地巩固下来。
"顿悟"时刻(Aha Moment)。 在训练日志中,研究者观察到一个标志性的行为模式:模型开始在推理过程中产生自我反思和纠错的语言,例如"Wait, wait. Wait. That's an aha moment I can flag here. Let's reevaluate this step-by-step..."。

图 18-4:DeepSeek-R1-Zero 训练过程中出现的"Aha Moment"——模型在推理中途发现错误,自发进行反思和纠正。这种行为不是通过监督学习教会的,而是在纯强化学习中涌现出来的。
这种行为值得深入思考。模型并没有被显式教导"要反思"或"要检查",它只是在追求"答对题目"的过程中,自发发展出了这些策略。这与人类学习的过程有异曲同工之妙——一个不断练习数学题的学生,也会逐渐养成"做完检查一遍"的习惯,不是因为老师要求,而是因为检查确实能提高正确率。
DeepSeek-R1 的完整训练流水线。 实际的生产系统会在纯 RLVR 训练的基础上叠加更多步骤。DeepSeek-R1 的流程是:(1)先在基座模型上用纯 RLVR 训练出 R1-Zero,验证涌现能力;(2)用 R1-Zero 生成大量推理轨迹数据,经过筛选后做 SFT 冷启动;(3)在 SFT 模型上再做多阶段 RL 训练,兼顾推理能力和通用对话能力。
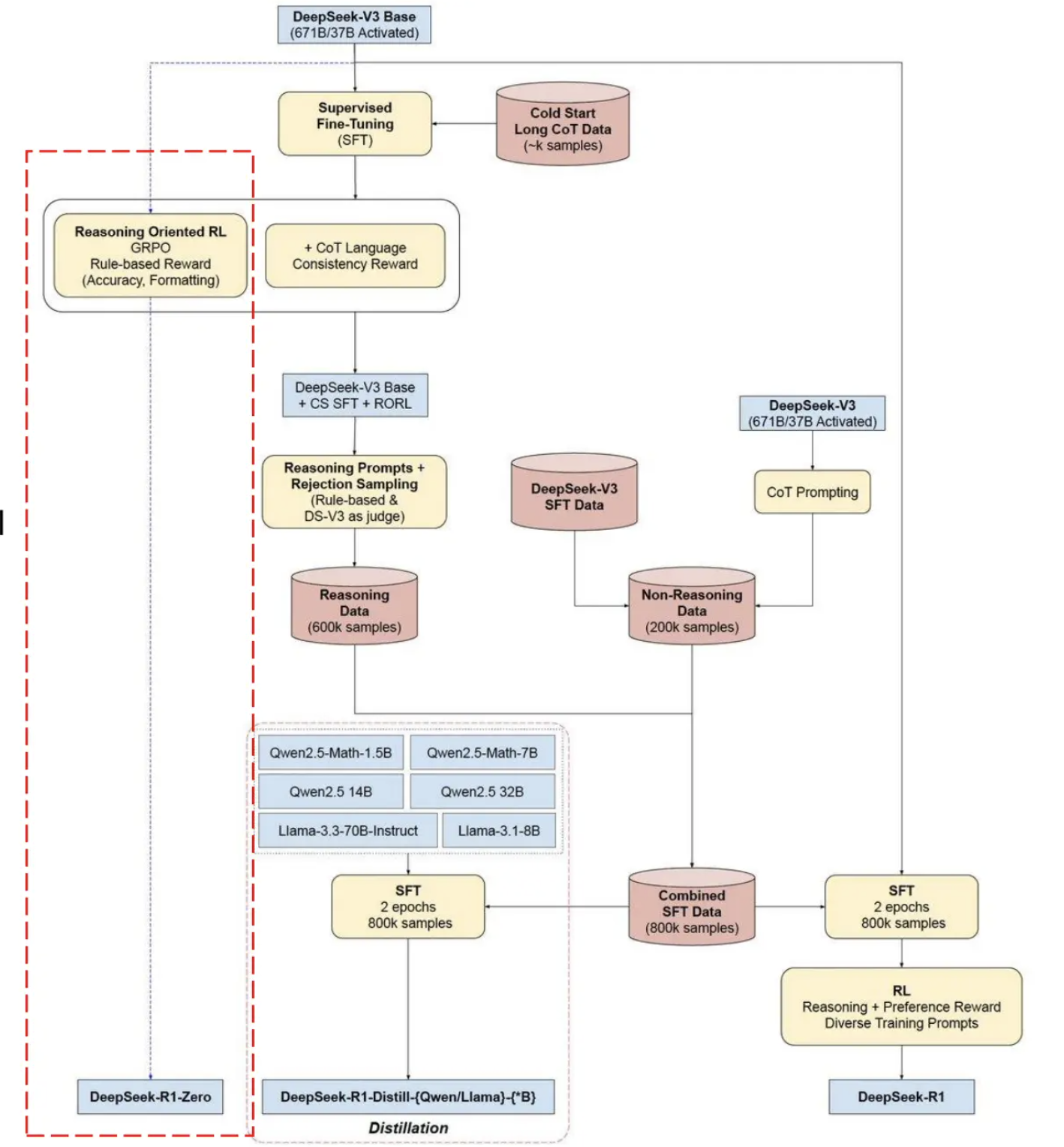
图 18-5:DeepSeek-R1 的完整训练流水线。左侧红色虚线框内是 R1-Zero 的纯 RL 路径;右侧是通过蒸馏将推理能力迁移到更小模型的路径。
18.1.6 从 RLVR 到 Agentic RL:更广阔的应用
RLVR 在数学和代码任务上取得了巨大成功,但它本质上是一个单步骤的 bandit 问题——模型生成一次完整回答,获得一个奖励,然后更新参数。当我们将 RL 应用于更复杂的 Agent 场景时(如多步工具调用、终端操作、网页导航),问题的结构发生了根本性变化。
RLVR 与 Agentic RL 的核心区别:
| 维度 | RLVR | Agentic RL |
|---|---|---|
| 交互模式 | 单步生成,一次性输出完整回答 | 多步交互,每步观察环境反馈后决策 |
| 奖励时机 | 即时(回答完毕立即判分) | 延迟且稀疏(整个任务完成后才知道成败) |
| 状态空间 | 仅为输入 prompt | 包含历史轨迹、工具输出、环境状态 |
| 信用分配 | 简单(整体回答对或错) | 困难(需要判断哪一步操作导致了最终成败) |
RLVR 开创的"用可验证信号替代人类偏好"的思路,是强化学习在语言模型上真正规模化落地的关键。然而,正如 ROLL 团队在实践中总结的那样:"RLVR 训练的是一个'会回答'的模型,而 Agentic RL 训练的是一个'会行动'的模型——跨时间、跨状态、跨不确定性地行动。" 从 RLVR 到 Agentic RL 的跨越,将在后续章节中详细展开。
本节小结
本节追溯了从 RLHF 到 RLVR 的范式演进。RLHF 通过人类偏好训练奖励模型来引导策略优化,虽然通用但受限于奖励模型的能力天花板和高昂的训练成本。RLVR 针对可验证任务(数学、代码等),用确定性规则直接计算奖励,配合 GRPO 算法删去了价值模型甚至参考模型,将四模型架构简化为单模型训练。工程上,数学验证器需要精心处理答案提取、LaTeX 标准化和符号等价判断三个层次。最重要的发现是,纯 RLVR 训练能让模型自发涌现出深度思考能力——长链条推理、自我反思和纠错行为,无需人工示范即可习得。这一发现深刻地改变了人们对语言模型推理能力来源的认知:推理不必被教会,它可以被激励出来。