22.1 RAG 基本概念
"不要让模型去'回忆'它从未见过的事实——给它一本参考书。" —— Lewis et al. (2020)
在第 21 章中,我们构建了智能体的完整理论与工程体系。当 Agent 需要回答一个关于特定企业内部手册的问题、或者解释上周刚发布的某篇论文的核心观点时,它面对的第一个根本性障碍不是推理能力不够,而是知识不够。大语言模型的参数中存储的知识具有三个致命缺陷:它是静态的(训练截止后不再更新)、不可控的(你不知道它到底"记住"了什么)、不可溯源的(输出无法指向某一条具体的参考资料)。
检索增强生成(Retrieval-Augmented Generation, RAG)正是为解决这些问题而诞生的技术范式。它的核心思想极其朴素:在让模型生成回答之前,先从外部知识库中检索出与问题相关的文档片段,然后把这些片段连同问题一起交给模型,让模型"看着资料答题"而非"凭记忆答题"。
本节的学习目标如下:(1)理解 RAG 系统的三大核心模块——检索器、生成器与检索融合——各自的职责与设计挑战;(2)掌握三种检索融合策略的原理、优劣与适用场景;(3)通过一个完整的代码示例,从零构建一个可运行的 RAG 系统;(4)认清 RAG 在实际部署中的核心痛点。
22.1.1 为什么需要 RAG
先用一个类比建立直觉。想象你正在参加一场闭卷考试(纯 LLM),你只能依赖大脑中"记住"的知识来回答问题。如果考题恰好涉及你没复习到的章节,你只有两个选择:编造一个看似合理的答案(幻觉),或者坦白说"不知道"。现在把考试改为开卷(RAG),你可以翻阅教材和参考资料,即使题目涉及你不熟悉的内容,你也能从资料中找到答案并准确作答。

图 22-0:纯 LLM 的"闭卷考试"模式。用户提出问题,模型仅凭参数中存储的知识直接生成回答,无法引用外部资料。来源:AIInfra RAGFlow 教程。
单独依赖 LLM 输出存在四个核心局限:
知识的局限性。 模型的知识广度完全取决于训练数据。对于企业内部文档、特定行业的专业规范、或某个小众领域的最新进展,模型的训练数据中很可能没有覆盖。
知识的滞后性。 模型的知识是在训练时"冻结"的。GPT-4 的训练数据截止到某个日期之后,世界上发生的一切对它而言都不存在。而大模型的训练成本极高,不可能频繁地为了弥补知识而重新训练。
幻觉问题。 所有生成式模型的本质是条件概率分布上的采样。当模型缺乏足够的知识来回答某个问题时,它不会"沉默",而是会生成一个在统计上看似合理、但在事实上可能完全错误的答案——这就是幻觉(Hallucination)。更危险的是,幻觉的输出往往语言流畅、逻辑自洽,用户很难凭直觉判断其真伪。
数据安全性。 对于企业来说,将私域数据上传至第三方平台训练意味着巨大的数据泄露风险。RAG 提供了一种折中方案:私域数据留在企业自己的检索系统中,模型只在推理时"临时借阅"这些数据,不需要将其编码进模型参数。
RAG 针对上述每个局限都提供了对应的解决方案:
| LLM 局限 | RAG 的应对策略 |
|---|---|
| 知识局限 | 连接外部知识库,随时引入新领域数据 |
| 知识滞后 | 知识库可实时更新,无需重新训练模型 |
| 幻觉问题 | 模型被引导基于检索到的事实生成,减少编造 |
| 数据安全 | 私域数据保留在检索侧,不进入模型训练 |
此外,RAG 还有一个常被忽视的优势:可溯源性。由于每次回答都基于具体的检索片段,系统可以在回答中标注引用来源(如"参考手册第 307 页"),用户能够直接验证答案的可靠性。
22.1.2 RAG 系统的三大核心模块
一个典型的 RAG 系统由三个模块构成:检索器(Retriever)、检索融合(Retrieval Fusion) 和 生成器(Generator)。它们各自承担不同的职责,协同完成"检索→融合→生成"的端到端流程。
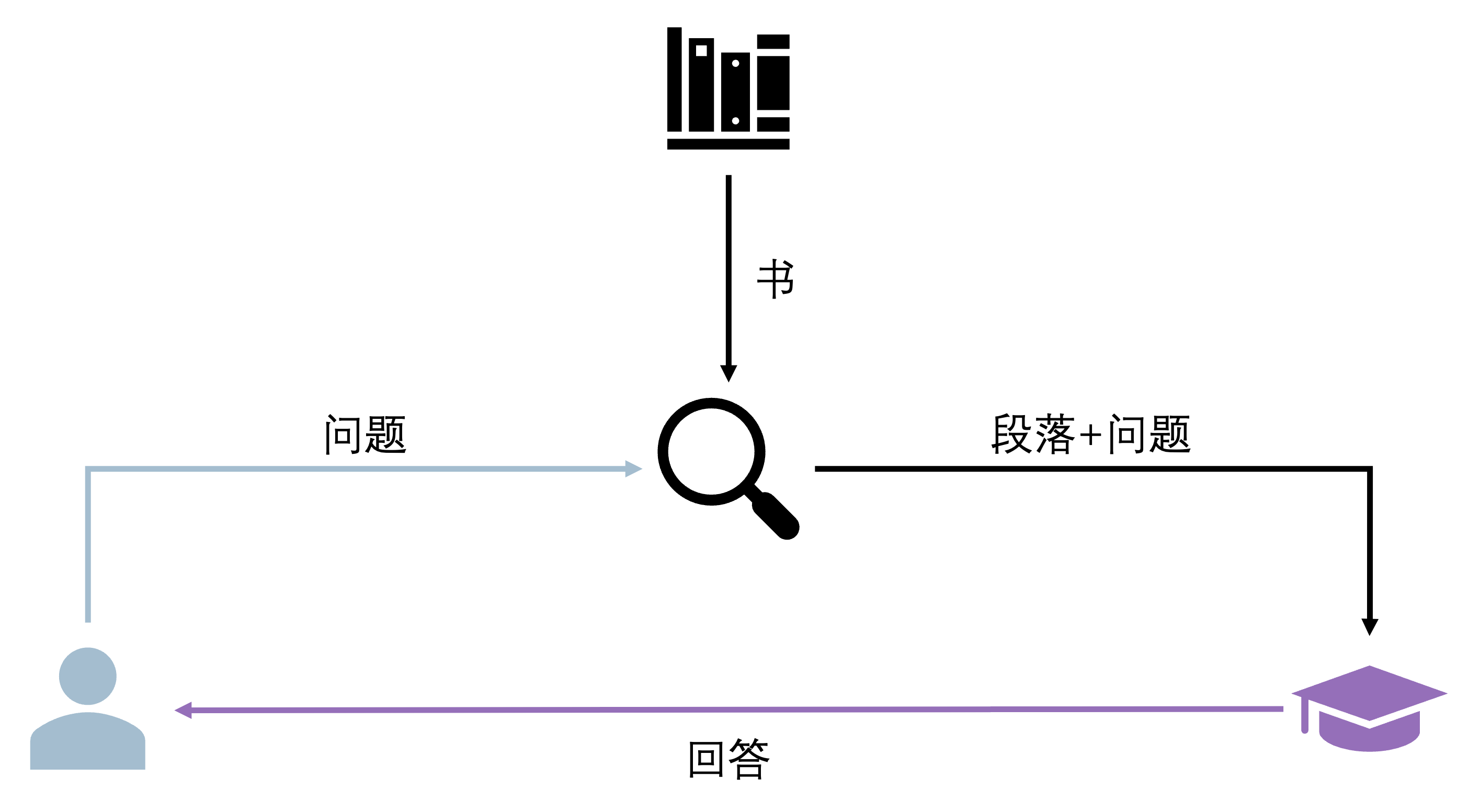
图 22-1:RAG 系统的"开卷考试"模式。用户提出问题后,系统先从外部知识库(书)中检索出相关段落,再将"段落+问题"一起送入生成器,最终输出基于参考资料的回答。来源:AIInfra RAGFlow 教程。
下面逐一拆解每个模块的设计。
22.1.3 检索器:从知识库中找到相关信息
检索器的任务可以用一句话概括:给定一个用户查询
构建一个检索器需要四个步骤:语料库分块 → 文本编码 → 构建索引 → 执行检索。
第一步:语料库分块(Chunking)。 原始文档通常很长(一份企业手册可能有几百页),直接对整篇文档做检索既低效又不精确。分块的目的是将长文档切分成语义相对独立的小片段,每个片段包含一个核心信息点。
分块策略主要有三种:
- 固定长度分块:最简单的方法,按字符数或 token 数等间隔切分,通常保留一定的重叠(overlap)以避免在切分边界处丢失语义。
- 语义分块:在句子边界或段落边界处切分,保证每个块在语义上更完整。
- 基于内容的分块:利用文档的结构特征(如 Markdown 标题、HTML 标签、代码函数定义)来决定切分位置。
分块大小的选择涉及一个核心权衡:块太大,则检索到的内容中噪声信息过多,模型难以聚焦;块太小,则单个块可能缺乏足够的上下文信息,导致语义不完整。实践中通常需要根据具体任务进行实验调优。
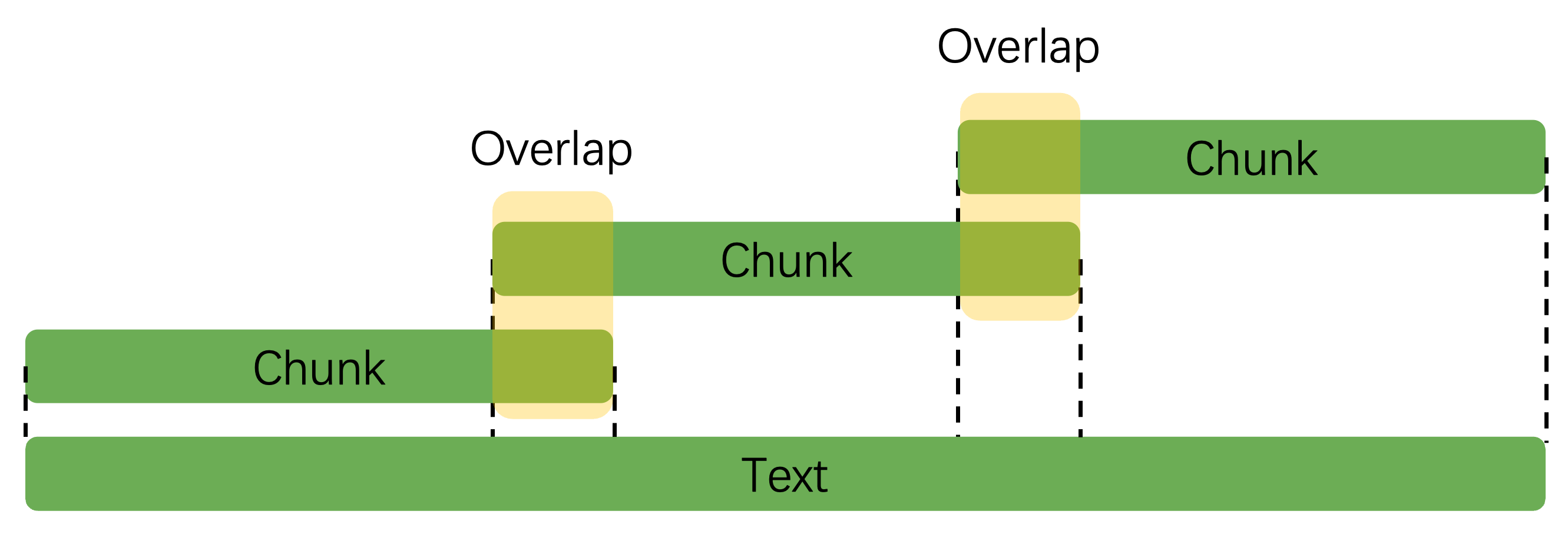
图 22-2:固定长度分块与重叠(Overlap)策略示意。底部为原始长文本,上方为切分后的 Chunk,相邻 Chunk 之间保留一段重叠区域(黄色部分),以避免在切分边界处丢失上下文语义。来源:AIInfra RAGFlow 教程。
第二步:文本编码(Encoding)。 将文本块转化为数值向量表示(embedding),以便进行数学上的相似性计算。编码方式分为两大类:
稀疏编码生成高维向量,其中绝大多数元素为零。典型方法包括词袋模型(Bag of Words)、TF-IDF 和 BM25。它们的核心思想是通过词频统计来表示文本,优势在于计算高效且对精确关键词匹配敏感,劣势在于无法捕捉语义相似性——例如"打开引擎盖"和"开前机舱盖"在稀疏编码中可能完全不匹配。
BM25 是稀疏编码中最常用的算法,其核心公式为:
其中
密集编码生成低维稠密向量(通常 768-1792 维),每个维度都携带语义信息。典型方法包括基于 BERT 的 Sentence Transformers、DPR(Dense Passage Retrieval)、以及商用的 text-embedding-ada-002 等。密集编码能够捕捉深层语义关系——"打开引擎盖"和"开前机舱盖"会被映射到向量空间中相近的位置。
实践中,混合检索(Hybrid Retrieval)将稀疏检索和密集检索结合使用,取两者之长:BM25 擅长处理精确的关键词匹配和专业术语,密集编码擅长处理同义改写和语义推理。
第三步:构建索引。 当知识库包含数百万甚至数十亿个文档块时,逐一计算查询与每个块的相似度是不可接受的。向量索引(Index)的作用是构建数据结构来加速最近邻搜索。常见的索引技术包括:
- HNSW(Hierarchical Navigable Small World):基于分层图结构,搜索质量高,是 FAISS 和 Milvus 等工具的默认选项之一。
- IVF(Inverted File Index):先对向量做粗聚类,搜索时只在查询所属聚类及其邻近聚类中搜索。
- PQ(Product Quantization):通过量化压缩向量,大幅降低存储和计算成本,但会损失一定精度。
这些技术统称为 ANN(Approximate Nearest Neighbor) 搜索——它们不保证找到精确的最近邻,但能在极短时间内找到足够好的近似结果。
第四步:执行检索。 给定查询
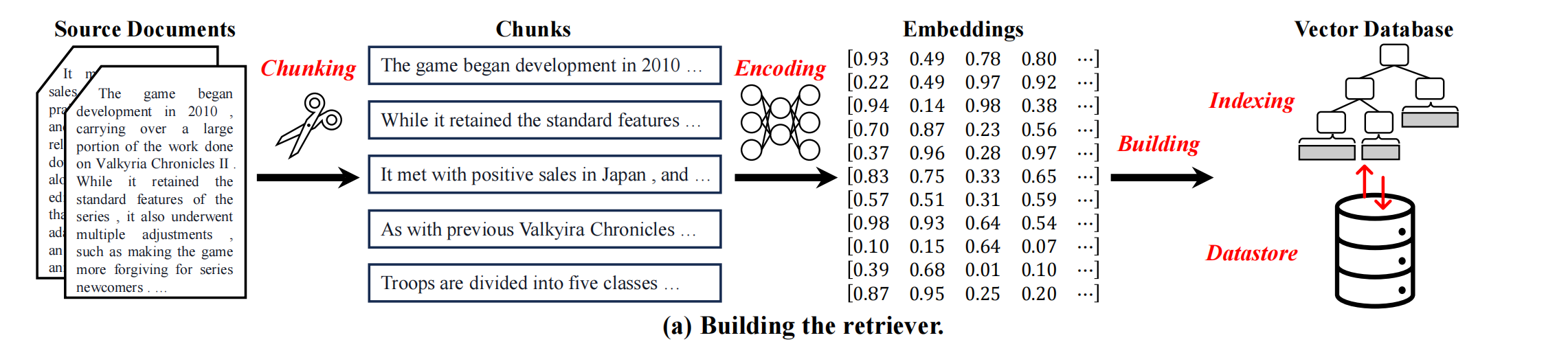
图 22-3:检索器的离线构建流程(Building the Retriever)。原始文档经过分块(Chunking)得到若干文本块(Chunks),再通过编码器转化为嵌入向量(Embeddings),最后构建索引并存入向量数据库(Vector Database)。来源:Wu et al., "Retrieval-Augmented Generation for NLP: A Survey" (2024)。

图 22-4:检索器的在线查询流程(Querying the Retriever)。用户的批量查询经编码后得到查询向量,通过 ANN 搜索在索引中找到 Top-K 最近邻,最后经过后处理(Post-processing)得到最终检索结果。来源:Wu et al., "Retrieval-Augmented Generation for NLP: A Survey" (2024)。
22.1.4 三种检索融合策略
检索器找到了相关文档,但如何将这些文档"喂给"生成器?这就是检索融合(Retrieval Fusion)模块的职责。融合策略的选择直接决定了 RAG 系统的性能上限与工程复杂度。当前的融合技术主要分为三大类。
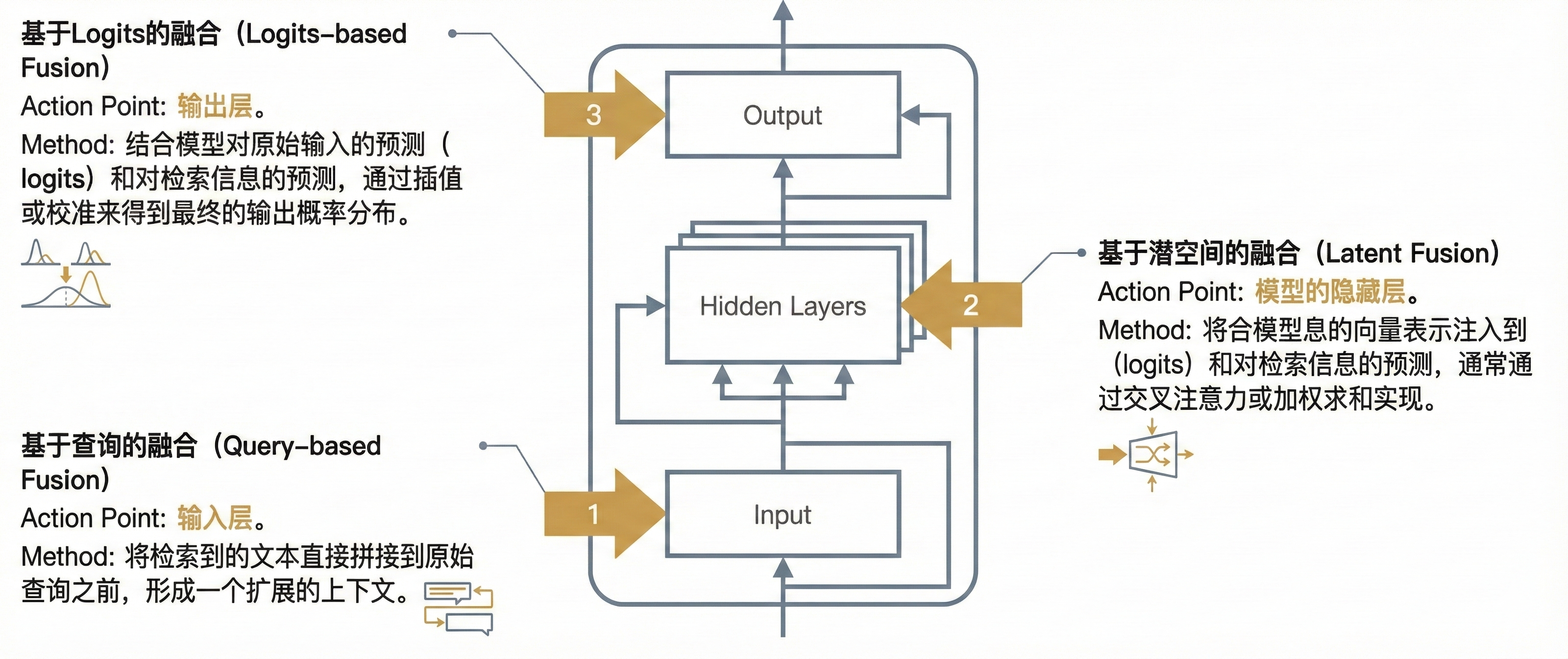
图 22-5:三种检索融合策略的作用位置对比。基于查询的融合(Query-based Fusion)在输入层将检索文本拼接到原始查询中;基于 Logits 的融合(Logits-based Fusion)在输出层对检索与生成的预测分布进行加权组合;潜在融合(Latent Fusion)在模型的中间隐藏层通过交叉注意力或加权相加注入检索信息。来源:AIInfra RAG 核心组件。
策略一:基于查询的融合(Query-based Fusion)。
这是最直观、最简单的融合方式,核心思想是:在将输入送给生成器之前,直接把检索到的文档拼接到查询中。
它有两种具体形式。文本拼接(Text Concatenation)直接将检索到的原始文本与查询拼接:
然后将拼接后的
特征拼接(Feature Concatenation)先用编码器将查询和检索结果分别编码为特征向量,再将特征向量拼接后送入解码器。
基于查询的融合的优势是实现简单、可解释性强(用户能直接看到模型参考了哪些资料),且无需修改生成器的架构,特别适合将闭源 LLM(如 GPT-4)作为"黑箱"通过 API 调用的场景。其劣势是拼接操作会显著增加输入序列的长度,导致推理延迟增大和计算成本上升,且受限于模型的上下文窗口长度。
策略二:基于 Logits 的融合(Logits-based Fusion)。
这种策略不修改生成器的输入,而是在输出层对检索信息进行融合。其核心思想是:让检索到的文档和原始查询分别通过生成器,得到各自的输出 logits,然后对这些 logits 进行加权组合来校准最终的预测。
kNN-LM(Khandelwal et al., 2020)是这种策略的代表性工作。它在推理时维护一个 key-value 存储,key 是训练语料中每个 token 位置的隐藏状态,value 是对应的下一个 token。生成时,模型将当前隐藏状态与存储中最相似的
其中
基于 Logits 的融合优势在于计算效率高——不增加输入序列的长度,检索内容可以批量并行处理,且将检索和生成过程解耦,便于独立优化。其劣势在于融合只发生在输出层(浅层整合),生成器内部的推理过程无法直接"看到"检索到的内容,这在需要深度推理的复杂任务中可能力不从心。
策略三:潜在融合(Latent Fusion)。
潜在融合是三种策略中最深层的整合方式,它将检索到的知识直接注入生成器 Transformer 的中间隐藏状态中。
RETRO(Borgeaud et al., 2022)是这一方向的代表。它在 Transformer 的部分层中插入交叉注意力模块(Cross-Attention),将生成器的隐藏状态作为 Query,检索到的文档块的编码作为 Key 和 Value:
其中
另一种轻量化的潜在融合方式是加权相加:将检索到的知识向量经过加权后直接叠加到隐藏状态上:
潜在融合的优势是整合深度最高、不增加输入序列长度、且可扩展性好(RETRO 的实验表明,较小的模型通过这种架构可以匹敌大得多的纯参数化模型的性能)。其劣势是需要对生成器的架构进行重大修改,通常需要从头预训练或精心微调,且融合发生在抽象的隐藏空间中,可解释性很低。
下表总结了三种融合策略的对比:
| 维度 | 基于查询的融合 | 基于 Logits 的融合 | 潜在融合 |
|---|---|---|---|
| 融合阶段 | 输入层 | 输出层 | 中间隐藏状态 |
| 整合深度 | 中等 | 浅层 | 深层 |
| 计算效率 | 低(序列变长) | 高 | 高且可扩展 |
| 架构修改 | 无(仅改 Prompt) | 最小 | 需修改 Transformer |
| 可解释性 | 高 | 中等 | 低 |
| 典型场景 | 黑箱 API 调用 | kNN-LM, 效率敏感 | 性能极致,可定制架构 |
融合策略的选择本质上是简单性、性能与可解释性之间的三角权衡。在当前的工业实践中,基于查询的文本拼接是使用最广泛的方式,因为它不需要修改模型架构,且与任何 LLM(包括闭源模型)兼容。
22.1.5 生成器:基于增强输入产生最终回答
生成器是 RAG 系统的最后一环,它接收经过融合增强的输入,输出最终的回答。从技术角度看,生成器就是一个大语言模型——它可以是预训练的通用模型(如 GPT-4、Qwen、LLaMA),也可以是经过特定训练的检索增强模型(如 RETRO)。
生成器的设计与融合策略密切相关:
- 闭源 LLM(如 GPT-4、Claude)只能通过 API 访问,因此只能使用基于查询的融合——将检索到的文档作为 prompt 的一部分传入。
- 开源 LLM(如 LLaMA、Qwen)可以访问模型内部,因此三种融合策略都可以使用。
在基于查询的融合(最常用的场景)中,生成器的 prompt 通常包含三个部分:
System: 你是一个知识问答助手,请严格基于给定的参考资料回答问题。
如果参考资料中没有答案,请直接说"资料中未找到相关信息"。
Context: [检索到的文档片段 r_1, r_2, ..., r_k]
User: [用户的原始查询 q]这里的 System Prompt 承担着关键的接地(Grounding) 作用——它明确告诉模型"只能基于给定资料回答",从而抑制模型依赖自身参数知识编造答案的倾向。
22.1.6 代码实战:从零构建一个简单的 RAG 系统
理论讲完了,现在用代码把所有组件串起来。下面的示例构建一个完整的 RAG 流程:准备知识库 → 分块 → 编码 → 构建索引 → 混合检索 → 生成回答。
"""
最小可运行的 RAG 系统示例
依赖安装: pip install sentence-transformers rank-bm25 jieba transformers torch
"""
import numpy as np
import jieba
from rank_bm25 import BM25Okapi
from sentence_transformers import SentenceTransformer
# ===================== 第一步:准备知识库并分块 =====================
# 模拟一个小型知识库(实际项目中会从文件/数据库加载)
documents = [
{"page": 1, "content": "FAISS 是 Facebook AI Research 开发的向量相似性搜索库,"
"支持多种索引类型,包括 IVF、HNSW 和 PQ。它能够在十亿级别的向量集合中"
"实现毫秒级的近似最近邻搜索。FAISS 同时支持 CPU 和 GPU 加速。"},
{"page": 2, "content": "BM25 是一种基于词频统计的文本检索算法,属于稀疏检索方法。"
"它通过逆文档频率(IDF)给稀有词更高权重,并使用文档长度归一化来避免长文档的"
"得分偏高。BM25 在精确关键词匹配场景下表现出色。"},
{"page": 3, "content": "密集检索使用深度学习模型将文本编码为稠密向量,"
"再通过向量相似度进行匹配。与 BM25 不同,密集检索能捕捉语义相似性,"
"例如同义词、改写句式等。常用模型包括 DPR、Sentence-BERT 和 BGE。"},
{"page": 4, "content": "混合检索结合了稀疏检索(如 BM25)和密集检索的优势。"
"通常先用两种方法分别检索 Top-N 候选,再用 Rerank 模型对候选集重排序,"
"选出最终的 Top-K 结果。Rerank 模型(如 bge-reranker)通过交叉编码器"
"精细评估查询与文档的匹配程度。"},
{"page": 5, "content": "RAG 的检索融合策略分为三种:基于查询的融合将检索文本直接"
"拼接到 prompt 中,实现简单但增加输入长度;基于 Logits 的融合在输出层"
"加权组合检索与生成的预测分布;潜在融合通过交叉注意力将检索信息注入"
"Transformer 的隐藏状态中,整合深度最高但需要修改模型架构。"},
]
def chunk_text(text: str, chunk_size: int = 150, overlap: int = 20) -> list[str]:
"""固定长度分块,带重叠以保留上下文连续性"""
chunks = []
for i in range(0, len(text), chunk_size - overlap):
chunk = text[i : i + chunk_size]
if chunk.strip():
chunks.append(chunk.strip())
return chunks
# 对每个文档进行分块(此示例中文档已较短,分块主要演示流程)
all_chunks = []
chunk_metadata = [] # 记录每个 chunk 对应的原始页码
for doc in documents:
chunks = chunk_text(doc["content"], chunk_size=200, overlap=30)
for c in chunks:
all_chunks.append(c)
chunk_metadata.append({"page": doc["page"]})
print(f"知识库共 {len(documents)} 篇文档,分块后共 {len(all_chunks)} 个 chunk")
# ===================== 第二步:构建双路检索(BM25 + 密集检索) =====================
# 2a. BM25 稀疏检索
tokenized_chunks = [jieba.lcut(c) for c in all_chunks]
bm25 = BM25Okapi(tokenized_chunks)
# 2b. 密集检索(使用 Sentence Transformers)
embed_model = SentenceTransformer("BAAI/bge-small-zh-v1.5")
chunk_embeddings = embed_model.encode(all_chunks, normalize_embeddings=True)
def hybrid_search(query: str, top_k: int = 3, bm25_weight: float = 0.3) -> list[dict]:
"""
混合检索:BM25 + 密集检索,按加权分数排序
Args:
query: 用户查询
top_k: 返回的结果数量
bm25_weight: BM25 分数的权重(密集检索权重 = 1 - bm25_weight)
Returns:
排序后的检索结果列表,每个元素包含 chunk 文本、分数和页码
"""
# BM25 检索
query_tokens = jieba.lcut(query)
bm25_scores = bm25.get_scores(query_tokens)
# 归一化 BM25 分数到 [0, 1]
if bm25_scores.max() > 0:
bm25_scores = bm25_scores / bm25_scores.max()
# 密集检索
query_emb = embed_model.encode(query, normalize_embeddings=True)
dense_scores = query_emb @ chunk_embeddings.T # 余弦相似度(已归一化)
# 加权融合
final_scores = bm25_weight * bm25_scores + (1 - bm25_weight) * dense_scores
# 按分数降序排列,取 top_k
top_indices = final_scores.argsort()[::-1][:top_k]
results = []
for idx in top_indices:
results.append({
"chunk": all_chunks[idx],
"score": float(final_scores[idx]),
"page": chunk_metadata[idx]["page"],
})
return results
# ===================== 第三步:构建 RAG 生成函数 =====================
def rag_generate(query: str, top_k: int = 3) -> str:
"""
完整的 RAG 流程:检索 → 构建 prompt → 生成回答
注意:此处用模板拼接模拟生成过程。实际项目中替换为 LLM API 调用。
"""
# 检索
results = hybrid_search(query, top_k=top_k)
# 构建 prompt(基于查询的文本拼接融合)
context = "\n\n".join(
f"[参考{i+1}, 来源第{r['page']}页] {r['chunk']}"
for i, r in enumerate(results)
)
prompt = f"""请严格基于以下参考资料回答问题。如果资料中没有答案,请说明"资料中未找到相关信息"。
参考资料:
{context}
问题:{query}
回答:"""
# 在实际项目中,这里应调用 LLM API,例如:
# from openai import OpenAI
# client = OpenAI()
# response = client.chat.completions.create(
# model="gpt-4",
# messages=[{"role": "user", "content": prompt}],
# )
# return response.choices[0].message.content
# 此处返回构建好的 prompt 用于演示
print("=" * 60)
print("【RAG 检索结果】")
for i, r in enumerate(results):
print(f" Top-{i+1} (得分 {r['score']:.3f}, 第{r['page']}页): "
f"{r['chunk'][:60]}...")
print("=" * 60)
print("【构建的 Prompt(截断展示)】")
print(prompt[:500])
return prompt
# ===================== 测试 =====================
query = "BM25 和密集检索有什么区别?"
rag_generate(query)运行上述代码,你会看到系统检索出了与 BM25 和密集检索最相关的文档片段,并将其组织成结构化的 prompt。在实际项目中,只需将最后一步的 prompt 发送给任何 LLM API,即可获得基于检索文档的准确回答。
22.1.7 RAG 的核心痛点与真实挑战
了解了 RAG 的基本架构后,有必要正视一个现实:能跑起来的 RAG 和能上线的 RAG 之间,隔着巨大的工程鸿沟。大多数入门教程展示的是"文档加载 → 默认分块 → top-5 检索 → LLM 生成"的"快乐路径",但真正决定 RAG 系统质量的核心难题,几乎都被回避了。
痛点一:分块策略至关重要,但没有万能方案。 chunk 大小应该设为多少?100 token?500 token?答案是:取决于你的任务、编码器和查询类型。问答任务可能偏好短 chunk(精准定位),摘要任务可能偏好长 chunk(保留上下文)。更麻烦的是,很多文档的信息密度不均匀——一段密集的技术描述和一段冗长的背景介绍不应使用相同的 chunk 大小。
痛点二:检索噪声是隐形的杀手。 top-k 中可能有多个完全不相关的 chunk 被检索出来。这些噪声 chunk 不仅浪费了宝贵的上下文窗口空间,还可能误导模型生成错误的答案。这就是为什么Rerank(重排序)在生产级 RAG 中几乎是必备环节——先用效率较高的检索方法(BM25 + 密集检索)获取较多的候选,再用精度更高的交叉编码器(如 bge-reranker)对候选集进行精排。
痛点三:模型太强反而掩盖了检索的弱点。 这是一个微妙但危险的陷阱。当模型本身的参数知识足以回答某个问题时,即使检索完全失败(返回的全是无关文档),模型依然会给出正确答案。开发者看到模型"答对了",就误以为 RAG 系统运转良好。但当问题涉及模型未见过的知识时,检索失败将导致完全错误的输出——而此时开发者才意识到自己的检索管道从一开始就没有真正起作用。
痛点四:评估体系的缺失。 你需要知道:召回率到底是多少?检索到的 chunk 中噪声占比多少?排序是否有效?哪类问题容易出错?这些问题需要系统性的评估框架(如 RAGAS),而不是靠几个 case 的定性观察。
这些痛点将在 §22.3 中进一步展开,我们会讨论 Rerank、查询改写、混合检索、Agentic RAG 等进阶技术。
22.1.8 本节要点总结
本节建立了 RAG 系统的全景认知。核心要点如下:
RAG 的动机:LLM 的知识是静态的、不可控的、不可溯源的。RAG 通过引入外部知识库来弥补这些缺陷,本质上是用"开卷考试"替代"闭卷考试"。
三大核心模块:检索器负责从知识库中找到相关文档(分块→编码→索引→搜索);检索融合负责将检索结果整合到生成过程中;生成器基于增强后的输入产生最终回答。
三种融合策略的权衡:基于查询的融合最简单、可解释性最强,适合黑箱 API;基于 Logits 的融合计算效率最高但整合深度有限;潜在融合整合最深但需要修改模型架构。当前工业实践以基于查询的文本拼接为主流。
混合检索是实用默认选择:BM25 擅长精确关键词匹配,密集检索擅长语义匹配,两者互补使用通常优于单一方法。
从"能跑"到"能用"的鸿沟:分块策略、检索噪声、Rerank、查询改写、评估体系等工程问题,才是决定 RAG 系统实际效果的关键。