17.6 推理时间 Scaling Law
前面几节从工程实现的角度逐一介绍了思维链提示、采样控制、自一致性、自改进等推理时间缩放技术。读者可能已经注意到一个反复出现的主题:在推理阶段投入更多计算资源,可以换取更高质量的输出。 但这种"投入-回报"关系是否存在系统性的规律?是否也像预训练阶段的 Scaling Law 一样,可以用理论框架来预测和优化?
本节将从理论层面回答这些问题。我们将首先建立推理时间缩放的统一框架,然后深入剖析两大类缩放机制——搜索策略(外部扩展)和过程监督(验证器引导),最后讨论强化学习如何从根本上改变推理时间缩放的范式。作为第 17 章的收尾,本节也将总结全章的技术脉络,为下一章"训练推理模型"搭建过渡桥梁。
17.6.1 从训练时缩放到推理时缩放
§17.0 已经介绍了预训练 Scaling Law 的核心公式
基本原理。 大语言模型生成单个 Token 的过程(即一次前向传播)包含的计算量是固定的。对于需要多步逻辑推演的复杂问题,模型无法在单次计算中完成求解。因此,通过生成一系列包含中间推理步骤的 Token——即让模型"展开思考过程"——可以有效提升推理能力。推理时间缩放的核心思想可以用一句话概括:
用推理阶段的算力换取训练阶段的算力。
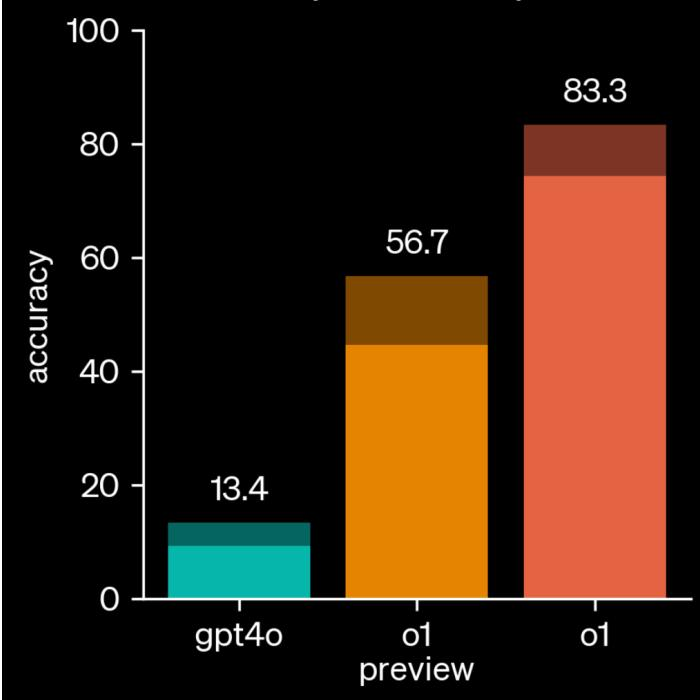
图 17-10:OpenAI o1 系列模型在 AIME 2024 数学竞赛上的表现。GPT-4o 仅 13.4%,o1-preview 提升至 56.7%,o1 达到 83.3%。这种飞跃式进步的核心驱动力正是推理时间缩放。
这一范式转换的标志性事件是 2024 年 9 月 OpenAI o1 的发布。o1 在 AIME 数学竞赛上的准确率从 GPT-4o 的 13.4% 飙升至 83.3%,而它并非简单地使用了更大的模型——关键在于它在推理时消耗了远多于传统模型的计算资源,通过生成超长的内部思维链来逐步解决复杂问题。
2024 年 8 月 Snell 等人在论文 "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters" 中首次系统性地研究了这一现象,提出了一个核心洞见:
在相同总算力预算下,优化推理时计算的分配方式,有时比增大模型参数更有效。
换言之,一个较小但"思考更久"的模型,可能在某些任务上超越一个更大但"只回答一次"的模型。这打破了"更大的模型一定更好"的传统认知,为推理时间缩放提供了理论基础。
17.6.2 推理时间缩放的两大机制
从技术实现的角度看,推理时间缩放主要有两大类机制:
| 机制 | 核心思想 | 代表方法 | 计算增长方式 |
|---|---|---|---|
| 并行搜索 | 生成多个候选,选最优 | Best-of-N、自一致性 | 与采样数 |
| 顺序深化 | 逐步推理,每步引导 | 集束搜索、前瞻搜索、自改进 | 与搜索深度/宽度乘积增长 |
前面几节已经覆盖了"并行搜索"类方法的实现细节。本节重点补充"顺序深化"类方法中尚未介绍的集束搜索和前瞻搜索,它们需要一个关键组件——过程奖励模型(Process Reward Model, PRM)——来引导每一步的搜索方向。
17.6.3 过程奖励模型(PRM)
§17.5 介绍的评分机制(启发式评分和 logprob 评分)有一个共同局限:它们只关注最终回答,无法判断推理过程中每一步是否正确。一个回答可能碰巧给出正确答案但推理过程完全错误,也可能推理严谨但最后一步计算失误。要在搜索过程中精细地引导模型,需要能够逐步评估推理质量的评分机制。
ORM vs PRM。 根据评估粒度的不同,奖励模型分为两类:
- 结果奖励模型(Outcome Reward Model, ORM):只看最终答案是否正确,给出一个整体评分。训练数据只需要 (问题, 回答, 是否正确) 三元组,标注成本低。
- 过程奖励模型(Process Reward Model, PRM):对推理链中的每一步给出评分,标记每步是正确、中性还是错误。训练数据需要逐步标注,成本极高——OpenAI 在 "Let's Verify Step by Step"(2023)论文中为 MATH 数据集的 1.2 万道题标注了 7.5 万个解答的 80 万个步骤的正确性。
PRM 的核心优势在于早期纠错:在搜索过程中,如果某一步被 PRM 判定为错误,后续基于该步的所有探索都可以被剪枝,从而大幅减少无效计算。实验表明,在 Best-of-1860 的极端设置下,PRM 引导的搜索(78.2%)显著超过 ORM(72.4%)和多数投票(69.6%)。
以下是 PRM 评分的基本逻辑(简化实现):
from typing import List, Tuple
def prm_score_solution(
step_scores: List[float],
aggregation: str = "min",
) -> float:
"""
基于过程奖励模型的逐步评分聚合。
参数:
step_scores: PRM 为每一步给出的分数列表(0-1 之间)
aggregation: 聚合方式
- "min": 取最低步骤分(保守策略,一步错即判低分)
- "product": 取所有步骤分的乘积(联合概率)
- "last": 取最后一步的分数
返回:
聚合后的整体评分
"""
if not step_scores:
return 0.0
if aggregation == "min":
return min(step_scores)
elif aggregation == "product":
result = 1.0
for s in step_scores:
result *= s
return result
elif aggregation == "last":
return step_scores[-1]
else:
raise ValueError(f"Unknown aggregation: {aggregation}")
# 示例:一个三步推理的评分
steps = [0.95, 0.88, 0.92] # PRM 为每步给出的分数
print(f"最低分聚合: {prm_score_solution(steps, 'min'):.3f}")
print(f"乘积聚合: {prm_score_solution(steps, 'product'):.3f}")
print(f"末步聚合: {prm_score_solution(steps, 'last'):.3f}")
# 输出:
# 最低分聚合: 0.880
# 乘积聚合: 0.770
# 末步聚合: 0.920在实际应用中,"最低分聚合"最为常用,因为它对推理中的最薄弱环节最为敏感——一条推理链的质量取决于其最差的一步。
17.6.4 搜索策略:Best-of-N、集束搜索与前瞻搜索
有了 PRM 作为逐步评分器,就可以构建比简单的自一致性更精细的搜索策略。下图展示了三种主流搜索方案的对比:
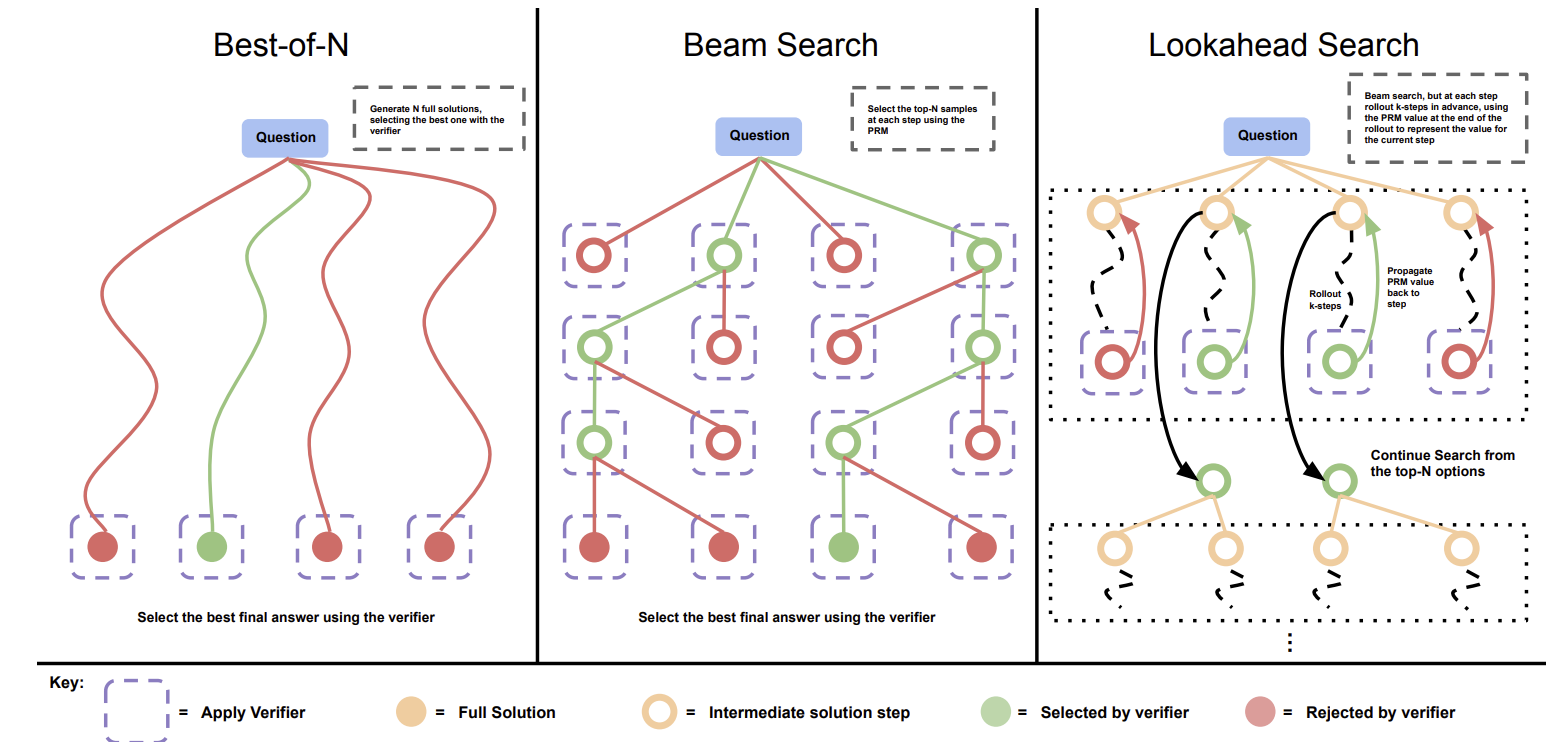
图 17-11:三种搜索策略的工作流程对比。绿色节点表示被验证器选中的步骤,红色节点表示被剪枝的步骤。Best-of-N 生成完整解答后选最优;集束搜索在每一步都保留最优的
Best-of-N(最优解采样)。 这是最简单的搜索策略,§17.5 已有详细介绍。对同一问题独立生成
集束搜索(Beam Search)。 集束搜索在推理的每一步都维持一个包含
- 从问题出发,模型生成
个可能的"第一步"推理 - PRM 对这
个第一步评分,保留得分最高的 个 - 从这
条路径出发,各自再生成 个后续步骤 - 再次评分和筛选,始终保持集束大小为
- 重复直到生成完整解答
集束搜索的优势在于逐步筛选,错误路径在早期就被淘汰,计算资源集中在有希望的方向上。但它也有局限:贪心地选择当前最优步骤可能会错过需要"先退后进"的推理路径——有些步骤在当前看来不够好,但从长远来看会引向正确答案。
前瞻搜索(Lookahead Search)。 前瞻搜索正是为了弥补集束搜索的"近视"问题。其核心思想是通过"预演"未来步骤来评估当前步骤的质量:
- 生成
个候选的"第一步" - 对每个候选,继续向前探索生成
个后续步骤(形成一条短路径) - PRM 评估每条短路径最终状态的质量
- 得分最高的
个最终状态所对应的"第一步"被保留 - 从这些被选中的步骤出发,重复上述过程
前瞻搜索本质上是在做一种有限深度的树搜索,通过"往前多看几步"来做出更好的当前决策。这与棋类 AI 中的蒙特卡洛树搜索(MCTS)有异曲同工之处。
以下代码展示了集束搜索的核心逻辑(简化实现):
from typing import Callable, List
def beam_search_reasoning(
generate_step_fn: Callable,
score_step_fn: Callable,
question: str,
beam_width: int = 3,
branch_factor: int = 5,
max_steps: int = 10,
) -> str:
"""
基于 PRM 的集束搜索推理。
参数:
generate_step_fn: 给定前文,生成下一步推理的函数
score_step_fn: PRM 评分函数,返回 0-1 的分数
question: 原始问题
beam_width: 集束宽度(保留的路径数 M)
branch_factor: 分支因子(每条路径的扩展数 N)
max_steps: 最大推理步数
返回:
最优推理路径的完整文本
"""
# 初始集束:每条路径是 (已生成文本, 累积分数) 的元组
beams: List[tuple] = [("", 0.0)]
for step in range(max_steps):
candidates = []
for text, cum_score in beams:
# 为当前路径生成 branch_factor 个后续步骤
context = question + "\n" + text
next_steps = generate_step_fn(
context, n=branch_factor
)
for ns in next_steps:
new_text = text + ns
step_score = score_step_fn(question, new_text)
candidates.append(
(new_text, cum_score + step_score)
)
# 保留得分最高的 beam_width 条路径
candidates.sort(key=lambda x: x[1], reverse=True)
beams = candidates[:beam_width]
# 检查是否有路径已生成完整答案
for text, score in beams:
if "\\boxed{" in text:
return text
# 返回得分最高的路径
return beams[0][0]三种搜索策略的核心权衡可以总结为:
| 策略 | 搜索粒度 | 计算成本 | PRM 调用次数 | 适用场景 |
|---|---|---|---|---|
| Best-of-N | 完整解答 | 简单问题、快速筛选 | ||
| 集束搜索 | 每步 | 中等复杂度、需要逐步引导 | ||
| 前瞻搜索 | 每步+预演 | 高复杂度、需要远见 |
表 17-9:三种搜索策略对比。
17.6.5 通用奖励模型与推理时扩展
PRM 虽然强大,但存在两个根本限制:一是标注成本极高(需要人工逐步标注正确性),二是只适用于可验证任务(数学、编程等有标准答案的领域)。对于开放式任务(写作、分析、创意等),如何构建有效的评分机制来支持推理时扩展?
奖励模型的分类。 从奖励生成范式和评分模式两个维度,可以将奖励模型归纳为以下分类:
- 标量模型(Scalar):直接输出一个数值评分(如 Bradley-Terry 模型)。确定性输出,对相同输入总是返回同一分数。
- 半标量模型(Semi-Scalar):先生成文本评语,再输出数值评分(如 CLoud)。虽然评语有多样性,但最终评分可能仍高度集中。
- 生成式模型(Generative):完全通过文本评语形式提供反馈,分数从评语中解析(如 LLM-as-a-Judge、Pointwise GRM)。每次采样可产生不同的评价视角。
关键洞察:推理时扩展能力依赖于输出多样性。 标量奖励模型是确定性的——对相同输入多次推理只会产生相同的分数——因此无法通过增加采样次数来提升性能。而生成式奖励模型的输出基于概率分布采样,多次推理可以产生多样化的评语和判断依据。通过聚合这些多样化输出(投票或加权平均),可以获得更鲁棒的最终评估。
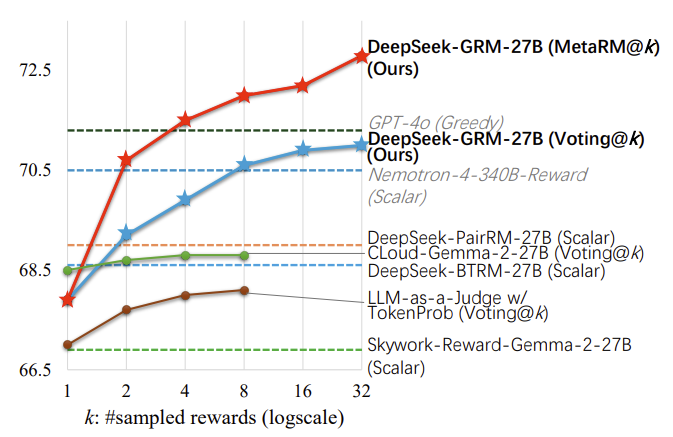
图 17-12:不同奖励模型在增加采样次数(
上图清晰地展示了这一规律:DeepSeek-GRM 在
17.6.6 强化学习驱动的推理时缩放
前面介绍的搜索策略和 PRM 都是在推理阶段"外部"施加的机制——模型本身并不知道自己在被搜索或评分。一个自然的问题是:能否让模型在训练阶段就学会"自主地"进行推理时缩放?
DeepSeek-R1-Zero 的启示。 DeepSeek 团队通过一个极简的实验回答了这个问题:在基座模型 DeepSeek-V3-Base 上,不进行任何 SFT、不使用 PRM、不引入搜索算法,仅通过 GRPO(Group Relative Policy Optimization)强化学习和基于规则的奖励(答案正确与否),模型就自发地学会了延长思考时间来解决复杂问题。
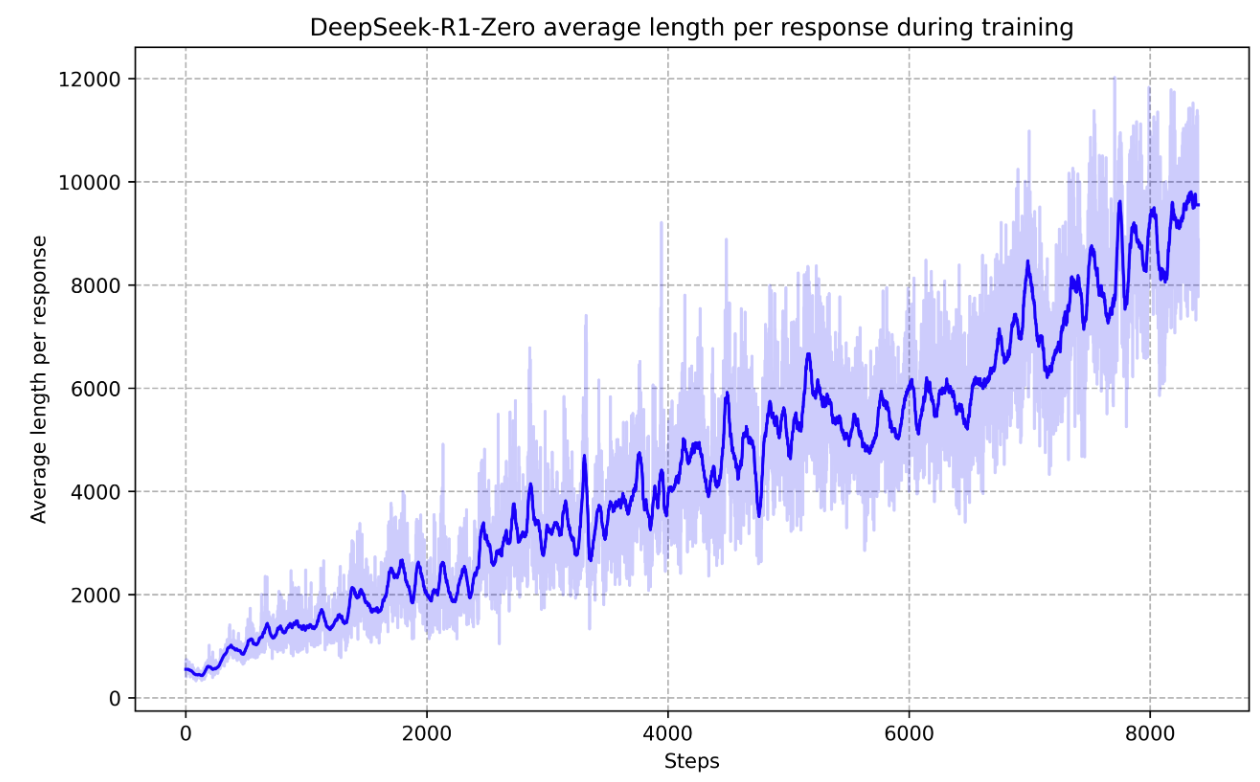
图 17-13:DeepSeek-R1-Zero 训练过程中每条响应的平均 Token 数。随着 RL 训练步数增加,模型自发地生成越来越长的推理链(从约 500 Token 增长到近 10000 Token),这种"深度思考"能力并非人工设计,而是从奖励信号中涌现出来的。
这一发现的深刻之处在于:推理时间缩放不一定需要外部搜索机制,模型可以通过 RL 训练内化这种能力。 具体来说,GRPO 的工作流程如下:
- 对每个问题,让当前策略采样一组候选回答
- 用规则验证每个回答的正确性作为奖励
- 通过组内比较计算每个回答的相对优势(无需价值模型)
- 用优势估计直接优化策略
在这个过程中,模型发现"生成更多推理步骤"能提高答对概率,从而获得更多奖励。于是它自发地学会了在面对困难问题时"思考更久"——本质上是将推理时间缩放从外部机制内化为了模型自身的行为策略。
从外部搜索到内部推理的范式转变。 这一发现标志着推理时间缩放的一次重要范式转变。用一张表来对比:
| 维度 | 外部搜索范式 | 内部推理范式 |
|---|---|---|
| 推理时扩展的来源 | 多次采样 + 验证器 | 模型自主生成长推理链 |
| 需要的额外组件 | PRM / ORM / 评分函数 | 无(奖励规则仅用于训练) |
| 推理时计算控制 | 显式(设定 | 隐式(模型自行决定思考多久) |
| 训练成本 | 需要训练 PRM + 策略模型 | 仅需 RL 训练策略模型 |
| 代表系统 | AlphaGo(MCTS + 价值网络) | OpenAI o1、DeepSeek-R1 |
表 17-10:外部搜索范式与内部推理范式的对比。
当然,两种范式并非互斥。实际的推理模型系统往往同时使用:先通过 RL 训练让模型具备内在的深度推理能力,再在推理时叠加外部搜索(如 Best-of-N 或自一致性投票)进一步提升可靠性。
17.6.7 推理时间缩放的计算经济学
理解了技术机制之后,一个关键的工程问题浮现出来:给定固定的算力预算,应该分配多少给模型训练、多少给推理时缩放? 这正是 Snell 等人论文的核心贡献。
计算分配的权衡。 假设总算力预算为
第 17 章前几节的实验数据直观地展示了这种权衡。在 MATH-500 基准上使用 0.6B 参数的基座模型:
| 方法 | 推理时算力倍率 | 准确率 |
|---|---|---|
| Baseline(贪心解码) | 1x | 15.2% |
| CoT 提示 | ~5x | 40.6% |
| 自一致性( | ~50x | 52.0% |
| 自一致性( | ~15x | 55.2% |
表 17-11:不同推理时间缩放策略的算力-准确率权衡。推理时算力倍率为相对于单次贪心解码的近似倍数。
一个值得注意的现象:0.6B 基座模型配合 10 次自一致性采样和 CoT(52.0%),其效果已经非常接近 0.6B 推理模型的 3 次自一致性(55.2%)。前者的模型更小(未经 SFT),但通过大量推理时计算弥补了差距。这正是"推理时间缩放可以部分替代模型参数缩放"这一论断的实证支撑。
最优分配取决于问题难度。 研究发现,推理时间缩放的收益高度依赖于问题难度:
- 简单问题:模型"一次就答对"的概率很高,额外的推理时计算几乎没有收益。此时应优先选择更大的模型而非更多的搜索。
- 中等难度问题:模型有一定概率答对,通过多次采样和搜索可以显著提升准确率。这是推理时间缩放收益最大的区间。
- 极难问题:超出模型能力范围,无论搜索多少次都无法找到正确答案。此时推理时计算完全浪费,应投入更大模型或更好的训练数据。
这意味着没有一个固定的最优计算分配比例——它必须根据任务的难度分布动态调整。实际系统中,可以先用少量采样估计问题难度,然后自适应地决定是否需要更多推理时计算。
17.6.8 智能体中的推理时间缩放
推理时间缩放的应用不局限于单次问答。当推理模型被嵌入智能体(Agent) 框架时,推理时间缩放的效应进一步放大。
Test-Time Diffusion Deep Researcher(TTD-DR)。 Google 提出的这一框架将推理时缩放应用于深度研究任务。智能体接收用户查询后,先生成一份初步草稿,然后进入迭代循环:在每个步骤中检索新的高质量信息来优化和重写草稿,同时持续优化从研究规划到报告生成的整个流程。这是"自改进"思想在智能体层面的自然延伸。
多智能体集成(TUMIX)。 Tool-Use Mixture 框架则将推理时缩放推向"群体智慧"方向:并行运行多个智能体,每个采用不同的工具使用策略和解题路径。所有智能体在多轮迭代中分享和精炼各自的回答,最终通过 LLM-as-Judge 判断是否停止迭代。这实质上是自一致性在智能体层面的推广——不再是同一模型的多次采样,而是不同策略的多路径探索。
这些扩展方向表明,推理时间缩放已经从一个单纯的推理技巧,演变为一种通用的计算范式:在任何需要高质量输出的场景中,都可以通过在推理阶段投入更多计算来换取更好的结果。
17.6.9 第 17 章总结
至此,我们完成了对推理时间缩放(Inference-Time Scaling)全部核心技术的系统梳理。回顾全章的技术脉络:
| 节 | 主题 | 核心方法 | 算力消耗 | 需要额外组件 |
|---|---|---|---|---|
| §17.1 | Prompt 工程 | 少样本/零样本提示 | 1x | 无 |
| §17.2 | 思维链 | CoT/Zero-shot CoT | ~3-10x | 无 |
| §17.3 | 采样控制 | 温度/Top-p/Top-k | 1x | 无 |
| §17.4 | 自一致性 | 多次采样 + 投票 | 无 | |
| §17.5 | 自改进 | 批评-修正循环/Best-of-N | 评分函数 | |
| §17.6 | Scaling Law | 搜索策略/PRM/RL | PRM/奖励模型 |
表 17-12:第 17 章技术脉络总结。
这些技术呈现出清晰的递进关系:
- 零成本优化(§17.1-17.3):通过更好的提示设计和采样策略,在不增加推理调用次数的前提下提升输出质量。
- 并行扩展(§17.4-17.5):通过多次采样获得多条候选路径,利用投票或评分选出最优,计算成本与采样数线性增长。
- 引导搜索(§17.6):引入过程监督和搜索算法,在推理的每一步进行精细引导,以更高的计算成本换取更大的质量提升。
- 内化推理(§17.6 后半部分,衔接 §18 章):通过强化学习让模型内化推理能力,无需外部搜索组件即可自主进行深度推理。
从预训练 Scaling Law 到推理时间 Scaling Law,大模型领域经历了一次根本性的范式转变:模型的智能不再仅仅取决于"它有多大",还取决于"它在推理时思考了多久"。 这一洞见打开了一个全新的扩展维度,也为下一章——如何通过强化学习训练出真正的推理模型——奠定了坚实的理论基础。