24.3 生成式推荐系统
推荐系统是互联网最核心的基础设施之一——打开抖音刷到的短视频、淘宝首页的"猜你喜欢"、Spotify 自动生成的每周歌单,背后都是推荐系统在运作。传统推荐系统经过十余年的发展,已经形成了一套成熟的"召回-排序"范式。然而,随着大语言模型(LLM)展现出强大的序列建模与生成能力,一个自然的问题浮出水面:能否用生成模型统一推荐系统的全部流程? 2024 年,Meta 发表的"Actions Speak Louder than Words"论文给出了肯定的答案——1.5 万亿参数的生成式推荐模型(Generative Recommenders, GR)不仅在 A/B 测试中取得了 12.4% 的性能提升,还已部署到服务数十亿用户的生产环境。
本节将从传统推荐系统的基本架构出发,沿着"红利期-瓶颈期-新范式"的演进脉络,深入讲解生成式推荐系统的核心思想、关键架构与工程挑战。
一、传统推荐系统:召回与排序
一个典型的推荐系统需要从数以亿计的物品库中,在毫秒级时间内挑选出用户最可能感兴趣的十余个物品。如此巨大的筛选比率决定了系统无法用同一个复杂模型处理所有候选,因此工业界普遍采用漏斗式多阶段架构。
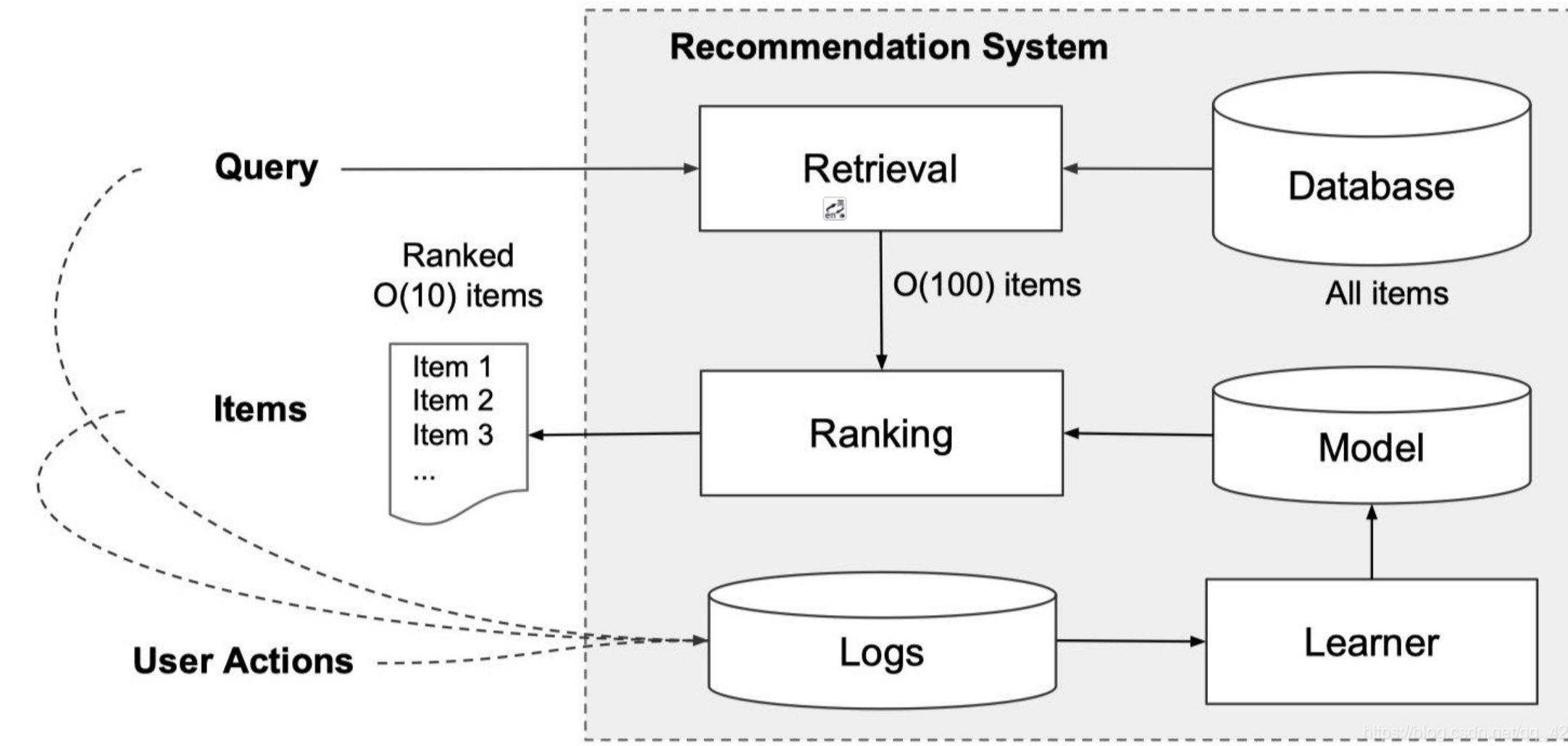
图 24-5:传统推荐系统的召回-排序架构。Query 输入后,Retrieval 模块从全量 Database 中检索约 O(100) 个候选物品,Ranking 模块对其精排后返回约 O(10) 个最终推荐结果。用户行为(User Actions)被记录到日志中,供 Learner 更新模型。
在工业实践中,这个漏斗通常被细分为四个阶段:
| 阶段 | 任务 | 典型规模 | 核心要求 |
|---|---|---|---|
| 召回(Retrieval) | 从海量物品中快速找回一批候选 | 亿级 → 千级 | 速度快、覆盖广 |
| 粗排(Pre-ranking) | 粗略排序,在保证精度的前提下削减候选量 | 千级 → 百级 | 轻量高效 |
| 精排(Ranking) | 融入丰富特征,精准地个性化排序 | 百级 → 十级 | 精度高 |
| 重排(Re-ranking) | 考虑多样性、新鲜度等业务约束,改善用户体验 | 十级 → 最终展示 | 业务适配 |
每个阶段使用不同复杂度的模型:召回阶段通常采用双塔(Two-Tower)模型或 ANN 检索,追求高吞吐低延迟;精排阶段则可以使用更复杂的特征交叉网络,追求预测精度。这种分阶段设计虽然工程上高效,但也带来了信息割裂的问题——每个阶段独立优化各自的目标函数,全局最优并不等于局部最优之和。
二、深度学习推荐的红利期(2016-2021)
2016 年是推荐系统的一个分水岭。Google 发表了 Wide & Deep 模型,首次将深度学习系统性地引入推荐系统的 CTR(Click-Through Rate,点击率)预测任务,极大改变了推荐系统的技术路线。
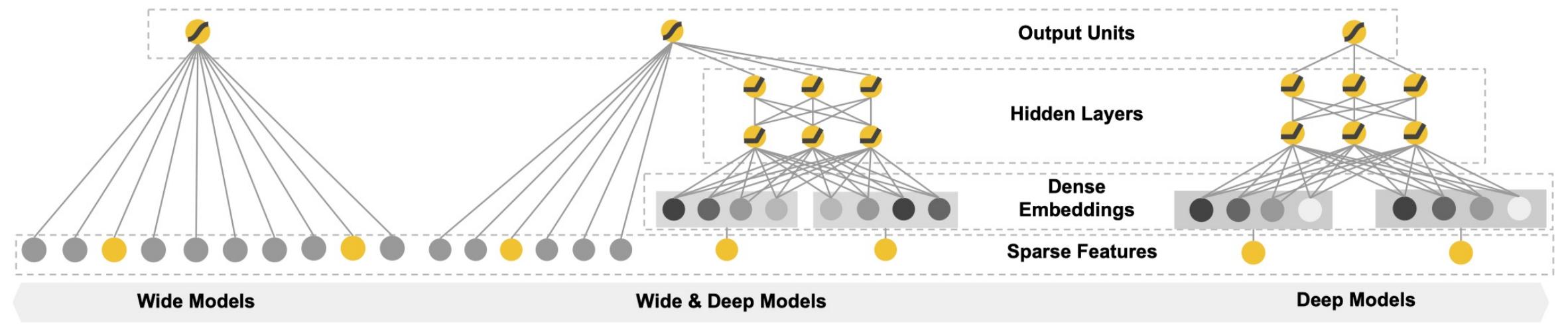
图 24-6:Wide & Deep 模型结构。Wide Models 通过线性变换直接处理稀疏特征的交叉组合,提供"记忆能力"(Memorization);Deep Models 通过多层神经网络学习特征的低维稠密表示,提供"泛化能力"(Generalization);Wide & Deep Models 将两者联合训练。
Wide & Deep 的核心思想简洁而深刻:
- Wide 部分:本质上是广义线性模型,直接对特征交叉进行记忆。例如,"用户 A 曾点击商品 B"这种精确的历史共现关系,Wide 部分可以直接学到。这赋予模型记忆能力(Memorization)。
- Deep 部分:将高维稀疏特征通过 Embedding 层映射为低维稠密向量,再经过多层全连接网络学习高阶特征交互。即使某个用户-物品组合从未出现过,模型也能通过向量空间的近邻关系进行预测。这赋予模型泛化能力(Generalization)。
两部分通过联合训练,输出层共享 Sigmoid 激活函数,实现了记忆与泛化的统一。
在 Wide & Deep 的基础上,2019 年 Meta 进一步总结工业界推荐模型的设计经验,提出了 DLRM(Deep Learning Recommendation Model) 架构。DLRM 将推荐模型的通用结构高度概括,明确区分了稠密特征(Dense Features)和稀疏特征(Sparse Features)的处理路径:
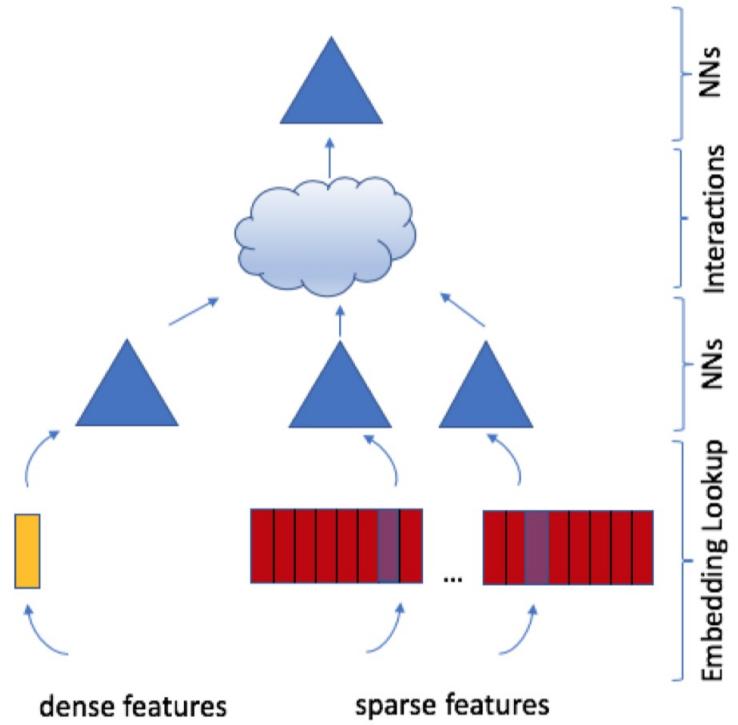
图 24-7:DLRM 模型架构。稠密特征(左侧)通过底层 MLP 处理;稀疏特征(右侧)通过 Embedding Lookup 转换为稠密向量;两类特征在 Interactions 层进行交互(如点积),最终经过顶层 MLP 输出预测结果。
DLRM 架构清晰地划分了推荐模型的计算瓶颈:
- Embedding 层:将数十亿级别的稀疏 ID 特征(用户 ID、物品 ID、类别 ID 等)映射为稠密向量。这部分参数量巨大(常达 TB 级),且访问模式为随机查表,是内存密集型计算。
- MLP 层:对稠密特征和交互特征进行多层变换。这部分是计算密集型操作。
- 特征交互层:通过点积等操作捕捉不同特征之间的关系。
这种架构很快成为工业界推荐系统的标准范式。从 2016 到 2021 年,深度学习推荐模型的参数规模从 Youtube(2016)的约 10 亿量级,增长到 Meta DLRM(2021)的超千亿量级,增长了 3 个数量级以上。
三、瓶颈期:DLRM 的 Scaling 困境(2021-2023)
参数量的增长带来了双重挑战:工程上的部署压力和效果上的收益递减。
工程挑战:TB 级模型的分布式推理。 Meta 的 DLRM 模型规模突破 TB 级别后,单机已无法容纳全部 Embedding 参数,占用了数据中心约 79% 的计算资源。在线推理面临巨大的 QPS 和时延压力,急需横向扩展的分布式推理架构。Meta 提出了 Scale-Out DLRM 方案,核心思路是将庞大的 Embedding 表分片(Shard)到多台服务器上,通过异步 RPC 调用远程分片完成 Embedding 查找,再将结果汇集到主节点完成后续计算。
效果瓶颈:Scaling Law 的饱和。 更根本的问题在于,在 DLRM 架构下,模型参数量的 Scaling 已经逼近极限。Meta 在 2023 年发表的"Understanding Scaling Laws for Recommendation Models"系统性地研究了推荐模型中参数量
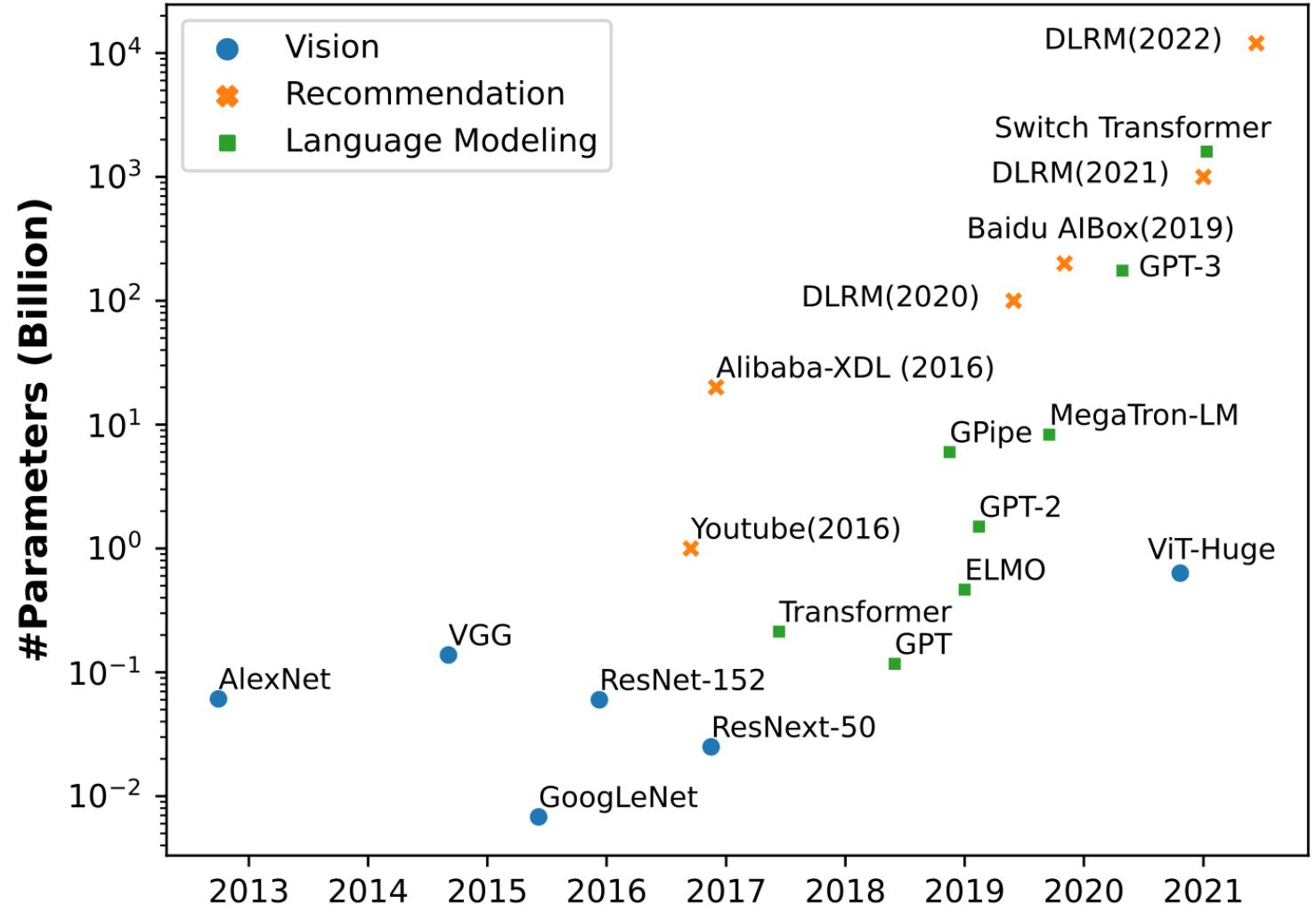
图 24-8:2013-2022 年间不同领域模型参数规模的增长趋势。推荐模型(橙色)的参数规模增长速度远超视觉(蓝色)和语言模型(绿色),从 2016 年 Youtube 的约 10 亿参数增长到 2022 年 DLRM 的约 10 万亿参数,增幅达 4 个数量级。
研究表明,推荐模型的性能与缩放维度之间遵循幂律函数关系,但不同维度的缩放效率差异显著:
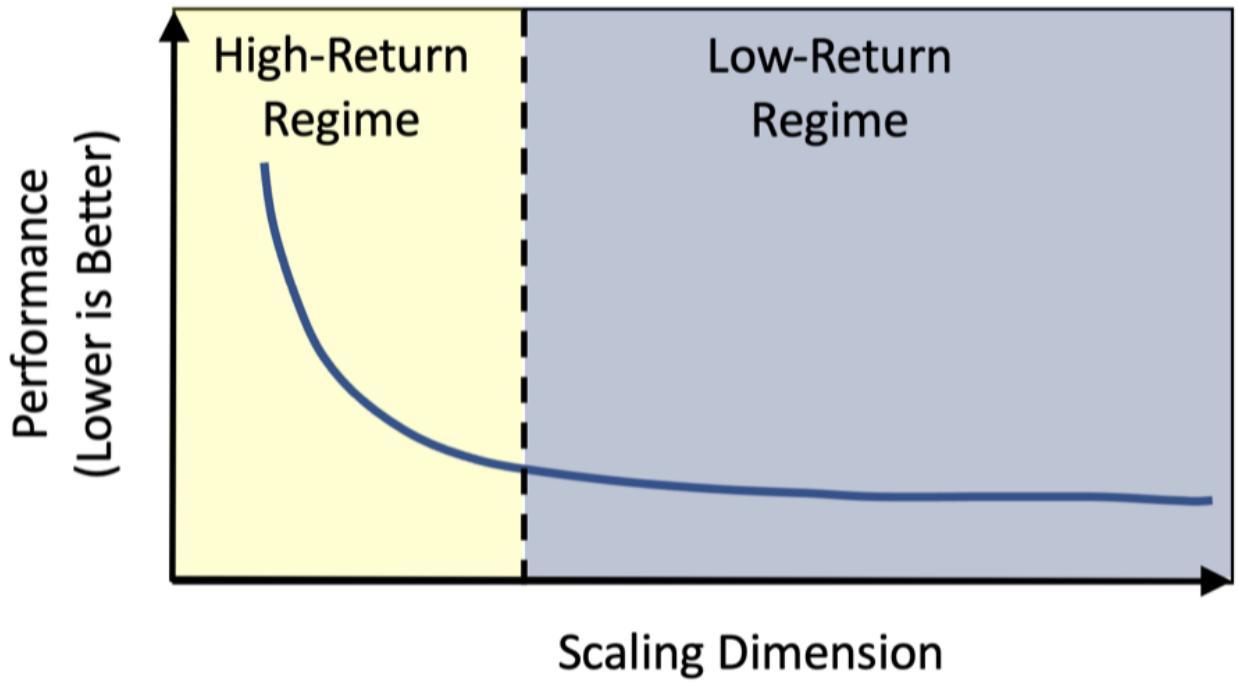
图 24-9:推荐模型 Scaling Law 的幂律函数特征。横轴为缩放维度(如参数量、数据量),纵轴为性能(越低越好)。在 High-Return 区间,缩放带来显著收益;进入 Low-Return 区间后,继续扩大规模的边际收益急剧下降。
关键发现可以总结如下:
- 参数量
的缩放已经饱和:在 DLRM 架构下继续增加参数量(主要是 Embedding 表),效果提升的边际收益极小。这是因为 DLRM 的 Embedding + MLP 架构的表达能力存在天花板,更多的参数并不能带来更好的特征交互建模。 - 数据量
仍有提升空间:训练数据量的缩放虽然效率不高( ),但尚未达到饱和点,仍可带来小幅稳定的提升。 - 架构创新(
参数效果提升)是长期出路:增加数据只能获得 级别的渐进提升,而架构本身的创新能够带来 级别的阶跃式提升。
换言之,DLRM 范式已经走到了 Scaling 的尽头——不是推荐系统不能继续 Scale,而是需要一种全新的架构来重新打开 Scaling 的空间。这正是生成式推荐系统(Generative Recommenders)诞生的背景。
四、新范式:用 Transformer 做推荐
大语言模型的成功给推荐系统带来了启发。从本质上看,用 Transformer 做推荐有两个天然的契合点:
- 长序列支持:LLM 已经能够处理数百万 token 的上下文窗口,而推荐系统中用户的行为序列通常也很长(数千到数万个交互事件),两者在序列长度的量级上具有可比性。
- 有序生成:LLM 通过自回归方式逐步生成下一个 token,而推荐本质上也是在预测"用户接下来最可能与之交互的物品"。Next-token prediction 天然对应 next-item prediction。
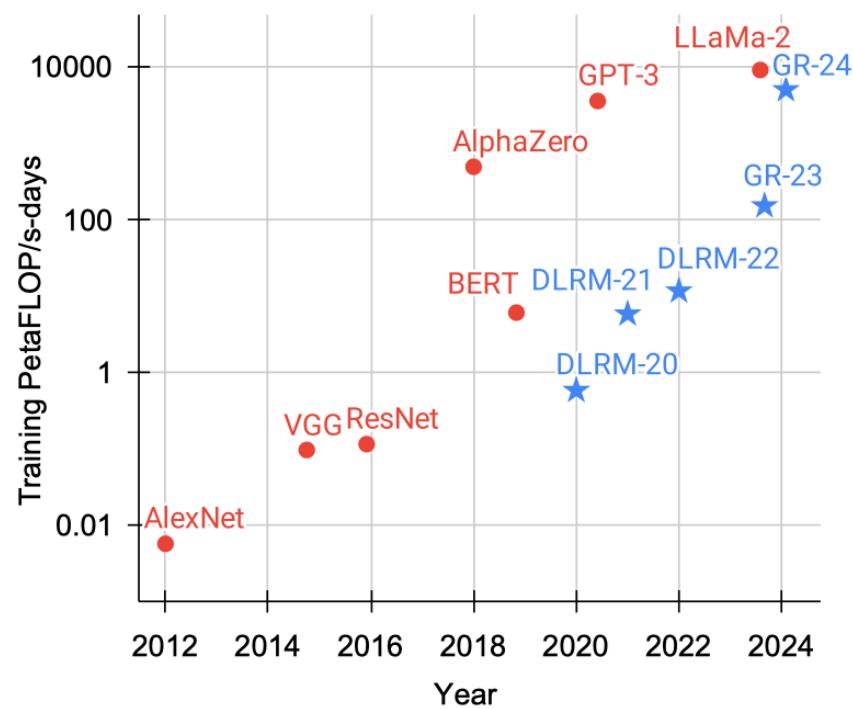
图 24-10:各类 AI 模型训练算力(PetaFLOP/s-days)的演进趋势。红色圆点为经典模型(AlexNet、BERT、GPT-3、LLaMA-2 等),蓝色星标为推荐模型(DLRM-20/21/22 和 GR-23/24)。生成式推荐模型 GR-24 的训练算力已达到与 LLaMA-2 同等量级。
然而,直接将 Transformer 架构搬到推荐场景存在三个重大挑战:
- 特征缺乏显式结构性:语言模型处理的 token 来自固定词表,语义相对明确。而推荐系统面对的是海量异构特征——高基数 ID 特征(数十亿用户 ID、物品 ID)、交叉特征、连续数值特征、类别特征等,缺乏统一的表示结构。
- 十亿级别动态词表:语言模型的词表通常为 100K 量级且固定不变,而推荐系统的"词表"(即物品集合)达到十亿规模,且实时动态变化——新物品不断上架、旧物品下架或过期。
- 计算开销巨大:大规模推荐系统的吞吐和访问量远超语言模型应用场景,交互行为数据的规模也远超语料库。Transformer 的
注意力机制在如此规模下显得尤为昂贵。
五、生成式推荐模型:Actions Speak Louder than Words
Meta 在 2024 年发表的论文"Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations"(Zhai et al., 2024)提出了生成式推荐系统(Generative Recommenders, GR) 的新范式,系统性地解决了上述挑战。其核心思想是:将推荐系统的召回和排序统一转化为序列直推式(Sequential Transducer)生成任务。
(1)从 DLRM 到 GR:特征的序列化统一
传统 DLRM 将每次推荐请求视为一个独立的样本,对用户特征和物品特征分别处理后交互打分。而 GR 的关键创新在于将所有信息——用户的历史行为、物品特征、上下文特征——统一编码为一条时间有序的序列,然后用 Transformer 进行自回归建模。
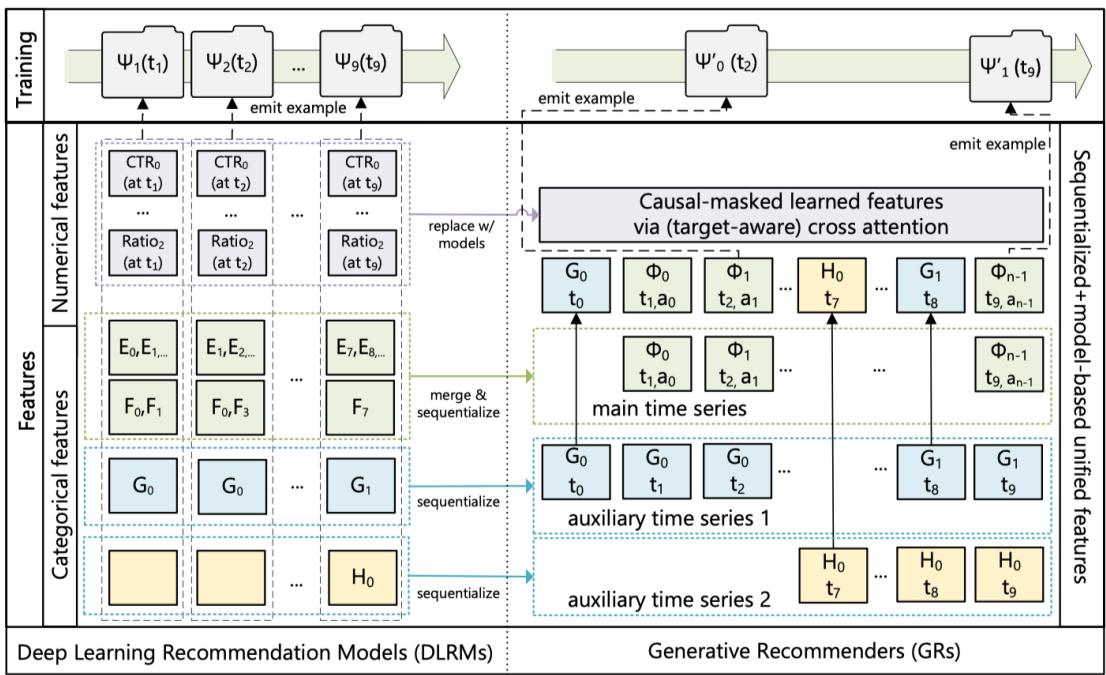
图 24-11:DLRM(左)与生成式推荐 GR(右)的架构对比。DLRM 按特征类型(数值特征、类别特征等)分别处理,每个时间步独立打分。GR 将所有特征合并并序列化(merge & sequentialize),形成包含主时间序列和辅助时间序列的统一序列表示,通过因果掩码交叉注意力(Causal-masked learned features via target-aware cross attention)进行端到端建模。
具体而言,GR 将特征处理从"按类型分别处理"转变为"按时间顺序统一排列":
- 数值特征(如 CTR、各种比率指标):在传统 DLRM 中每个时间步独立输入;在 GR 中被替换为模型自身通过因果掩码交叉注意力学习到的表示。
- 类别特征(如 Embedding ID):在 DLRM 中各自通过独立的 Embedding 表查询;在 GR 中被合并后按时间顺序排列为主时间序列(main time series)。
- 全局类别特征(如用户画像标签):被序列化为辅助时间序列(auxiliary time series),在每个时间步重复注入。
这种统一的序列化表示使得模型能够通过注意力机制自动学习任意特征之间的交互关系,而无需像 DLRM 那样手工设计特征交叉方式。
(2)HSTU Encoder:专为推荐设计的 Transformer 变体
直接使用标准 Transformer 做推荐面临效率问题——Softmax Attention 的计算复杂度为
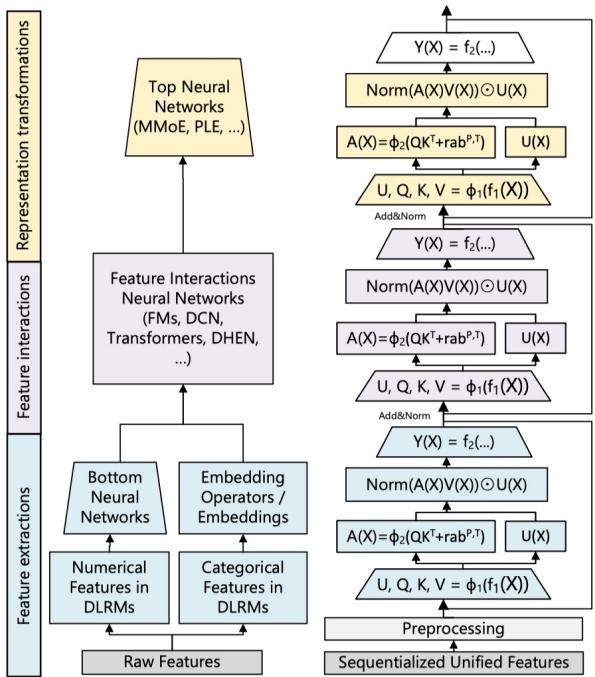
图 24-12:传统 DLRM(左)与 HSTU Encoder(右)的详细架构对比。左侧 DLRM 包含特征提取层(Bottom Neural Networks + Embedding)、特征交互层(FMs, DCN, Transformers 等)和表示转换层(Top Neural Networks 如 MMoE, PLE)。右侧 HSTU 将所有原始特征统一预处理为序列化特征后,经过多个相同结构的 Attention 层堆叠,每层使用 Pointwise Attention 代替 Softmax Attention。
HSTU 的核心设计包括:
- Pointwise Attention 代替 Softmax Attention:标准 Transformer 的注意力计算为
,其中 Softmax 对注意力权重进行归一化。HSTU 采用 Pointwise Attention,其计算形式为 ,其中 是逐元素的激活函数, 是相对位置偏置项。去掉 Softmax 归一化带来两个好处:一是降低了计算开销,二是更适合动态变化的词表——Softmax 的概率归一化隐含了"所有候选项互斥竞争"的假设,而推荐场景中候选集是动态变化的。 - 层归一化与残差连接:每个 HSTU 层的输出为
,通过 Add&Norm 机制保证深层网络的训练稳定性。 - 多层堆叠:与 DLRM 的固定三层架构(特征提取→特征交互→表示转换)不同,HSTU 通过统一结构的多层堆叠实现逐步深入的特征交互,层数可以自由扩展,从而打开了 Scaling 的空间。
(3)性能优化:从实验室到生产环境
万亿参数级别的生成式推荐模型要在在线服务中保持毫秒级响应,需要一系列工程优化:
- 流式训练采样(Streaming Training):推荐数据是连续到达的用户行为流。GR 采用流式训练管道,每个训练样本对应用户在某个时间点的行为快照,训练数据按时间顺序流入。
- 序列随机长度(Stochastic Sequence Length):每个训练样本的序列长度不固定,而是从用户实际行为长度中随机截取。这既避免了填充(Padding)带来的计算浪费,也增强了模型对不同长度序列的鲁棒性。
- 推理小 Batch 并行加速(M-Falcon 算法):在线推理时,推荐请求的 Batch Size 通常远小于语言模型的场景。M-Falcon 算法专门针对小 Batch 推理进行优化,通过算子融合和内存访问优化实现高效的并行推理。
六、代码示例:Pointwise Attention 的简化实现
为了帮助理解 HSTU 中 Pointwise Attention 与标准 Softmax Attention 的区别,下面给出一个简化的 PyTorch 对比实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SoftmaxAttention(nn.Module):
"""标准 Softmax Attention(用于对比)"""
def __init__(self, d_model: int, n_heads: int):
super().__init__()
self.n_heads = n_heads
self.d_k = d_model // n_heads
self.W_qkv = nn.Linear(d_model, 3 * d_model)
self.W_out = nn.Linear(d_model, d_model)
def forward(self, x: torch.Tensor, mask: torch.Tensor = None):
B, L, D = x.shape
qkv = self.W_qkv(x).reshape(B, L, 3, self.n_heads, self.d_k)
q, k, v = qkv.unbind(dim=2) # 各为 (B, L, n_heads, d_k)
q, k, v = [t.transpose(1, 2) for t in (q, k, v)] # (B, n_heads, L, d_k)
# Softmax 归一化的注意力权重
scores = torch.matmul(q, k.transpose(-2, -1)) / (self.d_k ** 0.5)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attn = F.softmax(scores, dim=-1)
out = torch.matmul(attn, v) # (B, n_heads, L, d_k)
out = out.transpose(1, 2).reshape(B, L, D)
return self.W_out(out)
class PointwiseAttention(nn.Module):
"""HSTU 风格的 Pointwise Attention(简化版)"""
def __init__(self, d_model: int, n_heads: int):
super().__init__()
self.n_heads = n_heads
self.d_k = d_model // n_heads
self.W_qkvu = nn.Linear(d_model, 4 * d_model) # Q, K, V, U 四路投影
self.W_out = nn.Linear(d_model, d_model)
self.norm = nn.LayerNorm(d_model)
# 可学习的相对位置偏置
self.rel_pos_bias = nn.Parameter(torch.zeros(1, n_heads, 1, 1))
def forward(self, x: torch.Tensor, mask: torch.Tensor = None):
B, L, D = x.shape
qkvu = self.W_qkvu(x).reshape(B, L, 4, self.n_heads, self.d_k)
q, k, v, u = qkvu.unbind(dim=2)
q, k, v, u = [t.transpose(1, 2) for t in (q, k, v, u)] # (B, H, L, d_k)
# Pointwise: 用 ReLU 代替 Softmax,不做归一化
scores = torch.matmul(q, k.transpose(-2, -1)) + self.rel_pos_bias
if mask is not None:
scores = scores.masked_fill(mask == 0, 0.0)
attn = F.relu(scores) # 逐元素激活,不做行级归一化
# A(X) * V(X) 后与 U(X) 做逐元素乘法(门控机制)
av = torch.matmul(attn, v) # (B, H, L, d_k)
av_normed = self.norm(av.transpose(1, 2).reshape(B, L, D))
u_flat = u.transpose(1, 2).reshape(B, L, D)
out = av_normed * u_flat # 逐元素门控
return self.W_out(out)
# 使用示例
d_model, n_heads, seq_len, batch = 128, 8, 256, 4
x = torch.randn(batch, seq_len, d_model)
causal_mask = torch.tril(torch.ones(seq_len, seq_len)).unsqueeze(0).unsqueeze(0)
softmax_attn = SoftmaxAttention(d_model, n_heads)
pointwise_attn = PointwiseAttention(d_model, n_heads)
out_softmax = softmax_attn(x, causal_mask)
out_pointwise = pointwise_attn(x, causal_mask)
print(f"Softmax Attention 输出: {out_softmax.shape}") # (4, 256, 128)
print(f"Pointwise Attention 输出: {out_pointwise.shape}") # (4, 256, 128)核心区别在于第 42-43 行:Pointwise Attention 使用 ReLU 作为逐元素激活函数,不进行 Softmax 那样的行级归一化。此外,第 46 行引入了额外的投影
七、推荐系统的演进全景
回顾推荐系统从传统方法到生成式范式的完整演进历程,可以清晰地看到技术发展的内在逻辑:
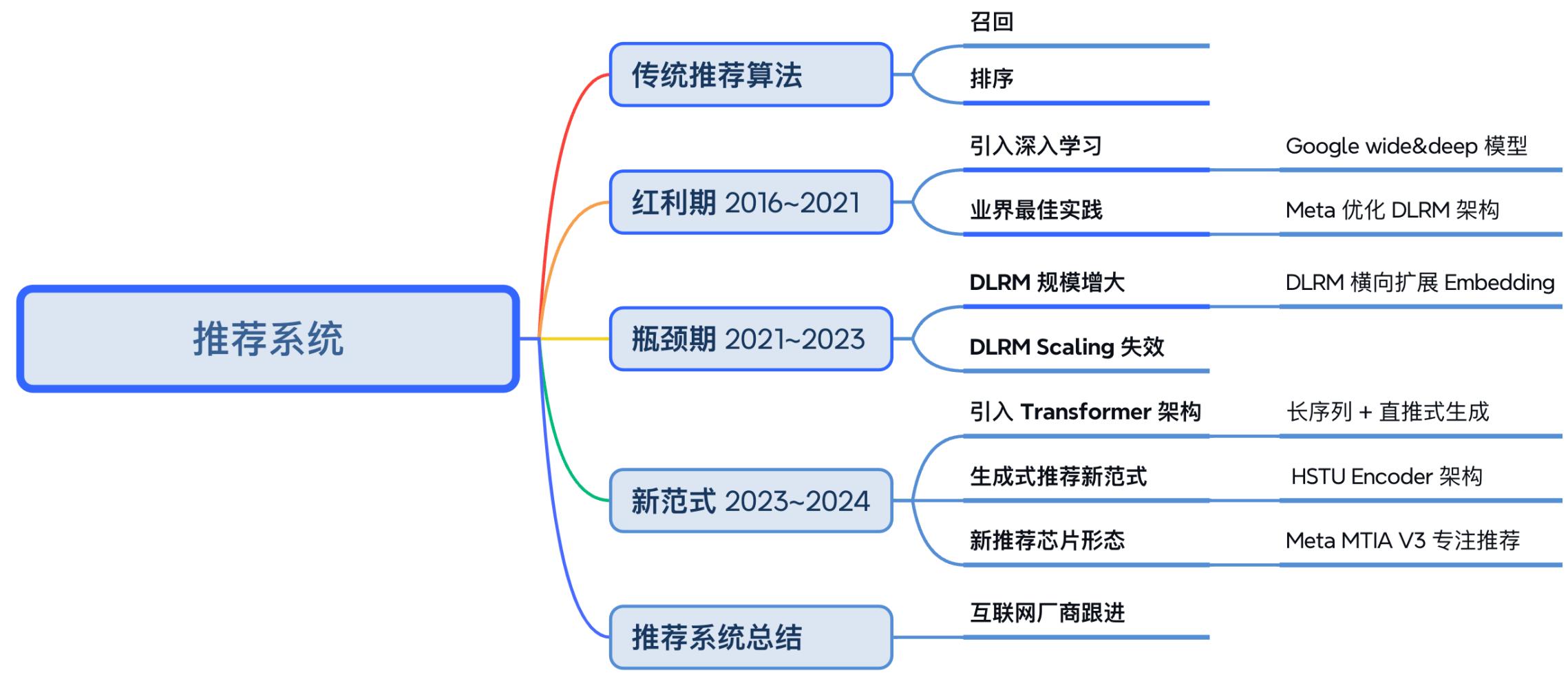
图 24-13:推荐系统技术演进的全景路线图。传统推荐算法基于召回+排序的分阶段范式;红利期(2016-2021)引入深度学习,Google Wide&Deep 和 Meta DLRM 成为标杆;瓶颈期(2021-2023)DLRM 规模增大但 Scaling 失效;新范式(2023-2024)引入 Transformer 架构,以 HSTU Encoder 为核心的生成式推荐和 Meta MTIA V3 专用芯片开启下一轮增长。
这条演进路线揭示了一个有趣的规律:推荐系统正在走大语言模型曾经走过的路。LLM 从早期的 RNN/LSTM 发展到 Transformer,再通过 Scaling Law 驱动参数量从十亿跃升到万亿级别。推荐系统同样经历了从传统机器学习到深度学习(Wide & Deep, DLRM),再到 Transformer 化(HSTU)的过程。两者的 Scaling Law 特征也高度相似——在旧架构下遇到瓶颈后,通过架构创新重新打开增长空间。
从工业实践的角度来看,随着 LLM 训练基础设施的成熟和训练技巧的积累,互联网头部厂商正在将这些能力迁移到推荐场景。生成式推荐有望成为继大语言模型训练之后,算力消耗的下一个主力方向。Meta 已经专门设计了 MTIA V3 芯片来加速推荐模型推理,这从硬件层面进一步印证了生成式推荐的战略地位。
本节小结
本节从传统推荐系统的召回-排序范式出发,沿着推荐技术的演进脉络,深入讲解了生成式推荐系统的核心思想与关键架构。几个重要的要点值得回顾:
- 传统范式的局限:多阶段漏斗式架构虽然工程高效,但各阶段独立优化导致全局次优,且 DLRM 架构下参数量的 Scaling 已逼近饱和。
- 生成式建模的核心转变:将推荐从"按特征类型分别处理再交叉打分"转变为"将所有特征序列化后端到端自回归生成",用 Next-item prediction 统一召回与排序。
- HSTU 的架构创新:Pointwise Attention 取代 Softmax Attention,去掉归一化约束,配合门控机制和多层堆叠,重新打开了推荐模型的 Scaling 空间。
- 工业级验证:Meta 的 1.5 万亿参数 GR 模型已在生产环境部署,A/B 测试取得 12.4% 的性能提升,证明了生成式推荐从理论到实践的可行性。
生成式推荐系统的出现标志着推荐领域正式进入"大模型时代"。正如大语言模型用统一的 Next-token prediction 范式取代了 NLP 中繁多的子任务模型,生成式推荐系统也有望用统一的序列生成范式取代推荐系统中的多阶段流水线,实现 End-to-End 的全局优化。