24.4 AI 安全与隐私
大模型正在以前所未有的速度渗透到医疗诊断、金融风控、自动驾驶等关键领域。然而,模型越强大,它所接触和处理的数据就越敏感——用户的聊天记录、健康数据、地理位置、财务信息,无一不是高价值的隐私资产。一个核心矛盾由此产生:AI 需要大量数据才能变得更智能,但数据的集中收集和处理恰恰构成了最大的隐私风险。 如何在保护用户隐私的前提下释放数据的价值,是大模型时代必须解决的系统级工程问题。
本节将围绕隐私计算(Privacy-Preserving Computation)这一核心概念展开,首先建立数据生命周期的安全分析框架,然后逐一讲解同态加密、可信执行环境、安全多方计算、联邦学习和差分隐私五大核心技术,最后以 Apple Intelligence 的端云协同架构为案例,展示这些技术如何在真实产品中落地。
一、数据生命周期与隐私威胁模型
要系统性地理解隐私保护,首先需要明确数据在整个生命周期中面临的风险。在大模型场景下,一次典型的推理请求可能涉及用户的个人偏好、对话历史甚至生物特征数据,这些数据从产生到消亡,经历四个阶段:存储、传输、计算和结果输出。每个阶段都有不同的安全技术与之对应。
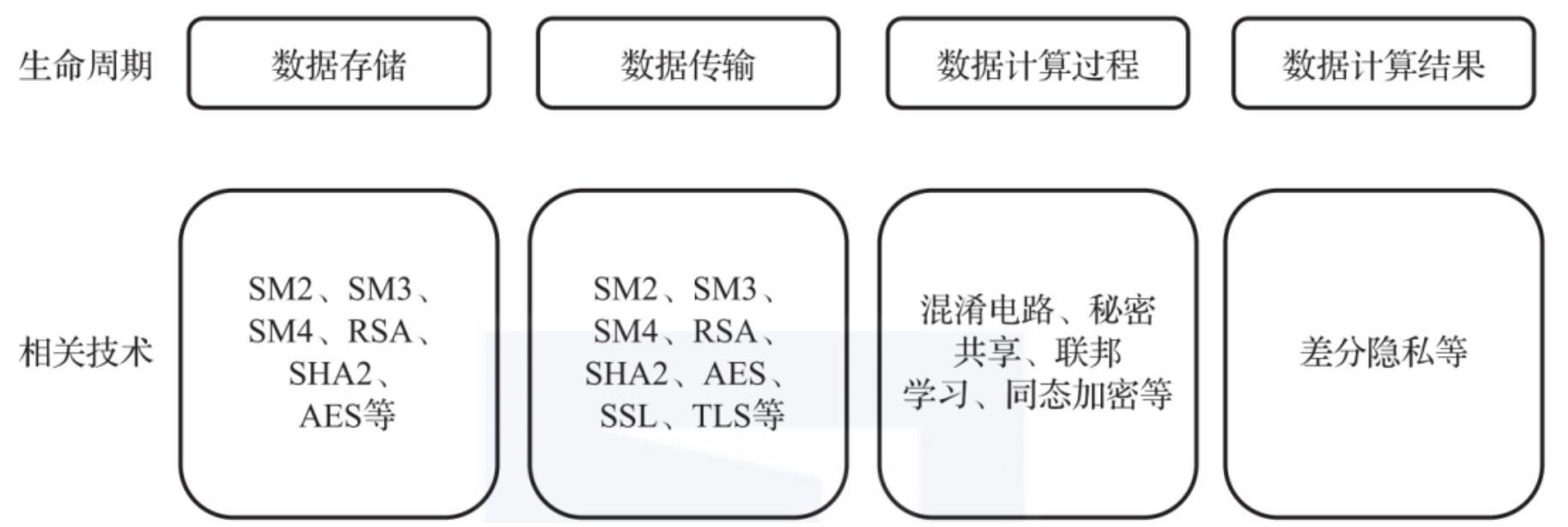
图 24-9:数据生命周期安全保护全景。存储阶段依赖 SM2/SM4/RSA/AES 等加密算法;传输阶段在此基础上增加 SSL/TLS 等通信加密;计算阶段引入混淆电路、秘密共享、联邦学习、同态加密等隐私计算技术;结果输出阶段则需要差分隐私等技术防止反推原始数据。
数据在不同状态下面临的威胁模型也不同:
- 静态数据(Data at Rest):面临存储介质被窃取、数据库被入侵等风险,通过传统加密(AES-256、SM4 等)即可有效保护。
- 传输中数据(Data in Transit):面临中间人攻击、网络窃听等风险,TLS/SSL 协议是标准解决方案。
- 使用中数据(Data in Use):面临内存读取、进程注入、内核级攻击等风险——这是传统安全手段最薄弱的环节。
传统的数据安全方案已经在前两个阶段建立了成熟的防线。但在 AI 时代,真正的瓶颈出现在使用中数据的保护——模型训练和推理都需要对数据进行大量运算,传统加密方法要求先解密再计算,这就在计算过程中暴露了明文数据。隐私计算(Privacy-Preserving Computation)正是为了解决这一难题而生的技术体系,其核心目标是实现"数据可用不可见"——在不泄露原始数据的前提下完成数据分析和模型训练。
根据数据生命周期,隐私计算中的参与方可分为三类角色:输入方(提供原始数据)、计算方(执行运算)和结果使用方(获取输出)。安全性则需要从两个维度保障:
- 输入隐私:任何参与方不能在未授权的情况下获取或解析出原始输入数据及中间计算结果。
- 输出隐私:任何参与方不能从最终输出结果反推出敏感信息。
以大模型推理为例:用户向云端 LLM 发送一个医疗咨询请求,输入隐私要求云服务商无法获取用户的症状描述原文;输出隐私则要求返回的诊断建议不能被第三方截获后反推出用户的健康状况。这两个维度的保障需要贯穿数据的整个生命周期。
二、隐私计算核心技术全景
隐私计算并非一种单一技术,而是一个由多种密码学和系统安全手段组成的技术族群。下表对比了六种核心技术的特性:
| 技术 | 核心原理 | 保护阶段 | 优势 | 局限 |
|---|---|---|---|---|
| 同态加密(HE) | 数据遮蔽 | 存储 + 计算 | 无信息损耗 | 算力开销大,数据增多时性能下降 |
| 可信执行环境(TEE) | 硬件隔离 | 存储 + 计算 | 性能高,通用性强 | 需信任硬件厂商,侧信道攻击风险 |
| 安全多方计算(MPC) | 密码学协议 | 计算 | 无需可信第三方 | 参与方增多时计算复杂度剧增 |
| 联邦学习(FL) | 数据不动模型动 | 计算 | 原始数据不出本地 | 隐私保护无密码学验证,需配合其他技术 |
| 差分隐私(DP) | 数据扰动 | 结果输出 | 可量化隐私预算 | 噪声降低数据精度 |
| 零知识证明(ZKP) | 证明而不泄露 | 计算 | 仅提供最低限度信息 | 标准化程度低,部分计算效率低 |
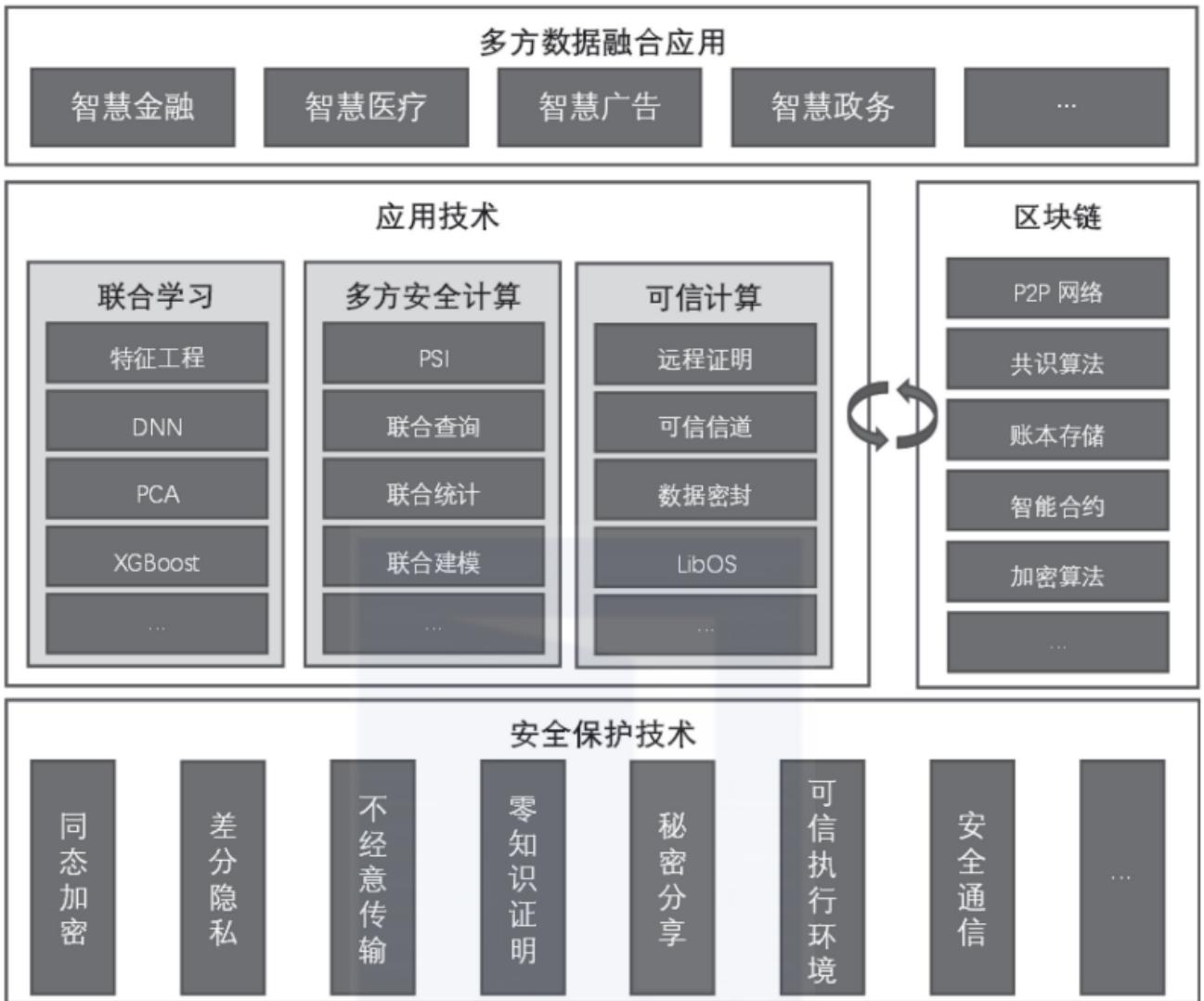
图 24-10:隐私计算全栈架构。底层是同态加密、差分隐私、零知识证明、秘密分享、可信执行环境、安全通信等安全保护技术;中层是联合学习、多方安全计算、可信计算等应用技术,与区块链技术互补;上层则面向智慧金融、智慧医疗、智慧广告、智慧政务等多方数据融合场景。
这些技术并非互相替代的关系,而是在不同的安全需求和性能约束下各有所长。一个实用的选型思路是:对安全性要求极高且可接受性能损失的场景(如金融清算),优先考虑 MPC 或 HE;对性能敏感且有硬件条件的场景(如实时推理),优先考虑 TEE;涉及多方协作训练的场景(如跨医院的模型联合训练),优先考虑 FL + DP 组合。下面逐一深入讲解其中最关键的几种技术。
三、同态加密:在密文上直接计算
同态加密(Homomorphic Encryption, HE)是隐私计算领域最具理论优雅性的技术。1978 年,Ron Rivest、Leonard Adleman 和 Michael L. Dertouzos 首次提出同态加密的构想,此后长达 30 年这一目标被视为密码学的"圣杯"。同态加密的核心能力是:允许直接对加密后的密文进行算术运算,解密后得到的结果与在明文上执行相同运算的结果完全一致。

图 24-11:同态加密工作原理。上方路径:原始数据经同态加密得到密文,在密文上执行计算处理得到密文结果,再经同态解密得到明文计算结果。下方路径:直接在明文上计算。两条路径得到的结果完全相同。
用数学语言表达,设加密函数为
则称该加密方案关于运算
- 部分同态加密(PHE):仅支持单一运算类型。例如 RSA 算法(1977)仅支持乘法同态,Paillier 算法(1999)仅支持加法同态。PHE 实现简单、效率较高,在联邦学习中的梯度聚合场景应用广泛。
- 半同态加密(SWHE):支持有限次数的加法和乘法混合运算,如 Boneh-Goh-Nissim 方案(2005)仅支持一次乘法运算。
- 全同态加密(FHE):支持对密文进行任意次数的加法和乘法运算。由于任何计算都可以分解为加法和乘法的组合(图灵完备性),FHE 理论上可以在密文上执行任意程序——这就是为什么它被称为密码学的"圣杯"。
全同态加密的实用化始于 2009 年 Gentry 提出的第一个 FHE 方案,这项工作被视为密码学历史上的里程碑。此后经历了多代演进:
| 代际 | 代表方案 | 年份 | 特点 | 典型实现 |
|---|---|---|---|---|
| 第一代 | Gentry 方案 | 2009 | 首个可行的 FHE,性能较差 | — |
| 第二代 | BGV / BFV | 2012 | 性能显著提升,支持 SIMD 批处理 | IBM HElib / 微软 SEAL |
| 第三代 | GSW | 2013 | 基于近似特征向量,简化密钥管理 | TFHE |
| 近似计算 | CKKS | 2017 | 支持浮点数近似运算,适合 ML 场景 | HElib / SEAL |
CKKS 方案的出现具有特殊意义——神经网络的前向传播本质上是矩阵乘法和非线性激活的交替执行,而 CKKS 天然支持浮点数的加法和乘法运算,这使得在密文上执行模型推理成为可能。当然,非线性激活函数(如 ReLU)需要用多项式近似来替代,这会引入一定的精度损失。
以一个简单的线性回归为例来建立直觉:假设我们要计算
同态加密的优缺点 需要客观看待。其安全理论优势无可比拟——数据始终处于加密状态,即使计算方也无法接触明文。但高昂的算力开销严重限制了其大规模应用:FHE 运算通常比明文运算慢 4-6 个数量级,且加密后的密文膨胀率(密文大小与明文大小之比)可达数千倍。因此,目前最适合的场景是数据量小、计算模式固定的任务,如隐私查询、加密投票、简单的统计聚合等。在云计算场景中,用户可以将数据加密后交给云服务器计算,云服务器无法获知数据明文,但仍能返回正确的计算结果——这种模式从根本上解决了"用户信任云服务商"的难题。
四、可信执行环境:硬件级隔离
如果说同态加密是用数学方法"蒙住"数据,那么可信执行环境(Trusted Execution Environment, TEE)则是用物理方法"锁住"数据。TEE 不依赖密码学,而是通过硬件机制在处理器内部划分出一块隔离的安全区域,所有敏感数据的计算都在这块"安全飞地"(Enclave)中完成。外部软件,包括操作系统内核甚至系统管理员,都无法读取安全区域内的数据。
TEE 的前身可追溯到 2009 年 OMTP 工作组提出的双系统方案:在同一个智能终端上,除了多媒体操作系统外,再提供一个隔离的安全操作系统来专门处理敏感信息。这一思想经过十余年的发展,已经演化出多种成熟的工业级实现。
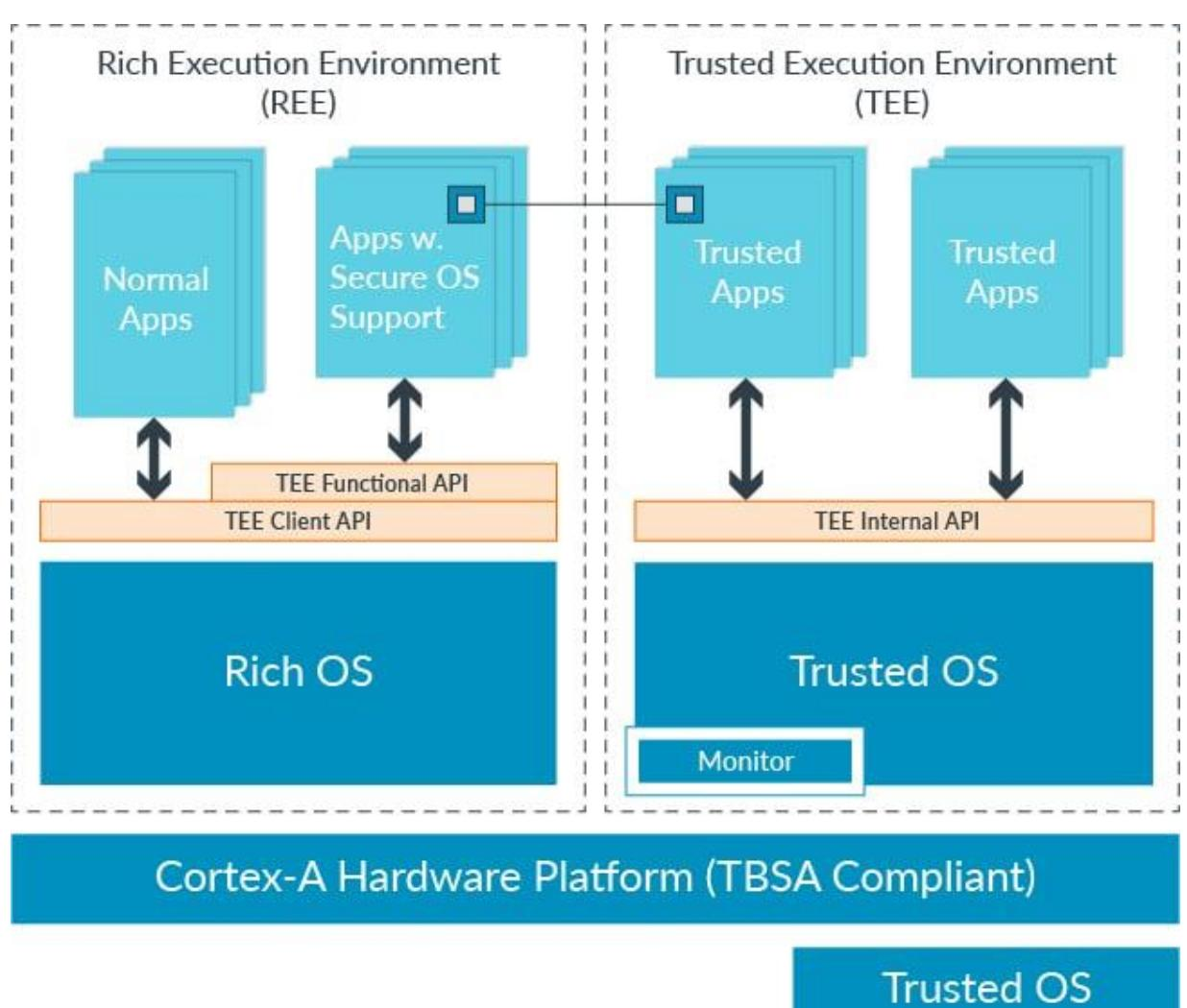
图 24-12:ARM TrustZone 架构。左侧是富执行环境(REE),运行普通应用和 Rich OS;右侧是可信执行环境(TEE),运行可信应用和 Trusted OS。两个世界通过 Monitor 进行受控切换,底层由符合 TBSA 标准的 Cortex-A 硬件平台提供支撑。
TEE 的安全模型建立在四个隔离特性之上:
- 数据隔离:安全区域内的数据对外部操作系统和其他应用完全不可见。
- 计算隔离:安全区域内的运算过程不可被外部观测或拦截。
- 通信控制:安全世界与普通世界之间的数据交互需经过严格管控。
- 错误隔离:普通世界的安全漏洞不会扩散到安全区域中。
以 ARM TrustZone 为例,处理器通过异常级别(Exception Level)来管理不同特权层次的软件:
- EL0:用户应用层,运行普通 App 或可信应用(Trusted Application)。
- EL1:操作系统内核层,普通世界运行 Rich OS(如 Linux),安全世界运行 Trusted OS。
- EL2:虚拟化层,运行 Hypervisor(普通世界)或 Secure Partition Manager(安全世界)。
- EL3:最高特权层,运行 Firmware / Secure Monitor,负责两个世界之间的受控切换。
安全世界和普通世界各自拥有独立的 EL0-EL2 软件栈,而 EL3 层的 Secure Monitor 是唯一可以跨越两个世界的组件。这种硬件级别的隔离比纯软件方案提供了更强的安全保证——即使普通世界的操作系统被完全攻破,安全世界中的数据仍然是安全的。
目前主流的 TEE 实现方案如下:
| 方案 | 厂商 | 架构 | 内存加密 | 远程证明 |
|---|---|---|---|---|
| SGX / TDX | Intel | x86 | 支持 | 支持 |
| TrustZone / CCA | ARM | ARM | 部分支持 | 支持 |
| SEV-SNP | AMD | x86 | 支持 | 支持 |
| CSV | 海光 | x86 | 支持 | 支持 |
| TrustZone | 鲲鹏/飞腾 | ARM | 部分支持 | 支持 |
国产芯片厂商如海光、鲲鹏、飞腾、兆芯等均已推出各自的 TEE 方案,信创国产化趋势明显,相关生态也在加速完善。
TEE 的最大优势是高性能——数据在安全区域内以明文形式计算,无需密码学运算的额外开销,计算性能接近原生水平,因此非常适合处理大规模 AI 推理任务。NVIDIA 的 H100 GPU 也集成了 Confidential Computing 能力,可以在 TEE 模式下运行大模型推理,这为云端 AI 服务的隐私保护提供了新的可能。但 TEE 的信任根基在于硬件厂商本身的可信度,且历史上已有多次针对 Intel SGX 的侧信道攻击被披露,这提醒我们不应将 TEE 作为唯一的安全手段。
五、安全多方计算与联邦学习
安全多方计算(Secure Multi-Party Computation, MPC)解决的是这样一个经典问题:多个互不信任的参与方,各自持有私密数据
这个概念最早由姚期智教授在 1982 年通过"百万富翁问题"提出——两个百万富翁如何在不透露各自财产的情况下比较谁更富有?1986 年,姚期智进一步提出混淆电路(Garbled Circuit)技术,实现了第一个两方安全计算方案。1987 年,Goldreich 等人提出基于秘密共享的 GMW 协议,将安全计算推广到多方场景。
MPC 的核心底层技术包括两大类:
混淆电路(Garbled Circuit)将计算任务编码为布尔电路,然后由一方("混淆者")对电路中每个门的真值表进行加密,另一方("求值者")在不知道输入具体值的情况下逐门求值。整个过程中,双方都无法获知对方的输入。混淆电路适合两方计算场景,且对任意函数通用。
秘密共享(Secret Sharing)则采用另一种策略:将秘密数据
MPC 基于密码学原理,安全性有严格的数学保证,但其计算和通信复杂度随参与方数量增长而迅速攀升——这是限制其大规模部署的主要瓶颈。在大模型场景中,MPC 主要应用于隐私保护推理(多方各持有模型的一部分或数据的一部分,协作完成推理)和安全聚合(多方安全地计算梯度平均值)。
联邦学习(Federated Learning, FL)是与 MPC 互补的另一种隐私保护协作计算框架,由 Google 在 2016 年首次提出并应用于移动端键盘预测。与 MPC 基于密码学协议不同,联邦学习的核心思想更加直观——"数据不动模型动":各参与方在本地使用自己的私有数据训练模型,只将加密后的模型更新(如梯度)上传至中心服务器进行聚合,原始数据始终不离开本地。
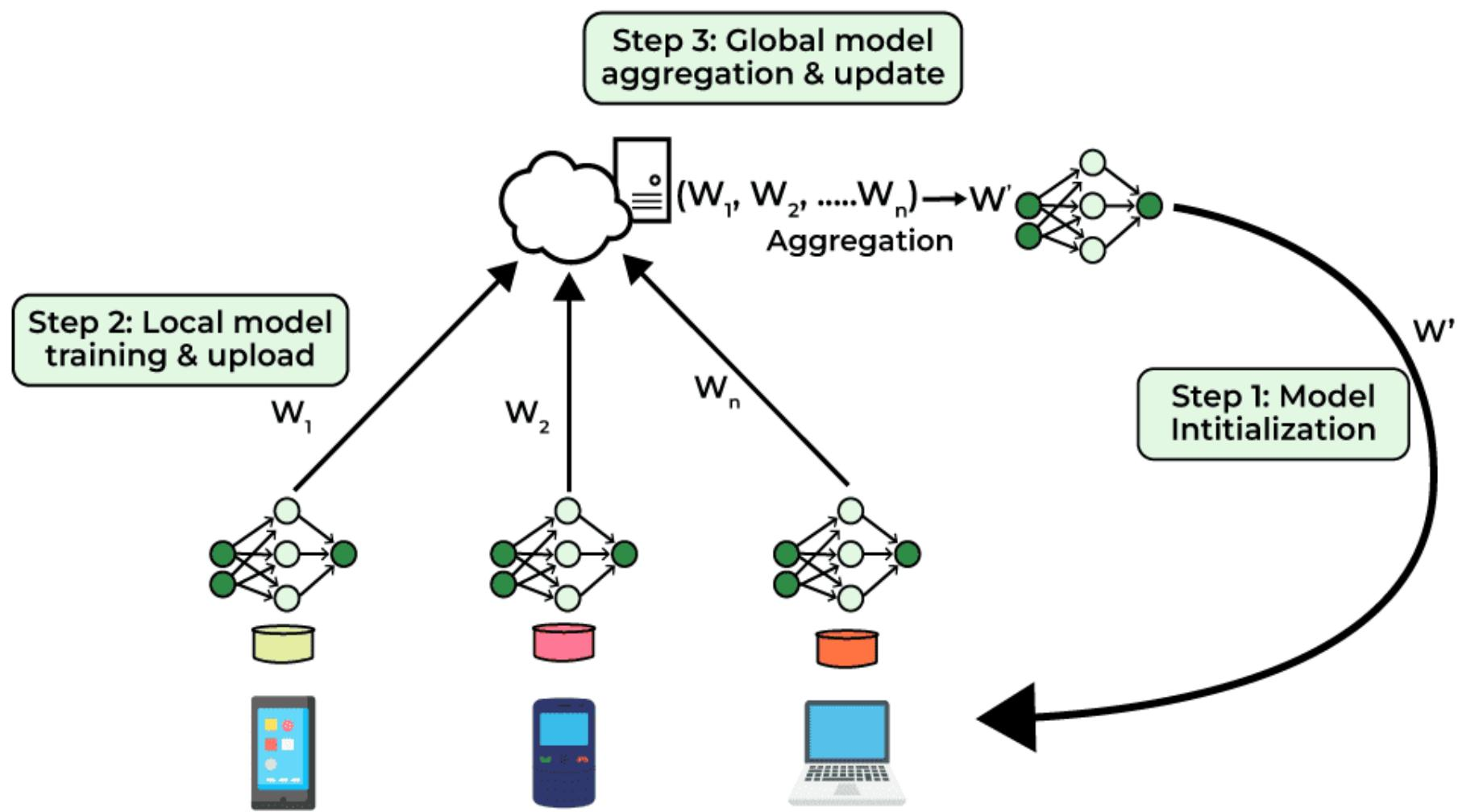
图 24-13:联邦学习三步循环。Step 1:中心服务器将全局模型
根据参与方数据的样本和特征重合情况,联邦学习分为三种类型:
| 类型 | 适用场景 | 核心思路 |
|---|---|---|
| 横向联邦学习 | 样本重合度低、特征重合度高 | 增加同特征下的样本量,如多家同类型医院共同训练诊断模型 |
| 纵向联邦学习 | 样本重合度高、特征重合度低 | 丰富同样本的特征维度,如银行与电商联合建模 |
| 联邦迁移学习 | 样本和特征重合度均低 | 利用迁移学习弥补数据不足,适合跨领域场景 |
需要注意,联邦学习本身并不能提供密码学级别的隐私保证。Zhu 等人 (2019) 的研究表明,通过分析共享的梯度更新,攻击者可以高精度地重建原始训练数据(Deep Leakage from Gradients)。因此,工业实践中联邦学习通常需要与其他隐私保护技术结合使用:
- 联邦学习 + 差分隐私:在上传梯度前添加校准过的噪声,以可量化的隐私预算
控制信息泄露量。 - 联邦学习 + 安全聚合:使用 MPC 或 HE 技术对梯度进行加密聚合,服务器只能获得聚合后的结果,无法看到任何单个参与方的梯度。
- 联邦学习 + TEE:在可信执行环境中完成梯度聚合,硬件级隔离保证聚合过程的安全性。
差分隐私(Differential Privacy, DP)值得单独强调,因为它是唯一能提供严格数学化隐私保证的技术。其形式化定义如下:对于随机化算法
则称
差分隐私的实现方式分为两种:中心化差分隐私(由数据收集方在汇总数据上添加噪声)和本地差分隐私(每个用户在上传数据前就在本地添加噪声)。后者提供更强的保护——即使数据收集方本身也无法获得任何单个用户的真实数据。
自 2006 年由 Dwork 提出以来,差分隐私已被 Google、Apple、Microsoft 等公司广泛采用。Google 的 RAPPOR 系统使用本地差分隐私收集 Chrome 浏览器的使用统计;Apple 在 iOS 中使用本地差分隐私收集 Emoji 使用频率和输入法词频数据;OpenAI 等公司在大模型训练中也在探索将差分隐私与联邦学习结合的方案。
六、案例研究:Apple Intelligence 的端云协同隐私架构
前面介绍的各种隐私计算技术如果只停留在论文和实验室中,其价值是有限的。真正的考验在于:能否在服务数十亿用户的商业产品中落地?Apple 在 2024 年推出的 Apple Intelligence 给出了一个令人信服的答案。作为全球首个将隐私计算技术体系化地应用于消费级 AI 产品的标杆案例,Apple Intelligence 面对"AI 需要强大算力但用户数据不能泄露"的矛盾,设计了一套精巧的端云协同架构。同时,Apple 与 OpenAI 合作将 ChatGPT 能力内置于 iOS/iPadOS/macOS,这意味着部分请求可能被路由到第三方模型——这使得隐私保护的工程复杂度进一步上升。
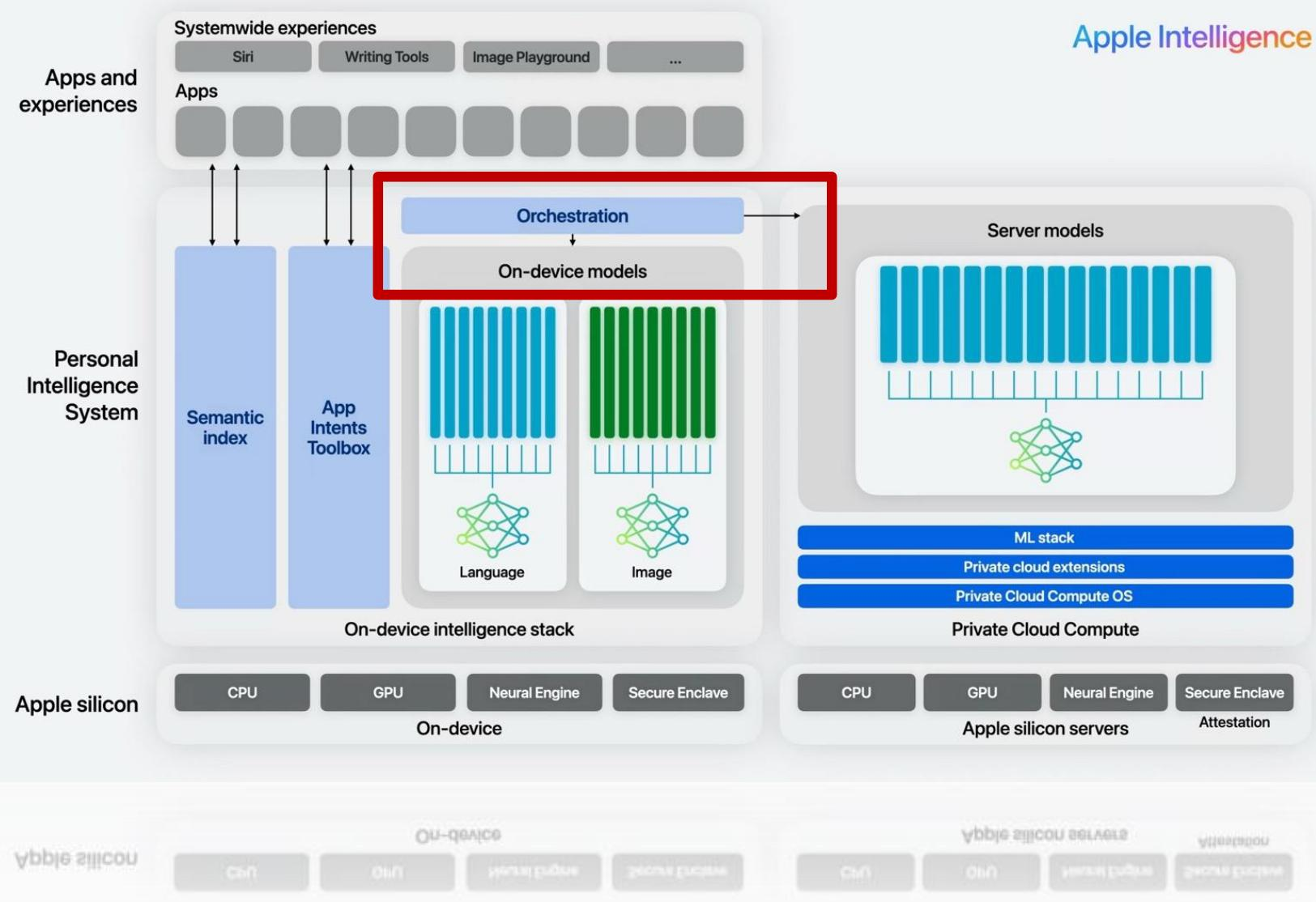
图 24-14:Apple Intelligence 端云协同架构。左侧是设备端智能栈,包含语言模型和图像模型,运行在配备 Neural Engine 和 Secure Enclave 的 Apple Silicon 上;右侧是 Private Cloud Compute(PCC),运行更大规模的服务器模型,同样基于 Apple Silicon 服务器;中间的 Orchestration 层负责动态调度任务分配。
这一架构的设计哲学是能在设备端处理的绝不上云。简单任务(如文本摘要、快速回复建议)由设备端的小模型直接完成;只有复杂任务(如长文档理解、复杂图像生成)才会被路由到云端的 Private Cloud Compute(PCC) 处理。PCC 的安全设计体现了多层隐私保护技术的综合运用:
第一层:无状态计算。 PCC 以无状态方式处理用户数据——请求到达后在内存中完成计算,结果返回后立即销毁所有中间数据,绝不写入持久化存储。这意味着即使服务器被物理入侵,攻击者也无法从硬盘中恢复任何用户数据。这从根本上消除了数据泄露的持久性风险,也使得合规审计变得更加简单。
第二层:通信隐私。 即使计算是无状态的,网络通信中仍然可能泄露用户信息(如 IP 地址可以关联到用户身份)。为此,Apple 采用 OHTTP(Oblivious HTTP) 协议隐藏用户的源 IP 地址。OHTTP 在 WWDC 2023 上首次发布,其核心思想是在客户端和服务器之间插入一个第三方中继节点,实现三方信息隔离:
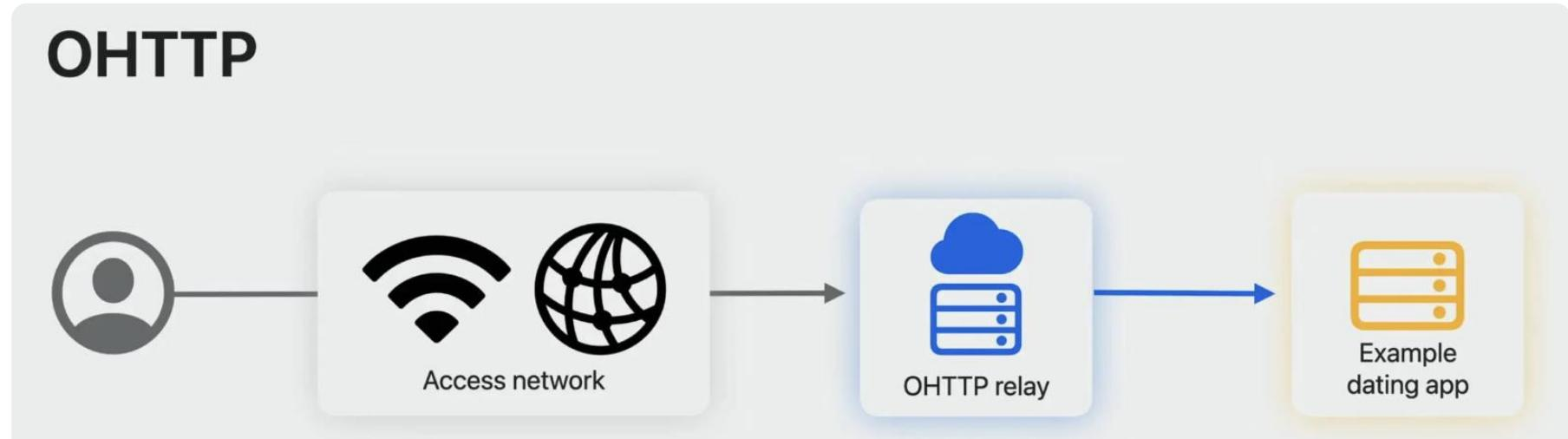
图 24-15:OHTTP 隐私中继架构。客户端知道请求内容但不直接连接服务器;OHTTP 中继知道客户端地址和服务器地址,但内容已加密无法读取;服务器能解密内容但只看到中继地址,不知道真实客户端 IP。三方中没有任何一方能获得完整的连接信息。
OHTTP 的信息隔离可以这样直觉地理解:客户端将请求内容加密后交给中继,中继只是一个"快递员"——它知道寄件人和收件人的地址,但包裹里装的是什么它看不到;服务器收到包裹后能打开内容,但只知道包裹来自中继站,不知道真正的寄件人是谁。Google 和其他浏览器厂商也在推进类似的 OHTTP 标准化工作。
第三层:同态加密实战。 Apple 在 iOS 18 中利用自研的 swift-homomorphic-encryption 开源库实现了 Live Caller ID Lookup(实时来电显示)功能。当用户收到来电时,系统需要查询来电号码对应的身份信息,但不能让服务器知道用户正在查询哪个号码。
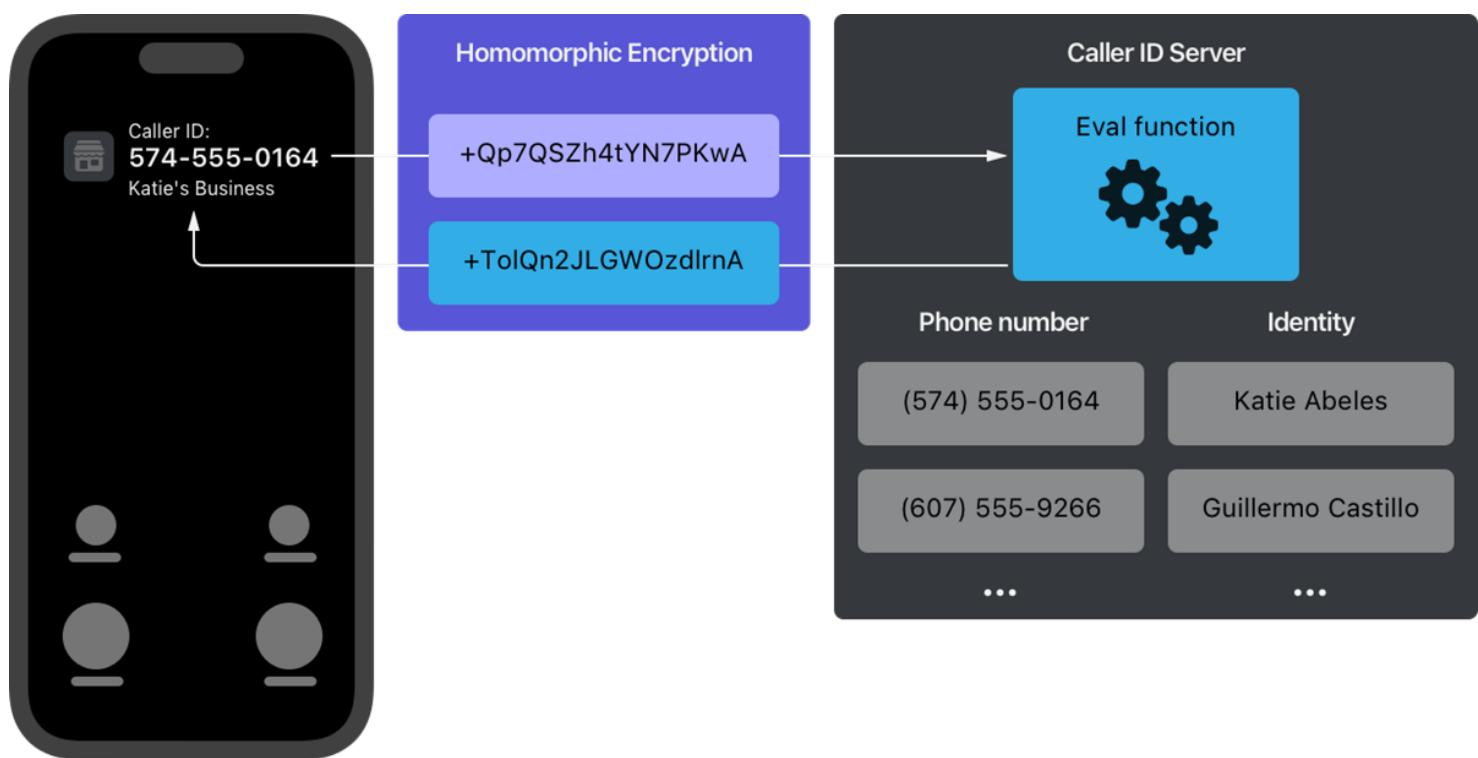
图 24-16:Live Caller ID Lookup 工作原理。手机端将来电号码通过同态加密编码为密文,发送至 Caller ID Server;服务器在不解密的情况下,通过 Eval 函数在密文上执行隐私信息检索(PIR);加密后的查询结果返回手机端解密,显示来电者身份。全程服务器无法知晓用户查询的是哪个号码。
这个实例完美展示了同态加密在"数据量小、查询模式固定"场景下的实用性。隐私信息检索(Private Information Retrieval, PIR)是同态加密最典型的应用场景之一:客户端希望从服务器的数据库中查询某条记录,但不希望服务器知道自己查的是哪条。PIR 查询只涉及单次键值对匹配,密文传输量和计算量都在可控范围内。Apple 的实现中,数据库和客户端仅需同步少量元数据,使得处理流程相对高效。
Apple 还结合了 Privacy Pass 协议实现匿名身份认证——用户在首次认证时获取一批匿名令牌,后续请求使用令牌证明身份合法性,服务器无法将多次请求关联到同一用户。这样就形成了 OHTTP + HE + Privacy Pass 的三层隐私防护体系。
第四层:可验证安全。 PCC 的安全架构对第三方安全专家开放审核,且没有任何特权后门可以绕过隐私保护——即使 Apple 自己的 SRE(站点可靠性工程师)也无法接触用户数据。PCC 运行在经过安全加固的专用硬件和操作系统上,其可信计算环境类似于 TEE 的软件实现版本。
Apple Intelligence 的隐私架构可以总结为一个四层纵深防御体系:
| 层级 | 技术手段 | 保护目标 |
|---|---|---|
| 端侧优先 | On-device 小模型 | 敏感数据尽量不出设备 |
| 通信隐私 | OHTTP 中继 | 隐藏用户 IP 和请求来源 |
| 计算隐私 | 同态加密 / 无状态 PCC | 云端不接触明文数据 |
| 身份隐私 | Privacy Pass 匿名认证 | 服务器无法关联多次请求 |
这种多层防护的设计思路对整个行业都具有示范意义——没有任何单一技术能够解决所有隐私问题,只有将多种技术有机组合,在不同层次建立防线,才能构建真正可信的 AI 系统。
与 Apple 的端侧优先策略形成对比的是,Google 和 Microsoft 等云优先的公司则更多依赖 TEE(如 Google 的 Confidential VMs 和 Microsoft Azure 的 Confidential Computing)来保护云端推理过程中的用户数据。不同的技术路线反映了不同的产品哲学和硬件生态优势,但共同的方向是一致的:让用户在享受 AI 能力的同时不必牺牲隐私。
七、隐私保护机器学习的未来方向
隐私计算与 AI 的结合正在催生一个新的交叉领域——隐私保护机器学习(Privacy-Preserving Machine Learning, PPML)。这一领域的核心挑战在于在隐私保护强度和计算效率之间找到平衡:
训练阶段的隐私保护。大模型预训练需要海量数据,但不同组织之间直接共享原始数据通常受到法规限制。联邦学习 + 差分隐私是当前最主流的解决方案:各参与方在本地训练后上传经噪声扰动的梯度更新,中心服务器完成聚合。Google 的 Gboard 输入法使用这一方案学习用户打字习惯,Apple 的 Siri 模型优化也采用了类似的技术路线。
推理阶段的隐私保护。用户向云端 LLM 发送的查询往往包含敏感信息,如何在不暴露查询内容的情况下获得模型响应?同态加密和 TEE 是两条主要技术路线。对于延迟敏感的场景(如实时对话),TEE 因其接近原生的计算性能成为首选;对于安全性要求极高的场景(如医疗影像分析),FHE 的密码学保证更为可靠,尽管需要承受更高的延迟。
多技术融合。实际工程中很少单独使用一种技术。Apple Intelligence 的案例表明,真正的隐私保护需要在通信层(OHTTP)、计算层(HE/TEE)和结果层(DP)形成纵深防御。每一层的技术选择都取决于该层的性能约束和安全需求。
从技术趋势看,各方向都在快速演进:
- 全同态加密加速:FHE 的性能正在以每年 1-2 个数量级的速度提升。Intel、DARPA 等机构正在研发专用 FHE 加速芯片(如 DARPA 的 DPRIVE 项目),目标是将 FHE 运算速度提升到接近明文计算的水平。一旦这一目标实现,在密文上运行完整的 Transformer 推理将不再是天方夜谭。
- 联邦学习进阶:从简单的梯度聚合(FedAvg)向支持异构模型架构、异步通信、个性化联邦学习等方向演进。跨组织的联邦大模型预训练也在探索中——多家医院联合训练医疗大模型而无需共享任何患者数据,这一愿景正在逐步成为现实。
- TEE 扩展:从 CPU 扩展到 GPU(如 NVIDIA H100 Confidential Computing),支持的安全内存容量不断增大,远程证明机制日趋完善。GPU TEE 的出现意味着大模型推理可以在硬件级安全保护下运行,这对云端 AI 服务的隐私保护具有革命性意义。
- 技术融合:TEE + HE、FL + DP + MPC 等多技术组合方案正在成为工程实践的主流,单一技术的局限通过互补组合来弥补。学术界也在探索新的理论框架,试图统一不同隐私保护技术的安全保证。
当这些技术的性能瓶颈被逐步突破,大模型真正实现"数据可用不可见"的目标将不再遥远。
值得一提的是,隐私保护不仅仅是技术问题,也是法规和商业问题。欧盟的 GDPR(通用数据保护条例)、中国的《个人信息保护法》、美国加州的 CCPA 等法规正在全球范围内推动企业重视数据隐私。对于 AI 服务提供商而言,采用隐私计算技术不仅是合规要求,也是赢得用户信任的竞争优势。Apple 将"Privacy"作为核心品牌价值的策略已经证明,隐私保护可以成为差异化竞争力的重要来源。
本节系统梳理了 AI 安全与隐私保护的技术全景。我们从数据生命周期的安全分析框架出发,理解了静态数据、传输中数据和使用中数据面临的不同威胁,以及隐私计算"数据可用不可见"的核心目标。通过同态加密、TEE、MPC、联邦学习、差分隐私五大核心技术的深入对比,我们看到每种技术都有其独特的优势和不可忽视的局限——没有银弹,只有针对具体场景的最优组合。最后,Apple Intelligence 的端云协同架构展示了如何将无状态计算、OHTTP 通信隐私、同态加密和匿名认证四层防护有机组合,在服务数十亿用户的消费级产品中实现了强隐私保证下的 AI 能力。
隐私保护不是 AI 发展的阻碍,而是赢得用户信任、实现可持续发展的必由之路。正如 Apple 所展示的——将隐私作为核心设计原则而非事后补丁,不仅能满足合规要求,更能成为产品的差异化竞争力。