27.3 CLI 快速使用
TRL 不仅提供了灵活的 Python API,还内置了一套命令行工具(CLI),让用户无需编写任何 Python 代码就能完成 SFT、DPO、GRPO 等训练任务。对于日常的超参搜索、快速原型验证和 CI/CD 训练流水线来说,CLI 是效率最高的入口。本节将从基础用法到高级配置,系统介绍 TRL CLI 的完整工作流。
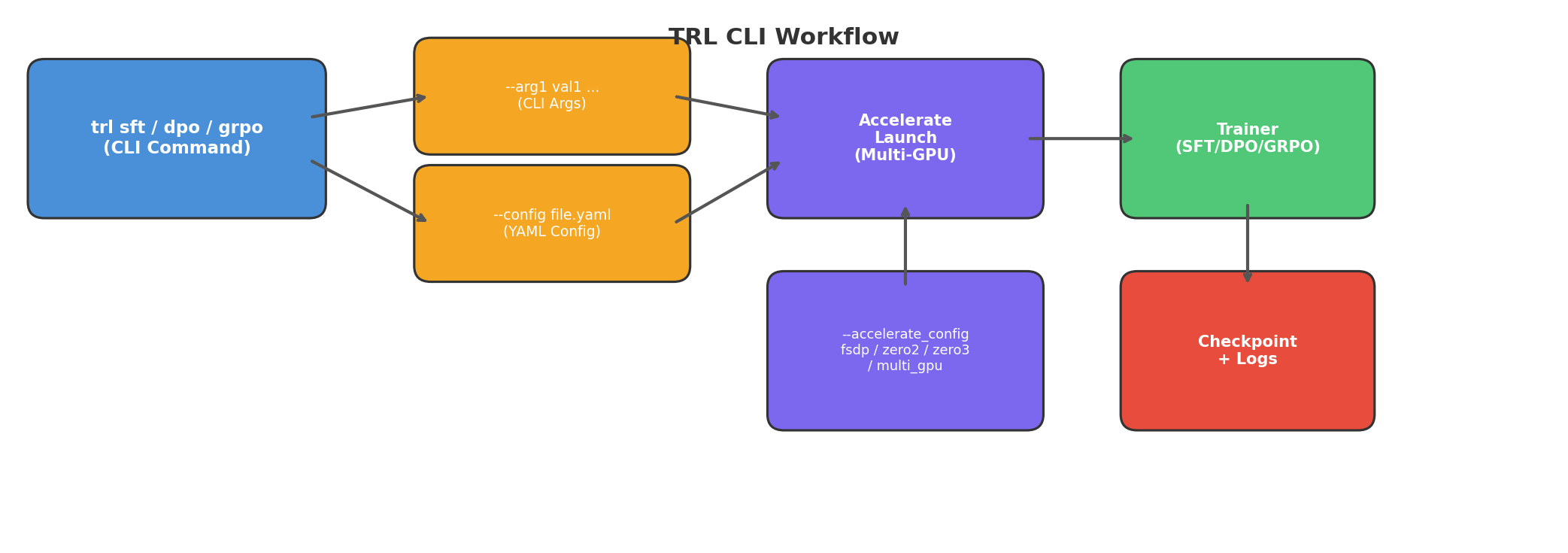
一、CLI 命令总览
安装 TRL 后,终端中即可使用 trl 命令。当前支持的子命令分为两类:
训练命令——每个命令对应一种训练算法:
| 命令 | 功能 | 对应 Trainer |
|---|---|---|
trl sft | 监督微调 | SFTTrainer |
trl dpo | 直接偏好优化 | DPOTrainer |
trl grpo | 群组相对策略优化 | GRPOTrainer |
trl kto | Kahneman-Tversky 优化 | KTOTrainer |
trl reward | 奖励模型训练 | RewardTrainer |
trl rloo | RLOO 策略优化 | RLOOTrainer |
辅助命令:
| 命令 | 功能 |
|---|---|
trl env | 打印系统环境信息(GPU、CUDA、各库版本) |
trl vllm-serve | 启动 vLLM 推理服务(供 GRPO server 模式使用) |
所有训练命令的参数名与对应 *Config 类的属性完全一致。例如 SFTConfig 中的 model_name_or_path 参数,在 CLI 中就是 --model_name_or_path。这意味着你在 Python API 文档中看到的每一个参数都可以直接搬到命令行使用。
二、基础用法:一行命令启动训练
最简单的情况下,只需指定模型和数据集即可开始训练。
SFT 示例——在 IMDb 数据集上微调 Qwen2.5-0.5B:
trl sft \
--model_name_or_path Qwen/Qwen2.5-0.5B \
--dataset_name stanfordnlp/imdbDPO 示例——在人类偏好数据上进行偏好对齐:
trl dpo \
--model_name_or_path Qwen/Qwen2.5-0.5B \
--dataset_name anthropic/hh-rlhfGRPO 示例——使用内置 accuracy_reward 进行强化学习训练:
trl grpo \
--model_name_or_path Qwen/Qwen2.5-0.5B \
--dataset_name HuggingFaceH4/Polaris-Dataset-53K \
--reward_funcs accuracy_reward注意 GRPO 和 RLOO 比 SFT/DPO 多了一个必需参数 --reward_funcs,因为它们是在线强化学习方法,需要在训练过程中计算奖励。TRL 内置了 accuracy_reward 等常用奖励函数,可以直接通过名称引用。
三、YAML 配置文件:可复现的训练方案
当参数变多时,命令行会变得冗长且难以管理。更好的做法是将所有参数写入 YAML 配置文件,通过 --config 选项加载:
SFT 配置文件示例(sft_config.yaml):
# sft_config.yaml
model_name_or_path: Qwen/Qwen2.5-0.5B
dataset_name: stanfordnlp/imdb
output_dir: ./sft-qwen-imdb
per_device_train_batch_size: 4
num_train_epochs: 3
learning_rate: 2.0e-5
bf16: true
logging_steps: 50
save_strategy: epoch启动训练只需一行:
trl sft --config sft_config.yamlDPO 配置文件示例(dpo_config.yaml):
# dpo_config.yaml
model_name_or_path: Qwen/Qwen2.5-0.5B
dataset_name: anthropic/hh-rlhf
output_dir: ./dpo-qwen-hhrlhf
per_device_train_batch_size: 2
learning_rate: 5.0e-7
beta: 0.1
max_length: 1024
bf16: true
gradient_accumulation_steps: 4trl dpo --config dpo_config.yamlGRPO 配置文件示例(grpo_config.yaml):
# grpo_config.yaml
model_name_or_path: Qwen/Qwen2.5-0.5B
dataset_name: HuggingFaceH4/Polaris-Dataset-53K
reward_funcs:
- accuracy_reward
output_dir: ./grpo-qwen-math
per_device_train_batch_size: 4
num_generations: 8
max_completion_length: 512
learning_rate: 5.0e-6
bf16: truetrl grpo --config grpo_config.yamlYAML 配置的优势在于可版本控制、可复现、可共享。团队成员可以直接 git clone 配置文件后一行命令复现实验,而不必在聊天记录中翻找参数组合。
配置覆盖规则:命令行参数的优先级高于配置文件。这意味着你可以用 YAML 文件定义"基线配置",再通过命令行覆盖个别参数:
bashtrl sft --config sft_config.yaml --learning_rate 1e-4这对超参搜索特别方便——只需改变一个命令行参数就能快速对比不同设置。
四、多 GPU 与分布式训练
TRL CLI 原生集成了 Accelerate,无需额外启动脚本即可进行多 GPU 训练。
方式一:--num_processes 指定 GPU 数
trl sft \
--model_name_or_path Qwen/Qwen2.5-0.5B \
--dataset_name stanfordnlp/imdb \
--num_processes 4同样可以写在 YAML 中:
# sft_4gpu.yaml
model_name_or_path: Qwen/Qwen2.5-0.5B
dataset_name: stanfordnlp/imdb
num_processes: 4方式二:--accelerate_config 使用预置分布式策略
TRL 内置了多种 Accelerate 配置模板,覆盖常见的分布式场景:
| 配置名 | 分布式策略 |
|---|---|
single_gpu | 单 GPU 训练 |
multi_gpu | 多 GPU 数据并行 |
fsdp1 | FSDP Stage 1(仅分片优化器状态) |
fsdp2 | FSDP Stage 2(分片优化器 + 梯度) |
zero1 | DeepSpeed ZeRO Stage 1 |
zero2 | DeepSpeed ZeRO Stage 2 |
zero3 | DeepSpeed ZeRO Stage 3(全分片) |
使用时只需传入配置名称:
trl dpo \
--model_name_or_path Qwen/Qwen2.5-0.5B \
--dataset_name anthropic/hh-rlhf \
--accelerate_config zero2如果内置模板不满足需求(例如需要自定义 DeepSpeed offload 策略),也可以传入自定义 YAML 文件路径:
trl grpo \
--model_name_or_path Qwen/Qwen2.5-7B \
--dataset_name HuggingFaceH4/Polaris-Dataset-53K \
--reward_funcs accuracy_reward \
--accelerate_config path/to/my/deepspeed_config.yaml同样地,accelerate_config 参数也可以写在 YAML 配置文件中:
# grpo_distributed.yaml
model_name_or_path: Qwen/Qwen2.5-7B
dataset_name: HuggingFaceH4/Polaris-Dataset-53K
reward_funcs:
- accuracy_reward
accelerate_config: zero3
per_device_train_batch_size: 2
gradient_accumulation_steps: 8
bf16: true五、数据集混合(Dataset Mixtures)
实际训练中,经常需要混合多个数据集来提升模型的泛化能力。TRL CLI 通过 YAML 中的 datasets 字段原生支持这一需求:
SFT 混合数据集示例:
# sft_mixed.yaml
model_name_or_path: Qwen/Qwen2.5-0.5B
datasets:
- path: stanfordnlp/imdb
- path: roneneldan/TinyStoriesDPO 混合数据集示例:
# dpo_mixed.yaml
model_name_or_path: Qwen/Qwen2.5-0.5B
datasets:
- path: BAAI/Infinity-Preference
- path: argilla/Capybara-PreferencesGRPO 混合数据集示例:
# grpo_mixed.yaml
model_name_or_path: Qwen/Qwen2.5-0.5B
datasets:
- path: HuggingFaceH4/Polaris-Dataset-53K
- path: trl-lib/DeepMath-103K
reward_funcs:
- accuracy_reward所有 datasets 列表中的数据集会被自动拼接为一个训练集。如需更精细的混合控制(如按比例采样、指定 split),可参考 DatasetConfig 和 DatasetMixtureConfig 的完整配置项。
六、环境信息检查
在提交 bug report 或排查环境问题时,trl env 命令可以一键输出当前系统的完整环境信息:
trl env输出类似如下内容:
- Platform: Linux-5.15.0-1048-aws-x86_64-with-glibc2.31
- Python version: 3.11.9
- PyTorch version: 2.4.1
- accelerator(s): NVIDIA H100 80GB HBM3
- Transformers version: 4.45.0.dev0
- Accelerate version: 0.34.2
- Datasets version: 3.0.0
- TRL version: 0.12.0
- PEFT version: 0.12.0
- DeepSpeed version: 0.15.1
- vLLM version: not installed这些信息涵盖了硬件(GPU 型号)、运行时(Python、CUDA 版本)和关键依赖(PyTorch、Transformers、Accelerate、DeepSpeed 等),是诊断训练问题的第一手数据。
七、CLI vs Python API:如何选择
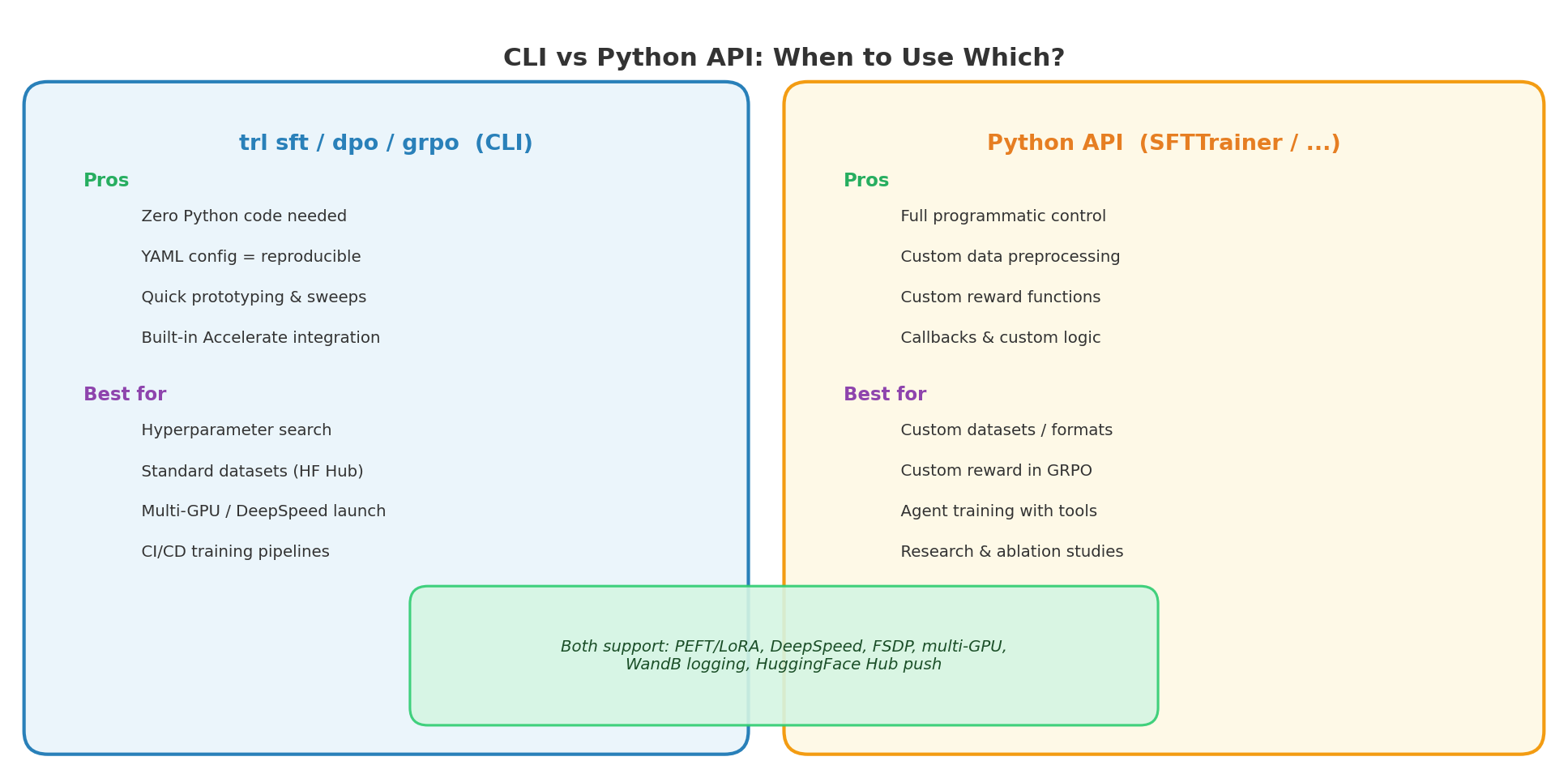
两种方式并非互斥,而是面向不同场景的互补工具。下面从几个维度做具体对比:
| 维度 | CLI | Python API |
|---|---|---|
| 代码量 | 零 Python 代码 | 需编写训练脚本 |
| 参数管理 | YAML 文件 + 命令行覆盖 | Config 对象 + 代码逻辑 |
| 数据预处理 | 仅支持 HF Hub 标准格式 | 任意自定义 preprocessing |
| 奖励函数 | 仅内置函数(如 accuracy_reward) | 任意自定义 Python 函数 |
| 分布式启动 | 内置 Accelerate,一键配置 | 需配合 accelerate launch |
| 可扩展性 | 受限于已暴露的参数 | 完全可编程(callbacks、自定义 loss 等) |
选 CLI 的典型场景:
- 在标准 HF Hub 数据集上快速验证一个训练方案
- 批量扫描超参数(结合 shell 脚本或 YAML 模板)
- CI/CD 流水线中的自动化训练
- 团队共享可复现的训练配置
选 Python API 的典型场景:
- 数据集需要自定义清洗、过滤或格式转换
- GRPO 中使用自定义奖励函数(如格式检查、代码执行验证)
- 需要训练中的 callback(如动态调整参数、自定义日志)
- Agent 训练(需要传入
tools参数) - 研究级别的消融实验,需要精细控制训练过程
实用建议:先用 CLI 快速验证思路可行,再切换到 Python API 做精细调优。两者共享完全相同的底层 Trainer,因此从 CLI 迁移到 Python API 只需将 YAML 参数映射到对应的 Config 对象即可。
八、实战示例:完整的 CLI 训练流程
下面给出一个从零开始的完整示例——用 CLI 在数学数据集上进行 GRPO 训练,包含 LoRA 微调和 DeepSpeed ZeRO-2 分布式策略。
第一步:确认环境就绪。
trl env第二步:编写 YAML 配置文件。
# grpo_math_lora.yaml
model_name_or_path: Qwen/Qwen2.5-7B-Instruct
dataset_name: trl-lib/DeepMath-103K
reward_funcs:
- accuracy_reward
output_dir: ./grpo-qwen7b-math
# 训练超参
per_device_train_batch_size: 2
gradient_accumulation_steps: 8
num_train_epochs: 1
learning_rate: 1.0e-5
bf16: true
max_completion_length: 1024
num_generations: 4
# LoRA 配置
use_peft: true
lora_r: 16
lora_alpha: 32
lora_target_modules: q_proj v_proj
# 分布式策略
accelerate_config: zero2
# 日志
logging_steps: 10
save_strategy: steps
save_steps: 500
report_to: wandb第三步:一行命令启动训练。
trl grpo --config grpo_math_lora.yaml如果需要临时调整某个参数(比如增大 batch size),直接在命令行覆盖:
trl grpo --config grpo_math_lora.yaml --per_device_train_batch_size 4整个过程无需编写一行 Python 代码,从配置到分布式训练再到日志上报全部通过 CLI 完成。
本节小结
TRL CLI 将复杂的训练流程压缩为"命令 + 配置文件"的简洁范式。核心要点包括:
- 六个训练命令(
trl sft/dpo/grpo/kto/reward/rloo)覆盖了从监督微调到在线强化学习的完整训练方法谱系; - YAML 配置文件让实验参数可版本控制、可复现、可共享,命令行参数可按需覆盖;
- Accelerate 集成支持通过
--num_processes或--accelerate_config一键切换单机/多机、FSDP/DeepSpeed 等分布式策略; - 数据集混合通过
datasets字段原生支持多数据源拼接; - CLI 与 Python API 共享同一套底层 Trainer,适合"CLI 快速验证 + Python API 精细调优"的渐进式工作流。
对于需要自定义数据预处理、奖励函数或训练回调的高级场景,请参阅本章其他小节中各 Trainer 的 Python API 详细用法。