15.3 RLAIF(AI 反馈强化学习)
§15.2 介绍了 RLHF 的经典流程:人类标注者提供偏好数据,训练奖励模型,再通过 PPO 优化策略。这条路线在 InstructGPT 和 ChatGPT 的成功中得到了验证,但也暴露出一个根本性矛盾——人类标注的成本与 AI 系统迭代速度之间的不匹配。当模型能力持续提升、应用场景不断扩展时,依赖人类逐条标注偏好数据的做法在规模和速度上都难以为继。
为解决这一矛盾,业界发展出了两条不同的替代路线:一条是用更强的 AI 模型替代人类标注者来提供反馈信号,即 RLAIF(Reinforcement Learning from AI Feedback,AI 反馈强化学习);另一条是用确定性的验证规则替代主观偏好判断,即 RLVR(Reinforcement Learning with Verifiable Rewards,可验证奖励强化学习)。本节将建立 RLHF、RLAIF、RLVR 三者的统一对比框架,深入分析 RLAIF 中的 AI 评委机制与偏差问题,并简要引出 RLVR 的核心思想——RLVR 的完整技术细节将在 §18.1 展开。
15.3.1 反馈信号的三分结构
RLHF、RLAIF 和 RLVR 的本质区别在于奖励信号的来源。三者共享同一个强化学习优化框架(如 PPO 或 GRPO),但在"谁来判断模型输出的好坏"这一问题上给出了截然不同的回答。
| 维度 | RLHF | RLAIF | RLVR |
|---|---|---|---|
| 反馈来源 | 人类标注者 | AI 模型("AI 评委") | 确定性规则/验证器 |
| 奖励信号类型 | 主观偏好 | AI 生成的偏好或评分 | 二元判定(对/错) |
| 典型任务 | 通用对话、创意写作 | 通用对话、安全评估 | 数学推理、代码生成 |
| 可扩展性 | 低(受限于人力) | 高(可自动化) | 极高(零人工) |
| 信号质量 | 高(但有人际差异) | 中(受 AI 能力制约) | 极高(确定性验证) |
| 适用范围 | 广(任何有偏好的任务) | 广(AI 能评判的任务) | 窄(有客观答案的任务) |
| 代表工作 | InstructGPT、ChatGPT | Anthropic Constitutional AI | DeepSeek-R1、Tulu 3 |
表 15-3:RLHF、RLAIF、RLVR 的三维对比。
这三种范式并非互斥,而是互补的。一个完整的后训练系统可以同时使用多种反馈来源:在有客观标准的任务上使用 RLVR 获取高质量信号,在开放式任务上使用 RLAIF 实现大规模自动化标注,在关键场景上保留少量人类标注作为质量锚点。
图 15-7:大模型后训练技术演进时间线。2022 年 RLHF 框架确立,2023 年 DPO 等无 RM 方法涌现,2024 年后 RLAIF 和 RLVR 成为主流方向。
15.3.2 RLAIF 的核心思想
RLAIF 的核心思想非常直观:用一个强大的 AI 模型("教师"或"评委")来替代人类标注者,为训练数据生成偏好标签或直接产生奖励分数。
基本流程。 RLAIF 的工作流程与 RLHF 高度相似,关键区别仅在数据标注环节:
- 生成候选回答:对每个 prompt
,用当前策略模型 采样若干候选回答 。 - AI 评委打分:将
对送入一个能力更强的 AI 模型(如 GPT-4、Claude),由其判断哪个回答更好,或直接给出评分。 - 训练奖励模型:用 AI 生成的偏好数据训练奖励模型
,训练方式与 RLHF 完全相同(Bradley-Terry 损失)。 - 策略优化:用 PPO、GRPO 等算法,利用
的信号优化策略模型 。
也有一些方案跳过第 3 步,直接将 AI 评委的输出作为在线奖励信号(即不训练独立的 RM),这种做法被称为直接 AI 反馈(Direct AI Feedback)。
为什么 RLAIF 可行? RLAIF 的可行性建立在两个前提上:
- 能力不对称:评判一个回答的好坏,通常比生成一个同样好的回答更容易。一个 70B 参数的模型可能无法写出完美的技术报告,但完全有能力判断两篇报告哪篇更好。
- 规模效应:AI 评委可以 24 小时不间断工作,标注成本几乎为零。当偏好数据量从数万条扩展到数百万条时,即使单条数据的质量略低于人类标注,总体训练效果仍可能更优。
15.3.3 AI 评委的实现方式
在实际系统中,AI 评委的实现方式多种多样,从简单的二分类到复杂的多维评估,各有适用场景。
配对比较(Pairwise Comparison)。 最常见的方式是将两个候选回答同时呈现给 AI 评委,要求其选择更好的一个。这与人类标注的形式完全一致,生成的偏好数据可以直接用于训练奖励模型。
"""
AI 评委的配对比较实现示例。
本示例展示如何用一个强模型对两个候选回答进行偏好判断。
"""
def pairwise_judge(prompt: str, response_a: str, response_b: str,
judge_model) -> int:
"""
用 AI 评委对两个回答进行配对比较。
Args:
prompt: 原始问题
response_a: 候选回答 A
response_b: 候选回答 B
judge_model: AI 评委模型(如 GPT-4 API)
Returns:
0 表示 A 更好,1 表示 B 更好
"""
judge_prompt = f"""请比较以下两个回答的质量,考虑准确性、完整性和清晰度。
只输出 "A" 或 "B",不要解释。
问题:{prompt}
回答 A:{response_a}
回答 B:{response_b}
更好的回答是:"""
result = judge_model.generate(judge_prompt)
return 0 if "A" in result else 1
def generate_preference_dataset(prompts: list, policy_model,
judge_model, samples_per_prompt: int = 2):
"""
批量生成偏好数据集。
对每个 prompt 采样多个回答,两两比较后生成 (prompt, chosen, rejected) 三元组。
"""
dataset = []
for prompt in prompts:
# 采样多个候选回答
responses = [policy_model.generate(prompt)
for _ in range(samples_per_prompt)]
# 配对比较
winner_idx = pairwise_judge(prompt, responses[0], responses[1],
judge_model)
loser_idx = 1 - winner_idx
dataset.append({
"prompt": prompt,
"chosen": responses[winner_idx],
"rejected": responses[loser_idx],
})
return dataset评分式评估(Pointwise Scoring)。 另一种方式是让 AI 评委直接对单个回答打分,例如在 1--10 分的量表上评估。这种方式更灵活——可以按多个维度分别打分(如准确性、流畅性、安全性),也可以直接作为 GRPO 等算法的奖励信号,无需训练独立的奖励模型。
多评委集成(Ensemble of Judges)。 单个 AI 评委可能存在系统性偏差。实践中常用多个不同的 AI 模型作为评委,通过投票或加权平均来得到更可靠的判断。TRL(Transformer Reinforcement Learning)库提供了完整的 Judge 接口框架,支持配对比较、排序和二分类等多种评判模式。
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
"""
多评委集成示例:用多个 AI 模型投票决定偏好。
"""
def ensemble_judge(prompt: str, response_a: str, response_b: str,
judge_models: list) -> int:
"""多评委投票。返回多数评委认为更好的回答索引。"""
votes = []
for model in judge_models:
vote = pairwise_judge(prompt, response_a, response_b, model)
votes.append(vote)
# 多数投票
return 1 if sum(votes) > len(votes) / 2 else 015.3.4 可扩展反馈与 Constitutional AI
RLAIF 最具影响力的实践之一是 Anthropic 提出的 Constitutional AI(宪法 AI) 框架。该框架的核心思想是:用一组人工编写的原则(Constitution)来指导 AI 评委的判断,从而将人类价值观的注入从"逐条标注"升级为"规则制定"。
两阶段流程:
- 自我批评阶段(Supervised):让模型对自己的输出进行自我批评和修正。给定一个可能有害的回答,模型被要求根据宪法原则指出问题并生成修正版本。修正后的 (prompt, 修正回答) 对用于 SFT。
- RLAIF 阶段:用 AI 评委根据同一组宪法原则生成偏好数据,替代人类标注,然后走标准的 RM 训练 + RL 优化流程。
Constitutional AI 的意义在于将 RLAIF 从"用 AI 模仿人类标注"提升为"用原则指导 AI 评判"。宪法原则可以涵盖安全性、诚实性、有用性等多个维度,且可以随时更新——新增一条原则远比重新标注数万条数据高效得多。
可扩展监督(Scalable Oversight)。 RLAIF 的深层价值在于它为可扩展监督提供了一条技术路径。随着 AI 系统能力的提升,人类将越来越难以直接评估模型的输出质量(例如,评判一段高级数学证明是否正确)。通过构建 AI 评委链——让中等能力的模型监督稍弱的模型,再由更强的模型监督中等模型——有望实现对超人类水平 AI 系统的间接监督。
15.3.5 RLAIF 的偏差与校准
RLAIF 虽然在效率上远超 RLHF,但引入 AI 评委也带来了独特的偏差问题。理解并缓解这些偏差,是 RLAIF 系统可靠运行的关键。
位置偏差(Position Bias)。 AI 评委在配对比较中倾向于偏好特定位置(通常是第一个出现的)的回答。缓解方法是对同一对回答交换顺序比较两次,取一致性结果或随机打破平局。
冗长偏差(Verbosity Bias)。 AI 评委倾向于偏好更长、更详细的回答,即使长度并未带来实质性的信息增益。这种偏差可能导致训练出的模型产生冗长输出,与 GRPO 等算法中的长度偏差问题叠加放大。
自我偏好(Self-Preference Bias)。 当 AI 评委与被评估的模型来自同一模型家族时,评委倾向于给予更高评分——它偏好与自己风格相似的输出。解决方案包括使用不同家族的模型作为评委,或采用多评委集成。
能力天花板。 AI 评委的评判质量受限于其自身能力。当被评估的模型在某些方面接近或超过评委的水平时,AI 反馈的信号质量会急剧下降。这被称为"弱监督强"问题,是 RLAIF 面临的根本性挑战。
下表总结了主要偏差类型及其缓解策略:
| 偏差类型 | 表现 | 缓解策略 |
|---|---|---|
| 位置偏差 | 偏好先出现的回答 | 交换顺序二次比较 |
| 冗长偏差 | 偏好更长的回答 | 控制长度的评分指令;长度惩罚 |
| 自我偏好 | 偏好同家族模型的输出 | 使用不同家族的评委;多模型集成 |
| 能力天花板 | 超出评委能力时信号失效 | 分解任务;专家评委组合 |
| 一致性波动 | 对相同输入给出不同判断 | 降低采样温度;多次采样取众数 |
表 15-4:AI 评委的主要偏差类型与缓解策略。
校准方法。 为了量化 AI 评委与人类判断的一致性,通常在小规模的人类标注数据上计算 AI 评委的准确率和 Cohen's Kappa 一致性系数。实验表明,GPT-4 级别的 AI 评委在大多数通用任务上与人类标注者的一致性已达到人类标注者之间的一致性水平(约 70--80% 的配对一致率)。
15.3.6 RLVR:可验证奖励的极简路线
RLVR 代表了反馈信号设计的另一个极端:完全去除主观判断,用确定性规则验证模型输出的正确性。
核心思想。 RLVR 的奖励函数是一个简单的二元判定器:
验证的具体方式取决于任务类型:
| 任务类型 | 验证方式 | 奖励设计示例 |
|---|---|---|
| 数学推理 | 提取最终答案,与标准答案比对 | 正确 |
| 代码生成 | 执行代码并运行测试用例 | 全部通过 |
| 指令遵循 | 检查输出是否符合指定格式 | 符合 |
| 多步推理 | 逐步验证推导逻辑 | 每正确步骤 |
表 15-5:不同任务类型下 RLVR 的验证方式与奖励设计。
RLVR 的独特优势:
- 零噪声:规则验证没有主观性,奖励信号是确定性的。
- 零成本:无需人类标注者,也无需运行大型 AI 评委模型。
- 完美可扩展:验证规则可以自动化地应用于任意规模的数据。
RLVR 的限制。 RLVR 的根本限制在于适用范围窄——它只能用于有客观正确答案或可自动验证的任务。对于"写一首好诗""生成一段有说服力的论证"这类开放式任务,不存在确定性的验证规则,RLVR 无法直接适用。
RLVR 的概念由 Nathan Lambert 在 Tulu 3 项目中正式提出,后被 DeepSeek-R1 等推理模型广泛采用。RLVR 的完整技术细节——包括验证器构建、奖励塑形(Reward Shaping)、以及"深度思考"的自发涌现现象——将在 §18.1 中专门讨论。
15.3.7 三种范式的统一视角
从算法层面看,RLHF、RLAIF 和 RLVR 可以纳入同一个统一框架——它们的区别仅在于奖励函数
| 范式 | |
|---|---|
| RLHF | |
| RLAIF | |
| RLVR |
表 15-6:三种范式下奖励函数的统一表示。
这意味着所有的策略优化算法(PPO、GRPO、DPO 等)都可以与任意奖励来源组合使用。奖励来源决定"学什么",优化算法决定"怎么学"——两者是正交的设计维度。
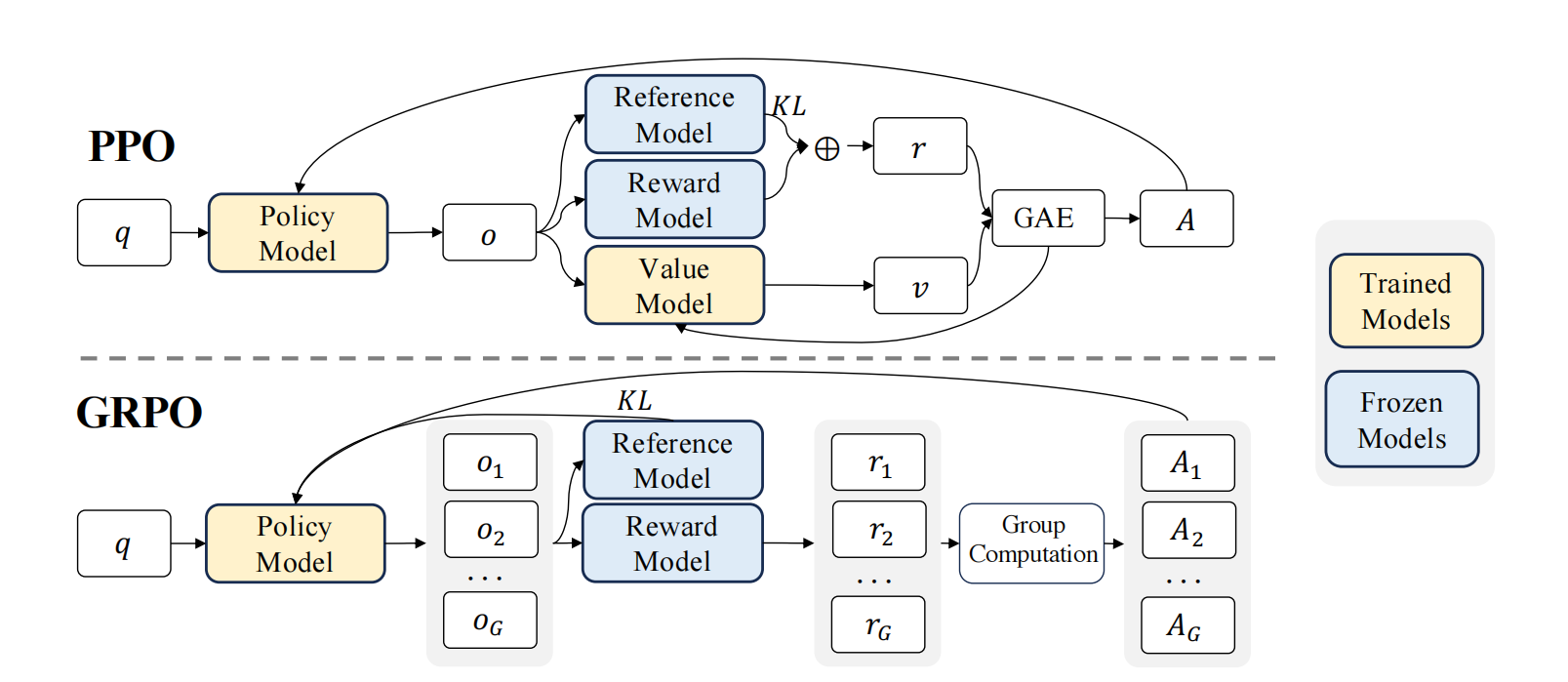
图 15-8:PPO 与 GRPO 的架构对比。无论使用哪种反馈来源(RLHF/RLAIF/RLVR),优化算法的框架保持不变——Reward Model 的位置可以被 AI 评委或规则验证器替换。
实际系统中的混合策略。 现代大模型的后训练往往综合使用多种反馈来源:
"""
混合奖励设计示例:结合规则奖励与模型奖励。
这是实际训练系统中的常见模式。
"""
def compute_hybrid_reward(prompt: str, response: str,
reward_model, format_weight: float = 0.3,
model_weight: float = 0.7) -> float:
"""
计算混合奖励分数,结合规则验证和模型评分。
Args:
prompt: 输入问题
response: 模型回答
reward_model: 奖励模型或 AI 评委
format_weight: 格式奖励权重
model_weight: 模型奖励权重
Returns:
综合奖励分数
"""
# 1. 规则验证:检查格式是否符合要求(RLVR 思想)
import re
format_score = 0.0
if re.search(r"<think>.*</think>\s*<answer>.*</answer>",
response, re.DOTALL):
format_score = 1.0
else:
# 部分格式奖励
tags = ["<think>", "</think>", "<answer>", "</answer>"]
format_score = sum(0.25 for tag in tags if tag in response)
# 2. 模型评分:用 AI 评委或 RM 打分(RLAIF/RLHF 思想)
model_score = reward_model.score(prompt, response)
model_score = max(-3.0, min(3.0, model_score)) # clip 防止极端值
# 3. 加权组合
total_reward = format_weight * format_score + model_weight * model_score
return total_reward这种混合设计在 MiniMind 等开源项目中有完整实现:格式奖励确保推理模型输出包含 <think>...</think><answer>...</answer> 结构,模型奖励则评估内容质量。格式奖励属于 RLVR 范畴(确定性规则验证),模型奖励属于 RLAIF 范畴(AI 模型打分),两者结合形成了更稳健的训练信号。
本节小结
本节建立了 RLHF、RLAIF 和 RLVR 的三分对比框架。三种范式的核心区别在于奖励信号的来源——人类标注、AI 评委或确定性规则——而它们共享相同的强化学习优化框架。RLAIF 通过 AI 评委实现了偏好标注的大规模自动化,但需要应对位置偏差、冗长偏差和能力天花板等固有挑战。RLVR 在可验证任务上提供了零噪声、零成本的极简方案,但适用范围受限。实际系统往往混合使用多种反馈来源,在信号质量与可扩展性之间取得平衡。
下一节(§15.4)将深入讨论奖励模型的设计——无论反馈来源是人类还是 AI,奖励模型的架构(ORM vs PRM)和训练方法都是决定对齐效果的核心环节。