4.3 嵌入与数据加载
前两节讨论了如何将原始文本拆分为子词单元(token)并训练分词器。然而,分词器的输出——一串整数 token ID——尚不能直接被神经网络处理。本节解决从 token ID 到模型输入的"最后一公里"问题:如何将离散的 token ID 转化为稠密的连续向量表示,如何将长文本切分为训练样本,以及如何高效地将模型权重加载到内存中。这三个环节构成了预训练数据管道的核心。
4.3.1 Token 嵌入
为什么需要嵌入层? 分词器将文本转化为整数序列,例如 [15496, 11, 466, 345]。这些整数只是符号索引,不携带任何语义信息——索引 345 与索引 346 在数值上相邻,但语义上可能毫无关联。嵌入层(Embedding Layer)的作用是为每个 token ID 分配一个可学习的稠密向量,使得语义相近的 token 在向量空间中也彼此接近。
在数学上,嵌入层维护一个权重矩阵
这等价于将 one-hot 向量 nn.Embedding 正是这样一个查找表:
import torch
import torch.nn as nn
vocab_size = 50257 # GPT-2 词表大小
embed_dim = 768 # 嵌入维度
token_embedding = nn.Embedding(vocab_size, embed_dim)
# 输入: (batch_size, seq_len) 的整数张量
input_ids = torch.tensor([[15496, 11, 466, 345],
[ 284, 502, 284, 11]])
embeddings = token_embedding(input_ids) # (2, 4, 768)嵌入层的权重在训练开始时随机初始化,通过反向传播与模型其他参数一同优化。训练完成后,语义相近的 token(如 "happy" 和 "joyful" 的子词)将拥有相近的嵌入向量。
4.3.2 位置编码
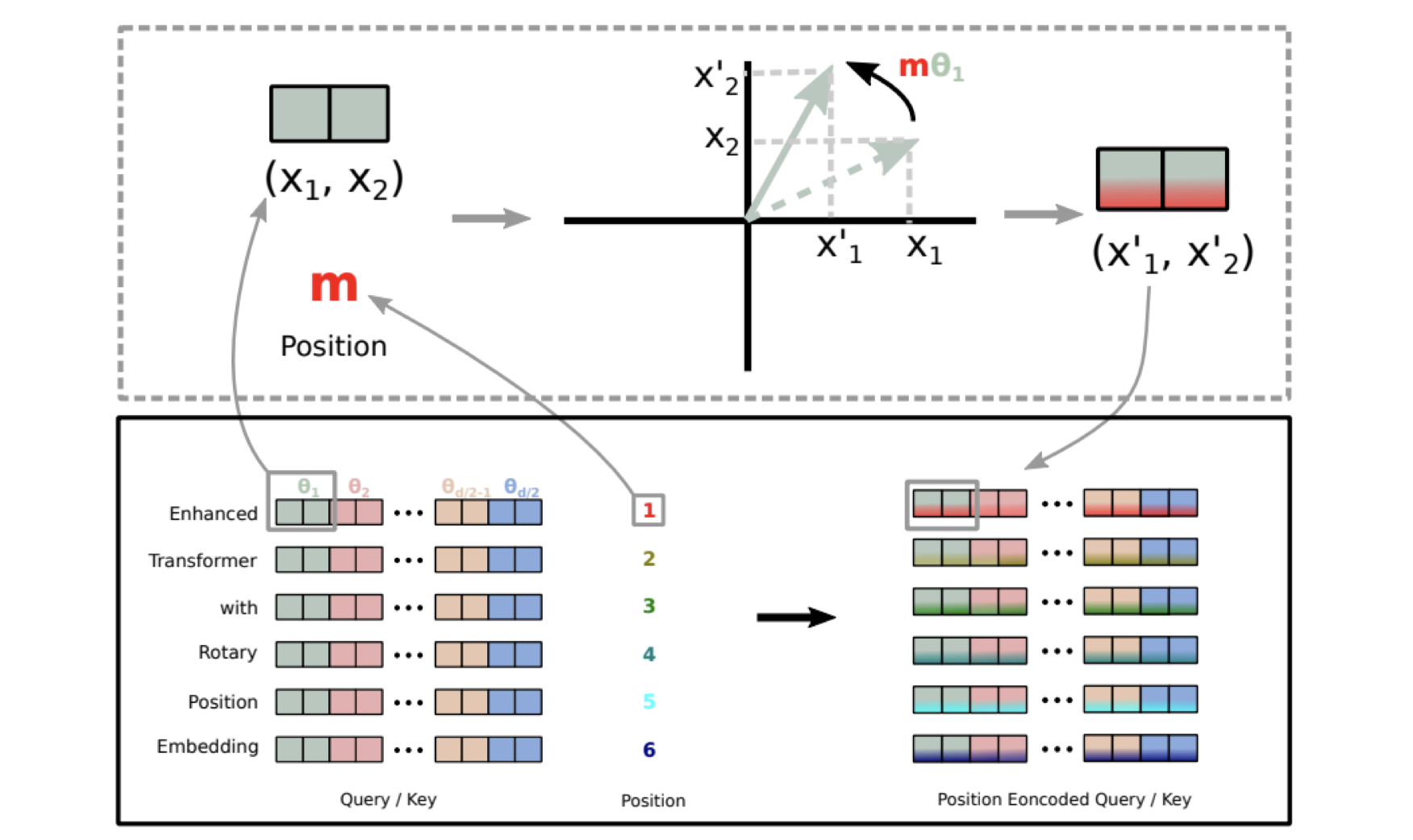
图 4-9:Token 嵌入与位置编码的组合过程。输入 token ID 经嵌入矩阵查表得到 token 嵌入,位置索引经位置编码矩阵得到位置嵌入,二者相加构成 Transformer 的输入。
嵌入层有一个根本性的局限:它对位置不敏感。无论 token "cat" 出现在序列的第 1 个位置还是第 100 个位置,它的嵌入向量完全相同。然而词序对语义至关重要——"狗追猫"和"猫追狗"的含义截然不同。因此,在将 token 嵌入送入 Transformer 之前,必须注入位置信息。
可学习位置嵌入。 GPT-2 和 BERT 采用最直接的方案——再维护一个位置嵌入矩阵
max_len = 1024 # GPT-2 的上下文长度
pos_embedding = nn.Embedding(max_len, embed_dim)
# 为序列中的每个位置生成位置索引
seq_len = input_ids.shape[1]
positions = torch.arange(seq_len) # [0, 1, 2, 3]
pos_embeds = pos_embedding(positions) # (4, 768)
# token 嵌入 + 位置嵌入 = 模型输入
input_embeds = embeddings + pos_embeds # (2, 4, 768),广播机制自动对齐 batch 维度可学习位置嵌入的优点是简单灵活,缺点是无法处理超过
两种嵌入的关系。 下图展示了从 token ID 到模型输入的完整流程。token 嵌入赋予每个 token 语义表示,位置嵌入赋予每个位置几何表示,二者相加后即为 Transformer 的输入序列。
图 4-10:嵌入管道。输入 token ID 经嵌入矩阵
4.3.3 滑动窗口数据采样
有了嵌入层的知识,接下来的问题是:如何从一段长文本中生成训练样本?
自回归语言模型的训练目标是"预测下一个 token"。给定前缀序列
滑动窗口采样。 给定一段被分词为
max_length(窗口大小):等于模型的上下文长度,如 GPT-2 为 1024。stride(步幅):窗口每次滑动的距离。当stride < max_length时,相邻窗口有重叠,产生更多训练样本但也增加了冗余;当stride = max_length时,窗口无重叠,训练效率最高。
下图直观展示了滑动窗口的工作方式。以 max_length=4、stride=1 为例,第一个窗口取位置 [0,1,2,3] 作为输入、[1,2,3,4] 作为目标;第二个窗口取 [1,2,3,4] 作为输入、[2,3,4,5] 作为目标——每次向右滑动 1 个位置。
图 4-11:滑动窗口数据采样。窗口大小为 4,步幅为 1。每个窗口产生一个 (input, target) 对,其中 target 是 input 右移一位的结果。
以下是一个自包含的滑动窗口 DataLoader 实现:
import tiktoken
import torch
from torch.utils.data import Dataset, DataLoader
class GPTDataset(Dataset):
"""滑动窗口式自回归语言模型数据集。
将一段长文本按固定窗口大小切分为 (input, target) 对,
其中 target 是 input 右移一位的结果。
Args:
text: 原始文本字符串
tokenizer: tiktoken 编码器实例
max_length: 窗口大小(等于模型上下文长度)
stride: 窗口滑动步幅
"""
def __init__(self, text: str, tokenizer, max_length: int, stride: int):
self.input_ids = []
self.target_ids = []
# 将整段文本编码为 token ID 列表
token_ids = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
# 滑动窗口切分
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i : i + max_length]
target_chunk = token_ids[i + 1 : i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self) -> int:
return len(self.input_ids)
def __getitem__(self, idx: int):
return self.input_ids[idx], self.target_ids[idx]
def create_dataloader(
text: str,
batch_size: int = 4,
max_length: int = 256,
stride: int = 128,
shuffle: bool = True,
drop_last: bool = True,
) -> DataLoader:
"""创建自回归语言模型的 DataLoader。
Args:
text: 原始文本
batch_size: 批大小
max_length: 上下文窗口长度
stride: 滑动步幅
shuffle: 是否打乱顺序
drop_last: 是否丢弃最后不足一个 batch 的样本
Returns:
PyTorch DataLoader 实例
"""
tokenizer = tiktoken.get_encoding("gpt2")
dataset = GPTDataset(text, tokenizer, max_length, stride)
return DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
)验证它的行为:
# 示例文本
sample_text = "The quick brown fox jumps over the lazy dog " * 100
dataloader = create_dataloader(
sample_text, batch_size=2, max_length=8, stride=8, shuffle=False
)
for inputs, targets in dataloader:
print("Inputs shape:", inputs.shape) # (2, 8)
print("Targets shape:", targets.shape) # (2, 8)
print("Inputs:\n", inputs)
print("Targets:\n", targets)
break步幅选择的权衡。 在实际预训练中,stride 通常设为与 max_length 相等,确保每个 token 恰好被覆盖一次——这在计算效率和数据利用率之间取得了最佳平衡。使用较小的步幅(如 stride = max_length // 2)会增加训练样本数量,但重叠部分的冗余会降低每个训练步骤的信息增益,且可能导致过拟合。
4.3.4 序列打包
上述滑动窗口方法有一个隐含假设:整段文本来自同一个文档。但实际预训练语料由成千上万篇独立文档拼接而成——新闻、书籍、代码、网页各不相同。如果滑动窗口跨越了两篇文档的边界,模型会被迫学习一种不存在的"跨文档上下文依赖",引入噪声。
序列打包(Sequence Packing)是工业级预训练管道的标准做法。其核心思想是:在每篇文档末尾插入特殊的 <|endoftext|> 分隔符,然后将多篇文档首尾相连拼接成一条长 token 流。滑动窗口在这条长流上滑动,当窗口内包含 <|endoftext|> 时,通过注意力掩码(attention mask)阻止跨文档的信息泄漏。
文档A的token... <|endoftext|> 文档B的token... <|endoftext|> 文档C的token...这种设计的优势在于:(1)每个 batch 的所有序列都恰好是 max_length 长度,不需要 padding,GPU 利用率达到 100%;(2)短文档不必单独占用一条序列的全部长度——多篇短文档可以被打包到同一个窗口中。相比于朴素的"一篇文档一条序列 + padding 对齐"方案,序列打包可以显著减少计算浪费,尤其当语料中包含大量短文本时。
对于预训练数据集构建,一种常见的简化实现是:先将所有文档 token 化并用 <|endoftext|> 拼接,然后按 stride = max_length 等步幅切分,不做显式的注意力掩码处理。这种方式牺牲了一小部分精度(窗口边界处可能产生跨文档的伪上下文),但工程上极为简洁。GPT-2 和许多开源预训练项目采用了这种策略。
4.3.5 内存友好的权重加载
图 4-12:DataLoader 的批处理流程。滑动窗口采样生成的 (input, target) 对被组织为 mini-batch,经过 collate 和 pin_memory 后送入 GPU 训练。
嵌入层在大型语言模型中占据可观的参数量。以 GPT-2 XL(15 亿参数)为例,仅 token 嵌入矩阵
朴素加载的内存问题。 标准的 PyTorch 权重加载流程如下:
model = GPTModel(config)
model.to(device) # 第一份:模型参数在 GPU 上
state_dict = torch.load("model.pth", map_location=device) # 第二份:加载的权重在 GPU 上
model.load_state_dict(state_dict) # 复制后丢弃 state_dict在 load_state_dict 完成之前,GPU 上同时存在模型参数和 state_dict 两份完整的权重副本,峰值显存是模型大小的 2 倍。对于 GPT-2 XL,这意味着峰值显存从 6.4 GB 飙升至 12.8 GB。
方案一:逐参数加载。 先将模型放到 GPU 上,将 state_dict 加载到 CPU 内存,然后逐个参数复制到 GPU:
model = GPTModel(config).to(device)
# state_dict 留在 CPU 内存,不占 GPU
state_dict = torch.load("model.pth", map_location="cpu", weights_only=True)
with torch.no_grad():
for name, param in model.named_parameters():
if name in state_dict:
param.copy_(state_dict[name].to(device))
del state_dict # 释放 CPU 内存这样 GPU 峰值显存仅略高于模型大小(多出一个参数张量的临时开销),从 12.8 GB 降至约 6.7 GB。代价是 CPU 内存需要容纳一份完整的 state_dict。
方案二:meta 设备 + 直接加载。 如果 CPU 内存也很有限,可以借助 PyTorch 的 meta 设备——它创建张量的元信息(形状、类型)但不分配实际存储:
with torch.device("meta"):
model = GPTModel(config) # 不分配任何实际内存
model = model.to_empty(device=device) # 在 GPU 上分配空间,但值未初始化
state_dict = torch.load("model.pth", map_location=device, weights_only=True)
with torch.no_grad():
for name, param in model.named_parameters():
if name in state_dict:
param.copy_(state_dict[name])这种方式将 CPU 内存消耗从数 GB 降至约 1 GB 级别,但 GPU 峰值显存会回到 2 倍(因为 state_dict 也在 GPU 上)。它适用于 "GPU 显存充裕但 CPU 内存紧张" 的场景。
方案三:mmap=True(推荐)。 PyTorch 的内存映射模式是最优雅的解决方案。它利用操作系统的虚拟内存机制,允许张量直接从磁盘文件读取数据,而不必将整个文件加载到 RAM:
with torch.device("meta"):
model = GPTModel(config)
model.load_state_dict(
torch.load("model.pth", map_location=device, weights_only=True, mmap=True),
assign=True,
)mmap=True 让操作系统按需将文件的页面映射到内存,实际物理内存使用取决于访问模式——在 RAM 充裕时性能与全量加载一致,在 RAM 紧张时则自动按需加载。assign=True 表示直接将加载的张量赋给模型参数(而不是复制),避免额外的内存分配。
safetensors 格式。 除了 PyTorch 原生的 .pth/.pt 格式,Hugging Face 推出的 safetensors 格式已成为社区事实标准。它具有三个关键优势:
- 安全性:
.pth文件基于 Python 的pickle序列化,可以嵌入任意代码执行——加载不可信来源的.pth文件存在安全风险。safetensors 采用纯数据格式,不允许执行代码。 - 零拷贝加载:safetensors 的文件布局支持内存映射(mmap),每个张量可以直接从文件的对应偏移量读取,无需反序列化整个文件。
- 跨框架兼容:同一个 safetensors 文件可以被 PyTorch、JAX、TensorFlow 等框架直接加载。
使用 safetensors 库加载权重的代码非常简洁:
from safetensors.torch import load_model
model = GPTModel(config)
load_model(model, "model.safetensors", device=str(device))下表总结了各种权重加载方式的内存特性:
| 加载方式 | GPU 峰值 | CPU 峰值 | 适用场景 |
|---|---|---|---|
朴素 load_state_dict | 2× 模型大小 | 中 | 内存充裕的开发环境 |
| 逐参数加载(CPU 中转) | ~1× 模型大小 | 1× 模型大小 | GPU 显存受限 |
meta 设备 + GPU 直接加载 | 2× 模型大小 | 极低 | CPU 内存受限 |
mmap=True + assign=True | ~1× 模型大小 | 按需 | 通用推荐方案 |
| safetensors | ~1× 模型大小 | 按需 | 社区模型分发标准 |
表 4-3:不同权重加载方式的内存占用对比。"按需"表示由操作系统内存映射机制管理,实际占用取决于可用物理内存。
本节小结
本节覆盖了从 token ID 到模型训练的完整数据通路:
- Token 嵌入将离散的整数 ID 映射为可学习的稠密向量,本质上是权重矩阵的行查找操作。位置嵌入注入序列顺序信息,与 token 嵌入相加后构成 Transformer 的输入。
- 滑动窗口采样用固定大小的窗口在 token 序列上滑动,每个窗口生成一个 (input, target) 对,target 是 input 右移一位的结果。步幅与窗口大小相等时效率最高。
- 序列打包将多篇文档用分隔符拼接后统一切分,避免 padding 浪费,是工业级预训练管道的标准做法。
- 权重加载在大模型场景下需要特别关注内存管理。逐参数加载、
meta设备、mmap内存映射和 safetensors 格式分别从不同维度优化了峰值内存占用,其中mmap=True配合 safetensors 是当前推荐的通用方案。