18.3 策略优化进阶
在 §15.7 中,我们从数学机制的角度剖析了熵崩溃与奖励崩溃的成因;在 §16.4 中,我们详述了 DAPO、Dr.GRPO、GSPO 等 GRPO 工程变体的算法设计。本节将视角从"算法原理"切换到"训练实操":当你真正启动一个推理模型的 RL 训练后,应该监控哪些指标、如何解读曲线、何时干预、按什么顺序调参。推理模型训练与通用 RLHF 相比有其独特挑战——长思维链(Long CoT)带来的超长序列、基于规则的稀疏奖励、格式奖励与正确性奖励的多目标博弈,都需要更精细的策略优化实践。
18.3.1 核心监控指标体系
一个完善的推理模型 RL 训练看板至少需要追踪以下六类指标。我们按重要程度排列,并给出每个指标在推理模型场景下的特殊含义。
| 指标 | 定义 | 推理模型中的特殊含义 |
|---|---|---|
| 优势统计量(Advantage Mean/Std) | 组内归一化后的优势值均值与标准差 | 反映当前 prompt 难度分布是否合理 |
| 策略熵(Policy Entropy) | 推理模型需要维持较高熵以保持探索能力 | |
| 策略比率(Policy Ratio) | 离线程度的直接度量,过大则 mini-batch 数据已"过时" | |
| KL 散度 | 控制策略偏离参考模型的幅度 | |
| 奖励分解(Reward Breakdown) | 正确性奖励 + 格式奖励的独立曲线 | 检测奖励崩溃和格式奖励压制正确性信号 |
| 生成长度(Response Length) | 平均生成 token 数 | 推理模型中长度是核心观测量,直接关联探索深度 |
下面的代码展示了如何在训练循环中实现完整的指标追踪。注意我们对优势值、熵、策略比率三个维度做了独立记录:
import torch
from dataclasses import dataclass, field
from typing import List, Dict
@dataclass
class TrainingMetrics:
"""推理模型 RL 训练的指标追踪器"""
step: int = 0
history: Dict[str, List[float]] = field(default_factory=lambda: {
"reward_avg": [], "reward_correct": [], "reward_format": [],
"adv_mean": [], "adv_std": [],
"entropy_avg": [], "policy_ratio": [],
"kl_divergence": [], "response_length": [],
"clip_fraction": [], "zero_adv_ratio": [],
})
def log_step(self, stats: dict):
"""记录单步训练指标"""
self.step += 1
rewards = torch.tensor(stats["rewards"])
advantages = torch.tensor(stats["advantages"])
self.history["reward_avg"].append(rewards.mean().item())
self.history["adv_mean"].append(advantages.mean().item())
self.history["adv_std"].append(advantages.std().item())
self.history["entropy_avg"].append(
torch.tensor(stats["entropies"]).mean().item()
)
# 策略比率:若接近 1.0 说明在线学习,偏离 1.0 说明离线偏差加大
if "policy_ratio" in stats and stats["policy_ratio"] is not None:
self.history["policy_ratio"].append(stats["policy_ratio"])
# KL 散度
if "kl_loss" in stats:
self.history["kl_divergence"].append(stats["kl_loss"])
# 生成长度
avg_len = sum(s["gen_len"] for s in stats["samples"]) / len(stats["samples"])
self.history["response_length"].append(avg_len)
def check_alerts(self) -> List[str]:
"""检测异常信号,返回告警信息列表"""
alerts = []
if len(self.history["entropy_avg"]) < 20:
return alerts
recent_entropy = self.history["entropy_avg"][-10:]
early_entropy = self.history["entropy_avg"][:10]
# 告警 1:熵骤降超过 50%
if sum(recent_entropy) / 10 < sum(early_entropy) / 20:
alerts.append(
f"[Step {self.step}] 熵骤降警告: "
f"近 10 步均值 {sum(recent_entropy)/10:.3f} "
f"< 前 10 步均值的 50%"
)
# 告警 2:优势标准差持续为零(全对或全错)
recent_adv_std = self.history["adv_std"][-10:]
zero_ratio = sum(1 for s in recent_adv_std if s < 1e-6) / 10
if zero_ratio > 0.5:
alerts.append(
f"[Step {self.step}] 无效梯度警告: "
f"近 10 步中 {zero_ratio*100:.0f}% 的优势标准差为零"
)
# 告警 3:生成长度失控暴增
recent_len = self.history["response_length"][-10:]
early_len = self.history["response_length"][:10]
if sum(recent_len) / 10 > sum(early_len) / 10 * 3:
alerts.append(
f"[Step {self.step}] 长度暴增警告: "
f"近 10 步均值 {sum(recent_len)/10:.0f} "
f"> 初期均值的 3 倍"
)
return alerts代码要点:
check_alerts方法实现了三条最关键的自动告警规则——熵骤降、无效梯度、长度暴增。在实际训练中,这三种信号往往先于奖励曲线下跌出现,是最早的"危险预兆"。
18.3.2 优势值的计算与监控
优势值(Advantage) 是策略梯度的核心驱动力。在推理模型场景下,优势值的计算有两个特殊之处值得关注。
第一,稀疏奖励放大了优势的方差。 数学推理任务通常使用二值奖励(正确得 1 分、错误得 0 分),这使得组内奖励的分布极端——要么大部分正确(优势集中在负半轴),要么大部分错误(优势集中在正半轴)。当一组采样全对或全错时,标准差为零,归一化优势全为零,这一步没有任何梯度信号。
这就是 DAPO 动态采样(Dynamic Sampling)要解决的问题。从监控角度,我们应关注零优势比率(Zero-Advantage Ratio):每一步中优势标准差低于阈值的 prompt 占比。如果这个比率持续上升(超过 30%),说明当前数据难度分布与模型能力已经严重不匹配——模型要么已经掌握了大部分训练题,要么还完全无法解答。
第二,优势归一化方式影响多目标学习。 当总奖励由正确性和格式两部分组成时,标准 GRPO 的"先求和后归一化"会抹平优先级(详见 §15.7.5)。在训练监控中,应当独立绘制各维度奖励的曲线。如果格式奖励快速上升而正确性奖励停滞,很可能发生了奖励崩溃——模型学会了"格式正确但内容错误"的策略。
下面的代码展示了完整的优势计算流程,包含跳过零优势的逻辑和格式奖励的分离追踪:
import torch
def compute_advantages_with_format(
correctness_rewards: torch.Tensor, # [G] 正确性奖励
format_rewards: torch.Tensor, # [G] 格式奖励
format_weight: float = 0.3,
eps: float = 1e-4,
use_gdpo: bool = True,
):
"""计算带格式奖励的优势值,支持 GDPO 解耦归一化"""
if use_gdpo:
# GDPO: 独立归一化后加权求和
c_norm = (correctness_rewards - correctness_rewards.mean()) / (
correctness_rewards.std() + eps
)
f_norm = (format_rewards - format_rewards.mean()) / (
format_rewards.std() + eps
)
advantages = c_norm + format_weight * f_norm
else:
# 标准 GRPO: 先求和后归一化
total = correctness_rewards + format_weight * format_rewards
advantages = (total - total.mean()) / (total.std() + eps)
is_zero = torch.allclose(advantages, torch.zeros_like(advantages), atol=1e-8)
return advantages, is_zero18.3.3 策略熵:推理模型的生命体征
策略熵在推理模型训练中的角色比通用 RLHF 更加关键。通用对齐任务中,熵稳步下降通常是健康的收敛信号;但推理模型需要持续探索不同推理路径,熵过早下降就意味着模型丧失了试错能力。
推理模型中的健康熵行为有三个判据:
- 熵保持稳定或缓慢下降——而非骤降。经验值是整个训练周期内熵的下降幅度不超过初始值的 40%。
- 生成长度同步上升——熵稳定的同时响应变长,说明模型在更广阔的空间中搜索答案,属于健康探索。
- 熵与正确率正相关——当验证集准确率上升时,训练熵没有同步骤降,说明模型是在"聪明地探索"而非"死记硬背"。
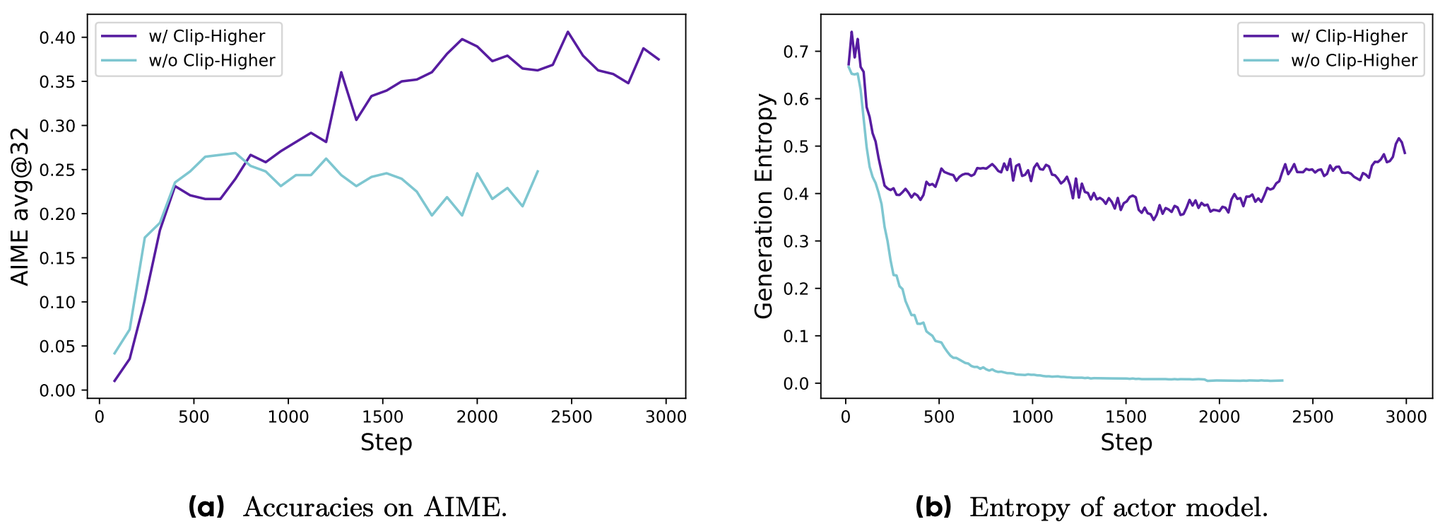
图 18-5:Clip-Higher 策略对推理模型熵和准确率的影响。左图为 AIME 数学竞赛准确率,右图为策略熵。不使用 Clip-Higher 时,熵在约 200 步内崩溃至零,探索能力完全丧失;采用 Clip-Higher 后,熵稳定在 0.4-0.5 的健康区间,准确率持续攀升。
熵的计算方法。 在实现层面,熵的计算需要遍历词表上的完整概率分布。下面的函数同时返回序列对数概率和逐 token 熵的均值:
import torch
def sequence_logprob_and_entropy(
logits: torch.Tensor, # [1, seq_len, vocab_size]
token_ids: torch.Tensor, # [seq_len]
prompt_len: int,
) -> tuple:
"""计算生成部分的序列对数概率和平均熵"""
logits = logits.squeeze(0).float()
logprobs = torch.log_softmax(logits, dim=-1)
# 选取实际生成的 token 的 log-prob
targets = token_ids[1:]
selected = logprobs[:-1].gather(1, targets.unsqueeze(-1)).squeeze(-1)
answer_logprobs = selected[prompt_len - 1:]
total_logp = answer_logprobs.sum()
# 逐 token 计算熵: H = -sum(p * log p)
answer_logprobs_full = logprobs[:-1][prompt_len - 1:]
if answer_logprobs_full.numel() == 0:
return total_logp, torch.tensor(0.0)
probs = torch.exp(answer_logprobs_full)
step_entropy = -(probs * answer_logprobs_full).sum(dim=-1) # [T]
mean_entropy = step_entropy.mean()
return total_logp, mean_entropy工程细节:计算熵时使用
log_softmax而非先算softmax再取log,数值更稳定,避免在极低概率区域出现 NaN。
18.3.4 裁剪比率与策略比率的解读
裁剪比率(Clip Fraction) 和 策略比率(Policy Ratio) 是两个容易混淆但含义不同的指标。
- 策略比率
衡量的是新旧策略在同一 token 上的概率之比。它反映了一次更新中策略变化的幅度。理想值接近 1.0;若均值偏离 1.0 超过 ,说明更新步长过大或数据已严重离线。 - 裁剪比率 是被裁剪函数截断的 token 占总 token 的比例。它反映了裁剪机制实际生效的频率。在标准 GRPO 中典型值约 0.1-0.3;GSPO 由于在序列级操作,裁剪比率可达 0.15,但其含义截然不同。
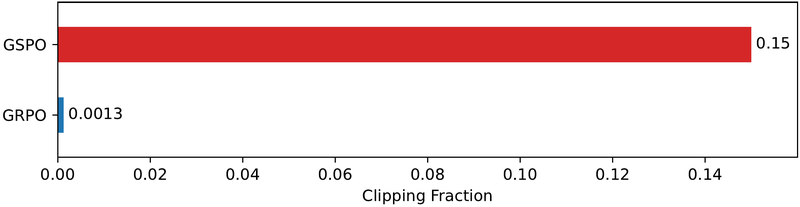
图 18-6:GSPO 与 GRPO 的裁剪比率对比。GSPO 裁剪了约 15% 的样本,GRPO 仅裁剪 0.13%,两者相差约两个数量级。然而 GSPO 的训练效率更高——"更少但更干净的梯度"胜过"更多但嘈杂的梯度"。
在推理模型训练中,裁剪比率的变化趋势尤为重要:
- 裁剪比率持续上升:说明新旧策略差异越来越大,通常意味着 rollout batch 中的 mini-batch 迭代次数过多或学习率过高。此时应减少内部迭代轮数(
inner_epochs)或降低学习率。 - 裁剪比率骤降至零:说明策略几乎没有更新,可能是梯度消失或所有样本的优势为零。
下面的代码演示了如何在 PPO 风格的裁剪目标函数中同时计算损失和裁剪统计量:
import torch
def clipped_policy_loss(
new_logps: torch.Tensor, # [G] 当前策略的序列 log-prob
old_logps: torch.Tensor, # [G] 旧策略的序列 log-prob
advantages: torch.Tensor, # [G] 优势值
clip_eps: float = 10.0,
) -> dict:
"""带裁剪统计的策略梯度损失"""
log_ratio = new_logps - old_logps.detach()
ratio = torch.exp(log_ratio)
clipped_ratio = torch.clamp(ratio, 1.0 - clip_eps, 1.0 + clip_eps)
adv = advantages.detach()
unclipped = ratio * adv
clipped = clipped_ratio * adv
# PPO 目标:正优势取 min,负优势取 max
obj = torch.where(
adv >= 0,
torch.minimum(unclipped, clipped),
torch.maximum(unclipped, clipped),
)
loss = -obj.mean()
# 裁剪统计
clip_fraction = (ratio != clipped_ratio).float().mean().item()
mean_ratio = ratio.mean().item()
return {
"loss": loss,
"clip_fraction": clip_fraction,
"mean_ratio": mean_ratio,
}18.3.5 KL 散度:推理模型中的特殊考量
KL 散度惩罚项在推理模型训练中的角色颇具争议。§16.4.1 已经提到,多项研究发现在数学推理任务上移除 KL 约束反而效果更好。但这并不意味着 KL 项毫无价值——关键在于分场景使用。
推理模型训练中 KL 项的三种策略:
| 策略 | KL 系数 | 适用场景 | 代表工作 |
|---|---|---|---|
| 完全移除 | 纯数学/代码推理,基于规则验证 | DAPO、Dr.GRPO | |
| 分域调控 | 数学域 | 多任务混合训练 | DeepSeek-V3.2 |
| 重加权 KL | 对不同 token 位置使用不同 KL 强度 | 需要保持通用能力的推理模型 | DeepSeek-V3.2 |
完全移除 KL 约束的逻辑是:推理模型的训练数据通常配有可验证的正确答案(数学公式、代码测试用例),奖励信号是可靠的,不存在 reward hacking 的风险,因此不需要用 KL 项把策略"拉回"参考模型附近。
但一旦训练数据包含不可完全验证的维度(如代码的风格、解释的清晰度),或者奖励模型存在偏见,KL 约束就重新变得必要。监控看板上应独立绘制 KL 散度曲线——如果 KL 持续上升且奖励曲线开始震荡,说明策略已经偏离参考模型过远,需要启用或加大 KL 系数。
import torch
def compute_kl_loss(
new_logps: torch.Tensor, # [G] 当前策略 log-prob
ref_logps: torch.Tensor, # [G] 参考模型 log-prob
kl_coeff: float = 0.001,
) -> torch.Tensor:
"""计算 KL 散度惩罚项(简化版本,使用序列级 log-prob 差)"""
# KL 散度近似:D_KL(π_θ || π_ref) ≈ E[log π_θ - log π_ref]
kl = torch.mean(new_logps - ref_logps.detach())
return kl_coeff * kl18.3.6 格式奖励与多目标优化
推理模型通常需要输出结构化的推理过程,如 <think>...</think> 标签包裹的思维链。格式奖励(Format Reward) 用于引导模型养成这种输出习惯。
格式奖励的实现非常直观——检查生成的 token 序列中是否正确出现了特定的标记:
import torch
THINK_TOKEN_ID = 151667 # <think> 的 token ID
END_THINK_TOKEN_ID = 151668 # </think> 的 token ID
def reward_format(token_ids: torch.Tensor, prompt_len: int) -> float:
"""检查输出是否包含正确的 <think>...</think> 格式"""
try:
gen = token_ids[prompt_len:].tolist()
# 要求 <think> 出现在 </think> 之前
return float(gen.index(THINK_TOKEN_ID) < gen.index(END_THINK_TOKEN_ID))
except ValueError:
return 0.0 # 缺少任一标签则格式不合格格式奖励的权重设置是一个微妙的平衡问题。权重过大,模型会"形式大于内容"——学会输出空洞的思维链;权重过小,格式引导失效。实践中的推荐做法:
- 起步阶段使用较高的格式权重(如 1.0),帮助模型快速建立结构化输出的习惯。
- 格式奖励稳定在高位后(例如超过 0.9),逐步降低权重(如降至 0.1-0.3),让正确性信号占据主导。
- 使用 GDPO 解耦归一化(§15.7.6)而非简单求和,避免格式奖励压制正确性信号。
18.3.7 训练监控仪表盘:端到端示例
将上述指标整合在一起,下面展示一个完整的训练监控输出示例。每一步的日志信息应包含所有关键维度:
[Step 150/500] loss=0.42 reward_avg=0.625 format_reward_avg=0.875
kl=0.003 tok/sec=2450.3 avg_resp_len=287.4
adv_avg=0.00 adv_std=0.82 entropy_avg=0.47 policy_ratio=1.02从这一行日志中可以读出:
- reward_avg=0.625:约 62.5% 的采样回答正确,难度适中,有学习信号。
- format_reward_avg=0.875:格式奖励已接近饱和,可以考虑降低格式权重。
- entropy_avg=0.47:熵处于健康区间,探索能力充足。
- adv_std=0.82:优势标准差不为零,梯度信号有效。
- policy_ratio=1.02:策略变化幅度很小,训练稳定。
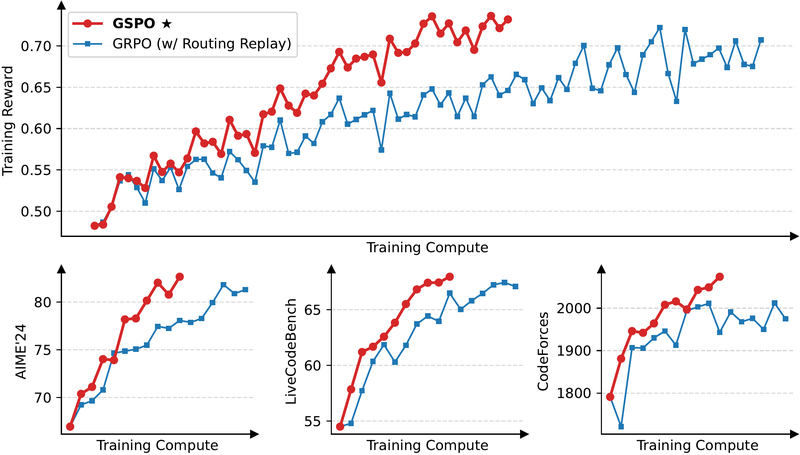
图 18-7:典型的推理模型 RL 训练曲线(GSPO vs GRPO,基于 Qwen3-30B-A3B)。训练奖励曲线稳步上升且方差可控是健康信号;三个下游基准同步提升表明训练泛化良好。
当以下任一条件触发时,应立即暂停训练并排查原因:
| 危险信号 | 可能原因 | 建议干预措施 |
|---|---|---|
| 熵在 100 步内下降超过 50% | 对称裁剪导致马太效应 | 启用 Clip-Higher( |
| 零优势比率 > 30% | 数据难度与模型能力不匹配 | 启用 Dynamic Sampling,调整数据配比 |
| 生成长度 > 初始值的 3 倍 | 复读机模式或超长推理链 | 启用 Overlong Reward Shaping |
| KL 散度持续单调上升 | 策略过度偏离参考模型 | 增大 KL 系数或检查奖励信号是否可靠 |
| 训练集奖励上升但验证集停滞 | Reward hacking 或过拟合 | 扩充训练数据,加入 KL 约束 |
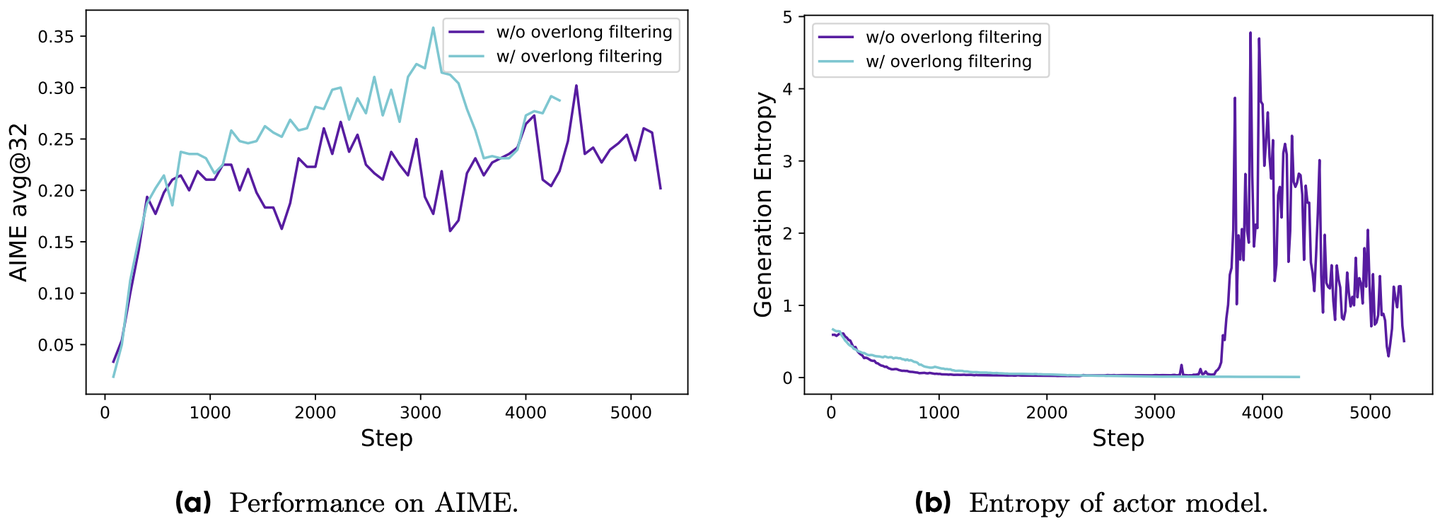
图 18-8:Overlong Reward Shaping 消融实验。左图为准确率,右图为熵。不使用超长过滤时,截断样本的噪声奖励导致熵在第 3000 步附近开始剧烈震荡,准确率随之波动;使用超长过滤后,训练全程保持平稳。
18.3.8 调参优先级与实践建议
推理模型 RL 训练的超参数空间很大,但实践表明调参有明确的优先级序列——按以下顺序逐一排查,通常能用最少的实验次数找到合理配置。
第一优先级:数据层面。
- 确保训练数据的难度梯度合理,避免过多"全对"或"全错"的 prompt。
- 启用 Dynamic Sampling 过滤零梯度样本。
第二优先级:裁剪策略。
- 使用非对称裁剪(Clip-Higher),推荐
, 。 - 对于 MoE 模型或超长序列场景,优先考虑 GSPO 的序列级裁剪。
第三优先级:KL 与学习率。
- 纯推理任务(数学、代码):从
开始,仅在观察到奖励震荡时引入 KL 约束。 - 学习率建议从
起步,DAPO 推荐值为 配合 20 步线性预热。
第四优先级:采样与生成参数。
- 组大小(Group Size)
:推荐 8-16。 过小导致优势估计方差大, 过大则计算代价高。 - Temperature:推荐 0.8-1.0。推理模型需要较高温度维持多样性。
- Top-p:推荐 0.9-0.95。
本节小结
推理模型的策略优化不仅需要正确的算法设计,更需要系统化的监控和调优流程。核心要点如下:
- 建立完整的指标体系:优势统计量、策略熵、策略比率、KL 散度、奖励分解、生成长度六个维度缺一不可。
- 熵是推理模型最重要的生命体征:推理模型需要维持较高熵以保持探索能力,熵骤降是最早的危险信号,应通过 Clip-Higher 等机制预防。
- 裁剪比率的"反直觉"启示:更高的裁剪比率不一定意味着更差的训练——GSPO 用更多裁剪换来了更干净的梯度信号。
- KL 约束按需使用:纯推理任务可移除 KL 项;混合任务或不可靠奖励场景下,KL 约束仍然是不可或缺的安全阀。
- 调参遵循优先级序列:数据 > 裁剪策略 > KL 与学习率 > 采样参数,避免在低优先级参数上浪费实验预算。