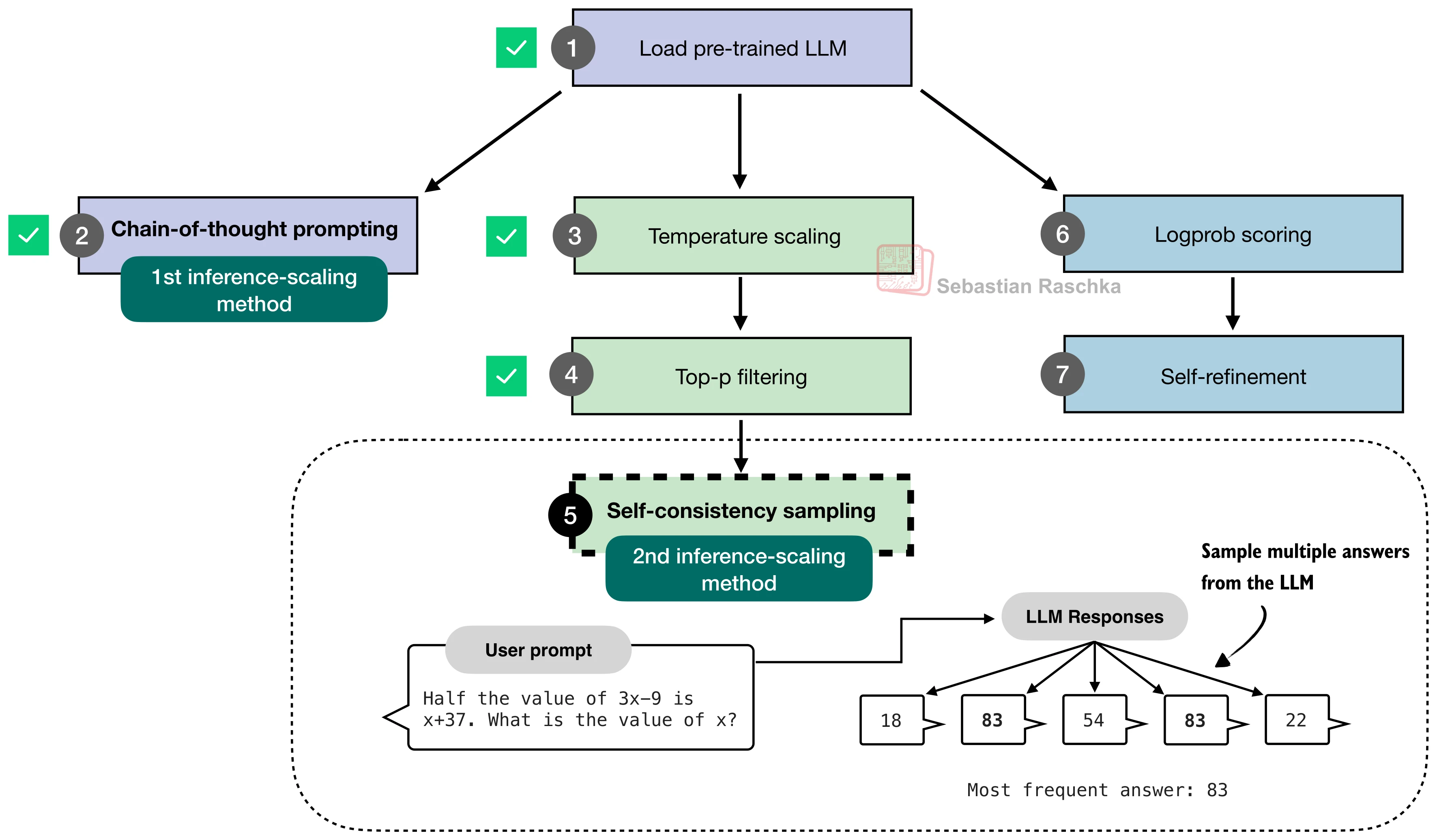
26.3 推理时间缩放实验
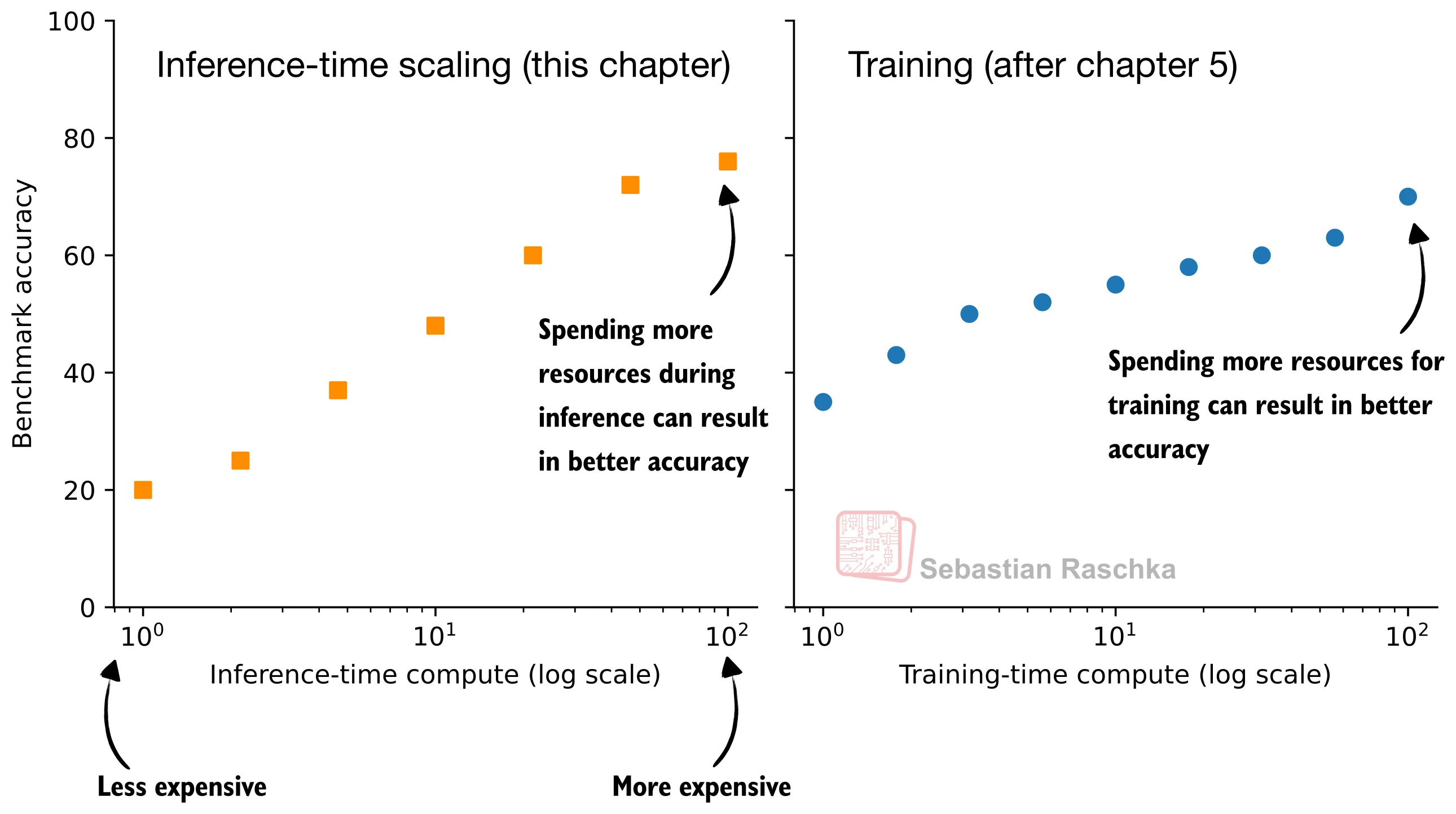
上一节搭建了从答案提取到符号等价判定的完整评估框架。有了自动评分能力,本节正式进入推理时间缩放(Inference-Time Scaling) 的实验。核心问题是:在不重新训练模型的前提下,仅在推理阶段投入更多计算资源,能否系统性地提升模型的推理准确率?
传统的模型改进路径是训练时间缩放(Train-Time Scaling)——增大模型参数、扩充训练数据、延长训练时间。推理时间缩放则提供了一条互补路径:通过精心设计的采样策略、多轮投票和迭代改进,让一个固定的模型在推理阶段"思考得更久、更深"。
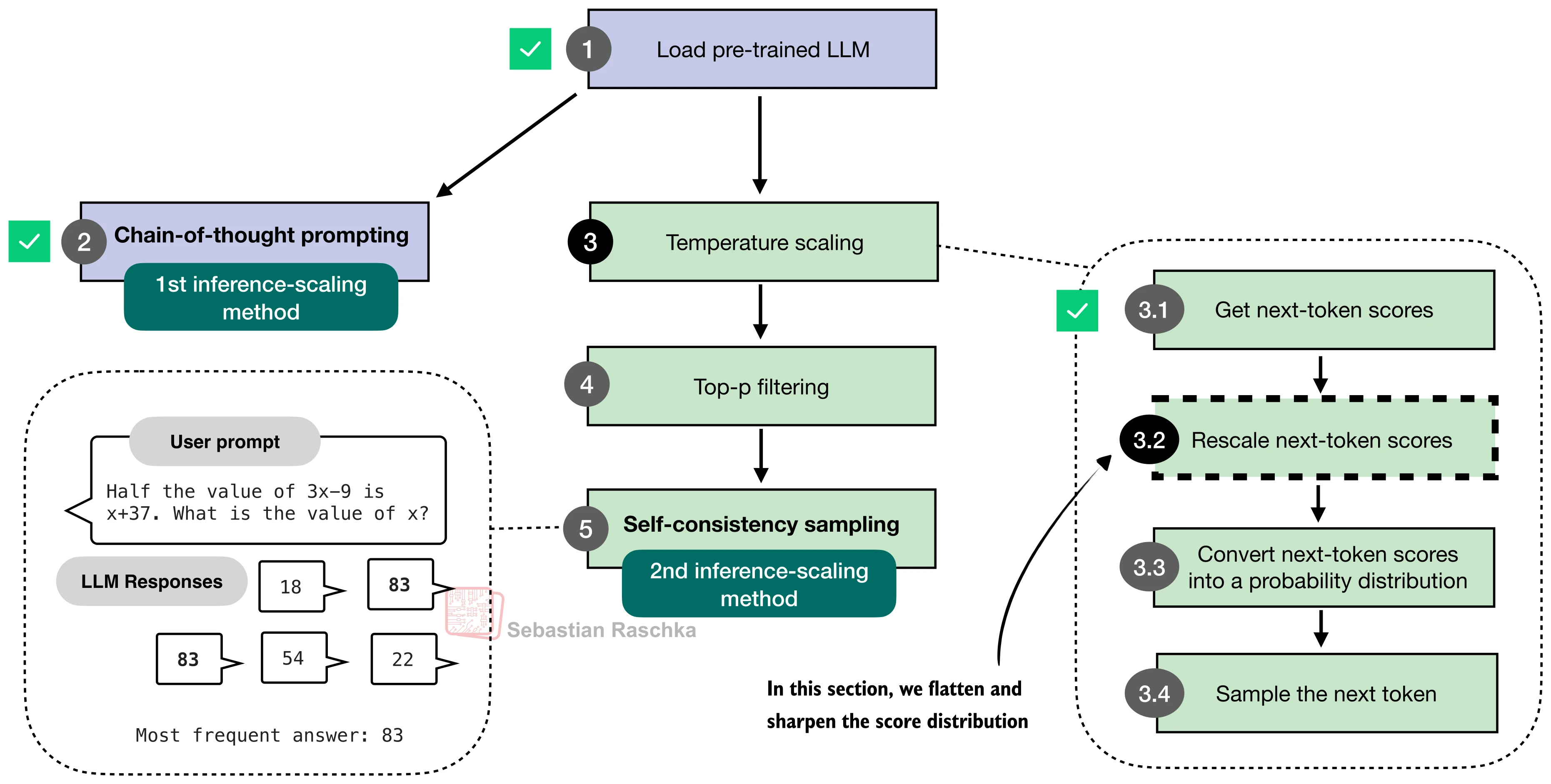
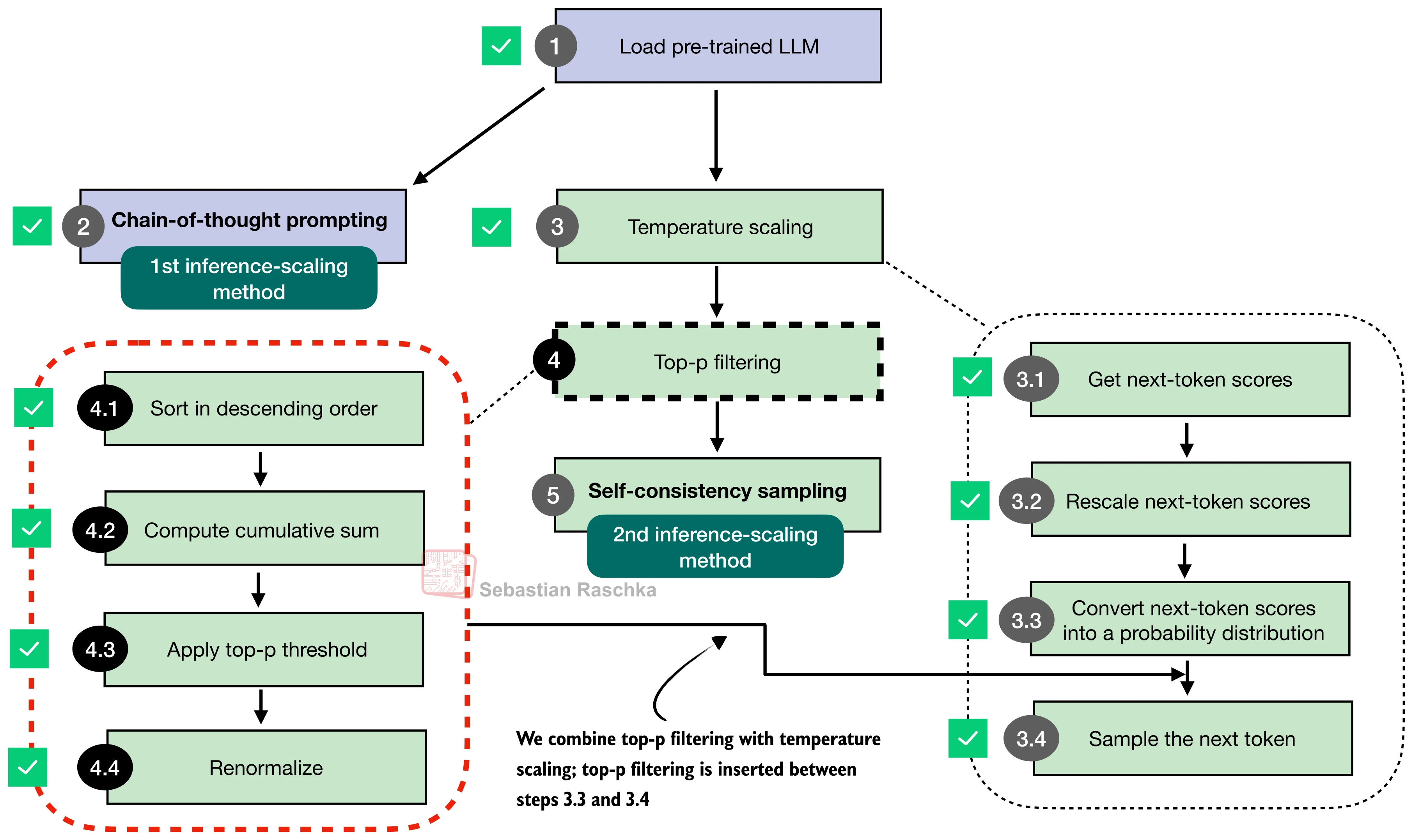
本节将依次实现五种推理时间缩放方法——链式思维提示(CoT)、温度缩放与 top-p 采样、自一致性投票(Self-Consistency)、Best-of-N 选择、自改进(Self-Refinement)——并在 MATH-500 上对比它们的效果。下图给出了这些方法的全景视图:
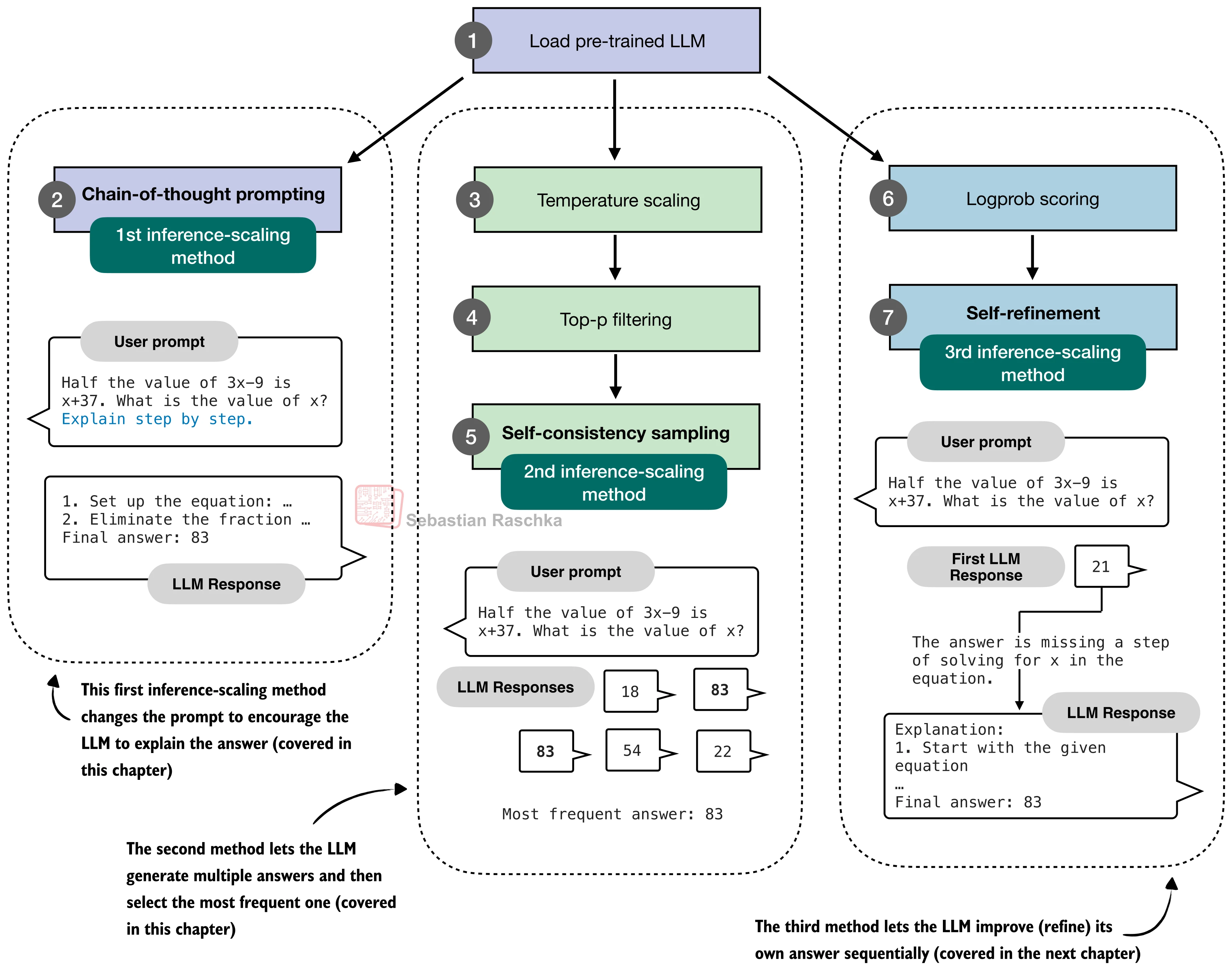
一、链式思维提示(Chain-of-Thought Prompting)
最简单也最有效的推理时间缩放方法是修改提示,引导模型在给出最终答案前先生成推理步骤。
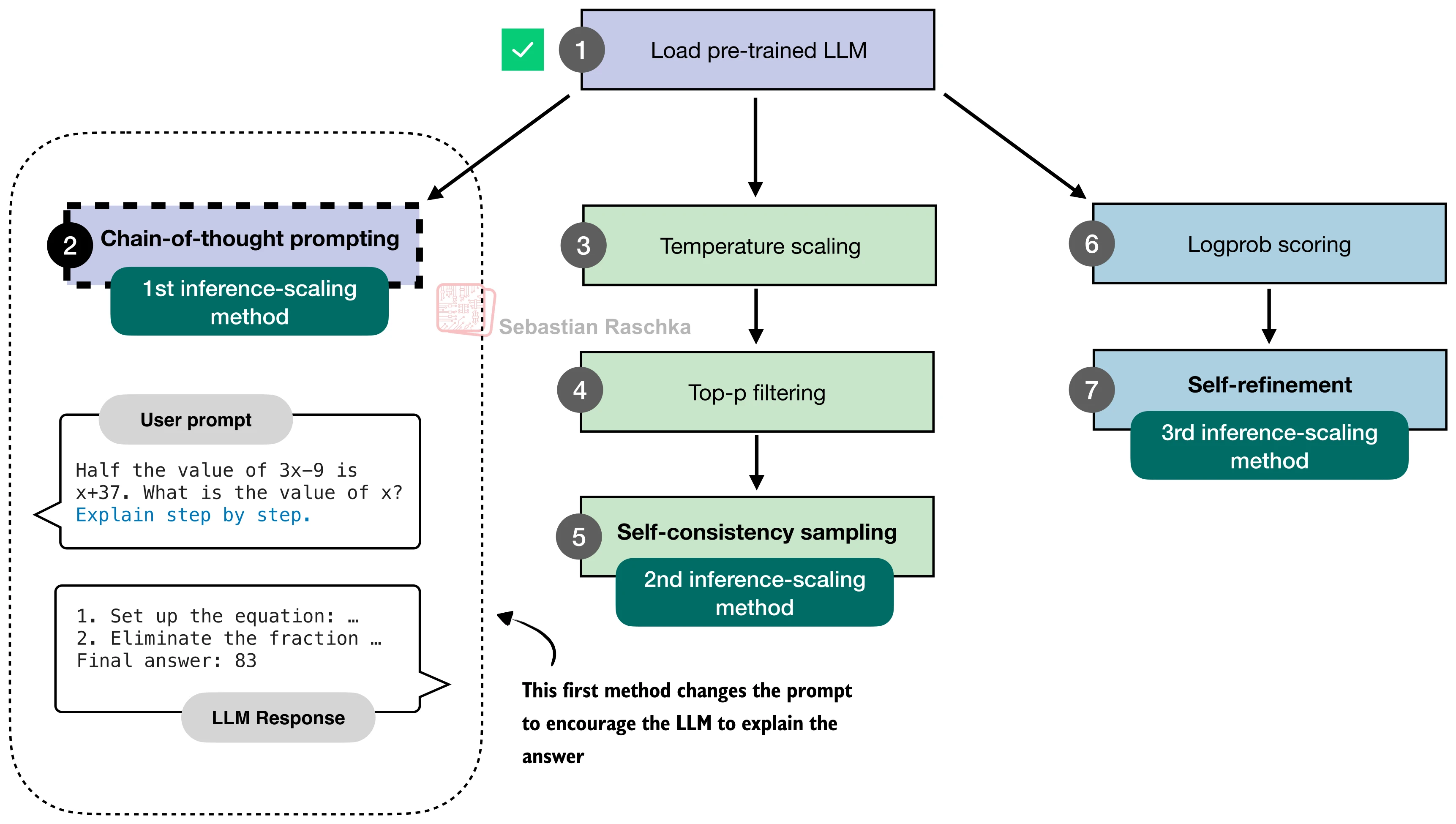
实现非常直接——在标准提示末尾追加一句指令:
prompt_cot = prompt + " \n\nExplain step by step."这一简单修改带来的效果令人惊讶。以题目"Half the value of \boxed{20}(错误),而加入 CoT 提示后,模型会逐步列出方程、消除分数、移项、求解,最终正确得到 \boxed{83}。
CoT 提示之所以有效,直觉在于:模型被迫生成中间推理步骤时,每一步的输出都成为下一步的上下文,相当于在自回归生成过程中构建了一条隐式的"草稿纸"。这让模型能够解决需要多步推理的问题——而在直接给出答案时,这些中间状态无处安放。
在 MATH-500 上的实测结果显示,仅凭 CoT 提示就能将 0.6B 基座模型的准确率从 15.2% 提升到 40.6%,代价是生成时间从 10 分钟增加到约 85 分钟(因为要生成更长的推理链)。
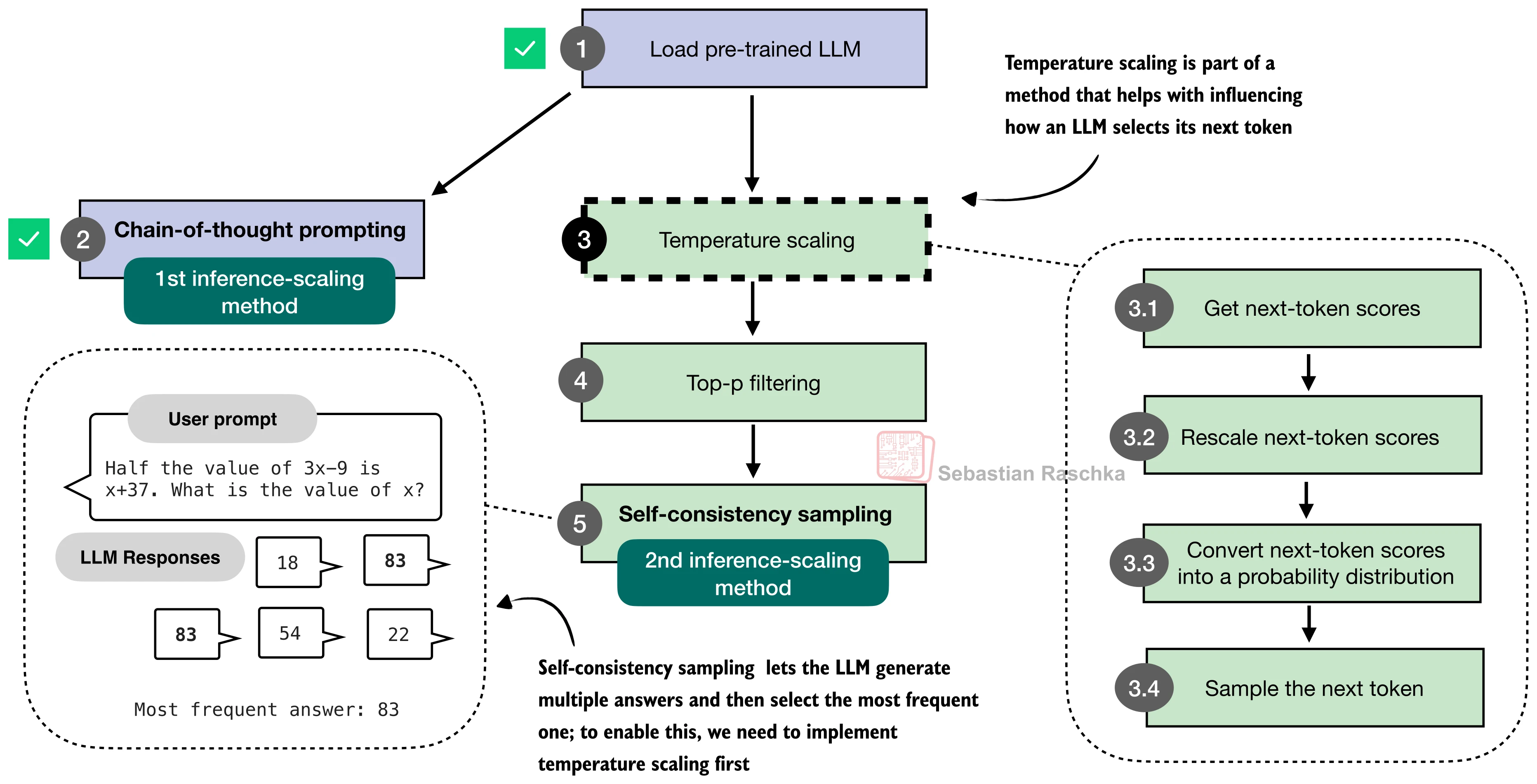
二、温度缩放与随机采样
CoT 提示解决了"如何让模型思考"的问题,但模型的输出仍然是确定性的——在贪心解码(greedy decoding)下,同一个输入永远得到同一个输出。要实现后续的多样本投票和选择策略,首先需要让模型能够生成多样化的回答。这就引出了温度缩放(Temperature Scaling)和随机采样。
温度参数的作用
回忆 LLM 的生成过程:在每一步,模型输出一个覆盖整个词表的 logit 向量
- 当
时,logit 之间的差异被放大,概率分布变得更尖锐,高概率 token 占据更大份额; - 当
时,差异被压缩,分布变平,低概率 token 获得更多被选中的机会; - 当
时,退化为贪心解码(始终选择最高概率 token)。
代码实现非常简洁:
def scale_logits_by_temperature(logits, temperature):
if temperature <= 0:
raise ValueError("Temperature must be positive")
return logits / temperature从概率分布中采样
温度调整后的 logit 经过 softmax 转换为概率分布,然后通过多项式采样(multinomial sampling) 随机选取下一个 token:
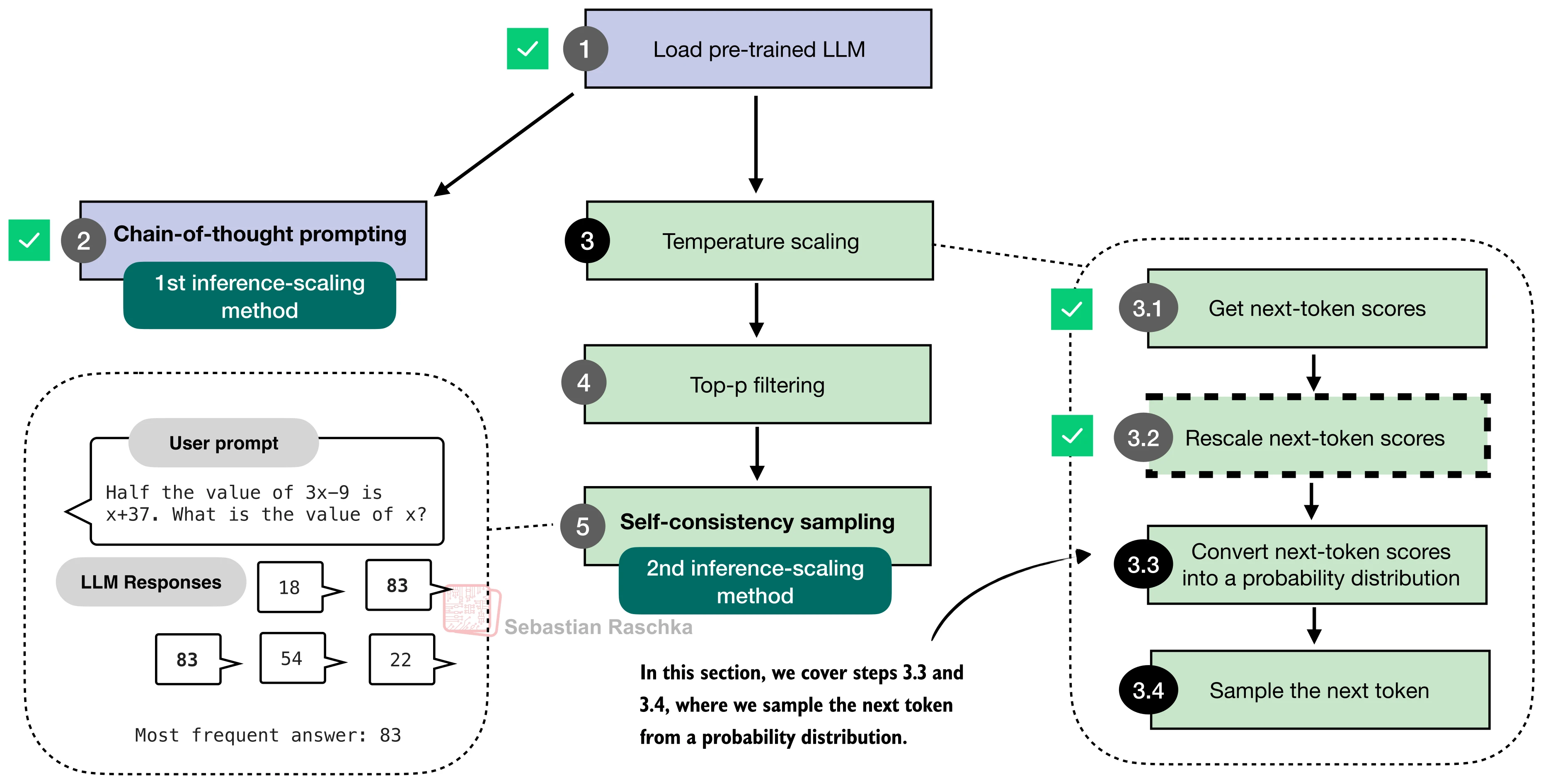
# 温度缩放 → softmax → 采样
rescaled_logits = scale_logits_by_temperature(logits, temperature)
probas = torch.softmax(rescaled_logits, dim=-1)
next_token = torch.multinomial(probas, num_samples=1)温度过高时采样会过于随机("The capital of Germany is mistress"),温度过低时又缺乏多样性。实践中
Top-p 核采样
纯温度缩放有一个问题:即使在合理的温度下,词表中仍存在大量极低概率的"噪声"token。Top-p 采样(Nucleus Sampling) 通过动态截断解决了这个问题:
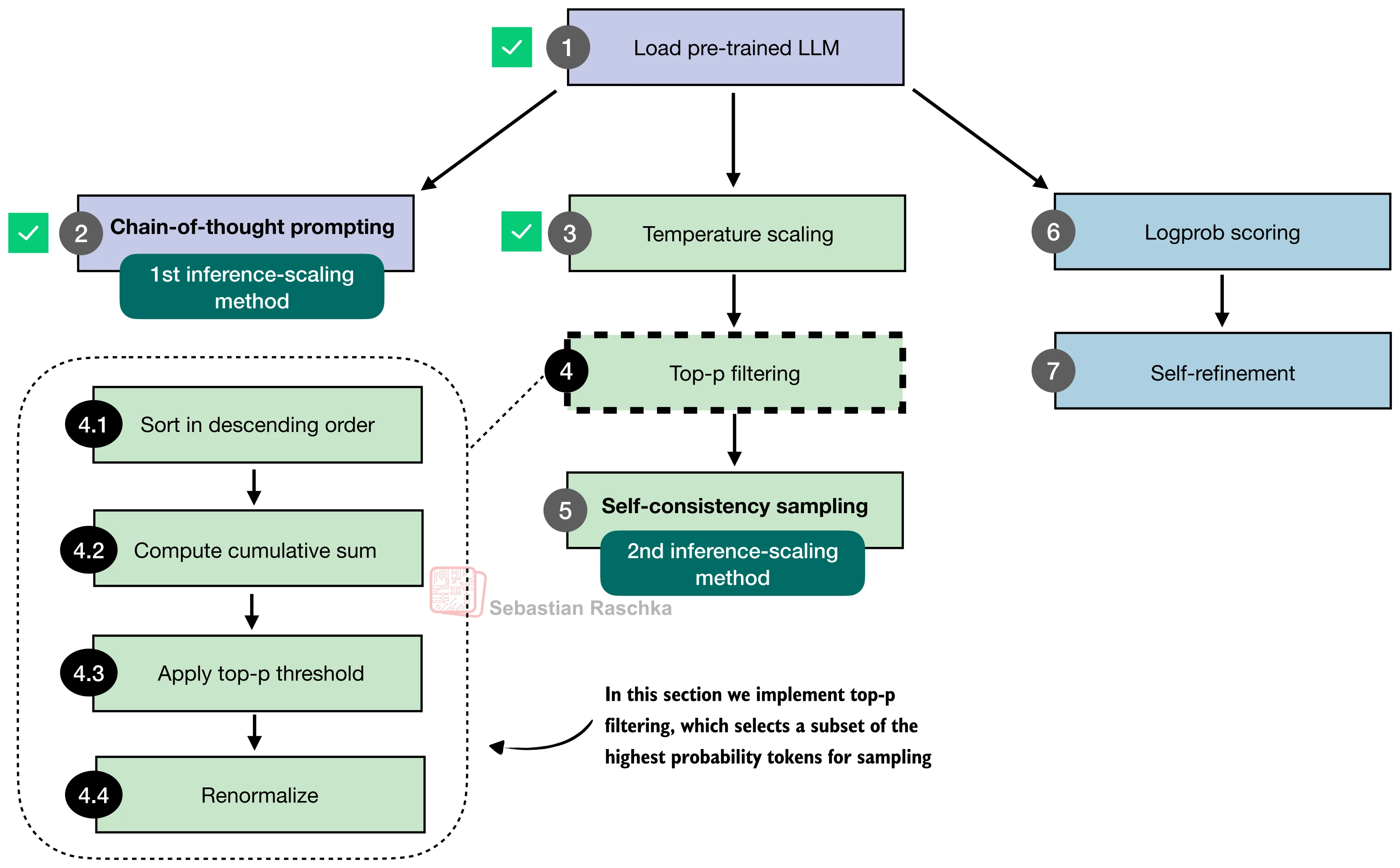
算法步骤如下:
- 将所有 token 按概率降序排列;
- 计算累积概率,找到使累积和首次超过阈值
的位置; - 丢弃排在该位置之后的所有 token;
- 对保留的 token 重新归一化概率。
def top_p_filter(probas, top_p):
if top_p is None or top_p >= 1.0:
return probas
# 按概率降序排列
sorted_probas, sorted_idx = torch.sort(probas, dim=1, descending=True)
# 计算每个 token 之前的累积概率
cumprobas = torch.cumsum(sorted_probas, dim=1)
prefix = cumprobas - sorted_probas
# 保留累积前缀 < top_p 的 token
keep = prefix < top_p
keep[:, 0] = True # 至少保留一个 token
# 截断并重新归一化
kept_sorted = torch.where(keep, sorted_probas, torch.zeros_like(sorted_probas))
filtered = torch.zeros_like(probas).scatter(1, sorted_idx, kept_sorted)
return filtered / torch.sum(filtered, dim=1, keepdim=True).clamp_min(1e-12)以"The capital of Germany is"为例,在
三、自一致性投票(Self-Consistency)
有了随机采样能力,就可以实现一种朴素但强大的策略——自一致性(Self-Consistency)。核心思想来自 Wang 等人 (2023) 的论文 Self-Consistency Improves Chain of Thought Reasoning in Language Models:对同一个问题多次采样,提取每次的最终答案,然后通过多数投票(Plurality Vote) 选出出现频率最高的答案。
直觉类比:如果你对一道题不确定,独立做五次,其中三次得到 83、一次得到 22、一次得到 54,那么 83 最可能是正确答案。
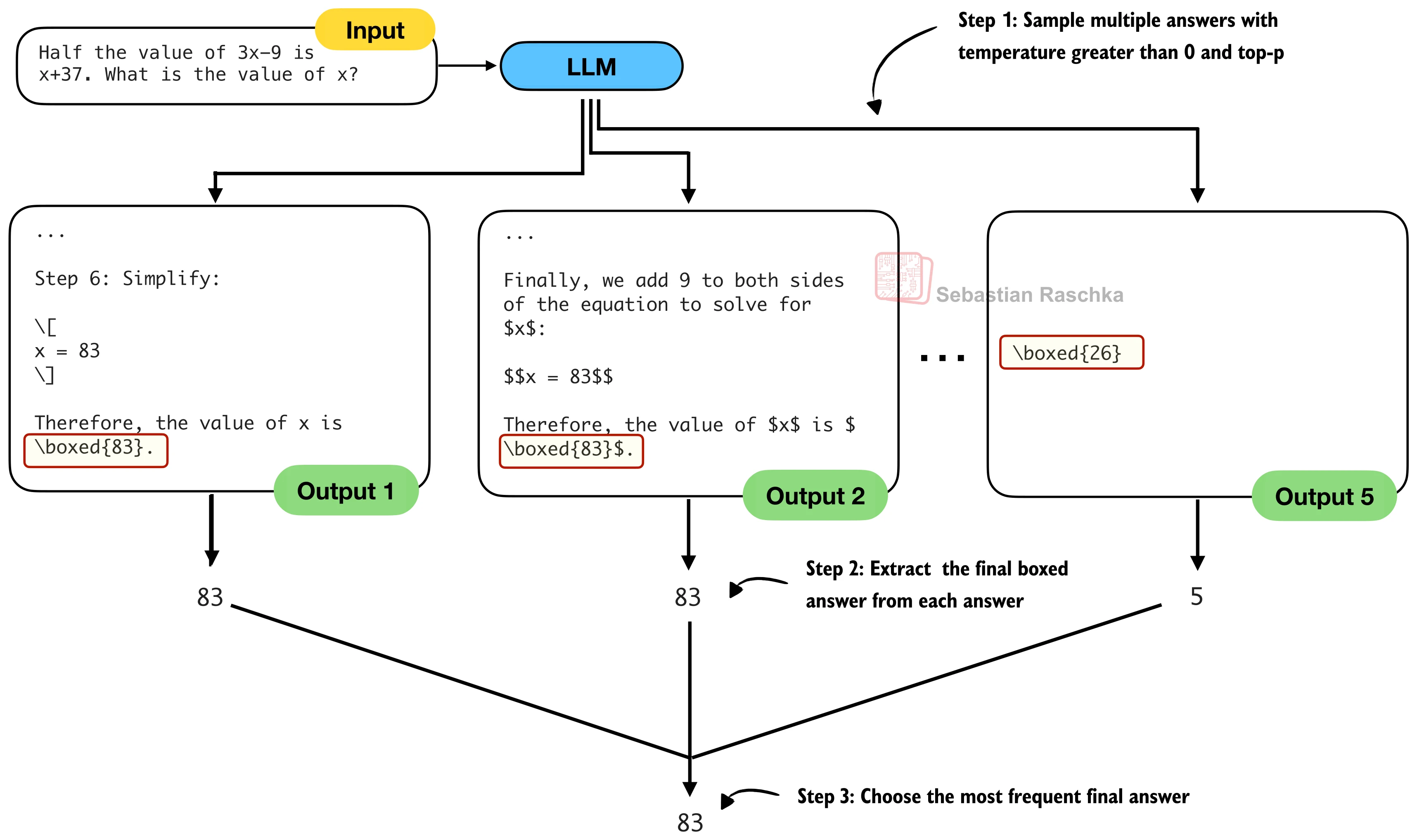
from collections import Counter
def self_consistency_vote(
model, tokenizer, prompt, device,
num_samples=10, temperature=0.8, top_p=0.9,
max_new_tokens=2048, seed=None
):
short_answers = []
# 1. 用不同随机种子采样多个回答
for i in range(num_samples):
if seed is not None:
torch.manual_seed(seed + i + 1)
answer = generate_with_top_p(
model, tokenizer, prompt, device,
max_new_tokens=max_new_tokens,
temperature=temperature, top_p=top_p
)
# 2. 从每个回答中提取最终答案
short = extract_final_candidate(answer, fallback="number_then_full")
short_answers.append(short)
# 3. 多数投票选出最频繁的答案
counts = Counter(short_answers)
final_answer = counts.most_common(1)[0][0]
return final_answer, counts在实际实验中,CoT 提示与自一致性的组合效果尤为突出。仅用 CoT 提示的准确率为 40.6%,加上
四、Best-of-N 选择
自一致性的投票机制虽然有效,但只利用了最终答案的信息,忽略了推理过程的质量。Best-of-N 策略引入了评分函数(Scorer),对所有生成的回答进行打分,选择得分最高的那个:
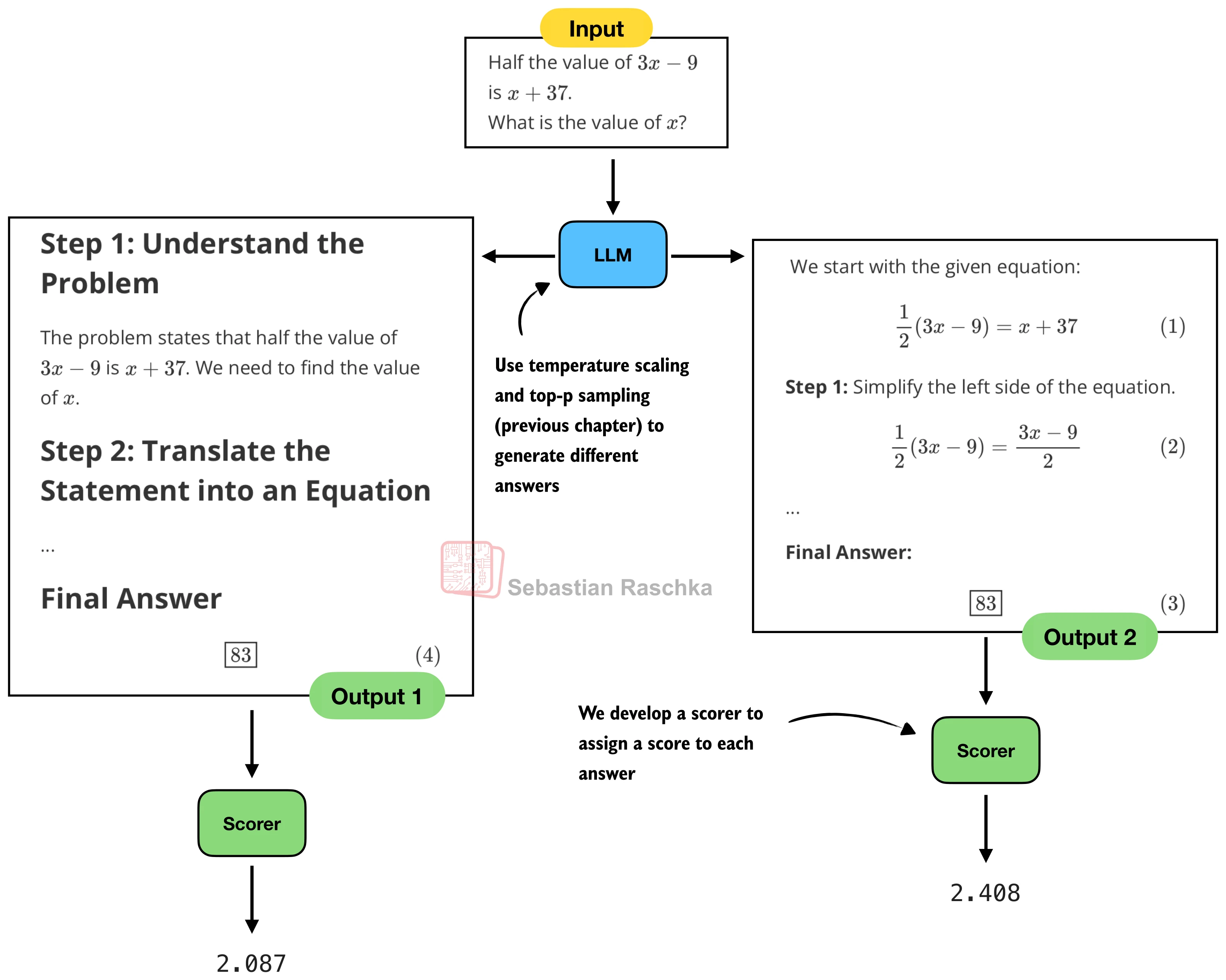
评分函数的选择直接决定了 Best-of-N 的效果。本节介绍两类评分器:
启发式评分器
基于简单规则打分——是否包含 \boxed{} 格式、回答是否简洁等:
import math
def heuristic_score(answer, prompt=None, brevity_bonus=500.0):
score = 0.0
# 奖励包含 \boxed{} 的回答
cand = extract_final_candidate(answer, fallback="none")
if cand:
score += 2.0
# 简洁性奖励:越短的正确回答越好
score += 1.5 * math.exp(-len(answer) / brevity_bonus)
return score简洁性奖励
对数概率评分器
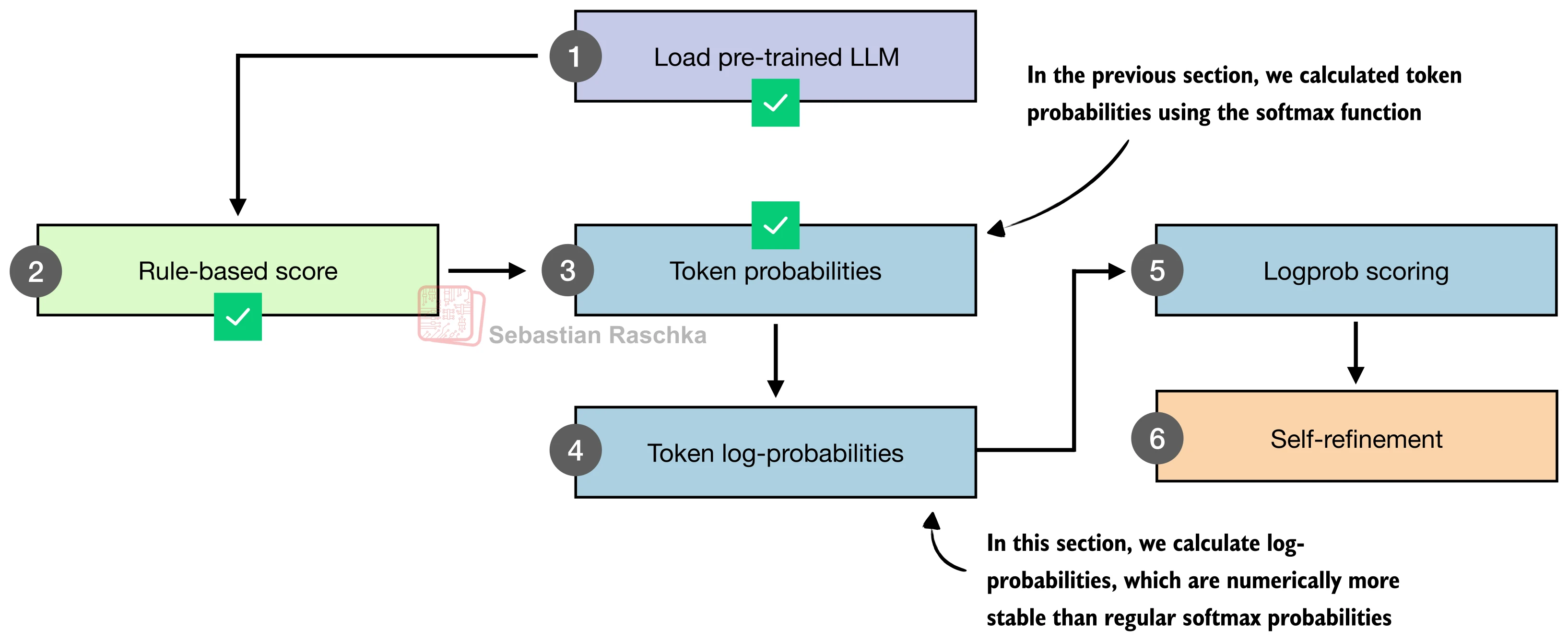
更精细的方法是利用模型自身的对数概率(Log-Probability) 作为置信度指标。对于模型生成的回答序列
为了避免长回答因 token 数多而被惩罚,使用平均对数概率:
@torch.inference_mode()
def avg_logprob_score(model, tokenizer, prompt, answer, device="cpu"):
prompt_ids = tokenizer.encode(prompt)
answer_ids = tokenizer.encode(answer)
full_ids = torch.tensor(prompt_ids + answer_ids, device=device)
logits = model(full_ids.unsqueeze(0)).squeeze(0)
logprobs = torch.log_softmax(logits, dim=-1)
# 只对回答部分的 token 计分(排除提示部分)
start = len(prompt_ids) - 1
end = full_ids.shape[0] - 1
t_idx = torch.arange(start, end, device=device)
next_tokens = full_ids[start + 1 : end + 1]
answer_logprobs = logprobs[t_idx, next_tokens]
return torch.mean(answer_logprobs)注意两个关键设计选择:(1)只对回答部分计分,排除提示 token——因为提示的 logprob 对所有候选回答都相同,不提供区分信息;(2)使用 log_softmax 而非先 softmax 再取 log,前者在数值上更稳定。
在 MATH-500 上,Best-of-N (
五、自改进(Self-Refinement)
前面的方法都是独立采样——每次生成互不相关。自改进(Self-Refinement)则引入了迭代反馈机制:让模型审视自己的回答、指出问题、然后修正。
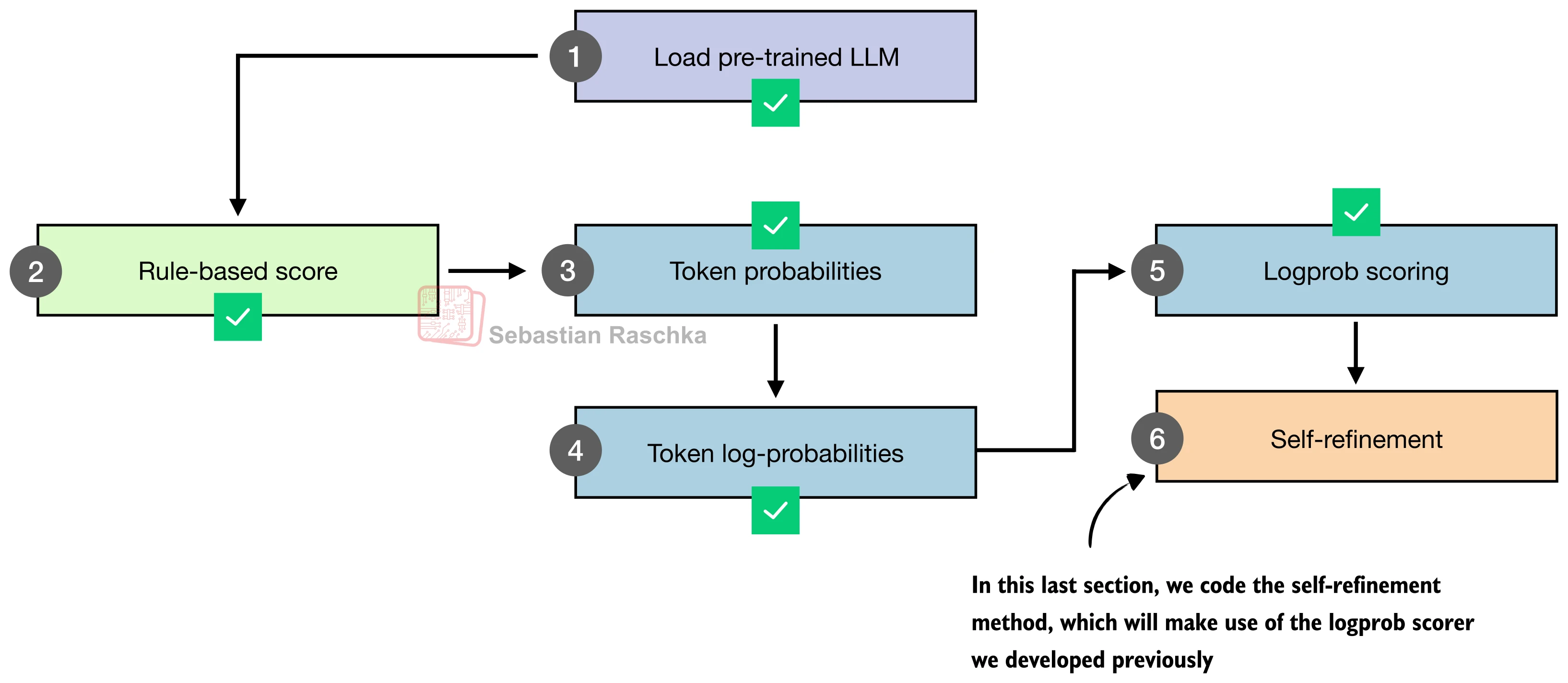
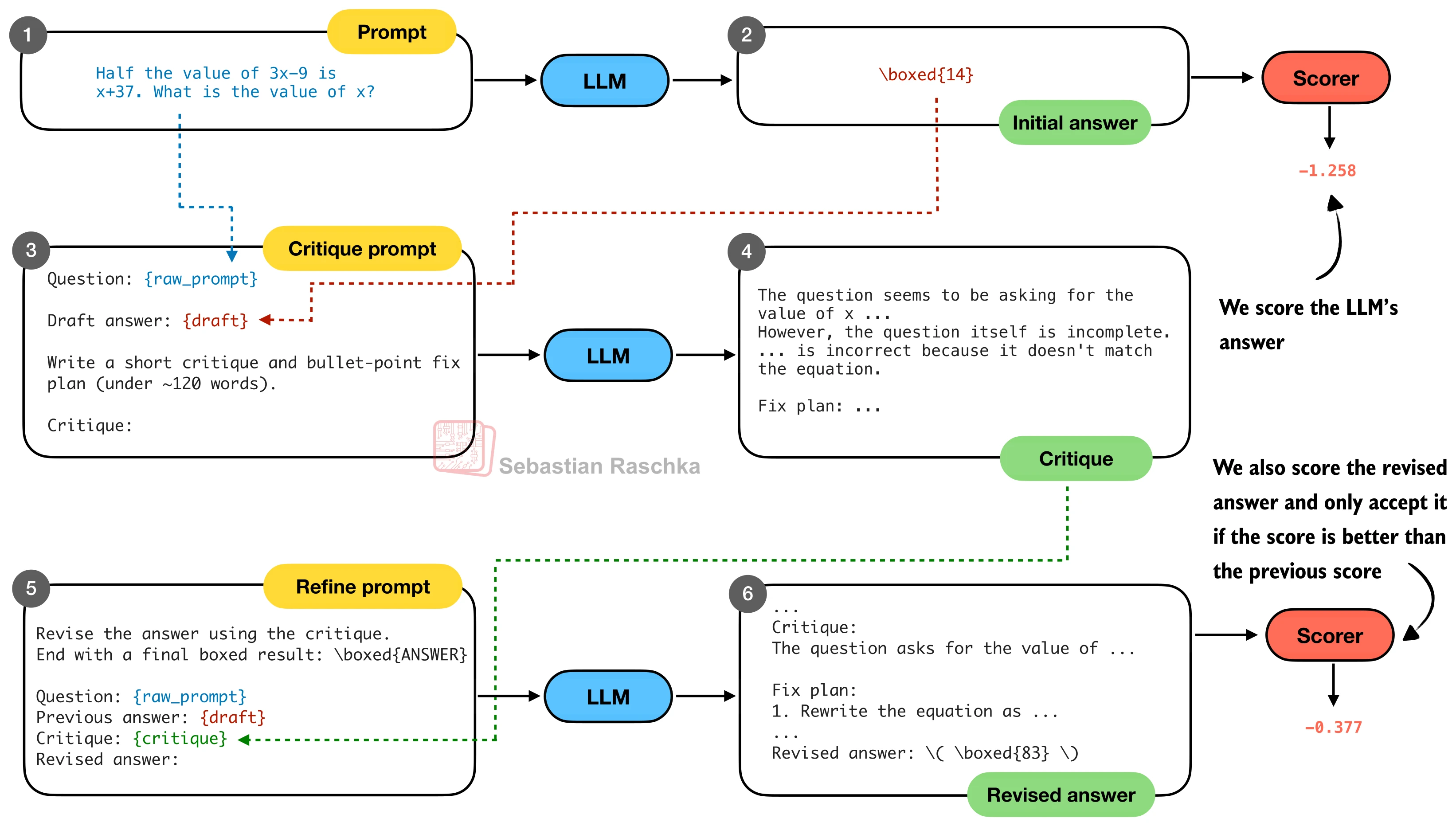
整个流程分为三步:
第一步:生成初始回答(Draft)。用标准的 CoT 提示生成第一版回答。
第二步:生成批判(Critique)。将原始问题和初始回答组合成批判提示,要求模型找出逻辑错误、遗漏步骤或计算失误:
def make_critique_prompt(raw_prompt, draft):
return (
"You are a meticulous reviewer. Identify logical errors, "
"missing steps, or arithmetic mistakes. If the answer seems "
"correct, say so briefly. Then propose a concise plan to fix issues.\n\n"
f"Question:\n{raw_prompt}\n\n"
f"Draft answer:\n{draft}\n\n"
"Write a short critique and bullet-point fix plan "
"(under ~120 words).\nCritique:"
)第三步:生成修订版(Revised Answer)。将批判结果反馈给模型,要求基于批判修正回答:
def make_refine_prompt(raw_prompt, draft, critique):
return (
"Revise the answer using the critique. Keep it concise and "
"end with a final boxed result: \\boxed{ANSWER}\n\n"
f"Question:\n{raw_prompt}\n\n"
f"Previous answer:\n{draft}\n\n"
f"Critique:\n{critique}\n\nRevised answer:"
)
完整的自改进循环将以上三步封装,并引入评分函数决定是否接受修订版:
def self_refinement_loop(model, tokenizer, raw_prompt, device,
iterations=2, score_fn=None, **kwargs):
# 生成初始回答
current = generate_initial_response(model, tokenizer, raw_prompt, device, **kwargs)
current_score = score_fn(current) if score_fn else 0.0
for it in range(iterations):
# 生成批判
critique = generate_critique(model, tokenizer, raw_prompt, current, device, **kwargs)
# 生成修订版
revised = generate_revised(model, tokenizer, raw_prompt, current, critique, device, **kwargs)
revised_score = score_fn(revised) if score_fn else 0.0
# 只在修订版不比当前版本差时才接受
if revised_score >= current_score:
current = revised
current_score = revised_score
return current评分函数在此扮演"看门人"角色——没有评分函数时,模型可能在迭代中越改越差(尤其是小模型),因为批判本身也可能出错。加入评分函数后,只有改进才会被采纳。
以之前的数学题为例,初始回答 \boxed{18}(错误),经过一轮批判-修正后变为 \boxed{83}(正确),对数概率分数从 -0.855 上升到 -0.226。
六、MATH-500 综合对比
下面的表格汇总了所有推理时间缩放方法在 MATH-500(500 道竞赛级数学题)上的完整实验结果,基于 0.6B 参数量的 Qwen3 模型:
| # | 方法 | 模型 | 准确率 | 耗时 |
|---|---|---|---|---|
| 1 | 基线(贪心解码) | 基座 | 15.2% | 10.1 min |
| 2 | 基线(贪心解码) | 推理 | 48.2% | 182.1 min |
| 3 | CoT 提示 | 基座 | 40.6% | 84.5 min |
| 4 | 温度 + Top-p(无 CoT) | 基座 | 17.8% | 30.7 min |
| 5 | 自一致性 (n=3) | 基座 | 29.6% | 97.6 min |
| 6 | 自一致性 (n=5) | 基座 | 27.8% | 116.8 min |
| 7 | 自一致性 (n=10) | 基座 | 31.6% | 300.4 min |
| 8 | Top-p + CoT | 基座 | 33.4% | 129.2 min |
| 9 | 自一致性 (n=3) + CoT | 基座 | 42.2% | 211.6 min |
| 10 | 自一致性 (n=5) + CoT | 基座 | 48.0% | 452.9 min |
| 11 | 自一致性 (n=10) + CoT | 基座 | 52.0% | 862.6 min |
| 12 | 自一致性 (n=3) + CoT | 推理 | 55.2% | 544.4 min |
从这张表中可以读出几个关键结论:
1. CoT 是性价比最高的方法。仅一行提示修改就把准确率从 15.2% 提升到 40.6%,是所有方法中收益/成本比最大的。
2. 随机采样本身不提升准确率。第 4 行(17.8%)与第 1 行(15.2%)相差甚微——单纯引入随机性没有意义,关键是如何利用多样性。
3. 自一致性需要 CoT 配合。不加 CoT 时,自一致性的收益有限(第 5-7 行,最高 31.6%);加上 CoT 后效果显著提升(第 9-11 行,最高 52.0%)。原因是:没有推理链时,不同样本的错误高度相关(模型倾向于犯同一类错误),投票无法纠错。
4. 更多样本并非总是更好。第 6 行(n=5, 27.8%)反而低于第 5 行(n=3, 29.6%),说明在没有 CoT 引导时,增加样本数可能引入更多噪声。但在有 CoT 时,准确率随
5. 推理时间缩放可以弥补训练差距。基座模型 + 自一致性 (n=10) + CoT 的 52.0% 超过了推理模型贪心解码的 48.2%——这意味着适当的推理时间策略可以让一个未经推理训练的模型达到甚至超越经过专门训练的模型。
自改进方法的完整 MATH-500 结果也值得关注:
| # | 方法 | 评分器 | 迭代次数 | 模型 | 准确率 |
|---|---|---|---|---|---|
| 1 | 自改进 | 无 | 1 | 基座 | 25.0% |
| 2 | 自改进 | 无 | 2 | 基座 | 22.0% |
| 3 | 自改进 | 启发式 | 1 | 基座 | 21.6% |
| 4 | 自改进 | 对数概率 | 1 | 基座 | 21.4% |
| 5 | 自改进 | 无 | 1 | 推理 | 56.6% |
| 6 | 自改进 | 启发式 | 1 | 推理 | 57.8% |
自改进在基座模型上效果有限(最高 25.0%),因为 0.6B 参数量的基座模型自身的批判能力不足以可靠地发现错误。但在推理模型上,自改进 + 启发式评分将准确率从 48.2% 提升到 57.8%,证明了该方法在模型能力足够时确实有效。
七、方法选择指南
基于以上实验结果,可以总结出一套实用的方法选择策略:
计算预算极低时:优先使用 CoT 提示。零额外计算开销,仅修改提示文本,即可获得最大单次收益。
计算预算中等时:CoT + 自一致性 (n=3-5)。三到五次采样的投票在成本和准确率之间取得了良好平衡。如果存在平票情况,用对数概率评分作为 tie-breaker。
计算预算充足时:CoT + 自一致性 (n=10+) 或 Best-of-N + 对数概率评分。前者在大量样本时表现更稳健,后者在样本数较少时更高效。
模型能力较强时:可以考虑自改进,尤其是配合启发式评分函数。但对于小模型,自改进的收益不如自一致性稳定。
这些推理时间缩放技术不仅适用于数学推理——CoT 提示、自一致性和 Best-of-N 已被广泛应用于代码生成、逻辑推理、常识问答等任务。它们提供了一种"用计算换准确率"的通用框架,与下一节将介绍的 GRPO 训练形成互补:推理时间缩放改善推理阶段的输出质量,GRPO 则从根本上提升模型的推理能力。