18.5 DeepSeek-R1 与形式化数学
2025 年 1 月,DeepSeek 发布了 DeepSeek-R1 系列推理模型,其中最引人注目的是 DeepSeek-R1-Zero——一个完全不依赖监督微调(Supervised Fine-Tuning, SFT),仅通过大规模强化学习(Reinforcement Learning, RL)就涌现出强大推理能力的模型。这一实验不仅在 AIME 2024 和 MATH-500 等数学推理基准上取得了媲美 OpenAI o1 的成绩(DeepSeek-AI, 2025),更从根本上回答了一个深刻的问题:推理能力是否可以通过纯 RL 激励而自发涌现? 与此同时,形式化数学领域也在 Lean 4 等证明辅助工具的推动下取得了飞速进展。本节将深入剖析 R1-Zero 的纯 RL 方案、R1 的完整训练流水线,以及自动定理证明(Automated Theorem Proving, ATP)的最新进展。
18.5.1 R1-Zero:纯 RL 涌现推理能力
传统的推理模型训练遵循"先 SFT 再 RL"的范式——首先用大量人工标注的思维链(Chain-of-Thought, CoT)数据进行监督微调,然后再通过 RL 进一步优化。DeepSeek-R1-Zero 的大胆之处在于完全跳过 SFT 阶段,直接在 DeepSeek-V3-Base(一个仅经过预训练和中间训练、未做任何指令微调的基座模型)上运行大规模 RL。
奖励设计。 R1-Zero 采用了极其简洁的基于规则的奖励系统,仅包含两类信号:
- 准确性奖励(Accuracy Reward):对于数学问题,要求模型将最终答案放在指定格式中(如
\boxed{}),通过规则匹配判断正误;对于编程问题,使用编译器和测试用例自动验证。 - 格式奖励(Format Reward):要求模型将推理过程放在
<think>和</think>标签之间。
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
def r1_zero_reward(response: str, ground_truth: str) -> float:
"""R1-Zero 的奖励函数:准确性 + 格式"""
# 准确性奖励:提取最终答案并比对
predicted = extract_boxed_answer(response)
accuracy_reward = 1.0 if predicted == ground_truth else 0.0
# 格式奖励:检查 <think> 标签完整性
has_open = "<think>" in response
has_close = "</think>" in response
if has_open and has_close:
format_reward = 0.1
elif has_open or has_close:
format_reward = -0.1 # 标签不完整则惩罚
else:
format_reward = 0.0
return accuracy_reward + format_rewardR1-Zero 刻意不使用任何神经网络奖励模型。研究团队发现,在大规模 RL 训练过程中,神经奖励模型容易出现奖励黑客(Reward Hacking) 现象——模型学会欺骗奖励网络而非真正提升能力,且重新训练奖励模型会增加资源消耗和流程复杂度。基于规则的确定性奖励从根本上消除了这一风险。这一设计选择体现了从 RLHF(基于人类反馈的 RL)向 RLVR(Reinforcement Learning from Verifiable Rewards,基于可验证奖励的 RL) 的重要范式转移——数学和代码等领域天然拥有确定性的验证手段,无需依赖噪声较大的人类偏好或学习到的奖励模型。
训练模板。 R1-Zero 使用了一个极简的提示模板来引导基座模型:模板仅要求模型先输出推理过程,再输出最终答案,刻意不指定任何具体的推理策略(如"请反思你的推理"或"请尝试多种方法"),以确保研究者能准确观察模型在 RL 过程中的自然演化。模板结构如下:
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within <think> </think> and <answer> </answer> tags respectively.
训练算法:GRPO。 R1-Zero 使用 GRPO(Group Relative Policy Optimization,组相对策略优化) 作为 RL 算法。GRPO 最早在 DeepSeekMath 中提出,其核心创新是移除价值函数(Value Model),用同一问题下多个采样回答的组内统计量来估计优势(Advantage)。
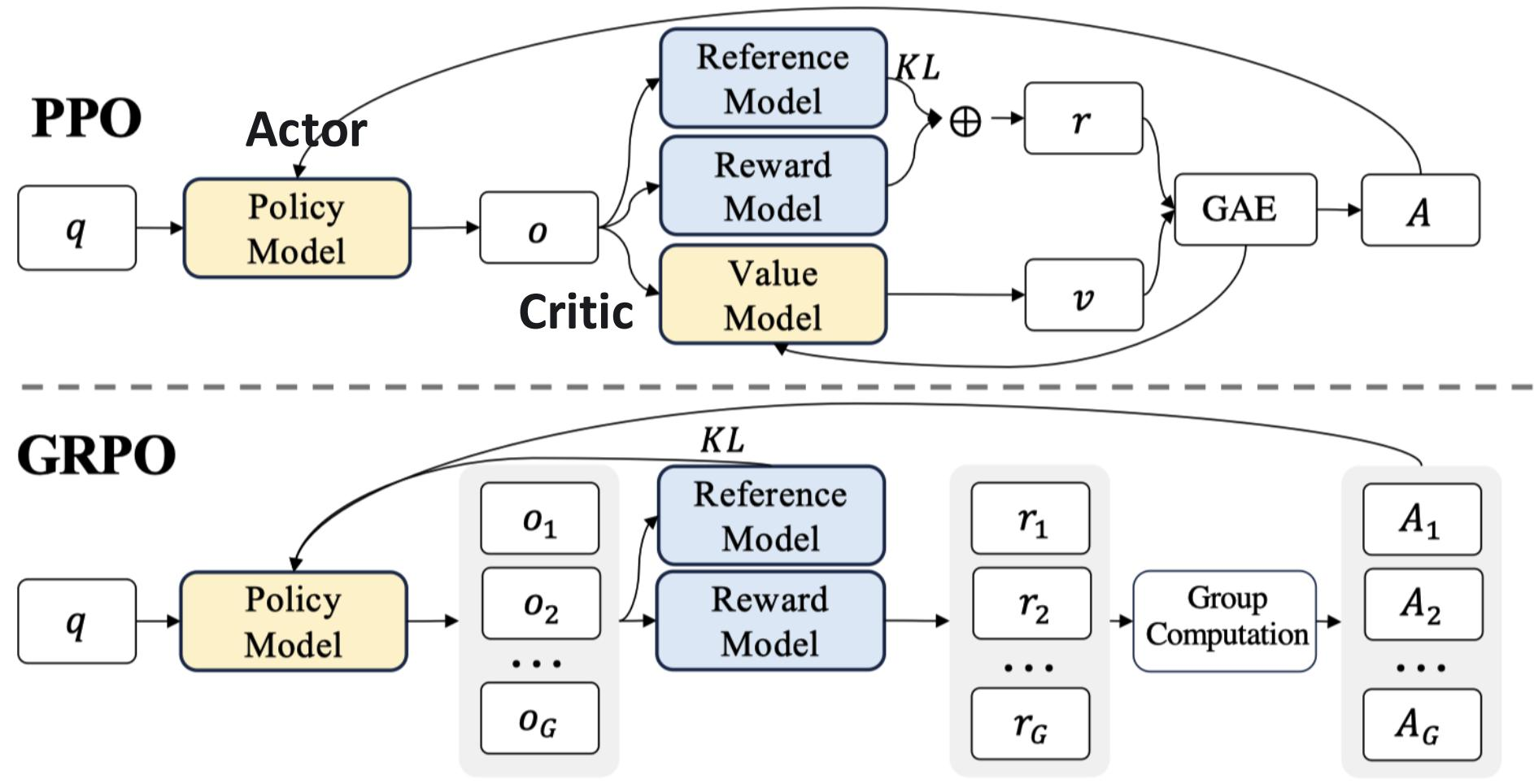
图 18-13:PPO 与 GRPO 架构对比。PPO 需要额外训练一个与策略模型同等规模的价值模型,而 GRPO 通过对同一问题采样 G 个回答并计算组内奖励的均值和标准差来替代价值函数,将内存开销几乎减半。
具体而言,对于每个问题
其中优势
| 特性 | PPO | GRPO |
|---|---|---|
| 价值函数 | 需要训练一个同等规模的 Value Model | 不需要 |
| 基线来源 | 学习的 | 组内经验均值 |
| 显存占用 | ~2 倍策略模型 | ~1 倍策略模型 |
| 适用场景 | 通用 RL | 特别适合语言模型(可对同一 prompt 采样多个回答) |
表 18-5:PPO 与 GRPO 的核心差异。
惊人结果。 经过数千步 RL 训练后,R1-Zero 在 AIME 2024 数学竞赛基准上的 Pass@1 从初始的 15.6% 稳步攀升至 71.0%,使用多数投票(Majority Voting)后进一步达到 86.7%,与 OpenAI o1-0912 持平。
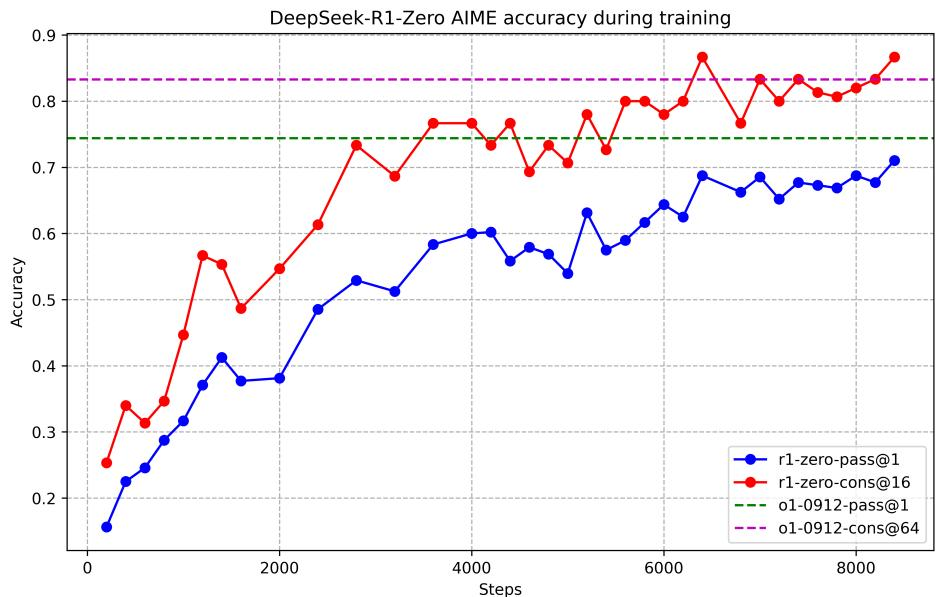
图 18-14:R1-Zero 在 AIME 2024 上的训练曲线。仅凭纯 RL 训练,模型的数学推理能力就呈现出清晰的持续增长趋势,最终逼近 OpenAI o1-0912 的水平。
18.5.2 涌现行为与"顿悟时刻"
R1-Zero 训练过程中最令人着迷的发现是推理行为的自发涌现。在没有任何显式教导的情况下,模型自主发展出了以下高级推理策略:
- 思考时间自然增长:随着训练推进,模型的平均回答长度从数百 token 增长到近万 token,这意味着模型在"主动分配更多思考时间"给复杂问题。
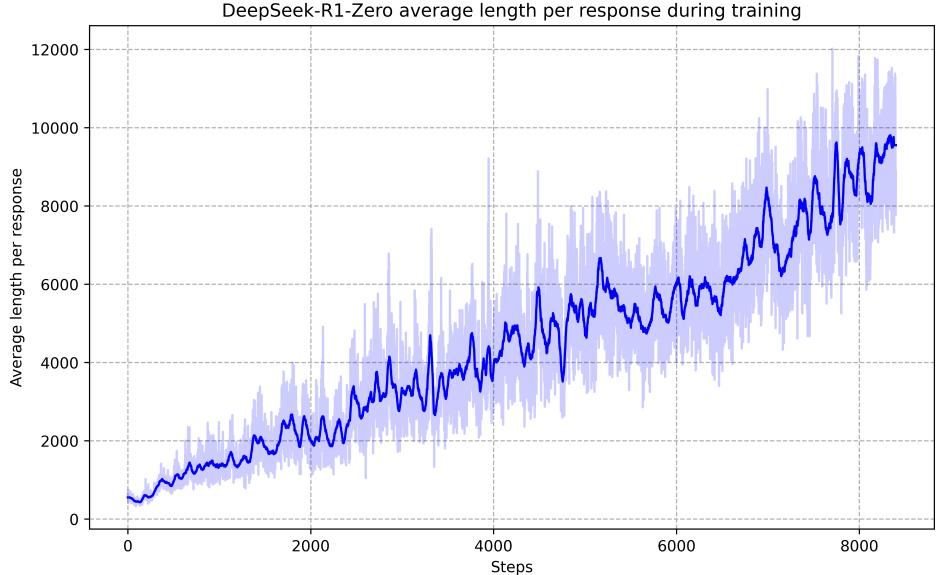
图 18-15:R1-Zero 的平均回答长度随训练步数单调增长,体现了测试时计算(Test-Time Compute)的自发扩展。
- 自我验证(Self-Verification):模型学会在给出答案后回头检查,主动发现并纠正错误。
- 多路径探索:面对困难问题时尝试不同解法,而非死磕一条路。
- "顿悟时刻"(Aha Moment):在训练的中间阶段,模型生成了如下令人惊叹的推理片段:
输入方程
,模型推导到四次方程后写道: "Wait, wait. Wait. That's an aha moment I can flag here. Let's reevaluate this step-by-step..."
模型自发暂停、回顾之前的步骤,然后从不同角度重新展开推理。
研究团队评价说,这个"顿悟时刻"不仅是模型的 aha moment,也是研究者的 aha moment——它表明只要提供正确的激励(奖励信号),模型就能自主发展出高级问题解决策略,无需人类手把手教。
争议与反思。 R1-Zero 的涌现行为并非没有质疑。后续的 Dr. GRPO 论文从算法层面提出了系统性的批评:
- 长度增长可能是 GRPO 算法的长度偏差导致的:DeepSeekMath 原版 GRPO 对损失函数做了长度归一化,即将每个 token 的损失除以序列总长度。这引入了一个反向激励——答错时,更长的回答使得每 token 的负梯度更小(惩罚被"稀释"),模型的最优策略是生成尽可能长的错误回答;答对时,更短的回答使得每 token 的正梯度更大(奖励被"集中"),最优策略是生成尽可能短的正确回答。Dr. GRPO 建议直接移除长度归一化,或改用显式的长度奖励来控制回答长度。
- 标准差归一化违反策略梯度定理:GRPO 的优势估计除以了组内标准差,但策略梯度定理只允许减去与动作无关的基线,除法操作并不在理论保证范围内。当某个 prompt 过于简单(所有回答都接近正确,标准差趋近于零)时,梯度会被异常放大,导致训练不稳定。
- "aha moment"可能在预训练阶段就已存在:V3-Base 是一个极其强大的基座模型,RL 可能只是"解锁"了它已有的能力,而非从零创造。在较弱的基座模型上重复 R1-Zero 实验时,涌现效果显著减弱,这支持了"RL 释放能力"而非"RL 创造能力"的解释。
这些争论并不否定 R1-Zero 的价值,但提醒我们:(1)区分"RL 创造了新能力"和"RL 释放了已有能力"这两种不同的叙事;(2)算法的实现细节(如归一化方式)可能在无意中引入系统性偏差,需要仔细审视。
18.5.3 从 R1-Zero 到 R1:冷启动与多阶段训练
尽管 R1-Zero 展现了纯 RL 的巨大潜力,它也暴露了明显的缺陷:可读性差(推理过程杂乱无章)和语言混杂(中文问题用英文推理,或多种语言混在一起)。为了解决这些问题并进一步提升性能,DeepSeek 设计了完整的 R1 四阶段训练流水线。
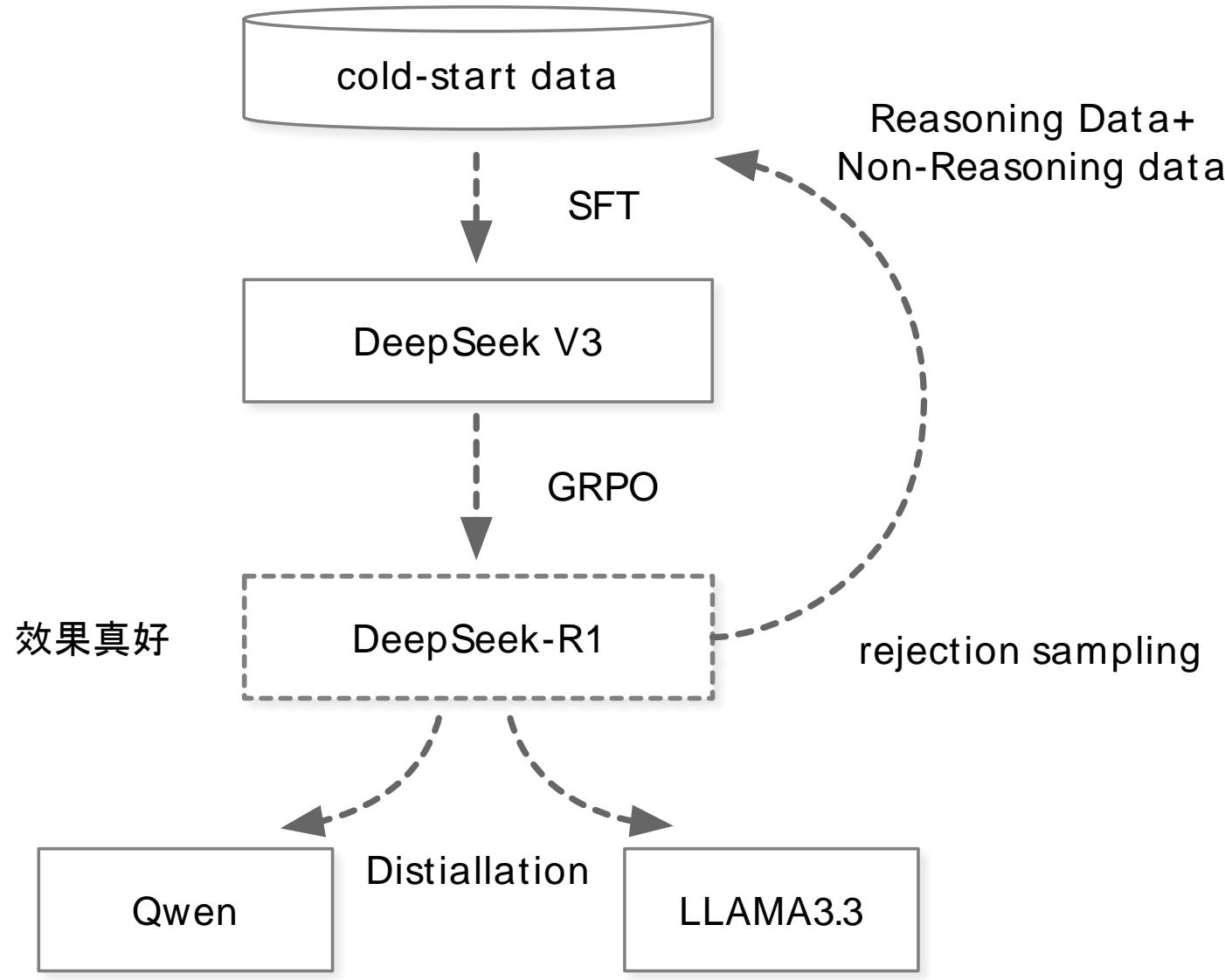
图 18-16:DeepSeek-R1 的四阶段训练流水线。Cold-start SFT → 推理 RL → 拒绝采样 + SFT → 全场景 RL,最终还可以蒸馏到更小的开源模型。
阶段一:冷启动 SFT。 收集数千条高质量长思维链数据,对 DeepSeek-V3-Base 进行微调,作为 RL 的起点。数据来源包括:少样本提示生成、模型自生成后人工筛选、R1-Zero 可读输出的后处理。冷启动数据的输出格式设计为 |special_token|<推理过程>|special_token|<总结>,既保留了完整的推理链,又在末尾提供了简洁的答案摘要。
阶段二:推理导向 RL。 在冷启动模型上运行与 R1-Zero 相同的 GRPO 训练,聚焦数学、代码、科学和逻辑等推理密集型任务。关键创新是引入了语言一致性奖励(Language Consistency Reward):
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
def language_consistency_reward(prompt: str, response: str) -> float:
"""计算回答中目标语言词汇的占比"""
target_lang = detect_language(prompt) # 检测提问语言
thinking_part = extract_between_tags(response, "<think>", "</think>")
# 统计思维链中目标语言词汇的比例
target_words = count_words_in_language(thinking_part, target_lang)
total_words = count_total_words(thinking_part)
return target_words / max(total_words, 1)最终奖励 = 准确性奖励 + 语言一致性奖励。消融实验表明语言一致性奖励会导致性能微降,但大幅提升了可读性。
阶段三:拒绝采样 + 混合 SFT。 当推理 RL 收敛后,利用当前检查点通过拒绝采样(Rejection Sampling)生成约 60 万条推理数据(保留正确答案、过滤混合语言和格式混乱的输出),并结合约 20 万条来自 DeepSeek-V3 的非推理数据(写作、问答、角色扮演等),总计约 80 万样本重新微调 V3-Base。
阶段四:全场景 RL。 在混合 SFT 后的模型上进行第二轮 RL,同时覆盖推理和通用场景。这一阶段的奖励设计更为精细:
- 推理数据:继续使用规则奖励(数学答案正确性、代码测试用例通过率等)。
- 通用数据:引入奖励模型来捕捉人类偏好,复用 DeepSeek-V3 的偏好对和训练 prompt 分布。
- 有用性评估:仅评估最终摘要部分,避免干扰底层推理过程。
- 安全性评估:评估完整回答(包括推理过程和摘要),确保推理链中不会产生有害内容。
这种"推理用规则奖励、通用用奖励模型"的混合方案,使得最终的 R1 模型既在推理任务上表现卓越,又在写作、问答等通用任务上保持了强大能力。
最终性能。 DeepSeek-R1 在多个基准上达到了与 OpenAI o1-1217 相当的水平:
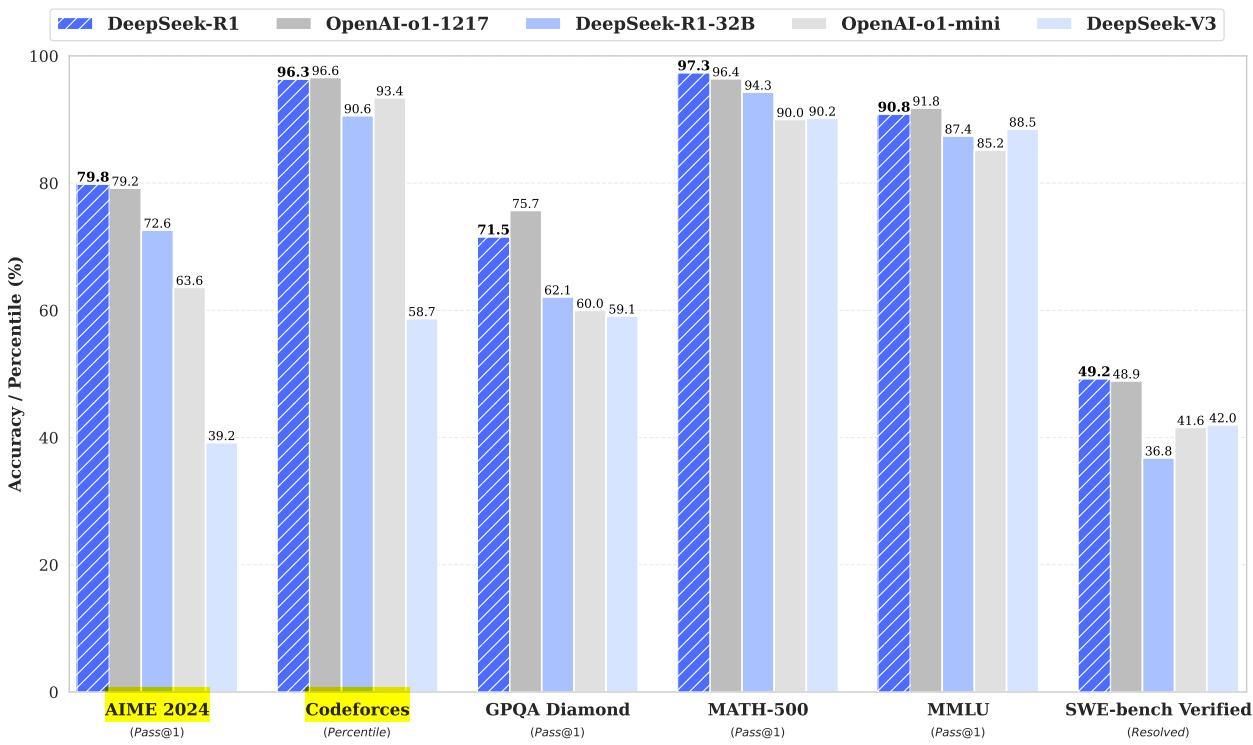
图 18-17:DeepSeek-R1 在各基准上的表现。AIME 2024 达到 79.8% Pass@1,MATH-500 达到 97.3%,Codeforces 达到 2029 Elo 评分(超过 96.3% 的人类参赛者)。
| 基准 | DeepSeek-R1 | OpenAI o1-1217 | OpenAI o1-mini | DeepSeek-V3 |
|---|---|---|---|---|
| AIME 2024 (Pass@1) | 79.8% | 79.2% | 63.6% | 39.2% |
| MATH-500 (Pass@1) | 97.3% | 96.4% | 90.0% | 90.2% |
| Codeforces (Rating) | 2029 | 2061 | 1820 | 1134 |
| GPQA Diamond (Pass@1) | 71.5% | 75.7% | 60.0% | 59.1% |
表 18-6:DeepSeek-R1 与代表性模型的关键指标对比。
18.5.4 蒸馏:让小模型也能推理
DeepSeek 进一步探索了将 R1 的推理能力蒸馏(Distillation) 到小型开源模型的方案。方法出人意料地简单:用 R1 生成的 80 万条包含完整思维链的数据,直接对 Qwen2.5 和 Llama 3 系列基座模型进行 SFT。
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
distill_data = []
for problem in reasoning_problems:
# 用 R1 采样多个回答
responses = [r1_model.generate(problem, max_tokens=16384) for _ in range(8)]
# 仅保留正确的回答
correct = [r for r in responses if verify_answer(r, problem.answer)]
if correct:
distill_data.append({"prompt": problem.text, "response": correct[0]})
# 在小模型上直接 SFT
small_model.finetune(distill_data, epochs=2)蒸馏结果令人惊叹:
| 蒸馏模型 | AIME 2024 (Pass@1) | MATH-500 | GPQA Diamond | LiveCodeBench | Codeforces |
|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9% | 83.9% | 33.8% | 16.9% | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5% | 92.8% | 49.1% | 37.6% | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7% | 93.9% | 59.1% | 53.1% | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6% | 94.3% | 62.1% | 57.2% | 1691 |
| DeepSeek-R1-Distill-Llama-70B | 70.0% | 94.5% | 65.2% | 57.5% | 1633 |
| QwQ-32B-Preview(对比基线) | 50.0% | 90.6% | 54.5% | 41.9% | 1316 |
| OpenAI o1-mini(对比基线) | 63.6% | 90.0% | 60.0% | 53.8% | 1820 |
表 18-8:DeepSeek-R1 蒸馏模型在各基准上的表现。
仅 7B 参数的蒸馏模型在 AIME 2024 上就达到了 55.5%,超过了 32B 参数的 QwQ-32B-Preview(50.0%);32B 蒸馏模型更是达到 72.6%,显著超越 o1-mini 的 63.6%。即使是最小的 1.5B 蒸馏模型也在 MATH-500 上达到了 83.9%,超过了 GPT-4o 的 74.6%。
一个关键发现是:蒸馏远优于对小模型直接做 RL。在相同的 Qwen-32B-Base 上,直接运行大规模 RL(超过 10K 步)仅在 AIME 2024 上达到 47.0%,而从 R1 蒸馏则达到 72.6%——差距高达 25 个百分点。这带来两条重要启示:
- 大模型发现的推理模式可以被高效迁移:通过思维链数据,小模型能够"复制"大模型的推理策略,而不需要自己从头探索。
- 突破智能边界仍需大模型 + 大规模 RL:蒸馏虽然经济高效,但蒸馏模型的上限受限于教师模型。要持续推进推理能力的前沿,最终仍需在更强的基座模型上进行更大规模的 RL 训练。
18.5.5 被放弃的方案:PRM 与 MCTS
DeepSeek 在论文中坦率地分享了两条被放弃的技术路线,这些负面结果同样具有重要的参考价值。
过程奖励模型(Process Reward Model, PRM)。 PRM 的理念是对推理过程的每一步给予奖励,而非只看最终答案。理论上这能提供更密集的学习信号。但 DeepSeek 发现在大规模 RL 中 PRM 面临三个困难:(1)对通用推理任务难以定义"一步"的精确边界;(2)判断中间步骤的正确性本身就很困难,自动标注不可靠,人工标注又无法规模化;(3)一旦引入神经奖励模型就不可避免地出现奖励黑客现象。
蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)。 受 AlphaGo 和 AlphaZero 启发,DeepSeek 尝试将推理过程建模为树结构,通过 MCTS 系统性地探索解题空间。具体做法是通过提示让模型生成多个标签来标记推理步骤的边界,然后在这些步骤节点上构建搜索树。但实践中遇到了两个根本性困难:
- 搜索空间爆炸:语言生成的分支因子远比棋盘大——每个节点可以扩展出的合法 token 序列数量是指数级的。为控制搜索规模而设置的节点扩展限制反而导致模型陷入局部最优。
- 价值模型训练困难:AlphaGo 的成功核心在于价值模型能准确评估棋盘局面的胜率,从而引导搜索方向。但在语言推理中,评估一个中间推理步骤的"好坏"远比评估棋盘局面困难,训练出的价值模型质量不足以驱动迭代进步。
启示:当数据和算力充足时,简单算法往往胜过复杂算法。R1 的成功表明,在拥有足够强大的基座模型和足够多的可验证奖励信号时,GRPO + 规则奖励这样直接的方案已经足够。
18.5.6 自动定理证明与形式化推理
如果说 R1 展示了大模型在非形式化(informal)数学推理上的飞跃,那么自动定理证明(Automated Theorem Proving, ATP) 则代表了在形式化(formal)数学推理领域的另一条重要路线。两者的核心区别在于:
| 维度 | 非形式化推理(R1 风格) | 形式化证明(ATP 风格) |
|---|---|---|
| 表示方式 | 自然语言思维链 | Lean 4 / Coq / Isabelle 等形式化语言 |
| 正确性保证 | 无法机器验证,可能"看似正确实则有误" | 编译器类型检查,数学上严格正确 |
| 知识利用 | 可利用丰富的世界知识 | 受限于已形式化的数学库 |
| 灵活性 | 高(可处理模糊表述) | 低(语法和逻辑极其严格) |
表 18-7:非形式化推理与形式化证明的对比。
形式化思想的历史渊源。 自动定理证明的历史远长于深度学习。上世纪的逻辑学家们致力于为数学建立严格的基础,围绕三个核心问题展开:一致性(系统是否无矛盾)、完备性(所有真命题是否都可证明)、可判定性(是否存在算法自动判断命题真假)。Goedel 不完备定理和 Church-Turing 定理分别否定了后两者的普遍可能性,但也催生了对"可机械化证明"的持续追求。最早的自动定理证明程序可追溯到 1954 年——Martin Davis 编写的程序成功证明了"两个偶数之和为偶数"。
Curry-Howard 同构。 现代形式化数学的理论根基是一个深刻的对应关系——命题即类型,证明即程序。直观来说,证明一个数学定理等价于编写一个满足特定类型签名的程序。例如在 Lean 4 中,theorem 是一个关键字,定理的声明就是一个类型签名,而定理的证明就是该类型的一个具体实例。Lean 编译器通过类型检查来验证证明的正确性,这就提供了一个可靠的自动验证器。
以下是 Lean 4 中证明推广 Sylow 第二定理的一个片段,展示了形式化证明的风格:
-- 推广的 Sylow 第二定理:若 Sylow p-子群个数有限,则所有 Sylow p-子群共轭
instance Sylow.isPretransitive_of_finite
[hp : Fact p.Prime] [Finite (Sylow p G)] :
IsPretransitive G (Sylow p G) :=
⟨fun P Q => by
classical
have H := fun {R : Sylow p G} {S : orbit G P} =>
calc
S ∈ fixedPoints R (orbit G P) ↔ S.1 ∈ fixedPoints R (Sylow p G) :=
forall_congr' fun a => Subtype.ext_iff
_ ↔ R.1 ≤ S := R.2.sylow_mem_fixedPoints_iff
_ ↔ S.1.1 = R := ⟨fun h => R.3 S.1.2 h, ge_of_eq⟩
-- ... 后续证明步骤
⟩Lean 4 与 Mathlib。 Lean 4 是当前最活跃的数学形式化语言,由微软研究院开发。Lean 不仅是一个证明辅助工具,也是一个完整的函数式编程语言。其配套的数学库 Mathlib 已经形式化了大量本科和研究生级别的数学内容,构成了自动定理证明的重要知识基础。在实际使用中,Lean 编译器会输出当前的证明状态(goal state)——包括已知条件和待证目标——这为 AI 系统提供了精确的中间反馈,使得"生成-验证-修正"的迭代工作流成为可能。
当前主流的形式化自动定理证明包含三个关键子任务:
- 自动形式化(Autoformalization):将自然语言书写的数学命题翻译为 Lean 等形式化语言。
- 证明生成(Proof Generation):直接生成完整的形式化证明代码。
- 证明搜索(Proof Search):利用编译器反馈构建搜索工作流,通过反复尝试和修正找到正确的证明路径。
DeepSeek-Prover 系列。 DeepSeek 在形式化证明领域也有持续投入:
- DeepSeek-Prover(2024.5):在 DeepSeekMath 7B 上通过自动形式化和证明训练进行迭代优化,采用全证明生成(whole-proof generation)的方式直接输出完整的 Lean 4 证明。
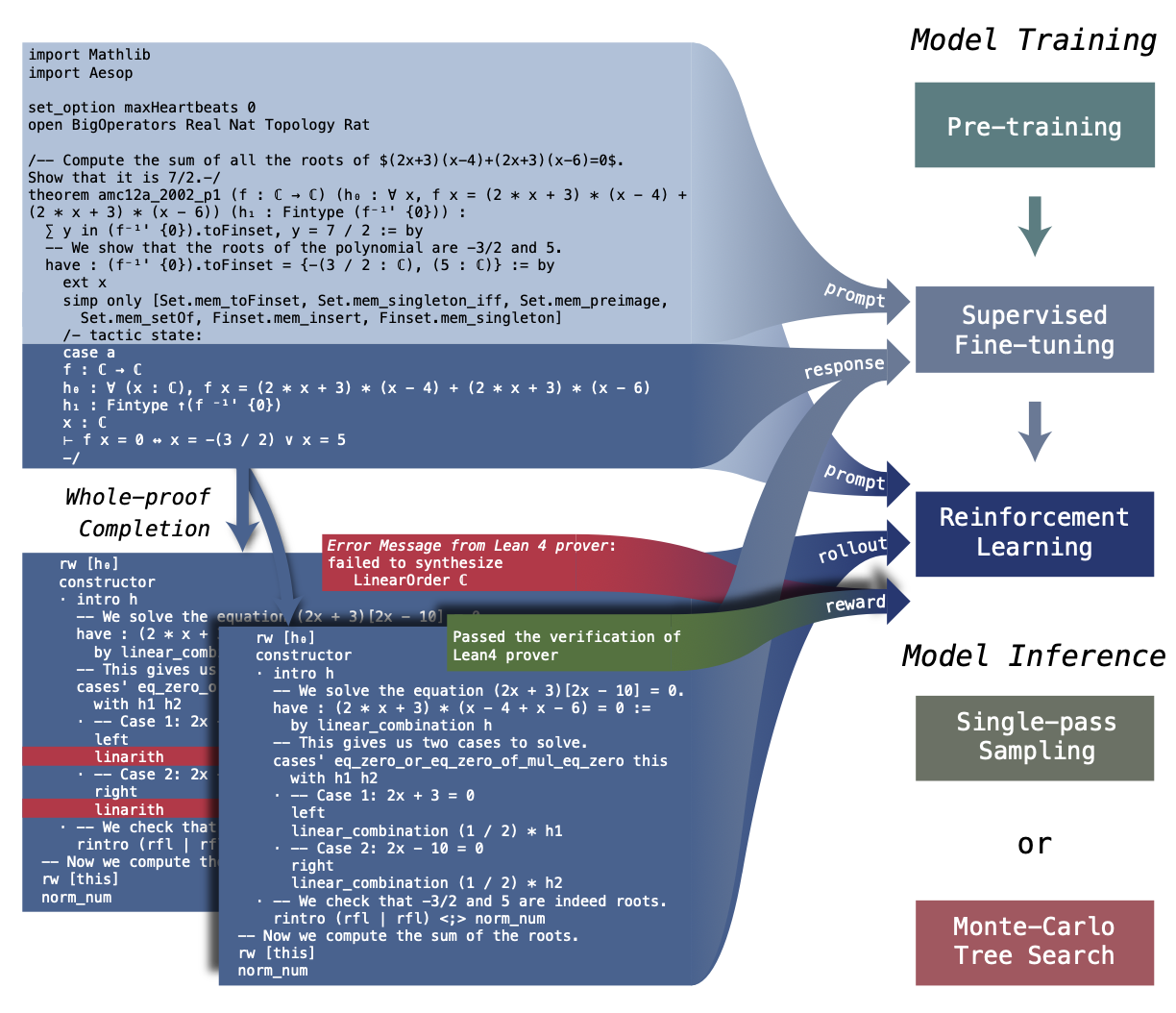
图 18-18:DeepSeek-Prover-V1.5 的训练与推理架构,支持全证明生成和树搜索两种推理模式。
- DeepSeek-Prover-V1.5(2024.8):在前代基础上增加了强化学习、错误修正和证明搜索能力,通过与 Lean 编译器的交互反馈不断修正证明。
- DeepSeek-Prover-V2(2025.4):直接将模型参数扩展到 671B(基于 DeepSeek-V3),在 miniF2F 基准上达到 88.9% 准确率(Pass@8192),标志着大模型在形式化证明领域的重大突破。
AlphaProof 与 AlphaGeometry。 Google DeepMind 在 2024 年发布了两个里程碑式的系统:AlphaGeometry 通过神经-符号混合方法几乎征服了 IMO 平面几何题(30 道题解出 25 道);AlphaProof 结合自动形式化和 RL 训练的 Lean 证明器,与 AlphaGeometry 2 合作在 IMO 2024 上取得了银牌水平。这些系统展示了 AI 在特定数学领域达到甚至超越人类竞赛选手的可能性。
miniF2F 基准的演进。 miniF2F 是衡量形式化定理证明能力的核心基准,包含高中数学竞赛级别的证明题。从 2021 年约 30% 的准确率到 2025 年 Seed-Prover 达到 100%,该基准的性能曲线清晰地展现了领域的快速进步。
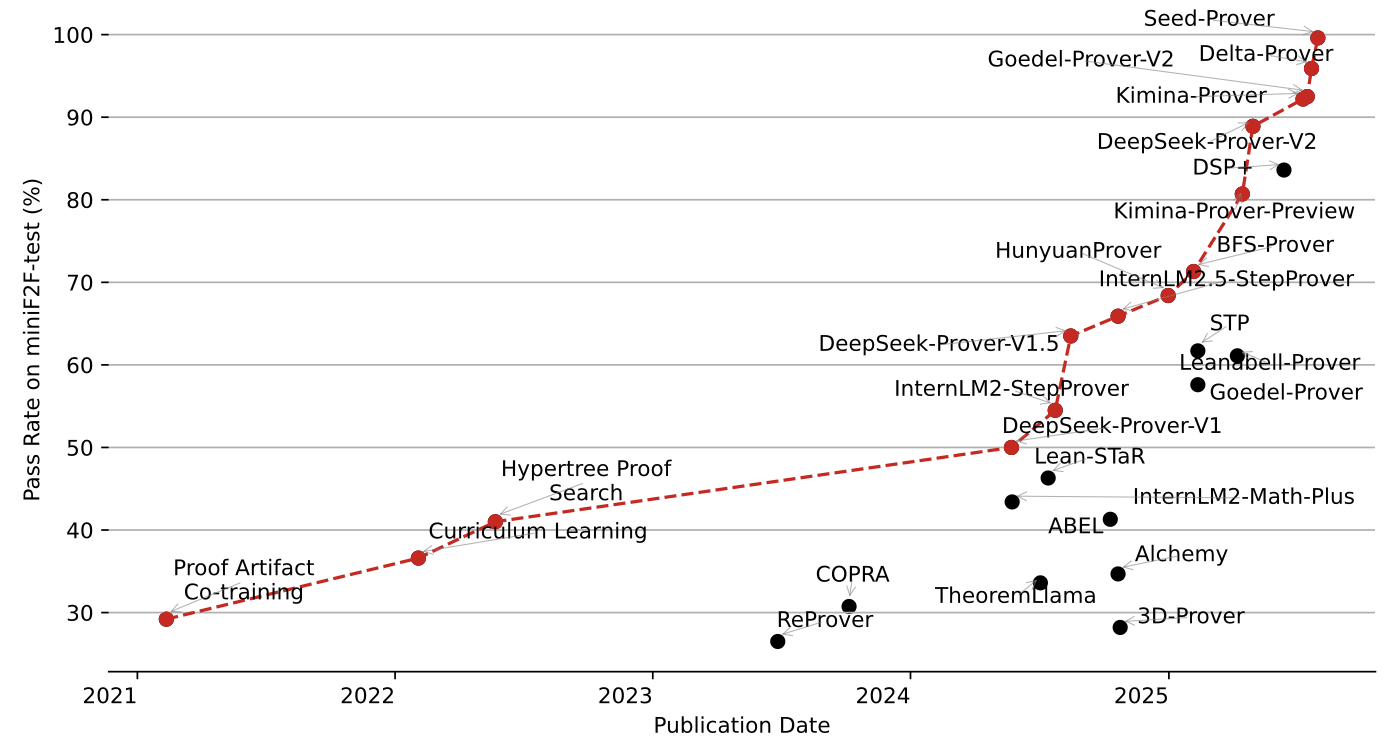
图 18-19:miniF2F 基准的性能演进时间线。Seed-Prover 是第一个在该基准上达到 100% 准确率的系统,而 DeepSeek-Prover-V2、Kimina-Prover 等系统也已超过 85%。
Seed-Prover:工程化的胜利。 字节跳动的 Seed-Prover 是 2025 年形式化自动定理证明领域的一个大型工程项目。它是第一个在 miniF2F 上达到 100% 准确率的系统,关键技术包括引理式证明(lemma-based proving)——将复杂定理分解为多个子引理分别证明,以及自我迭代验证工作流——通过逐引理验证、修正和并行迭代来充分利用测试时算力扩展。Seed-Prover 同样使用了自动形式化合成数据和强化学习训练,展现了"规模化工程"在自动定理证明中的巨大威力。
新兴趋势:自然语言与形式化的融合。 最新的研究(如 Hilbert 和 Aristotle 系统)开始将两条路线融合:用大语言模型的自然语言推理能力来规划证明策略和分解子目标,再用形式化证明器(如 Goedel-Prover-V2)执行具体的 Lean 证明,最终通过编译器验证正确性。这种"自然语言规划 + 形式化执行 + 编译器验证"的混合架构已经展现出巨大的潜力。
具体而言,Hilbert 系统的工作流程如下:(1)使用 Gemini 2.5 Pro 等大模型作为推理引擎,生成自然语言证明草案;(2)结合 RAG 检索将证明草案转换为 Lean 语言的证明梗概,并分解为多个子目标;(3)使用专门的证明器模型(如 Goedel-Prover-V2 32B)逐个攻克子目标;(4)根据 Lean 编译器的反馈不断迭代调整。凭借这一架构,Hilbert 在 miniF2F 上达到 99.2%,在 PutnamBench 竞赛题上达到 70%,远超此前 Seed-Prover 的 50%。
这一趋势揭示了一个重要的方向:自然语言推理提供"直觉"和"策略",形式化系统提供"严格性"和"验证",二者的结合比任何一方单独工作都更为强大。 这与人类数学家的工作方式惊人地相似——先用直觉和草稿纸上的非形式推理找到证明思路,再将其严格地写成形式化证明。
18.5.7 小结
本节从 DeepSeek-R1-Zero 的纯 RL 实验出发,逐步展开了推理模型训练的全景图。核心要点如下:
- 纯 RL 可以涌现推理能力:R1-Zero 证明了在足够强的基座模型上,仅凭准确性奖励和 GRPO 算法就能激发出自我验证、多路径探索等高级推理行为,但也伴随可读性差和语言混杂等问题。
- 冷启动 + 多阶段训练更为实用:R1 的四阶段流水线通过少量冷启动数据引导 RL 起步,再用拒绝采样和二次 RL 平衡推理能力与通用能力。
- 蒸馏优于对小模型直接做 RL:大模型发现的推理模式可以通过思维链数据高效迁移到小模型,这是当前最经济的推理能力获取方式。
- 简单算法往往足够:PRM 和 MCTS 在大规模 RL 设置下表现不如简单的结果奖励 + GRPO,提示我们不应盲目追求算法复杂度。
- 形式化证明正在快速进步:Lean 4 生态为自动定理证明提供了可靠的验证基础,而"自然语言规划 + 形式化执行"的混合范式正成为最有前景的方向。
- 可验证奖励是关键:从 R1 的规则奖励到 Lean 编译器的类型检查,确定性的验证信号是推理能力提升的核心驱动力。这与 AlphaGo 依赖围棋规则、AlphaFold 依赖物理约束的成功逻辑一脉相承——当奖励信号准确且无噪声时,RL 的威力才能充分释放。