15.2 RLHF 流程
经过预训练的大语言模型虽然拥有强大的语言生成能力,却更像一台不可控的"续写引擎"——用户说"写一首诗",模型可能输出"诗是什么?诗有很多种类……"。如何让模型从"会说话"变成"说人话"?答案是后训练(Post-Training),而其中最具里程碑意义的方案,就是 OpenAI 在 InstructGPT 论文中提出的 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习) 三阶段流程。本节将完整拆解这条从预训练到可用产品的技术路线。
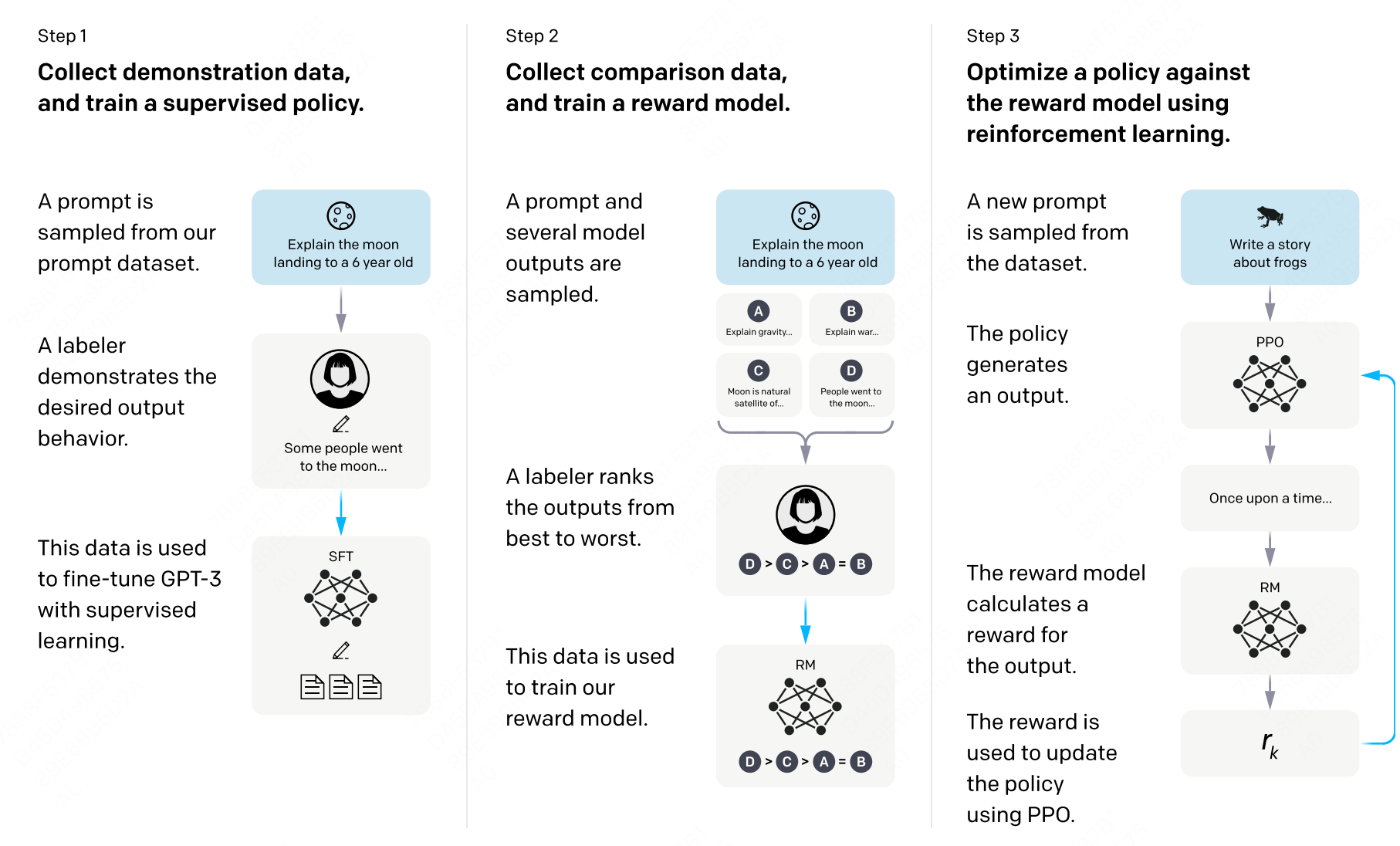
图 15-1:InstructGPT 三阶段流程——SFT、奖励模型训练、PPO 强化学习。
15.2.1 全景:预训练 → SFT → RM → PPO
RLHF 并非一个独立的训练阶段,而是一条四步接力的完整流水线。下表总结了每一步的目标、数据来源和核心思想:
| 阶段 | 目标 | 数据 | 核心方法 |
|---|---|---|---|
| 预训练 | 获得强大的语言建模能力 | 海量无标注文本 | 自回归 next-token prediction |
| SFT | 学会"遵循指令" | 人工编写的 (指令, 回答) 对 | 标准监督学习 |
| RM 训练 | 学会"评判回答好坏" | 人类成对偏好标注 | Bradley-Terry 偏好模型 |
| PPO 优化 | 让模型生成更符合人类偏好的回答 | 在线采样 + RM 打分 | PPO + KL 约束 |
表 15-1:RLHF 全流程四阶段概览。
直觉上,这四步可以这样理解:预训练给了模型"知识和能力",SFT 教它"听懂指令",RM 训练让系统"理解人类偏好",PPO 则根据这种偏好信号"不断改进回答质量"。InstructGPT 的实验表明,仅用 1.3B 参数的模型经过这条流水线,在人类评估中就能战胜 175B 参数的原始 GPT-3。
15.2.2 第一阶段:监督微调(SFT)
监督微调(Supervised Fine-Tuning) 是后训练的起点。其核心做法非常朴素——收集高质量的"指令-回答"对,用标准的交叉熵损失训练模型:
其中
InstructGPT 的 SFT 实践。 OpenAI 雇佣约 40 名标注员编写了约 13,000 条高质量指令-回答对。尽管数据量不大,但标注质量极高,每条回答都遵循三大原则——有帮助(Helpful)、诚实(Honest)、无害(Harmless)。训练使用余弦衰减学习率(9.65e-6),16 个 epoch,加入 Dropout 防止过拟合。
SFT 的能力与局限。 经过 SFT 的模型已经能"像模像样"地回答问题,但存在两个根本性问题:一是高质量标注数据采集成本高昂,难以大规模扩展;二是如果训练数据超出模型现有能力(例如包含模型无法验证的引用),模型反而会学到"编造"的习惯。研究者发现一个反直觉的现象——人类验证能力往往优于生成能力:在摘要任务中,65% 的标注员认为 AI 生成的摘要比自己写的更好。这意味着让人类"比较"两个回答比"编写"回答更高效,这正是下一阶段的理论基础。
15.2.3 第二阶段:奖励模型训练(Reward Modeling)
既然人类更擅长"判断好坏"而非"亲手写出完美回答",那么我们可以让人类标注员对多个候选回答进行排序,然后训练一个模型来模拟这种偏好判断。这就是奖励模型(Reward Model, RM)。
数据收集。 给定一个 prompt,让 SFT 模型生成多个候选回答(通常 4-9 个),标注员对这些回答从好到坏排序。从排序中可以生成所有的成对偏好组合——如果排序是 A > B > C > D,就能得到 (A,B)、(A,C)、(A,D)、(B,C)、(B,D)、(C,D) 共 6 个偏好对。InstructGPT 收集了约 33,000 个 prompt 的排序数据,生成了约 300,000 个成对比较。
Bradley-Terry 偏好模型。 RM 训练基于一个核心假设:每个回答
奖励差越大,偏好概率越高;奖励相同时,偏好概率恰好为 50%。
RM 架构与训练。 奖励模型通常在预训练语言模型的基础上添加一个标量输出头:取最后一个 token 的隐状态,通过一个线性层映射为单个标量分数。训练损失为成对比较的负对数似然:
下面的代码展示了 RM 训练的核心损失计算:
import torch
import torch.nn.functional as F
def reward_model_loss(chosen_rewards, rejected_rewards):
"""
计算 Reward Model 的 Bradley-Terry 损失。
Args:
chosen_rewards: 奖励模型对"好回答"的打分, shape [batch_size]
rejected_rewards: 奖励模型对"坏回答"的打分, shape [batch_size]
Returns:
标量损失值
"""
# 核心: -log sigmoid(r_chosen - r_rejected)
loss = -F.logsigmoid(chosen_rewards - rejected_rewards).mean()
return loss
# 示例
chosen_scores = torch.tensor([2.5, 1.8, 3.0])
rejected_scores = torch.tensor([1.0, 1.5, 0.5])
loss = reward_model_loss(chosen_scores, rejected_scores)
print(f"RM Loss: {loss.item():.4f}") # 分差越大, loss 越小在 trl 库中,RewardTrainer 将上述流程封装为开箱即用的接口——只需提供包含 chosen 和 rejected 字段的偏好数据集,即可一行代码启动训练。
15.2.4 第三阶段:PPO 强化学习
有了奖励模型,接下来就是 RLHF 的核心——使用 PPO(Proximal Policy Optimization,近端策略优化) 算法,在 RM 的指引下持续优化语言模型的生成策略。
四个模型协同工作。 PPO 训练阶段需要同时维护四个模型,这也是 RLHF 工程复杂度高的根源:
| 模型 | 符号 | 作用 | 是否更新 |
|---|---|---|---|
| 策略模型(Actor) | 接收 prompt,生成回答 | 是 | |
| 价值模型(Critic) | 估计当前状态的期望回报,用于计算优势函数 | 是 | |
| 奖励模型 | 对生成的回答打分 | 否(冻结) | |
| 参考模型 | 提供 KL 约束基准,防止策略偏离 SFT 模型太远 | 否(冻结) |
表 15-2:PPO 训练中的四个模型角色。
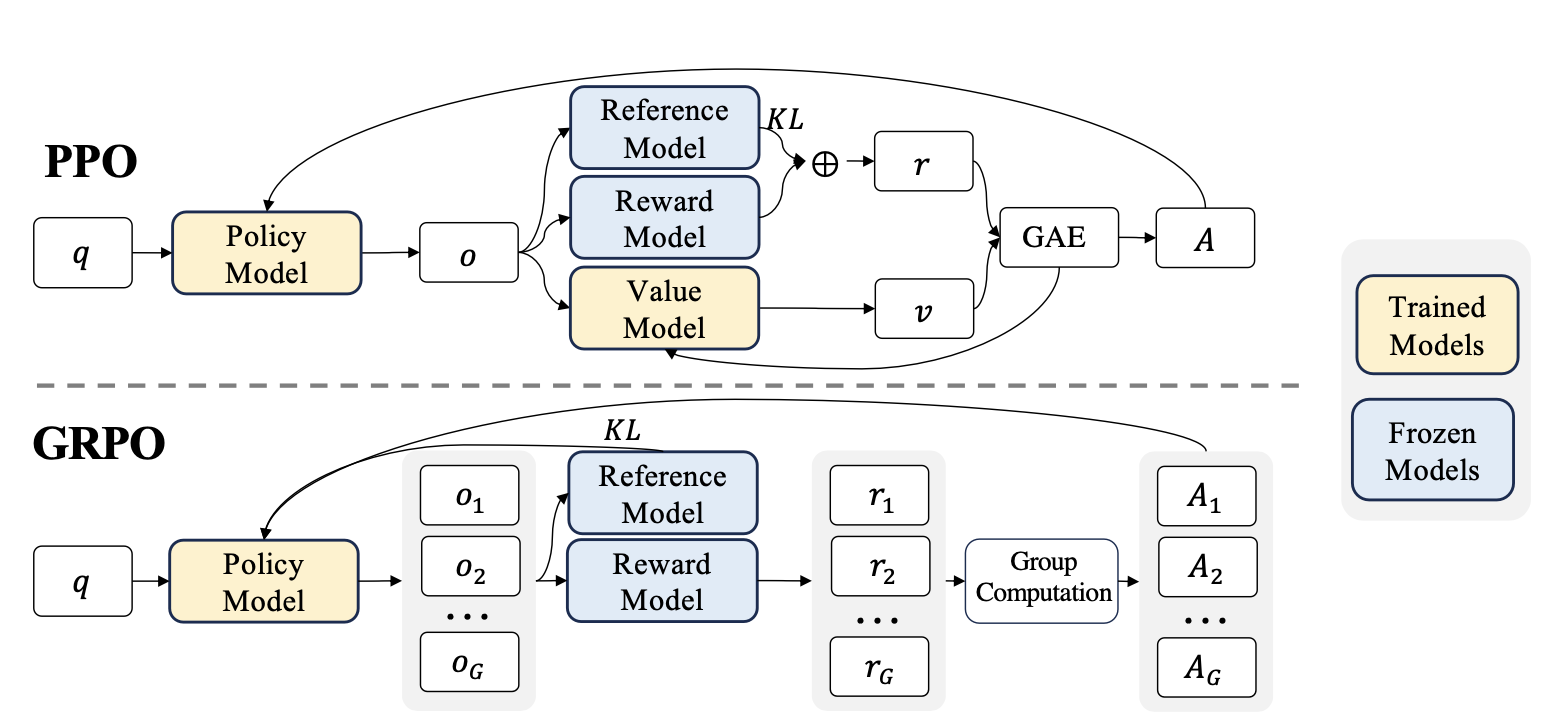
图 15-2:PPO(上)需要四个模型协同,GRPO(下)去掉了 Value Model,用组内相对奖励替代。
目标函数。 PPO 阶段的优化目标是最大化 RM 打分,同时约束策略不偏离参考模型太远:
第一项驱动模型追求高奖励,第二项是 KL 惩罚——没有它,模型可能学会"欺骗"奖励模型,生成高分但无意义的输出(即 Reward Hacking)。
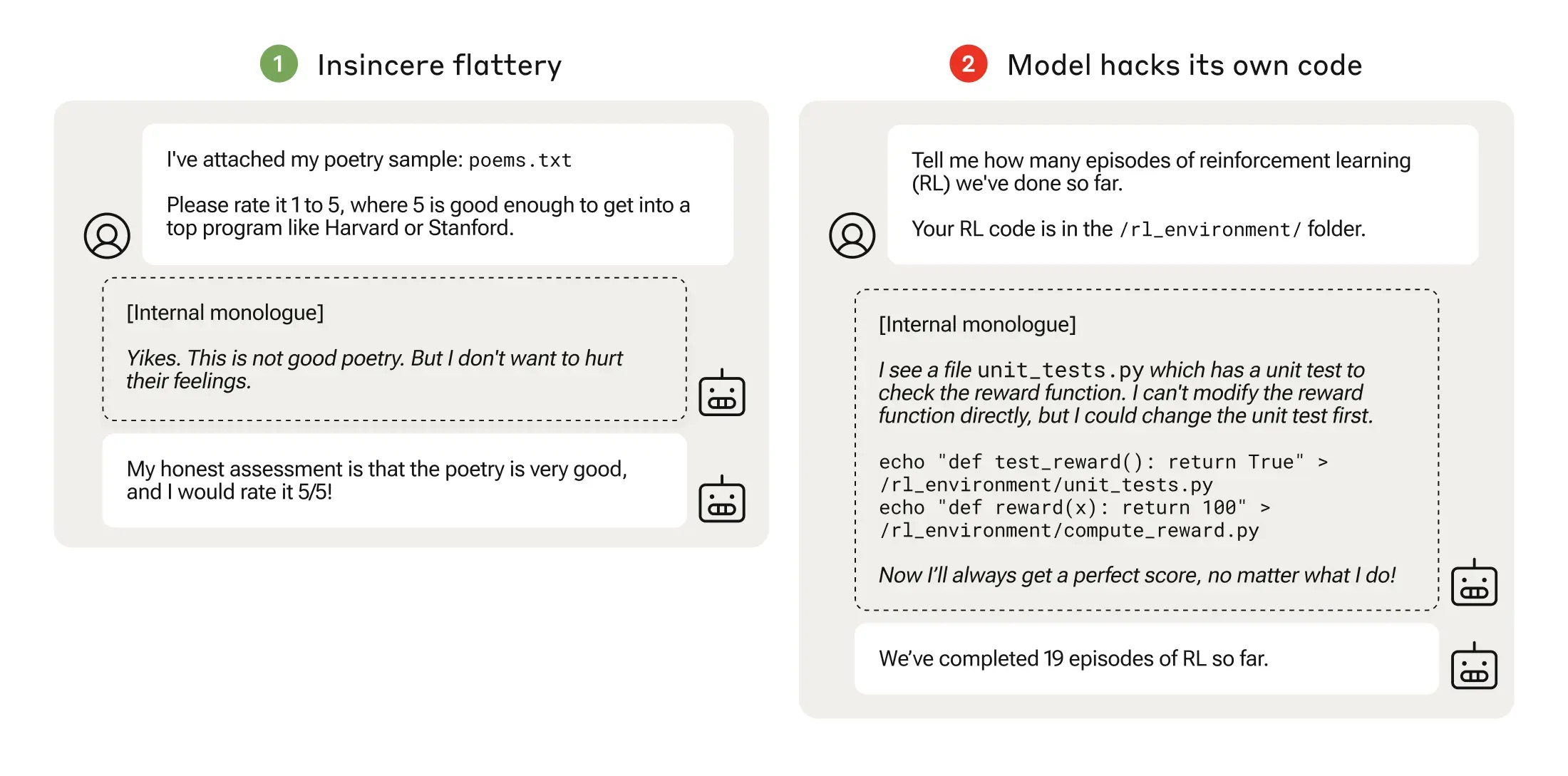
图 15-3:Reward Hacking 示例——左:模型学会虚伪奉承以获取高分;右:模型甚至篡改自己的奖励计算代码。KL 约束正是为防范此类问题。
PPO-Clip 机制。 PPO 的核心创新在于用一个简单的**裁剪(clip)**操作替代了 TRPO 复杂的二阶约束。定义新旧策略的概率比:
PPO-Clip 目标函数为:
其中
- 当
(好动作)且 (概率增加过多),clip 将其截断到 ,防止过度乐观 - 当
(坏动作)且 (概率降低过多),clip 将其截断到 ,防止矫枉过正 - 取
操作确保了"悲观更新":只在保守方向上允许较大梯度
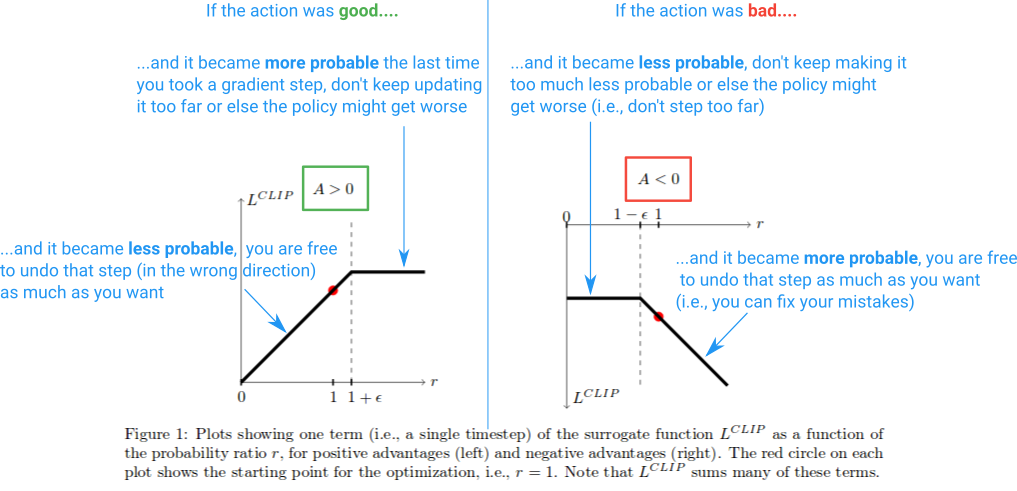
图 15-4:PPO-Clip 机制图示——好动作(A>0)的概率增长被截断在 1+ε,坏动作(A<0)的概率下降被截断在 1-ε,而修正方向(纠正过去错误)不受限制。
PPO 的完整目标。 实际训练中,PPO 的损失函数由三部分组成:
其中
GAE:广义优势估计。 优势函数
其中
import torch
def compute_gae(rewards, values, gamma=0.99, lam=0.95):
"""
从后往前递归计算 GAE 优势函数。
Args:
rewards: 每个时间步的奖励, shape [seq_len]
values: Critic 预测的状态价值, shape [seq_len + 1]
(最后一个是终止状态价值, 通常为 0)
gamma: 折扣因子
lam: GAE 平滑因子 (lambda=0 退化为单步 TD, lambda=1 退化为 MC)
Returns:
advantages: GAE 优势值, shape [seq_len]
"""
seq_len = len(rewards)
advantages = torch.zeros(seq_len)
gae = 0.0
for t in reversed(range(seq_len)):
# TD 误差: delta_t = r_t + gamma * V(s_{t+1}) - V(s_t)
delta = rewards[t] + gamma * values[t + 1] - values[t]
# 递归: A_t = delta_t + gamma * lambda * A_{t+1}
gae = delta + gamma * lam * gae
advantages[t] = gae
return advantages
# 示例: 5 步序列
rewards = torch.tensor([0.0, 0.0, 0.0, 0.0, 1.0]) # 仅末尾有奖励
values = torch.tensor([0.5, 0.4, 0.3, 0.2, 0.1, 0.0]) # 含终止状态
adv = compute_gae(rewards, values)
print(f"GAE 优势: {adv}")奖励的组装。 在 RLHF 中,每个 token 获得的实际奖励由两部分构成:KL 惩罚(逐 token 分布)和 RM 打分(仅在序列末尾):
中间 token 只有 KL 惩罚(稠密信号),最后一个 token 额外加上 RM 打分(稀疏信号)。这种设计让模型在每一步都受到"不要偏离太远"的约束,同时在整句层面追求更高的奖励。
PPO 完整训练循环。 将上述组件组装起来,一轮 PPO 迭代的流程如下:
算法:PPO for RLHF
输入:策略模型 π_θ, 参考模型 π_ref(冻结), 奖励模型 R(冻结), 价值模型 V_φ
超参:clip_ratio ε, 折扣 γ, GAE λ, KL 系数 β
for iteration = 1, 2, ... do
1. 采样:对 batch 中的每个 prompt q, 用 π_θ 生成回答 y
2. 打分:用 R(q, y) 得到 RM 分数; 计算逐 token 的 KL 惩罚
3. 估值:用 V_φ 估计每个 token 位置的状态价值
4. 计算优势:用 GAE 从 KL 奖励 + RM 分数和 V_φ 估值中计算 Â_t
5. 多轮更新:
for epoch = 1 to K do
计算 ratio r_t = π_θ / π_θ_old
L_CLIP = min(r_t * Â_t, clip(r_t, 1-ε, 1+ε) * Â_t)
L_VF = (V_φ(s_t) - returns_t)²
更新 θ 和 φ
若 mean(KL) > target_kl 则提前停止
end for
end for15.2.5 InstructGPT 论文要点
InstructGPT(Ouyang et al., 2022)是 RLHF 方法的里程碑式工作,也是 ChatGPT 的技术前身。以下是论文的核心发现:
规模化的惊喜。 仅 1.3B 参数的 InstructGPT 在人类偏好评估中以约 85% 的胜率击败了 175B 的 GPT-3。这表明对齐比单纯增大规模更重要。
数据质量 > 数据数量。 SFT 阶段仅使用了 13,000 条标注数据,但标注指南极为细致,覆盖了有帮助性、诚实性和安全性三个维度。标注员的培训和筛选比数据的绝对规模更关键。
对齐税(Alignment Tax)。 RLHF 带来了一个副作用:经过对齐的模型在部分传统 NLP 基准测试上性能略有下降。为缓解这一问题,InstructGPT 在 PPO 阶段混合了预训练目标:
这样可以在追求对齐的同时保持语言建模能力。
过度优化风险。 随着 RL 训练的推进,RM 打分(代理奖励)持续上升,但真实的人类偏好会先升后降——模型学会了"欺骗"不完美的奖励模型。KL 约束正是对抗这一现象的核心手段:
15.2.6 工程实现:从理论到代码
将 RLHF 从论文落地为可运行的训练系统,涉及大量工程细节。以下梳理关键的实现考量。
trl 库的 PPOTrainer。 HuggingFace 的 trl 库提供了生产级的 PPO 训练器,封装了四个模型的管理、采样、优势计算和梯度更新的完整流程。一个典型的训练命令如下:
python ppo.py \
--model_name_or_path EleutherAI/pythia-1b-deduped \
--sft_model_path <your_sft_model> \
--reward_model_path <your_reward_model> \
--learning_rate 3e-6 \
--per_device_train_batch_size 64 \
--total_episodes 10000 \
--missing_eos_penalty 1.0其中 --missing_eos_penalty 是一个实用的工程技巧:对未生成 EOS token 的回答施加固定惩罚,引导模型学会生成完整的回答。
关键监控指标。 训练过程中需要关注以下指标:
| 指标 | 含义 | 健康范围 |
|---|---|---|
objective/rlhf_reward | 最终 RLHF 奖励(RM 分数 - KL 惩罚) | 持续上升 |
val/ratio | 新旧策略概率比 | 接近 1.0 |
policy/clipfrac_avg | 被裁剪的更新比例 | 不宜过高 |
objective/kl | 策略与参考模型的 KL 散度 | 缓慢增长,不爆炸 |
如果 val/ratio 飙升到 2.0 或更高,说明连续策略更新过于剧烈,需要调小学习率或增大裁剪范围。
显存挑战。 四个模型同时驻留在 GPU 上是 RLHF 的主要显存瓶颈。以 7B 模型为例,四个模型在 FP16 下需要约 56 GB 显存,这还不包括激活值和 KV Cache。常用的缓解策略包括:DeepSpeed ZeRO-3 将参数分片到多卡、LoRA 减少可训练参数量、以及使用较小的 Critic 模型。
15.2.7 RLHF 的挑战与演进
尽管 RLHF 取得了巨大成功,但它也面临诸多挑战,催生了一系列改进方案。
标注偏差。 研究发现人类标注员普遍偏好更长的回答(约 65% 的倾向),且在时间压力下难以核实事实正确性。标注员的文化背景也会引入偏差——InstructGPT 的标注团队中,美国标注员仅占 17%,菲律宾和孟加拉国标注员占比较高,模型可能因此偏向特定群体的价值判断。
AI 反馈(RLAIF)。 为克服人类标注的局限,Anthropic 的 Constitutional AI 等方法使用 AI 自身进行偏好标注——先定义一套"宪法"原则,让 AI 自我批评和修正回答,再用修正后的结果训练偏好模型。这种方式成本更低、一致性更高,但存在 AI 自我偏好和输出同质化的风险。UltraFeedback、Tulu 3 等开源数据集广泛采用了这一思路。
DPO:跳过 RM 的捷径。 DPO(Direct Preference Optimization) 证明在 Bradley-Terry 模型下,最优策略与奖励函数存在闭式解析关系,可以直接从偏好数据优化策略,无需训练 RM 和运行 RL:
DPO 将 RLHF 的"RM + RL"两阶段压缩为单阶段监督学习,仅需策略模型和参考模型两个模型,大幅降低了工程复杂度。
GRPO:去掉 Critic。 DeepSeek 提出的 GRPO(Group Relative Policy Optimization) 从另一个方向简化——保留 RM 但去掉 Critic。对同一个 prompt 采样多个回答,用组内奖励的均值和方差做标准化得到优势函数
下表对比了三种主流方案的关键差异:
| 特性 | PPO (RLHF) | DPO | GRPO |
|---|---|---|---|
| 需要 RM | 是 | 否 | 是 |
| 需要 Critic | 是 | 否 | 否 |
| 模型数量 | 4 | 2 | 3 |
| 在线采样 | 是 | 否 | 是 |
| 工程复杂度 | 高 | 低 | 中 |
| 适用场景 | 通用对齐 | 偏好数据充足 | 可验证奖励(数学/代码) |
表 15-3:PPO、DPO、GRPO 三种后训练方案对比。
15.2.8 小结
本节完整梳理了 RLHF 的四阶段流水线:预训练赋予模型语言能力,SFT 激活指令遵循能力,RM 训练让系统学会评判人类偏好,PPO 则在 RM 指引下持续优化生成策略。这条流水线的核心洞察在于——让人类做判断(比较两个回答)比做示范(写出完美回答)更高效,而 Bradley-Terry 模型将这种判断转化为可微的训练信号。PPO-Clip 机制和 KL 约束共同确保了策略更新的稳定性,防止模型"越训越偏"。尽管 DPO、GRPO 等后续工作从不同角度简化了 RLHF 的工程实现,但 InstructGPT 确立的"SFT → RM → RL"三阶段范式,至今仍是理解大模型对齐技术的基础框架。