5.4 加载预训练权重
从零预训练一个大语言模型需要消耗大量算力和时间。幸运的是,OpenAI 和 HuggingFace 等机构已经公开了多种规模的 GPT-2 预训练权重。本节将介绍如何将这些外部权重加载到我们自己实现的 GPTModel 中,涵盖 OpenAI 原始 TensorFlow 格式的权重转换、HuggingFace safetensors 格式的直接加载,以及内存高效的加载策略。
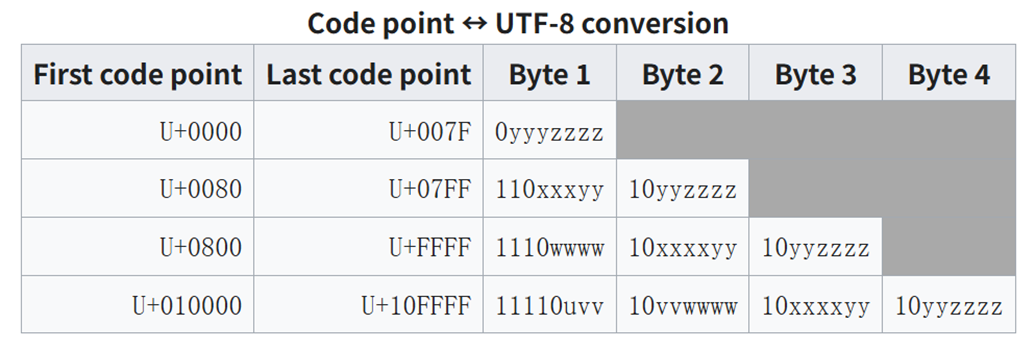
图 5-13:预训练权重的加载流程。从外部格式(TensorFlow checkpoint 或 safetensors)读取参数,经过格式转换后赋值给自定义模型。
5.4.1 从 OpenAI 加载 TensorFlow 权重
OpenAI 发布的 GPT-2 权重采用 TensorFlow checkpoint 格式,因此加载时需要借助 TensorFlow 库读取,再将 NumPy 数组转换为 PyTorch 张量。整个流程分为三步:下载权重文件、解析 checkpoint 为 Python 字典、将字典中的参数逐一赋值给 GPTModel。
第一步:下载与解析 checkpoint。 OpenAI 提供了四种规模的 GPT-2 模型(124M、355M、774M、1558M),权重文件托管在公开的 Azure Blob Storage 上。每个模型包含 checkpoint 索引文件、数据文件和超参数配置文件 hparams.json。下载完成后,使用 TensorFlow 的 tf.train.list_variables 和 tf.train.load_variable 逐一读取 checkpoint 中的变量,并按照层级结构组织为嵌套字典:
import json
import numpy as np
import tensorflow as tf
def load_gpt2_params_from_tf_ckpt(ckpt_path, settings):
params = {"blocks": [{} for _ in range(settings["n_layer"])]}
for name, _ in tf.train.list_variables(ckpt_path):
variable_array = np.squeeze(tf.train.load_variable(ckpt_path, name))
variable_name_parts = name.split("/")[1:] # 跳过 'model/' 前缀
target_dict = params
if variable_name_parts[0].startswith("h"):
layer_number = int(variable_name_parts[0][1:])
target_dict = params["blocks"][layer_number]
for key in variable_name_parts[1:-1]:
target_dict = target_dict.setdefault(key, {})
last_key = variable_name_parts[-1]
target_dict[last_key] = variable_array
return params解析后的 params 字典包含以下顶层键:wte(token embedding)、wpe(position embedding)、g 和 b(final LayerNorm 的 scale 和 shift),以及 blocks 列表(每个元素对应一个 Transformer 层的参数)。
第二步:初始化模型。 加载 OpenAI 权重时,模型配置必须与原始 GPT-2 保持一致。特别需要注意的是,原始 GPT-2 的注意力层使用了 bias 向量,因此必须设置 qkv_bias=True;上下文长度为 1024:
BASE_CONFIG = {
"vocab_size": 50257,
"context_length": 1024,
"drop_rate": 0.0,
"qkv_bias": True
}
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
CHOOSE_MODEL = "gpt2-small (124M)"
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
gpt = GPTModel(BASE_CONFIG)第三步:权重赋值。 OpenAI 的权重布局与我们的 GPTModel 存在两处关键差异,赋值时需要处理:
- QKV 合并权重需要拆分。 OpenAI 将 query、key、value 的投影矩阵拼接为一个
c_attn权重,需要沿最后一个维度等分为三份。 - 权重矩阵需要转置。 OpenAI 使用 Conv1D 实现线性层(权重形状为
[in, out]),而 PyTorch 的nn.Linear期望[out, in],因此所有权重矩阵在赋值时需要转置。
import numpy as np
import torch
def assign(left, right):
if left.shape != right.shape:
raise ValueError(f"Shape mismatch. Left: {left.shape}, Right: {right.shape}")
return torch.nn.Parameter(torch.tensor(right))
def load_weights_into_gpt(gpt, params):
gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params["wpe"])
gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params["wte"])
for b in range(len(params["blocks"])):
# 拆分合并的 QKV 权重和偏置
q_w, k_w, v_w = np.split(
params["blocks"][b]["attn"]["c_attn"]["w"], 3, axis=-1)
q_b, k_b, v_b = np.split(
params["blocks"][b]["attn"]["c_attn"]["b"], 3, axis=-1)
# 注意力层(权重需转置)
gpt.trf_blocks[b].att.W_query.weight = assign(
gpt.trf_blocks[b].att.W_query.weight, q_w.T)
gpt.trf_blocks[b].att.W_key.weight = assign(
gpt.trf_blocks[b].att.W_key.weight, k_w.T)
gpt.trf_blocks[b].att.W_value.weight = assign(
gpt.trf_blocks[b].att.W_value.weight, v_w.T)
gpt.trf_blocks[b].att.W_query.bias = assign(
gpt.trf_blocks[b].att.W_query.bias, q_b)
gpt.trf_blocks[b].att.W_key.bias = assign(
gpt.trf_blocks[b].att.W_key.bias, k_b)
gpt.trf_blocks[b].att.W_value.bias = assign(
gpt.trf_blocks[b].att.W_value.bias, v_b)
# 注意力输出投影
gpt.trf_blocks[b].att.out_proj.weight = assign(
gpt.trf_blocks[b].att.out_proj.weight,
params["blocks"][b]["attn"]["c_proj"]["w"].T)
gpt.trf_blocks[b].att.out_proj.bias = assign(
gpt.trf_blocks[b].att.out_proj.bias,
params["blocks"][b]["attn"]["c_proj"]["b"])
# 前馈网络(权重需转置)
gpt.trf_blocks[b].ff.layers[0].weight = assign(
gpt.trf_blocks[b].ff.layers[0].weight,
params["blocks"][b]["mlp"]["c_fc"]["w"].T)
gpt.trf_blocks[b].ff.layers[0].bias = assign(
gpt.trf_blocks[b].ff.layers[0].bias,
params["blocks"][b]["mlp"]["c_fc"]["b"])
gpt.trf_blocks[b].ff.layers[2].weight = assign(
gpt.trf_blocks[b].ff.layers[2].weight,
params["blocks"][b]["mlp"]["c_proj"]["w"].T)
gpt.trf_blocks[b].ff.layers[2].bias = assign(
gpt.trf_blocks[b].ff.layers[2].bias,
params["blocks"][b]["mlp"]["c_proj"]["b"])
# LayerNorm
gpt.trf_blocks[b].norm1.scale = assign(
gpt.trf_blocks[b].norm1.scale, params["blocks"][b]["ln_1"]["g"])
gpt.trf_blocks[b].norm1.shift = assign(
gpt.trf_blocks[b].norm1.shift, params["blocks"][b]["ln_1"]["b"])
gpt.trf_blocks[b].norm2.scale = assign(
gpt.trf_blocks[b].norm2.scale, params["blocks"][b]["ln_2"]["g"])
gpt.trf_blocks[b].norm2.shift = assign(
gpt.trf_blocks[b].norm2.shift, params["blocks"][b]["ln_2"]["b"])
# 最终 LayerNorm 和输出头(与 token embedding 共享权重)
gpt.final_norm.scale = assign(gpt.final_norm.scale, params["g"])
gpt.final_norm.shift = assign(gpt.final_norm.shift, params["b"])
gpt.out_head.weight = assign(gpt.out_head.weight, params["wte"])最后一行将输出头的权重设为 token embedding 权重——这是 GPT-2 的权重共享(weight tying)设计,输出层和输入 embedding 共用同一组参数,既减少了参数量,又在语义空间上保持了一致性。
5.4.2 从 HuggingFace 加载 safetensors 权重

图 5-14:HuggingFace 模型权重仓库结构。safetensors 格式的权重文件、配置文件和分词器文件共同构成可复用的预训练模型包。
OpenAI 原始格式依赖 TensorFlow,安装和兼容性问题较多。更现代的替代方案是直接从 HuggingFace Hub 下载 safetensors 格式的权重文件。
safetensors 与 state_dict 对比。 PyTorch 原生的 state_dict 保存方式基于 Python 的 pickle 序列化协议,而 safetensors 是 HuggingFace 开发的专用格式。两者的核心差异如下:
| 特性 | state_dict (.pth/.bin) | safetensors (.safetensors) |
|---|---|---|
| 序列化协议 | pickle(可执行任意 Python 代码) | 自定义二进制格式(仅存储张量数据) |
| 安全性 | 加载时可能执行恶意代码 | 设计上不可执行代码,天然安全 |
| 加载速度 | 需要反序列化整个文件 | 支持零拷贝和内存映射,加载更快 |
| 跨框架 | 仅 PyTorch | 支持 PyTorch、TensorFlow、JAX 等 |
| 防护措施 | PyTorch 2.6+ 默认 weights_only=True | 无需额外参数 |
表 5-4:state_dict 与 safetensors 格式对比。
在 PyTorch 2.6 之前,torch.load 默认允许执行 pickle 中的任意代码,攻击者可以构造恶意权重文件在加载时执行任意命令。PyTorch 2.6 起默认启用 weights_only=True 来缓解此风险,但 safetensors 从设计层面根本消除了这一攻击面。对于从不可信来源下载的权重,推荐优先使用 safetensors 格式。
图 5-15:safetensors 格式的优势。相比 pickle 序列化的 state_dict,safetensors 提供安全性、零拷贝加载和跨框架兼容性。
加载流程。 HuggingFace Hub 上的 openai-community/gpt2 仓库提供了 safetensors 格式的权重。加载代码如下:
import os
import requests
import torch
from safetensors.torch import load_file
# 下载 safetensors 文件
model_id = "gpt2" # 可选:gpt2, gpt2-medium, gpt2-large, gpt2-xl
url = f"https://huggingface.co/openai-community/{model_id}/resolve/main/model.safetensors"
output_file = f"model-{model_id}.safetensors"
if not os.path.exists(output_file):
response = requests.get(url, timeout=60)
response.raise_for_status()
with open(output_file, "wb") as f:
f.write(response.content)
# 加载为 state_dict
state_dict = load_file(output_file)load_file 返回的是一个键为参数名、值为 PyTorch 张量的字典。HuggingFace 格式的参数命名与 OpenAI 原始格式不同——使用点分层级命名(如 h.0.attn.c_attn.weight),但权重的语义和布局完全一致,同样需要拆分 QKV 和转置权重矩阵:
def assign(left, right):
if left.shape != right.shape:
raise ValueError(f"Shape mismatch. Left: {left.shape}, Right: {right.shape}")
return torch.nn.Parameter(right.detach())
def load_weights_from_safetensors(gpt, params):
gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params["wpe.weight"])
gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params["wte.weight"])
for b in range(len(gpt.trf_blocks)):
# 拆分 QKV(使用 torch.chunk 替代 np.split)
q_w, k_w, v_w = torch.chunk(
params[f"h.{b}.attn.c_attn.weight"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.weight = assign(
gpt.trf_blocks[b].att.W_query.weight, q_w.T)
gpt.trf_blocks[b].att.W_key.weight = assign(
gpt.trf_blocks[b].att.W_key.weight, k_w.T)
gpt.trf_blocks[b].att.W_value.weight = assign(
gpt.trf_blocks[b].att.W_value.weight, v_w.T)
q_b, k_b, v_b = torch.chunk(
params[f"h.{b}.attn.c_attn.bias"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.bias = assign(
gpt.trf_blocks[b].att.W_query.bias, q_b)
gpt.trf_blocks[b].att.W_key.bias = assign(
gpt.trf_blocks[b].att.W_key.bias, k_b)
gpt.trf_blocks[b].att.W_value.bias = assign(
gpt.trf_blocks[b].att.W_value.bias, v_b)
gpt.trf_blocks[b].att.out_proj.weight = assign(
gpt.trf_blocks[b].att.out_proj.weight,
params[f"h.{b}.attn.c_proj.weight"].T)
gpt.trf_blocks[b].att.out_proj.bias = assign(
gpt.trf_blocks[b].att.out_proj.bias,
params[f"h.{b}.attn.c_proj.bias"])
gpt.trf_blocks[b].ff.layers[0].weight = assign(
gpt.trf_blocks[b].ff.layers[0].weight,
params[f"h.{b}.mlp.c_fc.weight"].T)
gpt.trf_blocks[b].ff.layers[0].bias = assign(
gpt.trf_blocks[b].ff.layers[0].bias,
params[f"h.{b}.mlp.c_fc.bias"])
gpt.trf_blocks[b].ff.layers[2].weight = assign(
gpt.trf_blocks[b].ff.layers[2].weight,
params[f"h.{b}.mlp.c_proj.weight"].T)
gpt.trf_blocks[b].ff.layers[2].bias = assign(
gpt.trf_blocks[b].ff.layers[2].bias,
params[f"h.{b}.mlp.c_proj.bias"])
gpt.trf_blocks[b].norm1.scale = assign(
gpt.trf_blocks[b].norm1.scale, params[f"h.{b}.ln_1.weight"])
gpt.trf_blocks[b].norm1.shift = assign(
gpt.trf_blocks[b].norm1.shift, params[f"h.{b}.ln_1.bias"])
gpt.trf_blocks[b].norm2.scale = assign(
gpt.trf_blocks[b].norm2.scale, params[f"h.{b}.ln_2.weight"])
gpt.trf_blocks[b].norm2.shift = assign(
gpt.trf_blocks[b].norm2.shift, params[f"h.{b}.ln_2.bias"])
gpt.final_norm.scale = assign(gpt.final_norm.scale, params["ln_f.weight"])
gpt.final_norm.shift = assign(gpt.final_norm.shift, params["ln_f.bias"])
gpt.out_head.weight = assign(gpt.out_head.weight, params["wte.weight"])
gpt = GPTModel(BASE_CONFIG)
load_weights_from_safetensors(gpt, state_dict)
gpt.eval()与 OpenAI 格式的 assign 函数相比,safetensors 版本使用 right.detach() 而非 torch.tensor(right)——因为加载得到的已经是 PyTorch 张量,无需再从 NumPy 数组转换。
5.4.3 使用 transformers 库加载
如果已经安装了 HuggingFace 的 transformers 库,可以更简洁地完成权重加载。GPT2Model.from_pretrained 会自动下载权重并实例化模型,我们只需从其 state_dict() 中提取参数即可:
from transformers import GPT2Model
gpt_hf = GPT2Model.from_pretrained("openai-community/gpt2", cache_dir="checkpoints")
gpt_hf.eval()
# 从 HuggingFace 模型中提取 state_dict,赋值给自定义模型
gpt = GPTModel(BASE_CONFIG)
d = gpt_hf.state_dict()
# 赋值逻辑与 safetensors 版本完全一致
# (参数名格式相同:h.0.attn.c_attn.weight 等)这种方式最为简便,但引入了对 transformers 库的依赖。在生产环境或资源受限场景下,直接使用 safetensors 加载更为轻量。
5.4.4 内存高效的权重加载
图 5-16:模型配置参数与权重加载的对应关系。配置文件中的超参数决定了模型结构,权重文件中的张量按命名规则映射到模型的各个层。
当模型规模增大(如 GPT-2 XL 的 1558M 参数,约 6.4 GB),朴素的加载方式会导致 GPU 显存峰值翻倍。原因在于 model.load_state_dict(torch.load(...)) 会在显存中同时保留模型本身和加载的 state_dict 两份完整的参数副本。以 GPT-2 XL 为例,模型本身占 6.4 GB,加载过程的峰值显存达到 12.8 GB。
方法一:逐参数拷贝。 先将 state_dict 加载到 CPU 内存,再逐个参数拷贝到 GPU 上的模型中。这样 GPU 上只需保留模型本身加上当前正在拷贝的单个参数张量:
model = GPTModel(BASE_CONFIG).to(device)
state_dict = torch.load("model.pth", map_location="cpu", weights_only=True)
with torch.no_grad():
for name, param in model.named_parameters():
if name in state_dict:
param.copy_(state_dict[name].to(device))以 GPT-2 XL 为例,GPU 峰值显存从 12.8 GB 降至约 6.7 GB——仅比模型本身多出一个参数张量的大小。
方法二:meta device + 直接加载到 GPU。 如果 CPU 内存也很紧张,可以使用 PyTorch 的 meta device 创建模型骨架(不分配实际内存),然后将权重直接加载到 GPU:
with torch.device("meta"):
model = GPTModel(BASE_CONFIG)
model = model.to_empty(device=device)
state_dict = torch.load("model.pth", map_location=device, weights_only=True)
with torch.no_grad():
for name, param in model.named_parameters():
if name in state_dict:
param.copy_(state_dict[name])这种方式将 CPU 内存占用从约 6.3 GB 压缩到约 1.3 GB,代价是 GPU 峰值显存回到 12.8 GB(因为 state_dict 也在 GPU 上)。
方法三:mmap 内存映射(推荐)。 PyTorch 的 torch.load 支持 mmap=True 参数,启用内存映射文件 I/O。操作系统按需从磁盘读取数据,无需将整个文件加载到内存。结合 meta device 和 assign=True,这是最简洁高效的方案:
with torch.device("meta"):
model = GPTModel(BASE_CONFIG)
model.load_state_dict(
torch.load("model.pth", map_location=device, weights_only=True, mmap=True),
assign=True
)在 CPU 内存充足时,mmap 的表现与普通加载相近;但在内存受限的环境下,操作系统会自动管理页面换入换出,显著降低峰值内存占用。
三种方法的显存和内存占用对比如下(以 GPT-2 XL 为例):
| 加载方式 | GPU 峰值显存 | CPU 峰值内存 |
|---|---|---|
| 朴素 load_state_dict | 12.8 GB | 4.4 GB |
| 逐参数拷贝(CPU 中转) | 6.7 GB | 6.3 GB |
| meta device + GPU 直接加载 | 12.8 GB | 1.3 GB |
| meta device + mmap(推荐) | 6.4 GB | 按需分配 |
表 5-5:不同权重加载策略的内存占用对比(GPT-2 XL, 1558M 参数)。
本节小结
本节介绍了将预训练权重加载到自定义 GPT 模型的完整流程:
- OpenAI TensorFlow 格式需要借助 TensorFlow 解析 checkpoint,手动将嵌套字典中的 NumPy 数组赋值给 PyTorch 参数,核心难点在于 QKV 合并权重的拆分和 Conv1D 到 Linear 的转置。
- HuggingFace safetensors 格式绕过了 TensorFlow 依赖,直接加载为 PyTorch 张量字典。safetensors 相比传统 pickle 格式在安全性、加载速度和跨框架兼容性上均有优势,是当前推荐的权重分发格式。
- transformers 库提供了最简洁的
from_pretrained一行加载方式,适合快速实验。 - 内存优化方面,逐参数拷贝可将 GPU 峰值显存减半;meta device 可大幅压缩 CPU 内存占用;
mmap=True结合assign=True是兼顾简洁性与效率的推荐方案。
权重加载是连接"模型架构"与"训练成果"的桥梁。理解不同格式之间的转换规则和内存行为,是在实际工程中灵活使用各种开源模型的基础。