3.6 Encoder-only 与 BERT 预训练范式
前几节聚焦于 Transformer 的架构细节与 Decoder-only 模型的设计演化。然而,在大型语言模型席卷一切之前,自然语言处理领域经历了一段同样精彩的旅程:从静态词嵌入到上下文相关的预训练表示,再到"预训练—微调"范式的确立。本节沿着这条脉络,从最基础的词向量技术讲起,逐步推进到 BERT——Encoder-only 架构的集大成者。理解这段历史,既能帮助读者把握 NLP 预训练思想的本质,也能为后文讨论 Decoder-only 预训练范式提供对照基线。
3.6.1 从 One-Hot 到分布式词表示
为什么需要词嵌入? 自然语言中的词是离散符号。最直接的数值化方式是独热编码(One-Hot Encoding):假设词典大小为
换言之,独热编码无法表达词与词之间的语义关系:"猫"和"狗"、"猫"和"飞机"在这种表示下同样遥远。
词嵌入(Word Embedding)的思想是将每个词映射到一个低维稠密向量空间
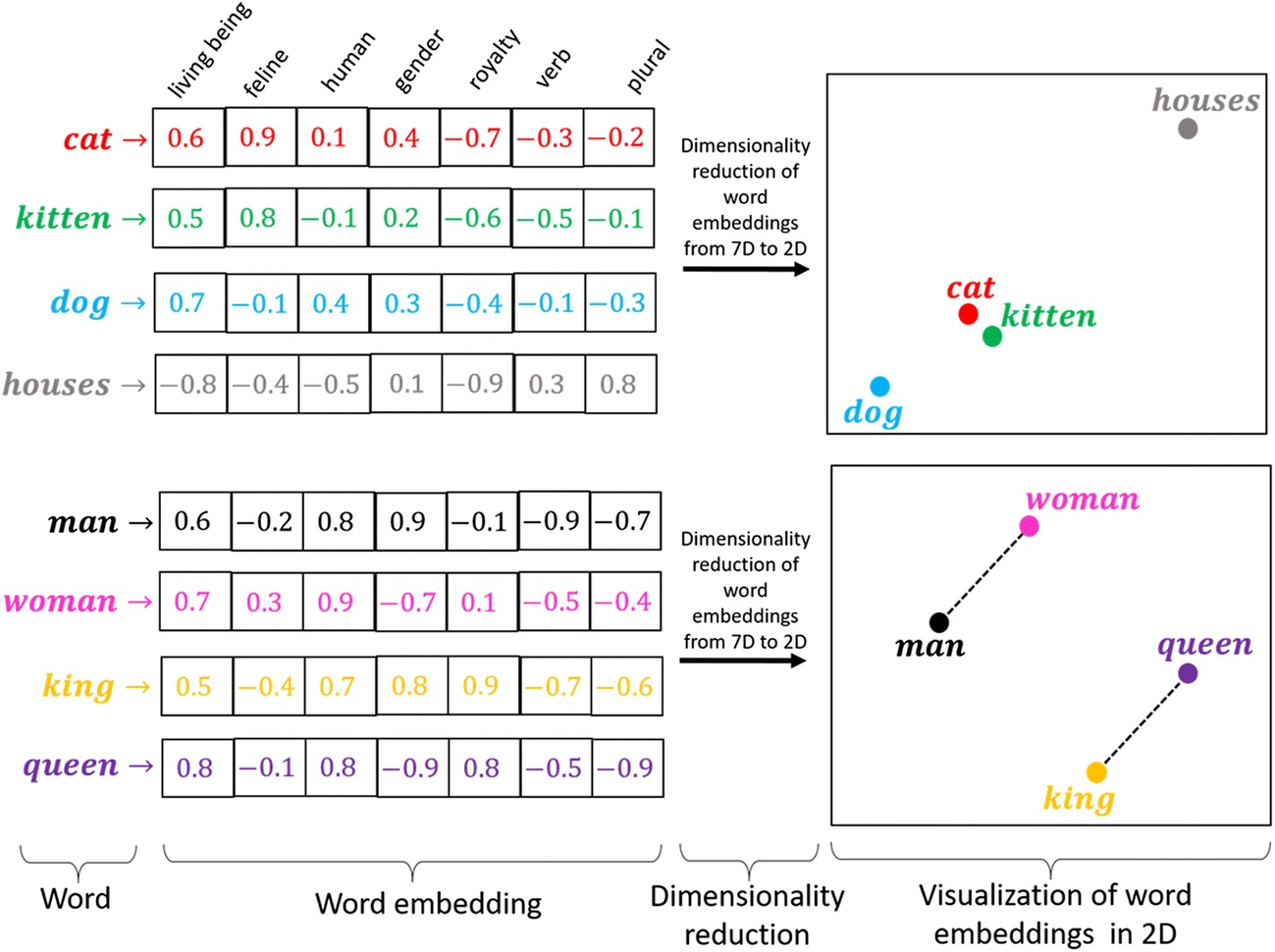
图 3-11:词嵌入的直观理解。每个词被映射为一个稠密向量(图中为 7 维示例),经降维可视化后,语义相近的词在二维空间中自然聚集。下半部分展示了词向量的经典类比性质:
3.6.2 word2vec:Skip-gram 与 CBOW
2013 年,Mikolov 等人提出的 word2vec 是词嵌入的里程碑之作。它提供了两种模型架构,核心思想都是利用词与上下文的共现关系进行自监督学习。
Skip-gram 模型。 给定一个中心词,预测其周围的上下文词。以文本序列"the man loves his son"为例,若选择"loves"为中心词,上下文窗口大小
形式化地,每个词拥有两套
对长度为
训练完成后,通常使用中心词向量
CBOW 模型(Continuous Bag of Words)。 方向相反——给定周围的上下文词,预测中心词。它将上下文词向量取平均
两种模型的核心差异在于预测方向:Skip-gram 从一个词预测多个上下文词,对低频词的表示质量更好;CBOW 从多个上下文词预测一个中心词,训练速度更快。实践中,Skip-gram 更为常用。
计算瓶颈与优化。 上述 softmax 的分母需要对整个词典求和,计算代价为
。word2vec 提出了负采样(Negative Sampling)和层次 softmax(Hierarchical Softmax)两种近似方法来大幅降低计算量。负采样的核心思想是将多分类问题转化为一组二分类问题:对每个正样本(真实上下文词),随机采样若干负样本(非上下文词),仅在这些样本上计算损失。
3.6.3 GloVe 与子词嵌入
GloVe(Global Vectors)。 Pennington 等人(2014)观察到,词-词共现的全局统计量蕴含丰富的语义信息。例如,"solid"与"ice"的共现概率远高于与"steam"的共现概率,而"gas"与"steam"的共现概率远高于与"ice"的共现概率。共现概率之比能够直观地表达语义关系:
| solid | gas | water | fashion | |
|---|---|---|---|---|
| 0.00019 | 0.000066 | 0.003 | 0.000017 | |
| 0.000022 | 0.00078 | 0.0022 | 0.000018 | |
| 比值 | 8.9 | 0.085 | 1.36 | 0.96 |
GloVe 的思路是直接拟合共现矩阵的对数:
其中
子词嵌入与 BPE。 传统词嵌入为每个词分配一个独立向量,无法处理未登录词(Out-of-Vocabulary, OOV)。子词嵌入的思路是将词拆分为更细粒度的子词单元。最广泛使用的子词分割算法是字节对编码(Byte Pair Encoding, BPE)。其流程如下:
- 初始化:将每个词拆分为字符序列,末尾添加特殊标记
</w>表示词边界,所有字符构成初始词典。 - 迭代合并:统计语料中所有相邻子词对的出现频率,将最高频的一对合并为新子词,加入词典,更新语料中的切分结果。
- 终止条件:重复上述过程,直到词典大小达到预设值。
例如,通过 BPE,模型只需学习 "low"、"high"、"er"、"est" 四个子词的表示,即可泛化到 "lower"、"higher"、"lowest"、"highest" 等词。这种方法在现代 NLP 中几乎是标准配置——BERT 使用 WordPiece(BPE 的变体),GPT 系列使用 BPE。
静态词嵌入的根本局限。 无论 word2vec 还是 GloVe,它们都属于上下文无关(Context-Independent)的词表示:每个词无论出现在什么语境中,对应的向量始终相同。然而自然语言中多义现象普遍存在——"crane"在"a crane is flying"中指鹤,在"a crane driver came"中指起重机——静态词向量无法区分这两种含义。这一局限直接催生了上下文相关的预训练表示。
3.6.4 从 ELMo 到 GPT:上下文相关表示的崛起
ELMo(Embeddings from Language Models)。 Peters 等人(2018)提出的 ELMo 是第一个大规模成功的上下文相关词表示方法。它使用双向 LSTM 语言模型,将各层的隐藏状态加权求和作为词的表示。ELMo 的表示是上下文相关的——同一个词在不同句子中会得到不同的向量。但 ELMo 有两个显著局限:(1)双向性是"浅层"的——前向和后向 LSTM 独立训练后拼接,并非真正的深度双向交互;(2)预训练模型的参数在下游任务中被冻结,只作为特征提取器使用,每个下游任务需要设计专门的架构。
GPT(Generative Pre-Training)。 Radford 等人(2018)提出的 GPT 基于 Transformer Decoder,采用从左到右的自回归语言模型进行预训练。GPT 的关键创新在于任务无关(Task-Agnostic)的设计——对不同下游任务,只需在预训练模型之上添加简单的线性输出层,然后微调所有参数。GPT 在 12 项任务中的 9 项刷新了当时的最优结果。但 GPT 的自回归特性意味着它只能利用左侧上下文,对于需要双向理解的任务(如自然语言推理)存在天然劣势。
3.6.5 BERT:双向编码器的架构设计
BERT(Bidirectional Encoder Representations from Transformers) 由 Devlin 等人(2018)提出,结合了 ELMo 的双向性和 GPT 的任务无关性,成为 NLP 预训练范式的标志性工作。
Encoder-only 架构。 BERT 使用 Transformer 的编码器(Encoder)部分。与解码器不同,编码器的自注意力没有因果掩码——每个 token 可以同时关注序列中所有位置(包括左侧和右侧),从而实现真正的深度双向上下文编码。BERT 有两个版本:
| 版本 | 层数 | 隐藏维度 | 注意力头数 | 参数量 |
|---|---|---|---|---|
| BERT-Base | 12 | 768 | 12 | 1.1 亿 |
| BERT-Large | 24 | 1024 | 16 | 3.4 亿 |
输入表示:三重嵌入。 BERT 的输入表示是三种嵌入的逐元素求和:
- 词元嵌入(Token Embedding):将每个子词映射为
维向量,使用 WordPiece 分词。 - 段落嵌入(Segment Embedding):用于区分输入中的两个文本段。属于第一个段落的 token 加
,属于第二个段落的加 。对于单句输入,仅使用 。 - 位置嵌入(Position Embedding):与原始 Transformer 使用固定正弦编码不同,BERT 采用可学习的位置嵌入,最大位置长度为 512。
最终的输入表示为:
特殊标记。 BERT 的输入序列遵循特定格式:
- 单句输入:
[CLS] 句子A [SEP] - 句对输入:
[CLS] 句子A [SEP] 句子B [SEP]
其中 [CLS](Classification)是特殊的分类标记,其最终隐藏状态被用作整个序列的聚合表示;[SEP](Separation)用于分隔两个文本段落。
3.6.6 BERT 的预训练任务
BERT 的预训练由两个自监督任务构成,二者的损失函数线性相加作为总损失。
任务一:掩码语言模型(Masked Language Model, MLM)。 传统的从左到右语言模型无法直接用于训练双向编码器——因为在双向注意力下,模型可以"透视"到自身从而直接看到待预测的词。MLM 的解决方案非常巧妙:随机遮蔽输入序列中 15% 的 token,然后让模型根据双向上下文预测被遮蔽的 token。
然而,如果被选中的 token 全部替换为 [MASK],则会引入预训练与微调之间的不一致——微调阶段的输入中不会出现 [MASK] 标记。为此,BERT 对被选中的 token 采用了 80/10/10 策略:
- 80% 概率:替换为
[MASK](例如 "this movie is great" → "this movie is[MASK]") - 10% 概率:替换为词典中的随机词(例如 "this movie is great" → "this movie is drink")
- 10% 概率:保持原词不变(例如 "this movie is great" → "this movie is great")
这种设计的动机是:80% 的 [MASK] 替换确保模型主要学习从上下文预测被遮蔽词的能力;10% 的随机替换迫使模型不能简单依赖输入 token 本身(因为输入可能是错误的),需要真正利用上下文信息;10% 的保持不变则使模型倾向于将表示向真实词的方向拉近,缓解预训练与微调的分布偏差。
![BERT 预训练的 Masked Language Model 示意图:左侧展示 Transformer 编码器的输入输出结构,输入中 "love" 被替换为 [MASK],模型需要预测原始词;右侧展示完整的双向注意力矩阵,每个 token 都能关注到所有其他 token](/assets/ch00_sec1_bert_pretrain.DMe5IpF4.png)
图 3-12:BERT 预训练中的掩码语言模型。左侧:输入序列 "<cls> I <mask> this red car" 经过 Transformer 编码器后,模型需要在被掩码的位置预测出原始词 "love"。右侧:双向注意力矩阵——与 Decoder 的因果掩码不同,编码器中每个 token 都能关注到序列中的所有其他 token,从而实现深度双向上下文编码。
任务二:下一句预测(Next Sentence Prediction, NSP)。 MLM 能够捕捉词级别的双向上下文,但无法显式建模句子间的逻辑关系。NSP 任务作为补充,让模型判断两个句子是否构成前后文关系。训练数据的构造方式如下:
- 50% 的正样本:句子 B 确实是句子 A 的下一句,标签为 IsNext。
- 50% 的负样本:句子 B 从语料库中随机采样,标签为 NotNext。
模型使用 [CLS] 标记对应的最终隐藏状态,经过一个 MLP 分类器进行二分类预测。
NSP 的争议。 后续研究对 NSP 的必要性提出了质疑。RoBERTa(Liu 等人, 2019)通过实验发现,移除 NSP 任务并增大训练数据量后,模型性能反而有所提升。这表明 NSP 任务可能过于简单——随机采样的负样本往往来自不同主题,模型仅需捕捉主题差异即可完成分类,并未真正学到深层的逻辑推理能力。尽管如此,NSP 的设计思路——在预训练中引入句子级别的监督信号——对后续工作(如 ALBERT 的句序预测任务 SOP)具有启发意义。
预训练语料与规模。 原始 BERT 在 BooksCorpus(8 亿词)和英文 Wikipedia(25 亿词)上进行预训练。BERT-Base 的训练在 4 个 Cloud TPU 上耗时约 4 天,BERT-Large 在 16 个 Cloud TPU 上耗时约 4 天。最终损失为 MLM 损失与 NSP 损失之和:
3.6.7 BERT 微调范式与下游任务
BERT 确立的"预训练—微调"范式极大地简化了 NLP 应用的开发流程:只需在预训练好的 BERT 之上添加轻量的任务特定输出层,然后在下游任务的标注数据上端到端地微调所有参数。这与 ELMo 的"特征提取"方式形成鲜明对比——BERT 微调时,预训练参数和新增输出层参数一同更新,使得整个模型能够针对目标任务进行深度适配。
根据输出粒度的不同,BERT 的下游任务可以分为两大类:
序列级任务(Sequence-level Tasks)。 对整个输入序列(或序列对)产生一个分类标签。利用 [CLS] token 的最终隐藏状态
典型任务包括:
- 情感分析(如 SST-2):判断电影评论是正面还是负面。
- 自然语言推理(如 MNLI, RTE):判断两个句子之间是蕴含、矛盾还是中立关系。
- 语义等价判断(如 QQP, MRPC):判断两个句子是否表达相同含义。
- 语义相似度(如 STS-B):输出两个句子的相似度分数。
词元级任务(Token-level Tasks)。 对输入序列中的每个 token 产生一个标签。利用每个 token 的最终隐藏状态
典型任务包括:
- 命名实体识别(如 CoNLL-2003):标注文本中的人名、地名、组织名等实体。
- 问答抽取(如 SQuAD):给定段落和问题,预测答案在段落中的起止位置。具体做法是对每个 token 分别预测其作为答案起始位置和结束位置的概率。
BERT 的 SOTA 成绩。 在原始论文中,BERT 在 11 项 NLP 基准任务上刷新了当时的最优结果,涵盖单句分类、句对分类、问答和序列标注四大类别。特别是在 GLUE 基准上将平均分提升至 80.5%(BERT-Large),在 SQuAD v1.1 上 F1 达到 93.2%,首次超越人类表现。这些结果有力地证明了"大规模无监督预训练 + 下游任务微调"范式的威力。
3.6.8 BERT 的历史定位与后续演化
BERT 的贡献可以从三个层面理解:
范式层面。 BERT 确立了"预训练—微调"的两阶段范式。在 BERT 之前,每个 NLP 任务通常需要从零开始设计模型架构和训练流程;在 BERT 之后,预训练语言模型成为几乎所有 NLP 系统的基础组件,极大地降低了开发门槛。
架构层面。 BERT 证明了 Encoder-only 架构在自然语言理解任务上的强大能力。双向注意力使得每个 token 的表示能够融合完整的上下文信息,这对分类、匹配、标注等理解类任务尤为关键。
局限性与演化方向。 BERT 的设计也存在已知的不足:
- 预训练与微调的分布偏差:
[MASK]标记仅出现在预训练阶段,微调阶段从不出现,80/10/10 策略只是部分缓解了这一问题。 - 被遮蔽 token 的独立性假设:MLM 预测各个被遮蔽位置时相互独立,忽略了被遮蔽 token 之间的依赖关系。XLNet(Yang 等人, 2019)通过排列语言模型(Permutation Language Model)解决了这一问题。
- 不擅长生成任务:Encoder-only 架构天然适合理解而非生成。需要生成能力的场景更适合使用 Decoder-only(GPT 系列)或 Encoder-Decoder(T5)架构。
- NSP 任务的有效性存疑:如前所述,RoBERTa 证明移除 NSP 后性能不降反升。
在 BERT 之后,一系列变体在不同维度进行了改进:RoBERTa 优化了训练策略(更多数据、更大 batch、去除 NSP);ALBERT 通过参数共享和分解嵌入矩阵大幅减小了模型体积;DeBERTa 引入了解耦注意力机制,分离了内容与位置的交互计算;SpanBERT 将遮蔽单元从单个 token 扩展到连续片段。这些工作共同将 Encoder-only 预训练模型推向了成熟。
本节小结
本节追溯了从静态词嵌入到 BERT 预训练范式的完整演化路径。word2vec 和 GloVe 通过共现统计学习了高质量的静态词向量,但无法处理多义词和上下文依赖;ELMo 引入了上下文相关表示,但仍依赖任务特定架构且双向性较浅;GPT 实现了任务无关的预训练—微调范式,但受限于单向建模。BERT 集各家之长——以 Transformer Encoder 为骨架,通过 MLM 实现深度双向编码,通过三重嵌入统一处理单句和句对输入,通过微调范式适配多种下游任务——成为 NLP 领域的分水岭。
从更宏观的视角看,BERT 代表了 Encoder-only 路线的最高成就,而 GPT 系列则沿着 Decoder-only 路线不断演化,最终在模型规模和通用能力上走得更远。理解 BERT 的设计决策及其权衡,对于把握整个预训练语言模型的技术图景至关重要。