附录D:Qwen3 模型源代码注释
本附录提供 Qwen3 稠密模型的完整 PyTorch 实现,包含逐行中文注释。第七章(§7.2)已从架构设计的角度剖析了 Qwen3 的各个组件——RMSNorm、RoPE、SwiGLU、GQA 及其变体;本附录的目标不同:给出一份可独立运行的完整代码,让读者能够对照注释逐行理解每个组件的实现细节,并在自己的环境中加载预训练权重进行推理。
代码基于 Qwen3-0.6B 模型,但通过修改配置字典可以直接适配 Qwen3 全系列(0.6B 至 32B)的稠密模型。全部代码仅依赖 PyTorch 和 Python 标准库,无需任何第三方模型框架。
D.1 代码组织结构总览
整个实现由以下八个模块组成,自底向上依次为:
| 模块 | 类/函数名 | 作用 | 对应章节 |
|---|---|---|---|
| 归一化 | RMSNorm | 均方根层归一化 | §3.2, §7.2 |
| 位置编码 | compute_rope_params / apply_rope | 旋转位置编码 | §3.3, §7.2 |
| 前馈网络 | FeedForward | SwiGLU 门控前馈 | §3.2, §7.2 |
| 注意力 | GroupedQueryAttention | 分组查询注意力 + QKNorm + KV Cache | §3.2, §7.2 |
| 变换器块 | TransformerBlock | 单个 Transformer 层 | §7.2 |
| 完整模型 | Qwen3Model | 模型组装与前向传播 | §7.2 |
| KV 缓存 | KVCache | 推理时的键值缓存管理 | §7.2 |
| 推理生成 | generate | 自回归文本生成 | §7.2 |
各模块之间的组件关系如下图所示:
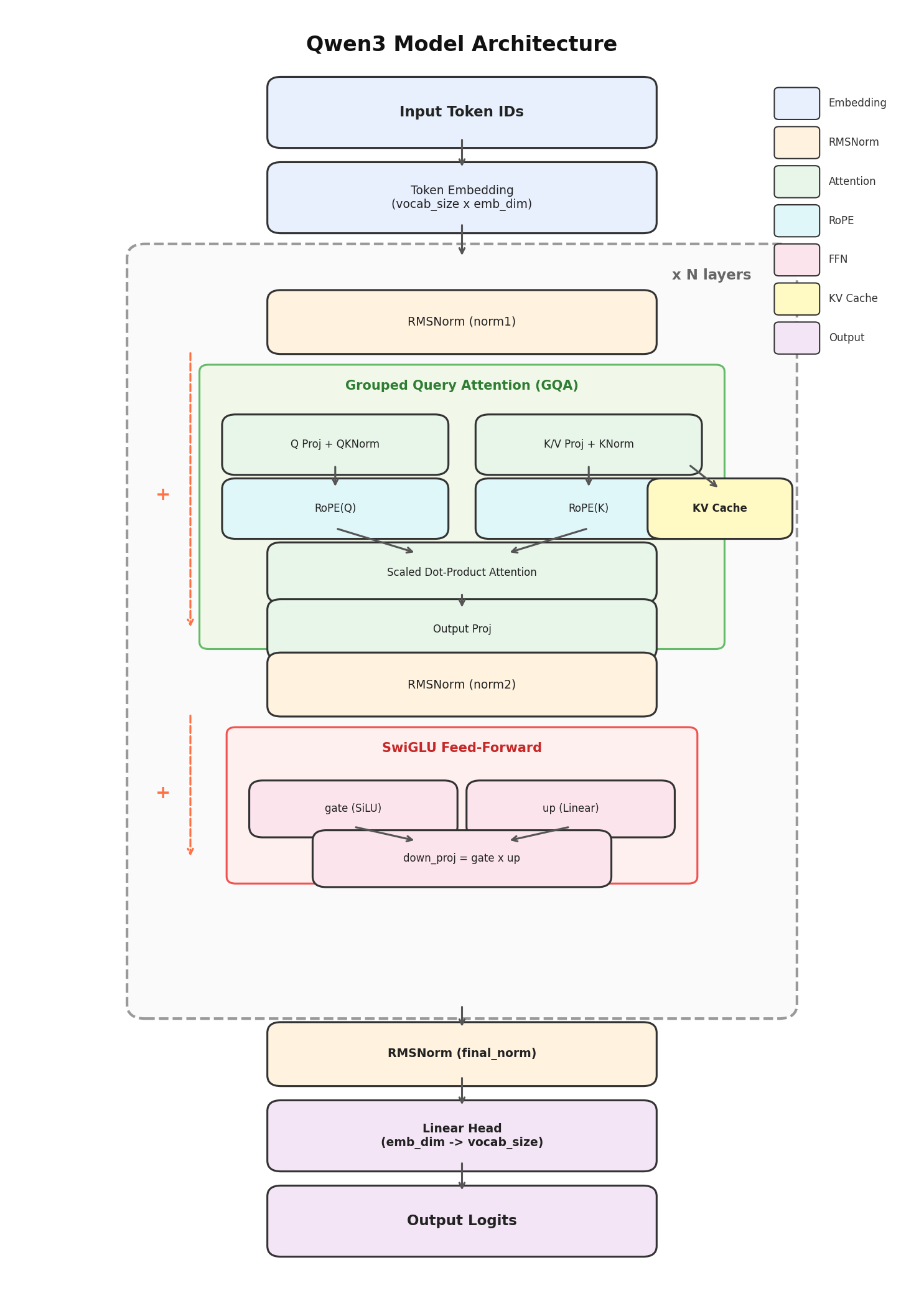
图 D-1:Qwen3 稠密模型架构总览。输入 Token ID 经过 Embedding 层后,依次通过 N 个 Transformer 块(每块包含 RMSNorm → GQA 注意力 → 残差连接 → RMSNorm → SwiGLU FFN → 残差连接),最后经 RMSNorm 和线性投影头输出 logits。GQA 内部集成了 QKNorm、RoPE 和 KV Cache。
D.2 RMSNorm 实现
RMSNorm(Root Mean Square Layer Normalization)是 Qwen3 使用的归一化方法,相比 LayerNorm 省去了均值中心化步骤,计算更快且效果相当。其数学定义为:
其中
import torch
import torch.nn as nn
class RMSNorm(nn.Module):
"""均方根层归一化(RMSNorm)。
与 LayerNorm 不同,RMSNorm 不对输入做均值中心化,
仅使用均方根进行缩放归一化。参数量更少、计算更快。
"""
def __init__(self, emb_dim, eps=1e-6):
"""
参数:
emb_dim: 嵌入维度,即归一化作用的最后一个维度大小
eps: 防止除零的小常数,默认 1e-6
"""
super().__init__()
self.eps = eps
# 可学习的缩放参数 γ,初始化为全 1 向量
# 初始化为 1 保证训练开始时 RMSNorm 接近恒等映射
self.scale = nn.Parameter(torch.ones(emb_dim))
def forward(self, x):
# 保存输入的原始数据类型(可能是 bfloat16)
input_dtype = x.dtype
# 关键:先转为 float32 再计算方差
# bfloat16 仅有 8 位尾数,在低精度下计算 pow(2).mean()
# 会导致显著的精度损失,特别是当输入值较大时
x = x.to(torch.float32)
# 计算每个位置的均方值:对最后一个维度求 x² 的均值
# keepdim=True 保持维度以便后续广播
variance = x.pow(2).mean(dim=-1, keepdim=True)
# rsqrt = 1/sqrt,即计算 x / sqrt(variance + eps)
# 加 eps 防止 variance 为零时除零
norm_x = x * torch.rsqrt(variance + self.eps)
# 乘以可学习的缩放参数 γ,然后转回原始精度
# scale 的形状是 (emb_dim,),通过广播与 norm_x 相乘
return (norm_x * self.scale).to(input_dtype)实现要点: Qwen3 的 RMSNorm 没有偏置参数(bias),这与"移除所有线性层偏置项"的设计原则一致。scale 参数初始化为全 1,保证初始化时归一化层接近恒等映射,不会破坏残差连接的梯度流。
D.3 RoPE 旋转位置编码
旋转位置编码(Rotary Position Embedding, RoPE)通过对 Query 和 Key 向量施加与位置相关的旋转变换来注入位置信息。其核心思想是:将
对于位置
其中 rotate_half 操作将向量的前半部分与后半部分交换并取反。
def compute_rope_params(head_dim, theta_base=10_000,
context_length=4096, dtype=torch.float32):
"""预计算 RoPE 所需的 cos 和 sin 值。
参数:
head_dim: 每个注意力头的维度(必须为偶数)
theta_base: 频率基数,Qwen3 稠密版使用 1,000,000
更大的 theta_base 使频率衰减更缓慢,
有助于模型在超长上下文中保持位置分辨率
context_length: 最大上下文长度
dtype: 计算精度
返回:
cos, sin: 形状均为 (context_length, head_dim) 的张量
"""
assert head_dim % 2 == 0, "注意力头维度必须为偶数"
# 计算逆频率向量:θ_i = 1 / (theta_base^(2i/d))
# 其中 i = 0, 1, ..., d/2-1
# 低维度对应高频旋转(变化快),高维度对应低频旋转(变化慢)
inv_freq = 1.0 / (theta_base ** (
torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float()
/ head_dim
))
# 生成位置索引:0, 1, 2, ..., context_length-1
positions = torch.arange(context_length, dtype=dtype)
# 外积:每个位置 m 与每个频率 θ_i 相乘,得到旋转角度
# angles 形状: (context_length, head_dim // 2)
angles = positions[:, None] * inv_freq[None, :]
# 拼接使角度覆盖完整的 head_dim 维度
# 前半部分和后半部分使用相同的角度值
# 形状: (context_length, head_dim)
angles = torch.cat([angles, angles], dim=1)
# 预计算 cos 和 sin 值,避免在每次前向传播时重复计算
cos = torch.cos(angles)
sin = torch.sin(angles)
return cos, sin
def apply_rope(x, cos, sin, offset=0):
"""将 RoPE 旋转应用到输入张量。
参数:
x: 输入张量,形状 (batch_size, num_heads, seq_len, head_dim)
cos: 预计算的余弦值
sin: 预计算的正弦值
offset: 位置偏移量,用于 KV Cache 场景
在增量解码时,新 token 的位置不是从 0 开始,
而是从已缓存的序列长度开始
返回:
旋转后的张量,形状与输入相同
"""
batch_size, num_heads, seq_len, head_dim = x.shape
assert head_dim % 2 == 0, "注意力头维度必须为偶数"
# 将输入向量拆分为前半部分和后半部分
# 每半部分代表 d/2 个二维旋转子空间的一个分量
x1 = x[..., : head_dim // 2] # 前半部分: x_1, x_3, x_5, ...
x2 = x[..., head_dim // 2 :] # 后半部分: x_2, x_4, x_6, ...
# 根据 offset 截取对应位置的 cos/sin 值
# unsqueeze(0).unsqueeze(0) 添加 batch 和 head 维度以便广播
# 最终形状: (1, 1, seq_len, head_dim)
cos = cos[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)
sin = sin[offset:offset + seq_len, :].unsqueeze(0).unsqueeze(0)
# rotate_half 操作:将 (-x2, x1) 拼接
# 对应二维旋转矩阵的 [-sin, cos] 部分
rotated = torch.cat((-x2, x1), dim=-1)
# 应用旋转公式:x' = x * cos + rotate_half(x) * sin
# 等价于对每对 (x_{2i}, x_{2i+1}) 施加二维旋转矩阵
x_rotated = (x * cos) + (rotated * sin)
# 旋转后可以安全地转回低精度(cos/sin 运算在 float32 下完成)
return x_rotated.to(dtype=x.dtype)实现要点: offset 参数是支持 KV Cache 增量解码的关键。在预填充阶段 offset=0,所有 token 从位置 0 开始编码;在逐 token 解码阶段,offset 等于已生成的 token 数,确保新 token 获得正确的位置编码。Qwen3 稠密版使用 theta_base=1,000,000(比原始 RoPE 的 10,000 大 100 倍),使旋转角度变化更缓慢,提升长上下文的位置分辨率。
D.4 SwiGLU 前馈网络
SwiGLU(Swish-Gated Linear Unit)是 Qwen3 使用的前馈网络结构,由两条并行的线性投影构成:一条经过 SiLU(即 Swish)激活作为门控信号,另一条保持线性,两者逐元素相乘后通过下投影层降维:
其中
class FeedForward(nn.Module):
"""SwiGLU 门控前馈网络。
包含三个线性层:gate_proj(门控投影)、up_proj(上投影)
和 down_proj(下投影)。门控投影经过 SiLU 激活后与上投影
逐元素相乘,实现自适应的信息过滤。
参数量为 3 × emb_dim × hidden_dim,比标准 FFN 多 50%,
因此 hidden_dim 通常设为 emb_dim 的约 3 倍(而非 4 倍)以保持总参数量可比。
"""
def __init__(self, cfg):
super().__init__()
# gate_proj:门控投影,输出经过 SiLU 激活
# 将 emb_dim 维输入映射到 hidden_dim 维
self.fc1 = nn.Linear(
cfg["emb_dim"], cfg["hidden_dim"],
dtype=cfg["dtype"], bias=False # Qwen3 全系列不使用偏置
)
# up_proj:上投影,保持线性(不经过激活函数)
self.fc2 = nn.Linear(
cfg["emb_dim"], cfg["hidden_dim"],
dtype=cfg["dtype"], bias=False
)
# down_proj:下投影,将 hidden_dim 维映射回 emb_dim 维
self.fc3 = nn.Linear(
cfg["hidden_dim"], cfg["emb_dim"],
dtype=cfg["dtype"], bias=False
)
def forward(self, x):
# 门控分支:SiLU(x @ W_gate)
# SiLU(x) = x * sigmoid(x),是一个平滑的非线性激活函数
x_fc1 = self.fc1(x)
# 线性分支:x @ W_up
x_fc2 = self.fc2(x)
# 门控机制:两条分支逐元素相乘
# SiLU 的输出范围大致在 (-0.28, +∞),起到软门控的作用:
# 当 gate 值接近 0 时信息被抑制,gate 值大时信息通过
x = nn.functional.silu(x_fc1) * x_fc2
# 下投影:将 hidden_dim 维映射回 emb_dim 维
return self.fc3(x)实现要点: 三个线性层在 Qwen3 权重文件中分别对应 gate_proj(fc1)、up_proj(fc2)和 down_proj(fc3)。SwiGLU 的参数量为 hidden_dim=3072 = 3 × emb_dim,恰好弥补了多出的第三个投影矩阵带来的参数开销。
D.5 分组查询注意力(GQA)
分组查询注意力(Grouped Query Attention, GQA)是 MHA 和 MQA 的折中方案:Query 保持完整的头数,Key 和 Value 使用较少的分组数,同一组内的多个 Query 头共享一组 K/V。Qwen3 全系列固定 head_dim=128、n_kv_groups=8。
此外,Qwen3 引入了 QKNorm——在 Query 和 Key 送入 RoPE 之前,分别通过 RMSNorm 归一化。这防止了深层网络中注意力 logits 爆炸:当层数达到 64 时,未归一化的 Q/K 向量范数可能增长到溢出 bfloat16 的表示范围。
注意力计算的完整流程为:
class GroupedQueryAttention(nn.Module):
"""分组查询注意力,支持 QKNorm 和 KV Cache。
Query 头数为 num_heads,Key/Value 头数为 num_kv_groups。
每 group_size = num_heads // num_kv_groups 个 Q 头共享
同一组的 K/V 头,在推理时大幅减少 KV Cache 的内存占用。
"""
def __init__(self, d_in, num_heads, num_kv_groups,
head_dim=None, qk_norm=False, dtype=None):
"""
参数:
d_in: 输入嵌入维度
num_heads: Query 头的总数
num_kv_groups: Key/Value 的分组数(共享组数)
head_dim: 每个头的维度,若为 None 则自动计算为 d_in // num_heads
qk_norm: 是否对 Q 和 K 做 RMSNorm(Qwen3 全系列启用)
dtype: 参数数据类型
"""
super().__init__()
# Q 头数必须是 KV 组数的整数倍
assert num_heads % num_kv_groups == 0
self.num_heads = num_heads
self.num_kv_groups = num_kv_groups
# 每个 KV 组对应的 Q 头数
self.group_size = num_heads // num_kv_groups
if head_dim is None:
assert d_in % num_heads == 0
head_dim = d_in // num_heads
self.head_dim = head_dim
# Q 的总输出维度 = num_heads × head_dim
# 注意:当 head_dim 被显式指定时,d_out 可能不等于 d_in
# 例如 Qwen3-0.6B: d_in=1024, num_heads=16, head_dim=128
# → d_out = 16 × 128 = 2048 ≠ d_in
self.d_out = num_heads * head_dim
# Q 投影:d_in → num_heads × head_dim
self.W_query = nn.Linear(d_in, self.d_out, bias=False, dtype=dtype)
# K 投影:d_in → num_kv_groups × head_dim(比 Q 少)
self.W_key = nn.Linear(
d_in, num_kv_groups * head_dim, bias=False, dtype=dtype
)
# V 投影:与 K 相同维度
self.W_value = nn.Linear(
d_in, num_kv_groups * head_dim, bias=False, dtype=dtype
)
# 输出投影:d_out → d_in,将多头拼接结果映射回原始维度
self.out_proj = nn.Linear(self.d_out, d_in, bias=False, dtype=dtype)
# QKNorm:在 RoPE 之前对 Q 和 K 做 RMSNorm
# 归一化粒度是每个头(head_dim 维),而非整个投影
if qk_norm:
self.q_norm = RMSNorm(head_dim, eps=1e-6)
self.k_norm = RMSNorm(head_dim, eps=1e-6)
else:
self.q_norm = self.k_norm = None
def forward(self, x, mask, cos, sin, start_pos=0, cache=None):
"""
参数:
x: 输入张量,形状 (batch, seq_len, d_in)
mask: 因果注意力掩码
cos, sin: RoPE 预计算的三角函数值
start_pos: KV Cache 场景下的位置偏移
cache: 元组 (prev_keys, prev_values) 或 None
返回:
output: 注意力输出,形状 (batch, seq_len, d_in)
next_cache: 更新后的 KV 缓存
"""
b, num_tokens, _ = x.shape
# ===== 1. 线性投影 =====
queries = self.W_query(x) # (b, seq_len, num_heads * head_dim)
keys = self.W_key(x) # (b, seq_len, num_kv_groups * head_dim)
values = self.W_value(x) # (b, seq_len, num_kv_groups * head_dim)
# ===== 2. 重塑为多头格式 =====
# 从 (b, seq_len, total_dim) 变为 (b, num_heads, seq_len, head_dim)
queries = queries.view(
b, num_tokens, self.num_heads, self.head_dim
).transpose(1, 2)
keys_new = keys.view(
b, num_tokens, self.num_kv_groups, self.head_dim
).transpose(1, 2)
values_new = values.view(
b, num_tokens, self.num_kv_groups, self.head_dim
).transpose(1, 2)
# ===== 3. QKNorm =====
# 在 RoPE 之前归一化 Q 和 K,防止注意力 logits 爆炸
if self.q_norm:
queries = self.q_norm(queries)
if self.k_norm:
keys_new = self.k_norm(keys_new)
# ===== 4. 应用 RoPE =====
# offset=start_pos 确保增量解码时位置编码连续
queries = apply_rope(queries, cos, sin, offset=start_pos)
keys_new = apply_rope(keys_new, cos, sin, offset=start_pos)
# ===== 5. KV Cache 拼接 =====
if cache is not None:
# 将新计算的 K/V 与缓存中的历史 K/V 拼接
prev_k, prev_v = cache
keys = torch.cat([prev_k, keys_new], dim=2)
values = torch.cat([prev_v, values_new], dim=2)
else:
# 预填充阶段:无缓存,直接使用当前 K/V
keys, values = keys_new, values_new
# 保存当前完整的 K/V 供下一步解码使用
next_cache = (keys, values)
# ===== 6. 扩展 KV 头以匹配 Q 头数 =====
# GQA 的核心操作:将 num_kv_groups 个 KV 头
# 复制 group_size 次,使其与 num_heads 个 Q 头一一对应
# 例如:8 个 KV 组,group_size=2 → 扩展为 16 个 KV 头
keys = keys.repeat_interleave(self.group_size, dim=1)
values = values.repeat_interleave(self.group_size, dim=1)
# ===== 7. 缩放点积注意力 =====
# Q @ K^T: (b, heads, seq_q, head_dim) @ (b, heads, head_dim, seq_k)
# → (b, heads, seq_q, seq_k)
attn_scores = queries @ keys.transpose(2, 3)
# 应用因果掩码:未来位置的分数设为 -inf
attn_scores = attn_scores.masked_fill(mask, -torch.inf)
# 缩放后 softmax:除以 sqrt(head_dim) 防止点积过大
attn_weights = torch.softmax(
attn_scores / self.head_dim**0.5, dim=-1
)
# ===== 8. 加权求和与输出投影 =====
# (b, heads, seq_q, seq_k) @ (b, heads, seq_k, head_dim)
# → (b, heads, seq_q, head_dim)
context = (attn_weights @ values).transpose(1, 2)
# 拼接所有头:(b, seq_q, num_heads * head_dim)
context = context.reshape(b, num_tokens, self.d_out)
# 输出投影:将多头拼接结果映射回 d_in 维
return self.out_proj(context), next_cache实现要点:
- GQA 的内存节省:以 Qwen3-0.6B 为例,
num_heads=16、num_kv_groups=8,KV Cache 的内存占用仅为 MHA 的;对于更大的模型如 Qwen3-32B( num_heads=64、num_kv_groups=8),节省比例达到。 - QKNorm 的位置:QKNorm 必须在 RoPE 之前执行——如果在 RoPE 之后归一化,会破坏旋转编码注入的位置信息。
repeat_interleavevsexpand:此处使用repeat_interleave实际复制了数据,在某些硬件上可以获得更好的内存访问模式;生产环境中也可以使用expand避免数据复制。
D.6 Transformer Block
每个 Transformer 块遵循 Pre-Norm + 残差连接的标准布局:先归一化再计算,计算结果与原始输入相加。这种设计保证了梯度在残差路径上的直接流动,使深层网络的训练更加稳定。
class TransformerBlock(nn.Module):
"""单个 Transformer 层。
结构:x → norm1 → GQA → + x → norm2 → FFN → + x
采用 Pre-Norm 布局:归一化在子层之前,而非之后。
"""
def __init__(self, cfg):
super().__init__()
# 分组查询注意力子层
self.att = GroupedQueryAttention(
d_in=cfg["emb_dim"],
num_heads=cfg["n_heads"],
head_dim=cfg["head_dim"],
num_kv_groups=cfg["n_kv_groups"],
qk_norm=cfg["qk_norm"],
dtype=cfg["dtype"]
)
# SwiGLU 前馈网络子层
self.ff = FeedForward(cfg)
# 两个独立的 RMSNorm 层,分别用于注意力和 FFN 之前
self.norm1 = RMSNorm(cfg["emb_dim"], eps=1e-6)
self.norm2 = RMSNorm(cfg["emb_dim"], eps=1e-6)
def forward(self, x, mask, cos, sin, start_pos=0, cache=None):
"""
参数与 GroupedQueryAttention.forward 相同。
返回:
x: 该层的输出,形状 (batch, seq_len, emb_dim)
next_cache: 该层更新后的 KV 缓存
"""
# --- 注意力子层 + 残差连接 ---
shortcut = x # 保存输入用于残差连接
x = self.norm1(x) # Pre-Norm:先归一化
x, next_cache = self.att( # 注意力计算
x, mask, cos, sin,
start_pos=start_pos,
cache=cache
)
x = x + shortcut # 残差连接:加回原始输入
# --- FFN 子层 + 残差连接 ---
shortcut = x # 保存中间结果
x = self.norm2(x) # Pre-Norm
x = self.ff(x) # SwiGLU 前馈网络
x = x + shortcut # 残差连接
return x, next_cacheD.7 完整模型组装
Qwen3Model 将所有组件组装为完整的语言模型:Token Embedding → N 个 Transformer 块 → 最终 RMSNorm → 线性输出头。
class Qwen3Model(nn.Module):
"""Qwen3 稠密语言模型。
支持两种前向模式:
1. 预填充(prefill):输入完整提示序列,不使用缓存
2. 增量解码(cached decoding):逐 token 生成,使用 KV Cache
"""
def __init__(self, cfg):
super().__init__()
# Token Embedding:将 token ID 映射为稠密向量
self.tok_emb = nn.Embedding(
cfg["vocab_size"], cfg["emb_dim"], dtype=cfg["dtype"]
)
# N 个 Transformer 块堆叠
self.trf_blocks = nn.ModuleList(
[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
# 最终归一化层:在输出头之前做一次 RMSNorm
self.final_norm = RMSNorm(cfg["emb_dim"])
# 线性输出头:将 emb_dim 维向量映射到 vocab_size 维 logits
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"],
bias=False, dtype=cfg["dtype"]
)
# 预计算 RoPE 的 cos/sin 值并注册为 buffer
# buffer 不参与梯度计算,但会随模型一起移动到 GPU
if cfg["head_dim"] is None:
head_dim = cfg["emb_dim"] // cfg["n_heads"]
else:
head_dim = cfg["head_dim"]
cos, sin = compute_rope_params(
head_dim=head_dim,
theta_base=cfg["rope_base"],
context_length=cfg["context_length"]
)
# persistent=False: 不保存到 state_dict(节省空间,可重新计算)
self.register_buffer("cos", cos, persistent=False)
self.register_buffer("sin", sin, persistent=False)
self.cfg = cfg
# 跟踪当前解码位置,用于 KV Cache 场景
self.current_pos = 0
def forward(self, in_idx, cache=None):
"""
参数:
in_idx: 输入 token ID 张量,形状 (batch, seq_len)
cache: KVCache 对象或 None
None 表示预填充模式,KVCache 表示增量解码模式
返回:
logits: 形状 (batch, seq_len, vocab_size) 的输出概率分布
"""
# Token Embedding 查表
tok_embeds = self.tok_emb(in_idx)
x = tok_embeds
num_tokens = x.shape[1]
# ===== 构建因果注意力掩码 =====
if cache is not None:
# 增量解码模式:
# 当前位置 = 已生成 token 数,新 token 需要能看到所有历史 token
pos_start = self.current_pos
pos_end = pos_start + num_tokens
self.current_pos = pos_end
# 掩码形状: (num_tokens, pos_end)
# 新 token 可以看到所有已生成的 token(包括自己)
mask = torch.triu(
torch.ones(
pos_end, pos_end,
device=x.device, dtype=torch.bool
),
diagonal=1
)[pos_start:pos_end, :pos_end]
else:
# 预填充模式:标准因果掩码
# 每个位置只能看到自己和之前的 token
pos_start = 0
mask = torch.triu(
torch.ones(
num_tokens, num_tokens,
device=x.device, dtype=torch.bool
),
diagonal=1
)
# 添加 batch 和 head 维度以便广播
# (seq_q, seq_k) → (1, 1, seq_q, seq_k)
# PyTorch 会自动广播到 (batch, num_heads, seq_q, seq_k)
mask = mask[None, None, :, :]
# ===== 逐层通过 Transformer 块 =====
for i, block in enumerate(self.trf_blocks):
# 从 KV Cache 中获取该层的缓存
blk_cache = cache.get(i) if cache else None
x, new_blk_cache = block(
x, mask, self.cos, self.sin,
start_pos=pos_start, cache=blk_cache
)
# 更新该层的 KV 缓存
if cache is not None:
cache.update(i, new_blk_cache)
# ===== 最终归一化与输出 =====
x = self.final_norm(x)
# final_norm 内部转为 float32 计算,输出也是 float32
# out_head 的权重是 bfloat16,需要显式转换以避免精度不匹配
logits = self.out_head(x.to(self.cfg["dtype"]))
return logits
def reset_kv_cache(self):
"""重置 KV Cache 的位置计数器。
在开始新的生成任务前调用。
"""
self.current_pos = 0模型配置字典: 以下是 Qwen3-0.6B 的完整配置。通过修改这些参数可以构建 Qwen3 全系列模型(详见 §7.2 的配置对照表):
QWEN3_CONFIG_06B = {
"vocab_size": 151_936, # 词表大小(覆盖中英文及特殊 token)
"context_length": 40_960, # 最大上下文长度(约 40K tokens)
"emb_dim": 1024, # 嵌入维度
"n_heads": 16, # Query 注意力头数
"n_layers": 28, # Transformer 层数
"hidden_dim": 3072, # FFN 中间维度(= 3 × emb_dim)
"head_dim": 128, # 每个注意力头的维度
"qk_norm": True, # 是否启用 QKNorm
"n_kv_groups": 8, # KV 分组数(GQA)
"rope_base": 1_000_000.0, # RoPE 频率基数
"dtype": torch.bfloat16, # 参数数据类型(半精度节省内存)
}D.8 KV Cache
KV Cache 是自回归推理的核心加速机制。在逐 token 生成时,如果不缓存历史 Key/Value,每生成一个 token 都需要重新计算整个序列的注意力——计算量随序列长度平方增长。KV Cache 将已计算的 K/V 缓存起来,使每步只需计算新 token 的 Q/K/V 并与缓存拼接,将推理复杂度从
class KVCache:
"""逐层 KV 缓存管理器。
为模型的每一层维护一个缓存槽,存储该层已计算的 Key 和 Value 张量。
推理时,新 token 的 K/V 会与缓存拼接,避免重复计算。
"""
def __init__(self, n_layers):
"""
参数:
n_layers: Transformer 层数,每层一个独立的缓存槽
"""
# 初始化为 None 列表,预填充阶段会写入第一批 K/V
self.cache = [None] * n_layers
def get(self, layer_idx):
"""获取指定层的缓存。
返回 None(首次调用)或 (keys, values) 元组。
"""
return self.cache[layer_idx]
def update(self, layer_idx, value):
"""更新指定层的缓存。
value 是 (keys, values) 元组,包含该层截至当前的完整 K/V 序列。
"""
self.cache[layer_idx] = value
def reset(self):
"""清空所有层的缓存。开始新序列时调用。"""
for i in range(len(self.cache)):
self.cache[i] = NoneD.9 推理与生成
以下是一个完整的贪心解码(greedy decoding)生成函数,配合 KV Cache 实现高效的自回归文本生成:
def generate(model, token_ids, max_new_tokens, eos_token_id=None):
"""使用 KV Cache 的贪心自回归文本生成。
工作流程:
1. 预填充阶段:将完整提示一次性送入模型,建立 KV Cache
2. 解码阶段:逐 token 生成,每次只送入最新的 1 个 token
参数:
model: Qwen3Model 实例
token_ids: 提示 token ID 张量,形状 (1, prompt_len)
max_new_tokens: 最大生成 token 数
eos_token_id: 结束 token ID,遇到时提前停止
返回:
生成的 token ID 列表
"""
model.eval()
# 创建 KV 缓存并重置位置计数器
cache = KVCache(n_layers=model.cfg["n_layers"])
model.reset_kv_cache()
generated_ids = []
# ===== 阶段一:预填充(Prefill)=====
# 将完整提示一次性送入,建立所有层的 KV Cache
# 只取最后一个位置的 logits(用于预测下一个 token)
with torch.no_grad():
logits = model(token_ids, cache=cache)
next_token_logits = logits[:, -1, :] # (1, vocab_size)
# ===== 阶段二:逐 token 解码 =====
for _ in range(max_new_tokens):
# 贪心解码:选择概率最高的 token
next_token = torch.argmax(next_token_logits, dim=-1, keepdim=True)
# 检查是否生成了结束标记
if eos_token_id is not None and next_token.item() == eos_token_id:
break
generated_ids.append(next_token.item())
# 将新 token 送入模型(只有 1 个 token,利用 KV Cache)
# 模型内部会:
# 1. 用 offset=current_pos 为新 token 计算正确的 RoPE
# 2. 将新的 K/V 拼接到缓存中
# 3. 只输出新 token 位置的 logits
with torch.no_grad():
logits = model(next_token, cache=cache)
next_token_logits = logits[:, -1, :]
return generated_ids完整使用示例。 以下代码展示了如何将所有组件串联起来,从构建模型到生成文本:
# ===== 1. 构建模型 =====
model = Qwen3Model(QWEN3_CONFIG_06B)
# ===== 2. 加载预训练权重 =====
# 此处假设已下载 Qwen3-0.6B 的权重文件
# state_dict = torch.load("qwen3-0.6B-base.pth")
# model.load_state_dict(state_dict)
# ===== 3. 将模型移动到目标设备 =====
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# ===== 4. 编码输入文本 =====
# 此处使用简化的手动编码示例
# 实际使用时应配合 Qwen3 的 tokenizer
prompt = "The capital of France is"
# token_ids = tokenizer.encode(prompt) # 实际项目中使用 tokenizer
# input_ids = torch.tensor([token_ids], device=device)
# ===== 5. 生成文本 =====
# generated = generate(model, input_ids, max_new_tokens=50)
# output_text = tokenizer.decode(generated)
# print(output_text)D.10 小结
本附录提供了 Qwen3 稠密模型从底层组件到完整推理流程的自包含实现。回顾整个代码的关键设计决策:
RMSNorm 的 float32 计算:在 bfloat16 训练/推理环境下,先转为 float32 再计算方差是保证数值稳定性的必要步骤。
RoPE 的 offset 机制:通过
offset参数实现 KV Cache 场景下的位置编码连续性——预填充时offset=0,增量解码时offset递增。GQA 的分组共享:16 个 Q 头共享 8 组 KV 头,推理时 KV Cache 内存减半,而性能几乎无损。
QKNorm 防溢出:在 Q/K 送入 RoPE 之前做 RMSNorm 归一化,防止深层网络中注意力分数溢出 bfloat16 的有效范围。
SwiGLU 门控:双分支设计让网络学会自适应地过滤信息流,在相同参数量下优于标准 FFN。
KV Cache 的两阶段推理:预填充阶段一次性处理完整提示并建立缓存,解码阶段每步只处理 1 个 token,将推理开销从
降低到 。
读者可以将本附录的代码复制到单个 Python 文件中,配合 Qwen3 的预训练权重和 tokenizer 即可运行完整的文本生成流程。关于 Qwen3 的架构设计理念、MoE 变体和 Reasoning 模式的详细讨论,请参阅 §7.2。