11.2 服务器与散热
上一节我们概览了 AI 集群的整体架构层次。本节将目光聚焦到集群中最基本的物理单元——服务器节点,以及让这些节点持续稳定运行的关键支撑系统:散热与供电。一台 AI 服务器满载运行时功耗可达 10 kW 以上,数千台服务器组成的集群每年电费和散热开销以亿元计。理解硬件形态、散热技术路线和供电架构,是设计高效 AI 集群的必要基础。
11.2.1 服务器节点基础
通用服务器与 AI 服务器的本质区别。 通用服务器采用同构架构,以 CPU 为唯一计算核心,典型形态是 1U 2 路机架式——"1U"指高度 4.445 cm,"2 路"指搭载 2 颗 CPU。其设计追求计算、存储与网络的均衡能力,功耗通常在 300--500 W,风冷散热即可胜任。
AI 服务器则采用异构架构,在 CPU 之外搭载 4--8 张高性能 GPU 或 NPU 作为主力算力单元。以典型的 8 卡 GPU 服务器为例,其核心差异可以归纳为:
| 对比维度 | 通用服务器 | AI 服务器 |
|---|---|---|
| 核心架构 | 同构(仅 CPU) | 异构(CPU + GPU/NPU) |
| 加速卡配置 | 无或 1 张入门级显卡 | 4--8 张高性能 GPU/NPU |
| 典型功耗 | 300--500 W | 2000--15000 W |
| 散热方式 | 风冷 | 风冷 / 液冷 / 风液混合 |
| 典型应用 | Web 服务、数据库 | 大模型训练 / 推理 |
表 11-1:通用服务器与 AI 服务器核心差异对比。
AI 服务器的物理结构。 以搭载 8 张 NVIDIA HGX H100 的 4U 机架式服务器为例,其内部主要由以下部件构成:
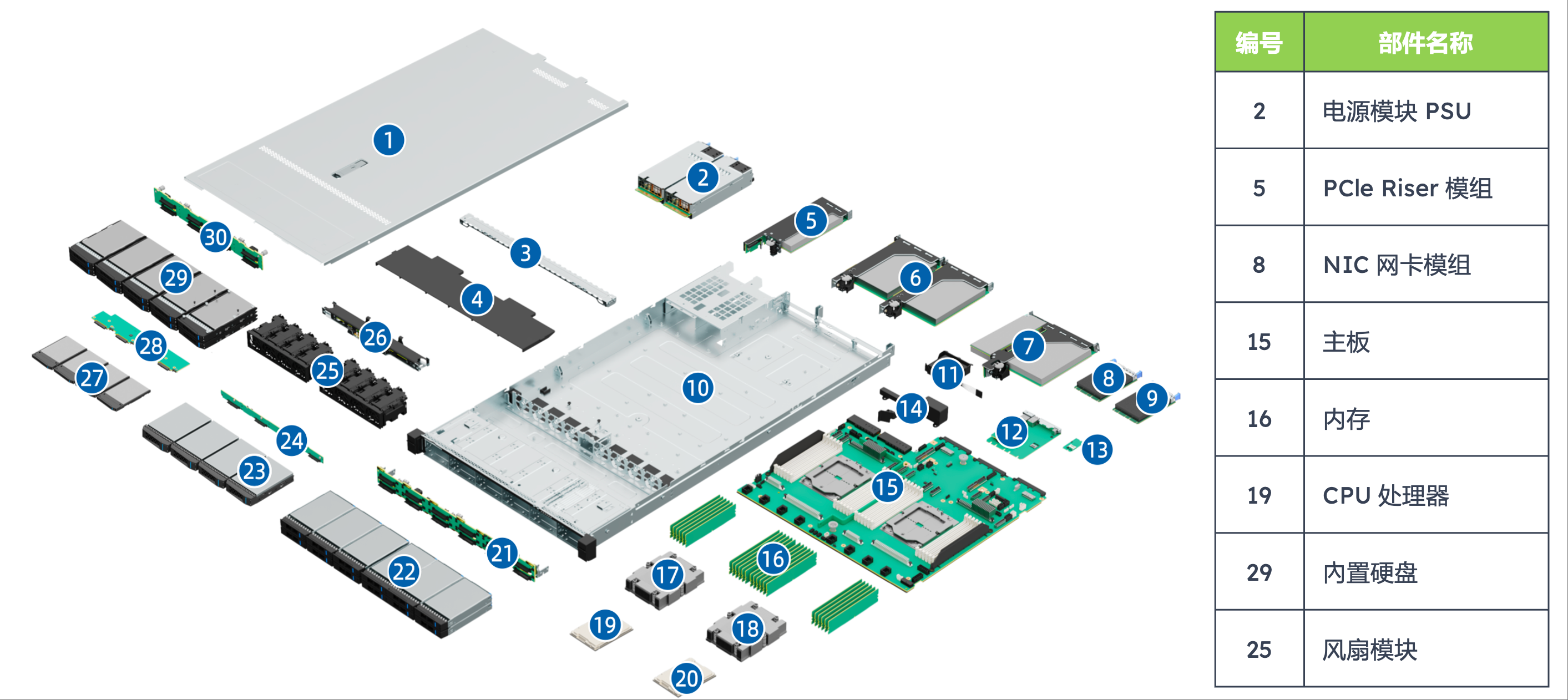
- CPU:2 颗 AMD EPYC 9004/9005 系列处理器,负责任务调度、数据预处理与 GPU 协同管理
- GPU:8 张 HGX H100(Hopper 架构),通过 NVLink 与 NVSwitch 实现 GPU 间高速通信,总互联带宽 900 GB/s
- PCIe Switch 板:采用 PCIe 5.0 交换芯片,作为 CPU 与 GPU 之间的数据桥梁
- 内存:12 通道 DDR5 RDIMM,支持 ECC 校验,最大容量 1.5 TB
- 存储:8 块 2.5 英寸 Gen5 NVMe 热插拔硬盘,单盘速率 7.4 GB/s
- 电源模块(PSU):5+1 冗余 3000 W 电源(80 PLUS Titanium 认证),总功率 15000 W
- DPU:数据处理单元,卸载 CPU 的网络任务,支持 RDMA,降低分布式训练延迟
- 风扇模组:分为系统风扇(负责 CPU、内存散热)和 GPU 专属风扇(下吹式风道),支持温度联动调速
为什么服务器是长条形? 这个看似简单的外观设计背后有四重工程考量:(1)长条形态可以设计线性风道,冷空气从前端均匀流过所有发热部件后从后端排出,避免局部热量堆积;(2)提供足够空间容纳多块硬盘和扩展插槽,满足扩展性需求;(3)兼容不同厂商的标准化配件;(4)前后分区维护——前端插拔硬盘,后端更换电源与风扇——无需拆卸整个节点。
GPU 服务器的功耗演进。 从 NVIDIA 近几代 HGX 平台可以清晰看到 AI 服务器的功耗增长趋势。下表对比了主流 8 卡 GPU 服务器的关键指标:
| 指标 | HGX A100 | HGX H100 | HGX H200 | HGX B100 | HGX B200 |
|---|---|---|---|---|---|
| 架构 | Ampere | Hopper | Hopper | Blackwell | Blackwell |
| 显存 | 640 GB | 1.1 TB | 1.1 TB | 1.44 TB | 1.44 TB |
| FP16 算力 | 2.4 PFlops | 8 PFlops | 8 PFlops | 14 PFlops | 18 PFlops |
| FP8 算力 | -- | 16 PFlops | 16 PFlops | 28 PFlops | 36 PFlops |
| GPU 互联带宽 | 600 GB/s | 900 GB/s | 900 GB/s | 1.8 TB/s | 1.8 TB/s |
| GPU 功耗 | 3.2 kW | 5.6 kW | 5.6 kW | 5.6 kW | 8 kW |
| 整机功耗 | 6.5 kW | 10.2 kW | 10.2 kW | 10.2 kW | 14.3 kW |
表 11-1b:NVIDIA 历代 HGX 8 卡服务器关键指标对比。
可以看到,从 A100 到 B200,FP8 算力提升了超过 2 倍,但单机功耗也从 6.5 kW 翻倍至 14.3 kW。算力密度虽然在提升(每瓦算力在改善),但绝对功耗的增长速度对散热系统构成了持续压力。
从单节点到超节点。 随着模型规模增长,业界出现了将多台服务器整合进单个机柜形成超节点(Super PoD) 的趋势。例如 NVIDIA GH200 NVL32 方案将 32 颗 GPU 集成在单个机柜中,功耗约 40 kW;而 GB200 NVL72 更进一步将 72 颗 GPU 集成在单个机柜中,通过 NVLink 实现机柜内全互联,总功耗飙升至约 130 kW。这种高度集成化的形态对散热和供电提出了极为严苛的要求——传统风冷方案在这样的功率密度下已完全无法胜任。
11.2.2 散热技术:从风冷到液冷
散热是 AI 集群基础设施中最关键也最烧钱的环节之一。数据中心的用能可以分为四大类:IT 设备(CPU、GPU、交换机等)、制冷系统、供配电系统、照明及其他。在一个 PUE = 1.5 的传统数据中心中,IT 设备耗能约占 67%,制冷系统约占 27%,供配电约占 5%,照明及其他约占 1%。换言之,每消耗 2 元钱的电费,就有接近 1 元花在了"给服务器降温"上。
PUE(Power Usage Effectiveness,电能使用效率) 是衡量数据中心能源效率的核心指标:
PUE 越接近 1.0,说明用于制冷和供电等非 IT 设备的开销越少。传统风冷数据中心的 PUE 通常在 1.5--2.0,而采用液冷技术可以将 PUE 降至 1.1 以下。
下面用一段简单的 Python 代码来直观感受不同散热方案对数据中心总能耗的影响:
def estimate_dc_power(num_gpus: int, power_per_gpu_w: float, pue: float):
"""估算数据中心总电力需求和年度电费"""
it_power_mw = num_gpus * power_per_gpu_w / 1e6
total_power_mw = it_power_mw * pue
cooling_power_mw = total_power_mw - it_power_mw
# 按 0.8 元/度电、全年 8760 小时满载估算
annual_cost_billion = total_power_mw * 1000 * 8760 * 0.8 / 1e8
print(f"GPU 数量: {num_gpus // 10000} 万卡")
print(f"IT 功耗: {it_power_mw:.1f} MW")
print(f"PUE = {pue} -> 总功耗: {total_power_mw:.1f} MW "
f"(制冷+供电: {cooling_power_mw:.1f} MW)")
print(f"年度电费: {annual_cost_billion:.2f} 亿元\n")
# 10 万卡集群在不同散热方案下的能耗对比
for pue, method in [(1.5, "传统风冷"), (1.2, "冷板式液冷"), (1.08, "全液冷")]:
estimate_dc_power(100_000, 350, pue)运行结果大致如下:
GPU 数量: 10 万卡
IT 功耗: 35.0 MW
PUE = 1.5 -> 总功耗: 52.5 MW (制冷+供电: 17.5 MW)
年度电费: 3.68 亿元
GPU 数量: 10 万卡
IT 功耗: 35.0 MW
PUE = 1.2 -> 总功耗: 42.0 MW (制冷+供电: 7.0 MW)
年度电费: 2.94 亿元
GPU 数量: 10 万卡
IT 功耗: 35.0 MW
PUE = 1.08 -> 总功耗: 37.8 MW (制冷+供电: 2.8 MW)
年度电费: 2.65 亿元从传统风冷(PUE=1.5)切换到全液冷(PUE=1.08),一个 10 万卡集群每年可节省约 1 亿元电费,制冷功耗从 17.5 MW 降至 2.8 MW,降幅超过 80%。这就是为什么大规模 AI 集群纷纷转向液冷的核心经济驱动力。
风冷:成熟但逼近极限
风冷(Air Cooling) 是目前数据中心最主流的散热方式,其工作原理直观:通过风扇或空调将冷空气吹入服务器内部,带走热量后排出热空气。在服务器节点层面,冷空气从前面板进入,流经 CPU、内存、GPU 等发热部件后从后端排出;在机房层面,CRAH(Computer Room Air Handler,计算机房空调)将冷水管中的冷量传递给空气,再通过地板送风或行间空调送入服务器机柜。
风冷的端到端换热链路包含三级换热:
- 一级(风液换热):机柜内的空调将 12°C 冷水的冷量传递给空气,空气升温至约 17°C 后送入服务器
- 二级(液液换热):冷水机组将低温冷冻水(12°C)输出给机房空调,自身回收 17°C 温水
- 三级(液液换热):冷却塔利用室外环境将冷水机组排出的 37°C 热水冷却至 32°C,完成最终散热
风冷的优势在于技术成熟、兼容性好、维护成本低,完全兼容现有服务器架构,无需特殊防护。但它有三个根本性弱点:
- 导热系数低:空气的热导率约 0.026 W/(m·K),仅为水的 1/23
- 比热容小:空气的比热容约 1.0 kJ/(kg·K),仅为水的 1/4,意味着带走同等热量需要更大的风量
- 噪音与能耗:高功率 GPU 服务器的风扇转速极高,噪音可达 70 dB 以上,风扇本身的功耗也不可忽视
当单芯片 TDP(Thermal Design Power,热设计功耗)超过 300 W、单机柜功率密度超过 20 kW 时,风冷就开始力不从心。这一极限正在被 AI 加速卡快速逼近:NVIDIA H100 单卡功耗约 700 W,8 卡 GPU 功耗合计约 5.6 kW,整机功耗超过 10 kW;到了 Blackwell 架构(B200),单卡功耗预计达到 1 kW,整机功耗将进一步攀升至 14.3 kW。与此同时,先进封装技术(2.5D/3D 封装,如台积电 CoWoS)在提升芯片集成度的同时也推高了热流密度——单位面积上的发热量——使得散热问题不仅是"总功耗高",更是"热量集中在极小面积上"。
单机柜功耗也从传统数据中心的 4--6 kW 飙升至 AI 智算中心的 20--50 kW,未来预计达到 70--200 kW。在如此高的功率密度下,风冷已经无法保证芯片结温(Junction Temperature,
什么是结温? 结温是半导体器件内部最热点的温度,特别是晶体管 PN 结处的温度。控制结温是芯片散热管理的核心任务——结温过高会导致芯片降频甚至物理损伤。
液冷:高效但复杂
液冷(Liquid Cooling) 利用液体代替空气作为换热介质。由于水的比热容是空气的 4 倍、热导率是空气的 23 倍,液冷的散热效率远高于风冷。液冷的端到端链路只需两级换热:
- 一级(风液/液液换热):液冷机柜内,工质水通过冷板直接接触 GPU/CPU 表面带走热量,出水温度约 40°C
- 二级(液液换热):CDU(Cooling Distribution Unit,冷量分配单元)将一次侧的热工质水与二次侧的冷却塔循环水进行热交换,将热量排出机房
液冷的通用架构包含三个核心环节:
- 热捕获:发生在服务器内部,冷板(Cold Plate)紧贴 GPU/CPU 表面,冷却液体在冷板内部的微通道中流动,高效吸收芯片热量
- 热交换:CDU 作为一次侧(服务器)和二次侧(设施水系统)之间的桥梁,完成冷量分配与热量转移
- 冷源:位于数据中心外部,通过冷却塔或冷水机组将热量最终排放到大气中
根据液冷方案覆盖范围的不同,业界将其分为三种形态:
冷板式液冷(Cold Plate / Direct Liquid Cooling, DLC)。 这是目前 AI 集群中最常见的液冷方案。冷板仅覆盖 CPU 和 GPU 等高功耗部件,其余部件(内存、硬盘、光模块等)仍然依赖风冷辅助散热。冷板内部采用高密度铲齿(Pin-Fin)流道设计,铜合金材质配合硅脂或液态金属界面材料降低接触热阻。冷板式液冷的优势在于基本兼容现有风冷服务器架构,只需在服务器内部增加冷板和管路,对硬盘、光模块等部件无需改造。
浸没式液冷(Immersion Cooling)。 将整个服务器主板浸入非导电冷却液中,所有发热部件均直接与液体接触。根据冷却液是否发生相变,又分为单相浸没(冷却液始终保持液态)和两相浸没(冷却液在芯片表面沸腾汽化,蒸汽在冷凝器上液化后回流)。浸没式液冷的散热效率最高,可以完全取消风扇,PUE 可低于 1.1,但需要定制化服务器架构,初期建设成本最高。
风液混合方案。 在实际部署中,许多 AI 集群采用折中方案:GPU 和 CPU 使用冷板式液冷,其余低功耗部件仍用风冷。机柜内部配备风液换热器——一个安装在机柜顶部的换热芯体,将风冷侧排出的热空气与液冷管路中的冷水进行热交换,使机柜成为一个封闭散热单元,无需向机房排放热空气。
下表对比了三种散热方案的核心特征:
| 特征 | 风冷 | 冷板式液冷 | 全液冷/浸没式 |
|---|---|---|---|
| 工作原理 | 风扇/空调吹冷空气 | 冷板覆盖高功耗部件,风冷辅助 | 液体直接接触所有部件 |
| PUE | 1.5--2.0 | < 1.2(风液混合)/ < 1.1(纯液冷) | < 1.1 |
| 能耗 | 高(空调 + 风扇) | 显著降低(空调能耗降低 70%) | 最低(取消风扇) |
| 初期建设成本 | 低 | 较高(需安装液冷管路) | 最高(需全系统改造) |
| 维护成本 | 低 | 中等(需处理漏液风险) | 高(专业液体循环维护) |
| 兼容性 | 完全兼容现有架构 | 基本兼容(硬盘/光模块无需改动) | 需定制化服务器 |
| 噪音 | 高 | 中等 | 极低 |
| 适用场景 | 低密度传统数据中心 | 中高密度 AI 智算中心 | 超大规模/超算中心 |
表 11-2:风冷、冷板式液冷与全液冷散热方案对比。
液冷的工程挑战。 液冷虽然在散热效率上远超风冷,但它带来了一系列工程复杂性:
- 材料兼容性:工质水需要特殊物化配方,不同厂家的配方可能与冷板材料不兼容,导致腐蚀或堵塞
- 流道精度:冷板内部的铲齿流道间隙仅约 100 微米(约一根头发丝粗细),对杂质耐受度极低
- 设施耦合:液冷服务器本身无动力驱动液体流动,完全依赖机房的 CDU 设备,服务器与基础设施之间形成强耦合
- 泄漏风险:数据中心内长期储存数吨非饮用水,管路连接处存在泄漏风险,需要配备光电式漏液传感器和应急排水系统
- 建设成本:仅一个水泵的成本就可能超过整机风扇总成本的数倍,加上管道、接头、CDU 等组件,整体造价显著上升
11.2.3 机柜与机房架构
服务器节点需要安装在标准化的机柜(Rack) 中,多个机柜排列组成机房。根据散热方式的不同,机柜分为三种形态。
风冷机柜。 外部结构由机柜主体、管理模块、电源框、电池框、计算节点、交换节点和假面板组成。内部通过 Cable 背板提供节点间网络传输,Busbar 提供电力传输。风冷机柜的设计简单直接——前面板进冷风,后面板出热风,机柜之间通过冷热通道隔离(Hot Aisle / Cold Aisle Containment)来提高空调效率。
板冷机柜(Board Cooling Cabinet)。 在风冷机柜的基础上增加了 Manifold 集流管等液冷组件。Manifold 是液冷管路系统的核心分配器,包含供水管、回水管、排气阀、球阀、导流管等部件。冷却液通过 Manifold 分配到各台服务器节点的冷板上,再通过回水管收集升温后的液体返回 CDU。板冷机柜兼顾了冷板式液冷的高效散热和风冷的兼容性。
全液冷机柜。 比板冷机柜多一个风液换热器,安装在机柜顶部。风液换热器组件包括冷热水管、排气阀、冷热水管针阀、换热芯体、排水管和浮子式漏液传感器等。全液冷机柜内的服务器节点和交换节点均采用液冷散热,风液换热器负责处理机柜内残余的热空气,使机柜形成封闭散热循环,无需向机房排放热风。全液冷机柜适用于 NVIDIA GB200 NVL72 等超高密度方案。
全液冷方案中传统服务器与 AI 服务器的机柜结构也存在差异:传统服务器机柜通常采用 X86 架构处理器计算节点,交换节点使用风冷散热并通过线缆转接托盘连接;而 AI 服务器机柜采用 ARM 架构处理器,交换节点支持主芯片、CDR 和光模块的液冷散热,通过 Cable 背板进行数据交换,无需额外连接线缆。
数据中心选址:散热的宏观策略。 除了服务器和机柜层面的散热技术,数据中心的地理位置本身就是一种散热策略。低温环境可以显著降低制冷能耗:苹果将数据中心建在贵州的山区,中国移动选择内蒙古作为算力基地,Google 在芬兰建设了利用北欧冷空气散热的数据中心,微软甚至尝试过将服务器放入海底(Project Natick)利用海水散热。这些看似极端的选址策略背后,都是对散热成本的精打细算——在自然环境温度足够低的地区,数据中心可以大幅减少甚至完全关闭机械制冷,将 PUE 逼近理论极限。
11.2.4 电源系统
电力是 AI 集群运行的第一前提。截至 2023 年底,全球约有 8000 多个数据中心,其中美国占 30%,中国以 449 个位居亚太之首。2023 年全球数据中心电力消耗量约 460 TWh(太瓦时),比 2022 年增长约 15%–19%(来源:IEA, Electricity 2024 报告)。国际能源署数据显示,2024 年中国数据中心用电量已占全球数据中心用电总量的 25%(约 1000 亿度电)。在 AI 大模型训练的推动下,数据中心的电力需求正以前所未有的速度增长。
以一个 10 万卡规模的大型 AI 集群为例,按单卡平均功耗 350 W 计算:
再考虑 PUE = 1.3 的制冷和供配电开销:
这 45.5 MW 相当于一座小型城市的用电量。需要注意的是,这里的"IT 功耗"是纯设备功耗(IT Load),不包括光模块、交换机、冷却系统、UPS、变压器等配套设施。
供配电链路。 从发电厂到服务器节点,电力经历多级变压与转换:
- 发电侧:发电厂输出电压 > 1000 kV,经特高压电站远距离输送
- 高压变电站:降压至 35 kV / 60 kV / 110 kV / 220 kV
- 中压变压器:进一步降压至 3 kV / 6 kV / 10 kV,接入数据中心
- 低压配电:最终降压至 220 V / 380 V,通过 PDU(Power Distribution Unit,电源分配单元)送入各个机柜
AI 集群通常采用三相五线制(TN-S)配电方式:三根火线(L1、L2、L3)+ 一根中性线(N)+ 一根保护地线(PE),这是目前最安全、最规范的接地系统。额定电压为 380 V 三相交流电。
主流供电架构。 数据中心有三种主要的供电架构:
UPS 供电架构(Uninterruptible Power Supply)。 市电经变压器降压后,进入 UPS 系统进行整流(AC→DC)、升压、逆变(DC→AC)、滤波等多步骤处理,最终输出稳定的交流电。UPS 内置电池组,当市电中断时可立即切换到电池供电模式,保障训练任务不因短暂停电而中断。UPS 是传统数据中心的主流选择,但多级转换带来额外的能量损耗。
HVDC 供电架构(High Voltage Direct Current)。 高压直流供电将交流电一次转换为 240 V 直流电,直接送入服务器。相比 UPS 架构减少了 DC→AC 逆变环节,链路更短,转换效率更高,损耗更低。HVDC 适用于追求高效节能的中大型数据中心。
巴拿马电源架构。 市电通过移相变压器直接转换为较低电压的交流电,再经 AC/DC 转换输出直流电。这种架构整合了 HVDC 中的前置变压器和输入滤波环节,以更紧凑的形态适应高功耗 AI 集群的用电需求。巴拿马电源是 AI 集群和 GPU 集群等高密度场景下追求极致效率与简化配电层的新兴选择。
电力接入的现实挑战。 中压输入方案(四路 10 kV 供电)最大仅能支持约 20 MW 容量,足以覆盖万卡级别的 AI 集群。但当集群规模达到 10 万卡以上,总电力需求超过 45 MW,就需要自建 110 kV 变电站或接入更高电压等级的电源。下表展示了不同规模 AI 集群的电力需求:
| 集群规模 | GPU/NPU 卡数 | IT 功耗(350W/卡) | 总电力需求(PUE=1.3) |
|---|---|---|---|
| 典型 AI 集群 | 1 万卡 | 3.5 MW | 4.55 MW |
| 中型 AI 集群 | 5 万卡 | 17.5 MW | 22.75 MW |
| 大型 AI 集群 | 10 万卡 | 35 MW | 45.5 MW |
| 超大 AI 集群 | 50 万卡 | 175 MW | 227.5 MW |
表 11-3:不同规模 AI 集群的电力需求估算。
随着单机柜功率密度从传统的 2.5--5 kW 提升至 AI 时代的 20--100 kW,供配电系统所占的机房面积也在急剧增长。下表直观展示了这一关系:
| 单机柜功耗 | 供配电系统占地面积 |
|---|---|
| 2.5--5 kW | 约为 AI 算力设备占地面积的 1/4 |
| 8 kW | 约为 AI 算力设备占地面积的 1/2 |
| 16 kW | 与 AI 算力设备占地面积相当 |
表 11-4:单机柜功耗与供配电系统占地面积的关系。
这意味着在高功率密度的 AI 集群中,机房里有将近一半的面积不是放服务器的,而是放变压器、UPS、电池、配电柜的。AI 集群的选址不仅要考虑网络连通性和运维便利性,更要优先确保充足的电力供应——电力已经从"基础保障"变成了集群规模的硬性上限。
本节要点
- AI 服务器采用 CPU + GPU/NPU 的异构架构,单机功耗可达 10--15 kW,远超通用服务器
- 散热技术沿着"风冷 → 冷板式液冷 → 全液冷/浸没式"路线演进,核心驱动力是单芯片 TDP 突破 300 W 和单机柜功率密度突破 20 kW 的物理极限
- 液冷通过更高比热容和热导率的液体介质将 PUE 从 1.5+ 降至 1.1 以下,但带来了材料兼容性、流道精度、设施耦合和泄漏风险等工程挑战
- 供电架构从传统 UPS 向 HVDC 和巴拿马电源演进,追求更少的转换环节和更高的能效
- 10 万卡级 AI 集群总电力需求约 45 MW,电力供应已成为集群选址和规模扩展的首要约束