15.1 强化学习基础
大语言模型的对齐训练——无论是 RLHF、DPO 还是 GRPO——都建立在强化学习(Reinforcement Learning, RL)的理论框架之上。本节从经典 RL 的基本概念出发,依次介绍马尔可夫决策过程(MDP)、值函数与贝尔曼方程、策略梯度定理,以及 Q-Learning、REINFORCE、Actor-Critic 等经典算法,最终过渡到 LLM 场景下 RL 概念的重新诠释,为后续章节的 PPO、GRPO、DPO 等算法打下基础。
15.1.1 强化学习的基本范式
强化学习的核心范式可以概括为一句话:智能体(Agent)通过与环境(Environment)的交互,根据获得的奖励信号学习策略,以最大化累积奖励。
与监督学习需要大量"输入-标签"配对不同,RL 只需要一个稀疏的奖励信号(Reward Signal),智能体通过试错(Trial and Error)来发现哪些行为是好的。这种学习范式天然适用于难以提供逐样本标签的场景——游戏对弈、机器人控制,以及 LLM 对齐。
RL 中的核心概念可以归纳为下表:
| 概念 | 符号 | 含义 |
|---|---|---|
| 智能体(Agent) | — | 做决策的主体,输出动作 |
| 环境(Environment) | — | 接收动作、返回状态与奖励的外部系统 |
| 状态(State) | 环境的当前描述,Agent 据此决策 | |
| 动作(Action) | Agent 在某状态下可选择的行为 | |
| 奖励(Reward) | 环境对动作的即时反馈标量 | |
| 策略(Policy) | 从状态到动作的概率分布 | |
| 回报(Return) | 从 |
表 15-1:强化学习核心概念。
智能体与环境的交互形成一个循环:智能体在状态
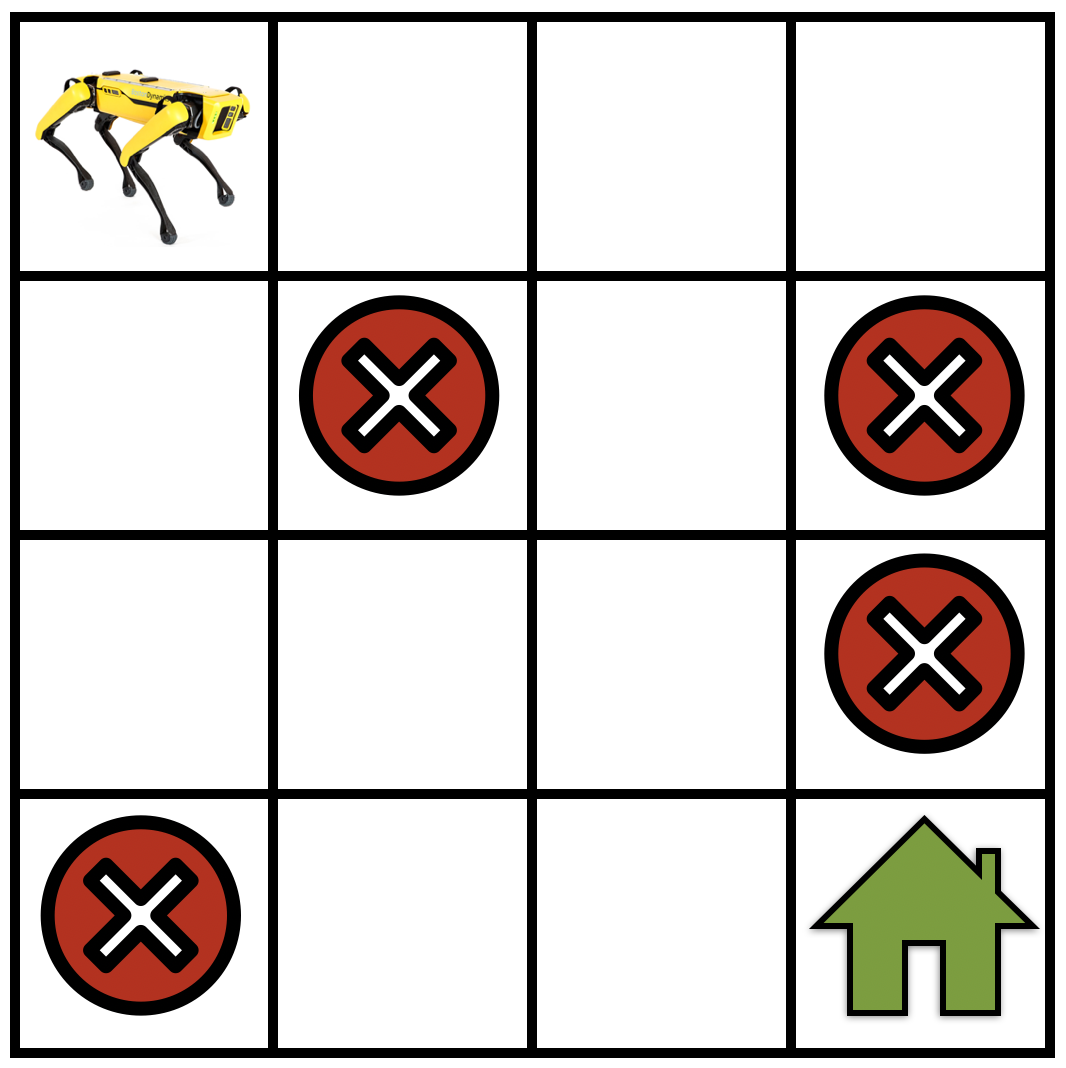
图 15-1:一个 4×4 GridWorld 导航任务。机器人(左上角)需要找到通往目标位置(绿色房子)的路径,同时避开陷阱(红色叉号)。这是 MDP 的一个典型实例。
15.1.2 马尔可夫决策过程(MDP)
要让 RL 问题在数学上可处理,需要引入一个关键假设——马尔可夫性(Markov Property):
即下一状态仅依赖当前状态和动作,与更早的历史无关。直观地说,当前状态已经携带了做最优决策所需的全部信息。下棋时只需看当前棋盘布局即可决策,不必记忆每一步如何走到这里。
在马尔可夫性的基础上,我们可以将 RL 问题形式化为马尔可夫决策过程(Markov Decision Process, MDP),由五元组
| 符号 | 含义 |
|---|---|
| 状态空间 | |
| 动作空间 | |
| 状态转移概率 | |
| 奖励函数 | |
| 折扣因子,权衡即时与未来奖励 |
表 15-2:MDP 五元组。
回报(Return) 定义为从
折扣因子
15.1.3 值函数与贝尔曼方程
值函数是 RL 中最核心的概念之一,它回答了一个问题:"从某个状态(或状态-动作对)出发,按照某个策略行动,未来能获得多少累积奖励?"
状态值函数(State Value Function)
动作值函数(Action Value Function / Q 函数)
两者的关系是:
优势函数(Advantage Function) 度量某个动作相对于"平均水平"的好坏:
贝尔曼方程(Bellman Equation) 是值函数的递归表达,也是几乎所有 RL 算法的理论基石。将回报拆分为"即时奖励 + 折扣后的未来回报":
对
该方程的深刻含义是:一个状态的价值等于"从该状态出发一步可获得的奖励"加上"下一状态价值的折扣期望"。这种递归结构使得我们可以通过迭代求解值函数,而不需要枚举所有可能的轨迹。
类似地,Q 函数的贝尔曼方程为:
最优值函数对应最优策略
这就是贝尔曼最优性方程——
下面用一个简单的 GridWorld 示例来演示值迭代的过程:
import numpy as np
def value_iteration(grid_size=4, gamma=0.99, theta=1e-6):
"""在一个简单 GridWorld 上演示值迭代算法。
目标位置在右下角 (grid_size-1, grid_size-1),到达后获得奖励 +1。
其余位置每步奖励为 -0.04(鼓励尽快到达目标)。
"""
n_states = grid_size * grid_size
# 动作:上(0)、下(1)、左(2)、右(3)
actions = [(-1, 0), (1, 0), (0, -1), (0, 1)]
goal = (grid_size - 1, grid_size - 1)
V = np.zeros((grid_size, grid_size))
for iteration in range(1000):
delta = 0
for r in range(grid_size):
for c in range(grid_size):
if (r, c) == goal:
continue # 目标状态值固定为 0(已结束)
old_v = V[r, c]
# 对所有动作取 max(贝尔曼最优性方程)
action_values = []
for dr, dc in actions:
nr, nc = max(0, min(r + dr, grid_size - 1)), \
max(0, min(c + dc, grid_size - 1))
reward = 1.0 if (nr, nc) == goal else -0.04
action_values.append(reward + gamma * V[nr, nc])
V[r, c] = max(action_values)
delta = max(delta, abs(old_v - V[r, c]))
if delta < theta:
print(f"值迭代在第 {iteration + 1} 轮收敛")
break
# 提取最优策略
policy = np.full((grid_size, grid_size), ' ')
symbols = ['↑', '↓', '←', '→']
for r in range(grid_size):
for c in range(grid_size):
if (r, c) == goal:
policy[r, c] = '★'
continue
best_a = -1
best_v = float('-inf')
for i, (dr, dc) in enumerate(actions):
nr = max(0, min(r + dr, grid_size - 1))
nc = max(0, min(c + dc, grid_size - 1))
reward = 1.0 if (nr, nc) == goal else -0.04
v = reward + gamma * V[nr, nc]
if v > best_v:
best_v = v
best_a = i
policy[r, c] = symbols[best_a]
print("\n最优值函数:")
print(np.round(V, 2))
print("\n最优策略:")
for row in policy:
print(' '.join(row))
value_iteration()运行结果会显示值函数从目标位置向外衰减的梯度,以及指向目标的最优策略箭头——这正是贝尔曼方程递归结构的直观体现。
15.1.4 从 Q-Learning 到 REINFORCE
经典 RL 算法大致分为两条技术路线:基于值函数(Value-based)和基于策略梯度(Policy Gradient)。
Q-Learning:基于值函数的代表。 Q-Learning 是一种无模型(Model-free)、离策略(Off-policy)的算法,直接学习最优动作值函数
其中
Q-Learning 的策略隐含在 Q 函数中:
import numpy as np
def q_learning_demo(episodes=500, alpha=0.1, gamma=0.99, epsilon=0.1):
"""在 4x4 GridWorld 上演示 Q-Learning。"""
grid_size = 4
n_states = grid_size * grid_size
n_actions = 4 # 上、下、左、右
actions = [(-1, 0), (1, 0), (0, -1), (0, 1)]
goal = (grid_size - 1, grid_size - 1)
Q = np.zeros((n_states, n_actions))
def state_to_idx(r, c):
return r * grid_size + c
def step(r, c, action_idx):
dr, dc = actions[action_idx]
nr = max(0, min(r + dr, grid_size - 1))
nc = max(0, min(c + dc, grid_size - 1))
reward = 1.0 if (nr, nc) == goal else -0.04
done = (nr, nc) == goal
return nr, nc, reward, done
for ep in range(episodes):
r, c = 0, 0 # 从左上角出发
for _ in range(100): # 每轮最多 100 步
s = state_to_idx(r, c)
# epsilon-greedy 选择动作
if np.random.random() < epsilon:
a = np.random.randint(n_actions)
else:
a = np.argmax(Q[s])
nr, nc, reward, done = step(r, c, a)
ns = state_to_idx(nr, nc)
# Q-Learning 更新(核心)
td_target = reward + gamma * np.max(Q[ns]) * (1 - done)
Q[s, a] += alpha * (td_target - Q[s, a])
r, c = nr, nc
if done:
break
# 输出学到的最优策略
symbols = ['↑', '↓', '←', '→']
print("Q-Learning 学到的策略:")
for r in range(grid_size):
row = []
for c in range(grid_size):
if (r, c) == goal:
row.append('★')
else:
row.append(symbols[np.argmax(Q[state_to_idx(r, c)])])
print(' '.join(row))
q_learning_demo()Q-Learning 的局限在于:它只能处理离散且低维的状态-动作空间。语言模型的动作空间是整个词汇表(数万到数十万),状态是变长的 token 序列——表格式 Q-Learning 完全不可行。虽然 DQN(Deep Q-Network)用神经网络替代 Q 表解决了部分问题,但对于 LLM 这种超大规模的策略空间,基于策略梯度的方法更为自然。
REINFORCE:策略梯度的起点。 REINFORCE 直接参数化策略
其中
策略梯度定理的推导基于一个关键恒等式
REINFORCE 的问题是方差极大:用完整轨迹的回报
- 引入基线(Baseline):从回报中减去一个与动作无关的基线
,常取 。数学上, ,所以减基线不改变梯度期望,但显著降低方差。 - 只关注未来(Reward-to-go):
时刻的梯度只用 之后的奖励,过去的奖励对当前决策没有因果影响。
当基线选为
15.1.5 Actor-Critic 与 GAE
Actor-Critic 架构是 REINFORCE 的自然进化:用一个Actor 网络(策略
: ,等价于单步 TD 误差,方差最低但偏差最高。 : ,等价于蒙特卡洛估计,偏差最低但方差最高。 - 实际中常用
,兼顾偏差和方差。
GAE 的递归形式使其计算非常高效——从轨迹末尾向前递推:
import torch
def compute_gae(rewards, values, gamma=0.99, lam=0.95):
"""计算广义优势估计(GAE)。
Args:
rewards: 每步即时奖励, shape [T]
values: Critic 估计的状态值, shape [T+1](含终止状态)
gamma: 折扣因子
lam: GAE 平滑因子
Returns:
advantages: 每步优势估计, shape [T]
"""
T = len(rewards)
advantages = torch.zeros(T)
last_gae = 0.0
for t in reversed(range(T)):
delta = rewards[t] + gamma * values[t + 1] - values[t]
last_gae = delta + gamma * lam * last_gae
advantages[t] = last_gae
return advantages
# 示例
rewards = torch.tensor([0.0, 0.0, 0.0, 1.0]) # 最后一步获得奖励
values = torch.tensor([0.5, 0.6, 0.7, 0.9, 0.0]) # 含终止状态值=0
adv = compute_gae(rewards, values)
print(f"GAE 优势估计: {adv}")
# 结果中靠近终点的步骤优势较高,体现了 GAE 的信用分配能力Actor-Critic + GAE 的组合正是 PPO 算法的基础——PPO 在此之上引入裁剪机制来保证策略更新的稳定性。
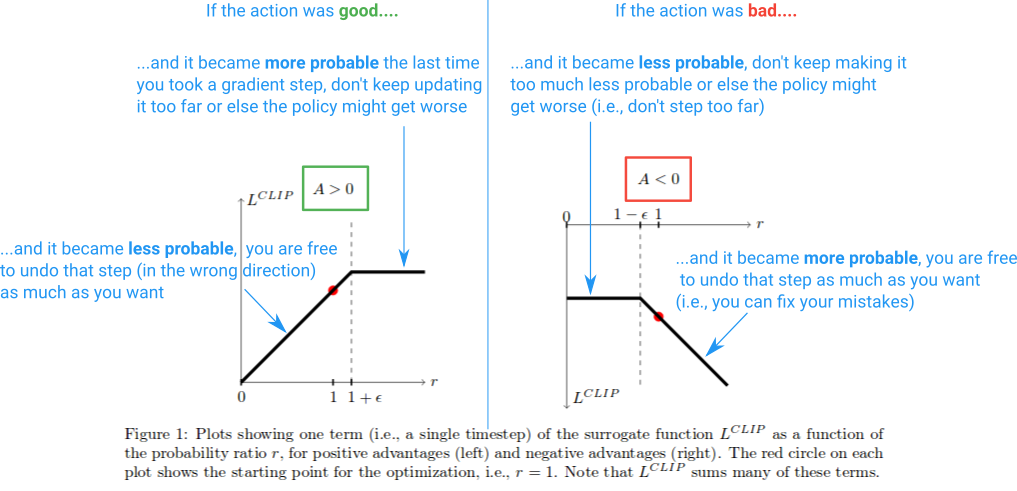
图 15-2:PPO-Clip 目标函数的直观解释。左图:当优势
15.1.6 从古典 RL 到 LLM RL 的概念映射
将 RL 应用于大语言模型时,经典概念需要重新诠释:
| 经典 RL | LLM RL | 说明 |
|---|---|---|
| 环境 | 用户 prompt + 评价系统 | 环境"给出" prompt 并评价 response |
| 状态 | 已生成的 token 序列 | prompt + 已生成的部分 response |
| 动作 | 生成下一个 token | 动作空间 = 词汇表大小 |
| 策略 | 语言模型本身 | |
| 奖励 | Reward Model 打分 / 规则验证 | 通常只在序列末尾给出(稀疏奖励) |
| 轨迹 | 完整的 response 序列 | |
| 回报 | 整句奖励 | 多数情况下 |
表 15-3:经典 RL 与 LLM RL 的概念映射。
LLM 场景下的 RLHF 流程涉及四个模型的协作:
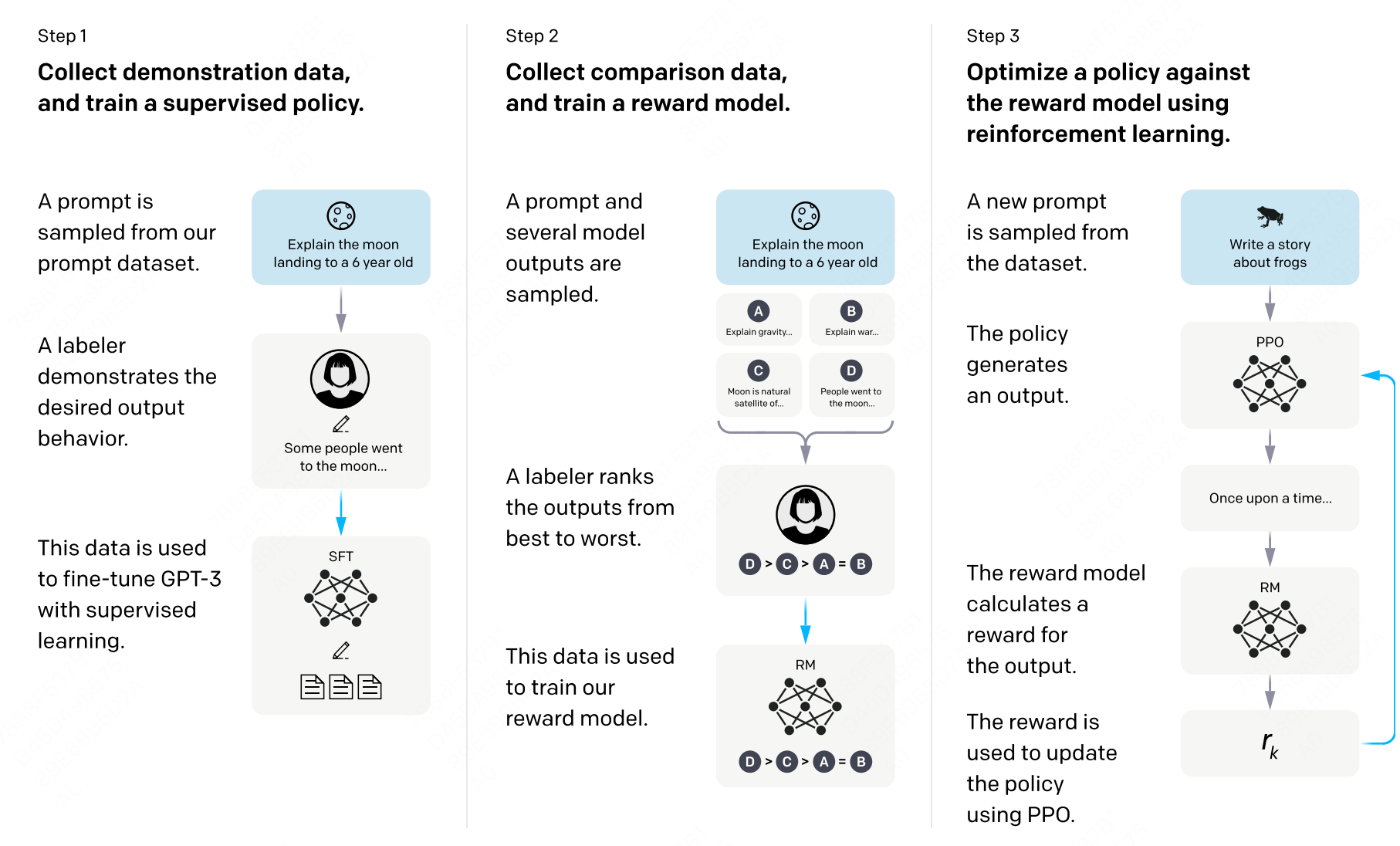
图 15-3:InstructGPT 的 RLHF 三阶段流程。Step 1:用人类标注数据进行 SFT;Step 2:用人类偏好数据训练奖励模型;Step 3:用 PPO 优化策略模型,使其生成的回答最大化奖励模型的评分。
| 模型 | 作用 | 是否更新 |
|---|---|---|
| 策略模型(Actor, | 生成回答 | 是 |
| 参考模型(Reference, | KL 约束基准,防止偏离 SFT | 否(冻结) |
| 奖励模型(Reward Model) | 对 (prompt, response) 打分 | 否(冻结) |
| 价值模型(Critic, | 估计状态价值,用于 GAE | 是(PPO 需要,GRPO 不需要) |
表 15-4:RLHF 中的四个模型。
15.1.7 Token 级 vs 序列级:策略/价值/优势的粒度差异
LLM RL 中一个关键的设计选择是优化粒度——在 token 级还是序列级计算策略比率、价值和优势?这一选择直接影响算法的方差、稳定性和计算效率。
Token 级优化(PPO、GRPO)。 对每个生成的 token
- PPO:通过 Critic 网络
和 GAE 计算每个 token 的优势 ,实现细粒度信用分配——知道"错在哪个 token"。 - GRPO:对同一 prompt 采样
个完整回答,用组内奖励的均值和标准差做归一化,得到句子级优势 ,然后将同一个 共享给该回答的所有 token。
Token 级的优势在于粒度细,但也引入了更高的方差——每个 token 的概率比率
序列级优化(GSPO、DPO)。 将整个序列视为一个"动作",计算序列级的概率比率:
序列级方法的优势是方差低,因为
DPO 则更进一步,完全绕过了 RL 循环:它直接从偏好数据
下表总结了不同算法在优化粒度上的差异:
| 算法 | 优化粒度 | 是否需要 Critic | 优势来源 | 方差特征 |
|---|---|---|---|---|
| PPO | token 级 | 需要 | GAE(Critic + TD) | 中等 |
| GRPO | token 级(句子级优势共享) | 不需要 | 组内归一化奖励 | 较高 |
| GSPO | 序列级 | 不需要 | 组内归一化奖励 | 较低 |
| DPO | 偏好对(序列级) | 不需要 | 隐式奖励差 | 低 |
表 15-5:主要 LLM RL 算法在优化粒度上的对比。
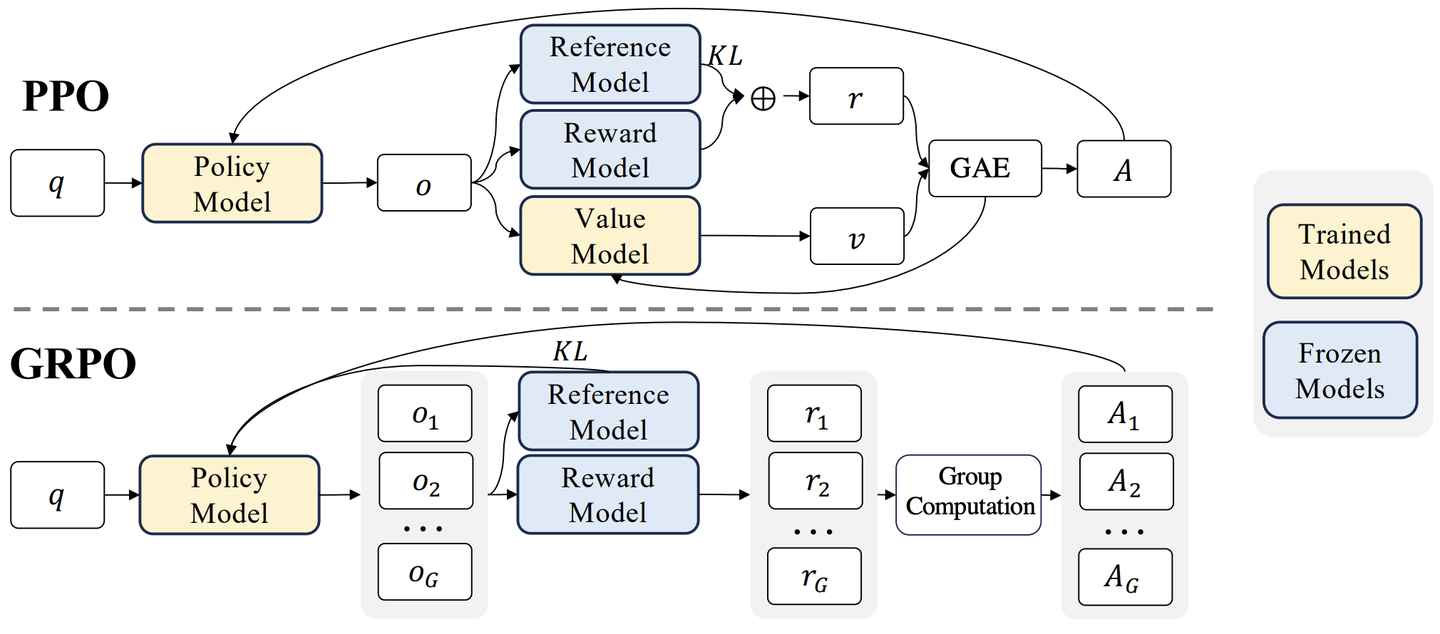
图 15-4:PPO 与 GRPO 的架构对比。PPO 需要策略模型、参考模型、奖励模型和价值模型四个模型协同工作;GRPO 通过对同一 prompt 采样多个回答并在组内计算相对优势,完全去掉了价值模型,将显存占用减少近一半。
15.1.8 RL 算法族谱与 LLM 对齐的演进
从经典 RL 到 LLM 对齐,算法的演进可以概括为以下谱系:
古典 RL
├── 基于值函数
│ ├── Q-Learning (表格式, 离策略, TD 更新)
│ └── DQN (深度 Q 网络, 离散动作空间)
│
└── 基于策略梯度
├── REINFORCE (蒙特卡洛, 高方差)
├── Actor-Critic (引入 Critic 降方差)
│ ├── A2C / A3C (同步/异步 Actor-Critic)
│ ├── TRPO (信赖域约束, 二阶优化)
│ └── PPO (裁剪替代 KL 约束, 一阶优化)
│ ├── PPO + RLHF (InstructGPT, ChatGPT)
│ ├── VAPO (价值增强, 推理专用)
│ └── GRPO (去 Critic, 组相对优势)
│ ├── DAPO (非对称 clip, 动态采样)
│ ├── GSPO (序列级, 低方差)
│ └── Dr.GRPO (修正长度偏差)
│
└── 偏好优化 (独立分支)
└── DPO (无 RM, 无 RL 循环, Bradley-Terry)图 15-5:RL 算法族谱——从古典 RL 到 LLM 对齐。
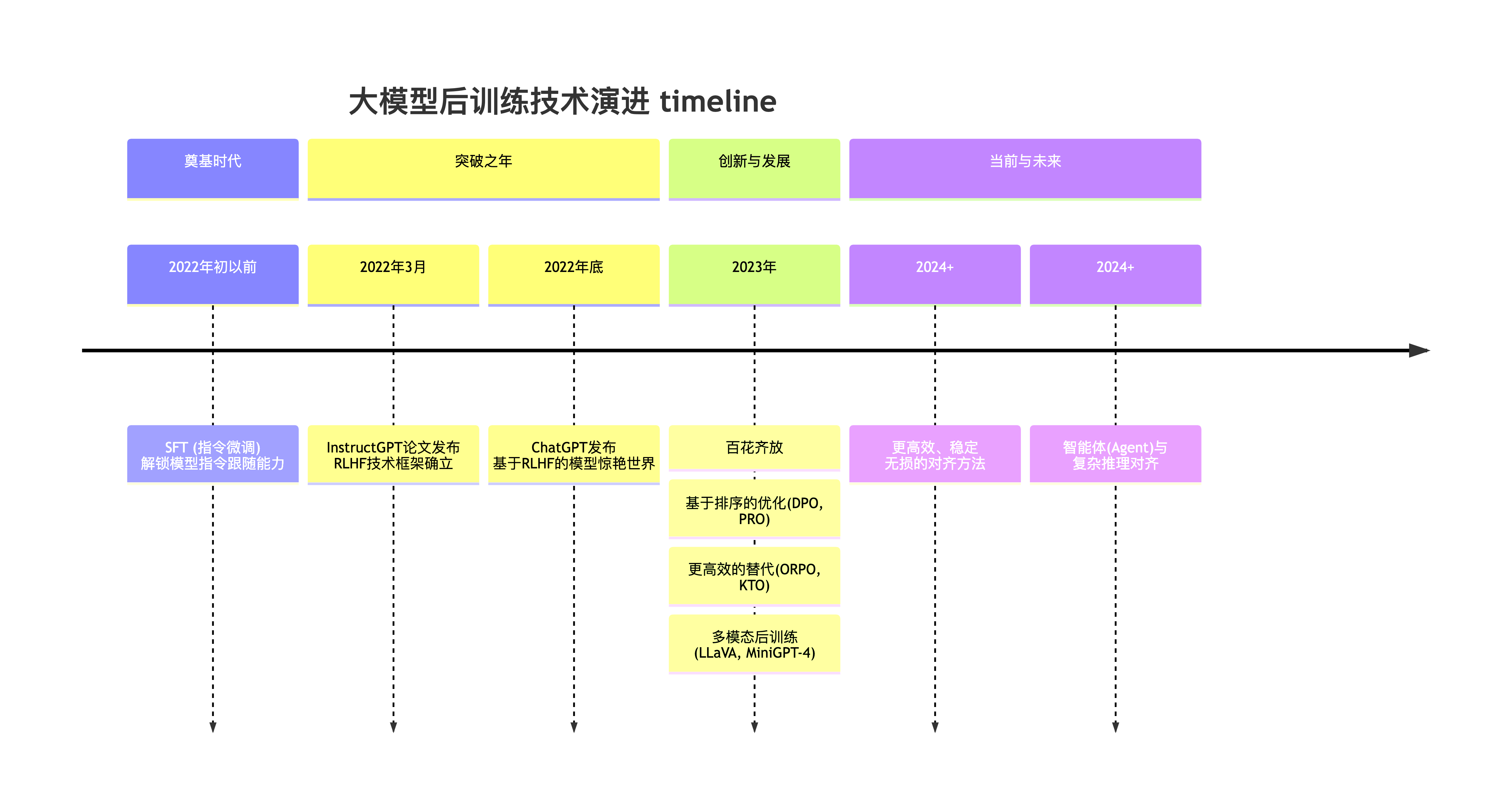
图 15-6:大模型后训练技术的历史演进。从 SFT 到 RLHF 框架确立,再到 DPO/GRPO 等更高效的替代方案,后训练技术始终在稳定性、效率和效果之间寻找平衡。
这条演进路线的核心脉络是:
- 从无模型到有模型再到无模型:Q-Learning 不需要环境模型但需要 Q 表 → DQN 用网络替代 → 策略梯度直接优化策略。
- 从高方差到低方差:REINFORCE 方差极大 → Actor-Critic 用 Critic 做基线 → GAE 平衡偏差-方差 → PPO Clip 进一步稳定。
- 从通用 RL 到 LLM 特化:PPO + RLHF 首次将 RL 用于 LLM 对齐 → GRPO 利用"同 prompt 多采样"的 LLM 特有结构去掉 Critic → DPO 完全绕过 RL。
- 从精确到实用:理论上 PPO + GAE 的 token 级优势最精细,但实践中 GRPO 的句子级共享优势已足够有效,而 DPO 甚至不需要在线采样。
15.1.9 本节小结
本节从 RL 的基本范式出发,建立了以下核心概念链:
- MDP 五元组为 RL 问题提供了数学框架,马尔可夫性使递归求解成为可能。
- 值函数与贝尔曼方程是几乎所有 RL 算法的理论基石——Q-Learning 通过 TD 更新逼近
的不动点,值迭代通过动态规划直接求解。 - 策略梯度定理开辟了直接优化策略的道路,REINFORCE 是其最朴素的实现,Actor-Critic 和 GAE 通过引入 Critic 基线大幅降低了方差。
- 将这些概念映射到 LLM 场景:状态是已生成的 token 序列,动作是下一个 token,策略就是语言模型本身。RLHF 的四模型架构(Actor, Critic, Reward, Reference)正是 Actor-Critic 在 LLM 中的实例化。
- Token 级与序列级的优化粒度选择是 LLM RL 算法设计的核心权衡:粒度越细,信用分配越精确但方差越高;粒度越粗,方差越低但信号越模糊。
掌握了这些基础之后,下一节将深入 PPO 在 LLM 中的具体实现细节——包括如何计算 token 级的 KL 惩罚奖励、如何设计裁剪目标函数、以及 PPO 训练的工程挑战。