0.4 本书路线图与阅读路径
本书共分七篇二十八章加九个附录,覆盖了大模型从数学基础到工程落地的完整知识链。然而,并非每位读者都需要按顺序通读全书。本节将梳理各篇的定位与知识依赖关系,为不同背景的读者提供三条经过精心设计的阅读路径,并约定全书数学标注的阅读优先级。
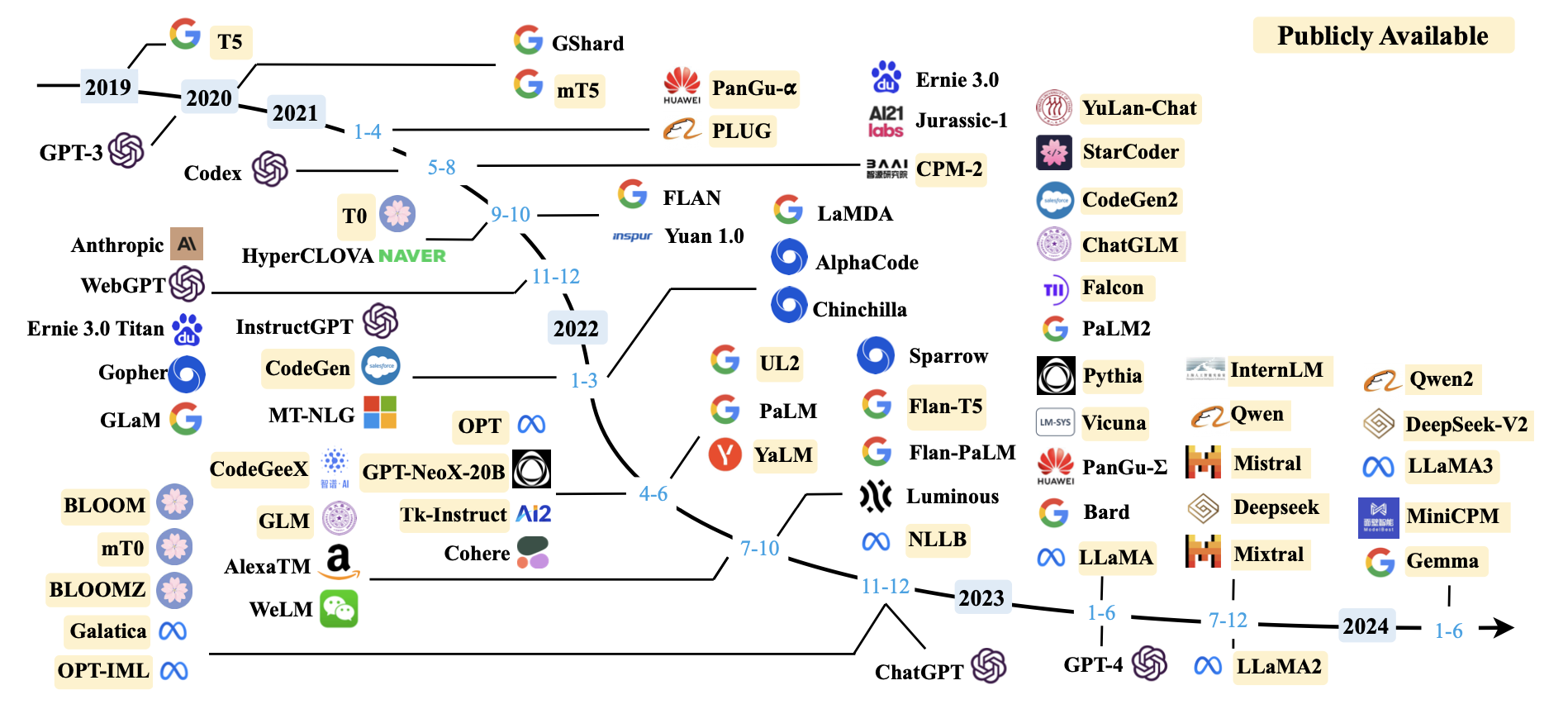
图 0-9:2019-2024 年间主要大语言模型的发展时间线。本书所覆盖的技术栈——从 GPT 系列的基础架构到 DeepSeek、LLaMA 的最新创新——正是在这张时间线上不断演进的产物。理解这些模型之间的继承与创新关系,是选择阅读路径的重要参考。
0.4.1 全书七篇定位一览
| 篇 | 章节范围 | 核心定位 | 关键词 |
|---|---|---|---|
| 第一篇:基础篇 | 第 0--3 章 | 从深度学习基本功到 Transformer 架构的完整推导 | 深度学习、序列建模、注意力机制 |
| 第二篇:构建篇 | 第 4--8 章 | 亲手搭建一个可训练的大语言模型 | 分词、预训练、注意力优化、模型解剖、MoE |
| 第三篇:系统篇 | 第 9--11 章 | 让模型跑起来的硬件与分布式基础设施 | GPU 编程、分布式训练、AI 集群 |
| 第四篇:对齐篇 | 第 12--16 章 | 让模型"听话"并符合人类偏好 | SFT、LoRA、蒸馏、RLHF、偏好优化 |
| 第五篇:推理篇 | 第 17--19 章 | 推理阶段的效率与能力提升 | 推理时间缩放、推理模型训练、推理优化 |
| 第六篇:应用篇 | 第 20--24 章 | 把大模型变成可用产品 | 评估、Agent、RAG、多模态、前沿应用 |
| 第七篇:实战篇 | 第 25--27 章 | 端到端项目实战与工具链 | MiniMind、推理模型实战、TRL |
| 附录 | A--I | 数学工具箱、历史回顾、论文索引等参考材料 | 线性代数、概率论、AlphaGo、代码注释 |
0.4.2 知识依赖关系图
全书的章节之间存在清晰的前置依赖关系。理解这些依赖,是灵活选择阅读路径的基础。
┌─────────────────────────────────────────────────┐
│ 第一篇:基础篇(第 0-3 章) │
│ 深度学习基础 → 序列建模 → Transformer │
└──────────────┬──────────────────────────────────┘
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
┌────────────────────┐ ┌──────────────┐ ┌──────────────────┐
│ 第二篇:构建篇 │ │ 第三篇:系统篇│ │ 第六篇:应用篇 │
│ (第 4-8 章) │ │ (第 9-11 章)│ │ (第 20-24 章) │
│ 分词→预训练→MoE │ │ GPU→分布式 │ │ 评估→Agent→RAG │
└────────┬───────────┘ └──────┬───────┘ └────────┬─────────┘
│ │ │
▼ │ │
┌────────────────────┐ │ │
│ 第四篇:对齐篇 │◄────────┘ │
│ (第 12-16 章) │ │
│ SFT→LoRA→RLHF │ │
└────────┬───────────┘ │
│ │
▼ │
┌────────────────────┐ │
│ 第五篇:推理篇 │◄────────────────────────────┘
│ (第 17-19 章) │
│ 推理缩放→推理优化 │
└────────┬───────────┘
│
▼
┌────────────────────┐
│ 第七篇:实战篇 │
│ (第 25-27 章) │
│ MiniMind→TRL │
└────────────────────┘核心依赖关系的文字说明:
第一篇(第 0--3 章)是全书基石。 第 0 章回顾深度学习基础,第 1--2 章引入序列建模范式,第 3 章完整推导 Transformer 架构。后续所有篇章都假设读者已掌握第 3 章的内容。如果你对 Transformer 的多头注意力、位置编码、残差连接已经非常熟悉,可以快速浏览第 3 章后直接进入后续篇章。
第二篇(第 4--8 章)依赖第一篇。 分词器(第 4 章)需要序列建模的背景知识;预训练(第 5 章)需要理解 Transformer 架构;注意力优化(第 6 章)和模型解剖(第 7 章)是对 Transformer 内部机制的深入探索;MoE 与创新架构(第 8 章)则在此基础上拓展前沿方向。
第三篇(第 9--11 章)与第二篇相对独立,但共同依赖第一篇。 GPU 编程(第 9 章)侧重硬件与算子层面,不要求掌握预训练细节;分布式训练(第 10 章)和 AI 集群(第 11 章)则需要对模型结构有基本认知。第三篇是第四篇大规模训练的前置知识。
第四篇(第 12--16 章)依赖第二篇和第三篇。 SFT(第 12 章)需要预训练知识;LoRA(第 13 章)需要理解模型参数结构;蒸馏(第 14 章)涉及教师-学生模型的训练;RLHF(第 15 章)和偏好优化(第 16 章)是对齐技术的核心,需要对模型训练流程有完整理解。
第五篇(第 17--19 章)依赖第二篇,与第三篇部分交叉。 推理时间缩放(第 17 章)需要理解模型的前向传播流程;训练推理模型(第 18 章)桥接了对齐与推理两个方向;推理优化(第 19 章)涉及量化、KV Cache 等系统级技术,与第 9 章的 GPU 知识相互呼应。
第六篇(第 20--24 章)依赖第一篇,部分章节依赖第四篇。 评估(第 20 章)需要了解模型能力的来源;Agent(第 21--22 章)和 RAG(第 23 章)更偏应用层,对底层训练细节的依赖较弱;多模态(第 23 章)和前沿应用(第 24 章)则需要更广泛的知识储备。
第七篇(第 25--27 章)是全书的综合实战。 MiniMind 实战(第 25 章)串联构建篇和对齐篇的知识;推理模型实战(第 26 章)串联推理篇的理论与实践;TRL 工具链(第 27 章)提供工程化的训练框架。
0.4.3 各篇验收产物
每一篇学完后,读者应当能够交付一个具体的"验收产物",以此检验学习效果:
| 篇 | 验收产物 | 产物形式 |
|---|---|---|
| 第一篇:基础篇 | 从零实现一个单层 Transformer Encoder/Decoder,在简单序列任务上完成训练和推理 | 代码(约 300 行 PyTorch) |
| 第二篇:构建篇 | 从零实现 BPE 分词器 + 一个完整的 GPT 风格语言模型(含注意力优化),在小规模语料上完成预训练 | 代码(约 1500 行 PyTorch) |
| 第三篇:系统篇 | 编写一个简单的 CUDA Kernel 并用 PyTorch DDP 在多卡上训练模型,理解集群调度的基本流程 | CUDA 代码 + 分布式训练脚本 |
| 第四篇:对齐篇 | 对预训练模型依次完成 SFT 微调、LoRA 适配、DPO 偏好优化,获得一个可对话的小模型 | 训练流水线 + 模型权重 |
| 第五篇:推理篇 | 实现 KV Cache、Speculative Decoding 等推理加速技术,将模型推理速度提升 2 倍以上 | 优化后的推理引擎代码 |
| 第六篇:应用篇 | 搭建一个包含 Agent 调度 + RAG 检索增强的端到端问答系统 | 应用系统(含向量数据库 + Agent 框架) |
| 第七篇:实战篇 | 完成 MiniMind 全流程(预训练 → 对齐 → 推理优化 → 部署),或使用 TRL 复现一个公开模型的训练 | 完整项目代码 + 训练日志 + 评估报告 |
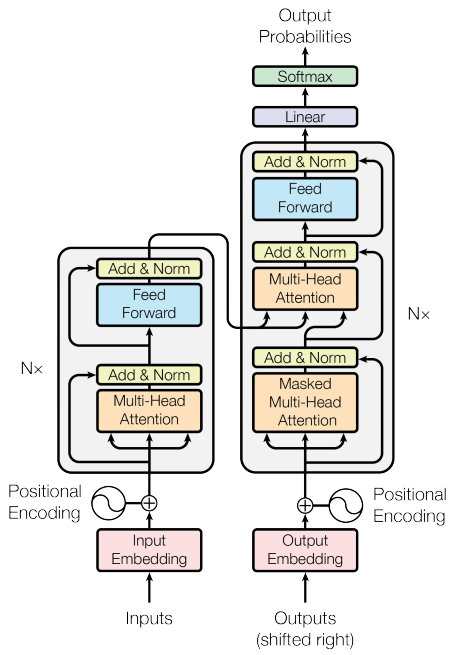
图 0-11:Transformer 的 Encoder-Decoder 架构全貌。编码器栈(左)和解码器栈(右)通过交叉注意力连接。这一架构是本书第 3 章的核心内容,也是后续所有变体(Encoder-only、Decoder-only)的共同基础。
0.4.4 三条推荐阅读路径
根据读者的背景和目标,我们设计了三条主线路径。每条路径都经过精简,确保在最短的阅读链路内达成特定目标。
路径一:模型训练路线——"我想从零训一个大模型"
适合人群: 希望深入理解大模型训练全流程的研究者、算法工程师,或准备在预训练/对齐方向发论文的研究生。
路线: 第 1--5 章 → 第 8 章 → 第 10 章 → 第 12--14 章 → 第 25 章
| 阶段 | 章节 | 学习目标 | 预计时间 |
|---|---|---|---|
| 打基础 | 第 1--3 章 | 掌握序列建模与 Transformer 架构的完整推导 | 2--3 周 |
| 学构建 | 第 4--5 章 | 理解分词、预训练的数据流与训练目标 | 1--2 周 |
| 看前沿 | 第 8 章 | 了解 MoE、创新架构等扩展方向 | 1 周 |
| 上规模 | 第 10 章 | 掌握数据并行、模型并行、流水线并行等分布式训练策略 | 1--2 周 |
| 做对齐 | 第 12--14 章 | 走通 SFT → LoRA → 蒸馏的对齐流水线 | 2--3 周 |
| 跑实战 | 第 25 章 | 用 MiniMind 项目串联全流程,端到端训练一个小模型 | 2 周 |
说明: 本路径跳过了第 6--7 章(注意力优化与模型解剖)和第 9 章(GPU 编程),这些内容在首次阅读时可以作为选读。但如果你计划在千卡级别上训练模型,强烈建议回头补充第 9--11 章的系统篇内容。第 15--16 章(RLHF 与偏好优化)可在完成第 25 章实战后作为进阶阅读。
路径二:推理系统路线——"我想把模型部署得又快又省"
适合人群: 推理引擎开发者、系统工程师、MLOps 工程师,或关注模型服务化与边缘部署的从业者。
路线: 第 3 章 → 第 6--7 章 → 第 9 章 → 第 17--19 章 → 第 26 章
| 阶段 | 章节 | 学习目标 | 预计时间 |
|---|---|---|---|
| 懂架构 | 第 3 章 | 理解 Transformer 的计算流程与内存占用特征 | 1--2 周 |
| 抠细节 | 第 6--7 章 | 深入注意力机制的优化手段(FlashAttention 等)与模型内部结构 | 2 周 |
| 碰硬件 | 第 9 章 | 理解 GPU 内存层次、算子融合、CUDA 编程基础 | 2 周 |
| 学推理 | 第 17--19 章 | 掌握推理时间缩放定律、推理模型训练、KV Cache/量化/投机解码等优化技术 | 3 周 |
| 跑实战 | 第 26 章 | 完成推理模型的端到端实战 | 1--2 周 |
说明: 本路径聚焦于"理解模型结构 → 优化计算 → 加速推理"这条主线。跳过了预训练(第 5 章)和对齐(第 12--16 章)的大部分内容——推理工程师不需要知道模型是怎么训出来的,但必须清楚模型内部每一层在做什么运算、每个张量占多少显存。如果后续需要做量化感知训练(QAT),可回头补充第 5 章和第 13 章。
路径三:Agent/应用路线——"我想用大模型构建智能应用"
适合人群: 应用开发者、产品经理、全栈工程师,或希望快速将大模型能力集成到产品中的创业者。
路线: 第 3 章 → 第 15--16 章 → 第 21--22 章 → 第 23 章
| 阶段 | 章节 | 学习目标 | 预计时间 |
|---|---|---|---|
| 懂原理 | 第 3 章 | 建立对 Transformer 架构的直觉理解(不需要手推公式) | 1 周 |
| 懂对齐 | 第 15--16 章 | 理解 RLHF 与偏好优化如何塑造模型行为,学会设计奖励信号 | 1--2 周 |
| 建 Agent | 第 21--22 章 | 掌握 Agent 的设计范式:工具调用、规划、记忆、多 Agent 协作 | 2 周 |
| 做增强 | 第 23 章 | 搭建 RAG 系统:向量检索、文档切分、检索增强生成 | 1--2 周 |
说明: 这是三条路径中最短的一条,适合希望快速上手的读者。本路径有意跳过了预训练、分布式训练、推理优化等底层内容,直接从"模型能做什么"出发构建应用。第 15--16 章被纳入路径是因为理解对齐机制对于 prompt engineering 和 Agent 行为调试至关重要。完成本路径后,如果你发现需要微调模型来适配特定场景,可以回头走模型训练路线的对齐部分(第 12--14 章)。
0.4.5 三条路径总览
模型训练路线: [1-5] ──→ [8] ──→ [10] ──→ [12-14] ──→ [25]
推理系统路线: [3] ──→ [6-7] ──→ [9] ──→ [17-19] ──→ [26]
Agent/应用路线: [3] ──→ [15-16] ──→ [21-22] ──→ [23]
▲
│
共同起点:第 3 章 Transformer三条路径的共同起点都是 第 3 章 Transformer——这是全书的"枢纽章节"。无论你选择哪条路径,请确保对第 3 章的核心内容(自注意力机制、多头注意力、前馈网络、残差与层归一化)有扎实的理解。
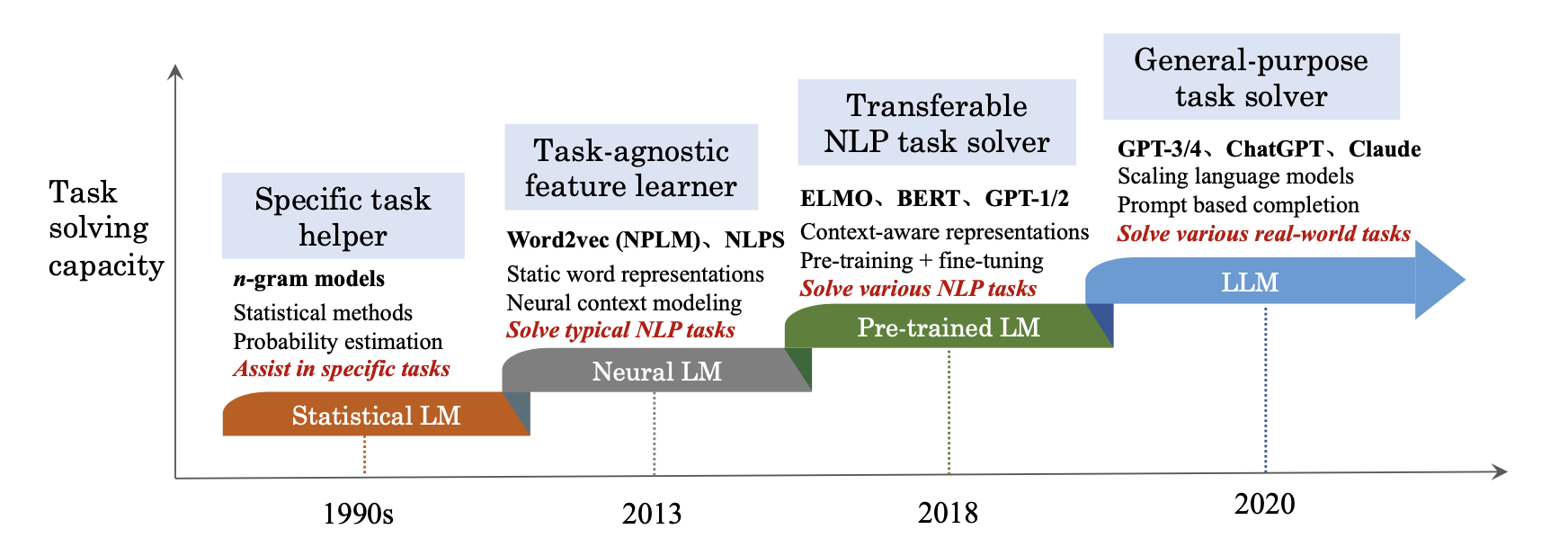
图 0-10:语言模型技术范式的四次跃迁——从统计语言模型到大语言模型。本书的三条阅读路径分别侧重这一演进链条的不同环节:模型训练路线深入第三到第四阶段的训练方法论,推理系统路线聚焦第四阶段的效率优化,Agent/应用路线则着眼于大语言模型的能力释放与工程落地。
0.4.6 数学前置约定
本书涉及大量数学推导。为了兼顾不同数学背景的读者,我们在全书的硬核推导处采用三级标注体系:
| 标注 | 含义 | 建议 |
|---|---|---|
| [必读] | 理解后续内容的必要推导,跳过会导致知识链断裂 | 务必逐行跟读,必要时手写推导一遍 |
| [选读] | 加深理解但不影响主线阅读的补充推导 | 首次阅读可跳过,回头需要时再读 |
| [挑战] | 面向数学功底扎实的读者的进阶内容 | 如果你不以研究为目标,可安全跳过 |
遇到陌生符号怎么办? 全书的数学符号约定统一收录在 附录 A:数学工具箱 中,涵盖线性代数、概率论与信息论的核心记号。当你在正文中遇到不熟悉的符号或运算时,请回跳至附录 A 查阅对应条目。附录 A 按主题组织而非按字母排列,方便快速定位。
此外,以下几个数学主题在多章中反复出现,建议提前建立直觉:
- 矩阵乘法与分块矩阵运算(附录 A.1):贯穿注意力计算、分布式并行、推理优化
- 概率分布与采样(附录 A.2):贯穿语言模型输出、RLHF 奖励建模、推理解码策略
- 梯度与反向传播(附录 A.3):贯穿预训练、微调、LoRA 等所有涉及参数更新的章节
- 信息论基础(熵、KL 散度、交叉熵)(附录 A.4):贯穿损失函数设计、蒸馏、偏好优化
0.4.7 给不同读者的建议
如果你是深度学习初学者: 请老老实实从第 0 章开始,按顺序读完第一篇,确保基础扎实后再选择路径。第一篇中标注 [挑战] 的内容可以先跳过。
如果你是有经验的算法工程师: 快速浏览第 3 章确认没有知识盲区,然后直接跳入你关心的路径。遇到前置知识缺失时按依赖关系图回跳即可。
如果你是系统/基础设施工程师: 推理系统路线是为你量身设计的。第 3 章重点关注计算图和张量形状,数学推导看 [必读] 即可。
如果你是产品经理或非技术背景读者: Agent/应用路线对数学要求最低。第 3 章只需建立直觉理解,[选读] 和 [挑战] 内容可全部跳过。
如果你想通读全书: 我们推荐的顺序是——第一篇 → 第二篇 → 第三篇 → 第四篇 → 第五篇 → 第六篇 → 第七篇。这是知识依赖最自然的线性顺序。附录随用随查,不必提前通读。
没有哪条路径是"唯一正确"的。大模型领域的知识高度交织,训练工程师需要理解推理优化来设计高效的模型结构,应用开发者需要理解对齐原理来写出更好的 prompt,推理工程师需要理解训练目标来做出正确的量化决策。我们提供路径,是为了降低入门门槛;但最终,一位优秀的大模型从业者会逐步将这三条路径融会贯通。
选一条路径开始,走到足够远之后,你自然会知道下一步该读什么。