17.4 自一致性(Self-Consistency)
上一节介绍了温度缩放与 Top-p 采样如何控制输出多样性。这些技术单独使用时,每次只产生一条推理路径——模型"掷一次骰子"就定了答案。但对于复杂推理任务,单条路径的偶然性很大:同一模型在不同随机种子下可能得到截然不同的结果。自一致性(Self-Consistency) 正是针对这一问题提出的推理时间缩放策略:让模型对同一问题独立采样多条推理路径,提取每条路径的最终答案,然后通过多数投票(Majority Voting) 选出出现频率最高的答案作为最终输出。
这一方法的核心直觉是:正确答案比错误答案更容易被多条独立推理路径同时发现。 错误答案各有各的错法,但正确答案只有一个——因此当采样足够多条路径时,正确答案在投票中自然会胜出。本节将从原理出发,给出完整的实现代码,并结合实验数据分析自一致性的效果与局限。
17.4.1 从单路径到多路径:为什么需要自一致性
§17.2 介绍的 CoT 提示虽然能显著提升推理准确率,但存在一个根本问题:单条推理链是脆弱的。 模型在生成推理步骤时,任何一步的随机波动都可能导致整条推理链偏向错误答案。即使提示完全相同,不同的采样(不同随机种子、不同温度)也会产生不同结果——有时对,有时错。
Wang et al. (2023) 在论文 "Self-Consistency Improves Chain of Thought Reasoning in Language Models" 中系统提出了自一致性方法。其核心思想可以用一句话概括:多次独立采样,然后投票。 具体流程分为三步:
- 多次采样(Sample):使用较高的温度(如
)和 Top-p 采样(如 ),对同一问题生成 条独立的推理路径。每条路径包含完整的 CoT 推理过程和最终答案。 - 答案提取(Extract):从每条推理路径中提取最终答案(如
\boxed{83}中的83)。 - 多数投票(Vote):统计所有提取到的答案的出现频率,选择出现次数最多的答案作为最终输出。
下面用一个具体例子来说明。假设模型对问题 "Half the value of
| 采样编号 | 推理过程(简化) | 提取答案 |
|---|---|---|
| 1 | 83 | |
| 2 | 错误地将 | 22 |
| 3 | 计算过程中漏项,得到 | 54 |
| 4 | 正确推理, | 83 |
| 5 | 符号错误,得到 | 61 |
投票结果:83 出现 2 次,其余各出现 1 次。最终答案选择 83(正确)。虽然 5 次采样中有 3 次给出了错误答案,但多数投票仍然选出了正确结果。
需要注意的是,这里的"多数投票"严格来说是多元投票(Plurality Voting):选择得票最多的答案,而非要求获得超过半数的票。当答案空间较大时(如数学题的答案可以是任意数字),正确答案可能只获得少数投票,但仍是所有答案中得票最多的。
17.4.2 自一致性的完整实现
下面给出一个完整的、自包含的自一致性实现。代码分为三个核心组件:答案提取、单次采样和投票聚合。
答案提取器。 从模型输出中提取结构化答案:
import re
from collections import Counter
def extract_answer(text: str) -> str:
"""
从模型输出中提取最终答案。
优先匹配 \\boxed{...} 格式,回退到最后一个数字。
"""
# 优先提取 \boxed{...} 格式
boxed = re.findall(r"\\boxed\{([^}]*)\}", text)
if boxed:
return boxed[-1].strip()
# 回退:提取最后一个独立数字
numbers = re.findall(r"-?\d+\.?\d*", text)
if numbers:
return numbers[-1]
# 最终回退:返回最后一行
return text.strip().split("\n")[-1].strip()自一致性投票的核心实现:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import random
def self_consistency_solve(
question: str,
call_llm_func,
num_samples: int = 5,
temperature: float = 0.8,
top_p: float = 0.9,
show_progress: bool = True,
) -> dict:
"""
自一致性推理:多次采样 + 多数投票。
参数:
question: 待解问题
call_llm_func: LLM 调用函数,签名为 f(prompt, temperature, top_p) -> str
num_samples: 采样次数
temperature: 温度参数,控制输出多样性
top_p: Top-p 采样阈值
show_progress: 是否打印每次采样结果
返回:
包含 final_answer、all_answers、vote_counts 的字典
"""
# 构造 CoT 提示
system = (
"You are a helpful math assistant.\n"
"Answer the question and write the final result "
"on a new line as:\n\\boxed{ANSWER}\n"
)
prompt = f"{system}\nQuestion:\n{question}\n\nAnswer:\n\nExplain step by step."
full_responses = []
extracted_answers = []
# 步骤 1:多次独立采样
for i in range(num_samples):
response = call_llm_func(prompt, temperature=temperature, top_p=top_p)
answer = extract_answer(response)
full_responses.append(response)
extracted_answers.append(answer)
if show_progress:
print(f"[Sample {i+1}/{num_samples}] -> {answer!r}")
# 步骤 2:多数投票
vote_counts = Counter(extracted_answers)
most_common = vote_counts.most_common()
# 选择得票最多的答案;平票时取首次出现者
if most_common:
top_count = most_common[0][1]
winners = [ans for ans, cnt in most_common if cnt == top_count]
if len(winners) == 1:
final_answer = winners[0]
else:
# 平票打破:选择最先出现的答案
for ans in extracted_answers:
if ans in winners:
final_answer = ans
break
else:
final_answer = None
return {
"final_answer": final_answer,
"all_answers": extracted_answers,
"vote_counts": dict(vote_counts),
"full_responses": full_responses,
}使用示例:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
# 模拟 LLM 调用(实际使用时替换为真实 API 调用)
def mock_llm(prompt: str, temperature: float = 0.8, top_p: float = 0.9) -> str:
"""模拟 LLM 在不同温度下产生不同推理路径"""
responses = [
"Step 1: (1/2)(3x-9) = x+37\nStep 2: 3x-9 = 2x+74\nStep 3: x = 83\n\\boxed{83}",
"Step 1: (3x-9)/2 = x+37\nStep 2: 3x-9 = 2x+74\nStep 3: x = 83\n\\boxed{83}",
"Step 1: half of 3x-9 is x+37\nStep 2: 3x/2 = x+46\nStep 3: x = 92\n\\boxed{92}",
"Step 1: (1/2)(3x-9) = x+37\nStep 2: 3x-9 = 2(x+37)\nStep 3: x = 83\n\\boxed{83}",
"Step 1: 3x-9 = 2(x+37)\nStep 2: 3x-9 = 2x+74\nStep 3: x = 83\n\\boxed{83}",
]
mock_llm._call_count = getattr(mock_llm, "_call_count", -1) + 1
return responses[mock_llm._call_count % len(responses)]
result = self_consistency_solve(
question="Half the value of 3x-9 is x+37. What is the value of x?",
call_llm_func=mock_llm,
num_samples=5,
)
print(f"\n投票统计: {result['vote_counts']}")
print(f"最终答案: {result['final_answer']}")
# 输出:
# 投票统计: {'83': 4, '92': 1}
# 最终答案: 8317.4.3 温度与采样次数的权衡
自一致性的效果取决于两个关键超参数:温度(Temperature) 和 采样次数(
温度的选择。 温度过低(如
采样次数的选择。 增加采样次数可以提升投票的可靠性,但计算成本线性增长。下表是 Raschka (2025) 在 MATH-500 基准上使用 Qwen3-0.6B 基座模型的实验结果:
| 方法 | 准确率 | 耗时 |
|---|---|---|
| 标准提示(贪心解码) | 15.2% | 10.1 min |
| CoT(单路径) | 40.6% | 84.5 min |
| Top-p + 自一致性 (n=3) | 29.6% | 97.6 min |
| Top-p + 自一致性 (n=10) | 31.6% | 300.4 min |
| CoT + 自一致性 (n=3) | 42.2% | 211.6 min |
| CoT + 自一致性 (n=5) | 48.0% | 452.9 min |
| CoT + 自一致性 (n=10) | 52.0% | 862.6 min |
表 17-3:自一致性在 MATH-500 上的实验结果。数据来自 Raschka (2025) 在 DGX Spark 上的实验。
几个关键观察:
自一致性必须与 CoT 结合才能发挥最大效果。 不使用 CoT 时,Top-p + 自一致性 (n=10) 仅达到 31.6%;而 CoT + 自一致性 (n=10) 达到 52.0%——这是因为没有 CoT 时,模型的推理能力本身就很弱,多数投票只是在多个"猜测"中选择,而非在多条"推理"中选择。
收益递减但稳定提升。 从 n=3 到 n=5 提升了 5.8 个百分点(42.2% → 48.0%),从 n=5 到 n=10 提升了 4.0 个百分点(48.0% → 52.0%)。更多采样仍然有效,但边际收益递减。
计算开销线性增长。 n=10 的耗时是 n=3 的约 4 倍,是单路径 CoT 的约 10 倍。这是典型的"用计算换准确率"的推理时间缩放。
基座模型可以超越专用推理模型。 CoT + 自一致性 (n=10) 的 52.0% 超过了专用推理模型的 48.2%——仅通过推理时策略,就实现了与模型训练相当甚至更好的效果。
17.4.4 提前终止与效率优化
当采样次数较多时(如 n=10 或更高),一个自然的优化思路是提前终止(Early Stopping):如果某个答案已经获得了绝对多数票(超过剩余可能被翻转的票数),就无需继续采样。
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
def self_consistency_with_early_stop(
question: str,
call_llm_func,
num_samples: int = 10,
temperature: float = 0.8,
top_p: float = 0.9,
) -> dict:
"""带提前终止的自一致性投票"""
system = (
"You are a helpful math assistant.\n"
"Answer the question and write the final result "
"on a new line as:\n\\boxed{ANSWER}\n"
)
prompt = f"{system}\nQuestion:\n{question}\n\nAnswer:\n\nExplain step by step."
counts = Counter()
all_answers = []
for i in range(num_samples):
response = call_llm_func(prompt, temperature=temperature, top_p=top_p)
answer = extract_answer(response)
all_answers.append(answer)
counts[answer] += 1
# 提前终止:某答案票数已超过总样本数的一半
if counts[answer] > num_samples / 2:
print(f"提前终止:'{answer}' 已获 {counts[answer]}/{num_samples} 票")
return {
"final_answer": answer,
"all_answers": all_answers,
"vote_counts": dict(counts),
"samples_used": i + 1,
}
# 常规投票
final_answer = counts.most_common(1)[0][0]
return {
"final_answer": final_answer,
"all_answers": all_answers,
"vote_counts": dict(counts),
"samples_used": num_samples,
}提前终止在模型准确率较高时效果显著。例如,如果模型在某问题上 80% 的概率给出正确答案,那么 10 次采样中通常在第 3-4 次就能确定多数票,节省 60-70% 的计算量。
除了提前终止,另一个重要的效率优化是批量并行采样(Batched Sampling)。与逐条串行生成相比,将
17.4.5 自一致性的数学直觉
为什么投票能提升准确率?我们可以用一个简化的概率模型来理解。
假设模型对某问题的单次采样正确率为
下面的代码计算并可视化了这一关系:
from math import comb
def majority_vote_accuracy(p: float, n: int) -> float:
"""计算 n 次独立采样后多数投票的正确率"""
threshold = n // 2 + 1 # 需要的最低票数
total = 0.0
for k in range(threshold, n + 1):
total += comb(n, k) * (p ** k) * ((1 - p) ** (n - k))
return total
# 展示不同单次正确率和采样次数下的投票正确率
for p in [0.4, 0.5, 0.6, 0.7, 0.8]:
results = [f"n={n}: {majority_vote_accuracy(p, n):.3f}" for n in [1, 3, 5, 11]]
print(f"p={p:.1f} {' '.join(results)}")
# 输出:
# p=0.4 n=1: 0.400 n=3: 0.352 n=5: 0.317 n=11: 0.236
# p=0.5 n=1: 0.500 n=3: 0.500 n=5: 0.500 n=11: 0.500
# p=0.6 n=1: 0.600 n=3: 0.648 n=5: 0.683 n=11: 0.753
# p=0.7 n=1: 0.700 n=3: 0.784 n=5: 0.837 n=11: 0.932
# p=0.8 n=1: 0.800 n=3: 0.896 n=5: 0.942 n=11: 0.988这个结果揭示了自一致性的核心前提条件:
- 当
时,投票正确率随 增加单调上升,趋向 1.0。这正是自一致性有效的区间。 - 当
时,投票与随机猜测无异,增加采样次数没有帮助。 - 当
时,投票反而降低正确率——多数投票会放大错误倾向。
这解释了为什么自一致性必须与 CoT 结合:没有 CoT 时,基座模型的单次正确率可能低于 50%(如表中的 15.2%),此时投票不仅无益,反而有害。CoT 将单次正确率提升到 40.6% 后(对于多选或有限答案空间的子问题,有效的
这一分析也揭示了自一致性的理论上界:它无法创造模型不具备的能力,只能放大已有的正确倾向。 如果模型对某类问题完全无法正确推理,再多的采样也无济于事。
17.4.6 从投票到评分:自一致性的进阶方向
朴素的多数投票对每条推理路径一视同仁——不管推理过程质量如何,只要最终答案相同就计为一票。这显然不是最优的。自一致性的进阶方向包括:
加权投票。 为每条推理路径赋予不同权重,质量更高的路径权重更大。权重可以基于模型的对数概率置信度(Log-probability Confidence) 计算:将推理路径中所有生成 Token 的对数概率求和或求均值,得到路径的整体置信度分数。高置信度路径的投票权重更大。
Best-of-N 采样。 与多数投票不同,Best-of-N 使用一个独立的验证器(Verifier) 或奖励模型(Reward Model) 对每条推理路径进行评分,选择得分最高的路径作为最终输出。验证器可以是过程监督奖励模型(Process-supervised Reward Model, PRM),它对推理链中的每一步进行打分,从而不仅评估最终答案的正确性,还评估推理过程的合理性。
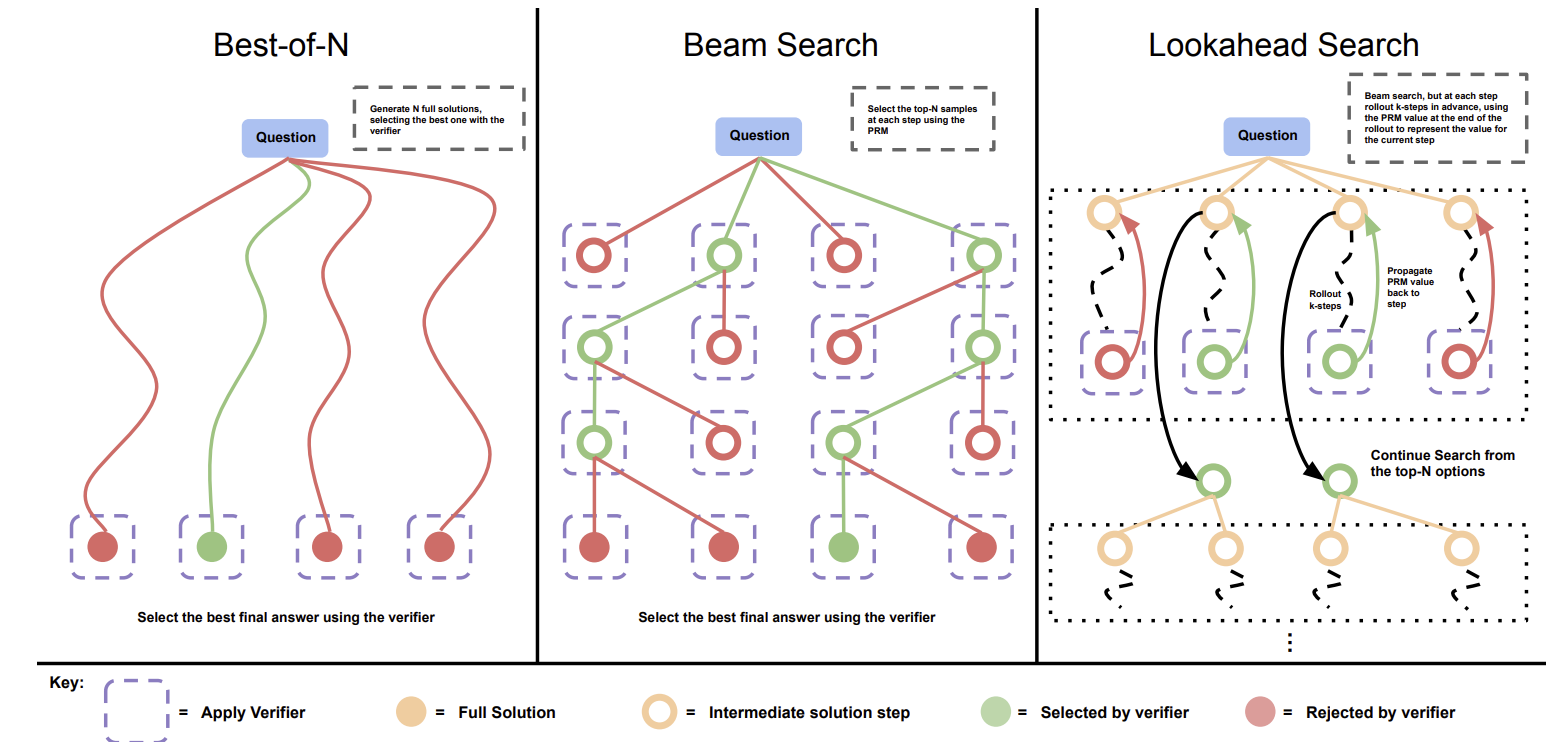
图 17-5:三种基于验证器的推理时搜索策略对比。Best-of-N 是最简单的变体,与自一致性共享"多次采样"的思想,但用评分替代了投票。Beam Search 和 Lookahead Search 则在推理过程中进行更细粒度的搜索。综合整理自 Snell et al. (2024) 和 Wang et al. (2024)。
LLM-as-Judge。 使用另一个(通常更强的)语言模型作为裁判,对多条推理路径进行比较评估,选出最优的一条。这种方法在 Claude 4 等前沿系统中已有应用——系统在内部并行生成多条回答,再用内部模型对回答进行评分和排序。
这些进阶方法将在 §17.5(自改进)和 §17.6(推理时间 Scaling Law)中进一步展开讨论。
本节总结
自一致性是一种简洁而有效的推理时间缩放策略,其核心思想是"多次独立采样 + 多数投票"。通过让模型生成多条独立的推理路径并对最终答案进行投票,自一致性利用了"正确答案更容易被多条路径独立发现"的统计规律,将单次推理的偶然性转化为集体决策的稳定性。实验表明,CoT + 自一致性 (n=10) 可以将 0.6B 参数基座模型在 MATH-500 上的准确率从 40.6%(单路径 CoT)提升至 52.0%,甚至超越专用推理模型。但自一致性有一个核心前提:模型的单次正确率必须高于随机水平,否则投票只会放大错误。提前终止和批量并行采样等优化手段可以有效降低计算开销。在此基础上,加权投票、Best-of-N 和 LLM-as-Judge 等进阶方法进一步将"盲投票"升级为"有评分的选择",为更精细的推理时间缩放奠定了基础。