25.2 全流程实战
前一节我们从宏观视角理解了大模型训练的各个阶段。本节将以一个约 26M 参数的微型语言模型为案例,手把手走完从 Tokenizer 训练到推理模型蒸馏的完整七步流程。每一步都给出可运行的核心代码、关键设计决策的分析,以及真实训练曲线,让读者在自己的单卡 GPU 上即可复现全过程。
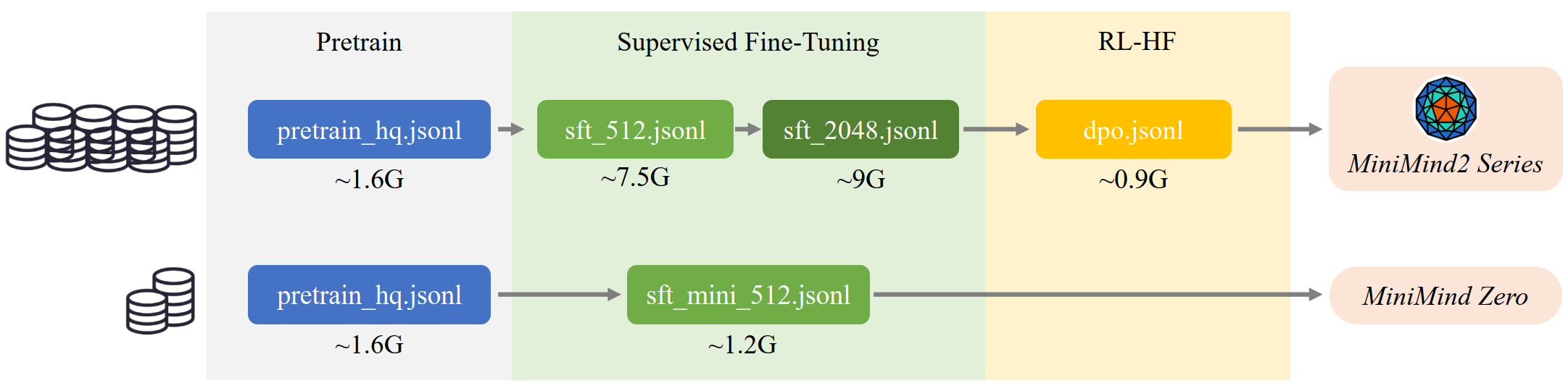
整体流水线如下图所示,数据从预训练语料出发,经过 SFT 多轮对话、偏好优化,最终产出可部署的对话模型:
Step 1:训练 Tokenizer
Tokenizer 是大模型的"眼睛"——它决定了模型看到的是什么。 选择一个好的分词器直接影响模型的词表效率、中文覆盖率和训练收敛速度。对于小模型,我们通常从零训练一个 BPE(Byte Pair Encoding)分词器,而非复用 GPT-4 的 10 万词表——过大的词表会让 Embedding 层占据模型的绝大部分参数。
BPE 核心思想:从最小单元(字节或字符)出发,迭代地合并语料中出现频率最高的相邻字节对,直到词表达到预设大小。这在编码效率和未登录词(OOV)处理之间取得了平衡。
训练数据准备。使用 JSONL 格式的预训练语料,每条数据是一段由 <|im_start|> 和 <|im_end|> 包裹的文本片段:
# 数据格式示例(pretrain_hq.jsonl 中的一条)
{
"text": "<|im_start|>鉴别一组中文文章的风格和特点...<|im_end|> <|im_start|>好的,现在帮我查一下今天的天气...<|im_end|>"
}使用 HuggingFace tokenizers 库训练 BPE 分词器。该库底层由 Rust 实现,支持多线程加速:
from tokenizers import Tokenizer, models, trainers, pre_tokenizers
import json
def train_tokenizer(data_path, vocab_size=6400, save_dir="tokenizer"):
"""从 JSONL 语料训练 BPE 分词器"""
tokenizer = Tokenizer(models.BPE())
tokenizer.pre_tokenizer = pre_tokenizers.ByteLevel(add_prefix_space=False)
# 定义特殊 Token
special_tokens = [
"<|im_start|>", "<|im_end|>",
"<s>", "</s>", "<unk>",
]
trainer = trainers.BpeTrainer(
vocab_size=vocab_size,
special_tokens=special_tokens,
show_progress=True,
)
# 构建文本迭代器
def text_iterator():
with open(data_path, "r", encoding="utf-8") as f:
for line in f:
yield json.loads(line)["text"]
tokenizer.train_from_iterator(text_iterator(), trainer=trainer)
tokenizer.save(f"{save_dir}/tokenizer.json")
print(f"词表大小: {tokenizer.get_vocab_size()}")
return tokenizer训练完成后,验证编解码的一致性:
test_text = "<|im_start|>system\n你是一个优秀的聊天机器人<|im_end|>"
encoded = tokenizer.encode(test_text)
decoded = tokenizer.decode(encoded.ids)
assert decoded == test_text, "编解码不一致!"
print(f"词表长度: {tokenizer.get_vocab_size()}") # 6400
print(f"编码长度: {len(encoded.ids)}") # 约 42 个 token词表大小的选择是一个关键的工程决策。对于 26M 的小模型,6400 的词表是合理的——词表过大会导致 Embedding 层参数占比过高(例如 50000 词表 × 512 维 = 25.6M,几乎占满所有参数)。下表对比了不同规模模型的词表选择:
| 模型规模 | 典型词表大小 | Embedding 参数占比 |
|---|---|---|
| 26M (MiniMind-Small) | 6,400 | ~10% |
| 125M (GPT-3 Small) | 50,257 | ~30% |
| 7B (LLaMA-2) | 32,000 | ~3% |
| 72B (Qwen2) | 151,936 | <1% |
此外,还需要编写 tokenizer_config.json 来配置聊天模板(Chat Template)。聊天模板使用 Jinja2 语法,定义了如何将多轮对话的消息列表转换为模型能理解的单一字符串。其核心格式为 <|im_start|>角色\n内容<|im_end|>,与 ChatML 格式一致。
Step 2:数据准备
大模型训练涉及多种数据格式,不同训练阶段的需求截然不同。
预训练数据(PretrainDataset)。核心任务是"预测下一个 token",无需区分角色:
from torch.utils.data import Dataset
class PretrainDataset(Dataset):
"""自回归预训练数据集:将连续文本切分为固定长度"""
def __init__(self, data_path, tokenizer, max_length=512):
self.tokenizer = tokenizer
self.max_length = max_length
self.samples = []
with open(data_path, "r") as f:
for line in f:
text = json.loads(line)["text"]
token_ids = tokenizer.encode(text).ids
# 将长文本切分为 max_length 的片段
for i in range(0, len(token_ids) - max_length, max_length):
self.samples.append(token_ids[i : i + max_length + 1])
def __getitem__(self, idx):
ids = self.samples[idx]
X = torch.tensor(ids[:-1], dtype=torch.long) # 输入
Y = torch.tensor(ids[1:], dtype=torch.long) # 标签(右移一位)
return X, YSFT 数据(SFTDataset)。核心区别在于 Loss Mask——只对 Assistant 的回复部分计算损失,忽略 User 的提问和系统提示:
class SFTDataset(Dataset):
"""有监督微调数据集:只在 assistant 回复部分计算 loss"""
def __init__(self, data_path, tokenizer, max_length=512):
self.tokenizer = tokenizer
self.max_length = max_length
self.data = [json.loads(l) for l in open(data_path)]
# 预计算 assistant 头部标记的 token id 序列
self.assistant_bos = tokenizer.encode("<s>assistant").ids
def __getitem__(self, idx):
conversations = self.data[idx]["conversations"]
# 使用 chat_template 将多轮对话拼接为字符串
prompt = self.tokenizer.apply_chat_template(conversations)
input_ids = self.tokenizer.encode(prompt).ids[:self.max_length]
# 生成 loss mask:只在 assistant 回复部分标记为 1
loss_mask = self._generate_loss_mask(input_ids)
X = torch.tensor(input_ids[:-1], dtype=torch.long)
Y = torch.tensor(input_ids[1:], dtype=torch.long)
mask = torch.tensor(loss_mask[1:], dtype=torch.long)
return X, Y, mask
def _generate_loss_mask(self, input_ids):
"""扫描序列,找到每段 assistant 回复的起止位置"""
mask = [0] * len(input_ids)
i = 0
while i < len(input_ids):
# 检测 <s>assistant 标记
if input_ids[i:i+len(self.assistant_bos)] == self.assistant_bos:
start = i + len(self.assistant_bos)
# 找到对应的 </s> 结束标记
end = start
while end < len(input_ids) and input_ids[end] != self.tokenizer.eos_token_id:
end += 1
# 标记回复内容及结束符
for j in range(start, min(end + 1, len(input_ids))):
mask[j] = 1
i = end + 1
else:
i += 1
return maskSFT 的 Mask 设计直觉:我们希望模型学会"怎么回答",而不是"怎么提问"。如果把用户的提问也纳入 Loss 计算,模型会分散精力去模拟用户的说话方式,反而影响回答质量。
Step 3:预训练(Pretrain)
预训练是大模型获取通用语言能力的基础。模型通过海量文本学习"下一个词预测"任务,逐步掌握语法、常识和推理模式。
模型架构。我们采用类 LLaMA 的 Decoder-only Transformer,包含以下核心组件:
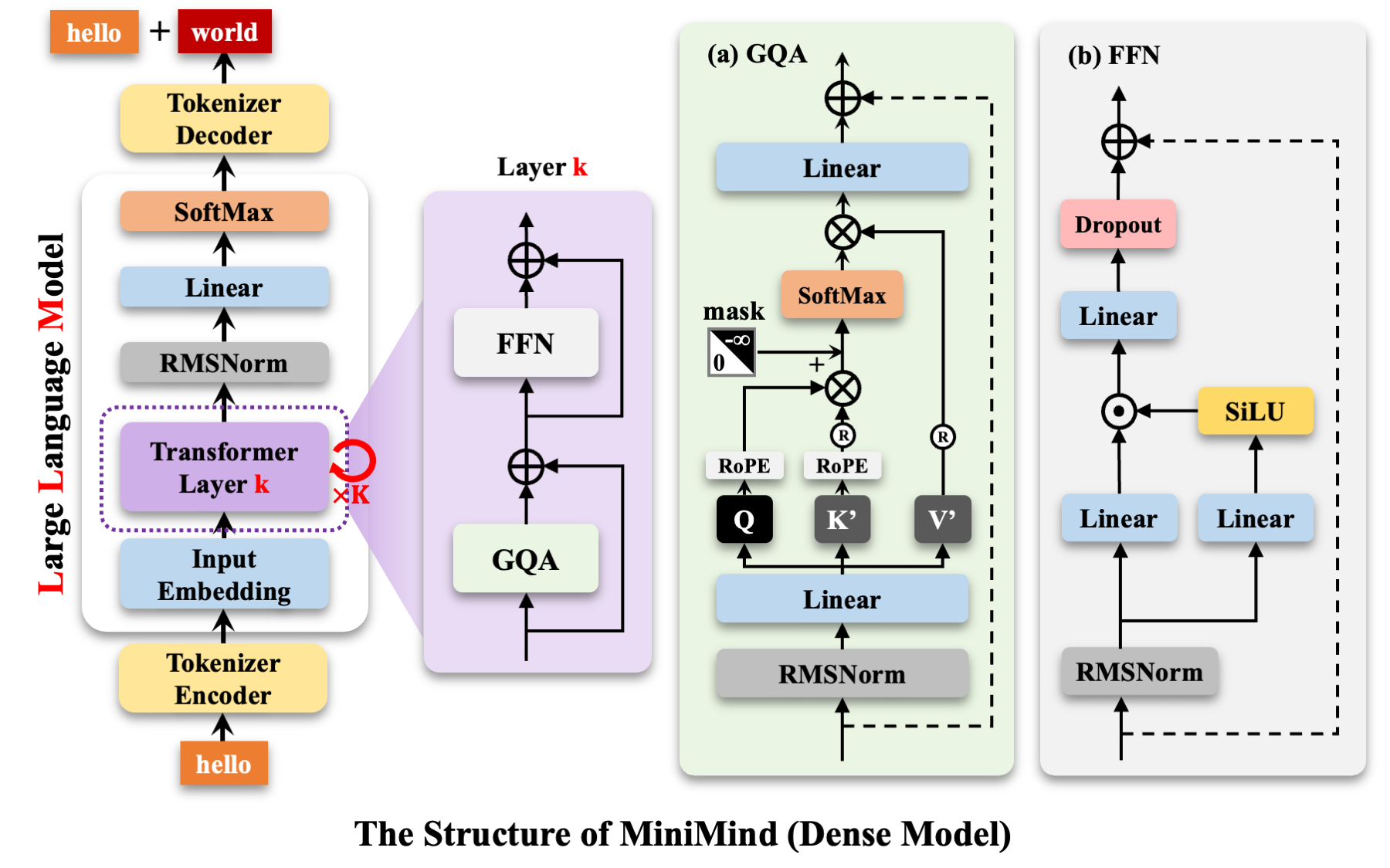
- RMSNorm:比 LayerNorm 更简洁的归一化方式,省略了减均值的步骤
- RoPE:旋转位置编码,通过旋转向量的方式注入位置信息
- SwiGLU:门控前馈网络,使用 SiLU 激活的门控机制筛选特征
- GQA:分组查询注意力,多个 Query 共享一组 KV,降低显存占用
GPT-3 论文中给出了不同参数规模模型的典型配置,可作为参考:
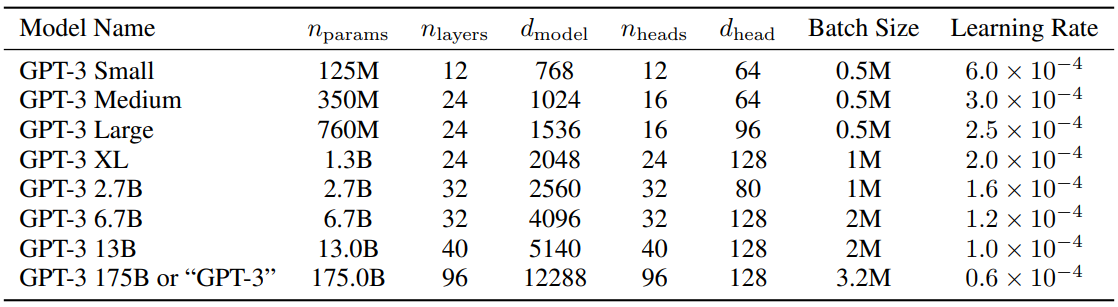
对于 26M 的小模型,典型配置为:8 层 Transformer、隐藏维度 512、8 个注意力头、4 个 KV 头(GQA)。
训练脚本核心逻辑。以下是预训练循环的关键代码:
import torch
import math
from torch.cuda.amp import autocast, GradScaler
def get_lr(current_step, total_steps, lr_max, warmup_steps=1000):
"""线性预热 + 余弦退火 + 最小学习率"""
if current_step < warmup_steps:
return lr_max * current_step / warmup_steps
progress = (current_step - warmup_steps) / (total_steps - warmup_steps)
return lr_max / 10 + 0.5 * lr_max * (1 + math.cos(math.pi * progress))
def pretrain(model, loader, optimizer, epochs=1, lr=5e-4, device="cuda"):
scaler = GradScaler(enabled=True) # fp16 混合精度防梯度下溢
total_steps = len(loader) * epochs
step = 0
for epoch in range(epochs):
model.train()
for X, Y in loader:
X, Y = X.to(device), Y.to(device)
# 动态调整学习率
lr_now = get_lr(step, total_steps, lr)
for pg in optimizer.param_groups:
pg["lr"] = lr_now
with autocast(dtype=torch.float16):
logits = model(X).logits
loss = torch.nn.functional.cross_entropy(
logits.view(-1, logits.size(-1)), Y.view(-1)
)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
step += 1学习率策略。"线性预热 + 余弦退火 + 10% 最小学习率"是当前大模型训练的黄金策略:
- 预热阶段(前 ~5% 的步数):从接近零线性上升到目标学习率,避免训练初期梯度爆炸
- 余弦衰减阶段:从峰值平滑衰减,但不降到零,保留 10% 的"底噪"让模型在后期仍能微调
混合精度训练。使用 GradScaler 是 fp16 训练的必备组件。fp16 能表示的最小正数约为
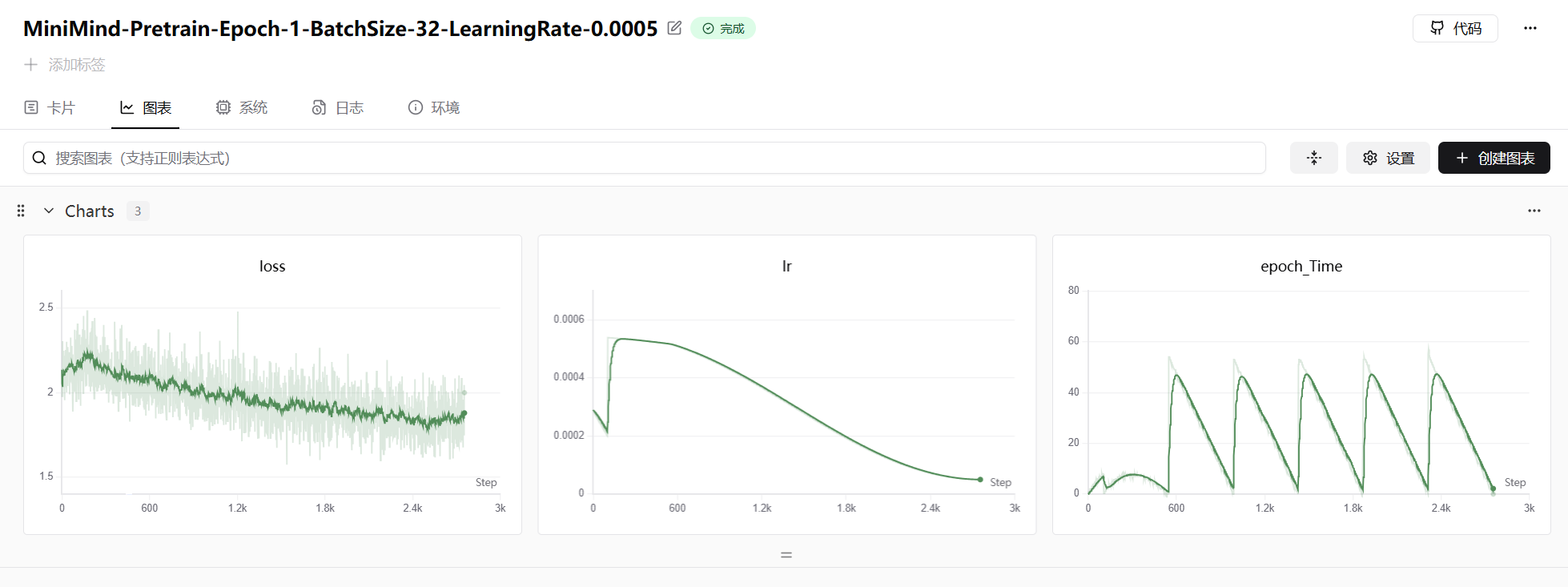
预训练曲线如下图所示,loss 从 2.5 左右稳步下降,学习率呈现典型的余弦退火形状:
Step 4:有监督微调(SFT)
预训练后的模型具备了"补全文本"的能力,但还不会"对话"。SFT 阶段的目标是让模型学会按照指令格式回答问题。
SFT 与 Pretrain 的核心区别在于 Loss 的计算方式。在 Pretrain 中,所有 token 都参与 loss 计算;而在 SFT 中,只计算 assistant 回复部分的 loss。这通过上一步介绍的 loss_mask 实现:
def sft_train_step(model, X, Y, loss_mask, scaler, optimizer):
with autocast(dtype=torch.float16):
logits = model(X).logits
# 逐 token 计算交叉熵(不聚合)
loss_per_token = torch.nn.functional.cross_entropy(
logits.view(-1, logits.size(-1)), Y.view(-1), reduction="none"
).view(Y.size())
# 只对 assistant 回复部分求平均
loss = (loss_per_token * loss_mask).sum() / loss_mask.sum().clamp_min(1)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
return loss.item()多轮对话的处理。SFT 数据通常包含多轮 user-assistant 交互。_generate_loss_mask 会扫描整个序列,找到每一段 assistant 回复并标记为 1,从而支持多轮对话的训练。
SFT 阶段的 loss 曲线通常波动较大(因为不同对话的难度差异明显),但整体呈下降趋势:
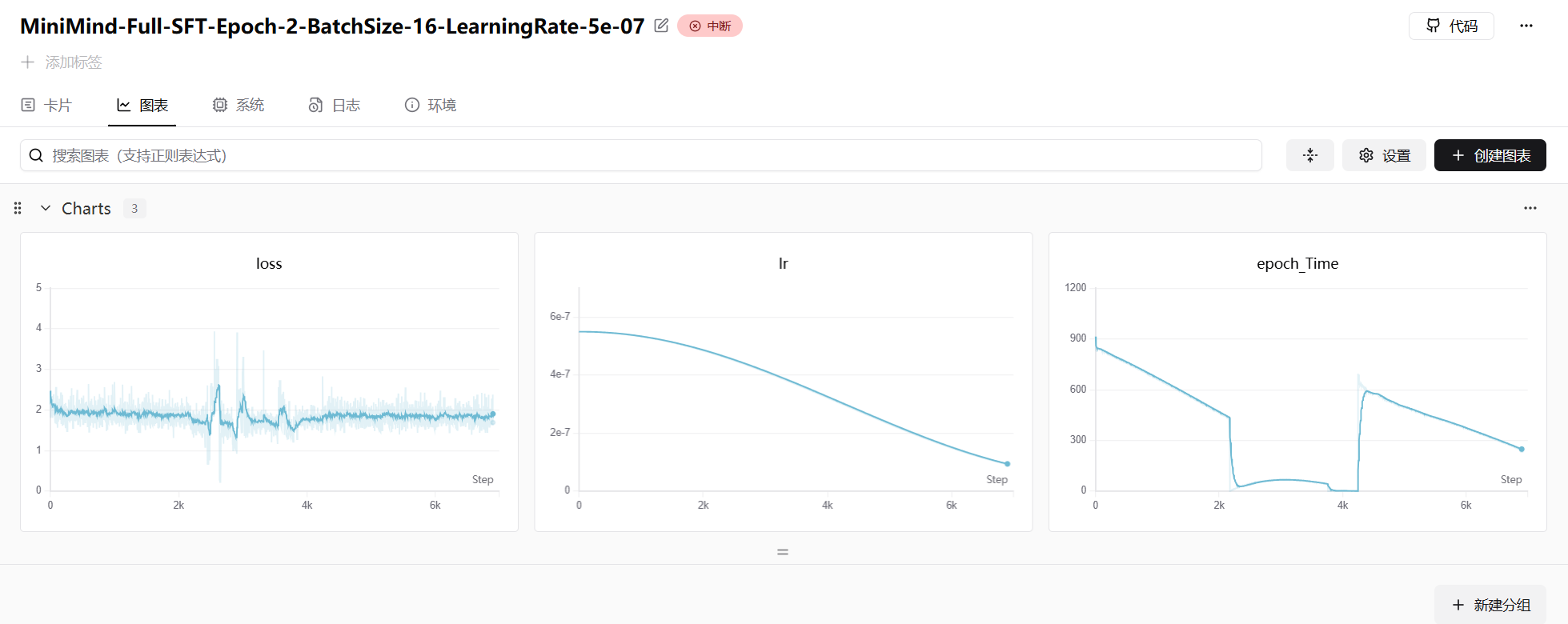
Step 5:LoRA 微调
当我们需要在特定领域数据(如医疗、法律)上微调模型,但又没有足够的计算资源进行全参数微调时,LoRA(Low-Rank Adaptation) 是最优解。
核心思想:大模型的权重更新矩阵
前向传播变为
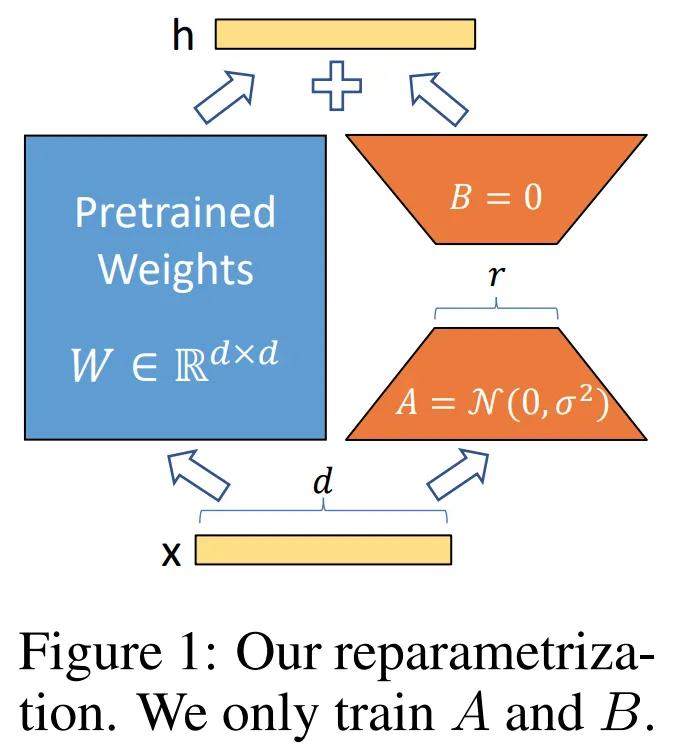
从零实现 LoRA:
import torch.nn as nn
class LoRA(nn.Module):
"""低秩适配器"""
def __init__(self, in_features, out_features, rank=16):
super().__init__()
self.A = nn.Linear(in_features, rank, bias=False)
self.B = nn.Linear(rank, out_features, bias=False)
# A 高斯初始化,B 零初始化 → 初始时 ΔW = 0
nn.init.normal_(self.A.weight, std=0.02)
nn.init.zeros_(self.B.weight)
def forward(self, x):
return self.B(self.A(x))
def apply_lora(model, rank=16):
"""将 LoRA 模块注入模型中所有方阵线性层"""
for name, module in model.named_modules():
if isinstance(module, nn.Linear) and module.weight.shape[0] == module.weight.shape[1]:
lora = LoRA(module.weight.shape[0], module.weight.shape[1], rank=rank)
lora = lora.to(next(module.parameters()).device)
setattr(module, "lora", lora)
original_forward = module.forward
def forward_with_lora(x, orig=original_forward, lo=lora):
return orig(x) + lo(x)
module.forward = forward_with_lora训练时只优化 LoRA 参数:
# 注入 LoRA
apply_lora(model, rank=16)
# 冻结原始参数,只训练 LoRA
for name, param in model.named_parameters():
if "lora" not in name:
param.requires_grad = False
lora_params = [p for n, p in model.named_parameters() if "lora" in n]
optimizer = torch.optim.AdamW(lora_params, lr=1e-4)
# 打印参数统计
total = sum(p.numel() for p in model.parameters())
trainable = sum(p.numel() for p in lora_params)
print(f"总参数: {total:,}, LoRA 参数: {trainable:,}, 占比: {trainable/total*100:.2f}%")
# 输出示例: 总参数: 26,092,032, LoRA 参数: 262,144, 占比: 1.00%LoRA 权重的保存与加载:
def save_lora(model, path):
"""只保存 LoRA 层的参数"""
state_dict = {}
for name, module in model.named_modules():
if hasattr(module, "lora"):
for k, v in module.lora.state_dict().items():
state_dict[f"{name}.lora.{k}"] = v
torch.save(state_dict, path)
def load_lora(model, path):
"""加载 LoRA 参数到已注入 LoRA 的模型"""
state_dict = torch.load(path, map_location="cpu")
for name, module in model.named_modules():
if hasattr(module, "lora"):
lora_state = {
k.replace(f"{name}.lora.", ""): v
for k, v in state_dict.items()
if f"{name}.lora." in k
}
module.lora.load_state_dict(lora_state)LoRA 的训练曲线通常收敛很快(因为参数量极少),几十个 epoch 即可看到明显效果:
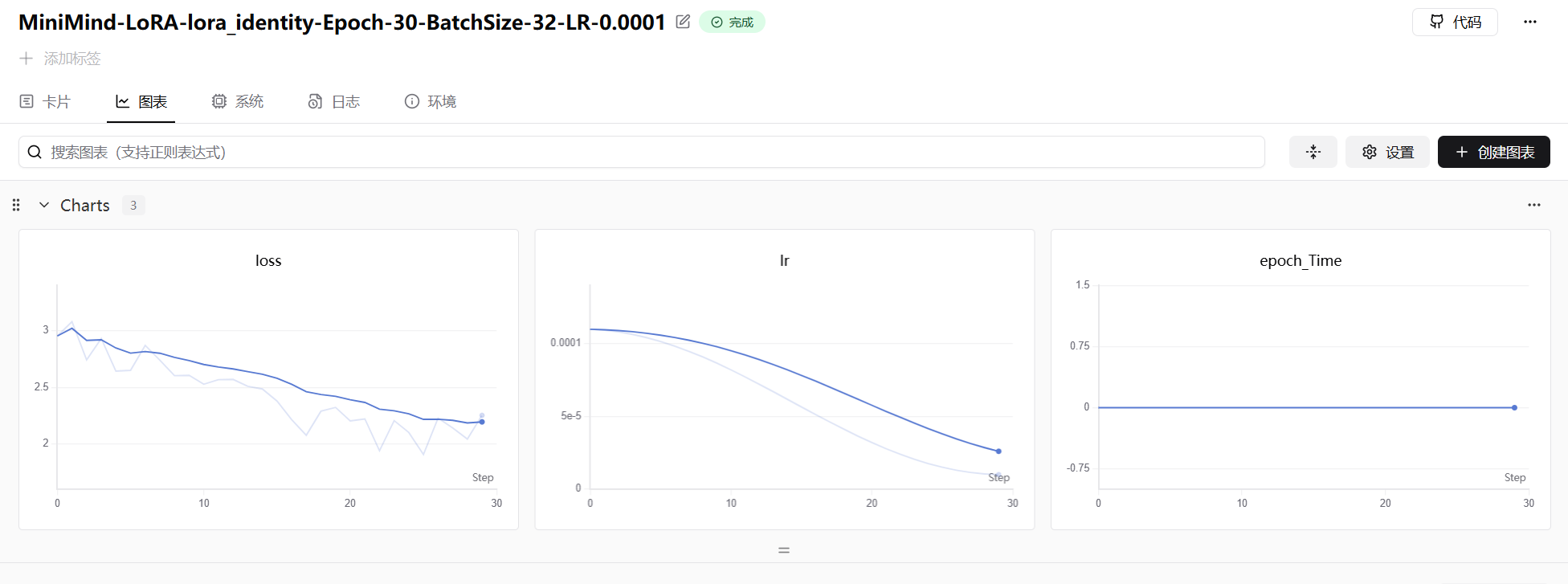
Step 6:强化学习对齐(DPO / PPO / GRPO)
SFT 让模型学会了"怎么回答",但不一定能区分"什么是好的回答"。强化学习对齐(RLHF/RLAIF)的目标是让模型偏好人类认为更好的回答。本步介绍三种主流方案。
6.1 DPO:直接偏好优化
DPO(Direct Preference Optimization) 是最简单的对齐方案——它不需要训练 Reward Model,直接从偏好数据中学习。
给定输入
其中
实现要点:
import torch.nn.functional as F
def dpo_loss(policy_logps, ref_logps, mask, beta=0.1):
"""
计算 DPO 损失
policy_logps, ref_logps: [batch_size, seq_len] 对数概率
mask: [batch_size, seq_len] 有效 token 掩码
假设 batch 前半为 chosen,后半为 rejected
"""
# 长度归一化的平均对数概率
seq_lens = mask.sum(dim=1).clamp_min(1)
policy_avg = (policy_logps * mask).sum(dim=1) / seq_lens
ref_avg = (ref_logps * mask).sum(dim=1) / seq_lens
half = policy_avg.shape[0] // 2
# 当前模型与参考模型的"偏好差距"
pi_diff = policy_avg[:half] - policy_avg[half:]
ref_diff = ref_avg[:half] - ref_avg[half:]
logits = pi_diff - ref_diff
return -F.logsigmoid(beta * logits).mean()长度归一化是一个重要的工程 trick。如果 chosen 和 rejected 回复长度差异很大,累加的 log probability 会因长度本身产生巨大的数值偏差。除以长度后,优化目标变成"平均每个 token 的置信度",训练更稳定。
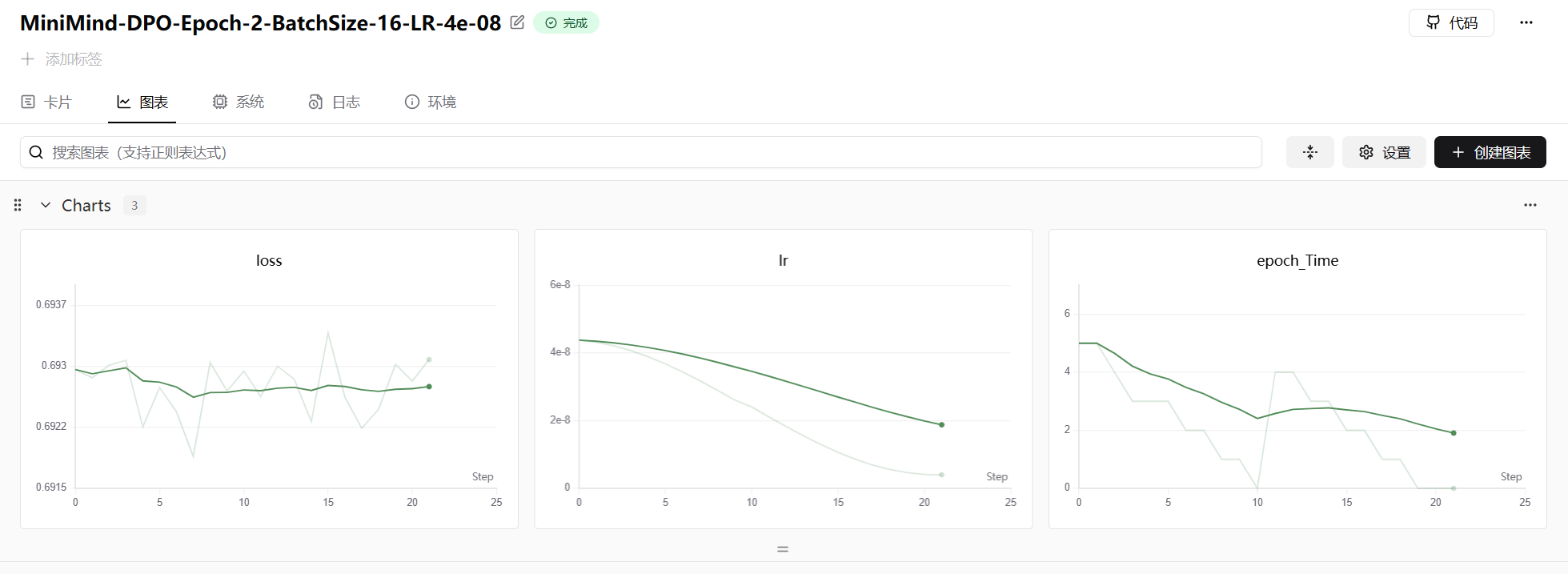
6.2 PPO:近端策略优化
PPO(Proximal Policy Optimization) 是经典的 RLHF 方案,涉及四个模型协作:
| 模型 | 角色 | 是否训练 |
|---|---|---|
| Actor | 生成回复的策略网络 | 是 |
| Critic | 估计状态价值的网络 | 是 |
| Reference | SFT 后的参考模型 | 否(冻结) |
| Reward Model | 对回复质量打分 | 否(冻结) |
PPO 的总损失由三部分组成:
1. 策略损失(Clip Loss):限制每次更新幅度,防止策略崩溃:
其中重要性比率
2. 价值损失:训练 Critic 准确估计奖励:
3. KL 散度惩罚:防止 Actor 偏离 Reference 太远(Reward Hacking):
def ppo_loss(actor_logp, old_logp, ref_logp, advantages, values, rewards,
clip_eps=0.1, vf_coef=0.5, kl_coef=0.02):
"""计算 PPO 的三部分损失"""
# 1. 策略损失
ratio = torch.exp(actor_logp - old_logp)
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - clip_eps, 1 + clip_eps) * advantages
policy_loss = -torch.min(surr1, surr2).mean()
# 2. 价值损失
value_loss = F.mse_loss(values, rewards)
# 3. KL 惩罚
kl_penalty = (actor_logp - ref_logp).mean()
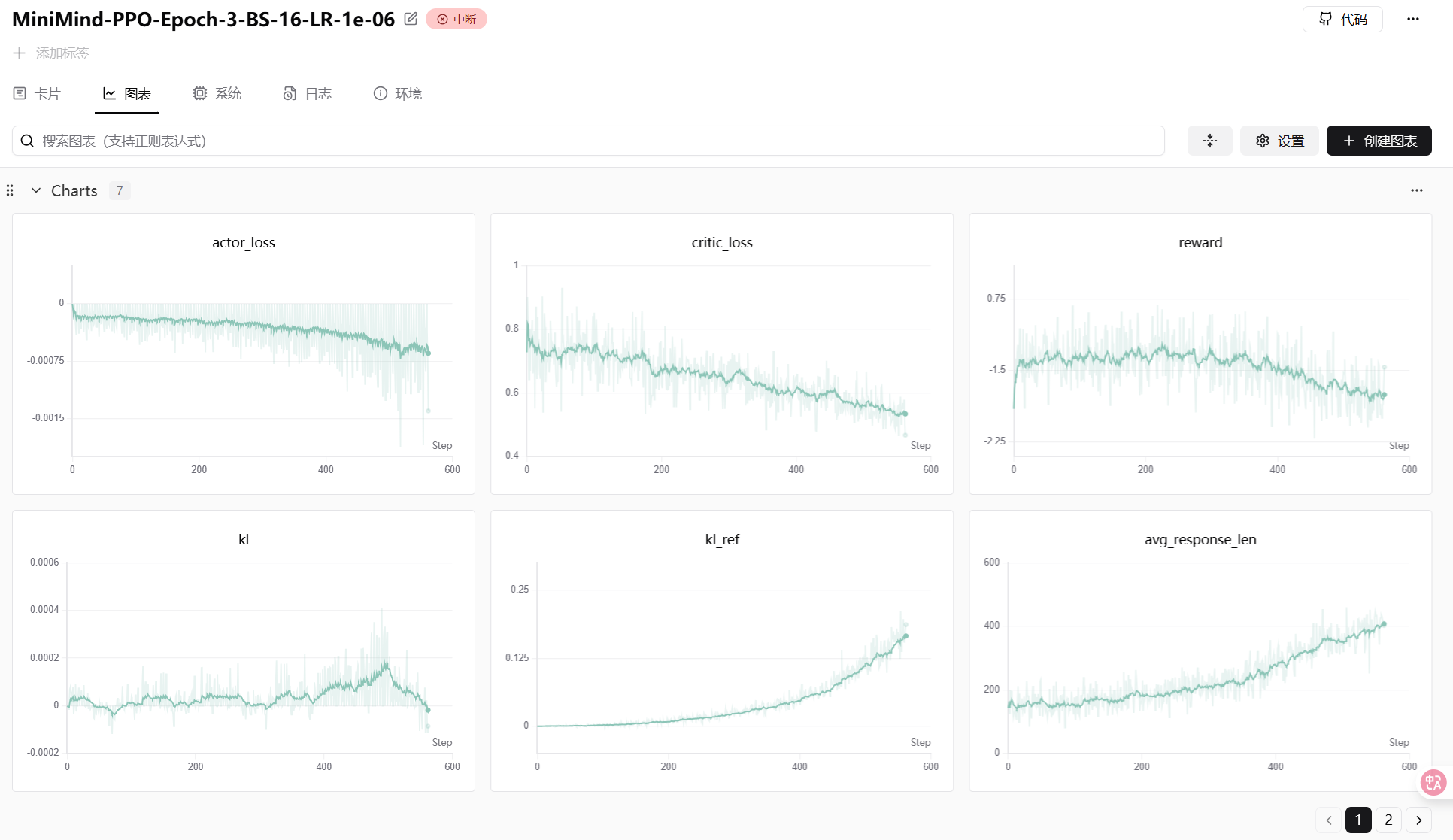
return policy_loss + vf_coef * value_loss + kl_coef * kl_penaltyPPO 训练曲线包含多个指标——actor loss、critic loss、reward、KL 散度等,需要综合观察:
6.3 GRPO:组相对策略优化
GRPO(Group Relative Policy Optimization) 是 DeepSeek 提出的 PPO 简化版本,核心改进是去掉了 Critic 模型,用组内采样的统计量替代价值基线。
对同一个 Prompt
KL 散度使用 Schulman 估计器的近似形式:
def grpo_loss(logp, ref_logp, rewards, num_generations, beta=0.1):
"""
GRPO 损失函数
logp: [batch_size, seq_len] 当前策略对数概率
rewards: [batch_size] 每个回复的奖励
"""
# 组内标准化计算优势
grouped = rewards.view(-1, num_generations) # [num_prompts, G]
mean_r = grouped.mean(dim=1, keepdim=True)
std_r = grouped.std(dim=1, keepdim=True).clamp_min(1e-4)
advantages = ((rewards.unsqueeze(1) - mean_r.repeat_interleave(num_generations, 0))
/ std_r.repeat_interleave(num_generations, 0)).squeeze(1)
# KL 散度(Schulman 近似)
kl_diff = ref_logp - logp
per_token_kl = torch.exp(kl_diff) - kl_diff - 1
# 策略梯度 + KL 惩罚
# 注意:torch.exp(logp - logp.detach()) 在单次更新时等于 1,但保留梯度
ratio = torch.exp(logp - logp.detach())
per_token_loss = -(ratio * advantages.unsqueeze(1) - beta * per_token_kl)
return per_token_loss.mean()GRPO vs PPO 对比:
| 特性 | PPO | GRPO |
|---|---|---|
| 需要 Critic 模型 | 是 | 否 |
| 优势基线 | 组内均值(统计量) | |
| 每个 Prompt 采样数 | 1 | |
| 显存占用 | 高(4 个模型) | 较低(3 个模型) |
| 训练稳定性 | 依赖 Critic 质量 | 组统计天然稳定 |
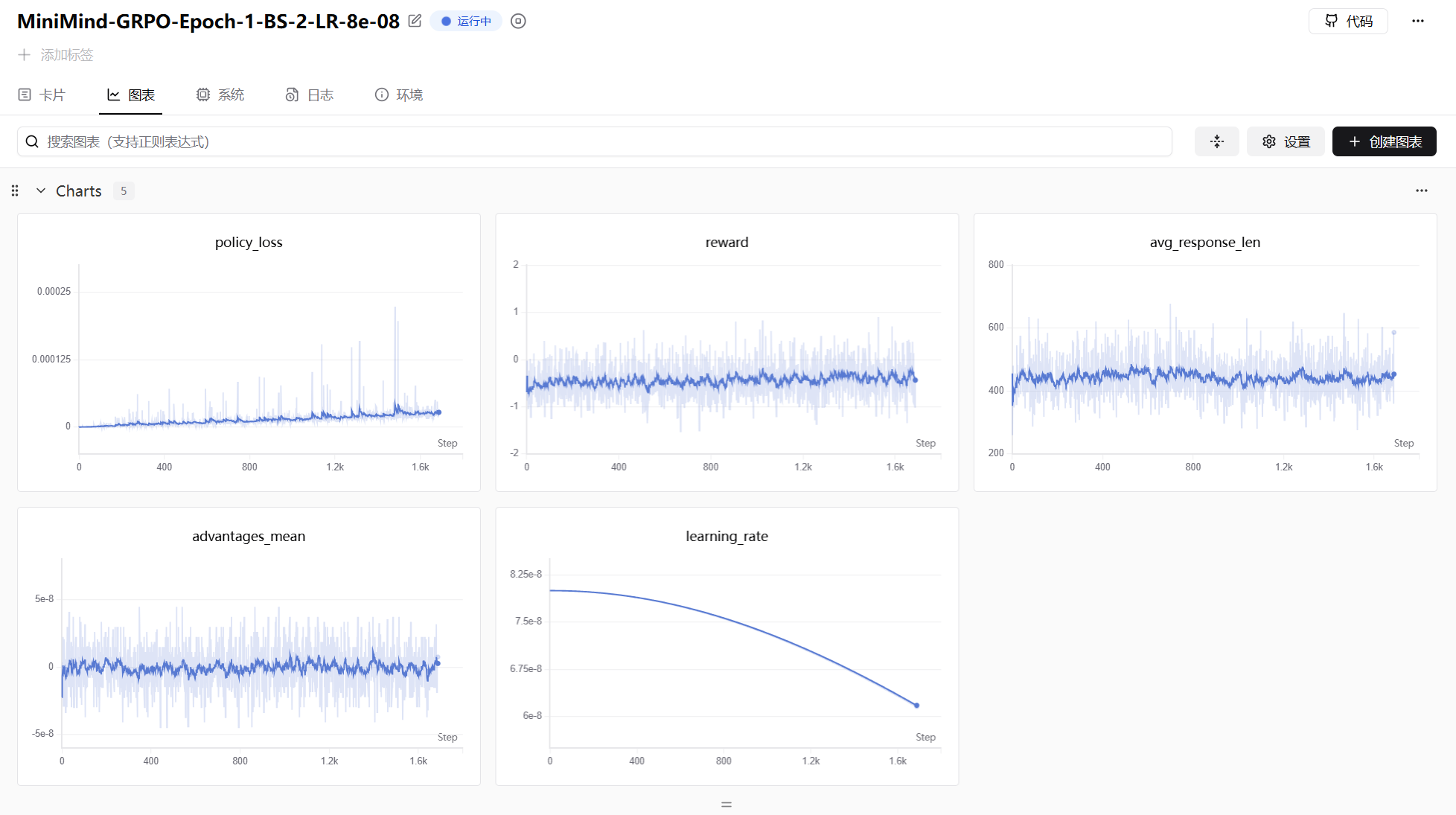
GRPO 的训练曲线中,policy_loss 通常波动较大但 reward 稳步上升:
Step 7:推理模型蒸馏
最后一步是知识蒸馏——将大模型(Teacher)的知识压缩到小模型(Student)中。在推理模型场景下,这尤其重要:我们希望小模型也能学会"先思考再回答"的推理链模式(<think>...</think><answer>...</answer>)。
蒸馏损失函数。总损失由交叉熵损失和 KL 蒸馏损失加权组成:
其中 KL 蒸馏损失使用温度
温度
def distillation_loss(student_logits, teacher_logits, labels, mask,
temperature=2.0, alpha=0.5):
"""知识蒸馏损失:交叉熵 + KL 散度"""
# 1. 硬标签交叉熵损失
ce_loss = F.cross_entropy(
student_logits.view(-1, student_logits.size(-1)),
labels.view(-1), reduction="none"
).view(labels.size())
ce_loss = (ce_loss * mask).sum() / mask.sum().clamp_min(1)
# 2. 软标签蒸馏损失
student_log_probs = F.log_softmax(student_logits / temperature, dim=-1)
teacher_probs = F.softmax(teacher_logits / temperature, dim=-1)
kl = F.kl_div(student_log_probs, teacher_probs, reduction="none").sum(dim=-1)
kl_loss = (kl * mask).sum() / mask.sum().clamp_min(1)
kl_loss = temperature ** 2 * kl_loss
return alpha * ce_loss + (1 - alpha) * kl_loss推理标签加权是蒸馏推理模型的特有技巧。对 <think>、</think>、<answer>、</answer> 等控制思维链起止的特殊 token,将其 loss 权重提高 10 倍,强迫模型精准预测何时开始/结束思考:
def weighted_reasoning_loss(loss_per_token, labels, loss_mask, special_token_ids, weight=10):
"""对推理标签加权的损失计算"""
flat_labels = labels.view(-1)
flat_mask = loss_mask.view(-1).float()
mask_sum = flat_mask.sum() # 在加权前计算分母
# 找到特殊 token 的位置,将 mask 权重提高
sp_ids = torch.isin(flat_labels, torch.tensor(special_token_ids, device=labels.device))
flat_mask[sp_ids] = weight
flat_mask = flat_mask.view(labels.size())
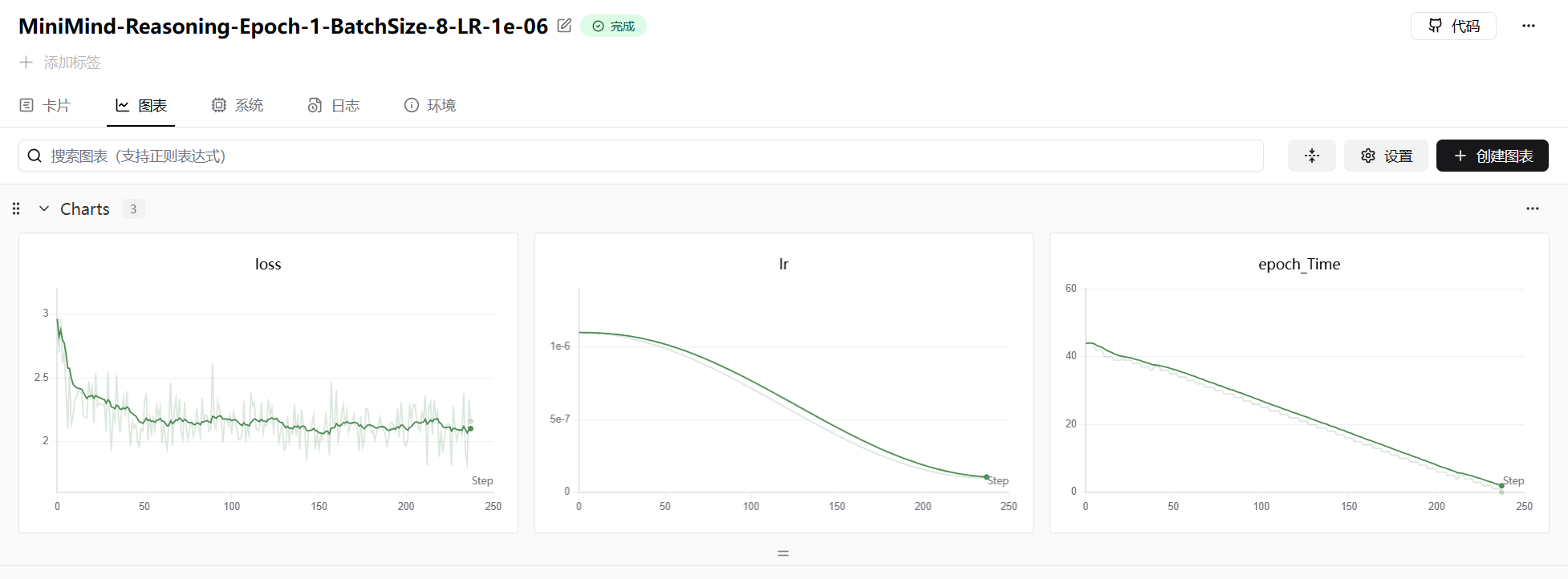
return (loss_per_token * flat_mask).sum() / mask_sum.clamp_min(1)蒸馏推理模型的训练曲线通常收敛较快,因为教师模型提供了强监督信号:
工程实践要点
走完上述七步之后,有几个贯穿全流程的工程经验值得总结:
1. 断点续训。大模型训练经常中断(GPU 故障、显存溢出等)。使用 SkipBatchSampler 配合 batch_sampler 参数创建 DataLoader,可以在恢复时精确跳过已训练的 batch,保证学习率、日志和训练进度完美连续。
2. DDP 多卡训练。在使用 DistributedDataParallel 时,需要将 RoPE 的预计算表(freqs_cos / freqs_sin)排除在同步范围之外。这两个 buffer 在所有 GPU 上完全相同,但由于每张卡的序列长度可能不同(动态 padding),DDP 尝试同步时会因形状不匹配而报错:
model._ddp_params_and_buffers_to_ignore = {"freqs_cos", "freqs_sin"}3. 混合精度的选择。fp16 需要搭配 GradScaler 使用;bfloat16 则不需要(其指数范围与 fp32 相同),但 bfloat16 需要 Ampere 架构及以上的 GPU(如 A100、RTX 3090)。
4. 权重绑定。在小模型中,Embedding 层和输出投影层(lm_head)共享权重矩阵是常见做法,可以将参数量减少约 10%-15%,同时防止过拟合。
5. 训练数据规模参考。
| 阶段 | 典型数据量 | 数据格式 |
|---|---|---|
| Pretrain | 1-2 GB JSONL | 连续文本 |
| SFT | 7-10 GB JSONL | 多轮对话 |
| DPO | 0.5-1 GB JSONL | chosen/rejected 对 |
| RLHF (PPO/GRPO) | 从 SFT 数据采样 1 万条 | prompt only |
| 蒸馏 | 与 SFT 数据规模相当 | 多轮对话 + 教师 logits |
本节以一个 26M 参数的微型模型为载体,走完了从 Tokenizer 到推理蒸馏的完整七步流程。每一步的核心代码都是自包含的,读者可以在单卡 GPU(如 RTX 3090)上用约 2 小时完成全流程复现。这个"麻雀虽小五脏俱全"的实验,是理解后续章节中更大规模训练技术的最佳起点。