3.4 注意力变体(算法层面)
在 3.2 节中,我们完整推导了缩放点积注意力(SDPA)和多头注意力(MHA)的数学形式。MHA 赋予了 Transformer 强大的表达能力,但也带来了一个实际工程中绑定性极强的代价——KV Cache 的线性膨胀。在自回归生成阶段,模型需要为每一层、每个注意力头缓存所有历史 token 的 Key 和 Value 向量。当模型规模达到百亿参数、上下文长度达到 128K 时,KV Cache 的显存占用可以轻松超过模型参数本身。
本节从算法层面出发,梳理围绕这一瓶颈演化出的注意力变体谱系。我们首先追踪从 MHA 到 MQA、GQA 的"KV 头共享"路线,再深入讲解 DeepSeek-V2 提出的多头潜在注意力(MLA)如何通过"低秩联合压缩"实现更激进的 KV Cache 压缩,最后介绍最新的 Gated Attention 机制如何通过在注意力输出上叠加门控来提升模型的表达力和训练稳定性。
3.4.1 KV Cache:推理瓶颈的根源
在正式讨论注意力变体之前,我们需要明确优化目标——KV Cache 为何成为瓶颈。
回顾自回归生成过程:模型逐个 token 地生成文本。在生成第
KV Cache 的核心思想:由于自回归模型使用因果掩码,历史 token 的 Key 和 Value 在后续步骤中不会改变。因此,我们可以将已经计算好的
但缓存本身需要占用大量显存。设模型有
以一个具体的例子来感受量级:Batch Size = 32,
更关键的是,自回归解码的每一步只做一次矩阵-向量乘法(Batch Size = 1 时),计算量极小,但每步都需要从显存中读取整个 KV Cache。这使得解码过程严重受限于内存带宽(Memory-Bound)而非计算能力(Compute-Bound)。在这种访存瓶颈下,减小 KV Cache 的大小等同于直接提升推理吞吐量。
这一核心矛盾催生了两条优化路线:
- KV 头共享:减少 KV 头的数量(MQA → GQA)。
- 低秩压缩:将 KV 投影到低维潜在空间(MLA)。
接下来我们逐一展开。
3.4.2 从 MHA 到 MQA 再到 GQA:KV 头共享路线
多头注意力(MHA)回顾
标准 MHA 中,每个注意力头
其中
多查询注意力(MQA)
Shazeer(2019)在论文 Fast Transformer Decoding: One Write-Head is All You Need 中提出了一个极其简洁的想法:所有 Query 头共享同一份 Key 和 Value。
其中
MQA 的推理提速效果显著,但代价也很明显:所有头被迫使用相同的 K 和 V 来计算注意力,注意力子空间的多样性大幅下降。在大规模模型上,这种表达能力的损失会反映在下游任务的性能退化上。
分组查询注意力(GQA)
Ainslie 等人(2023)在论文 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints 中提出了折中方案——将 Query 头分为若干组,每组共享一份 KV 头。
设 KV 头数为
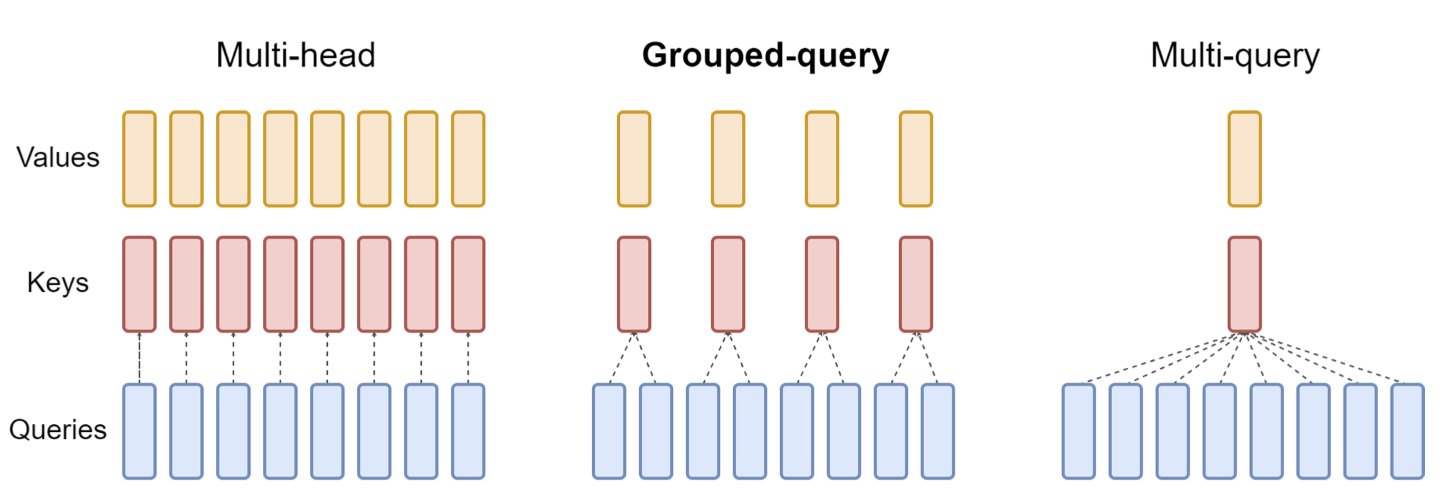
图 3-8:MHA、GQA 与 MQA 的结构对比。左侧为标准 MHA,每个 Query 头拥有独立的 Key 和 Value 头。中间为 GQA,将 Query 头分组,每组共享一对 KV 头。右侧为 MQA,是 GQA 在
GQA 提供了一个灵活的旋钮:
时退化为标准 MHA(无压缩)。 时退化为 MQA(最大压缩)。 - 实践中
取 的某个因子(如 8 头 Query / 2 头 KV),在性能损失极小的情况下获得接近 MQA 的推理加速。
GQA 已成为当前主流大语言模型的标准配置——LLaMA 2/3、Mistral、Qwen 等均采用 GQA。然而,无论是 MQA 还是 GQA,其本质都是对 KV 空间施加结构化约束(强制不同头共享完全相同的 K 和 V),这在信息论意义上并非最优的压缩策略。
下表总结了三种机制在 KV Cache 上的开销对比:
| 机制 | 每 token 缓存量 | 相对 MHA 的压缩比 | 代表模型 |
|---|---|---|---|
| MHA | 1x | GPT-3, BERT | |
| GQA | LLaMA 2/3, Mistral, Qwen | ||
| MQA | PaLM, Falcon |
表 3-4:MHA、GQA、MQA 的 KV Cache 对比。
3.4.3 多头潜在注意力(MLA):低秩压缩路线 [必读]
GQA 的压缩策略是"减少 KV 头数量",但每个 KV 头仍然保持完整的
MLA 的推导包含三个关键阶段,每个阶段解决一个核心问题。我们依次展开。
Phase 1:低秩联合压缩——从高维 KV 到低维潜在向量 [必读]
数学动机。 从线性代数的角度看,GQA 本质上是一种特殊的结构化低秩近似——它强制同组内的不同头使用完全相同的 K 和 V 向量。如果放宽这种结构化约束,使用一般的线性变换,能在同等缓存量下提供更优的表达能力。
基于奇异值分解(SVD)和 Eckart-Young-Mirsky 定理,对于任意矩阵
具体做法。 MLA 引入一个共享的低维潜在向量(latent vector)
其中
其中
此时的矛盾。 如果按照上述公式直接计算,我们仍然需要将
要让这个低秩分解真正发挥作用,我们需要一种方法使得推理时只缓存低维的
Phase 2:矩阵吸收——推理时无需还原高维 KV [必读]
MLA 最精妙的代数技巧在于利用矩阵乘法的结合律(associativity),将上采样矩阵从 KV 端转移到 Query 端和 Output 端,使得推理时直接对低维的
处理 Attention Score。 考虑第
代入低秩展开式
关键观察:
推理时,Query 的计算等效为
处理 Value 聚合。 同理,第
阶段性结论。 通过矩阵吸收,推理时我们只需要缓存
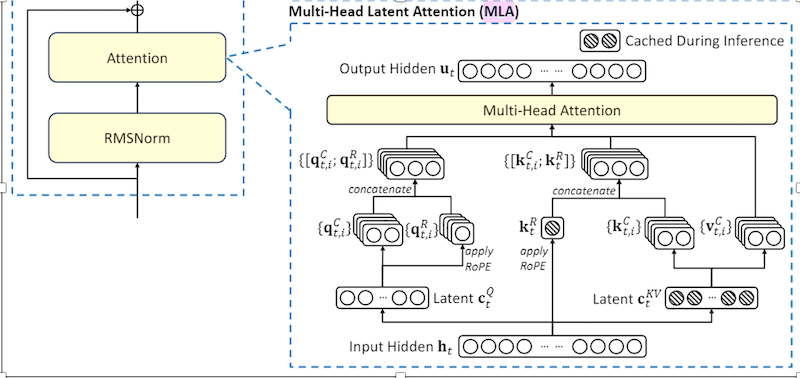
图 3-9:MLA 的完整架构。底部输入隐状态
Phase 3:解耦 RoPE——兼容位置编码的矩阵吸收 [必读]
Phase 2 的矩阵吸收技巧在引入旋转位置编码(RoPE,参见 3.3 节)时会失效。
RoPE 是一种依赖于绝对位置
展开后得到:
利用正交性
矛盾所在:位置相关的动态矩阵
MLA 的解决方案:解耦内容与位置。 将 Query 和 Key 各自拆分为两个独立的部分——内容部分(不含 RoPE,可进行矩阵吸收)和位置部分(含 RoPE,单独计算)。
新增一个专用于承载 RoPE 的维度
Query 侧:
- 内容部分:
,从 Query 的潜在向量恢复,不施加 RoPE。 - 位置部分:
,施加 RoPE,所有头共享。
Key 侧:
- 内容部分:
,不施加 RoPE。 - 位置部分:
,施加 RoPE,所有头共享。
注意力分数的计算(含缩放因子
通过这种解耦:
- 内容项完全遵循 Phase 2 的结合律,推理时只需缓存
。 - 位置项需要额外缓存所有头共享的
,代价极小。
因此,MLA 推理阶段每个 token 需要缓存的内容为:
每 token 缓存量 =
DeepSeek-V2 的具体参数与 57 倍压缩
以 DeepSeek-V2 的实际配置为例,量化 MLA 的压缩效果:
| 参数 | 符号 | 值 |
|---|---|---|
| 隐藏层维度 | 5120 | |
| 注意力头数 | 128 | |
| 每头维度 | 128 | |
| KV 压缩维度 | 512 | |
| RoPE 维度 | 64 |
表 3-5:DeepSeek-V2 中 MLA 的关键超参数。
- 传统 MHA:每 token 缓存
个元素。 - MLA:每 token 缓存
个元素。 - 压缩比:
57 倍。
这个压缩比远超 GQA 所能达到的水平(GQA 即使用
补充说明:Query 的低秩压缩。 MLA 对 Query 也引入了类似的潜在向量
训练与推理的计算模式转换
MLA 在训练和推理阶段采用完全不同的计算路径,这是理解其设计精妙之处的关键:
训练阶段。 采用类似标准 MHA 的并行计算模式,显式地计算出所有头的
推理阶段。 分为三步:
- 离线预处理:将上采样矩阵
吸收到 中得到 ,将 吸收到 中。这些吸收矩阵只需计算一次。 - Prefill 阶段:并行计算所有 token 的
和 ,存入 KV Cache。 - Generation 阶段:形式上退化为等效的 MQA——所有头共享同一份低维 KV Cache(
)。由于不需要重构多头的 KV 向量,访存量极大降低。
这里有一个微妙但重要的权衡:矩阵吸收后,Query 的等效维度变为
3.4.4 Gated Attention:注意力输出的门控调制 [选读]
前面三个小节聚焦于"如何压缩 KV Cache",属于效率优化。接下来我们转向另一个维度——如何提升注意力机制本身的表达能力。
Tiezzi 等人(2025)在论文 Gated Attention 中提出了一种简洁的改进:在 SDPA 输出之后、进入输出投影
其中:
是 SDPA 的输出(即注意力加权后的 Value 聚合结果)。 是当前层的输入隐状态。 是门控层的可学习权重矩阵,每个头拥有独立的 。 为 Sigmoid 激活函数,将门控分数映射到 。 为逐元素乘法。
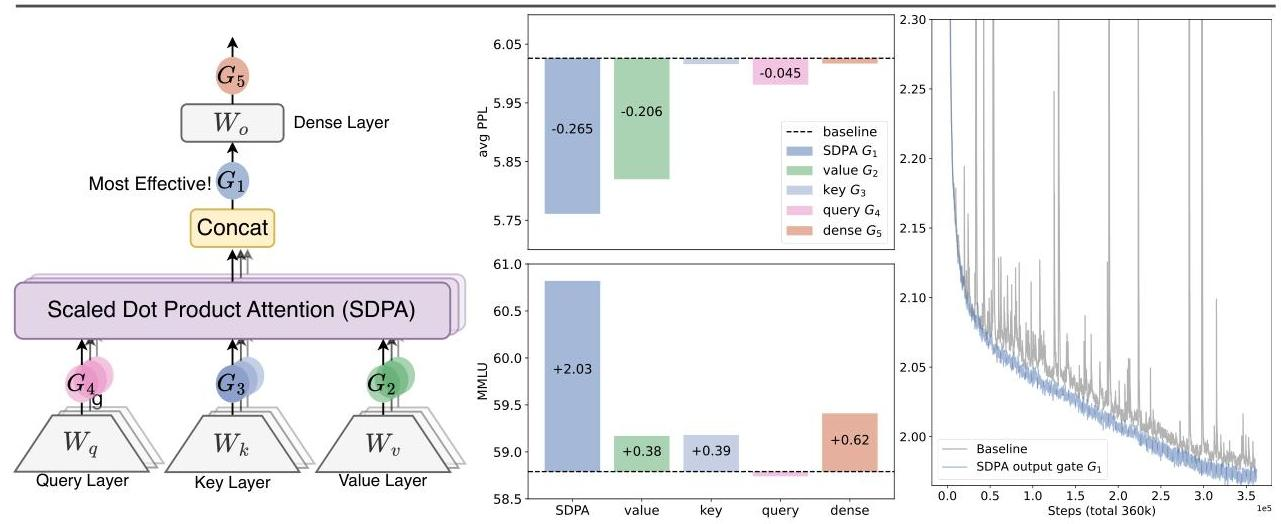
图 3-10:Gated Attention 的结构与实验结果。左图标注了门控可以插入的五个位置(
两大生效机理
机理一:非线性注入。 在标准注意力中,
机理二:输入依赖的稀疏性。 Sigmoid 门控充当了一个动态滤波器。对于每个注意力头的每个维度,门控分数
消除 Attention Sink
Attention Sink(注意力汇聚现象)是指在自回归语言模型中,大量注意力权重会不正常地集中到序列的第一个 token 上,即使第一个 token 在语义上并不重要(通常是 BOS token 或标点符号)。这一现象的根源在于 Softmax 的归一化约束——注意力权重必须求和为 1,当模型对当前位置"无事可做"时,它需要一个"垃圾桶"来放置多余的注意力权重,第一个 token 因为始终可见而成为默认的接收器。
Gated Attention 通过 Sigmoid 门控优雅地解决了这一问题:当门控分数接近 0 时,某些维度的注意力输出被整体抑制。模型不再需要通过扭曲注意力分布来实现"不关注"的效果——它可以在保持注意力分布合理的同时,通过门控来丢弃不需要的信息。实验表明,加入门控后 Attention Sink 现象自然消失,无需任何额外的损失函数约束。
训练稳定性与长文本外推
减少 Loss Spike。 大模型训练中时常出现突发的损失尖峰(Loss Spike),这通常与注意力权重的数值不稳定有关。Gated Attention 的 Sigmoid 门控将输出限制在有界范围内,起到了隐式的梯度裁剪效果,显著减少了训练过程中 Loss Spike 的频率和幅度。实验表明,门控模型可以承受更大的学习率,有利于大规模训练的效率。
长文本外推能力。 得益于 Attention Sink 的消除和动态稀疏性,Gated Attention 在上下文长度外推(例如从 32K 训练长度扩展到 128K 推理长度)时表现优于标准注意力模型。动态稀疏性使得模型在处理超长序列时能更好地过滤无关信息,避免注意力分散到噪声 token 上。
工程开销
Gated Attention 的额外开销很小:每个注意力头增加一个
3.4.5 计算-内存权衡分析
本节讨论的注意力变体,其设计哲学都围绕一个核心问题:在计算量(Compute-Bound)和内存带宽(Memory-Bound)之间如何权衡。
Memory-Bound vs Compute-Bound
GPU 的两大核心资源是算力(FLOPs/s)和内存带宽(Bytes/s)。两者的比值定义了算术强度(Arithmetic Intensity, AI)的均衡点——也称为Roofline 模型中的脊点(Ridge Point):
对于 NVIDIA A100(BF16),峰值算力约 312 TFLOPS,显存带宽约 2 TB/s,因此脊点约 156 FLOPs/Byte。这意味着:如果一个操作每读取 1 Byte 数据的计算量不到 156 FLOPs,它就是 Memory-Bound(带宽受限);否则是 Compute-Bound(算力受限)。
Prefill 阶段(处理完整的 prompt)通常是 Compute-Bound:输入序列长度较长,注意力计算是矩阵-矩阵乘法(GEMM),算术强度高,GPU 算力可以被充分利用。
Generation 阶段(逐 token 生成)通常是 Memory-Bound:每步只有一个新 Query,注意力计算退化为矩阵-向量乘法(GEMV),但需要读取整个 KV Cache。算术强度极低,GPU 的大部分时间在等待数据从显存传输到计算单元。
各注意力变体的权衡位置
| 变体 | 缓存量 / token | Generation 访存量 | Generation 计算量 | 权衡策略 |
|---|---|---|---|---|
| MHA | 基准 | 基准 | 无压缩 | |
| GQA ( | 基准 | 减少 KV 头 | ||
| MQA | 基准 | 极端共享 | ||
| MLA | 以计算换带宽 | |||
| Gated Attn | 同基础机制 | 同基础机制 | 以少量计算换表达力 |
表 3-6:各注意力变体在计算-内存权衡中的定位。
GQA 和 MQA 的策略是"在 Memory-Bound 侧做减法"——通过减少 KV 头来降低缓存和访存量,计算量基本不变。
MLA 的策略更为激进:"在 Memory-Bound 侧做极致减法,在 Compute-Bound 侧做加法"。由于 Generation 阶段是深度 Memory-Bound(算术强度远低于脊点),增加的计算量可以被 GPU 空闲的算力"免费"吸收,而减少的访存量直接转化为吞吐量提升。这就是 MLA "以计算换带宽"能够成功的物理根基。MLA 的高效 GPU kernel 实现(FlashMLA)将在 9.4 节详细讨论。
Gated Attention 走的是另一条路:"以极少量的额外计算换取更好的表达能力"。它不改变 KV Cache 的大小,而是提升单位计算量中注意力机制能提取的信息量。Gated Attention 可以与 GQA 或 MLA 正交组合使用。
实际部署的选型建议
选择哪种注意力变体,取决于部署场景的具体约束:
- 长上下文 + 大 Batch Size:KV Cache 占主导,优先选择 MLA 或激进的 GQA。
- 短上下文 + 低延迟:Prefill 阶段占主导,MLA 的额外计算开销可能不利,GQA 更平衡。
- 训练稳定性优先:Gated Attention 作为即插即用模块可叠加到任何基础注意力机制上。
- 简单工程实现:GQA 的代码改动最小,是 MHA 到高效注意力的最低成本迁移路径。
本节小结
本节系统梳理了注意力机制在算法层面的演进路线:
- KV Cache 是自回归生成的核心瓶颈:其显存占用与序列长度线性增长,解码过程严重 Memory-Bound,减小 KV Cache 直接提升推理吞吐量。
- MQA 和 GQA 通过减少 KV 头数量实现压缩,GQA 在性能与效率之间提供了灵活的平衡,是当前主流方案。
- MLA 开创了低秩压缩路线,通过三阶段推导——低秩联合压缩、矩阵吸收、解耦 RoPE——实现了 57 倍的 KV Cache 压缩,同时保持甚至提升了建模性能。其核心洞察是"以计算换带宽",精准利用了 Generation 阶段 Memory-Bound 的特性。
- Gated Attention 通过在 SDPA 输出后插入 Sigmoid 门控,以极低的额外成本注入非线性和动态稀疏性,消除了 Attention Sink,提升了训练稳定性和长文本外推能力。
- 计算-内存权衡是理解所有注意力变体设计哲学的统一框架:GQA 做"Memory 侧减法",MLA 做"Memory 侧极致减法 + Compute 侧加法",Gated Attention 做"Compute 侧微量加法换表达力"。