23.5 语音大模型
在前面几节中,我们已经看到大模型如何处理文本、图像和视频等模态。然而,语音是人类最自然的交流方式——我们与智能助手对话、收听有声读物、使用实时字幕,这些场景的核心都是让机器"听懂"和"说出"人类语言。语音大模型正是这一领域的前沿方向,它将传统的语音识别(ASR)与语音合成(TTS)技术与大语言模型深度融合,实现了从"模块拼接"到"端到端智能"的跨越。
本节将从语音信号的基础表示出发,依次深入 ASR 和 TTS 两大核心任务的技术演进,最后讨论以 Whisper、VALL-E 和 GPT-4o 为代表的多模态语音大模型如何将语音能力无缝整合进统一的大模型框架。
23.5.1 语音信号基础
在进入模型架构之前,我们需要理解语音数据的基本表示方式。一段语音本质上是一个随时间变化的连续物理信号(声波)。要让神经网络处理它,必须先将其转化为离散的数值序列。
采样与分帧。 麦克风采集到的模拟声波首先经过采样(Sampling)被离散化——按照固定的采样率(通常为 16 kHz,即每秒采集 16000 个样本点)将连续信号转化为数字信号。随后进行分帧(Framing):将连续的采样序列切割为一系列短小的时间窗口(通常为 25 ms),相邻帧之间有 10 ms 的重叠以保证信息的连续性。
声学特征提取。 对每一帧语音,我们提取能够有效表征其声学特性的数值向量,称为声学特征向量(Acoustic Feature Vector)。最常用的两种特征是:
- 梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients, MFCC):模拟人耳对不同频率的非线性感知特性,将频谱映射到梅尔尺度上,通常提取 13-40 维特征
- 梅尔频谱图(Mel-Spectrogram):将短时傅里叶变换(STFT)的结果映射到梅尔滤波器组上,得到一个二维的"时间-频率"热力图,是现代深度学习 TTS 模型最常用的中间表示
经过上述处理,一段原始语音信号被转换为一个特征向量序列:
其中
以下代码展示了如何用 Python 从音频波形中提取梅尔频谱图:
import numpy as np
def compute_mel_spectrogram(
waveform: np.ndarray,
sample_rate: int = 16000,
n_fft: int = 400,
hop_length: int = 160,
n_mels: int = 80,
) -> np.ndarray:
"""从音频波形计算梅尔频谱图(简化实现)。
Args:
waveform: 一维音频信号数组
sample_rate: 采样率 (Hz)
n_fft: FFT 窗口大小(对应 25ms: 16000 * 0.025 = 400)
hop_length: 帧移(对应 10ms: 16000 * 0.01 = 160)
n_mels: 梅尔滤波器数量
Returns:
shape (n_mels, T) 的梅尔频谱图(对数尺度)
"""
# 1. 短时傅里叶变换 (STFT)
num_frames = 1 + (len(waveform) - n_fft) // hop_length
stft_matrix = np.zeros((n_fft // 2 + 1, num_frames))
window = np.hanning(n_fft)
for i in range(num_frames):
start = i * hop_length
frame = waveform[start : start + n_fft] * window
spectrum = np.fft.rfft(frame)
stft_matrix[:, i] = np.abs(spectrum) ** 2 # 功率谱
# 2. 构造梅尔滤波器组
mel_filters = _create_mel_filterbank(sample_rate, n_fft, n_mels)
# 3. 应用滤波器并取对数
mel_spec = mel_filters @ stft_matrix
log_mel_spec = np.log(np.maximum(mel_spec, 1e-10))
return log_mel_spec
def _create_mel_filterbank(sr: int, n_fft: int, n_mels: int) -> np.ndarray:
"""构造梅尔滤波器组矩阵。"""
# Hz 到梅尔的转换
def hz_to_mel(hz):
return 2595.0 * np.log10(1.0 + hz / 700.0)
def mel_to_hz(mel):
return 700.0 * (10.0 ** (mel / 2595.0) - 1.0)
mel_low, mel_high = hz_to_mel(0), hz_to_mel(sr / 2)
mel_points = np.linspace(mel_low, mel_high, n_mels + 2)
hz_points = mel_to_hz(mel_points)
bin_points = np.floor((n_fft + 1) * hz_points / sr).astype(int)
filters = np.zeros((n_mels, n_fft // 2 + 1))
for m in range(n_mels):
left, center, right = bin_points[m], bin_points[m + 1], bin_points[m + 2]
for k in range(left, center):
filters[m, k] = (k - left) / max(center - left, 1)
for k in range(center, right):
filters[m, k] = (right - k) / max(right - center, 1)
return filters23.5.2 语音识别(ASR):让机器听懂人类
自动语音识别(Automatic Speech Recognition, ASR)的目标是将语音信号转换为对应的文本序列。从数学上看,这是一个序列到序列的映射问题:给定声学特征序列

图 23-15:完整的语音交互流水线。语音输入首先经 ASR 转为文本,经语义理解模块生成回复文本,最后由 TTS 合成语音输出。
传统方法:贝叶斯分解与混合模型
根据贝叶斯公式,后验概率可以分解为两个独立的组件:
- 声学模型(Acoustic Model, AM)
:建模"给定某个文本,说出这段语音的概率"。传统方法使用**隐马尔可夫模型(HMM)与高斯混合模型(GMM)**的组合——HMM 捕捉语音的时序动态,GMM 估计每个状态下声学特征的分布 - 语言模型(Language Model, LM)
:建模"文本序列本身出现的概率"。传统方法使用 N-gram 统计模型
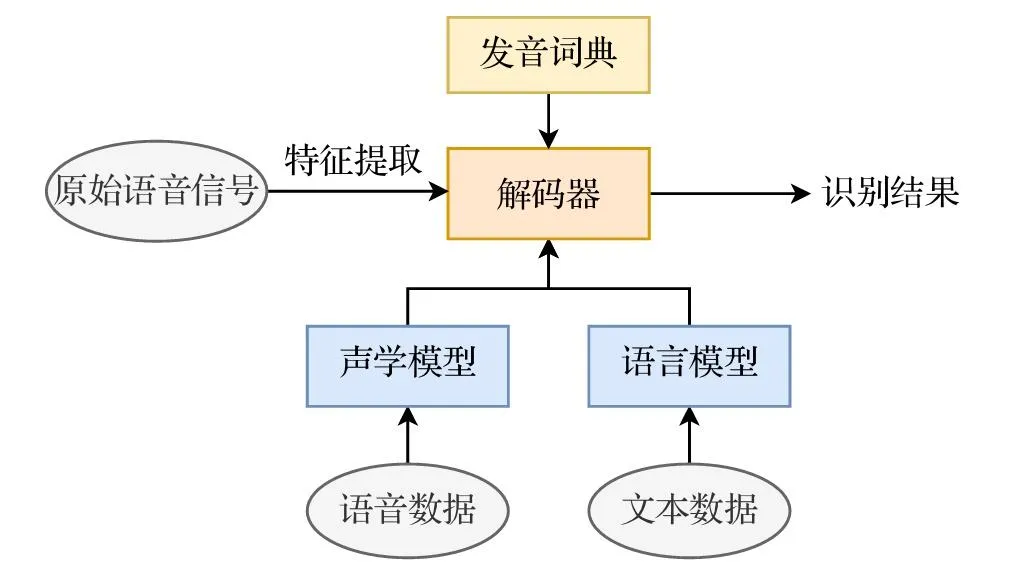
图 23-16:传统 ASR 系统架构。原始语音信号经特征提取后送入解码器,解码器结合声学模型(由语音数据训练)、语言模型(由文本数据训练)和发音词典进行联合解码,输出最终识别结果。
端到端模型:深度学习的革命
深度学习的兴起催生了端到端(End-to-End, E2E)ASR 模型,它们用单一神经网络直接学习从
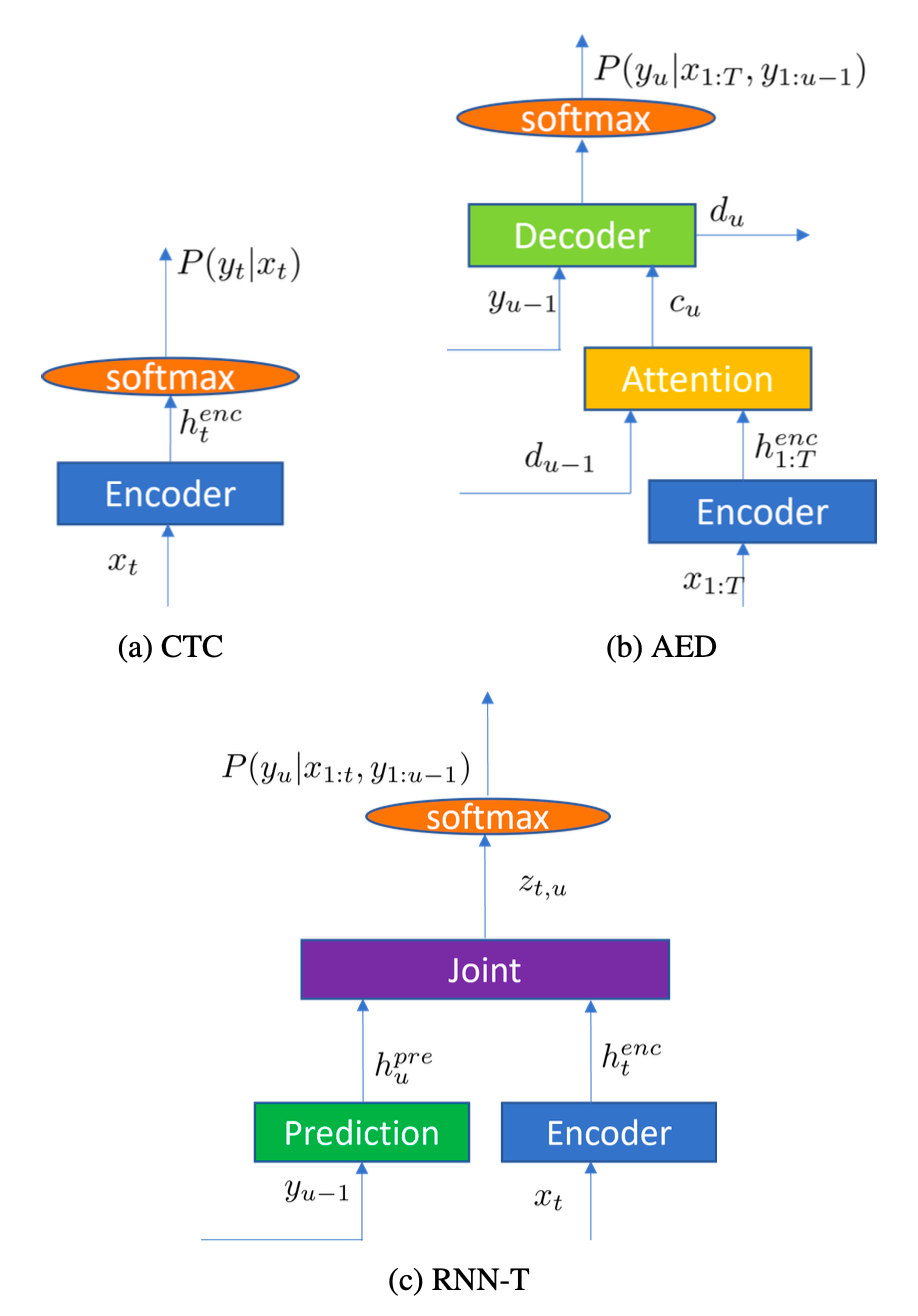
图 23-17:三种主流端到端 ASR 架构对比。(a) CTC:编码器直接对每帧进行分类;(b) AED:编码器-解码器结构,通过注意力机制动态对齐;(c) RNN-T:编码器、预测网络和联合网络协同工作,支持流式识别。
1. 连接时序分类(CTC)。 CTC 引入了一个特殊的"空白"标签
其中
2. 基于注意力的序列到序列模型(AED)。 这类模型采用编码器-解码器结构:编码器将整个语音序列编码为隐藏表示,解码器通过注意力机制在生成每个输出 token 时动态聚焦于编码器输出的不同位置。本质上,它把 ASR 当作一个"翻译"任务——将"语音语言"翻译为"文字语言"。AED 能有效捕捉长距离依赖,但由于需要看到完整输入才能计算注意力权重,不太适合流式场景。
3. 循环神经网络变换器(RNN-T)。 RNN-T 是当前工业界最主流的 E2E 模型,特别适合流式识别。它由三个组件构成:
- 编码器(Encoder):对当前语音帧进行声学编码,输出
- 预测网络(Prediction Network):对已生成的文本历史进行编码,输出
- 联合网络(Joint Network):将声学编码和文本历史编码融合,预测下一个输出 token
联合网络的输出概率为:
RNN-T 的关键优势在于输出不仅依赖当前音频输入,还依赖已生成的文本历史,天然支持因果推断和低延迟处理。
23.5.3 语音合成(TTS):让机器开口说话
语音合成(Text-to-Speech, TTS)是 ASR 的逆过程:将文本转换为自然流畅的语音波形。TTS 的技术演进经历了从规则合成、拼接合成到统计参数合成、再到深度学习端到端模型的长期发展。
两阶段端到端模型
早期端到端 TTS 的主流架构将任务分为两个阶段:声学模型(文本到梅尔频谱图)和神经声码器(梅尔频谱图到波形)。
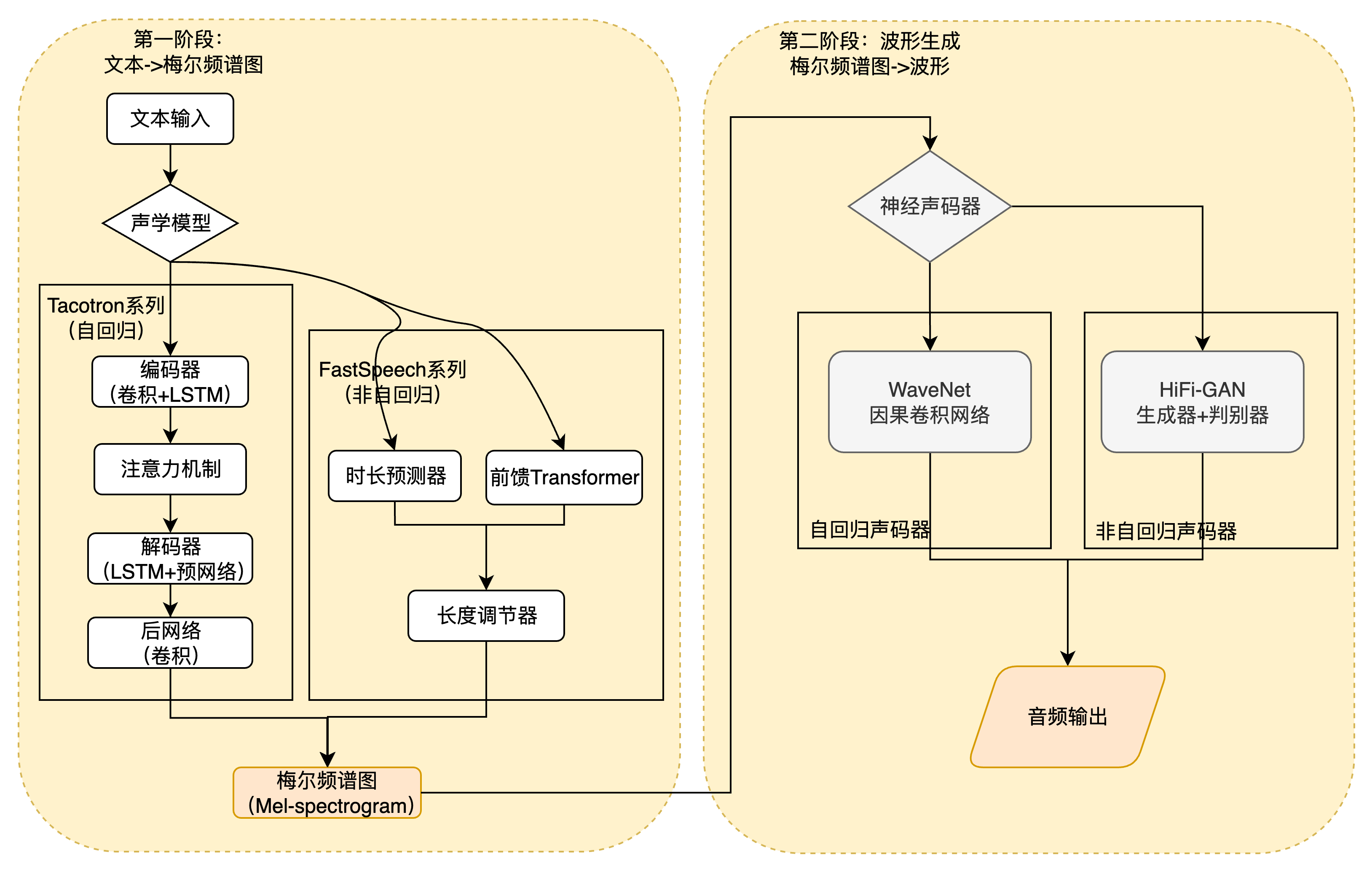
图 23-18:深度学习 TTS 两阶段架构。左侧第一阶段:Tacotron(自回归)和 FastSpeech(非自回归)将文本转为梅尔频谱图;右侧第二阶段:WaveNet(自回归声码器)和 HiFi-GAN(非自回归声码器)将频谱图转为音频波形。
声学模型代表作:
- Tacotron 系列(Google, 2017-2018):采用编码器-解码器结构,通过注意力机制逐帧自回归地生成梅尔频谱图。Tacotron 2 结合 WaveNet 声码器实现了接近真人的音质,但自回归方式导致推理速度较慢
- FastSpeech 系列(2019-2020):引入非自回归架构,核心创新是时长预测器(Duration Predictor)和长度调节器(Length Regulator)。时长预测器预测每个音素的持续帧数,长度调节器据此将音素序列扩展到与目标频谱图对齐的长度,实现一次性并行生成,推理速度比 Tacotron 快数百倍
神经声码器代表作:
- WaveNet(DeepMind, 2016):使用因果膨胀卷积(Causal Dilated Convolution)在波形域逐点自回归生成,音质极高但推理极慢
- HiFi-GAN(2020):基于 GAN 的并行声码器,生成器根据梅尔频谱图直接生成完整波形,判别器在多个尺度和周期上评估真实性,在音质和速度间取得了良好平衡
单阶段端到端模型:VITS
VITS(2021)跳过了梅尔频谱图这个中间表示,直接从文本生成波形。它融合了:
- 变分自编码器(VAE):学习包含内容、音色、韵律信息的潜在空间
- 对抗训练:引入判别器提升生成真实感
- 归一化流(Normalizing Flow):精确建模潜变量的复杂分布
- 随机时长预测器:通过随机采样增加韵律多样性
VITS 实现了高速并行合成与高音质的统一,是单阶段 TTS 的重要里程碑。
23.5.4 语音大模型:当 LLM 遇见语音
上述 ASR 和 TTS 系统虽然已经非常成熟,但它们本质上仍是独立的模块。一个完整的语音交互系统需要串联 ASR → NLU → NLG → TTS 四个环节,模块间的误差累积、延迟叠加和情感信息丢失等问题难以根本解决。语音大模型的核心思路是:让大语言模型直接理解和生成语音,实现真正的端到端语音智能。
Whisper:大规模弱监督语音识别
2022 年,OpenAI 发布了 Whisper(Radford et al., 2022),这是一个在 68 万小时多语言弱监督数据上训练的端到端 ASR 模型。Whisper 的架构选择极其朴素——标准的 Encoder-Decoder Transformer:
- 编码器:输入 30 秒的对数梅尔频谱图(80 维,经两层 1D 卷积下采样),编码为隐藏表示序列
- 解码器:自回归地生成文本 token,同时支持多种特殊 token 来指定任务类型(转录/翻译)、语言和时间戳
Whisper 的核心创新不在架构,而在数据规模和多任务设计:
- 海量弱监督数据:68 万小时涵盖 99 种语言的音频-文本对,其中大部分来自互联网(YouTube 字幕等),无需人工精标
- 多任务统一格式:用特殊 token 序列统一表达多种任务——多语言转录、语音翻译(X→英语)、语音活动检测、时间戳预测,所有任务共享同一个模型
- 零样本跨域泛化:由于训练数据覆盖极广,Whisper 无需领域微调即可在大多数 ASR 基准上达到接近人类的水平
import torch
import torch.nn as nn
class WhisperEncoder(nn.Module):
"""Whisper 编码器的简化实现。"""
def __init__(self, n_mels=80, d_model=512, n_heads=8, n_layers=6):
super().__init__()
# 两层 1D 卷积:下采样 + 特征提取
self.conv1 = nn.Conv1d(n_mels, d_model, kernel_size=3, padding=1)
self.conv2 = nn.Conv1d(d_model, d_model, kernel_size=3, stride=2, padding=1)
self.gelu = nn.GELU()
# 正弦位置编码
self.positional_embedding = nn.Embedding(1500, d_model)
# 标准 Transformer 编码器层
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, nhead=n_heads, dim_feedforward=d_model * 4,
batch_first=True, activation="gelu"
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=n_layers)
self.ln = nn.LayerNorm(d_model)
def forward(self, mel: torch.Tensor) -> torch.Tensor:
"""
Args:
mel: 梅尔频谱图, shape (B, n_mels, T)
Returns:
编码器输出, shape (B, T', d_model)
"""
x = self.gelu(self.conv1(mel)) # (B, d_model, T)
x = self.gelu(self.conv2(x)) # (B, d_model, T//2)
x = x.permute(0, 2, 1) # (B, T//2, d_model)
positions = torch.arange(x.size(1), device=x.device)
x = x + self.positional_embedding(positions)
x = self.transformer(x)
x = self.ln(x)
return xVALL-E:语音合成的"语言建模"范式
2023 年,微软提出了 VALL-E(Wang et al., 2023),开创性地将 TTS 重新定义为一个条件语言建模任务。其核心思路是:
- 语音离散化:使用神经音频编解码器 EnCodec 将连续语音波形压缩为多层离散 token(称为语音 token 或 acoustic token)。EnCodec 使用残差向量量化(Residual Vector Quantization, RVQ)产生 8 层码本,第 1 层捕捉语义和说话人身份等粗粒度信息,后续层逐级补充声学细节
- 自回归 + 非自回归混合建模:第 1 层语音 token 使用 Decoder-only Transformer 自回归生成(逐 token 预测);第 2-8 层使用另一个 Transformer 非自回归地一次性生成,以所有之前层的 token 为条件
- 上下文学习(In-Context Learning):模型以一段 3 秒的参考语音(enrolled speech)的 token 作为 prompt,配合目标文本的音素序列,即可生成保持参考音色的语音——实现零样本语音克隆
VALL-E 的训练数据量达到 60,000 小时(LibriLight),比传统 TTS 数据集大两个数量级。这种规模的数据使模型学到了丰富的说话人特征和韵律模式,从而实现了仅凭 3 秒参考音频即可高质量克隆的能力。
VALL-E 的后续版本 VALL-E X(2023)进一步扩展到跨语言语音合成——用一段中文参考音频即可生成英文语音,保持同一说话人的音色和口音特征。
SeedTTS 与 CosyVoice:扩散与混合架构
2024 年,TTS 领域涌现了两条新的技术路线:
SeedTTS(ByteDance, 2024):基于扩散模型的 TTS 系统。模型从纯噪声出发,通过学习去噪网络逐步将噪声转化为目标语音的声学特征。标准扩散过程需要上千步迭代,SeedTTS 使用一致性蒸馏(Consistency Distillation)和流匹配(Flow Matching)将其压缩到仅需数步即可生成高质量语音
CosyVoice(Alibaba, 2024):采用 LLM + Flow Matching 的混合架构。LLM 负责生成富含语义和风格信息的语义 token,Flow Matching 模型负责将语义 token 转化为声学 token 并合成波形。这种设计既保留了 LLM 的自然语言指令控制能力(用户可以用文字描述情感、语速、口音),又通过 Flow Matching 保证了高保真音质
GPT-4o:真正的全模态统一
2024 年 5 月,OpenAI 发布了 GPT-4o("o" for "omni"),这是第一个在工业级产品中实现文本、图像、音频原生统一的大模型。与传统的 ASR→LLM→TTS 串联管线不同,GPT-4o 直接以音频 token 作为输入和输出,在一个统一的 Transformer 中完成:
- 语音理解(听)
- 文本理解和生成(读、写)
- 语音生成(说)
- 图像理解(看)
GPT-4o 的关键突破在于延迟和表现力。传统管线的端到端延迟通常在 2-5 秒(ASR 编码 + LLM 推理 + TTS 合成),而 GPT-4o 的语音响应延迟低至 232 毫秒——接近人类对话中的自然反应时间。更重要的是,由于音频信号直接进入模型而非先转为文本,GPT-4o 能感知说话人的语调、情绪、语速等副语言信息,并在回复中体现相应的情感表达。
这种设计思路与 §23.1 中介绍的 Janus 视觉编码解耦有异曲同工之处——不同模态的输入和输出需要不同粒度的表示,但可以共享同一个 LLM 骨干进行统一的语义理解和生成。
23.5.5 语音 Token 化:连接语音与语言的桥梁
语音大模型的一个核心技术问题是:如何将连续的语音信号转化为 LLM 可处理的离散 token?这个过程被称为语音 Token 化(Speech Tokenization),是连接语音世界和语言世界的关键桥梁。
EnCodec 与残差向量量化(RVQ)
Meta 提出的 EnCodec(Defossez et al., 2022)是目前最广泛使用的神经音频编解码器。它的工作流程如下:
- 编码器:将 24 kHz 的音频波形编码为低维连续表示(75 帧/秒)
- 残差向量量化(RVQ):将连续表示量化为多层离散 token。第 1 层量化器捕捉最显著的信息,后续每层量化上一层的残差误差,逐层精细化
- 解码器:从量化后的离散表示重建音频波形
RVQ 的数学描述如下。设连续语音表示为
最终的量化近似为所有层量化结果的累加:
这种层次化的 token 结构天然适合语音大模型的建模策略——粗粒度的第 1 层 token 承载语义信息,可以用自回归方式逐个生成;细粒度的后续层 token 承载声学细节,可以用非自回归方式并行生成。
import torch
import torch.nn as nn
class ResidualVectorQuantizer(nn.Module):
"""残差向量量化器的简化实现。"""
def __init__(self, dim: int = 128, codebook_size: int = 1024, num_layers: int = 8):
super().__init__()
self.num_layers = num_layers
# 每层一个独立的码本
self.codebooks = nn.ParameterList([
nn.Parameter(torch.randn(codebook_size, dim))
for _ in range(num_layers)
])
def quantize_one_layer(self, x: torch.Tensor, codebook: torch.Tensor):
"""单层量化:找到最近的码本向量。"""
# x: (B, T, D), codebook: (K, D)
distances = torch.cdist(x, codebook.unsqueeze(0).expand(x.size(0), -1, -1))
indices = distances.argmin(dim=-1) # (B, T)
quantized = codebook[indices] # (B, T, D)
return quantized, indices
def forward(self, z: torch.Tensor):
"""
Args:
z: 编码器输出的连续表示, shape (B, T, D)
Returns:
quantized: 量化后的表示, shape (B, T, D)
all_indices: 各层的 token 索引, list of (B, T)
"""
residual = z
quantized_sum = torch.zeros_like(z)
all_indices = []
for q in range(self.num_layers):
quantized_q, indices_q = self.quantize_one_layer(residual, self.codebooks[q])
quantized_sum = quantized_sum + quantized_q
residual = residual - quantized_q # 残差传递给下一层
all_indices.append(indices_q)
return quantized_sum, all_indices语义 Token 与声学 Token 的分离
更前沿的研究(如 CosyVoice、SpeechTokenizer)进一步将语音 token 分为两种:
- 语义 Token(Semantic Token):承载语言内容和高层语义信息,通常由自监督语音模型(如 HuBERT、WavLM)的中间层表示经 K-Means 聚类得到
- 声学 Token(Acoustic Token):承载音色、韵律、音质等声学细节,通常由 EnCodec 等神经编解码器产生
这种分离与 §23.1 中 Janus 的"理解编码器 vs 生成编码器"的解耦思想高度一致——不同层面的信息需要不同粒度的表示。在 CosyVoice 中,LLM 负责生成语义 Token(控制"说什么"和"怎么说"),Flow Matching 模型负责将语义 Token 转化为声学 Token(控制"听起来像谁"),实现了内容控制和音色控制的解耦。
23.5.6 前沿方向与展望
语音大模型正在快速发展,几个值得关注的方向:
1. 全双工语音对话。 GPT-4o 展示了低延迟语音交互的可能性,但真正的全双工对话——模型能在用户说话时同时进行思考和打断——仍是开放问题。这需要模型同时处理输入和输出的音频流,对架构设计和推理效率提出了新挑战。
2. 情感与风格的细粒度控制。 当前的 TTS 模型已经能实现基本的情感表达,但在细粒度控制上仍有欠缺。例如,如何让模型在同一句话中表达复杂情感(如"表面高兴但暗含讽刺"),如何精确控制语速、停顿和重音——这些都需要更精细的语音表示和更强的条件控制机制。
3. 多语言与代码切换。 全球化场景中,用户经常在对话中混用多种语言(如中英夹杂)。语音大模型需要无缝处理语言切换,包括识别不同语言片段、在合成时自然过渡发音系统。Whisper 在多语言识别上已经迈出了重要一步,但多语言语音合成仍有很大的提升空间。
4. 语音与更多模态的融合。 随着 GPT-4o 等全模态模型的出现,语音不再是孤立的模态,而是与文本、图像、视频一起构成统一的多模态输入输出空间。未来的语音大模型需要在"看到什么"和"听到什么"之间建立更紧密的联系——例如,描述视频中的声音场景,或者根据图像内容生成匹配的旁白语音。
本节要点总结
- 语音信号处理:语音波形经采样、分帧和特征提取(MFCC 或梅尔频谱图)后,转化为声学特征向量序列
,作为模型的输入基础。 - ASR 技术演进:从传统的 HMM-GMM 混合模型(贝叶斯分解 → 声学模型 + 语言模型),到端到端模型(CTC、AED、RNN-T)。其中 RNN-T 因支持流式低延迟推理成为工业界主流。
- TTS 技术演进:从两阶段模型(Tacotron/FastSpeech + WaveNet/HiFi-GAN)到单阶段 VITS,再到基于 LLM 的 VALL-E(语音 token 化 + 条件语言建模)和基于扩散的 SeedTTS。
- 语音 Token 化是连接语音与 LLM 的核心桥梁。EnCodec 的残差向量量化(RVQ)将连续波形压缩为多层离散 token,粗粒度层承载语义信息,细粒度层承载声学细节。
- 全模态统一(如 GPT-4o)代表了语音大模型的终极方向:文本、图像、语音在同一个 Transformer 中原生处理,消除了传统管线的延迟和信息瓶颈,并保留了语调、情绪等副语言信息。