7.2 Qwen3 全规模实现
前一节介绍了从 GPT-2 到现代 LLM 架构的渐进式改造路径:RoPE 替换绝对位置编码、RMSNorm 替换 LayerNorm、SwiGLU 替换 GELU 前馈网络、移除所有线性层偏置项。这些改造并非纸上谈兵——Qwen3 系列正是这一现代化架构的量产级实现。Qwen3 覆盖从 0.6B 到 32B 的稠密模型、30B-A3B 的 MoE 模型,以及支持思维链 Thinking Tokens 的 Reasoning 变体,三种形态共享同一套核心组件,仅在前馈网络和推理模式上有所分化。
本节将给出 Qwen3 的完整架构代码,逐一剖析稠密版本、MoE 版本和 Reasoning 变体的实现细节,并通过对比表总结三者的异同。
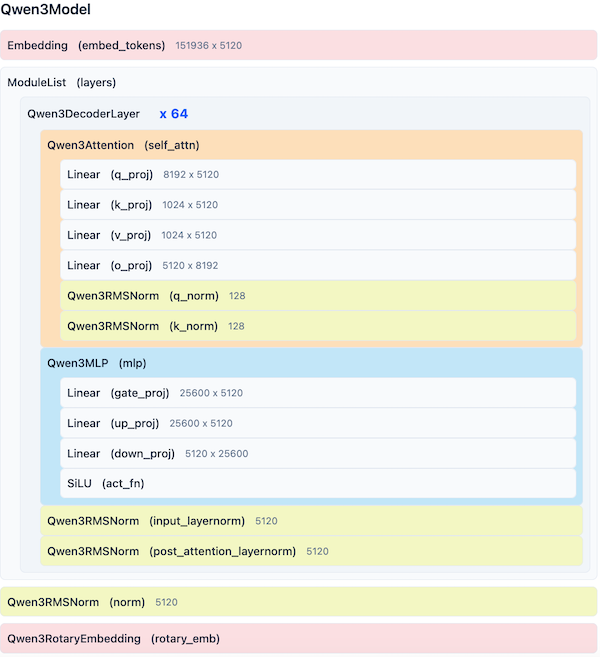
图 7-5:Qwen3 Dense 模型架构。采用 RMSNorm + SwiGLU + RoPE + GQA 的现代化配置,覆盖 0.6B 到 32B 的完整参数规模。
7.2.1 核心组件:四大改造的统一实现
Qwen3 的所有变体共享同一套核心组件:RMSNorm、RoPE、SwiGLU 前馈网络和分组查询注意力(GQA)。以下代码给出了完整的自包含实现。
RMSNorm。 Qwen3 在注意力层前后均使用 Pre-Norm 布局的 RMSNorm。实现中有一个与 Qwen3 官方权重兼容的细节:在计算方差前先将输入转换为 float32,归一化后再转回原始精度。这一步在使用 bfloat16 训练时至关重要——bfloat16 仅有 8 位尾数,直接在低精度下计算 pow(2).mean() 会导致显著的精度损失:
class RMSNorm(nn.Module):
def __init__(self, emb_dim, eps=1e-6):
super().__init__()
self.eps = eps
self.scale = nn.Parameter(torch.ones(emb_dim))
def forward(self, x):
input_dtype = x.dtype
x = x.to(torch.float32) # 关键:在 float32 下计算方差
variance = x.pow(2).mean(dim=-1, keepdim=True)
norm_x = x * torch.rsqrt(variance + self.eps)
return (norm_x * self.scale).to(input_dtype)与第六章介绍的通用 RMSNorm 相比,Qwen3 的实现有两点值得注意:(1)没有 shift 参数(即 bias=False),这与"移除所有偏置项"的设计原则一致;(2)scale 参数初始化为全 1 向量,保证初始化时 RMSNorm 接近恒等映射。
RoPE(旋转位置编码)。 Qwen3 使用的 RoPE 与 §6.4 中介绍的标准实现一致,但 theta_base 配置有所不同:稠密版本使用
def compute_rope_params(head_dim, theta_base=10_000,
context_length=4096, dtype=torch.float32):
assert head_dim % 2 == 0
inv_freq = 1.0 / (theta_base ** (
torch.arange(0, head_dim, 2, dtype=dtype)[: (head_dim // 2)].float()
/ head_dim
))
positions = torch.arange(context_length, dtype=dtype)
angles = positions[:, None] * inv_freq[None, :]
angles = torch.cat([angles, angles], dim=1)
return torch.cos(angles), torch.sin(angles)
def apply_rope(x, cos, sin):
# x: (batch, num_heads, seq_len, head_dim)
batch_size, num_heads, seq_len, head_dim = x.shape
x1 = x[..., : head_dim // 2]
x2 = x[..., head_dim // 2 :]
cos = cos[:seq_len, :].unsqueeze(0).unsqueeze(0)
sin = sin[:seq_len, :].unsqueeze(0).unsqueeze(0)
rotated = torch.cat((-x2, x1), dim=-1)
return ((x * cos) + (rotated * sin)).to(dtype=x.dtype)分组查询注意力(GQA)与 QKNorm。 Qwen3 全系列使用 GQA,且所有规模均固定 head_dim=128、n_kv_groups=8。一个关键的新增组件是 QKNorm——在将 Query 和 Key 送入 RoPE 之前,先各自通过一个 RMSNorm 层进行归一化。QKNorm 的作用是防止注意力 logits 在深层网络中爆炸:当模型层数达到 64 层(如 Qwen3-32B)时,未归一化的 Q/K 向量的范数可能随层数增长,导致注意力分数溢出 bfloat16 的表示范围。QKNorm 将每个头的 Q/K 向量归一化到单位方差,从根源上消除了这一问题:
class GroupedQueryAttention(nn.Module):
def __init__(self, d_in, num_heads, num_kv_groups,
head_dim=None, qk_norm=False, dtype=None):
super().__init__()
assert num_heads % num_kv_groups == 0
self.num_heads = num_heads
self.num_kv_groups = num_kv_groups
self.group_size = num_heads // num_kv_groups
if head_dim is None:
head_dim = d_in // num_heads
self.head_dim = head_dim
self.d_out = num_heads * head_dim
self.W_query = nn.Linear(d_in, self.d_out, bias=False, dtype=dtype)
self.W_key = nn.Linear(
d_in, num_kv_groups * head_dim, bias=False, dtype=dtype
)
self.W_value = nn.Linear(
d_in, num_kv_groups * head_dim, bias=False, dtype=dtype
)
self.out_proj = nn.Linear(self.d_out, d_in, bias=False, dtype=dtype)
# QKNorm:对 Q 和 K 分别做 RMSNorm
if qk_norm:
self.q_norm = RMSNorm(head_dim, eps=1e-6)
self.k_norm = RMSNorm(head_dim, eps=1e-6)
else:
self.q_norm = self.k_norm = None
def forward(self, x, mask, cos, sin):
b, num_tokens, _ = x.shape
queries = self.W_query(x)
keys = self.W_key(x)
values = self.W_value(x)
queries = queries.view(
b, num_tokens, self.num_heads, self.head_dim
).transpose(1, 2)
keys = keys.view(
b, num_tokens, self.num_kv_groups, self.head_dim
).transpose(1, 2)
values = values.view(
b, num_tokens, self.num_kv_groups, self.head_dim
).transpose(1, 2)
# QKNorm 在 RoPE 之前
if self.q_norm:
queries = self.q_norm(queries)
if self.k_norm:
keys = self.k_norm(keys)
queries = apply_rope(queries, cos, sin)
keys = apply_rope(keys, cos, sin)
# 扩展 KV 头以匹配 Q 头数
keys = keys.repeat_interleave(self.group_size, dim=1)
values = values.repeat_interleave(self.group_size, dim=1)
attn_scores = queries @ keys.transpose(2, 3)
attn_scores = attn_scores.masked_fill(mask, -torch.inf)
attn_weights = torch.softmax(
attn_scores / self.head_dim**0.5, dim=-1
)
context = (attn_weights @ values).transpose(1, 2).reshape(
b, num_tokens, self.d_out
)
return self.out_proj(context)注意力计算中的一个实现细节:缩放因子 self.head_dim**0.5 使用的是固定的 head_dim=128,而非 emb_dim // num_heads。由于 Qwen3 显式指定了 head_dim,Q 投影的输出维度为 num_heads * head_dim,当 emb_dim 不能被 num_heads 整除时(如 0.6B 的 emb_dim=1024、num_heads=16、head_dim=128,Q 输出维度为 2048 而非 1024),这种设计避免了维度不匹配的问题。
7.2.2 稠密版本:SwiGLU 前馈网络
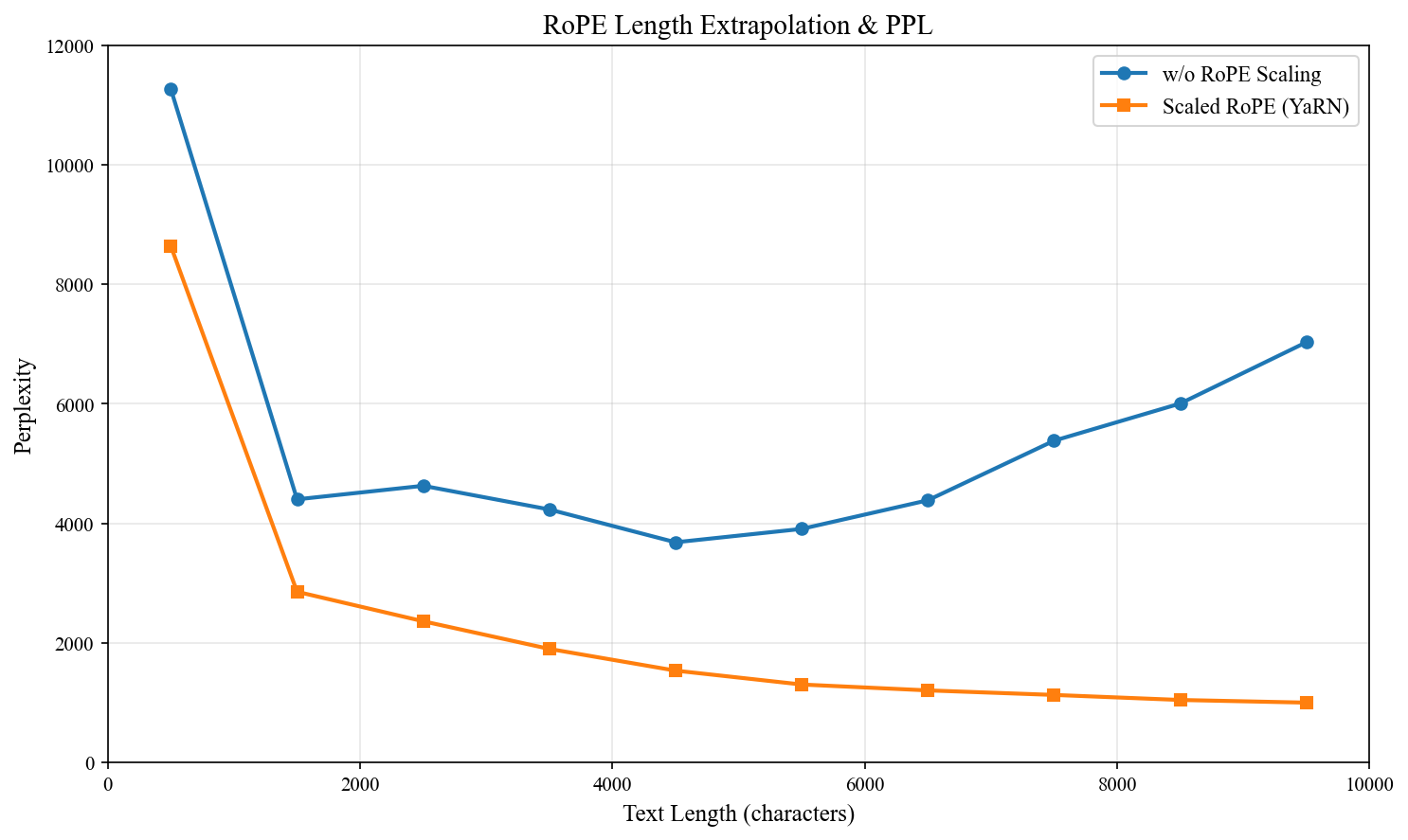
图 7-6:RoPE 基频对困惑度的影响。更大的
稠密版本使用标准的 SwiGLU 前馈网络。SwiGLU 由两条并行的线性投影构成:一条经过 SiLU 激活作为"门控",另一条保持线性,两者逐元素相乘后再通过一个下投影层:
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.fc1 = nn.Linear(
cfg["emb_dim"], cfg["hidden_dim"],
dtype=cfg["dtype"], bias=False
) # gate_proj
self.fc2 = nn.Linear(
cfg["emb_dim"], cfg["hidden_dim"],
dtype=cfg["dtype"], bias=False
) # up_proj
self.fc3 = nn.Linear(
cfg["hidden_dim"], cfg["emb_dim"],
dtype=cfg["dtype"], bias=False
) # down_proj
def forward(self, x):
return self.fc3(nn.functional.silu(self.fc1(x)) * self.fc2(x))这三个线性层在 Qwen3 的权重文件中分别对应 gate_proj(fc1)、up_proj(fc2)和 down_proj(fc3)。SwiGLU 的参数量为 hidden_dim 设为 emb_dim 的约 3 倍(而非标准 FFN 常用的 4 倍)。
Transformer 块与完整模型。 稠密版本的 Transformer 块遵循 Pre-Norm + 残差连接的标准布局:
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = GroupedQueryAttention(
d_in=cfg["emb_dim"], num_heads=cfg["n_heads"],
head_dim=cfg["head_dim"], num_kv_groups=cfg["n_kv_groups"],
qk_norm=cfg["qk_norm"], dtype=cfg["dtype"]
)
self.ff = FeedForward(cfg)
self.norm1 = RMSNorm(cfg["emb_dim"], eps=1e-6)
self.norm2 = RMSNorm(cfg["emb_dim"], eps=1e-6)
def forward(self, x, mask, cos, sin):
shortcut = x
x = self.att(self.norm1(x), mask, cos, sin)
x = x + shortcut
shortcut = x
x = self.ff(self.norm2(x))
x = x + shortcut
return x
class Qwen3Model(nn.Module):
def __init__(self, cfg):
super().__init__()
self.tok_emb = nn.Embedding(
cfg["vocab_size"], cfg["emb_dim"], dtype=cfg["dtype"]
)
self.trf_blocks = nn.ModuleList(
[TransformerBlock(cfg) for _ in range(cfg["n_layers"])]
)
self.final_norm = RMSNorm(cfg["emb_dim"])
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"],
bias=False, dtype=cfg["dtype"]
)
head_dim = cfg["head_dim"] or cfg["emb_dim"] // cfg["n_heads"]
cos, sin = compute_rope_params(
head_dim=head_dim,
theta_base=cfg["rope_base"],
context_length=cfg["context_length"]
)
self.register_buffer("cos", cos, persistent=False)
self.register_buffer("sin", sin, persistent=False)
self.cfg = cfg
def forward(self, in_idx):
x = self.tok_emb(in_idx)
num_tokens = x.shape[1]
mask = torch.triu(torch.ones(
num_tokens, num_tokens,
device=x.device, dtype=torch.bool
), diagonal=1)
for block in self.trf_blocks:
x = block(x, mask, self.cos, self.sin)
x = self.final_norm(x)
return self.out_head(x.to(self.cfg["dtype"]))注意 Qwen3Model 的最后一步 x.to(self.cfg["dtype"]):final_norm 内部会将输入转为 float32 计算,输出也是 float32,但 out_head 的权重是 bfloat16,为避免精度不匹配,需要显式转换。
稠密版本全系列配置。 以下列出 Qwen3 稠密模型从 0.6B 到 32B 的完整配置,所有模型共享 vocab_size=151,936、head_dim=128、n_kv_groups=8、qk_norm=True、rope_base=1,000,000:
| 规模 | emb_dim | n_heads | n_layers | hidden_dim | context_length | 总参数量 | 唯一参数量 |
|---|---|---|---|---|---|---|---|
| 0.6B | 1,024 | 16 | 28 | 3,072 | 40,960 | 7.52 亿 | 5.96 亿 |
| 1.7B | 2,048 | 16 | 28 | 6,144 | 40,960 | — | — |
| 4B | 2,560 | 32 | 36 | 9,728 | 40,960 | — | — |
| 8B | 4,096 | 32 | 36 | 12,288 | 40,960 | — | — |
| 14B | 5,120 | 40 | 40 | 17,408 | 40,960 | — | — |
| 32B | 5,120 | 64 | 64 | 25,600 | 40,960 | — | — |
从 0.6B 到 32B,模型的缩放路径遵循一个清晰的模式:emb_dim 从 1,024 增长到 5,120(5 倍),n_layers 从 28 增长到 64(2.3 倍),n_heads 从 16 增长到 64(4 倍)。其中 14B 和 32B 共享相同的 emb_dim=5,120,区别在于 32B 使用了更多的层(64 vs. 40)和更多的注意力头(64 vs. 40)。
0.6B 模型的"总参数量"(7.52 亿)与"唯一参数量"(5.96 亿)之间的差异来自 Weight Tying:tok_emb(嵌入层)和 out_head(输出投影层)共享同一组权重矩阵。共享的权重数量为
7.2.3 MoE 版本:稀疏前馈网络
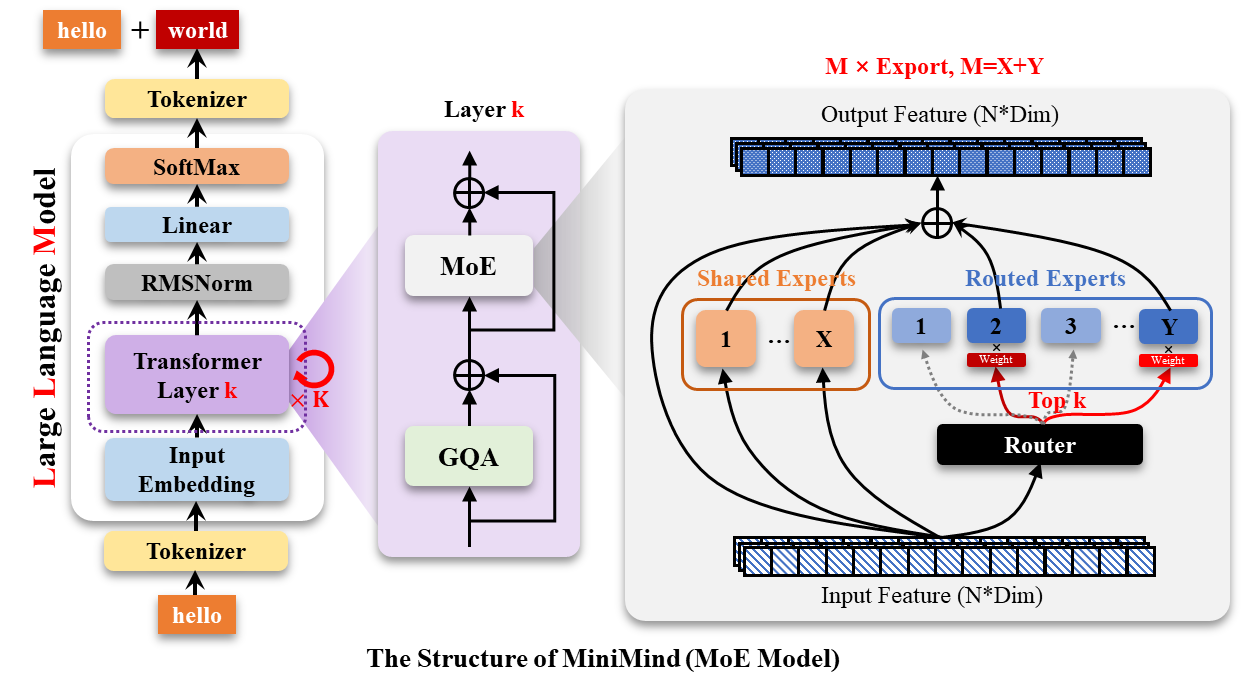
图 7-7:MoE Transformer 块结构。在标准 Transformer 块的 FFN 位置替换为 MoE 层,路由器为每个 token 选择 Top-K 个专家并行计算。
Qwen3 的 MoE 版本(30B-A3B)在架构上与稠密版本仅有一处不同:将每个 Transformer 块中的 FeedForward 替换为 MoEFeedForward。注意力层、RMSNorm、RoPE 等组件完全相同。
MoE 前馈网络。 MoE 的核心思想是:维护多个并行的"专家"前馈网络,每次前向传播只激活其中一小部分。30B-A3B 模型共有 128 个专家,每个 token 仅激活 8 个(num_experts_per_tok=8),通过一个线性门控层(router)选择激活哪些专家:
class MoEFeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.num_experts_per_tok = cfg["num_experts_per_tok"]
self.num_experts = cfg["num_experts"]
self.emb_dim = cfg["emb_dim"]
# Router:将输入映射到 num_experts 维的 logits
self.gate = nn.Linear(
cfg["emb_dim"], cfg["num_experts"],
bias=False, dtype=cfg["dtype"]
)
# 每个专家是一个独立的 SwiGLU FFN
self.fc1 = nn.ModuleList([
nn.Linear(cfg["emb_dim"], cfg["moe_hidden_dim"],
bias=False, dtype=cfg["dtype"])
for _ in range(cfg["num_experts"])
])
self.fc2 = nn.ModuleList([
nn.Linear(cfg["emb_dim"], cfg["moe_hidden_dim"],
bias=False, dtype=cfg["dtype"])
for _ in range(cfg["num_experts"])
])
self.fc3 = nn.ModuleList([
nn.Linear(cfg["moe_hidden_dim"], cfg["emb_dim"],
bias=False, dtype=cfg["dtype"])
for _ in range(cfg["num_experts"])
])
def forward(self, x):
# Router 计算:选择 top-k 专家
scores = self.gate(x) # (b, seq_len, num_experts)
topk_scores, topk_indices = torch.topk(
scores, self.num_experts_per_tok, dim=-1
)
topk_probs = torch.softmax(topk_scores, dim=-1)
batch, seq_len, _ = x.shape
x_flat = x.reshape(batch * seq_len, -1)
out_flat = torch.zeros(
batch * seq_len, self.emb_dim,
device=x.device, dtype=x.dtype
)
topk_indices_flat = topk_indices.reshape(
-1, self.num_experts_per_tok
)
topk_probs_flat = topk_probs.reshape(
-1, self.num_experts_per_tok
)
# 按专家分组处理,避免逐 token 循环
for expert_id in torch.unique(topk_indices_flat).tolist():
mask = topk_indices_flat == expert_id
token_mask = mask.any(dim=-1)
selected_idx = token_mask.nonzero(as_tuple=False).squeeze(-1)
if selected_idx.numel() == 0:
continue
expert_input = x_flat.index_select(0, selected_idx)
# 每个专家内部仍是 SwiGLU
hidden = (nn.functional.silu(self.fc1[expert_id](expert_input))
* self.fc2[expert_id](expert_input))
expert_out = self.fc3[expert_id](hidden)
# 加权累加:每个 token 的输出是其激活专家的加权和
mask_sel = mask[selected_idx]
slot_idx = mask_sel.int().argmax(dim=-1, keepdim=True)
probs = torch.gather(
topk_probs_flat.index_select(0, selected_idx),
dim=-1, index=slot_idx
).squeeze(-1)
out_flat.index_add_(
0, selected_idx,
expert_out * probs.unsqueeze(-1)
)
return out_flat.reshape(batch, seq_len, self.emb_dim)Router 机制解读。 self.gate 是一个 emb_dim -> num_experts 的线性层,对每个 token 输出 128 维的 logits。torch.topk 选出得分最高的 8 个专家,再对这 8 个得分做 Softmax 得到归一化权重。最终输出是 8 个专家输出的加权和。这种"Top-K + Softmax"的路由策略是 MoE 的标准做法。
按专家分组处理。 上述实现采用"按专家遍历"而非"按 token 遍历"的策略:外层循环遍历被激活的唯一专家 ID,内层通过 index_select 收集该专家需要处理的所有 token,批量执行前向传播,再通过 index_add_ 将结果写回。这种策略在 GPU 上更高效,因为同一专家处理的 token 可以组成一个连续的 mini-batch,充分利用矩阵乘法的并行性。
MoE 版本的 TransformerBlock。 仅在初始化时根据配置选择前馈网络类型:
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = GroupedQueryAttention(...) # 与稠密版本相同
if cfg["num_experts"] > 0:
self.ff = MoEFeedForward(cfg)
else:
self.ff = FeedForward(cfg)
self.norm1 = RMSNorm(cfg["emb_dim"], eps=1e-6)
self.norm2 = RMSNorm(cfg["emb_dim"], eps=1e-6)Qwen3Model 的代码无需任何修改——它只通过 TransformerBlock 间接使用前馈网络,而 TransformerBlock 已根据配置自动选择了正确的类型。
30B-A3B 的完整配置:
QWEN3_CONFIG_30B_A3B = {
"vocab_size": 151_936,
"context_length": 262_144, # 256K 上下文
"emb_dim": 2048,
"n_heads": 32,
"n_layers": 48,
"head_dim": 128,
"qk_norm": True,
"n_kv_groups": 4, # 注意:这里是 4,而非稠密版本的 8
"rope_base": 10_000_000.0, # 10M,比稠密版本大 10 倍
"dtype": torch.bfloat16,
"num_experts": 128,
"num_experts_per_tok": 8,
"moe_hidden_dim": 768,
}几个关键数值值得对比:
| 对比维度 | 稠密 8B | MoE 30B-A3B |
|---|---|---|
| 总参数量 | ~80 亿 | ~305 亿 |
| 每 token 激活参数量 | ~80 亿 | ~30 亿 |
| 单专家 hidden_dim | 12,288 | 768 |
| 专家数量 | 1 | 128(激活 8) |
| n_kv_groups | 8 | 4 |
| rope_base | 1,000,000 | 10,000,000 |
| context_length | 40,960 | 262,144 |
MoE 版本的核心优势在于:总参数量达到 305 亿,赋予模型更大的知识容量,但每个 token 仅激活约 30 亿参数(8 个专家 + 注意力层 + 嵌入层),推理计算量与稠密 3B 模型相当。这就是"30B-A3B"命名的含义——30B 总参数,3B 激活参数。
每个专家的 moe_hidden_dim=768 远小于稠密模型的 hidden_dim(如 8B 的 12,288),这是因为每次前向传播有 8 个专家并行工作,总的"有效 hidden_dim"为 hidden_dim。
MoE 版本还将 n_kv_groups 从 8 减少到 4,意味着 KV 头数更少、KV 缓存更小——这对 256K 的超长上下文尤为重要。同时 rope_base 增大 10 倍至
7.2.4 Reasoning 变体:Thinking Tokens 支持
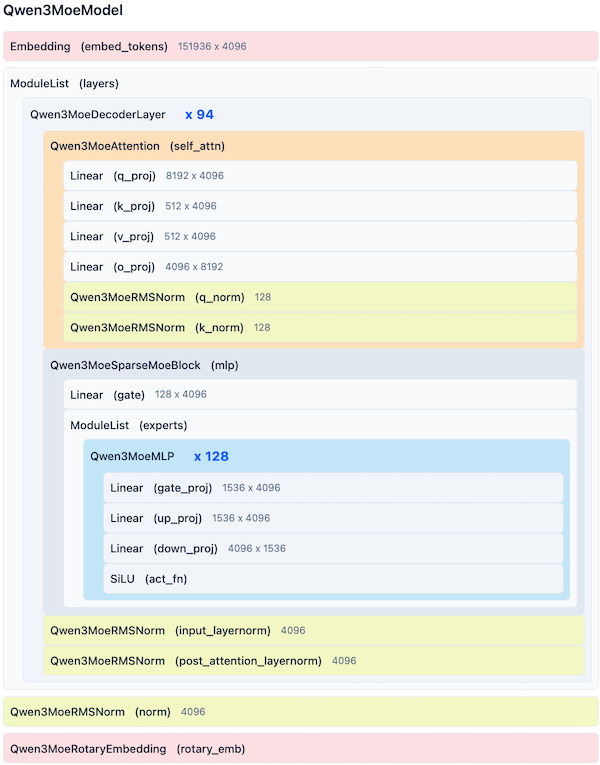
图 7-8:Qwen3 MoE 的路由策略。128 个专家中每个 token 激活 8 个,路由器输出 128 维 logits,Top-K 选择后 Softmax 归一化得到专家权重。
Qwen3 的 Reasoning 变体在模型架构上与非 Reasoning 版本完全相同——没有任何额外的参数或层。区别完全在推理时的 token 模板和训练阶段的强化学习。
三种使用模式。 Qwen3 的非 Base 模型(即经过指令微调和强化学习的模型)支持三种使用模式:
- Reasoning 模式:模型在生成正式回答前,先输出一段包裹在
<think>...</think>标签中的思维链推理过程。这些 Thinking Tokens 对用户可见,但不计入最终回答。 - Instruct 模式:通过在提示中预置空的
<think>\n\n</think>标签,抑制模型的思维链输出,使其直接给出简洁回答。 - Base 模式:不使用聊天模板,直接续写输入文本。
这三种模式的切换完全由 Tokenizer 的聊天模板控制:
class Qwen3Tokenizer:
def _wrap_chat(self, user_msg):
s = f"<|im_start|>user\n{user_msg}<|im_end|>\n"
if self.add_generation_prompt:
s += "<|im_start|>assistant"
if self.add_thinking:
# Reasoning 模式:让模型自由开始思考
s += "\n"
else:
# Instruct 模式:预置空 think 标签,抑制推理
s += "\n<think>\n\n</think>\n\n"
return sReasoning 模式的输入格式:
<|im_start|>user
Give me a short introduction to large language models.<|im_end|>
<|im_start|>assistant模型看到这个输入后,会自主生成 <think> 标签并开始推理,最终关闭 </think> 后给出正式回答。
Instruct 模式的输入格式:
<|im_start|>user
Give me a short introduction to large language models.<|im_end|>
<|im_start|>assistant
<think>
</think>通过预置空的 <think></think> 标签,模型被"告知"思考阶段已经结束,直接进入回答。这一技巧利用了模型在训练中学到的 </think> 后面应该是正式回答的模式。
Thinking Tokens 的本质。 从模型的视角看,<think> 和 </think> 只是词表中的两个特殊 token(ID 分别对应 tokenizer.json 中的条目)。模型在 Reasoning 训练阶段(通常使用 GRPO 等强化学习算法)学会了:
- 在
<think>后输出详细的推理过程(问题分解、假设验证、自我纠错等) - 在推理完成后输出
</think>标记结束 - 在
</think>后输出简洁、准确的最终回答
这种设计的巧妙之处在于:不需要修改任何模型架构,仅通过特殊 token 和训练目标就实现了"思考-回答"的两阶段生成。
7.2.5 三种变体对比总结
下表从架构、配置和使用方式三个维度总结 Qwen3 三种变体的异同:
| 维度 | 稠密版本(0.6B–32B) | MoE 版本(30B-A3B) | Reasoning 变体 |
|---|---|---|---|
| 注意力层 | GQA + QKNorm + RoPE | 相同 | 相同 |
| 前馈网络 | SwiGLU FFN | MoE SwiGLU(128 专家,激活 8) | 与底层模型相同 |
| 归一化 | RMSNorm (Pre-Norm) | 相同 | 相同 |
| 偏置项 | 全部移除 | 相同 | 相同 |
| head_dim | 128 | 128 | 128 |
| n_kv_groups | 8 | 4 | 与底层模型相同 |
| rope_base | 1,000,000 | 10,000,000 | 与底层模型相同 |
| context_length | 40,960 | 262,144 | 与底层模型相同 |
| 总参数量 | 0.6B–32B | ~30.5B | 与底层模型相同 |
| 激活参数量 | = 总参数量 | ~3B | 与底层模型相同 |
| Weight Tying | 小模型使用 | 使用 | 与底层模型相同 |
| 架构改动 | 无(基线) | 仅替换 FFN 为 MoE FFN | 无任何架构改动 |
| 训练差异 | 预训练 + SFT | 预训练 + SFT | 预训练 + SFT + RL(如 GRPO) |
| 推理模式 | Base / Instruct | Base / Instruct / Reasoning | Base / Instruct / Reasoning |
| 特殊 token | 标准聊天模板 | 标准聊天模板 | <think>/</think> Thinking Tokens |
图 7-9:Qwen3 MoE 架构。在 Dense 基础上将 FFN 替换为 MoE 层,每个 token 仅激活 Top-K 个专家,实现更大模型容量与高效推理的平衡。
本节小结
本节以完整的自包含代码给出了 Qwen3 全系列的架构实现:
- 共享核心:所有变体共享 RMSNorm(float32 计算方差)+ RoPE(
从 到 )+ SwiGLU + GQA with QKNorm 的组合。全部线性层移除偏置项,使用 bfloat16 精度,Pre-Norm 残差连接布局。 - 稠密版本(0.6B–32B):标准 SwiGLU 前馈网络,
hidden_dim约为emb_dim的 3 倍。从 0.6B 到 32B 的缩放主要通过增加emb_dim(1,024→5,120)、n_layers(28→64)和n_heads(16→64)实现。小模型使用 Weight Tying 节省参数。 - MoE 版本(30B-A3B):将 SwiGLU FFN 替换为 128 专家的 MoE FFN,每个 token 激活 8 个专家。总参数 305 亿但激活参数仅约 30 亿,推理计算量接近稠密 3B 模型。Router 使用 Top-K + Softmax 策略。
n_kv_groups减至 4、rope_base增至,支持 256K 上下文。 - Reasoning 变体:架构与底层模型完全相同,通过
<think>/</think>特殊 token 和强化学习训练实现思维链推理。三种使用模式(Reasoning / Instruct / Base)完全由 Tokenizer 的聊天模板控制,无需切换模型权重。