11.6 容器与云原生
在前几节中,我们讨论了 AI 集群的硬件拓扑、高速互连与存储系统。然而,即便硬件资源已经就位,要让成百上千张 GPU 协同服务于训练和推理任务,还需要一层"操作系统级"的软件抽象——这正是容器与云原生技术的核心使命。Docker 解决了"环境一致性"问题,Kubernetes(K8S)解决了"大规模编排"问题,两者结合构成了现代 AI 基础设施的软件底座。
本节将从容器的底层隔离机制讲起,经过 Docker 镜像与运行时原理,进入 Kubernetes 的编排体系(Pod、Deployment、StatefulSet),再深入 K8S 的存储、网络、资源管理、运行时与监控等关键子系统,最终勾勒出 AI 云平台的整体架构。
11.6.1 容器技术基础:从进程隔离到 Docker
为什么需要容器? 在大模型训练场景中,一个典型的痛点是:研究员在本地调通的训练脚本,部署到集群后往往因为 CUDA 版本不匹配、Python 依赖冲突、系统库缺失等原因无法运行。容器技术的核心价值,正是将应用及其全部依赖打包成一个不可变的单元,实现**"一次构建,到处运行"**。
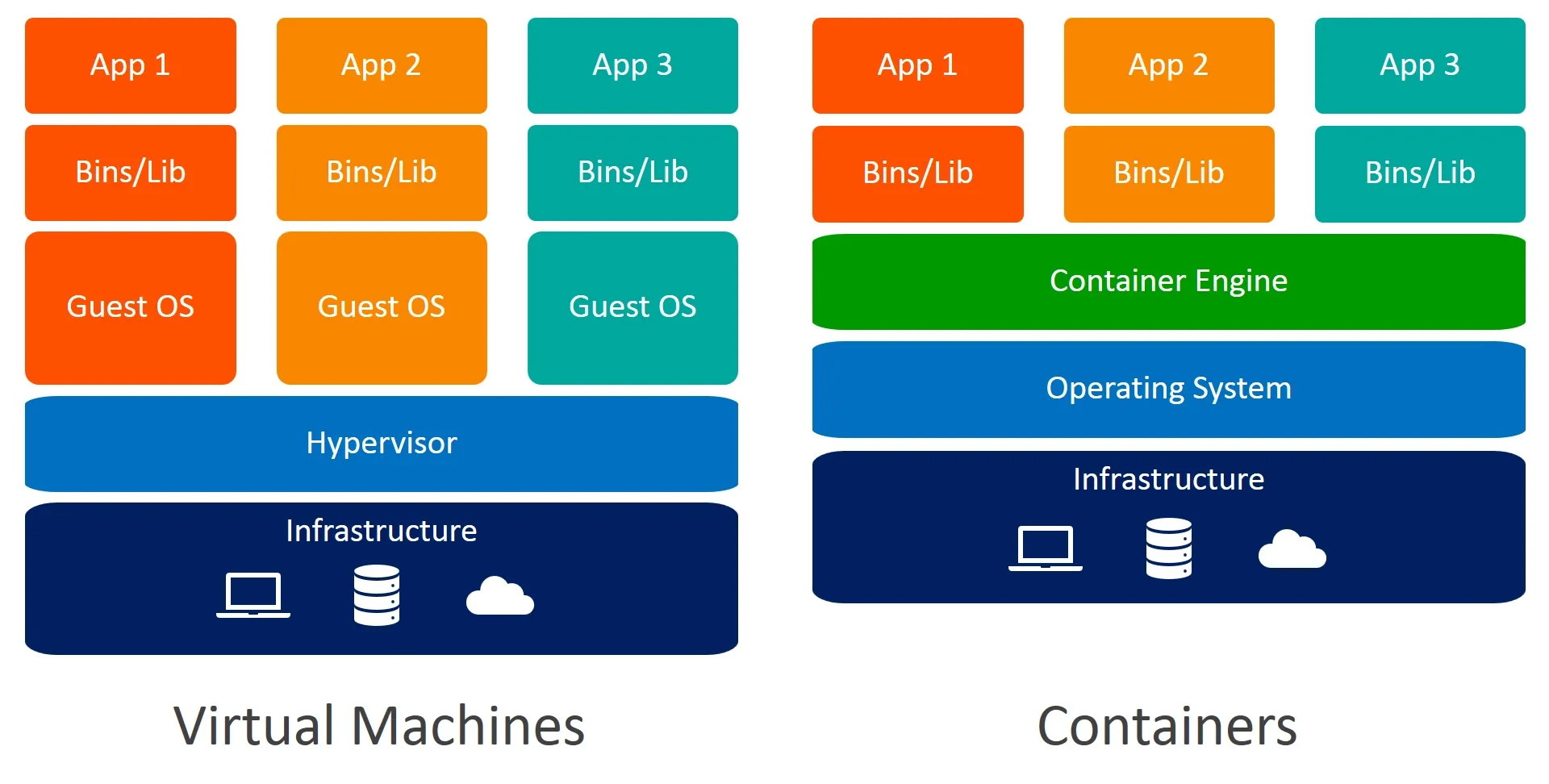
图 11-18:虚拟机与容器的架构对比。虚拟机通过 Hypervisor 模拟硬件并运行完整 Guest OS,开销大、启动慢;容器直接复用宿主机内核,仅通过 Namespace 和 Cgroups 实现进程级隔离,资源开销接近原生进程。
容器隔离的两大支柱。 容器并不是"轻量级虚拟机",其本质是一组被 Linux 内核特殊处理的进程。隔离能力来自两个内核机制:
Namespace(命名空间):实现视图隔离。Linux 为 PID、Network、Mount、UTS、IPC、User 等资源分别提供了独立的 Namespace。容器内的进程通过
clone()系统调用进入新的 Namespace 后,只能看到该 Namespace 内的资源视图——例如容器内的 1 号进程认为自己独占了系统,实际上在宿主机视角它只是众多进程中的一个。Cgroups(控制组):实现资源限制。Namespace 只解决了"看得到什么"的问题,但容器内进程仍可无限制地消耗宿主机资源。Cgroups 为进程组设定 CPU、内存、磁盘 I/O 等资源的使用上限。当容器内存超出限制时,内核的 OOM Killer 会终止超限进程,保护宿主机和其他容器的稳定性。
两者的协同关系可以概括为:Namespace 让容器"误以为独占系统",Cgroups 让容器"不能真的独占系统"。
Docker 的三大技术基石。 Docker 在 Namespace 和 Cgroups 之上,还引入了第三根支柱——联合文件系统(Union File System, UFS)。以当前默认的 Overlay2 为例,镜像由多个只读层(lowerdir)叠加而成,容器运行时在最上层添加一个可写层(upperdir),通过写时复制(Copy-on-Write)机制,容器的修改仅发生在可写层,底层镜像永远不变。这使得同一镜像可以同时运行上百个容器,彼此互不影响,且启动几乎不需要额外的磁盘拷贝。
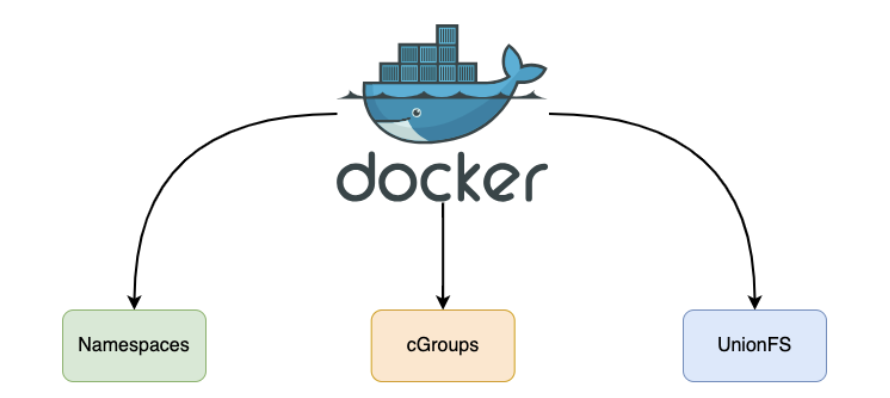
图 11-19:Docker 底层依赖的三大 Linux 内核技术——Namespaces(视图隔离)、Cgroups(资源限制)、UnionFS(分层镜像)。
从 Dockerfile 到运行态容器。 理解 Docker 的工作流可以分为两个阶段:
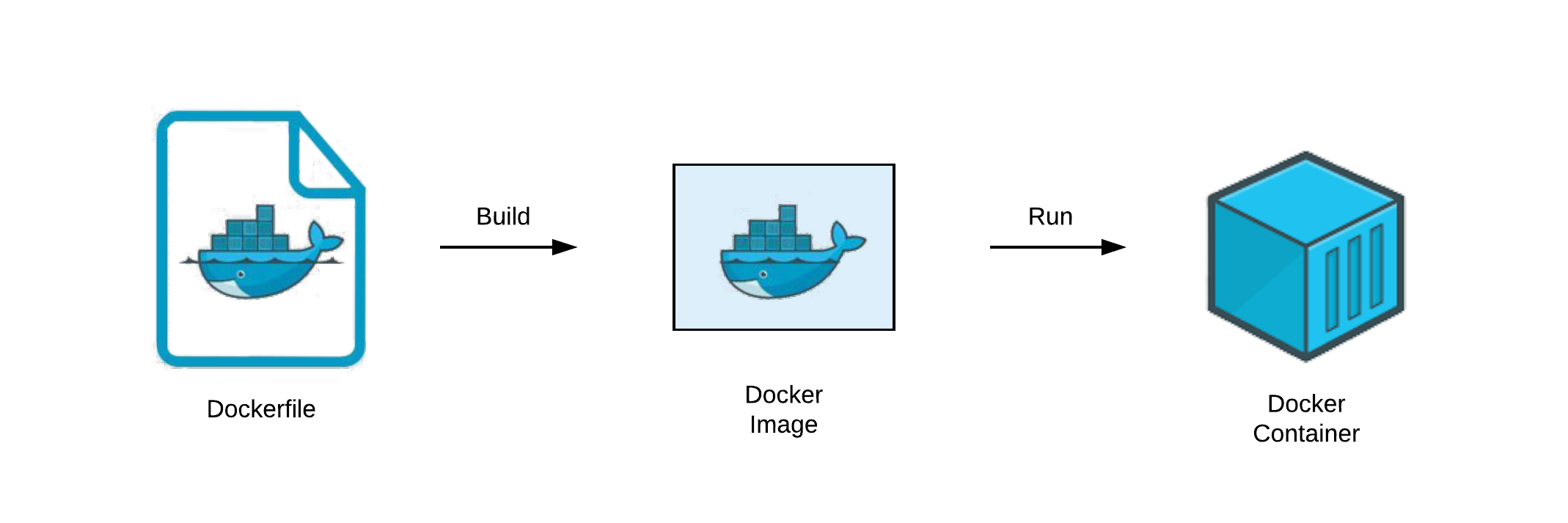
图 11-20:Dockerfile → Docker Image → Docker Container 的生命周期。Build 阶段将指令固化为分层镜像,Run 阶段基于镜像创建隔离的运行实例。
docker build阶段:Docker Engine 逐行解析 Dockerfile,每条RUN/COPY等指令都会启动一个临时中间容器执行操作,然后将文件系统变更固化为新的只读层。这些层按顺序叠加,最终生成不可变的镜像。docker run阶段:三大技术协同工作——UFS 在镜像层之上创建可写层并挂载为容器根文件系统;Namespace 为容器进程创建独立的 PID、网络、文件系统等视图;Cgroups 根据用户指定的--cpus、-m等参数设定资源边界。
以下是一个用于 AI 训练环境的 Dockerfile 示例:
FROM nvidia/cuda:12.1.0-devel-ubuntu22.04
WORKDIR /workspace
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY train.py .
CMD ["python", "train.py"]构建后,可以通过 docker run --gpus all -m 64g --cpus=32 my-training-image 启动一个带有 GPU 访问权限、内存限制为 64 GB、CPU 限制为 32 核的训练容器。
11.6.2 Kubernetes 容器编排
Docker 解决了单机上的容器打包与运行问题,但在 AI 集群中,我们面对的是成百上千个节点、多种异构设备、动态变化的训练和推理负载。Kubernetes(K8S) 正是解决这一"大规模容器编排"问题的事实标准——它本质上是面向数据中心的操作系统。
Pod:最小调度单元。 Pod 是 K8S 中最核心的抽象,它是一组超亲密容器的集合。Pod 内的容器共享 Network Namespace(同一 IP 地址和端口空间)、IPC Namespace 和 UTS Namespace,但各自保持独立的文件系统和 PID 空间。这种设计允许紧密协作的容器(例如训练主进程与日志收集 sidecar)直接通过 localhost 通信,而无需经过网络栈。
Pod 内部通过一个特殊的 Infra Container(也称 Pause 容器)来实现资源共享——它作为第一个启动的容器,负责创建共享的 Namespace,其他业务容器通过 setns 加入这些 Namespace。
Deployment:无状态应用管理。 Deployment 是管理无状态应用的核心对象,其设计哲学是声明式 API——用户只需定义"期望状态",K8S 的控制器会自动将集群调谐到该状态。

图 11-21:Kubernetes 控制器的 YAML 配置结构。上半部分为控制器定义(期望状态),下半部分为被控制对象的 Pod 模板。
控制器通过**控制循环(Reconciliation Loop)**持续运行:读取期望状态,对比实际状态,若不一致则执行编排动作(创建/删除 Pod、扩缩副本等)。以下示例定义了一个 3 副本的推理服务:
apiVersion: apps/v1
kind: Deployment
metadata:
name: inference-server
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
app: inference
template:
metadata:
labels:
app: inference
spec:
containers:
- name: model-server
image: my-registry/llm-inference:v2.1
ports:
- containerPort: 8080
resources:
limits:
nvidia.com/gpu: 1
memory: "32Gi"
requests:
cpu: "4"
memory: "16Gi"当需要更新模型版本时,Deployment 通过滚动更新逐步替换旧 Pod:先创建新版本 Pod,确认就绪后再终止旧版本,全程服务不中断。
Service 与 Ingress:服务暴露。 Pod 的 IP 地址是临时的,每次重建都会变化。Service 通过虚拟 IP(ClusterIP)为一组 Pod 提供稳定的访问入口,并自动实现负载均衡。Ingress 则在 Service 之上提供七层路由能力,例如根据域名或 URL 路径将请求分发到不同服务。
Job 与 CronJob:批处理任务。 AI 训练本质上是一次性批处理任务,而非长期运行的服务。K8S 的 Job 对象专为此设计——它保证任务运行到成功完成(退出码为 0),支持并行执行和失败重试:
apiVersion: batch/v1
kind: Job
metadata:
name: distributed-training
spec:
completions: 8
parallelism: 8
backoffLimit: 3
template:
spec:
containers:
- name: trainer
image: my-registry/llm-trainer:latest
resources:
limits:
nvidia.com/gpu: 8
restartPolicy: OnFailure11.6.3 K8S 存储系统(CSI)
容器的文件系统是临时的——Pod 被删除后数据即丢失。对于 AI 场景中的模型检查点、训练日志和数据集,需要持久化存储支撑。K8S 通过分层抽象解决了存储的解耦问题。

图 11-22:Kubernetes 存储抽象层。Pod 通过 Volume 挂载存储,PVC 声明存储需求,PV 代表实际存储资源,StorageClass 定义动态供应模板。
核心概念三角。 PersistentVolume(PV)代表集群级别的存储资源,生命周期独立于 Pod;PersistentVolumeClaim(PVC)是用户的存储请求声明,只需指定容量和访问模式,无需关心底层实现;StorageClass(SC)定义了动态供应模板,当 PVC 创建时自动分配 PV。
CSI(Container Storage Interface) 是 K8S 的存储插件标准,允许任何存储供应商编写 CSI 驱动来对接 K8S。在 AI 集群中,常见的存储后端包括:
| 存储类型 | 特点 | 典型场景 |
|---|---|---|
| 本地 NVMe(hostPath) | 极高 IOPS,节点绑定 | 训练数据缓存 |
| 网络文件系统(NFS/CephFS) | 跨节点共享 | 模型检查点、共享数据集 |
| 对象存储(S3/MinIO) | 海量存储,高吞吐 | 大规模数据集、模型归档 |
| 云盘(AWS EBS/阿里云 ESSD) | 高可用,支持快照 | 数据库、有状态服务 |
11.6.4 K8S 网络模型
K8S 网络的核心约束是:每个 Pod 拥有独立 IP,所有 Pod 之间可以直接通信,无需 NAT。这个"扁平网络"模型极大简化了分布式训练中的通信逻辑——训练进程只需知道其他 Pod 的 IP 即可直接建立连接。
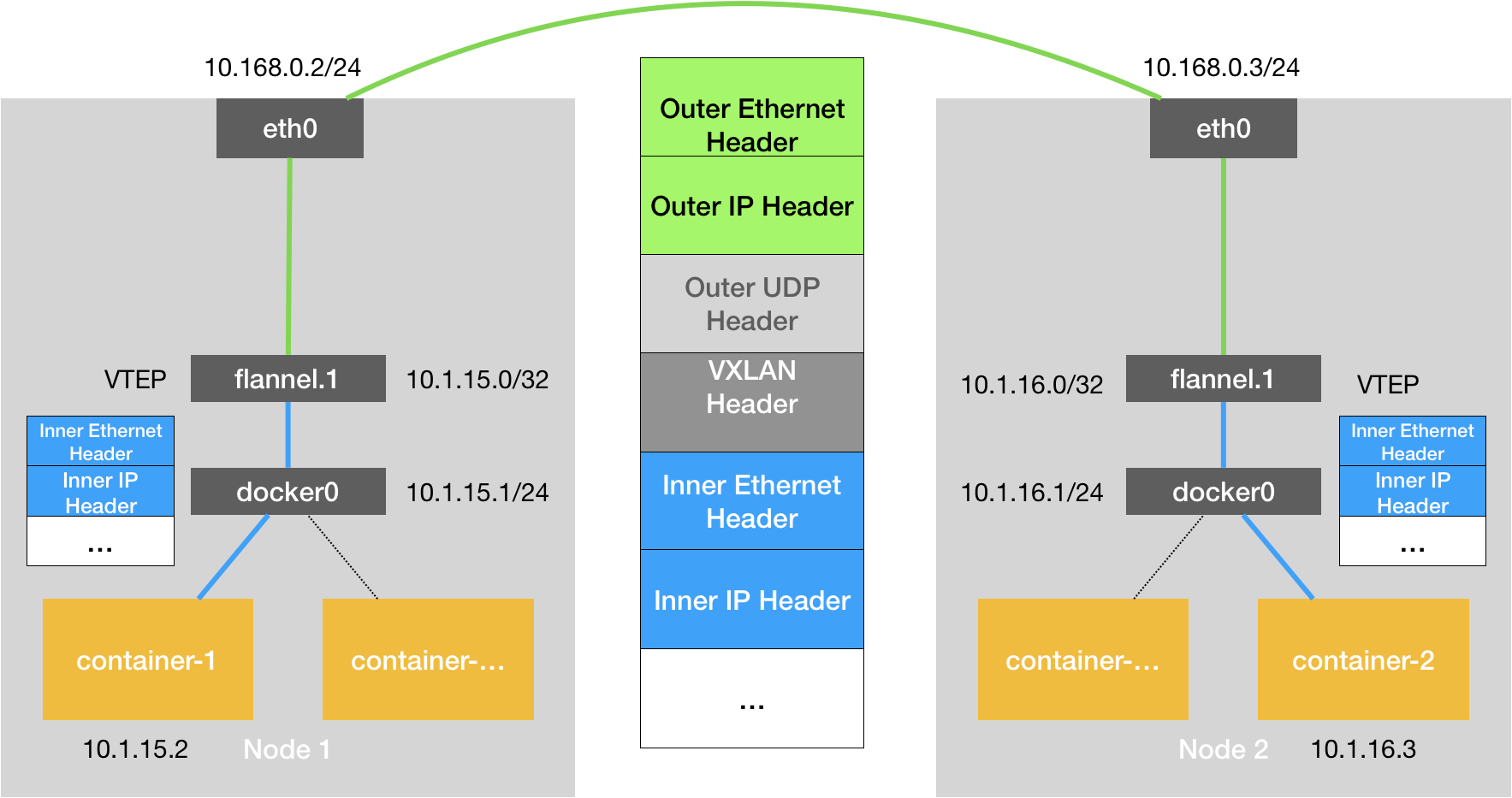
图 11-23:Flannel VXLAN 模式的跨节点通信原理。容器流量经过 docker0 网桥到达 VTEP 设备(flannel.1),被封装在宿主机 IP 包中穿越物理网络,到达目标节点后解封装送达目标容器。
CNI(Container Network Interface) 是 K8S 的网络插件标准,主流实现包括:
- Flannel:最简单的方案,支持 VXLAN(Overlay 封装,兼容性好但有封装开销)和 host-gw(纯路由,性能高但要求二层可达)模式。
- Calico:基于 BGP 协议的纯三层方案,性能接近原生,适合大规模集群。每台宿主机作为虚拟路由器,通过 BGP 传播路由信息。
- Cilium:基于 eBPF 的下一代方案,绕过 iptables 和内核协议栈,提供比传统方案快 5 倍以上的吞吐性能,同时支持 L3/L4/L7 层的细粒度网络策略。
对于 AI 训练集群,高性能网络是关键瓶颈。实际部署中,训练通信通常绑定到 RDMA/InfiniBand 网络(见 §11.4),K8S CNI 网络主要承载管理面流量和推理服务流量。
11.6.5 资源管理与调度
K8S 的调度系统就像集群的"智能大脑",负责将工作负载精准分配到最合适的节点。
资源模型。 每个容器可以声明两个维度的资源需求:
- requests:调度器保证的最低资源量,用于调度决策。
- limits:容器可使用的资源上限,由 Cgroups 强制执行。
CPU 是可压缩资源——不足时 Pod 会变慢但不会被杀;内存是不可压缩资源——超限时 Pod 会被 OOM Kill。K8S 据此定义了三个 QoS 等级:Guaranteed(requests = limits,最高优先级)、Burstable(设置了 requests 但小于 limits)、BestEffort(未设置资源限制,最先被驱逐)。
调度流程。 K8S 调度器的决策过程分为两个阶段:
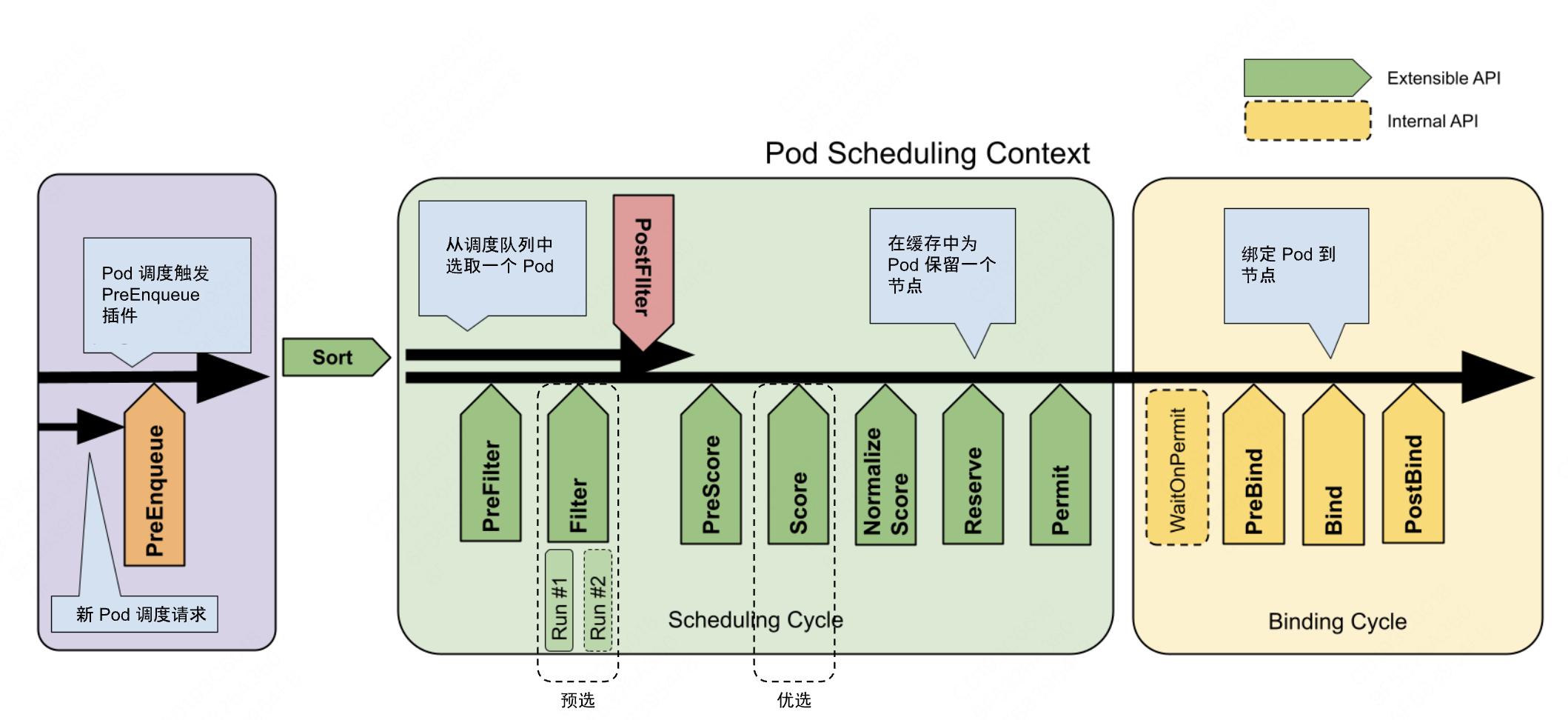
图 11-24:K8S 调度器的工作流程。Scheduling Cycle 包含预选(Filter)和优选(Score)两个阶段;Binding Cycle 负责将 Pod 绑定到选中的节点。
- 预选(Predicates/Filter):排除不满足基本条件的节点——资源不足、端口冲突、不满足节点亲和性规则、存在不可容忍的污点等。
- 优选(Priorities/Score):对通过预选的节点打分,选出最优节点。评分因素包括资源均衡度、数据亲和性、拓扑分布等。
对于 GPU 等非标资源,K8S 通过 Extended Resource 机制支持。例如 NVIDIA GPU Operator 会在每个 GPU 节点上注册 nvidia.com/gpu 资源,调度器据此进行 GPU 感知调度。
抢占机制。 当高优先级 Pod 无法调度时,调度器会尝试驱逐低优先级 Pod 以腾出资源。系统 Pod(优先级 > 10 亿)不会被用户 Pod 抢占。
11.6.6 容器运行时与 CRI
K8S 通过 CRI(Container Runtime Interface) 与底层容器运行时解耦。CRI 定义了两类 gRPC 接口:RuntimeService(管理容器生命周期)和 ImageService(管理镜像拉取与删除)。
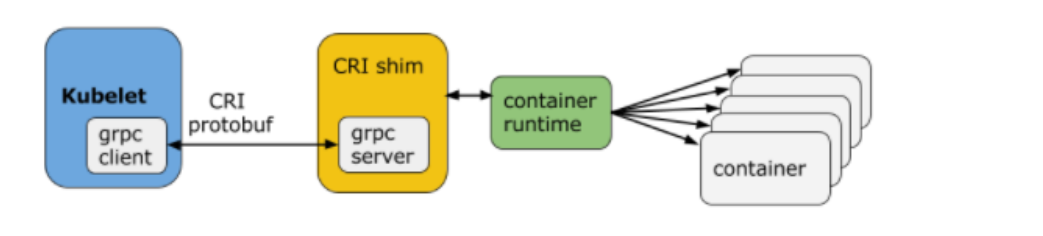
图 11-25:CRI 架构。Kubelet 通过 gRPC 协议与 CRI shim 通信,CRI shim 将请求转发给实际的容器运行时(containerd、CRI-O 等),运行时调用 Linux 内核创建容器。
创建一个 Pod 的完整流程如下:
- Kubelet 调用
RunPodSandbox,创建 Pod 的沙箱环境(Pause 容器),建立共享的 Namespace。 - 调用
CreateContainer,在沙箱内创建业务容器。 - 调用
StartContainer,启动容器进程。 - 运行期间通过
ExecSync/Attach等流式接口支持kubectl exec等交互操作。 - Pod 终止时调用
StopContainer和RemoveContainer清理资源。
主流容器运行时的选择:
| 运行时 | 特点 | 适用场景 |
|---|---|---|
| containerd | 轻量、高性能,K8S 默认推荐 | 大多数生产环境 |
| CRI-O | 专为 K8S 设计,最小化依赖 | Red Hat/OpenShift 生态 |
| Kata Containers | 轻量级虚拟机隔离,安全性更高 | 多租户、安全敏感场景 |
11.6.7 容器监控与日志
大规模 AI 集群需要全方位的可观测性,K8S 的监控与日志体系是运维的"眼睛"。
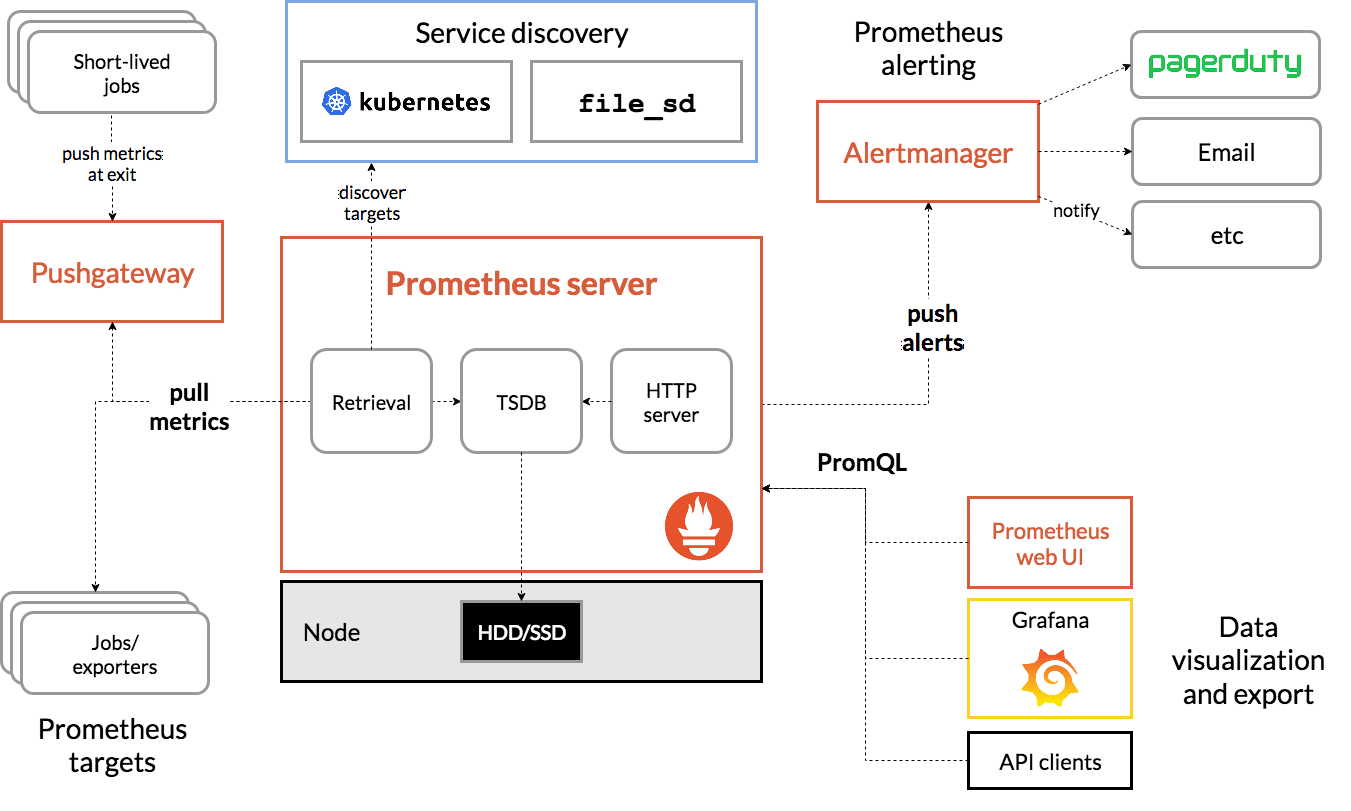
图 11-26:K8S 监控体系架构。cAdvisor 采集容器级指标,Prometheus 拉取并存储时序数据,Alertmanager 处理告警,Grafana 负责可视化。
监控数据采集。 K8S 的监控分为三个层次:
- 节点层:CPU/内存/磁盘/网络使用率,由 Node Exporter 采集。
- 容器层:每个容器的 CPU/内存使用量、重启次数、网络流量,由内置的 cAdvisor 采集。对于 GPU 监控,NVIDIA DCGM Exporter 提供 GPU 利用率、显存使用量、温度等指标。
- 应用层:请求延迟、吞吐量、错误率等业务指标,由应用通过 Client Library 暴露。
Prometheus 是 K8S 生态的监控事实标准。它采用拉取(Pull)模式定期从各个 Exporter 抓取指标,存储在内置的时序数据库(TSDB)中。配合 PromQL 查询语言和 Grafana 可视化面板,运维人员可以实时掌握集群的健康状态。告警配置示例:
groups:
- name: gpu-alerts
rules:
- alert: GPUMemoryNearFull
expr: dcgm_fb_used / dcgm_fb_total > 0.95
for: 5m
labels:
severity: warning
annotations:
summary: "GPU 显存使用率超过 95%"日志收集。 K8S 中容器日志通过 stdout/stderr 输出,由容器运行时写入节点本地的 JSON 文件。常见的日志收集方案有三种:(1)节点级代理(DaemonSet 部署 Fluentd/Filebeat),资源高效但要求应用输出到标准流;(2)Sidecar 容器转发日志文件到标准流;(3)应用直接推送到日志平台。生产环境中通常采用第一种方案,配合 Elasticsearch 或 Loki 实现集中式日志检索。
11.6.8 AI 云平台架构
将上述所有组件整合在一起,就构成了完整的 AI 云平台架构。从底层到上层,整个技术栈可以划分为四层:
| 层次 | 核心组件 | 功能 |
|---|---|---|
| 硬件层 | GPU/TPU/NPU、NVLink/InfiniBand、NVMe SSD | 提供算力、高速互连、高速存储 |
| 资源管理层 | K8S + GPU Operator + CSI/CNI 插件 | 容器编排、GPU 调度、存储/网络管理 |
| 平台服务层 | Kubeflow、KServe、MLflow、WandB | 训练流水线、模型服务、实验追踪 |
| 应用层 | 训练任务、推理服务、数据处理管道 | 直接面向 AI 研究员和工程师 |
在资源管理层,NVIDIA GPU Operator 自动化了 GPU 节点的驱动安装、设备插件部署和监控配置,使得 K8S 能够像管理 CPU 一样管理 GPU 资源。Kubeflow 是 K8S 原生的机器学习平台,提供了分布式训练(TFJob、PyTorchJob)、超参数调优(Katib)、模型服务(KServe)等端到端能力。
本节小结
本节系统介绍了容器与云原生技术在 AI 基础设施中的角色。容器技术的核心是 Linux 内核的三大机制:Namespace(视图隔离)、Cgroups(资源限制)和 Union File System(分层镜像)。Docker 将这三者封装为简洁的用户接口,Kubernetes 在此之上构建了完整的编排体系——Pod 作为最小调度单元,Deployment/Job 管理应用生命周期,CSI/CNI 标准化了存储和网络,CRI 解耦了容器运行时,Prometheus 提供了全方位监控。这些组件协同工作,将物理硬件转化为弹性可调度的"AI 算力池",支撑着从单卡实验到万卡训练的全谱系 AI 工作负载。