16.3 GRPO(群相对策略优化)
上一节介绍了 PPO 如何通过裁剪替代目标和价值网络来稳定策略更新。PPO 的效果已被广泛验证,但它有一个绑定条件:必须同时训练一个与策略模型同等规模的价值网络(Critic)。在大语言模型的尺度下,这意味着显存需求直接翻倍。DeepSeekMath 论文提出了 GRPO(Group Relative Policy Optimization,群相对策略优化),其核心洞察极为简洁——语言模型可以对同一个 prompt 采样多条回复,用组内统计量替代价值网络来估计优势函数,从而彻底去掉 Critic。
GRPO 全书分工导航:
- 本节(§16.3):统一符号、目标函数、优势估计器的数学推导(唯一算法定义处)
- §16.4:工程变体(DAPO、Dr.GRPO、SAPO 等)
- §18.2:RLVR 场景下的端到端管线
- §21.5:Agent 环境接口
- §26.4:代码工程实战(第 26 章,待完成)
16.3.1 从 PPO 到 GRPO:去掉价值网络
回顾 PPO 的训练流水线:给定 prompt
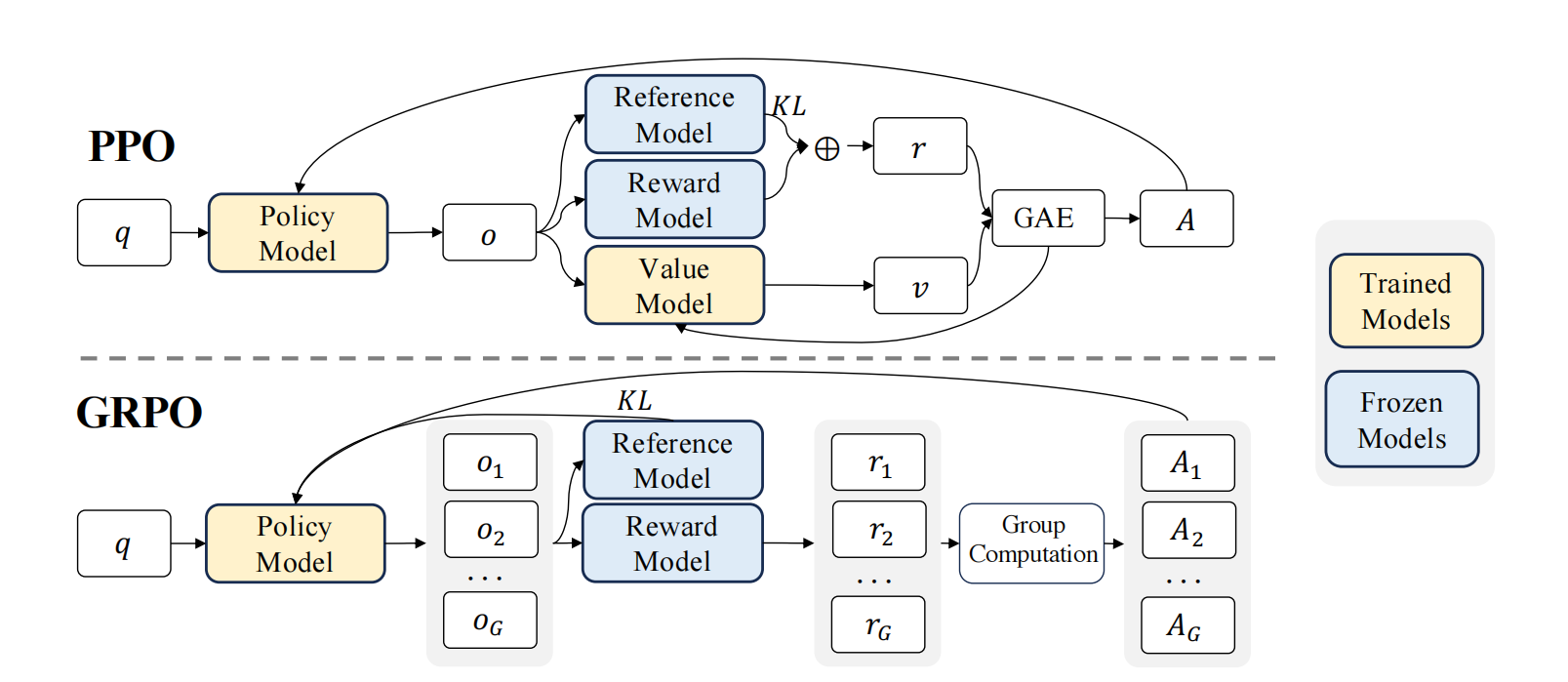
图 16-3:PPO 与 GRPO 架构对比。上半部分是 PPO 流程,需要额外训练 Value Model;下半部分是 GRPO 流程,对同一 prompt 采样 G 条回复,通过 Group Computation 直接得到优势。
GRPO 的改动可以归结为一句话:用"同一 prompt 下多条回复的相对排名"替代"价值网络对状态价值的预测"。具体来说:
| 对比维度 | PPO | GRPO |
|---|---|---|
| 优势估计来源 | 学习的价值函数 | 组内经验均值 |
| 需要的模型数 | 4(策略 + 参考 + 奖励 + 价值) | 3(策略 + 参考 + 奖励) |
| 显存占用 | ~2× 策略模型 | ~1× 策略模型 |
| 优势粒度 | token 级(GAE 逐步递推) | 回复级(同一回复内所有 token 共享) |
| 适用场景 | 通用 RL | 可对同一输入多次采样的场景(LLM) |
表 16-1:PPO 与 GRPO 核心对比。
GRPO 之所以能去掉价值网络,依赖于语言模型的一个结构性优势:给定同一个 prompt,可以低成本地采样出多条不同回复。这些回复的奖励均值天然构成了对状态价值
当组大小
16.3.2 分组相对优势估计 [必读]
GRPO 的优势估计器是整个算法的核心。给定一个 prompt
其中
直觉解释:
需要特别注意的是,这个优势是回复级别的——同一条回复的所有 token 共享同一个
下面用 Python 从零实现组优势计算:
import torch
def compute_group_advantages(rewards: torch.Tensor, epsilon: float = 1e-5) -> torch.Tensor:
"""
计算 GRPO 的分组相对优势。
Args:
rewards: 形状 [batch_size, group_size],每个 prompt 的 G 条回复的奖励
epsilon: 防止除零的小常数
Returns:
advantages: 形状 [batch_size, group_size],归一化后的优势值
"""
# 组内均值作为基线:[batch_size, 1]
group_mean = rewards.mean(dim=1, keepdim=True)
# 组内标准差:[batch_size, 1]
group_std = rewards.std(dim=1, keepdim=True)
# 标准化
advantages = (rewards - group_mean) / (group_std + epsilon)
return advantages
# ---- 数值示例 ----
rewards = torch.tensor([
[1.0, 2.0, 0.5, 1.5], # Prompt 1:4 条回复
[5.0, 6.0, 5.5, 7.0], # Prompt 2:4 条回复
])
advantages = compute_group_advantages(rewards)
print("Rewards:\n", rewards)
print("Advantages:\n", advantages)
# Prompt 1: mean=1.25, std≈0.65 → [-0.39, 1.16, -1.16, 0.39]
# Prompt 2: mean=5.875, std≈0.85 → [-1.03, 0.15, -0.44, 1.32]从输出可以看到,尽管 Prompt 2 的所有奖励绝对值都远高于 Prompt 1,归一化后的优势幅度却相当——这正是标准差归一化的效果:使不同难度的 prompt 对梯度产生大致相同的贡献。
16.3.3 GRPO 目标函数的完整推导 [必读]
有了优势估计,接下来构造完整的 GRPO 目标函数。GRPO 继承了 PPO 的裁剪替代目标,并在外层加上 KL 散度正则项,以防止策略偏离参考模型过远。
符号约定。 令
概率比率(Importance Ratio):
裁剪替代目标(Clipped Surrogate Objective):
KL 散度近似(Schulman 估计器):
这个近似器由 Schulman (2020) 提出。令
,则 。它是非负的(因为 ,等号当且仅当 ),并且在 时恰好为 0,满足 KL 散度的基本性质。
完整的 GRPO 目标函数(DeepSeekMath 原始版本):
对应的损失函数(取负号以转化为最小化问题):
当仅执行单次更新(
这里
16.3.4 GRPO 损失的从零实现
下面用 PyTorch 实现一个完整的 GRPO 损失计算,包含组优势、KL 散度和裁剪目标。
import torch
import torch.nn.functional as F
def grpo_loss(
logps: torch.Tensor, # [B*G, T] 当前策略的 per-token log prob
old_logps: torch.Tensor, # [B*G, T] 旧策略的 per-token log prob(采样时记录)
ref_logps: torch.Tensor, # [B*G, T] 参考模型的 per-token log prob
rewards: torch.Tensor, # [B, G] 每条回复的标量奖励
completion_mask: torch.Tensor, # [B*G, T] 1=回复 token, 0=prompt/pad
epsilon: float = 0.2, # PPO 裁剪系数
beta: float = 0.01, # KL 惩罚系数
advantage_eps: float = 1e-5, # 优势计算的防除零常数
) -> torch.Tensor:
"""
GRPO 损失函数(含裁剪目标 + KL 正则)。
Returns:
标量损失值
"""
B, G = rewards.shape
T = logps.shape[1]
# --- Step 1: 组优势估计 ---
group_mean = rewards.mean(dim=1, keepdim=True) # [B, 1]
group_std = rewards.std(dim=1, keepdim=True) # [B, 1]
advantages = (rewards - group_mean) / (group_std + advantage_eps) # [B, G]
# 展平并扩展到 token 维度:[B*G] -> [B*G, 1] -> 广播到 [B*G, T]
advantages_flat = advantages.reshape(B * G).unsqueeze(1) # [B*G, 1]
# --- Step 2: 概率比率与裁剪 ---
ratio = torch.exp(logps - old_logps) # [B*G, T]
surr1 = ratio * advantages_flat # 未裁剪
surr2 = torch.clamp(ratio, 1.0 - epsilon, 1.0 + epsilon) * advantages_flat
clipped_obj = torch.min(surr1, surr2) # [B*G, T]
# --- Step 3: KL 散度近似(Schulman 估计器) ---
log_ratio = ref_logps - logps # log(π_ref / π_θ)
kl = torch.exp(log_ratio) - log_ratio - 1.0 # [B*G, T]
# --- Step 4: 逐 token 损失 = -(裁剪目标 - β·KL) ---
per_token_loss = -(clipped_obj - beta * kl) # [B*G, T]
# 仅对回复部分求均值
masked_loss = (per_token_loss * completion_mask).sum() / completion_mask.sum()
return masked_loss这段代码完整覆盖了公式 (16.10) 的每一步。读者可以对照公式逐行验证。
16.3.5 退化组问题与缓解策略 [必读]
分组相对优势估计简洁有效,但当组内所有回复的奖励相同时,
退化组何时出现? 两类典型场景:
- 过于简单的 prompt:所有
条回复都答对,奖励全为 1。 - 过于困难的 prompt:所有回复都答错,奖励全为 0。
在这两种情况下,
问题影响:
- 零方差组:
,分子也为 0, ,组内完全没有学习信号。 - 极小方差组:
,微小的奖励差异被放大 100 倍,梯度失控。
TRL 框架报告了一个名为 frac_reward_zero_std 的指标,专门监控退化组的比例。当该比例较高时,训练效率会显著降低。
缓解策略:
| 策略 | 原理 | 适用场景 |
|---|---|---|
| 增大组大小 | 更多采样 → 更大概率出现差异化回复 | 通用,但增加计算量 |
| 课程学习数据筛选 | 只选"有挑战但可学"的题目(pass rate 在 0~1 之间) | 数学/代码等可验证奖励场景 |
| 去除标准差归一化 | 直接用 | Dr.GRPO 推荐 |
| batch 级标准差 | 均值在组内算,标准差在整个 batch 算 | 减少极端放大效应 |
下面的代码展示不同优势模式的实现与对比:
import torch
def compute_advantages(rewards: torch.Tensor, mode: str = "normalized",
epsilon: float = 1e-5) -> torch.Tensor:
"""
三种优势估计模式对比。
Args:
rewards: [batch_size, group_size]
mode: "raw" / "centered" / "normalized"
Returns:
advantages: [batch_size, group_size]
"""
if mode == "raw":
# 朴素策略梯度:直接用奖励(无基线)
return rewards
group_mean = rewards.mean(dim=1, keepdim=True)
if mode == "centered":
# Dr.GRPO 推荐:只减均值,不除标准差
return rewards - group_mean
if mode == "normalized":
# 标准 GRPO:减均值 + 除标准差
group_std = rewards.std(dim=1, keepdim=True)
return (rewards - group_mean) / (group_std + epsilon)
raise ValueError(f"Unknown mode: {mode}")
# ---- 退化组演示 ----
rewards_degenerate = torch.tensor([
[1.0, 1.0, 1.0, 1.0], # 全对:退化组
[0.0, 0.0, 0.0, 0.0], # 全错:退化组
[0.0, 1.0, 0.0, 1.0], # 正常组
])
for mode in ["raw", "centered", "normalized"]:
adv = compute_advantages(rewards_degenerate, mode=mode)
print(f"[{mode:>10s}] advantages =\n{adv}\n")运行结果会清晰展示:raw 模式下退化组仍有非零值(但没有区分度);centered 模式下退化组优势全为 0(正确行为);normalized 模式在正常组上效果好,但退化组的极小分母可能导致数值问题。
16.3.6 标准差归一化的理论争议 [选读]
标准的策略梯度定理允许从奖励中减去任意只依赖状态(prompt)的基线函数
这里
Dr.GRPO 论文指出了标准差归一化带来的两个具体问题:
问题一:难度偏差(Difficulty Bias)。 对于简单的 prompt,所有回复奖励接近(
问题二:长度偏差(Length Bias)。 原始 GRPO 公式中的
- 答错时(
):更长的回复 → 每 token 惩罚更小 → 模型倾向生成冗长的错误回答以"稀释"惩罚。 - 答对时(
):更长的回复 → 每 token 奖励更小 → 模型倾向生成极短的正确回答以"集中"奖励。
这两个偏差共同作用,可能导致训练中回复长度异常波动。Dr.GRPO 论文的建议是:移除标准差归一化,改用
16.3.7 GRPO 训练流程总览

图 16-4:GRPO 迭代训练算法伪代码(来自 DeepSeekMath 论文)。
结合算法伪代码,GRPO 的完整训练流程可以分为四个阶段:
- 采样阶段:对每个 prompt
,用当前策略 生成 条回复 。 - 评分阶段:用奖励函数(或奖励模型)为每条回复打分,得到
。 - 优势计算:按公式 (16.5) 计算组内相对优势
。 - 策略更新:执行
轮梯度下降,每轮用裁剪目标 + KL 正则更新策略参数 。
当
16.3.8 小结
本节从 PPO 的资源瓶颈出发,推导了 GRPO 的完整数学框架。核心要点如下:
- 分组相对优势:
,用组内统计量替代价值网络,省去 Critic 的训练与显存开销。 - 目标函数:在 PPO 裁剪替代目标的基础上,使用 Schulman KL 近似器作为正则项,平衡探索与稳定性。
- 退化组问题:当组内奖励无差异时学习信号消失,需要通过增大组大小、课程数据筛选或去除标准差归一化来缓解。
- 理论局限:标准差归一化不受策略梯度定理保证,可能引入难度偏差和长度偏差,实践中需谨慎选择。
GRPO 的数学框架已被 DeepSeek-R1、Kimi K1.5、Qwen 3 等主流推理模型验证有效。下一节将介绍在此基础上演化出的工程变体(DAPO、Dr.GRPO、SAPO),它们针对上述理论局限提出了各自的修正方案。