20.4 排行榜与竞技场
前一节梳理了各类评估基准的设计理念,但一个不可回避的问题是:当我们拥有几十个甚至上百个基准时,如何把这些分散的评测结果汇聚成一个全局排名? 静态基准衡量的是模型在特定任务上的绝对表现,而排行榜(Leaderboard)则试图回答一个更直接的问题——"在一众模型中,谁更好?"
本节将深入两种主流的排名方法:源自国际象棋的 Elo 评分系统和统计建模视角下的 Bradley-Terry 模型,并以 Chatbot Arena(LM Arena)为核心案例,剖析人类偏好驱动的排行榜是如何构建、运转和演进的。
20.4.1 从基准分数到配对比较
传统排行榜的做法很直观:在若干基准上跑分,然后按平均分排序。HELM 就是这一思路的代表——它将 MMLU、MATH、HumanEval 等基准聚合在一起,为每个模型计算综合得分。
但平均分排名有一个根本性缺陷:不同基准的分数不可直接比较。MMLU 上的 90 分与 GPQA 上的 40 分,哪个更能体现模型实力?权重如何分配?这些问题没有客观答案。
配对比较(Pairwise Comparison)提供了一条不同的路径。与其让模型独立解题再比分,不如让两个模型同时回答同一个问题,由人类(或自动评判器)直接选出更好的那个。大量配对比较累积起来,就能建立起模型之间的相对实力关系——这正是 Chatbot Arena 的核心思路。
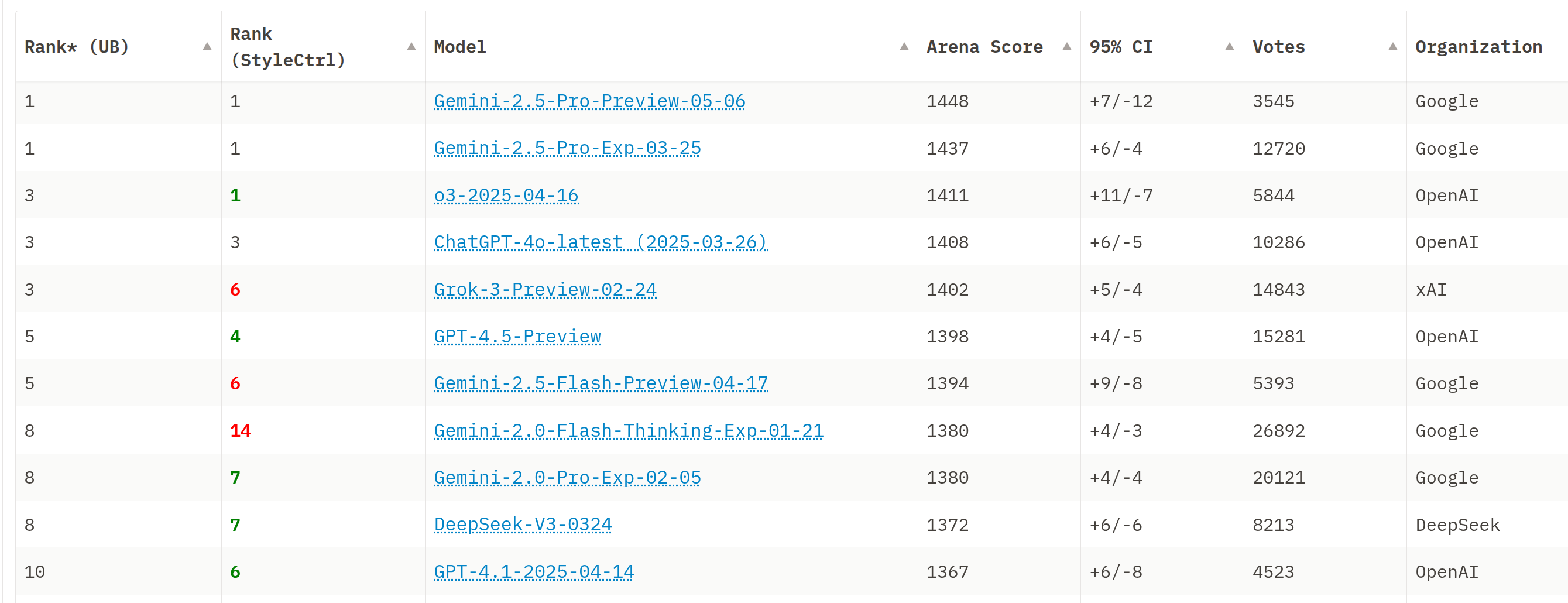
图 20-8:Chatbot Arena 排行榜。每个模型的 Arena Score 由大量匿名配对投票计算得出,95% CI 列给出了分数的置信区间,Votes 列显示该模型参与的总投票数。
配对比较的数据可以表示为一组二元组列表,每个元素 (winner, loser) 记录一次比较的结果:
# 模拟的配对投票数据:(胜方, 败方)
votes = [
("GPT-5", "Claude-3"), # GPT-5 被偏好
("GPT-5", "Llama-4"),
("Claude-3", "Llama-3"),
("Llama-4", "Llama-3"),
("Claude-3", "Llama-3"),
("GPT-5", "Llama-3"),
]接下来的问题是:如何从这些离散的胜负记录中推算出每个模型的"实力分数"?
20.4.2 Elo 评分系统
Elo 评分(Elo Rating)是最经典的配对排名算法,由匈牙利裔美国物理学家 Arpad Elo 于 1960 年代为国际象棋发明。其核心思想极为优雅:每个选手持有一个数值评分,比赛结果会根据预期胜率与实际结果的偏差来更新评分。
预期胜率。 给定模型 A 的评分
这是一个 Sigmoid 函数,其行为非常直观:
| 情况 | 指数项 | 含义 | |
|---|---|---|---|
| 极大负数 | A 几乎必胜 | ||
| 势均力敌 | |||
| 极大正数 | A 几乎必败 |
表 20-3:Elo 预期胜率的直觉。分差 400 分对应约 10:1 的胜率比。
其中常数 400 定义了尺度:分差 400 分意味着强者的预期胜率约为 91%(即 10:1 的胜负比)。
评分更新。 每场比赛结束后,根据实际结果
参数
完整实现。 以下是一个自包含的 Elo 评分系统实现:
import json
def elo_ratings(vote_pairs, k_factor=32, initial_rating=1000):
"""从配对投票数据计算 Elo 评分"""
# 初始化所有模型为相同基础分
ratings = {
model: initial_rating
for pair in vote_pairs
for model in pair
}
# 逐条处理投票,更新评分
for winner, loser in vote_pairs:
# 计算胜者的预期胜率
expected = 1.0 / (
1.0 + 10 ** ((ratings[loser] - ratings[winner]) / 400.0)
)
# 更新双方评分
ratings[winner] += k_factor * (1 - expected)
ratings[loser] += k_factor * (0 - (1 - expected))
return ratings
# 使用示例
votes = [
("GPT-5", "Claude-3"),
("GPT-5", "Llama-4"),
("Claude-3", "Llama-3"),
("Llama-4", "Llama-3"),
("Claude-3", "Llama-3"),
("GPT-5", "Llama-3"),
]
ratings = elo_ratings(votes, k_factor=32, initial_rating=1000)
for model in sorted(ratings, key=ratings.get, reverse=True):
print(f"{model:10s} : {ratings[model]:.1f}")
# 输出:
# GPT-5 : 1043.7
# Claude-3 : 1015.2
# Llama-4 : 1000.7
# Llama-3 : 940.4Elo 系统的最大优点是在线性(Online)——新模型只需与已有模型进行少量配对比较即可融入排行榜,无需让所有模型两两对决。但它也有明显局限:评分依赖于比赛的顺序。将同一批投票以不同顺序输入,最终评分会略有差异。此外,Elo 隐含地假设模型实力在所有投票期间保持不变,这对于不断更新迭代的语言模型来说并不完全成立。
20.4.3 Bradley-Terry 模型
为了克服 Elo 系统的顺序依赖问题,Chatbot Arena 后来转向了 Bradley-Terry 模型(简称 BT 模型)。这是一个于 1952 年由 Ralph Bradley 和 Milton Terry 提出的统计模型,它不逐条处理投票,而是一次性利用全部数据通过最大似然估计(Maximum Likelihood Estimation, MLE)来拟合模型实力参数。
模型定义。 为每个模型
其中
参数拟合。 给定
最大化这个目标等价于最小化负对数似然损失。由于
PyTorch 实现。 以下代码使用 Adam 优化器拟合 BT 模型,并将结果转换为 Elo 量级的分数:
import math
import torch
def bradley_terry(vote_pairs, lr=0.01, epochs=500):
"""使用梯度下降拟合 Bradley-Terry 模型"""
# 收集所有模型名称并编号
models = sorted({m for pair in vote_pairs for m in pair})
n = len(models)
idx = {m: i for i, m in enumerate(models)}
# 将投票转换为索引张量
winners = torch.tensor([idx[w] for w, _ in vote_pairs])
losers = torch.tensor([idx[l] for _, l in vote_pairs])
# 可学习参数:n-1 个自由参数(最后一个固定为 0 作为锚点)
theta = torch.nn.Parameter(torch.zeros(n - 1))
optimizer = torch.optim.Adam([theta], lr=lr, weight_decay=1e-4)
def scores():
return torch.cat([theta, torch.zeros(1)])
# 优化循环
for _ in range(epochs):
s = scores()
delta = s[winners] - s[losers]
loss = -torch.nn.functional.logsigmoid(delta).mean()
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# 将潜在分数转换为 Elo 量级
with torch.no_grad():
s = scores()
scale = 400.0 / math.log(10.0) # 自然对数到 log10 的尺度因子
R = s * scale
R -= R.mean()
R += 1000.0 # 居中到 1000
return {m: float(r) for m, r in zip(models, R.tolist())}
# 使用同一批投票数据
ratings_bt = bradley_terry(votes)
for model in sorted(ratings_bt, key=ratings_bt.get, reverse=True):
print(f"{model:10s} : {ratings_bt[model]:.1f}")
# 输出(参考值,因优化随机性可能略有浮动):
# GPT-5 : 1140.6
# Claude-3 : 1058.7
# Llama-4 : 950.3
# Llama-3 : 850.4与 Elo 的核心差异。 下表总结了两种方法的关键对比:
| 特征 | Elo 评分 | Bradley-Terry 模型 |
|---|---|---|
| 数据处理方式 | 逐条在线更新 | 批量最大似然估计 |
| 顺序依赖性 | 有(不同顺序产生不同结果) | 无(结果仅由数据集整体决定) |
| 统计基础 | 启发式更新规则 | 严格的概率模型 + MLE |
| 不确定性估计 | 不直接提供 | 可通过 Bootstrap 获得置信区间 |
| 计算成本 | 极低( | 较高(需迭代优化) |
| 新模型加入 | 自然支持 | 需要重新拟合整个模型 |
表 20-4:Elo 评分与 Bradley-Terry 模型的对比。LM Arena 最初使用 Elo,后切换至 BT 模型以获得更稳定的排名和置信区间。
20.4.4 Chatbot Arena 的运作机制
Chatbot Arena(原名 LMSYS Chatbot Arena,现更名为 LM Arena)是目前最具影响力的人类偏好排行榜。它由 UC Berkeley 的 LMSYS 团队于 2023 年推出,至今已积累数百万条投票数据。
用户交互流程。 整个流程包含五个步骤:
- 用户输入 Prompt——任何人都可以通过网页提交问题。
- 获得两个匿名回复——系统从模型池中随机选取两个模型生成回答,但不告知用户模型身份。
- 用户投票——选择"A 更好""B 更好""平局"或"都不好"。
- 揭示模型身份——投票完成后,系统才公布两个模型的名称。
- 累积数据——大量配对比较数据被汇聚,定期重新拟合 Bradley-Terry 模型并更新排行榜。
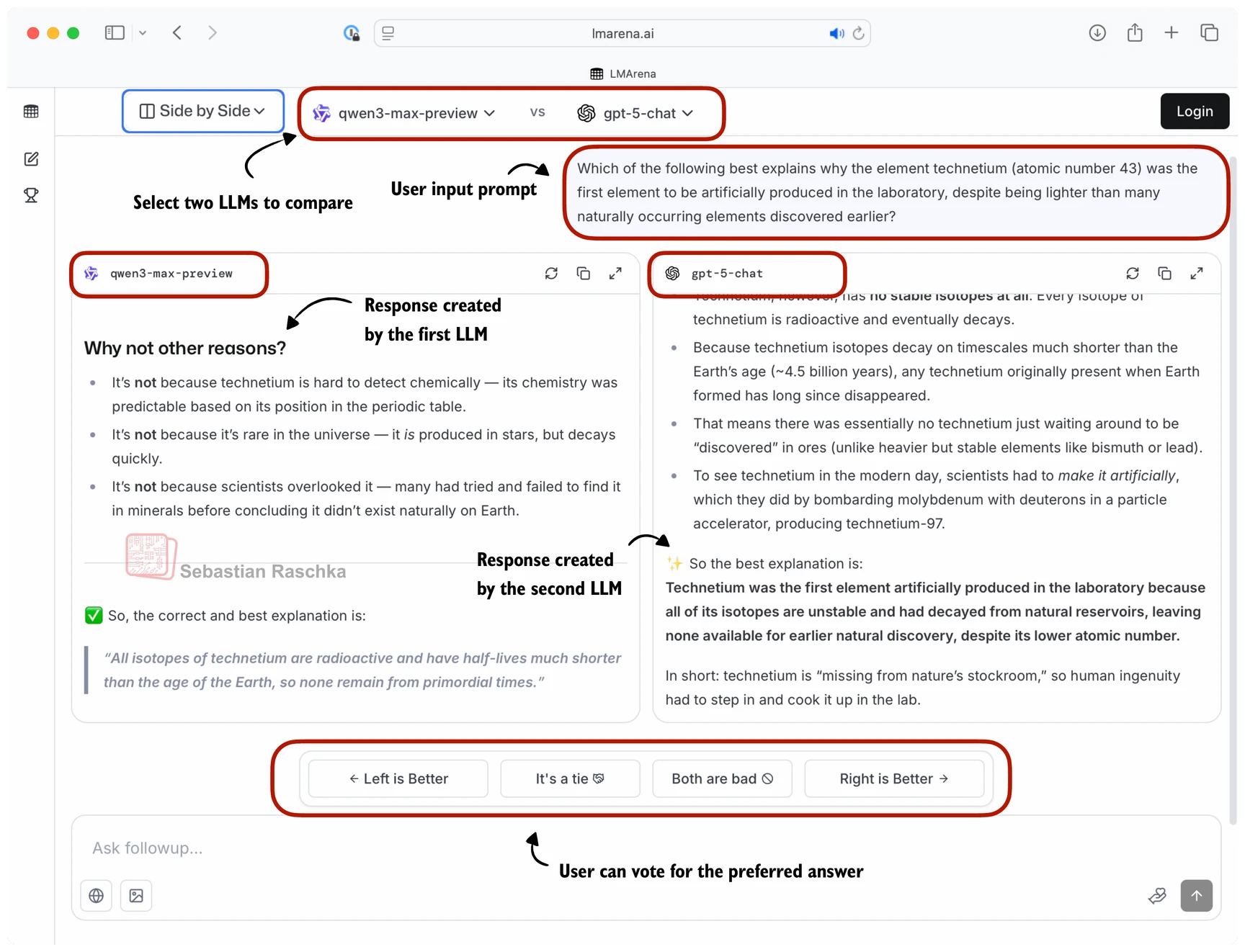
图 20-9:LM Arena 的配对比较界面。用户在不知道模型身份的情况下进行投票,避免了品牌偏见对评估结果的干扰。
从 Elo 到 BT 的演进。 Chatbot Arena 最初使用 Elo 评分系统计算排名。但随着投票量的增长和对统计严谨性要求的提高,团队在 2024 年切换到了 Bradley-Terry 模型。其官方论文(Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference, arXiv: 2403.04132)详细描述了这一转变。BT 模型的优势在于可以通过 Bootstrap 方法估计每个模型得分的95% 置信区间(如排行榜中的 95% CI 列所示),为排名的统计显著性提供了保障。
为何 Chatbot Arena 重要? 许多自动化评估基准(如 AlpacaEval、WildBench)都以与 Chatbot Arena 的相关性作为衡量自身有效性的标准:
| 自动化基准 | 与 Chatbot Arena 的相关性 |
|---|---|
| WildBench | |
| AlpacaEval(长度校正版) | |
| MMLU | 较低 |
表 20-5:自动化基准与 Chatbot Arena 人类偏好排名的相关性。高相关性意味着该基准能较好地预测人类偏好。
这实际上形成了一种"元评估"(evaluation of evaluation)——人类偏好排行榜已成为衡量其他基准是否有效的基准。
20.4.5 排行榜的局限与争议
尽管 Chatbot Arena 被广泛视为指令遵循评估的"事实标准",它并非没有问题。
The Leaderboard Illusion(排行榜幻觉)。 2024 年的同名论文揭示了一系列协议层面的隐患:部分模型提供者获得了多次提交机会和特权访问;评估协议的某些环节缺乏透明度;在知晓规则的情况下,排名存在被策略性操控(Gaming)的可能。
用户分布偏见。 Chatbot Arena 的投票来自"网络上随机访问的人",但这个群体的分布并不均匀——技术用户偏多、英语用户偏多、可能刻意测试边缘情况而非典型用例。投票质量也难以保证:用户是否真正仔细阅读了两个回复?是否存在长度偏见(更长的回复被系统性偏好)?AlpacaEval 早期版本就曾因长度偏见被小模型钻了空子,后来不得不引入长度校正。
成本盲区。 排行榜通常只比较质量,不考虑推理成本。一个需要 10 倍算力才能略微领先的模型,在实际部署中可能并非最优选择。Artificial Analysis 等平台试图通过"智能指数 vs 每 Token 价格"的帕累托前沿来弥补这一空白。
顺序效应与位置偏见。 在配对展示中,左侧(A 位)的回复可能获得系统性偏好。Chatbot Arena 通过随机化模型在 A/B 位的分配来缓解这一问题,但仍需持续监控和校正。
20.4.6 超越单一排行榜
认识到上述局限后,评估社区正朝着更精细化的方向发展。
分类排行榜。 LM Arena 已推出按领域细分的排行榜——编程、数学、多语言、长上下文等,因为一个模型在编程任务上的优势不一定能迁移到创意写作。
多信号融合。 将人类偏好(Chatbot Arena)、自动化基准(HELM、OpenCompass)、真实使用数据(OpenRouter 流量排名)、以及专家深度评估结合起来,才能构建更完整的模型画像。没有任何单一指标能告诉你全部真相。
动态与持续评估。 与静态基准不同,排行榜天然具备动态性——新模型可以随时加入,新投票持续流入。这种"活的"评估方式能更好地跟踪模型的快速迭代,但也要求更严格的协议管理和统计方法来保证结果的可靠性。
本节小结
排行榜与竞技场为"模型谁更好"这一核心问题提供了系统化的回答框架。Elo 评分以优雅的在线更新规则实现了从配对比较到全局排名的转换,Bradley-Terry 模型则以严格的概率建模克服了顺序依赖性并提供了不确定性估计。Chatbot Arena 将这些统计工具与大规模人类偏好数据结合,建立起当前最具影响力的 LLM 排行榜。然而,排行榜并非终极真相——用户偏见、协议漏洞、成本盲区等问题提醒我们,评估是一个需要持续改进的系统工程,任何单一排名都应与其他评估维度交叉验证。