18.6 推理模型蒸馏
经过前几节的深入讨论,我们已经掌握了训练推理模型的核心技术栈:RLVR 提供了可验证的奖励信号(§18.1),GRPO 管线实现了从采样到策略更新的完整循环(§18.2),策略优化进阶解决了训练中的监控与调参问题(§18.3),异步 Rollout 打破了生成与训练的串行瓶颈(§18.4)。但所有这些 RL 训练方法都有一个共同的隐含前提——模型本身需要足够大,才能通过自我探索涌现出推理能力。
那么问题来了:如果我们的目标是让一个 0.6B 或 1.5B 的小模型也能"思考",该怎么办?
答案是推理模型蒸馏(Reasoning Model Distillation)。DeepSeek-R1 论文中的一个关键实验结论揭示了其威力:在 Qwen-32B 上,使用 R1 的 800k 条蒸馏数据做 SFT 训练,AIME 2024 准确率达到 72.6%;而直接对同一小模型做大规模 RL 训练,仅得 47.0%。蒸馏全面碾压纯 RL。这一发现深刻影响了整个推理模型训练的技术路线选择。
第 14 章已系统讲解了蒸馏的基本原理——黑盒蒸馏(§14.1)、白盒蒸馏(§14.2)、推理蒸馏的数据结构与训练流程(§14.3)。本节不重复这些基础内容,而是站在第 18 章"训练推理模型"的视角,聚焦三个实战问题:蒸馏在 R1 训练流水线中的定位、蒸馏 vs 纯 RL 的工程决策、以及一条可落地的蒸馏训练配方。
18.6.1 蒸馏在 R1 四阶段流水线中的定位
回顾 §18.1 中介绍的 DeepSeek-R1 完整训练流水线(图 18-5),整个训练过程可以划分为四个阶段:
| 阶段 | 名称 | 核心操作 | 目标 |
|---|---|---|---|
| 1 | 冷启动 SFT | 用少量高质量长 CoT 数据做监督微调 | 为 RL 训练提供稳定的起点 |
| 2 | 推理导向 RL | GRPO + 规则奖励 + 语言一致性奖励 | 涌现深度思考能力 |
| 3 | 拒绝采样 + 通用 SFT | 从 RL 模型采样优质回答,结合通用数据做 SFT | 平衡推理能力与通用能力 |
| 4 | 最终 RL 对齐 | 再次 RL,同时包含推理奖励和偏好奖励 | 兼顾推理质量与对齐安全 |
表 18-6:DeepSeek-R1 的四阶段训练流水线。
蒸馏出现在流水线的两个关键位置:
第一个位置:阶段 1 的冷启动数据来源。 在 R1-Zero 实验中,研究者发现从零开始做纯 RL 训练虽然能涌现推理能力,但训练极不稳定——模型可能经历数千步的"无用探索"才找到正确的思考模式。因此 R1 的正式训练在第一阶段使用了数千条由更大模型生成的长思维链数据做冷启动 SFT,本质上就是一次小规模的推理蒸馏。这些"种子数据"教会模型基本的推理格式(<think>...</think> 标签的使用)和初步的思考模式,为后续 RL 训练提供一个远优于随机起点的初始策略。
第二个位置:训练完成后的能力下放。 R1(671B)训练完成后,研究者使用其生成的 800k 条推理轨迹数据,对 Qwen-1.5B/7B/14B/32B、Llama-8B/70B 等多个小模型进行 SFT 蒸馏。这一步的目标是将大模型经过 RL 训练后获得的高质量推理能力,以最低成本迁移到部署友好的小模型上。
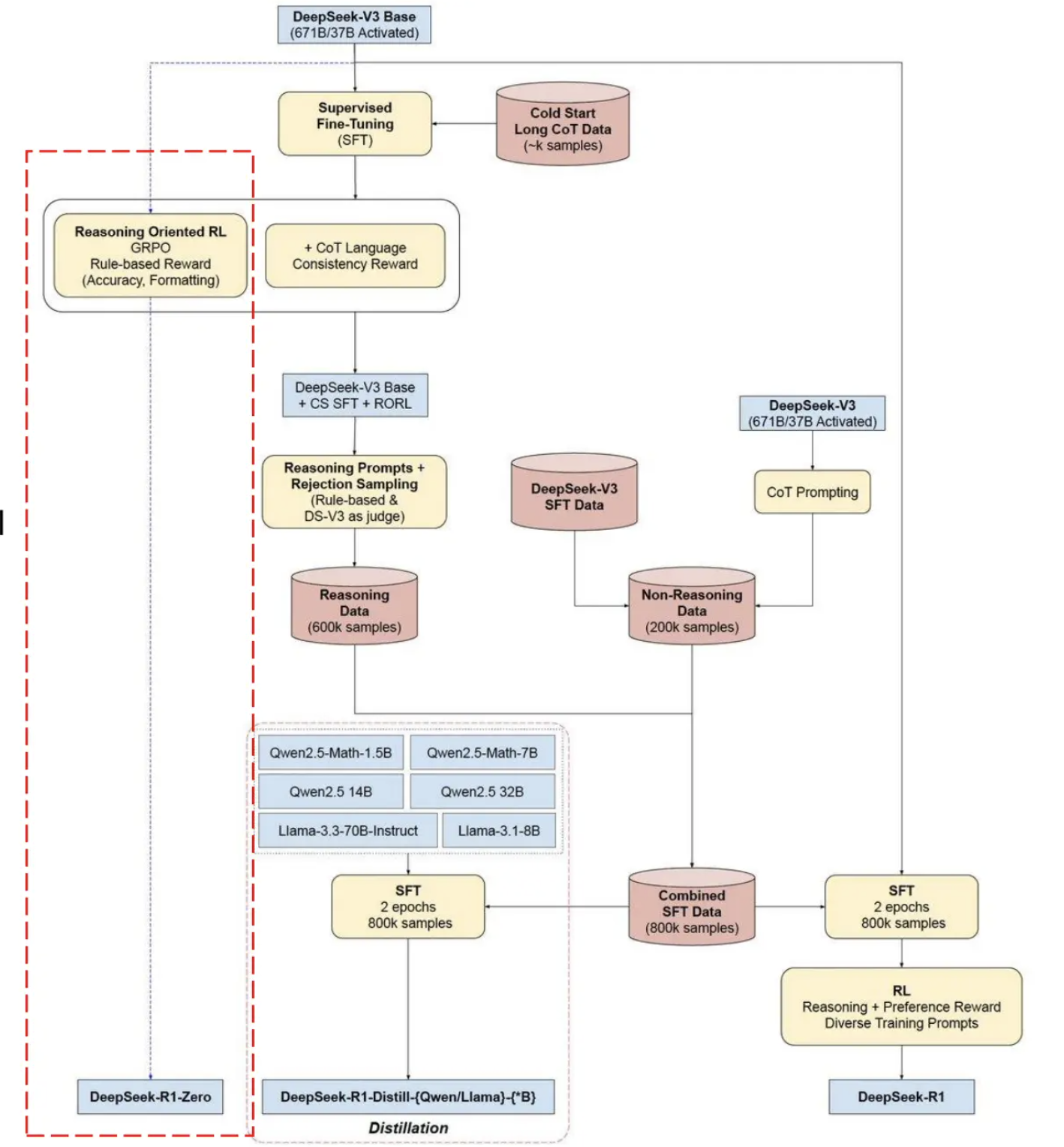
图 18-9(复用自 §18.1 图示):DeepSeek-R1 训练流水线全景。左侧红色虚线框为 R1-Zero 的纯 RL 路径;下方为蒸馏路径——将大模型的推理数据用于训练多个小模型。蒸馏既是大模型训练的起点(冷启动 SFT),也是其终点(能力下放)。
这两个位置揭示了一个重要的工程洞察:蒸馏与 RL 不是替代关系,而是互补关系。 RL 用于在大模型上"发现"推理能力,蒸馏用于"传播"推理能力。完整的推理模型训练管线,本质上是一条"RL 探索 → 蒸馏传播"的知识生产链路。
18.6.2 蒸馏 vs 纯 RL:工程决策框架
在实际项目中,"用蒸馏还是用 RL"往往是第一个需要回答的决策问题。下表从多个维度对比两条路线,帮助你做出判断:
| 维度 | 蒸馏路线 | 纯 RL 路线 |
|---|---|---|
| 计算成本 | 低。仅需 SFT 训练 + 教师推理生成 | 高。需要持续采样 + 梯度更新 |
| 训练稳定性 | 高。标准 SFT 流程,loss 单调下降 | 低。存在熵崩溃、奖励劫持等风险 |
| 质量上限 | 受教师模型能力限制 | 理论上无上限(但实践中受探索效率限制) |
| 对模型规模的要求 | 友好。小模型也能获得显著提升 | 苛刻。过小的模型难以通过 RL 涌现推理 |
| 数据依赖 | 依赖高质量教师数据 | 仅需 prompt + 验证器 |
| 可控性 | 强。数据可审查、可过滤 | 弱。模型行为由探索过程决定 |
表 18-7:蒸馏 vs 纯 RL 的工程决策对比。
决策建议。 根据 DeepSeek-R1 的实验数据和社区实践经验,可以总结出以下决策规则:
- 模型参数量 < 7B:优先选择蒸馏。小模型的探索空间不足以通过 RL 自发涌现推理能力,蒸馏是获取推理能力的最可靠路径。
- 模型参数量 7B-32B:蒸馏作为基线,RL 作为增强。先用蒸馏获得初始推理能力,再用 RL(如本章前几节介绍的 GRPO + RLVR 管线)在蒸馏检查点上继续训练,通常能再提升 5-15 个百分点。
- 模型参数量 > 32B:可以考虑 RL 优先。大模型有足够的容量通过自我探索发现推理模式,但仍建议用蒸馏数据做冷启动 SFT 以加速收敛。
- 资源极度受限:无论模型大小,蒸馏都是性价比最高的选择——它将推理能力的获取转化为一个"数据问题"而非"算法问题"。
18.6.3 教师数据生成:两条路径
推理蒸馏的质量上限由教师数据的质量决定。§14.3 已详细讲解了数据的结构设计(双段结构:message_thinking + message_content)、Ollama 本地生成和 OpenRouter API 调用两条路径。这里补充实战中容易被忽略的工程要点。
路径一:本地推理(Ollama)。 适合使用中等规模教师模型(8B-32B)进行快速实验。核心是启用思考模式(think: True),让模型在推理时分离出思考过程和最终回答:
import json
import urllib.request
def generate_distill_data(problems, model="deepseek-r1:32b",
base_url="http://localhost:11434",
max_tokens=8192, temperature=0.0):
"""通过 Ollama 批量生成推理蒸馏数据"""
results = []
for problem in problems:
# 构造 Ollama API 请求体,启用 think 模式
payload = {
"model": model,
"messages": [{"role": "user", "content": problem}],
"think": True, # 分离 thinking 和 content
"stream": False,
"options": {"num_predict": max_tokens, "temperature": temperature}
}
data = json.dumps(payload).encode("utf-8")
req = urllib.request.Request(
url=f"{base_url}/api/chat",
data=data,
headers={"Content-Type": "application/json"},
method="POST"
)
# 发送请求并解析响应中的思考过程和最终回答
with urllib.request.urlopen(req, timeout=600) as resp:
result = json.loads(resp.read().decode("utf-8"))
msg = result["message"]
results.append({
"problem": problem,
"message_thinking": msg.get("thinking", ""),
"message_content": msg.get("content", "")
})
return results路径二:云端 API(OpenRouter)。 当需要使用 671B 级别的教师模型时,必须通过 API 调用。成本结构的关键洞察是:推理模型的输出远长于普通模型——一道数学题的思考过程通常有 1000-2000 token,最终回答仅 100-300 token,因此输出 token 成本占据绝对主导。
以 DeepSeek-R1 为例,生成 1000 条数学蒸馏数据的成本约 $3.82,12000 条约 $46。如果顺序生成,12000 条约需 100 小时;通过 50 路并行线程,可压缩到 2 小时左右。
实战中的三个关键细节:
- 增量保存 + 断点续传。 数据生成周期长达数小时,必须每完成一条就写入磁盘(使用临时文件 + 原子替换,避免写入中断导致数据损坏),并支持通过
--resume参数从中断点继续。 - 教师选择的"亲和度"陷阱。 直觉上,越大的教师模型应该效果越好。但实验数据给出了反直觉的结果:Qwen3-235B 蒸馏 Qwen3-0.6B 的效果(MATH-500 准确率 45.0%)远优于 DeepSeek-R1 671B 蒸馏同一学生模型(30.6%)。同家族教师因词表兼容、表示空间对齐而具有天然优势。
- 输出长度控制。 设置
max_tokens=2048通常能覆盖大多数数学推理题,同时避免过长的思考过程浪费 token 预算。
18.6.4 蒸馏训练的完整配方
在获得教师生成的蒸馏数据后,训练流程本质上是一次带有推理格式约束的 SFT。以下是经过实验验证的完整训练配方。
第一步:数据格式化。 将蒸馏数据拼接为带有思考标签的完整序列:
def format_distilled_answer(entry, use_think_tokens=True):
"""将教师输出的思考过程和最终回答拼接为训练目标"""
content = entry["message_content"].strip()
thinking = entry.get("message_thinking", "").strip()
# 清除可能嵌套的标签
for tag in ["<think>", "</think>"]:
content = content.replace(tag, "")
thinking = thinking.replace(tag, "")
if use_think_tokens:
return f"<think>{thinking}</think>\n\n{content}"
if thinking:
return f"{thinking}\n\n{content}"
return content第二步:构建训练样本。 将格式化后的文本编码为 [prompt_ids] + [answer_ids] + [eos],并记录 prompt 长度以构建 loss mask——只在回答部分计算损失,prompt 部分不参与训练:
import torch
import torch.nn.functional as F
def compute_distill_loss(model, token_ids, prompt_len, device):
"""计算 answer-only 交叉熵损失"""
input_ids = torch.tensor(
token_ids[:-1], dtype=torch.long, device=device
).unsqueeze(0)
target_ids = torch.tensor(
token_ids[1:], dtype=torch.long, device=device
)
logits = model(input_ids).squeeze(0) # [seq_len-1, vocab_size]
# 只在回答部分(prompt 之后)计算损失
answer_start = max(prompt_len - 1, 0)
answer_logits = logits[answer_start:]
answer_targets = target_ids[answer_start:]
return F.cross_entropy(answer_logits, answer_targets)第三步:训练循环。 使用 AdamW 优化器和梯度裁剪。推理蒸馏的训练循环与普通 SFT 几乎一致,关键差异在于超参数的选择:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
def train_distillation(model, train_examples, device,
epochs=3, lr=1e-5, grad_clip=1.0):
"""推理蒸馏训练主循环"""
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
model.train()
for epoch in range(1, epochs + 1):
epoch_loss = 0.0
# 遍历所有蒸馏样本,仅在回答部分计算交叉熵损失
for i, example in enumerate(train_examples):
optimizer.zero_grad()
loss = compute_distill_loss(
model, example["token_ids"],
example["prompt_len"], device
)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), grad_clip)
optimizer.step()
epoch_loss += loss.item()
avg_loss = epoch_loss / len(train_examples)
print(f"Epoch {epoch}: avg_loss = {avg_loss:.4f}")
# 每轮结束后保存检查点
torch.save(model.state_dict(), f"distill_epoch{epoch}.pth")推荐超参数配置:
| 超参数 | 推荐值 | 说明 |
|---|---|---|
| 学习率 | 推理蒸馏需要保守学习率,避免破坏预训练知识 | |
| 训练轮数 | 1-3 | 过多轮数导致过拟合(见实验分析) |
| 最大序列长度 | 2048 | 推理轨迹通常比普通回答长 |
| 梯度裁剪 | 1.0 | 长序列容易导致梯度爆炸 |
| 分词器 | reasoning tokenizer | <think>/</think> 编码为单个特殊 Token |
表 18-8:推理蒸馏推荐超参数配置。
18.6.5 白盒蒸馏:进一步利用教师 logits
上述流程属于黑盒蒸馏——学生模型仅学习教师生成的文本序列。如果训练时能同时访问教师模型(或其 logits),则可以使用白盒蒸馏来进一步提升效果。
白盒蒸馏的总损失由三部分组成:
其中
蒸馏损失的核心是温度软化的 KL 散度:
温度
import torch.nn.functional as F
def distillation_loss(student_logits, teacher_logits, temperature=2.0):
"""计算温度软化的 KL 散度蒸馏损失"""
student_log_probs = F.log_softmax(student_logits / temperature, dim=-1)
teacher_probs = F.softmax(teacher_logits / temperature, dim=-1)
kl = F.kl_div(student_log_probs, teacher_probs, reduction="batchmean")
return (temperature ** 2) * kl在推理模型蒸馏场景中,白盒蒸馏还有一个特殊技巧——对思考控制标签施加高权重损失。具体做法是对 <think>、</think> 等特殊 Token 的预测错误施加 10 倍惩罚权重,迫使模型优先学会"何时开始思考、何时结束思考"的结构化控制能力:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
def compute_weighted_loss(loss_per_token, targets, special_token_ids,
loss_mask, device, weight=10.0):
"""对推理控制标签施加高权重"""
flat_mask = loss_mask.clone().view(-1)
original_sum = flat_mask.sum() # 未加权分母
is_special = torch.isin(
targets.view(-1),
torch.tensor(special_token_ids, device=device)
)
flat_mask[is_special] = weight
return (loss_per_token.view(-1) * flat_mask).sum() / original_sum注意分母使用的是未加权的掩码和——这意味着分子被放大而分母不变,特殊标签的梯度幅度被真正放大,而非被归一化稀释。
图 18-10:MiniMind 白盒蒸馏推理模型的训练曲线。左图为 loss 随训练步数的下降过程,中图为学习率调度,右图为每 epoch 耗时。可以看到 loss 在前 50 步快速下降后趋于平稳。
18.6.6 实验结果与关键发现
以下是使用 Qwen3-0.6B 作为学生模型的推理蒸馏实验结果(评测基准:MATH-500,配置:lr=
| 配置 | 教师模型 | 训练轮数 | MATH-500 准确率 | 验证损失 |
|---|---|---|---|---|
| Base(无蒸馏) | - | - | 15.2% | - |
| Reasoning(内置推理) | - | - | 48.2% | - |
| 蒸馏 | DeepSeek-R1 (671B) | 1 | 30.6% | 0.5436 |
| 蒸馏 | DeepSeek-R1 (671B) | 2 | 32.4% | 0.5349 |
| 蒸馏 | DeepSeek-R1 (671B) | 3 | 33.6% | 0.5343 |
| 蒸馏 | Qwen3-235B-A22B | 1 | 45.0% | 0.4043 |
| 蒸馏 | Qwen3-235B-A22B | 2 | 43.8% | 0.3963 |
| 蒸馏 | Qwen3-235B-A22B | 3 | 44.2% | 0.3948 |
表 18-9:不同教师模型的推理蒸馏效果对比。H100 上训练约 30 分钟,DGX Spark 上约 3 小时。
从这些数据中可以提炼出三个核心发现:
发现一:教师-学生的架构亲和度比教师绝对能力更重要。 Qwen3-235B 蒸馏 Qwen3-0.6B 的效果(45.0%)远优于 DeepSeek-R1 671B 蒸馏同一学生模型(30.6%),尽管后者的绝对推理能力更强。这意味着在选择教师模型时,词表兼容性和表示空间对齐是比模型规模更关键的因素。
发现二:推理蒸馏对过拟合高度敏感。 Qwen3-235B 蒸馏在第 1 轮即达到峰值(45.0%),第 2-3 轮反而下降到 43.8%。验证损失持续下降但测试准确率不升反降——经典的过拟合信号。实践建议:推理蒸馏使用 1-2 轮训练即可,或引入 early stopping。
发现三:蒸馏的性价比极高。 仅 0.6B 参数的模型,经 Qwen3-235B 蒸馏后达到 45.0%,接近其内置推理模式(48.2%)。而未蒸馏的 base 模型仅 15.2%——蒸馏带来了近 3 倍的准确率提升。考虑到训练成本仅为 SFT 级别,这是推理能力获取的最高性价比路径。
18.6.7 GKD:训练-推理分布对齐
标准蒸馏的一个固有缺陷是训练-推理分布不匹配——训练时学生模型在教师生成的序列上学习(teacher-forcing),推理时却需要在自己生成的序列上继续生成。学生模型在训练中从未"见过"自己的错误,因此在推理时一旦偏离教师轨迹就容易雪崩。
广义知识蒸馏(Generalized Knowledge Distillation, GKD) 正是为解决这一问题而设计的。其核心思想是让学生模型在自己生成的序列上,利用教师的 token 级反馈进行学习。GKD 通过一个参数
:纯监督蒸馏,学生在教师序列上训练(传统蒸馏) :纯 on-policy 蒸馏,学生在自己生成的序列上训练
GKD 还引入了广义 Jensen-Shannon 散度(JSD) 作为损失函数,通过参数
TRL 库提供了 GKDTrainer 的实现:
from datasets import Dataset
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl.experimental.gkd import GKDConfig, GKDTrainer
# 学生模型
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
# 教师模型
teacher = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2-1.5B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-0.5B-Instruct")
train_dataset = Dataset.from_dict({
"messages": [[
{"role": "user", "content": "Solve: 2x + 3 = 7"},
{"role": "assistant", "content": "<think>Subtract 3...</think>\nx = 2"}
]] * 1000
})
config = GKDConfig(
output_dir="gkd-reasoning",
per_device_train_batch_size=4,
lmbda=0.5, # 50% on-policy 数据
beta=0.5, # JSD 插值
seq_kd=False,
)
trainer = GKDTrainer(
model=model,
teacher_model=teacher,
args=config,
processing_class=tokenizer,
train_dataset=train_dataset,
)
trainer.train()GKD 在推理蒸馏中的价值在于:学生模型在训练阶段就有机会暴露自己的"思考错误",教师通过 token 级的概率反馈帮助纠正这些错误,从而缩小训练与推理之间的分布鸿沟。
18.6.8 本节小结与第 18 章总结
本节小结。 推理模型蒸馏是将大模型的推理能力高效迁移到小模型的最佳路径。在 R1 训练流水线中,蒸馏既是起点(冷启动 SFT),也是终点(能力下放)。实战中的关键要点包括:(1)教师-学生的架构亲和度比教师绝对能力更重要——同家族优先;(2)推理蒸馏对过拟合敏感,1-2 轮训练通常最优;(3)白盒蒸馏可通过温度软化的 KL 散度和特殊标签加权进一步提升效果;(4)GKD 通过 on-policy 训练解决训练-推理分布不匹配问题。
第 18 章总结。 回顾整章内容,我们走过了训练推理模型的完整技术路线:从 RLVR 的范式革新(§18.1),到 GRPO 管线的工程落地(§18.2),到策略优化的监控与调参实践(§18.3),到异步 Rollout 的效率突破(§18.4),到 DeepSeek-R1 与形式化数学的前沿探索(§18.5),最终以推理蒸馏收尾(§18.6)。
如果用一句话概括第 18 章的核心信息,那就是:大模型通过 RL 探索发现推理能力,小模型通过蒸馏继承推理能力——这是当前推理模型训练的黄金范式。 这条"RL 探索 + 蒸馏传播"的知识生产链路,将强大的推理能力从少数超大模型扩散到整个模型生态系统中,使得部署友好的小模型也能具备令人印象深刻的推理能力。