6.3 MLA(多头潜在注意力)
上一节介绍的 GQA 通过让多个查询头共享同一组 Key/Value 来压缩 KV 缓存,其本质是一种结构化的低秩约束——同一组内的所有头被强制使用完全相同的 K 和 V 向量。这种"复制"策略虽然简单高效,但在表达能力上存在天然上限:共享 KV 的头无法从相同输入中提取不同的键值信息。
多头潜在注意力(Multi-Head Latent Attention, MLA)提供了一条截然不同的压缩路径。它不再限制哪些头共享 KV,而是将所有头的 Key 和 Value 联合投影到一个低维潜在空间,推理时仅缓存这个低维向量;当实际需要计算注意力时,再将其投影回高维空间恢复出各头的 K 和 V。MLA 由 DeepSeek-V2 首次提出并引入实际部署,随后在 DeepSeek-V3 和 DeepSeek-R1 中延续使用。消融实验表明,在同等 KV 缓存预算下,MLA 的建模性能不仅超过 GQA,甚至略优于标准 MHA。
本节将从数学原理出发,完整推导 MLA 的低秩压缩机制、矩阵吸收技巧和解耦位置编码设计,并给出 PyTorch 参考实现。
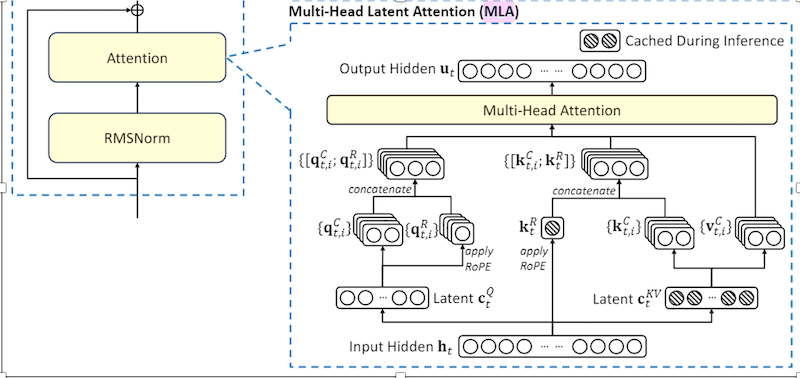
图 6-9:MLA 架构概览。Key 和 Value 被联合投影到低维潜在空间,推理时仅缓存潜向量,通过矩阵吸收避免恢复高维表示。
6.3.1 核心思想:低秩联合压缩
MHA 的 KV 缓存瓶颈。 回顾标准 MHA:对于第
其中
GQA 的约束本质。 GQA 通过将
MLA 的柔性低秩压缩。 MLA 引入一个维度为
这个低维向量
展开可以看到,MLA 中第
此时的问题。 如果按上述公式直接计算,推理阶段仍然需要将
6.3.2 矩阵吸收:真正实现缓存压缩
矩阵吸收利用的是矩阵乘法的结合律(Associativity),将上采样矩阵从 KV 端转移到 Query 端和输出端,从而使推理时无需显式恢复高维 K/V。
Key 端的吸收。 考虑第
代入 MLA 的低秩表达式:
注意
推理时,Query 的计算变为
Value 端的吸收。 类似地,第
多头输出拼接后需要乘以输出投影矩阵
吸收后的推理流程。 经过 Key 端和 Value 端的矩阵吸收,推理阶段的 KV 缓存中只需要存储
代价是推理时多了一步矩阵乘法(吸收矩阵与潜向量的乘法)。但在 LLM 解码阶段,瓶颈是显存带宽而非计算量(Memory-Bound),用少量额外计算换取大幅缓存压缩,在吞吐量上是净收益。
6.3.3 解耦旋转位置编码
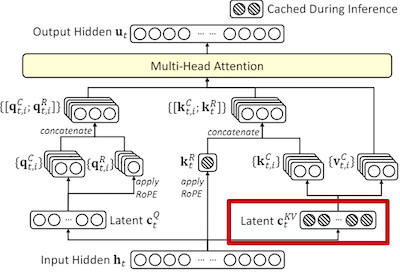
图 6-10:MLA 低秩投影过程。Key 和 Value 被联合投影到低维潜在空间,潜向量的维度远小于原始 KV 维度,实现缓存压缩。
上述矩阵吸收有一个前提:
RoPE 导致吸收失效。 RoPE 通过一个依赖于绝对位置
位置相关的动态矩阵
解耦策略。 MLA 的解决方案是将 Query 和 Key 各自拆分为内容部分(不含 RoPE)和位置部分(含 RoPE),两部分拼接后共同参与注意力计算。
具体地,引入一个较小的 RoPE 专用维度
Query 解耦:
- 内容部分:
(来自 Query 潜向量,不受 RoPE 影响) - 位置部分:
(施加 RoPE,所有头共享)
Key 解耦:
- 内容部分:
(不受 RoPE 影响) - 位置部分:
(施加 RoPE,所有头共享)
拼接后的注意力分数:
通过这种解耦:
- 内容项完全遵循 6.3.2 节的结合律,推理时只需缓存
。 - 位置项需要额外缓存所有头共享的
,但 很小(通常为 64)。
因此,MLA 推理阶段每个 token 的实际 KV 缓存大小为
6.3.4 PyTorch 实现
以下是 MLA 注意力模块的参考实现。为突出核心机制,省略了解耦 RoPE 和矩阵吸收优化,采用"训练模式"的显式低秩压缩—恢复流程:
import torch
import torch.nn as nn
class MultiHeadLatentAttention(nn.Module):
def __init__(self, d_in, d_out, num_heads, latent_dim,
dropout=0.0, qkv_bias=False):
super().__init__()
assert d_out % num_heads == 0, "d_out must be divisible by num_heads"
self.num_heads = num_heads
self.head_dim = d_out // num_heads
self.d_out = d_out
self.latent_dim = latent_dim
# 下采样:将输入投影到低维潜在空间
self.W_DKV = nn.Linear(d_in, latent_dim, bias=qkv_bias)
# 上采样:从潜向量恢复多头 Key 和 Value
self.W_UK = nn.Linear(latent_dim, d_out, bias=False)
self.W_UV = nn.Linear(latent_dim, d_out, bias=False)
# Query 投影(不压缩,与标准 MHA 相同)
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.out_proj = nn.Linear(d_out, d_out, bias=False)
self.dropout = nn.Dropout(dropout)
# KV Cache 缓冲区:缓存低维潜向量而非高维 K/V
self.register_buffer("cache_c", None, persistent=False)
self.ptr_current_pos = 0
def forward(self, x, use_cache=False):
b, seq_len, _ = x.shape
# Query:标准投影
Q = self.W_query(x)
Q = Q.view(b, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# KV:先下采样到潜在空间
c_kv = self.W_DKV(x) # (b, seq_len, latent_dim)
# 缓存逻辑:缓存的是低维潜向量,而非高维 K/V
if use_cache:
if self.cache_c is None:
self.cache_c = c_kv
else:
self.cache_c = torch.cat([self.cache_c, c_kv], dim=1)
c_kv_full = self.cache_c
else:
c_kv_full = c_kv
# 从潜向量恢复高维 Key 和 Value
K = self.W_UK(c_kv_full)
V = self.W_UV(c_kv_full)
K = K.view(b, -1, self.num_heads, self.head_dim).transpose(1, 2)
V = V.view(b, -1, self.num_heads, self.head_dim).transpose(1, 2)
# 缩放点积注意力 + 因果掩码
scale = self.head_dim ** 0.5
attn_scores = Q @ K.transpose(-2, -1) / scale
num_q = Q.size(2)
num_k = K.size(2)
if use_cache and num_q < num_k:
# Decode 阶段:动态构建因果掩码
offset = num_k - num_q
row_idx = torch.arange(num_q, device=x.device).unsqueeze(1)
col_idx = torch.arange(num_k, device=x.device).unsqueeze(0)
mask = col_idx > row_idx + offset
else:
mask = torch.triu(
torch.ones(num_q, num_k, device=x.device, dtype=torch.bool),
diagonal=1
)
attn_scores = attn_scores.masked_fill(mask, float("-inf"))
attn_weights = torch.softmax(attn_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
context = (attn_weights @ V).transpose(1, 2).contiguous()
context = context.view(b, num_q, self.d_out)
return self.out_proj(context)
def reset_cache(self):
self.cache_c = None
self.ptr_current_pos = 0代码要点解读:
W_DKV是关键新增模块——它将维输入压缩到 维( latent_dim),是 MLA 相对于 MHA 的核心结构差异。- 缓存的对象是
c_kv(低维潜向量),而非高维 K/V 向量。 这是 MLA 节省 KV 缓存内存的直接来源:缓存从每 token个元素降至 个元素。 W_UK和W_UV在每次注意力计算时在线执行,将潜向量恢复为高维 K/V。这增加了推理计算量,但由于解码阶段受限于显存带宽而非计算吞吐,这一代价在实际部署中通常可以忽略。- 训练模式 vs 推理模式。 上述实现采用的是训练模式——显式计算高维 K/V 后再做注意力。在优化后的推理模式中,可以通过矩阵吸收(6.3.2 节)将
W_UK合并到 Query 投影、W_UV合并到输出投影,从而在推理时完全跳过高维 K/V 的恢复过程。
6.3.5 KV 缓存内存对比
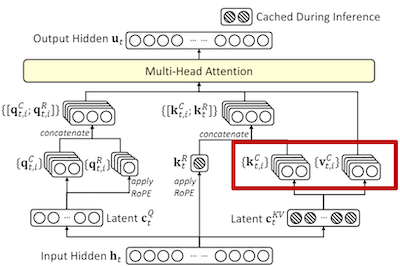
图 6-11:MLA 矩阵吸收过程。推理时将上采样矩阵吸收到 Query 和输出投影中,直接对潜向量计算注意力,避免恢复高维 KV 表示。
MLA 的 KV 缓存公式与 MHA/GQA 有本质不同。MHA 缓存的是高维 K/V 向量对,而 MLA 缓存的是低维潜向量(加上解耦 RoPE 的位置向量):
| 方法 | 单 token 单层缓存元素数 | 公式 |
|---|---|---|
| MHA | ||
| GQA( | ||
| MLA | 潜向量 + RoPE 键 |
MLA 的总 KV 缓存字节数为:
其中
对比一:理论配置。 使用 DeepSeek-V2 的参数(
| 方法 | 单 token 单层缓存 | 压缩比(相对 MHA) |
|---|---|---|
| MHA | 1x | |
| MLA | 56.9x |
这是一个惊人的 57 倍压缩,远超 GQA 通常能达到的 4-8 倍。
对比二:实验配置。 使用一个小规模对比实验的参数(emb_dim=768,n_heads=24,n_layers=12,context_length=32768,latent_dim=192,batch_size=1,dtype=bf16):
MHA 的 KV 缓存:
MLA 的 KV 缓存(仅计算潜向量,
压缩比为
| 配置 | KV 缓存 | 模型总内存(含 FFN) | 端到端压缩 |
|---|---|---|---|
MHA(emb_dim=768) | ~1.21 GB | 1.54 GB | 1.0x |
MLA(latent_dim=192) | ~0.15 GB | 0.68 GB | 2.3x |
表 6-4:MHA 与 MLA 端到端内存对比(emb_dim=768, n_heads=24, n_layers=12, context_length=32768, bf16)。KV 缓存本身压缩 8 倍,但模型参数的固定开销使整体压缩比降至约 2.3 倍。
需要注意的是,KV 缓存的节省效果与上下文长度成正比。在上述配置中,当上下文长度从 32K 增至 128K,KV 缓存将成为总内存的主导项,MLA 的 8 倍压缩优势将更加充分地体现。
图 6-12:MLA 矩阵吸收技巧。将 Key 端的上采样矩阵吸收到 Query 投影中,Value 端的上采样矩阵吸收到输出投影中,推理时直接对潜向量计算注意力。
6.3.6 DeepSeek-V2 消融实验
DeepSeek-V2 论文提供了一组关键消融实验,直接对比了 MHA、GQA 和 MLA 在相同训练设置下的建模性能(以困惑度 / Perplexity 或下游任务准确率衡量)。实验结论可以总结为两点:
GQA 性能低于 MHA。 在同等模型规模下,GQA 虽然节省了 KV 缓存,但在建模质量上出现了可测量的下降。这与预期一致——GQA 强制多个头共享完全相同的 K/V,相当于对注意力空间施加了刚性约束,限制了模型的表达能力。
MLA 性能略优于 MHA。 在 KV 缓存压缩幅度远超 GQA 的情况下,MLA 不仅没有损失建模质量,反而略微超过了标准 MHA。这一看似反直觉的结果有合理的解释:低秩投影充当了一种信息瓶颈(Information Bottleneck),迫使模型学习更紧凑、更具泛化性的 KV 表示,类似于自编码器中瓶颈层的正则化效果。
这一消融结果是 DeepSeek 团队选择 MLA 而非 GQA 的核心依据。从工程部署角度看,MLA 实现了"缓存更小、性能更好"的理想组合——这在 GQA 的框架下是不可能达到的。
6.3.7 训练与推理的模式差异
MLA 在训练和推理阶段的计算模式存在显著差异,这是理解其工程实现的关键:
训练阶段采用类似 MHA 的并行计算模式,显式地计算所有头的
推理阶段分为三步:
- 离线预处理:将上采样矩阵分别吸收到
和 中,预计算吸收矩阵。 - Prefill 阶段:并行计算所有 token 的
和 ,存入缓存。 - Decode 阶段:形式上退化为等效的 MQA——所有头共享同一个
进行注意力计算,访存量极大降低。
第三步值得特别说明:由于矩阵吸收后 Query 的维度变为
本节小结
本节介绍了多头潜在注意力(MLA)的原理与实现:
- 核心思想:将所有头的 Key 和 Value 联合投影到一个低维潜在空间(维度
),推理时仅缓存低维潜向量 ,通过矩阵吸收技巧避免恢复高维 K/V。与 GQA 的"复制共享"不同,MLA 允许每个头从共享潜向量中提取不同信息,提供更大的表达灵活度。 - 矩阵吸收:利用矩阵乘法的结合律,将 Key 端的上采样矩阵
吸收到 Query 投影中,将 Value 端的 吸收到输出投影中。吸收后推理时只需对潜向量执行注意力计算,无需显式恢复高维 K/V。 - 解耦 RoPE:RoPE 的位置相关矩阵会阻断矩阵吸收。MLA 将 Q/K 拆分为内容部分(可吸收)和位置部分(含 RoPE,单独计算),额外缓存一个所有头共享的
。 - 内存收益:单 token 单层 KV 缓存从 MHA 的
个元素降至 个元素。在 DeepSeek-V2 配置下实现约 57 倍压缩;在小规模实验配置下( latent_dim=192),KV 缓存压缩 8 倍,端到端模型内存从 1.54 GB 降至 0.68 GB。 - 建模性能:DeepSeek-V2 消融实验表明,MLA 在 KV 缓存大幅压缩的前提下,建模性能不仅不低于 MHA,反而略有提升——低秩瓶颈起到了正则化效果。这是 MLA 优于 GQA 的核心优势。
延伸阅读:MLA 的高效推理实现 FlashMLA 将在 §9.4 中详细讨论,包括其针对 GPU 内存层次的优化策略。