27.2 性能优化速查
上一节我们纵览了 TRL 提供的各类训练器——从监督微调到强化学习,功能已足够丰富。然而在工程实践中,训练效率往往决定了研究的迭代速度。一个 7B 模型的 GRPO 训练如果在线生成环节耗时占 80%,再好的算法设计也无法快速验证;一个 70B 模型如果单卡显存放不下,LoRA 训练也无从谈起。TRL 生态因此围绕四个核心维度构建了一套完整的性能优化工具链:推理加速(vLLM)、算子融合(Liger Kernel / HF Kernels)、显存优化(Unsloth)和分布式训练(DeepSpeed / FSDP)。本节将逐一剖析这四类优化手段的原理、配置方法和性能收益,最后给出组合策略建议。
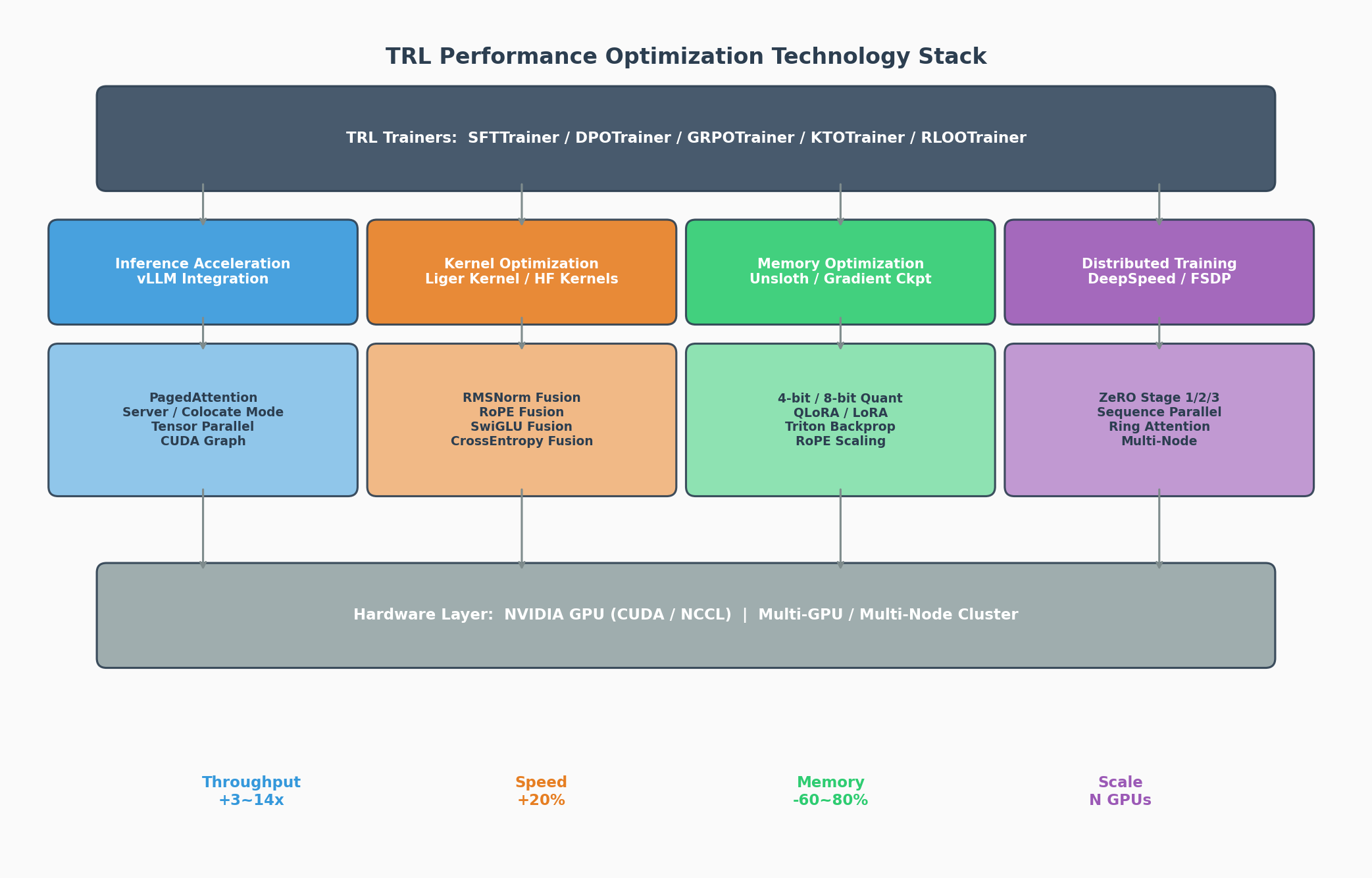
一、vLLM 集成:在线推理加速
1.1 解决什么问题
在线强化学习方法(GRPO、Online DPO、RLOO 等)的训练循环中,每一步都需要模型生成补全文本(completions),再由奖励函数打分。默认情况下,TRL 直接调用 HuggingFace 模型的 generate() 方法逐 token 自回归生成,这个过程极其缓慢——对大模型和长序列而言,生成时间可能占训练总时间的 70% 以上,成为最大瓶颈。
1.2 核心原理
vLLM 通过 PagedAttention 技术解决了自回归生成中的 KV Cache 显存碎片问题。传统实现为每个序列预分配连续显存块存储 KV Cache,导致大量内存碎片和浪费。PagedAttention 借鉴操作系统虚拟内存的分页思想,将 KV Cache 存储在非连续的内存页中,按需分配、动态管理。配合 Continuous Batching(持续批处理)和 CUDA Graph 优化,vLLM 可将推理吞吐量提升 3~14 倍。
1.3 两种运行模式
TRL 支持两种 vLLM 集成模式:
| 特性 | Server 模式 | Colocate 模式(默认) |
|---|---|---|
| 运行方式 | vLLM 作为独立进程在专用 GPU 上运行 | vLLM 在训练进程内运行,与模型共享 GPU |
| GPU 分配 | 训练 GPU 与推理 GPU 完全分离 | 训练与推理共用同一组 GPU |
| 优点 | 无显存争用,适合大规模训练 | 无需额外服务,配置简单 |
| 缺点 | 需要更多 GPU,需启动独立服务 | 可能出现显存争用 |
| 适用场景 | 多卡集群,有充足 GPU 资源 | 单机少卡,资源有限 |
1.4 配置示例
Server 模式——将 8 卡中的 0~3 号分配给 vLLM 推理,4~7 号用于训练:
# 步骤一:安装 vLLM 支持
pip install "trl[vllm]"
# 步骤二:在 GPU 0-3 上启动 vLLM 推理服务(4 卡张量并行)
CUDA_VISIBLE_DEVICES=0,1,2,3 trl vllm-serve \
--model Qwen/Qwen2.5-7B \
--tensor-parallel-size 4 \
--gpu-memory-utilization 0.9训练脚本 train.py:
from datasets import load_dataset
from trl import GRPOTrainer, GRPOConfig
from trl.rewards import accuracy_reward
dataset = load_dataset("trl-lib/DeepMath-103K", split="train")
training_args = GRPOConfig(
output_dir="./grpo_output",
use_vllm=True,
vllm_mode="server", # 使用独立服务模式
per_device_train_batch_size=4,
num_generations=8, # 每个 prompt 生成 8 个补全
learning_rate=5e-7,
)
trainer = GRPOTrainer(
model="Qwen/Qwen2.5-7B",
args=training_args,
reward_funcs=accuracy_reward,
train_dataset=dataset,
)
trainer.train()# 步骤三:在 GPU 4-7 上启动训练
CUDA_VISIBLE_DEVICES=4,5,6,7 accelerate launch train.pyColocate 模式——更简洁,无需单独启动服务:
training_args = GRPOConfig(
output_dir="./grpo_output",
use_vllm=True, # vllm_mode 默认为 "colocate"
per_device_train_batch_size=4,
)注意:Server 模式下,训练 GPU 和 vLLM GPU 必须完全隔离,否则 NCCL 通信会产生冲突。TRL v0.19.1 之后的版本会自动检测并报错。
1.5 支持的训练器
vLLM 集成目前支持以下需要在线生成的训练器:GRPOTrainer、RLOOTrainer、OnlineDPOTrainer、NashMDTrainer、XPOTrainer。
二、Liger Kernel:Triton 算子融合
2.1 解决什么问题
LLM 训练中,RMSNorm、RoPE、SwiGLU、CrossEntropy 等操作各自独立调用 CUDA kernel,导致大量内核启动开销和显存中间变量。每次操作都要在全局显存和计算单元之间搬运数据,效率很低。
2.2 核心原理
Liger Kernel 由 LinkedIn 团队开发,用 Triton 语言编写了一组融合算子(Fused Kernels)。其核心思路是将多个连续操作合并到一次 GPU kernel 调用中完成,减少内存读写次数和 kernel 启动开销。具体实现包括:
- FusedLinearCrossEntropy:将最后的线性投影层和交叉熵损失融合,避免 materialize 完整的 logits 矩阵(对 vocab size 很大的模型效果尤为显著)
- Fused RMSNorm:将归一化、乘以 weight、写回三步融合为一步
- Fused RoPE:将旋转位置编码的三角函数计算和向量旋转融合
- Fused SwiGLU:将 SiLU 激活和门控线性单元融合
这些融合算子与 FlashAttention、PyTorch FSDP、DeepSpeed 均完全兼容,开箱即用。
2.3 性能收益
根据官方基准测试(Llama 3.1-8B,单卡 A100):
| 指标 | 提升幅度 |
|---|---|
| 多 GPU 训练吞吐量 | +20% |
| 显存占用 | -60% |
| 可训练上下文长度 | 4x(得益于显存节省) |
显存减少后,甚至可以关闭 gradient_checkpointing 或 cpu_offloading,进一步提升速度。
2.4 配置示例
pip install liger-kernel只需一行配置即可启用——所有融合操作自动 patch 到模型中:
from trl import SFTConfig, SFTTrainer
training_args = SFTConfig(
output_dir="./sft_output",
use_liger_kernel=True, # 一键启用 Liger Kernel
per_device_train_batch_size=4,
max_length=4096,
bf16=True,
)
trainer = SFTTrainer(
model="meta-llama/Llama-3.1-8B",
args=training_args,
train_dataset=dataset,
)
trainer.train()2.5 支持的训练器
Liger Kernel 支持:SFTTrainer、DPOTrainer、GRPOTrainer、KTOTrainer、GKDTrainer。
2.6 HF Kernels Hub:免编译的注意力加速
除 Liger Kernel 外,TRL 还支持通过 HF Kernels Hub 直接加载预编译的注意力算子。传统方式下安装 FlashAttention 需要从源码编译,耗时可达数分钟甚至数小时。而 HF Kernels 在约 2.5 秒内即可完成加载,无需编译:
from transformers import AutoModelForCausalLM
from trl import SFTConfig
# 直接从 Hub 加载 FlashAttention 2 kernel
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2.5-7B",
attn_implementation="kernels-community/flash-attn2"
)
# 可与 Liger Kernel 联合使用
training_args = SFTConfig(
output_dir="./output",
use_liger_kernel=True, # Liger 融合算子
# attn_implementation 在模型加载时已指定 # HF Kernels 注意力
)根据 H100 上的基准测试(Qwen3-8B,batch size 8,bf16),HF Kernels 的延迟和峰值显存与手动编译安装的 FlashAttention 几乎一致,但零编译开销。
三、Unsloth:极致显存优化
3.1 解决什么问题
许多研究者只有单张消费级 GPU(如 RTX 3090/4090,24GB 显存),要微调 7B 甚至 13B 参数的模型,标准流程显存远远不够。即使用 LoRA 也可能在 batch size > 1 时 OOM。
3.2 核心原理
Unsloth 通过以下技术组合实现极致优化:
- 手写 Triton 内核:不使用 PyTorch autograd,而是为关键算子(RMSNorm、RoPE、CrossEntropy、SwiGLU 等)手动编写前向和反向传播的 Triton kernel,确保零近似误差
- 内存高效的 QLoRA:支持 4-bit 量化(QLoRA)和 8-bit 量化训练,基座模型以量化权重常驻显存,仅 LoRA 适配器以全精度训练
- 自动 RoPE Scaling:支持任意序列长度的位置编码自动缩放,无需手动配置
3.3 性能收益
| 指标 | 相比标准 HuggingFace 训练 |
|---|---|
| 训练速度 | 2x 加速 |
| 显存占用 | -80% |
| 精度损失 | 0%(无近似误差) |
3.4 配置示例
Unsloth 的使用方式与标准 TRL 略有不同——需要用 FastLanguageModel 替代 AutoModelForCausalLM:
import torch
from trl import SFTConfig, SFTTrainer
from unsloth import FastLanguageModel
# 加载 4-bit 量化模型
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/mistral-7b",
max_seq_length=2048,
dtype="auto", # 自动检测:T4/V100 用 FP16,Ampere+ 用 BF16
load_in_4bit=True, # 启用 4-bit 量化,显存降至约 1/4
)
# 添加高效 LoRA 适配器
model = FastLanguageModel.get_peft_model(
model,
r=16, # LoRA 秩
target_modules=[ # 典型目标模块
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
],
lora_alpha=16,
lora_dropout=0, # Unsloth 优化下 dropout=0 效率最高
bias="none", # 不训练偏置项
use_gradient_checkpointing=True,
random_state=3407,
)
# 正常使用 TRL 训练器
training_args = SFTConfig(
output_dir="./unsloth_output",
max_length=2048,
per_device_train_batch_size=4,
)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset,
)
trainer.train()训练完成后,Unsloth 支持多种格式导出:
# 保存 LoRA 适配器
model.save_pretrained("lora_adapter")
# 合并并导出为 16-bit(用于 vLLM 部署)
model.save_pretrained_merged("merged_model", tokenizer, save_method="merged_16bit")
# 导出为 GGUF 格式(用于 llama.cpp / Ollama)
model.save_pretrained_gguf("gguf_model", tokenizer, quantization_method="q4_k_m")四、DeepSpeed 分布式训练
4.1 解决什么问题
当模型参数量超出单卡显存容量(例如 70B 模型需要 ~140GB 仅存储 FP16 权重),必须将模型状态分片到多张 GPU 上。即使模型能放下单卡,多卡并行也能通过更大的全局 batch size 提升训练效率。
4.2 核心原理:ZeRO 三阶段
DeepSpeed 的 Zero Redundancy Optimizer (ZeRO) 将训练状态按冗余程度逐步分片:
| ZeRO 阶段 | 分片内容 | 每卡显存节省(8 卡) | 通信开销 |
|---|---|---|---|
| Stage 1 | 优化器状态(如 Adam 的 m, v) | ~4x | 低 |
| Stage 2 | + 梯度 | ~8x | 中 |
| Stage 3 | + 模型参数 | ~N 倍(N=GPU 数) | 高 |
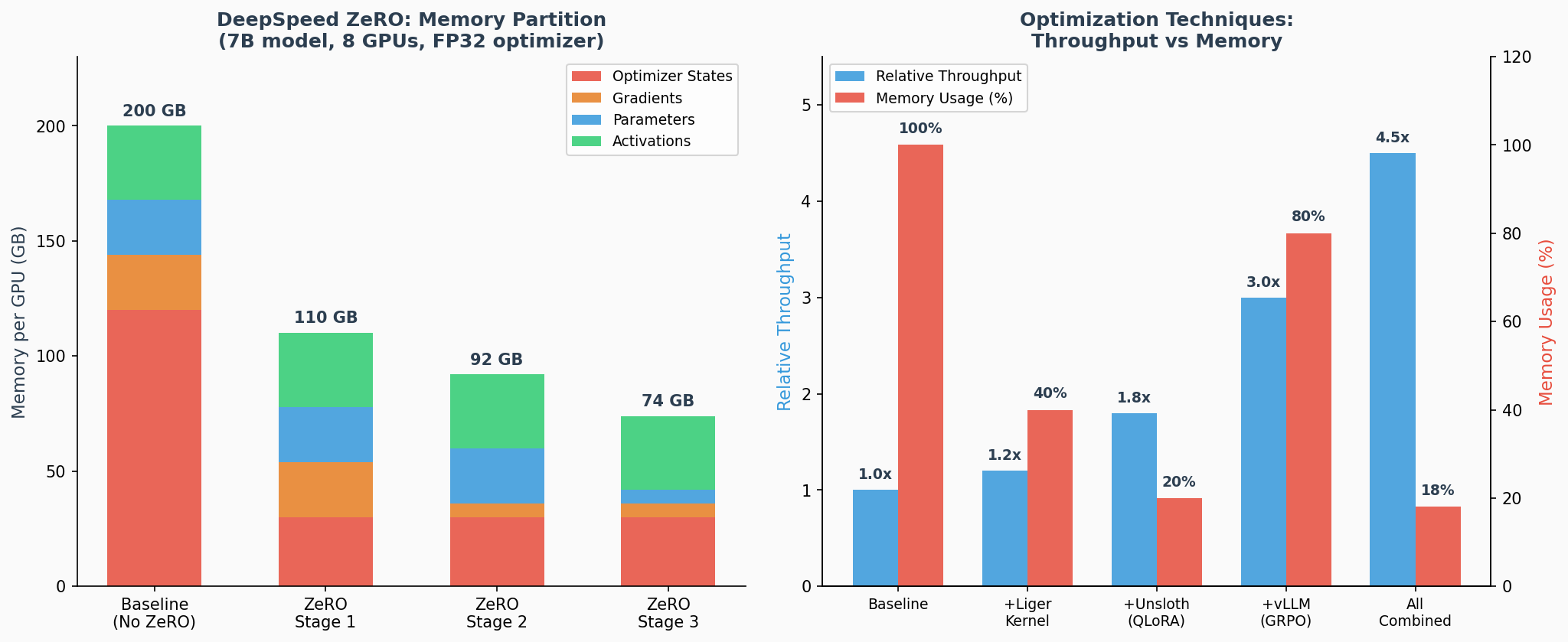
Stage 1 仅分片优化器状态(如 Adam 的一阶/二阶动量),通信量最小;Stage 2 进一步分片梯度,仅在需要更新参数时才做 All-Reduce;Stage 3 连模型参数也分片,每张 GPU 只存一个分片,前向/反向时按需从其他 GPU 获取——显存节省最大,但通信量也最大。
4.3 配置示例
使用 DeepSpeed 无需修改训练代码,只需准备 Accelerate 配置文件:
ZeRO Stage 2 配置(ds_zero2.yaml):
compute_environment: LOCAL_MACHINE
distributed_type: DEEPSPEED
deepspeed_config:
zero_stage: 2
offload_optimizer_device: none # 可改为 "cpu" 开启 CPU 卸载
offload_param_device: none
gradient_accumulation_steps: 4
gradient_clipping: 1.0
zero3_init_flag: false
mixed_precision: bf16
num_machines: 1
num_processes: 4 # GPU 数量ZeRO Stage 3 配置(ds_zero3.yaml):
compute_environment: LOCAL_MACHINE
distributed_type: DEEPSPEED
deepspeed_config:
zero_stage: 3
offload_optimizer_device: cpu # 将优化器状态卸载到 CPU
offload_param_device: cpu # 将模型参数卸载到 CPU
zero3_init_flag: true
zero3_save_16bit_model: true
mixed_precision: bf16
num_machines: 1
num_processes: 8启动训练:
accelerate launch --config_file ds_zero2.yaml train.py4.4 Sequence Parallelism:长序列训练
当单序列长度超过单卡显存所能容纳的范围(>32K tokens),DeepSpeed 还提供了 ALST/Ulysses 序列并行,将序列维度切分到多张 GPU 上。每张 GPU 处理一个序列片段,通过注意力头并行(Attention Head Parallelism)协调计算。
配置文件示例(4 GPU,2D 并行:SP=2 + DP=2):
compute_environment: LOCAL_MACHINE
distributed_type: DEEPSPEED
deepspeed_config:
zero_stage: 3
seq_parallel_communication_data_type: bf16
mixed_precision: bf16
num_processes: 4
parallelism_config:
parallelism_config_dp_shard_size: 2 # 数据并行分片数
parallelism_config_sp_size: 2 # 序列并行分片数
parallelism_config_sp_backend: deepspeedTRL 还支持基于 FSDP2 的 Ring Attention,两者的核心区别如下:
| 特性 | Ring Attention (FSDP2) | Ulysses (DeepSpeed) |
|---|---|---|
| 通信模式 | 点对点环形传递 | All-to-All 集合通信 |
| 注意力头约束 | 无约束 | num_heads >= sp_size |
| 最大序列长度 | 1M+ tokens | ~500K tokens |
| 网络要求 | 对拓扑不敏感 | 需要高带宽互联(NVLink) |
| 训练后端 | PyTorch FSDP v2 | DeepSpeed ZeRO |
4.5 多节点训练
当单机 GPU 不足时,可通过 Accelerate 配置多节点训练:
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
num_machines: 2
machine_rank: 0
main_process_ip: 10.0.0.1
main_process_port: 29500
num_processes: 16 # 所有节点 GPU 总数
mixed_precision: bf16# 节点 0(主节点)
accelerate launch --config_file multi_node.yaml --machine_rank 0 train.py
# 节点 1
accelerate launch --config_file multi_node.yaml --machine_rank 1 train.py对于 SLURM 集群,可通过 sbatch 提交:
#!/bin/bash
#SBATCH --nodes=2
#SBATCH --gpus-per-node=8
#SBATCH --job-name=trl_train
srun accelerate launch --config_file multi_node.yaml train.py五、BEMA:参考模型优化
在 DPO 训练中,参考模型(Reference Model)需要常驻显存以计算 KL 散度约束。TRL 提供了 BEMA(Bayesian Exponential Moving Average) 算法,通过回调函数动态更新参考模型,避免加载独立的参考模型副本:
from trl.experimental.bema_for_ref_model import BEMACallback, DPOTrainer
from datasets import load_dataset
dataset = load_dataset("trl-lib/ultrafeedback_binarized", split="train")
bema_callback = BEMACallback(update_ref_model=True)
trainer = DPOTrainer(
model="Qwen/Qwen2.5-7B",
train_dataset=dataset,
callbacks=[bema_callback],
)
trainer.train()BEMA 在训练过程中对参考模型权重做指数滑动平均更新,既保持了 KL 约束的有效性,又节省了一份完整模型副本的显存开销。
六、优化手段对比与组合策略
6.1 各技术适用场景总览
| 优化技术 | 优化维度 | 典型收益 | 适用训练器 | 硬件要求 |
|---|---|---|---|---|
| vLLM | 在线推理加速 | 吞吐量 3~14x | GRPO, RLOO, OnlineDPO | 需要额外 GPU |
| Liger Kernel | 算子融合 | 吞吐量 +20%, 显存 -60% | SFT, DPO, GRPO, KTO, GKD | 无额外要求 |
| HF Kernels | 注意力加速 | 零编译开销 | 所有训练器 | 无额外要求 |
| Unsloth | 显存优化 + 速度 | 速度 2x, 显存 -80% | SFT 为主 | 单 GPU 即可 |
| DeepSpeed ZeRO | 模型分片 | 支持超大模型 | 所有训练器 | 多 GPU |
| Seq Parallel | 序列分片 | 支持超长序列 | SFT | 多 GPU + 高带宽 |
| BEMA | 参考模型优化 | 节省一份模型显存 | DPO | 无额外要求 |
6.2 推荐组合方案
场景一:单卡微调 7B 模型(消费级 GPU)
# Unsloth QLoRA + Liger Kernel
from unsloth import FastLanguageModel
from trl import SFTConfig, SFTTrainer
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/mistral-7b",
max_seq_length=4096,
load_in_4bit=True,
)
model = FastLanguageModel.get_peft_model(model, r=16, target_modules=[
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
])
training_args = SFTConfig(
output_dir="./output",
use_liger_kernel=True, # 叠加 Liger 算子融合
max_length=4096,
per_device_train_batch_size=4,
bf16=True,
)场景二:多卡 GRPO 训练(8xH100)
# 4 卡 vLLM 推理 + 4 卡训练 + DeepSpeed ZeRO-2
CUDA_VISIBLE_DEVICES=0,1,2,3 trl vllm-serve \
--model Qwen/Qwen2.5-7B --tensor-parallel-size 4
CUDA_VISIBLE_DEVICES=4,5,6,7 accelerate launch \
--config_file ds_zero2.yaml train_grpo.pytraining_args = GRPOConfig(
output_dir="./grpo_output",
use_vllm=True,
vllm_mode="server",
use_liger_kernel=True, # vLLM + Liger + DeepSpeed 三重加速
per_device_train_batch_size=4,
num_generations=8,
)场景三:超长序列 SFT(128K context)
# Ring Attention + Liger Kernel + FSDP2
training_args = SFTConfig(
output_dir="./long_ctx_output",
max_length=131072, # 128K 序列
use_liger_kernel=True,
pad_to_multiple_of=16, # cp_size=8 时需 pad 到 16 的倍数
packing=True, # 启用 packing 减少填充浪费
per_device_train_batch_size=1,
bf16=True,
)# 使用 8 GPU Context Parallelism 配置启动
accelerate launch --config_file context_parallel_8gpu.yaml train.py6.3 组合兼容性速查
下表帮助快速判断哪些优化可以同时使用:
| vLLM | Liger | HF Kernels | Unsloth | DeepSpeed | FSDP2 | |
|---|---|---|---|---|---|---|
| vLLM | - | 兼容 | 兼容 | N/A | 兼容 | 兼容 |
| Liger | 兼容 | - | 兼容 | 部分重叠 | 兼容 | 兼容 |
| HF Kernels | 兼容 | 兼容 | - | 未测试 | 兼容 | 兼容 |
| Unsloth | N/A | 部分重叠 | 未测试 | - | 未官方支持 | 未官方支持 |
| DeepSpeed | 兼容 | 兼容 | 兼容 | 未官方支持 | - | 互斥 |
| FSDP2 | 兼容 | 兼容 | 兼容 | 未官方支持 | 互斥 | - |
提示:Unsloth 内置了自己的 Triton 优化算子,与 Liger Kernel 在功能上有重叠(两者都优化了 RMSNorm、RoPE 等算子)。同时启用可能不会带来额外收益。Unsloth 主要面向单卡场景,与 DeepSpeed/FSDP 的多卡方案不在同一使用场景。
本节小结
TRL 的性能优化工具链覆盖了 LLM 训练的四大瓶颈:vLLM 解决在线方法的推理速度问题,Liger Kernel 和 HF Kernels 通过算子融合提升计算密度,Unsloth 用量化和手写 Triton 内核压缩显存开销,DeepSpeed/FSDP 将训练扩展到多卡和多机。这些工具大多只需一两行配置即可启用,且相互之间高度兼容——合理组合后,即使在有限硬件条件下也能高效完成大模型的后训练流程。