2.2 编码-解码架构与 Seq2Seq
在自然语言处理中,许多核心任务——机器翻译、文本摘要、对话生成——都可以归结为同一类问题:给定一个变长输入序列,生成一个变长输出序列。输入与输出之间既没有长度对齐,也没有逐位置的对应关系。传统的单一 RNN 难以直接处理这种"序列到序列"的映射,因为它天然假设输入和输出等长。2014 年,Sutskever 等人和 Cho 等人几乎同时提出了 Seq2Seq(Sequence-to-Sequence) 模型,其核心正是一个通用的 编码器-解码器(Encoder-Decoder) 框架。这一架构奠定了后来 Attention 机制乃至 Transformer 的基础,是理解现代大模型演进不可绕过的一环。
2.2.1 Encoder-Decoder 框架
编码器-解码器架构的设计思想极为简洁:将"理解输入"和"生成输出"两个子任务分别交给两个独立的模块。

图 2-3:Encoder-Decoder 架构总览。输入序列经编码器压缩为固定形状的状态表示,解码器基于该状态逐步生成输出序列。
编码器(Encoder) 接收变长的输入序列
其中
最简单的选择是直接取最后一个时刻的隐藏状态
解码器(Decoder) 是一个条件语言模型:它以上下文变量
然后通过一个全连接层加 softmax,输出目标词表上的概率分布 <bos> 开始,遇到终止符 <eos> 时停止。
这个框架的优雅之处在于:编码器和解码器可以独立选择不同的网络结构和参数。只要编码器能输出一个固定形状的状态、解码器能接收这个状态作为初始条件,整个系统就能端到端训练。
2.2.2 基于 RNN 的 Seq2Seq 模型
将 Encoder-Decoder 框架用 RNN 实例化,便得到经典的 Seq2Seq 模型。以英语到法语的机器翻译为例,编码器逐个读入英文 token"They""are""watching"".",最终隐藏状态 <bos> 开始,依次生成法语 token"Ils""regardent""."直到输出 <eos>。
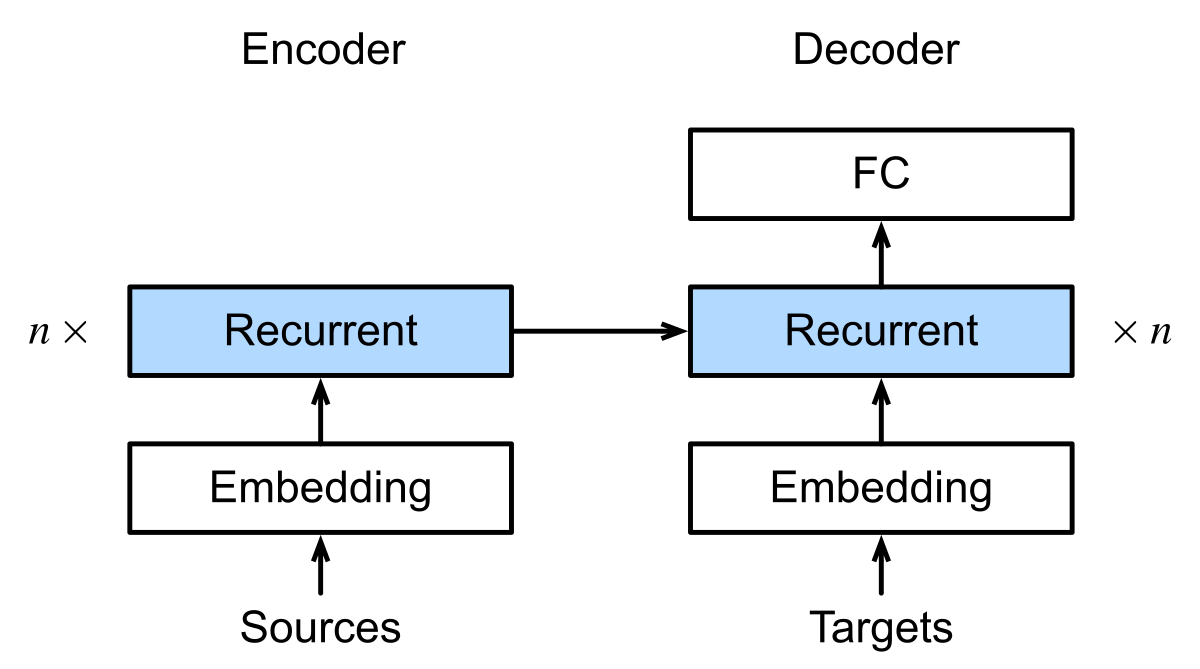
图 2-4:基于 RNN 的 Seq2Seq 模型层次结构。编码器和解码器各自包含嵌入层和多层 GRU/LSTM,上下文变量在每个解码时间步与输入词向量拼接后送入解码器 RNN。
具体实现中有几个关键设计决策:
词嵌入层。 输入和输出的 token 首先通过嵌入层映射为稠密向量。编码器和解码器通常各有独立的嵌入矩阵,因为源语言和目标语言的词表不同。
上下文变量的传递方式。 一种方案是仅用编码器的最终隐藏状态初始化解码器的第一步隐藏状态(Sutskever 等人的做法);另一种方案是将上下文变量在每个解码时间步都与当前输入拼接,送入解码器 RNN(Cho 等人的做法)。后者让解码器在每一步都能"看到"编码器的信息,效果通常更好。
Teacher Forcing。 训练时,解码器的每一步输入使用的是真实目标序列(ground truth)的前一个 token,而非模型自己上一步的预测。具体地,将 <bos> 与去掉最后一个 token 的目标序列拼接作为解码器输入,对应的标签则是去掉 <bos> 并附加 <eos> 的目标序列。Teacher Forcing 让训练更加稳定高效,避免了错误预测在解码过程中不断累积(即"暴露偏差"问题,exposure bias)。
损失函数与 Padding 掩码。 由于不同训练样本的目标序列长度不等,batch 内需要用 <pad> 补齐到统一长度。计算交叉熵损失时,必须用掩码将 <pad> 位置的损失置零,避免填充 token 干扰梯度。
BLEU 评估指标。 机器翻译领域使用 BLEU(Bilingual Evaluation Understudy)衡量生成质量。BLEU 的核心是计算预测序列中各长度
其中
2.2.3 信息瓶颈问题
Seq2Seq 的一个根本缺陷是:无论输入序列多长,编码器都必须将全部信息压缩到一个固定维度的上下文向量中。这就是所谓的信息瓶颈(information bottleneck)。当输入序列较短时,
Bahdanau 等人在 2014 年提出了 Attention 机制来突破这一瓶颈:解码器在每一步不再只看单一的
2.2.4 解码策略:从贪心搜索到 Beam Search
训练完成后,解码器在推理时需要一种策略来从概率分布中选取 token,逐步构建输出序列。目标是找到使整个序列联合概率最大的输出:
但这是一个指数级搜索问题——若词表大小为
贪心搜索(Greedy Search) 是最简单的策略:每步选择条件概率最大的 token:
计算复杂度仅为
Beam Search(束搜索) 在贪心与穷举之间取得平衡,是实际系统中最常用的解码策略。其核心思想是:在每一步保留
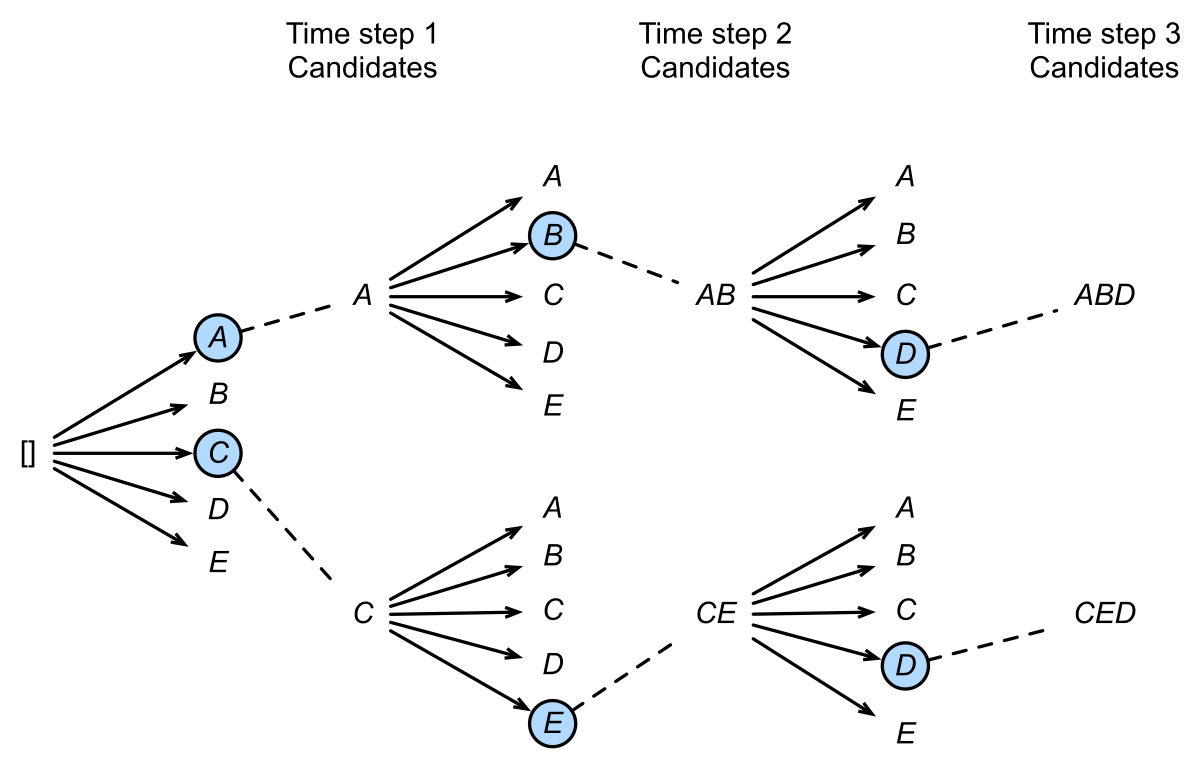
图 2-5:Beam Search 搜索过程(束宽
Beam Search 的具体步骤如下:
算法: Beam Search
输入: 编码器上下文 c,束宽 k,最大长度 T',词表 V
输出: 最优输出序列
1. 初始化: 候选集 B = {(<bos>, 0)} // (序列, 对数概率)
2. FOR t' = 1 TO T':
a. 对 B 中每条候选序列 (y_{1..t'-1}, score):
- 若该序列已以 <eos> 结尾,直接保留到候选集
- 否则,计算 P(y | y_{1..t'-1}, c) 对所有 y in V
- 生成 |V| 条扩展序列,累积对数概率:
score_new = score + log P(y | y_{1..t'-1}, c)
b. 从所有扩展序列中选取 score 最高的 k 条,更新 B
3. 对 B 中所有已完成的序列,按长度归一化得分排序:
score_final = (1 / L^α) * Σ log P(y_t' | y_{1..t'-1}, c)
4. 返回得分最高的序列其中长度惩罚因子
Beam Search 的计算复杂度为
随机采样策略。 在文本生成(如对话、创意写作)场景中,确定性的 Beam Search 会导致输出单调重复。此时通常采用随机采样策略:
- Top-
采样:仅保留概率最高的 个 token,其余概率置零后重新归一化,再从中随机采样。 - Top-
(Nucleus)采样:保留累积概率刚好超过阈值 的最小 token 集合,从中采样。相比 Top- ,它能根据分布的"尖锐程度"自适应调整候选数量。 - Temperature 缩放:在 softmax 前将 logits 除以温度参数
。 使分布更尖锐(更确定), 使分布更平滑(更随机)。
这些策略常组合使用。例如 GPT 系列模型的默认推理配置通常同时启用 Top-
2.2.5 本节小结
本节从 Encoder-Decoder 框架出发,系统介绍了 Seq2Seq 模型的架构设计、训练方法和推理策略。编码器将变长输入压缩为固定形状的上下文表示,解码器以此为条件自回归地生成输出序列。Teacher Forcing 保证了训练稳定性,Beam Search 在推理时兼顾了搜索质量与计算效率。
然而,这一架构的固有局限——信息瓶颈——在处理长序列时表现尤为突出。将全部信息压缩到单一向量的做法,本质上丢弃了输入序列的位置细节和局部结构。为了突破这一瓶颈,Attention 机制应运而生:它让解码器在每一步都能"回顾"编码器的完整输出序列,按需提取相关信息。这一思想不仅大幅提升了 Seq2Seq 的性能,更催生了 Transformer 架构中的核心组件——自注意力机制(Self-Attention),这将是下一节的主题。