5.5 Scaling Law
训练大语言模型的核心决策问题是:给定有限的计算预算,应该训练多大的模型、使用多少数据?Scaling Law(缩放定律)提供了一套数学工具来回答这个问题。它揭示了模型性能(以测试集交叉熵损失衡量)与三个宏观变量——参数量
本节将从 Kaplan 的经典幂律关系出发,介绍 Chinchilla 最优分配对早期结论的修正,详解 IsoFLOP 等实验方法论,并进一步讨论关键批量大小、超参数迁移(muP)、WSD 调度器等工程实践,最后简要介绍推理端的 Scaling Law。

图 5-17:大规模预训练的数据配比策略。不同数据来源(网页、代码、学术等)的混合比例对模型性能有显著影响。
5.5.1 标准 Scaling Law:Kaplan 幂律
2020 年,OpenAI 的 Kaplan 等人发表了奠基性论文 Scaling Laws for Neural Language Models,首次系统性地揭示了 Transformer 语言模型的性能与模型规模、数据集大小和计算量之间的精确幂律关系。
幂律的数学形式。 Scaling Law 的通用形式为:
其中
三个独立的幂律关系。 Kaplan 等人发现,在其他因素不构成瓶颈的前提下,损失分别与数据量、参数量、计算量满足以下关系:
- 数据量缩放:
- 参数量缩放:
其中
- 计算量缩放:
这里
三个典型阶段。 模型性能随规模变化通常经历三个阶段:
- 随机猜测区:模型太小,无法学习任何有效模式,损失停留在高位。
- 幂律缩放区:投入成倍的资源会带来固定比例的损失下降,在双对数坐标下呈严格线性。这是我们主要关注的区域。
- 饱和区:损失无限逼近数据本身的信息熵极限
,即不可约误差。
协同缩放的必要性。 前述三条幂律各自成立的前提是"其他因素不构成瓶颈"。在实际场景中,资源总是有限的。如果固定数据量
Kaplan 等人基于此提出了联合缩放建议:当计算预算
这一结论意味着应优先扩大模型参数量,数据量的增长比例相对较小。然而,后续研究发现这一结论存在系统性偏差。
其他发现。 Kaplan 等人还考察了若干潜在影响因素:
- 模型架构:在固定参数量的前提下,性能对深度、宽度、注意力头数等架构选择不敏感,只要宽高比保持在合理范围内(如 4 到 16)。
- 学习率:只要不太小且衰减不太快,对性能的影响有限。
- 样本效率:大模型比小模型具有更高的样本效率——达到相同损失水平,大模型需要的训练数据更少。这意味着大模型能更有效地从每个数据点中提取信息。
- 数据分布偏移:模型在域外数据上的损失会出现固定幅度的上升,但整体趋势仍与训练集上的表现成正比。
5.5.2 Chinchilla 最优分配
2022 年,DeepMind 的 Hoffmann 等人发表了 Training Compute-Optimal Large Language Models(即 Chinchilla 论文),对 Kaplan 的结论做出了关键修正。
核心发现:参数与数据等比缩放。 Chinchilla 的核心结论是:在固定计算预算下,参数量
这与 Kaplan 建议的"重参数、轻数据"(
两套幂律公式的对比。 下表总结了 Kaplan 和 Chinchilla 两套 Scaling Law 的关键差异:
| 维度 | Kaplan (OpenAI, 2020) | Chinchilla (DeepMind, 2022) |
|---|---|---|
| 损失函数形式 | ||
| 核心主张 | 优先扩大模型参数量 | 参数量与数据量等比扩展 |
| Token/Parameter 比 | 远低于 20:1 | 约 20:1 |
表 5-6:Kaplan 与 Chinchilla 两套 Scaling Law 对比。
Chinchilla 损失预测公式。 Chinchilla 提出了一个联合损失函数:
其中
实验验证。 为验证上述结论,DeepMind 用 1.4 万亿 token 训练了一个仅 70B 参数的 Chinchilla 模型——其参数量远小于 Gopher(280B)、GPT-3(175B)和 Megatron-Turing NLG(530B)。然而,Chinchilla 在众多下游任务上的表现反而优于这些更大的模型。这有力地证明了当时的大模型普遍处于训练不足(undertrained)状态:参数量过大而训练数据不够充分。
Kaplan 偏差的根源。 Kaplan 等人的分析之所以高估了参数量的重要性,一个关键原因是其实验中学习率调度器(cosine schedule)的总步数设置与实际训练步数不匹配,导致在小数据量下模型未充分收敛,从而系统性地低估了数据的贡献。
5.5.3 IsoFLOP 分析方法
Chinchilla 论文使用了三种不同的方法来拟合缩放定律,其中最直观、应用最广的是 IsoFLOP 分析(等算力线分析)。
方法原理。 IsoFLOP 分析的核心思路是:在固定计算预算
具体步骤如下:
- 设定多个固定的 FLOPs 预算等级(如
)。 - 对于每个预算等级,训练一系列不同参数量的模型。由于总计算量固定(
),参数量 越大,训练 token 数 就越少,反之亦然。 - 记录每个
组合的最终损失值。 - 对每个预算等级,绘制损失值关于模型参数量的曲线。
- 找到每条曲线的最低点,得到该预算下的最优模型配置。
- 将所有预算等级的最优点进行拟合,得出
和 随 增长的幂律关系。
U 型曲线与甜点区。 IsoFLOP 分析中最具特征性的现象是 U 型曲线。对于每个固定的计算预算,损失值关于模型参数量呈现清晰的 U 形:
- 左侧(
太小, 极大):模型容量不足,即使看了大量数据也无法充分学习数据中的模式,处于欠拟合状态,损失较高。 - 右侧(
极大, 太小):由于计算预算固定,过大的模型意味着训练数据严重不足。模型"脑容量"很大但只读了几页书,训练极不充分,损失同样很高。 - 谷底(甜点区,Sweet Spot):即最优的
组合。此时模型容量与训练数据量达到最佳平衡,损失最低。
图示说明(IsoFLOP 曲线示意图,ch05_sec5_isoflop_curve.png):图中每条彩色曲线代表一个固定的计算预算等级。横轴为模型参数量
(对数刻度),纵轴为最终损失值 。每条曲线呈 U 型,谷底即该预算下的最优模型大小。随着计算预算增加,U 型曲线整体下移(更多算力可达到更低损失),谷底对应的最优参数量也向右移动(更多算力应配以更大模型)。将所有谷底连线,即可得到计算最优前沿(Compute-Optimal Frontier)。
三种拟合方法对比。 Chinchilla 论文实际采用了三种方法:
- 训练曲线包络法(方法一):训练一系列不同规模的模型,绘制损失-计算量曲线,取各曲线的最低损失点构成最优包络线。
- IsoFLOP 配置法(方法二):即上述的 U 型曲线分析,最为直观。
- 参数化损失函数拟合法(方法三):直接拟合
的参数。
三种方法的前两种结论高度一致,第三种方法的拟合结果略有偏差但总体方向相同。
小模型外推方法论。 IsoFLOP 分析的实用价值在于:我们只需在小规模(如数百万到数十亿参数)上进行系统性实验,拟合出幂律参数后,就可以外推预测数百倍规模大模型的性能。这种"用小模型预测大模型"的方法论是大模型研发中控制成本的核心手段。工程实践中,通常使用非线性最小二乘法(如 scipy.optimize.curve_fit)拟合幂律公式
5.5.4 关键批量大小
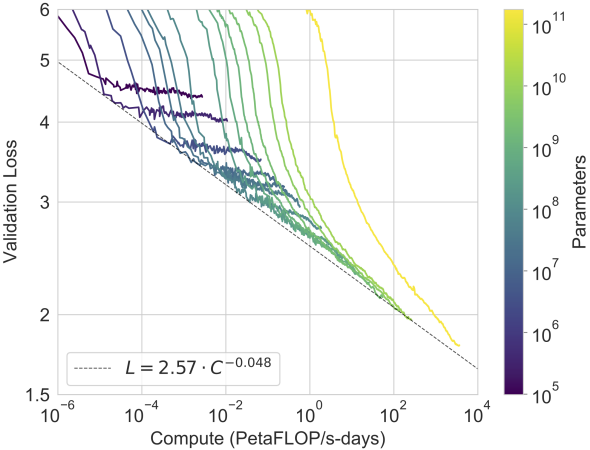
图 5-18:GPT-3 的缩放实验数据。模型参数量从 125M 到 175B,在多项基准上展现出清晰的幂律缩放关系。
在大规模训练中,批量大小(batch size)的选择直接影响训练效率和硬件利用率。Scaling Law 的研究揭示了一个重要概念——关键批量大小(Critical Batch Size,
定义与直觉。 关键批量大小是训练效率的转折点:
- 当
时:增加批量大小几乎线性地减少所需的训练步数。每增加一个样本都在有效降低梯度估计中的随机噪声,是时间效率最优的区域。 - 当
时:增加批量大小带来的收益急剧递减。额外的样本并未显著改善梯度方向的估计,因为梯度噪声已经小于优化地形(loss landscape)本身的曲率影响。继续增大批量只是在浪费计算资源。
梯度噪声尺度。 关键批量大小的本质与梯度噪声尺度(Gradient Noise Scale)直接相关。OpenAI 的研究给出了如下估计公式:
其中
动态变化:损失越低,
这一现象解释了为什么 Llama 3 等大模型训练中采用了动态批量调度(Dynamic Batch Scheduling)策略——在训练初期使用较小的批量大小,随着训练推进逐步增大。具体做法通常是在训练的后半段将批量大小翻倍,既充分利用了早期的计算效率,又在后期保证了梯度估计的精度。
工程实践建议。 在实际训练中,可以通过将一个大批量拆分为多个微批量(micro-batch)来估算梯度方差,进而计算当前的
5.5.5 muP 超参数转移
随着模型规模的不断扩大,超参数调优成为一个日益昂贵的问题。在标准参数化(Standard Parametrization, SP)下,最优学习率会随模型宽度的变化而漂移,迫使研究者在每个尺度上重新进行超参数搜索。最大更新参数化(Maximal Update Parametrization, muP)提供了一种优雅的解决方案:通过重新设计权重的初始化方差和学习率缩放规则,使得在小模型上调优的超参数可以零成本迁移到大模型。
核心思想:两个谱条件。 muP 的推导基于两个关于网络行为的物理假设,旨在确保信号在任意宽度的网络中既不爆炸也不消失:
- 条件 A1——初始化时激活值稳定:随着网络宽度
,每一层的激活值向量的坐标元素大小应保持为 。这意味着激活值向量的范数 随 增长。 - 条件 A2——梯度更新后激活值稳定:进行一次梯度更新步后,激活值的变化量
也应保持为 。这确保了模型在训练初期就能进行有效的特征学习。
数学推导简述。 考虑一个线性层
- 为了满足条件 A1(激活值稳定),根据随机矩阵理论,权重矩阵的初始化方差需要设为
,其中 为输入维度(fan-in)。 - 为了满足条件 A2(更新量稳定),不同优化器的学习率缩放规则不同:
- SGD:
- Adam:由于 Adam 对梯度的二阶矩进行了归一化,学习率通常缩放为
- SGD:
Transformer 中的 muP 缩放规则。 下表列出了 muP 在 Transformer 架构中对各类参数的具体要求(以 AdamW 优化器为例),其中
| 参数类型 | 初始化方差 | Adam 学习率缩放 |
|---|---|---|
| Embedding ( | 常数 | 常数 |
| Attention Q/K/V/O | ||
| FFN 权重 | ||
| 输出层 ( |
表 5-7:muP 在 Transformer 中的缩放规则(AdamW 优化器)。
此外,muP 还要求修改注意力机制的缩放因子:
# 标准 Transformer
attention_scores = (Q @ K.T) / math.sqrt(d_head)
# muP Transformer:缩放因子从 1/sqrt(d) 变为 1/d
attention_scores = (Q @ K.T) / d_head这一看似微小的改动背后有严格的理论依据:在 muP 下,Query 和 Key 向量的范数随宽度的缩放行为发生了变化,因此需要更强的归一化来保持注意力分数的稳定性。
实践验证。 Cerebras 团队在 Cerebras-GPT 项目中全面采用 muP,发现在 40M 参数的代理模型上搜索出的最佳学习率,可以按照上述规则直接迁移到 13B 模型,且损失预测极其精准。MiniCPM 同样使用 muP 来稳定超参数。
局限性。 第三方复现研究(Lingle, 2024)表明,muP 对 SwiGLU、Squared ReLU 等激活函数以及不同批量大小具有良好的鲁棒性;但当引入 RMSNorm 的可学习增益(learnable gain)、使用 Lion 优化器或施加强权重衰减时,muP 的迁移特性可能失效。
5.5.6 WSD 调度器
图 5-19:Few-shot 性能随模型规模的缩放。更大的模型在少样本学习任务上表现更优,体现了参数规模对 in-context learning 能力的影响。
学习率调度器是预训练中的关键组件之一。传统的余弦调度器(Cosine Schedule)存在一个严重的实用缺陷:其衰减曲线与总训练步数强耦合,一旦设定了总步数就无法灵活调整。WSD(Warmup-Stable-Decay)调度器解决了这一问题,并在 MiniCPM 和 DeepSeek LLM 等模型的训练中得到广泛采用。
三阶段设计。 WSD 调度器将学习率变化分为三个阶段:
- Warmup(预热):学习率从 0 线性增加到最大值
。通常占总训练步数的很小比例(如 1%-5%)。 - Stable(稳定):学习率保持在
不变,持续训练大部分时间(如 80%-90% 的 token)。这一阶段模型处于持续学习状态。 - Decay(衰减):在训练结束前,学习率迅速衰减(通常采用余弦衰减或线性衰减)到 0 或极小值。
与传统余弦调度器在预热结束后学习率就开始持续下降不同,WSD 在大部分训练过程中维持恒定的高学习率。实验表明,模型损失的大幅下降主要发生在最终的 Decay 阶段——这被称为"冷却效应"(cool-down effect)。即使 Stable 阶段的损失下降速度较慢,一旦进入 Decay 阶段,损失会迅速收敛。
WSD 对 Scaling Law 研究的价值。 WSD 调度器最大的实用优势在于其"一鱼多吃"的特性,使其成为拟合 Scaling Law 的高效工具:
- 在 Stable 阶段的任意节点(如训练到 10%、20%、50%、100% 数据量时),都可以取出一个 checkpoint,对其执行一次短期的 Decay 操作(cool-down),得到该数据量下模型的最终收敛性能。
- 这意味着只需一次主干训练(Stable 阶段),加上多次低成本的 Decay 分支,就能获得同一模型在不同数据量下的性能数据。
- 传统做法需要为每个数据量都完整跑一次 cosine schedule 训练,成本为
;WSD 将其降至接近 。
这一特性使得 IsoFLOP 分析的实验成本大幅降低。MiniCPM 和 DeepSeek 都借助 WSD 高效地生成了大量
性能对比。 多项研究表明,WSD 最终达到的收敛效果与经过完美调整的余弦调度器相当,在某些长训练周期任务中甚至更优。考虑到其在灵活性和缩放分析方面的巨大优势,WSD 已成为后 Chinchilla 时代大模型训练的主流调度策略。
5.5.7 现代缩放实践:从 Chinchilla 到 Over-Training
Chinchilla 的 20:1 比例并非终极答案。随着数据质量提升和训练技术进步,现代模型的缩放策略已经发生了显著演化。
训练最优 vs. 推理最优。 Chinchilla 关注的是训练成本最优——给定计算预算,使训练损失最低。但在 LLM 产品化场景下,推理成本往往远超训练成本(一个模型训练一次但要服务数百万次推理请求)。推理成本主要由参数量
这被称为过训练(over-training)策略。例如,Llama 3 使用约 15 万亿 token 训练了一个 8B 参数的模型,token/parameter 比高达约 1875:1,远超 Chinchilla 的 20:1。虽然这增加了训练成本,但极大地降低了部署体积和推理延迟。
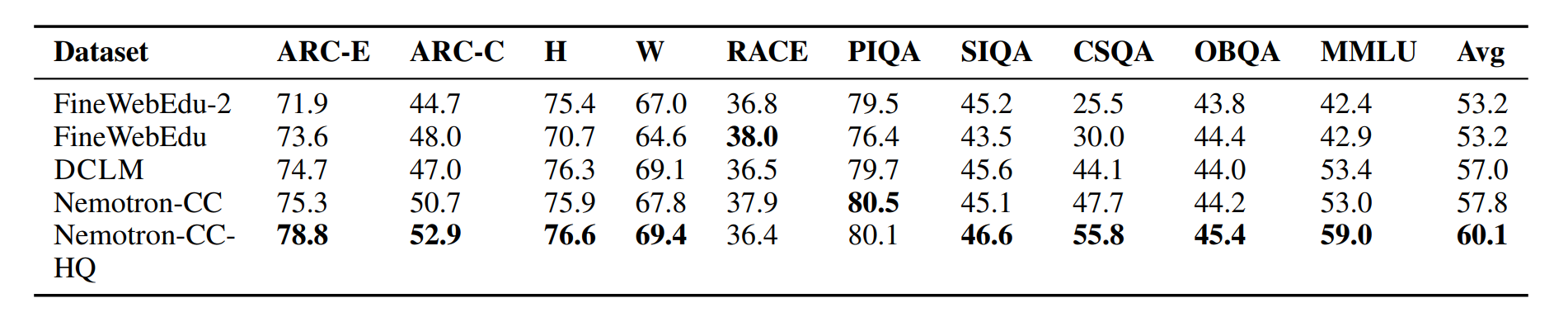
图 5-20:后 Chinchilla 时代的缩放策略对比。过训练(over-training)策略通过使用更多数据训练较小模型,在推理效率和性能之间取得更优平衡。
代表性缩放配方对比。 下表对比了三个后 Chinchilla 时代具有代表性的缩放策略:
| 特性 | Cerebras-GPT | MiniCPM | DeepSeek LLM |
|---|---|---|---|
| 超参数稳定性 | muP(核心) | muP | 网格搜索 + 缩放外推 |
| 学习率调度 | 传统 Cosine | WSD | WSD |
| Scaling 重点 | 模型宽度缩放 | 数据量缩放 | 综合 FLOPs 缩放 |
| 数据/参数比 | ~20:1 | ~192:1 | 动态分析(IsoFLOPs) |
表 5-8:后 Chinchilla 时代三种代表性缩放策略对比。
其中 MiniCPM 拟合出的最优数据/参数比高达 192:1,表明对于小模型(2B 级别),通过大量"过训练"可以达到极高的性能,同时在推理成本上具有显著优势。DeepSeek 没有使用 muP,而是通过在小规模模型上直接对关键批量大小和学习率进行网格搜索,拟合出超参数与计算量的对数线性关系,再外推到大模型。其成功表明:即使不依赖复杂的参数化技巧,只要缩放分析做得足够细致,也能精准预测大模型的行为。
数据墙与合成数据。 随着高质量人类文本数据逐渐耗尽("数据墙"),合成数据成为突破数据瓶颈的关键方向。数据质量比数量更关键——高质量数据可以显著改变缩放曲线的斜率,使同等计算量下达到更低的损失。
5.5.8 推理端 Scaling Law
传统 Scaling Law 聚焦于预训练阶段的资源分配。然而,以 OpenAI o1 和 DeepSeek-R1 为代表的推理模型揭示了一个新的维度:推理时计算量(Inference-Time Compute)同样遵循缩放定律。
核心思想。 推理端 Scaling Law 的基本假设是:允许模型在推理时消耗更多计算资源(如生成更长的思维链),可以系统性地提升其在复杂推理任务上的表现。这与人类解决难题时"多花时间思考"的直觉一致。
测试时扩展(Test-Time Scaling)的典型机制包括:
- 思维链(Chain-of-Thought, CoT):模型在输出最终答案前,先生成一段推理过程。推理步骤越多,消耗的计算量越大,但在数学证明、代码调试等需要多步推理的任务上效果显著。
- 多数投票/最佳选取(Best-of-N):对同一问题生成
个候选答案,通过投票或验证选取最佳答案。增加 提升了推理计算量,也提升了正确率。 - 搜索与验证:模型在推理时进行树搜索(如 MCTS),系统性地探索解空间。
与预训练 Scaling Law 的关系。 推理端缩放与预训练端缩放是互补而非替代的。当预训练的缩放收益开始放缓(数据墙、能源成本等约束),推理端缩放提供了另一个维度的性能提升途径。一个中等规模但经过强化学习训练的推理模型,在特定任务上可能优于纯粹靠堆参数训练出的更大模型。
推理端 Scaling Law 的研究目前仍处于早期阶段。一个核心的未解问题是:如何在预训练计算量和推理计算量之间进行最优分配?这可能需要一个统一的框架,将训练和推理的计算量纳入同一个优化目标。
本节小结
本节系统梳理了大语言模型 Scaling Law 的理论与实践:
- Kaplan 幂律奠定了基础框架,揭示了模型性能与参数量、数据量、计算量之间的幂律关系,但其"重参数、轻数据"的资源分配建议存在系统性偏差。
- Chinchilla 最优分配纠正了这一偏差,主张参数量与数据量应等比扩展(约 20:1 的 token/parameter 比),并通过实验验证了当时的大模型普遍处于训练不足状态。
- IsoFLOP 分析提供了一套实用的实验方法论,通过 U 型曲线找到给定计算预算下的最优配置,支持从小模型到大模型的性能外推。
- 关键批量大小标定了数据并行的效率边界,随训练推进(损失降低)而动态增大,指导了动态批量调度策略。
- muP 通过重新参数化使最优学习率在不同模型宽度上保持恒定,实现了超参数的零成本跨尺度迁移。
- WSD 调度器以其"一鱼多吃"的特性大幅降低了 Scaling Law 拟合的实验成本,成为后 Chinchilla 时代的主流学习率调度策略。
- 推理端 Scaling Law 开辟了性能提升的新维度——当预训练端缩放收益放缓时,通过在推理时投入更多计算(思维链、搜索等)来提升复杂任务上的表现。
Scaling Law 的核心价值不在于某一组具体的幂律参数,而在于它提供的方法论:用可控成本的小实验预测大规模训练的结果,将资源分配从"拍脑袋"变为有据可依的工程决策。 随着数据质量、训练技术和推理策略的持续演进,具体的最优比例(如 20:1 已被实践修正为远高于此)会不断变化,但这套方法论本身的价值是持久的。