11.3 万卡集群
当大模型的参数规模从千亿迈向万亿,训练所需的算力和数据吞吐量远超任何单机系统的极限。所谓"万卡集群",是指由数千乃至上万张 GPU/NPU 加速卡通过高速网络互联而成的超大规模计算系统,其目标是在数周到数月的训练周期内,高效、稳定地完成超大模型的预训练任务。从 Meta 的 24,576 张 H100 集群到 xAI 的 Colossus 十万卡超算,万卡集群已成为大模型时代的标配基础设施。
本节将系统性地剖析万卡集群的设计挑战、建设方案、测试验收流程,以及从 Hopper 到 Blackwell 的架构演进,并以 xAI Colossus 超算中心为案例,展示业界最前沿的实践。
11.3.1 万卡集群的核心挑战
建设万卡集群绝非"把上万张 GPU 卡简单堆在一起"那么简单。它面临着从电力供应到通信效率、从硬件故障到软件调度的全方位挑战,任何一个环节的短板都会严重拖累整体效率。
电力供应与散热。 这是万卡集群最底层、也最容易被低估的挑战。AI 芯片的功耗增长速度远超传统服务器:A100 单卡功耗为 250-400 W,H100 提升至 350-800 W,而最新的 Blackwell 架构 B200 单卡功耗已达 1000-1200 W,由两颗 B200 GPU 和一颗 Grace CPU 组成的 GB200 超级芯片总功耗高达 2700 W(数据来源:NVIDIA 官方产品规格,截至 2024 年)。以 10 万张 H100 GPU 计算,仅 GPU 部分的总功耗就达 52.5 MW,加上服务器、存储、网络等其他 IT 设备,整个集群总功耗可达 150 MW——年耗电量约 15.9 亿度,相当于约 15 万个家庭一年的用电量。
如此巨大的功耗密度使得传统风冷散热方案难以为继。液冷技术已成为万卡集群的必选项,包括冷板式液冷(在 GPU 等高热密度器件上安装金属冷板)和浸没式液冷(将整个服务器浸没在绝缘冷却液中)。混合散热架构——GPU 用液冷、网卡和内存用风冷——正成为主流方案。
供电架构也在经历变革。传统 12V 供电在大电流场景下 I²R 损耗严重,Google 在 2016 年提出 48V 机架供电方案,将配电损耗降低 16 倍。NVIDIA 更进一步提出 800V 直流架构以支撑 300 kW 以上的单机柜容量。Vicor 公司的垂直供电架构(Vertical Power Delivery, VPD)将电流倍增器直接放在处理器下方,实现 95-97% 的转换效率:
| 对比维度 | 传统 12V 架构 | 48V 直连架构 | VPD 垂直架构 |
|---|---|---|---|
| 传输损耗(100 μΩ 路径) | 100 W | 6.25 W | < 1 W |
| 转换效率 | 85-90% | 88-92% | 95-97% |
| 系统总效率 | 75-80% | 80-85% | 90-95% |
表 11-1:三种供电架构的损耗与效率对比。
网络通信瓶颈。 万卡集群中,GPU 间需要频繁进行梯度同步、参数更新和激活值传递。传统的 Ring AllReduce 通信算法在小规模集群中表现良好,但当 GPU 数量增长到万卡级别时,延迟随 GPU 数量线性增长——在 24,000 块 GPU 的集群中,树状通信算法在延迟上可优化约 180 倍。
光模块成本也是一个不容忽视的挑战。单个 10 万卡规模的 AI 集群需要 8-12 万个 800G 光模块,成本占集群总投资的 15-20%。InfiniBand 协议虽然提供了极低的通信延迟(微秒级),但 NVIDIA Quantum-2 交换机仅有 64 个 400 Gbps 端口,10 万卡集群需要 4 层 Clos 架构而非传统的 3 层,光模块成本因此增加约 33%。以太网 RoCE(RDMA over Converged Ethernet)方案正作为成本更优的替代方案崛起——Meta 的 24K H100 GPU 集群便采用了基于 RoCEv2 的单平面 Spine-Leaf 架构。
计算效率与 MFU。 模型 FLOPS 利用率(Model FLOPS Utilization, MFU)是衡量集群有效吞吐量的核心指标,定义为实际训练 FLOPS 与 GPU 峰值 FLOPS 的比值。当前万卡集群的 MFU 水平令人警醒:在 H100 集群的万亿参数训练中,16 位浮点运算通常仅实现约 30%–45% 的 MFU(Chowdhery et al., 2023; MegaScale, 2024),意味着超过半数的算力资源未被有效利用。
效率损失的根源是多方面的。通信延迟是最主要的瓶颈——在 10 万卡集群中,即使每条网络链路的平均故障间隔为 5 年,由于光模块数量众多,集群上发生第一次链路故障的期望时间仅为 26 分钟。MoE 模型的 All-to-All 通信更加剧了效率损失:与 AllReduce 的通信量为
字节跳动的 MegaScale 系统通过系统级优化,在 12,288 个 GPU 上训练 175B 参数模型时达到 55.2% 的 MFU,比 NVIDIA Megatron-LM 提升 1.34 倍,证明了通过精心设计可以显著提升计算效率。
硬件故障常态化。 万卡集群中,硬件故障不再是"偶发事件"而是"日常现实"。根据概率计算,假设单张 GPU 故障率为十万分之一,万卡集群的总体故障率为 9.5%,而十万卡集群的故障率飙升至 63.2%。Meta 在训练 Llama 3.1 时使用的 16,384 GPU 集群,在 54 天训练期间遇到 419 次意外故障——平均每 3 小时一次。故障类型分布如下:
- GPU 故障(148 次,占 30.1%):常见原因包括 Xid 错误、ECC 错误、NVLink 错误和 NCCL 通信错误
- HBM3 内存故障(72 次,占 17.2%):与 GPU 高功耗(700 W)带来的热应力密切相关
- 网络故障(约 35 次,占 8.4%):多为硬件故障(线缆或光模块失效),处理难度大、恢复时间长
- 其他故障:包括 CPU 故障(仅 2 次,说明 CPU 可靠性远高于 GPU)、存储故障、电源故障等
GPU 相关故障合计占全部意外中断的 58.7%。以 H100 集群每卡每小时算力成本约 10 元计算,万卡集群每次训练中断恢复耗时 1 小时,仅网络故障造成的单次算力损失就约 350 万元。
11.3.2 全栈建设方案:从机房到软件
万卡集群的建设是一个全栈工程,涵盖从 L0(基础设施)到 L3(上层应用软件)的全部层次。我们可以将其分为四个阶段:规划设计、硬件安装、软件部署和验收运维。
机房布局。 万卡集群采用以网络为核心的向心式布局:所有算力节点到网络核心节点的通信延迟必须控制在稳定的波动范围内。对于超大规模集群,通常采用同园区跨楼宇的多栋部署策略,核心设备居中、辅助区域环绕。

图 11-1:万卡集群机房功能分区布局,核心计算区居中部署,网络通信区、监控管理区和辅助设备区环绕四周。
机柜部署密度需要在空间利用率和运维便利性之间取得平衡。标准 42U 机柜中,每台 GPU 服务器高度约 4U,单机柜可放置 10 台。机柜按列部署(如 4 列 × 5 柜),列间距不小于 1.2 米以便运维。整个系统通常需预留 20-30% 的电力、机柜空间和网络带宽用于扩容。
布线设计。 布线方式直接影响集群的能效和可维护性。当前万卡集群普遍采用 TOR(Top of Rack) 布线方式——每个机柜顶部部署 1-2 台接入交换机,服务器通过短跳线接入柜内交换机,交换机上行通过光纤连接到汇聚层。相比传统的 EOR(End of Row)方案,TOR 方式大幅简化了机柜间布线,并提高了线缆密度。
在线缆选型上,万卡集群中最常见的三种线缆各有适用场景:机柜内 5 米以内的短距离连接优先使用 DAC 直连铜缆(成本低、功耗小);机柜间和楼栋间则使用多模光纤(短距高速,500 米以内)或单模光纤(长距传输,可达数十公里)。高密度布线通常采用 MPO/MTP 多芯光纤连接方案,单根线缆可集成 12-48 芯光纤,一次性完成多芯连接。
存算网络协同。 存储、计算和网络的协同设计是万卡集群区别于传统数据中心的关键。
在存储方面,传统集中式存储无法满足万卡规模的高并发访问需求,必须采用 Lustre、GPFS 等分布式文件系统,提供 PB 级数据存储和每秒 TB 级的 I/O 带宽。数据集通常按 128 MB 到 1 GB 的粒度分片,分片数量为 GPU 数量的 2-4 倍以确保负载均衡。
在网络方面,万卡集群通常采用 Rail-Optimized 网络架构(导轨优化)。以百度百舸 AIPod 为例,采用 8 导轨架构:每台 8 卡 GPU 服务器的 8 张网卡分别连接到 8 个不同的 TOR 汇聚组,TOR 和 Leaf 层通过 Full Mesh 互联。这种设计确保同号网卡间的通信可以通过单跳完成,最大限度减少跨轨通信的开销。
软件栈。 万卡集群的软件栈以 PyTorch + Megatron-LM 为核心。Megatron-LM 是 NVIDIA 开源的专为超大规模 Transformer 训练设计的框架,提供张量并行、流水线并行、序列并行、专家并行等全套并行策略。实测表明,即使在单机 8 卡环境下,Megatron-LM 比原生 PyTorch 的训练速度提升约 20%;在 MoE 模型上加速比可达 10 倍以上。
在调度方面,万卡集群通常采用 Kubernetes + Slurm 混合调度架构:K8s 管控在线服务,Slurm 调度离线训练任务。DeepSeek 的实践表明,这种混合架构将作业排队时间从 23 分钟缩短至 5 分钟以内,GPU 碎片率从 15-20% 降至 5% 以下,大规模作业成功率从 83% 提升至 99.6%。
调度策略需要支持多种算法的组合:Gang Scheduling(组调度,确保同一任务的所有 GPU 同时启动)、Topology-aware Scheduling(拓扑感知调度,将通信密集的进程放在网络拓扑邻近的节点上)和优先级队列(根据任务紧迫性和资源需求动态调整)。
快速故障恢复。 万卡集群的可靠性保障需要全栈配合。在硬件层面,通过 IPMI/BMC 管理接口实时监测服务器电源、温度和风扇状态;在系统层面,部署轻量级监控代理采集 CPU、内存、磁盘和网络指标;在应用层面,通过心跳机制检测训练进程的活跃度。当故障发生时,K8s 的 Node Controller 自动驱逐故障节点上的 Pod,结合预配置的备用节点池实现快速切换。
华为昇腾系统提出了分级恢复策略:进程级重调度恢复通过参数面网络将临终 Checkpoint 传递到备用节点,恢复时间缩短到 3 分钟以内;进程级在线恢复针对硬件 UCE 故障,通过 CANN 软件和 MindCluster 配合实现故障地址在线修复,恢复时间进一步缩短到 30 秒以内。百度百舸则基于 eBPF 技术构建了隐式故障感知体系,在不侵入用户代码的前提下,对训练进程的系统调用和网络通信进行微秒级跟踪,将隐式故障的平均检测时间从分钟级缩短至秒级。
11.3.3 测试验收:从单卡到万卡的递进验证
万卡集群的测试验收遵循"由小到大、由易到难、先功能再性能、先峰值再长稳"的核心原则,通过系统性的递进验证确保每个规模节点的稳定性。

图 11-2:万卡集群测试的完整流程,从镜像准备到分布式训练的全链路验证。
测试阶段设计。 测试规模采用指数级增长策略:
| 测试阶段 | 集群规模 | 测试重点 |
|---|---|---|
| 单机测试 | 1 节点(8 卡) | 单节点内多卡通信和负载均衡 |
| 小规模集群 | 16-64 卡 | 跨节点通信和任务分发 |
| 中规模集群 | 256-2048 卡 | 分布式训练功能、并行性能、中等规模压力测试 |
| 大规模集群 | 4096-万卡 | 大规模稳定性和集群性能极限 |
表 11-2:万卡集群递进式测试规模设计。
单核与单机压测。 单核压测使用 gpu_burn 等工具让 GPU 核心和显存满负载运行,检测硬件稳定性(过热、虚焊、供电问题)。单机压测则评估多 GPU 并行性能,关键指标包括加速比(Speedup)、效率(Efficiency = 加速比 / GPU 数量)和计算利用率。
通信压测。 这是万卡集群测试的核心环节。使用 NCCL-tests 测试 GPU 间集合通信性能,从单机多卡、跨节点、跨机架到全集群逐级推进。关键的测试维度包括:
- 通信原语:AllReduce、AllGather、ReduceScatter、All-to-All、Broadcast
- 数据规模:小包(1 KB 级,验证延迟稳定性)、中包(1-100 MB,吞吐量基准)、大包(500 MB-2 GB,批量传输性能)
- 通信协议:NVLink(节点内,1.8 TB/s)、InfiniBand(集群间,纳秒级延迟)、RoCE(成本敏感场景)
常用通信协议的性能特征对比如下:
| 协议 | 带宽 | 延迟 | CPU 开销 | 典型场景 |
|---|---|---|---|---|
| NVLink | 1.8 TB/s | 300 ns | 极低 | 单机多 GPU |
| InfiniBand | 400-800 Gbps | 纳秒级 | 低 | 大规模集群 |
| RoCE | 200-400 Gbps | 微秒级 | 低 | 成本敏感场景 |
| TCP/IP | 1-100 Gbps | 毫秒级 | 高 | 控制平面 |
表 11-4:万卡集群常用通信协议性能对比。
全集群万卡通信测试还需验证线性度——即通信性能是否随集群规模线性扩展。测试覆盖 256 卡、1024 卡、4096 卡、8192 卡、10240 卡等关键规模节点,在每个规模点上分别测试小消息(1-64 KB,主要受延迟影响)、中等消息(1-100 MB,平衡延迟与带宽)和大消息(500 MB-2 GB,主要受带宽影响)的通信性能。此外还需执行 24-72 小时的长时间稳定性压测,监控丢包率(目标
2K+X 冗余策略。 万卡集群测试通常配置 5-10% 的备用节点。以 2000 节点的测试集群为例,配置 100-200 个备用节点,采用"热备 + 冷备"混合策略:10% 的节点已启动并加入集群管理(热备),5% 关机待命(冷备)。故障切换采用自动化流程:检测到故障后将故障节点标记为不可用,从备用池选择健康节点,通过 K8s 重新调度训练任务,整个切换过程通常在 30 秒内完成。
性能验收指标。 万卡集群的验收需要评估多维度指标:
可靠性方面则关注 MTBF(平均无故障时间)和 MTTR(平均故障恢复时间)。目标是在万卡规模下实现 MFU > 40%、线性度 > 80%、有效训练率 > 95%。
下面的 Python 代码演示了如何根据单卡故障率估算不同规模集群的整体故障概率,以及集群首次故障的期望时间:
import math
def cluster_failure_analysis(
single_gpu_failure_rate: float = 1e-5, # 单卡故障率(每小时)
gpu_counts: list[int] = [1000, 10000, 100000],
link_mtbf_years: float = 5.0, # 单条链路平均无故障时间(年)
links_per_gpu: float = 3.6, # 每 GPU 对应的光模块数量
):
"""估算不同规模集群的故障概率与首次故障期望时间。"""
print(f"{'GPU 数量':>10} | {'整体故障率':>12} | {'首次GPU故障(h)':>14} | {'首次链路故障(min)':>16}")
print("-" * 65)
for n in gpu_counts:
# 至少一张 GPU 故障的概率:1 - (1-p)^n
p_failure = 1 - (1 - single_gpu_failure_rate) ** n
# 首次 GPU 故障的期望时间(小时)
expected_first_gpu_failure_h = 1 / (n * single_gpu_failure_rate)
# 光模块链路故障
num_links = int(n * links_per_gpu)
link_mtbf_hours = link_mtbf_years * 365.25 * 24
expected_first_link_failure_min = (link_mtbf_hours / num_links) * 60
print(f"{n:>10,} | {p_failure:>11.2%} | {expected_first_gpu_failure_h:>14.1f} | {expected_first_link_failure_min:>16.1f}")
cluster_failure_analysis()
# 输出示例:
# GPU 数量 | 整体故障率 | 首次GPU故障(h) | 首次链路故障(min)
# -----------------------------------------------------------------
# 1,000 | 0.99% | 100.0 | 7305.0
# 10,000 | 9.52% | 10.0 | 730.5
# 100,000 | 63.21% | 1.0 | 73.1这段代码清楚地展示了规模效应对可靠性的影响:10 万卡集群中,仅考虑 GPU 故障,期望每小时就会发生一次;加上光模块链路故障(基于每条链路 5 年 MTBF),首次链路故障的期望时间仅约 73 分钟。这就是为什么万卡集群必须将"容错"作为核心设计原则而非事后补救。
11.3.4 从 Hopper 到 Blackwell:集群架构演进
NVIDIA GPU 架构的每一次迭代都深刻影响着万卡集群的设计方式。从 Hopper 到 Blackwell,最显著的变化不仅是单卡算力的提升,更是从"芯片堆叠"到"整机柜解决方案"的系统级跃迁。

图 11-3:Blackwell 架构产品家族——从单芯片到 SuperPOD 的完整层次。B200 芯片采用双晶粒(2 Die)设计,4 颗 B200 芯片在算力上等效于 8 颗 Hopper 架构 GPU。
Blackwell 架构的关键突破。 Blackwell 最引人注目的创新是双晶粒(2 Die)设计——一颗 B200 芯片封装内包含两个独立的硅晶粒,通过 NVLink-C2C 高速互联。这意味着一张 B200 卡在计算资源上等效于两张 Hopper 架构的 GPU。在一个计算托盘(Compute Tray)中,4 颗 B200 芯片即可提供过去 8 颗 H100 的算力。
性能的提升体现在多个维度:FP16 算力从 H100 的 1 PFLOPS 跃升至 B200 的 2.25 PFLOPS;HBM 容量从 80 GB 增至 192 GB,带宽从 3 TB/s 提升至 8 TB/s;NVLink 带宽从 900 GB/s 翻倍至 1.8 TB/s。更重要的是,Blackwell 引入了 FP4 计算支持,在 GB200 上 FP4 算力达到 20 PFLOPS,为低精度推理开辟了新空间。
GB200 NVL72 与 SuperPOD。 GB200 NVL72 是 Blackwell 架构的旗舰集群单元,采用液冷机架设计,集成 36 个 GB200 Grace Blackwell 超级芯片(72 颗 GPU)。8 个 GB200 NVL72 组成一个 GB200 SuperPOD,总计 576 颗 GPU。
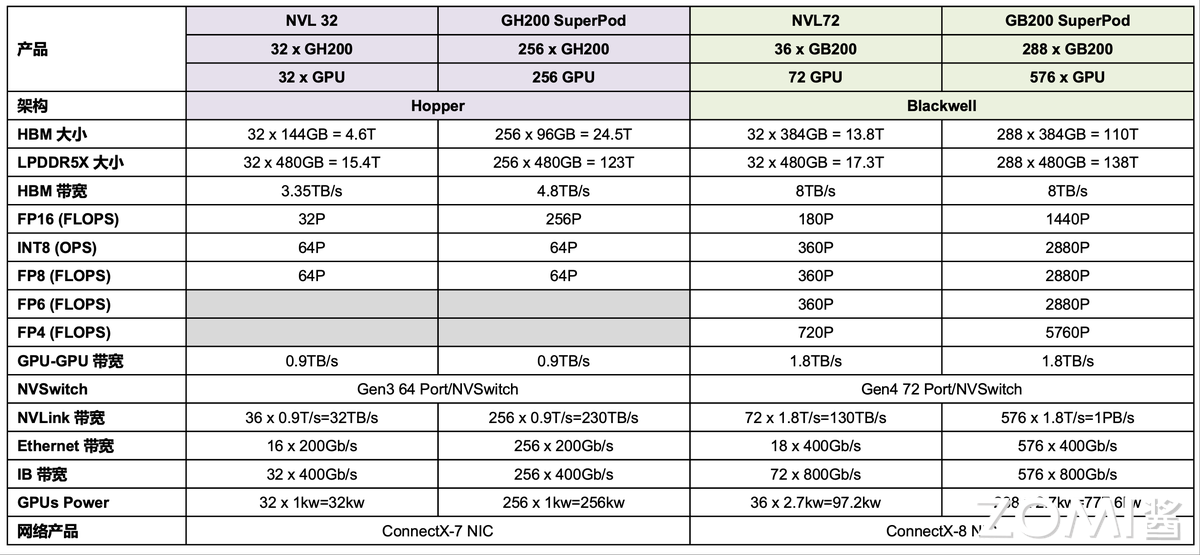
图 11-4:从 Hopper 到 Blackwell 的 NVL 与 SuperPOD 产品关键规格对比。GB200 SuperPOD 的 FP16 算力达到 1.44 EFLOPS,NVLink 总带宽达 1 PB/s。
下表对比了两代 SuperPOD 的核心指标:
| 指标 | GH200 SuperPod(Hopper) | GB200 SuperPod(Blackwell) |
|---|---|---|
| GPU 数量 | 256 | 576 |
| HBM 总容量 | 24.5 TB | 110 TB |
| FP16 算力 | 256 PFLOPS | 1440 PFLOPS(1.44 EFLOPS) |
| NVLink 总带宽 | 230 TB/s | 1 PB/s |
| IB 外部带宽 | 256 × 400 Gb/s | 576 × 800 Gb/s |
| 总功耗 | 256 kW | 777.6 kW |
表 11-3:Hopper 与 Blackwell SuperPOD 核心指标对比。
从表中可以看出,Blackwell SuperPOD 在 FP16 算力上实现了 5.6 倍的增长,NVLink 带宽提升 4.3 倍,但功耗仅增长 3 倍——这得益于双晶粒设计和更先进的制程工艺带来的能效提升。值得关注的是,IB 外部带宽从 400 Gb/s 升级到 800 Gb/s,表明 NVIDIA 也在积极解决节点间通信瓶颈。
11.3.5 xAI Colossus:十万卡超算案例
xAI 的 Colossus 超级计算机是截至 2024 年底公开报道中规模最大的 AI 训练集群之一,位于美国田纳西州孟菲斯市,拥有 10 万颗 NVIDIA H100 GPU。它的建设过程和技术选择,为万卡集群的工程实践提供了极具参考价值的案例。
硬件架构。 Colossus 采用超威电脑(Supermicro)的服务器,基于 NVIDIA HGX H100 方案,每台服务器配备 8 颗 H100 GPU,封装在 4U 液冷系统内。10 万颗 GPU 分布在约 12,500 台服务器中。集群配备了特斯拉 Megapack 储能系统,单个 Megapack 可存储 3.9 MWh 的电能,为集群提供电力缓冲和应急保障。
网络设计。 10 万卡规模的 InfiniBand 网络需要突破传统 3 层 Clos 架构的端口限制。Colossus 采用多层 Fat-Tree 拓扑,通过精心设计的路由策略和自适应负载均衡机制,确保任意两张 GPU 之间都能实现高带宽、低延迟通信。仅光模块部分就需要约 10 万个 800G 模块,功耗约 40 MW。
电力与散热方案。 Colossus 的总功耗约 150 MW,年电力成本约 1.24 亿美元。集群全面采用液冷散热方案,每台 4U 服务器内置冷板式液冷系统,通过 CDU(冷量分配单元)将热量传递至外部冷却水路。选址田纳西州的重要考量之一是电力资源——该地区电力供应充裕且成本相对较低。集群还配备了特斯拉 Megapack 电池储能系统作为 UPS 的补充,在市电波动时提供瞬时电力缓冲。
从建设速度看工程能力。 Colossus 的建设周期令人瞩目——据公开报道,从动工到初步投入运行仅用了约 122 天(2024 年初开始建设,2024 年 7 月开始运行;来源:The Information, 2024; Elon Musk X 平台公开声明)。如此紧迫的工期要求极高的工程协调能力:多方参与者(设计院、设备供应商、施工方)需要高度同步,机房基建(供电、制冷、布线)、硬件部署(12,500 台服务器上架、近千台交换机联调)和软件栈安装(操作系统、驱动、训练框架)三条线必须并行推进。超 10 万个光模块、8 万根数据线缆和 20 万个接头的安装与调试,构成了巨大的工程量。
可靠性实践。 在 10 万卡规模下,硬件故障是绝对的日常。假设单张 GPU 故障率为十万分之一,10 万卡集群的整体故障率高达 63.2%。Colossus 必须具备完善的故障检测、自动隔离和快速恢复机制:
- 多层次健康监控:硬件级(IPMI/BMC 监测温度、功耗、ECC 错误)→ 系统级(操作系统和驱动状态)→ 应用级(训练进程心跳和性能指标)
- 自动化故障切换:秒级检测、分钟级恢复,配合 5-10% 的热备/冷备节点池
- 高频 Checkpoint 保存:训练状态定期持久化到分布式存储,故障后从最近的检查点恢复。Checkpoint 间隔的选择需要在存储开销和回退代价之间权衡——间隔越短,故障恢复时回退的训练步数越少,但频繁保存会占用 I/O 带宽并暂停训练
- 光链路污染管理:10 万个光模块中,约 65% 的光链路故障由端面污染引起。需要建立从安装环节的洁净度控制(ISO 8 级以上洁净环境)到运行期间的在线脏污检测(如海思 StarSensor 技术,检测准确率达 90% 以上)的全生命周期管理
11.3.6 迈向十万卡:前瞻性思考
随着大模型参数规模持续膨胀,万卡级别可能很快成为"起步配置"。迈向十万卡甚至更大规模的集群,需要在多个维度上实现质的突破。
网络带宽 vs 计算算力的增速差。 GPU 算力的增长速度远快于网络带宽。从 Hopper 到 Blackwell,FP16 算力提升约 2.25 倍,而 InfiniBand 带宽仅从 400 Gb/s 升级到 800 Gb/s(2 倍)。这意味着通信占总训练时间的比例将持续上升,最终成为不可逾越的瓶颈。解决方案可能包括:更先进的通信-计算重叠技术、更高效的压缩通信算法(如 DeepSeek-V3 的自适应梯度压缩,可节省 40% 通信带宽),以及新型互联架构(如光电混合互联)。
集群可靠性的指数级挑战。 10 万卡集群中,每 26 分钟就可能发生一次网络链路故障。传统的"停机-排查-恢复"模式完全无法适应这种频率。未来集群需要实现无感故障恢复:在不中断训练的前提下自动隔离故障节点、重新分配计算任务。华为昇腾系统已在探索这一方向,其进程级在线恢复技术可将训练恢复时间缩短到 30 秒以内。
存算一体与近数据计算。 随着模型规模增长,数据搬运的能耗开始超过计算本身。将计算逻辑靠近数据存储,减少数据在 GPU、HBM 和网络之间的搬运距离,可能成为打破内存墙的关键路径。
国产化替代。 在地缘政治背景下,美国自 2022 年起四次升级对华出口管制,从禁止 A100/H100 到掐断 14 nm 以下技术的零部件供应,基于国产 NPU 构建万卡集群已成为刚需。华为昇腾万卡集群在 16,384 卡上完成了 405B 参数模型的预训练,MFU 达到 45.13%。
国产方案面临两个核心差距。算力差距:华为昇腾 910C 在 FP16 下约 800 TFLOPS,不到 NVIDIA B300(约 3840 TFLOPS)的四分之一。软件生态差距:全球 90% 的 AI 框架依赖 CUDA 接口,迁移到国产平台通常需要重写 35-40% 的代码,迁移周期约 3 个月。
不过,国产方案在互联技术上正在探索差异化路线。华为昇腾 384 超节点采用 MatrixLink 全光互联,总带宽达 1229 TB/s,芯片间时延仅 150 纳秒,而 NVIDIA NVL72 的 NVLink 铜缆互联总带宽为 130 TB/s,GPU 间时延在微秒级。这种"光互联换代差"的策略,为国产万卡集群提供了一条绕过单卡算力瓶颈的路径。
集群即产品的趋势。 从 Blackwell 的发展轨迹可以清晰看到,NVIDIA 正在从"卖芯片"转向"卖整柜"。GB200 NVL72 液冷整机柜、DGX SuperPOD 一体化交付,意味着未来的竞争焦点不再是单一芯片性能,而是从芯片、互联、散热、供电到软件的全栈系统集成能力。无论是国际巨头还是国产厂商,都需要在"造好芯"的基础上"搭好台",最终形成完整的计算生态。
本节小结
万卡集群是大模型时代的算力底座,其建设横跨电力供应、散热设计、网络互联、硬件可靠性和软件调度等多个工程维度。本节的核心要点如下:
- 挑战是全方位的:从电力供应(10 万卡集群功耗 150 MW)到硬件故障(每 3 小时一次)到计算效率(MFU 仅 40%),每个环节都存在严峻挑战。
- 建设是全栈的:涵盖 L0 机房布局(向心式部署、液冷散热)、L1 网络互联(Rail-Optimized 架构、Fat-Tree 拓扑)、L2 系统软件(Megatron-LM、K8s+Slurm 调度)和 L3 训练应用。
- 测试是递进的:从单卡压测到万卡长稳测试,通过 2K+X 冗余策略和多层次监控确保可靠性。
- 架构在演进:Blackwell 的双晶粒设计和 GB200 NVL72 液冷整机柜方案,标志着从"芯片堆叠"向"全栈系统解决方案"的转型。
- 十万卡是下一个前沿:xAI Colossus 已将集群规模推至 10 万卡,未来需要在网络带宽、故障自愈和存算协同等方面实现根本性突破。
- 可靠性是系统性工程:10 万卡集群每小时可能发生 GPU 故障、每 73 分钟可能发生链路故障,必须将容错作为设计核心而非事后补救。快速恢复(秒级检测、分钟级恢复)和高频 Checkpoint 是保障有效训练率的关键手段。
- 国产化道路任重道远:单卡算力和软件生态差距仍然显著,但光互联等差异化技术路线正在开辟新的可能性。