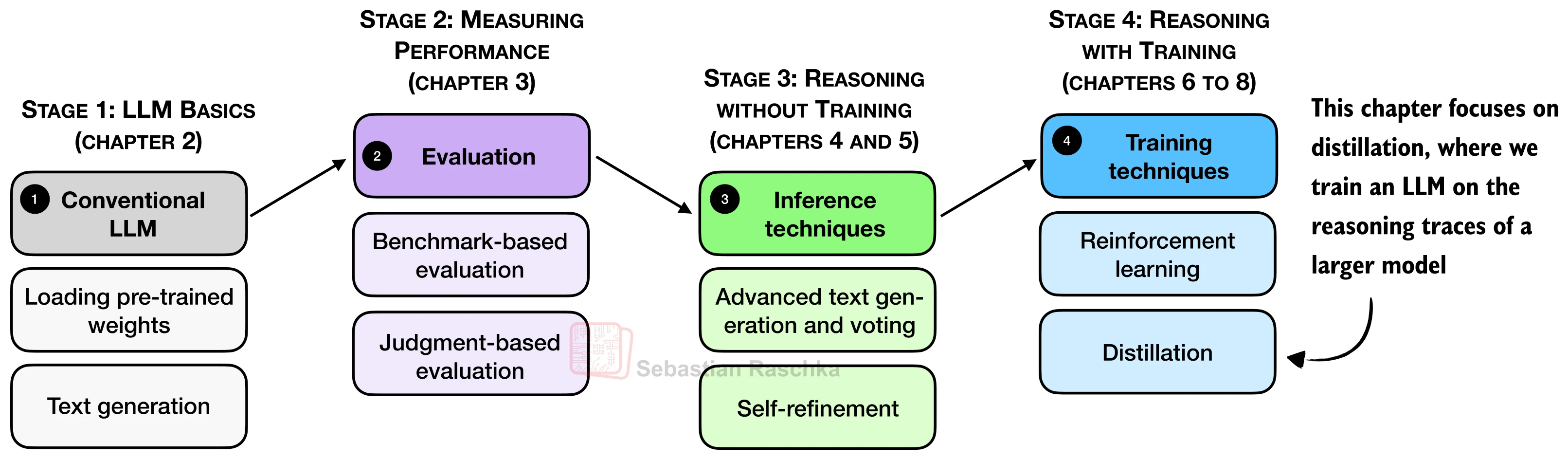
26.6 推理模型蒸馏
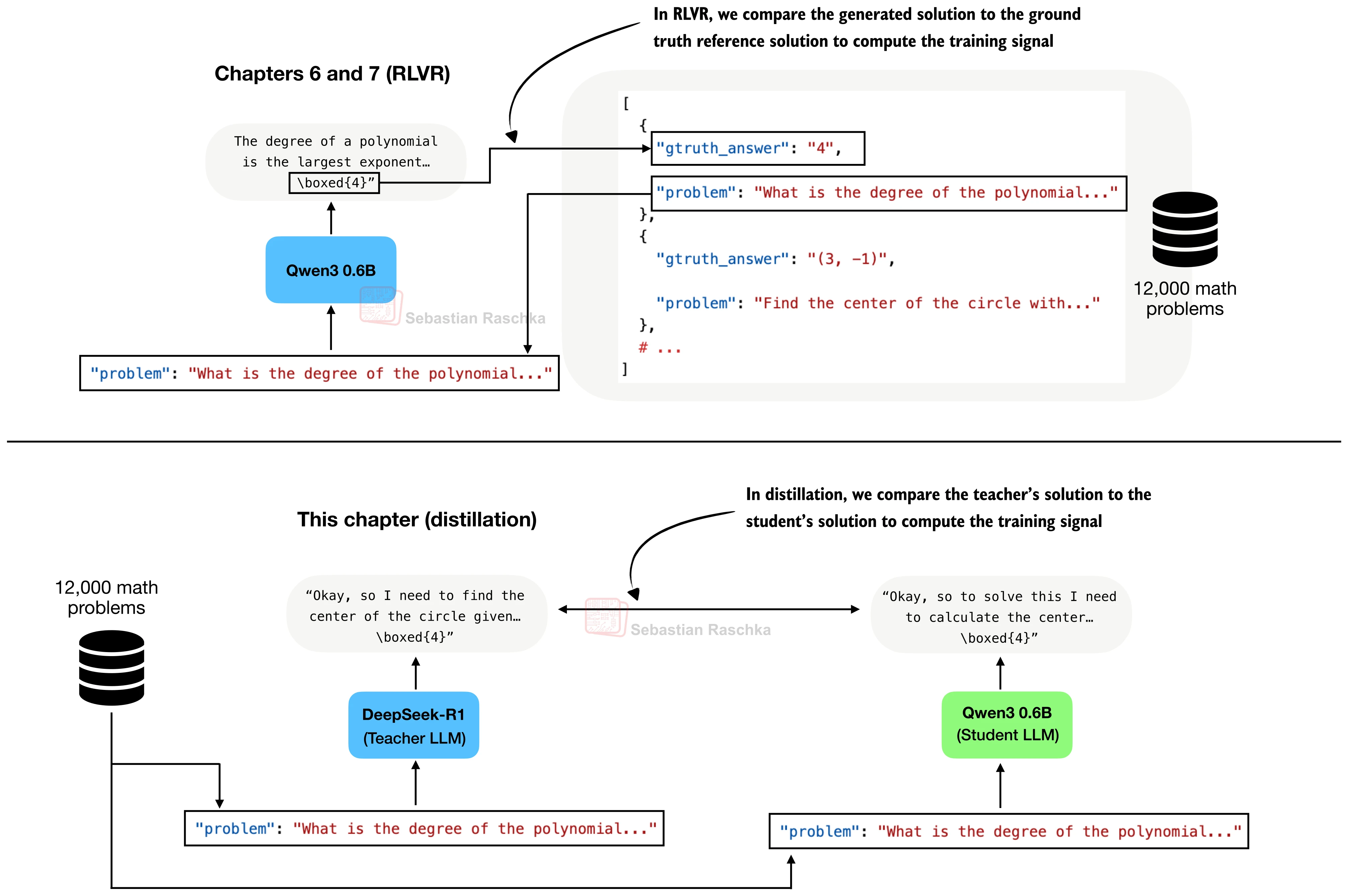
在前面几节中,我们介绍了如何通过强化学习(RLVR)让小模型自主习得推理能力。然而 DeepSeek-R1 的研究团队发现了一个引人注目的结论:对于较小的模型变体,蒸馏(Distillation)的效果往往优于从头进行 RLVR 训练(DeepSeek-AI, 2025)。他们先训练了一个 671B 参数的大型推理模型,再用它生成的推理轨迹去"教会"更小的模型——这一策略在实践中被证明既高效又可靠。本节将完整走通推理模型蒸馏的三个核心阶段:教师数据生成、蒸馏训练与效果评估。
一、蒸馏的基本原理
模型蒸馏(Model Distillation) 是指用一个大型的"教师"模型(Teacher)的输出来训练一个小型的"学生"模型(Student)。根据所使用的监督信号的类型,蒸馏可以分为三种范式:
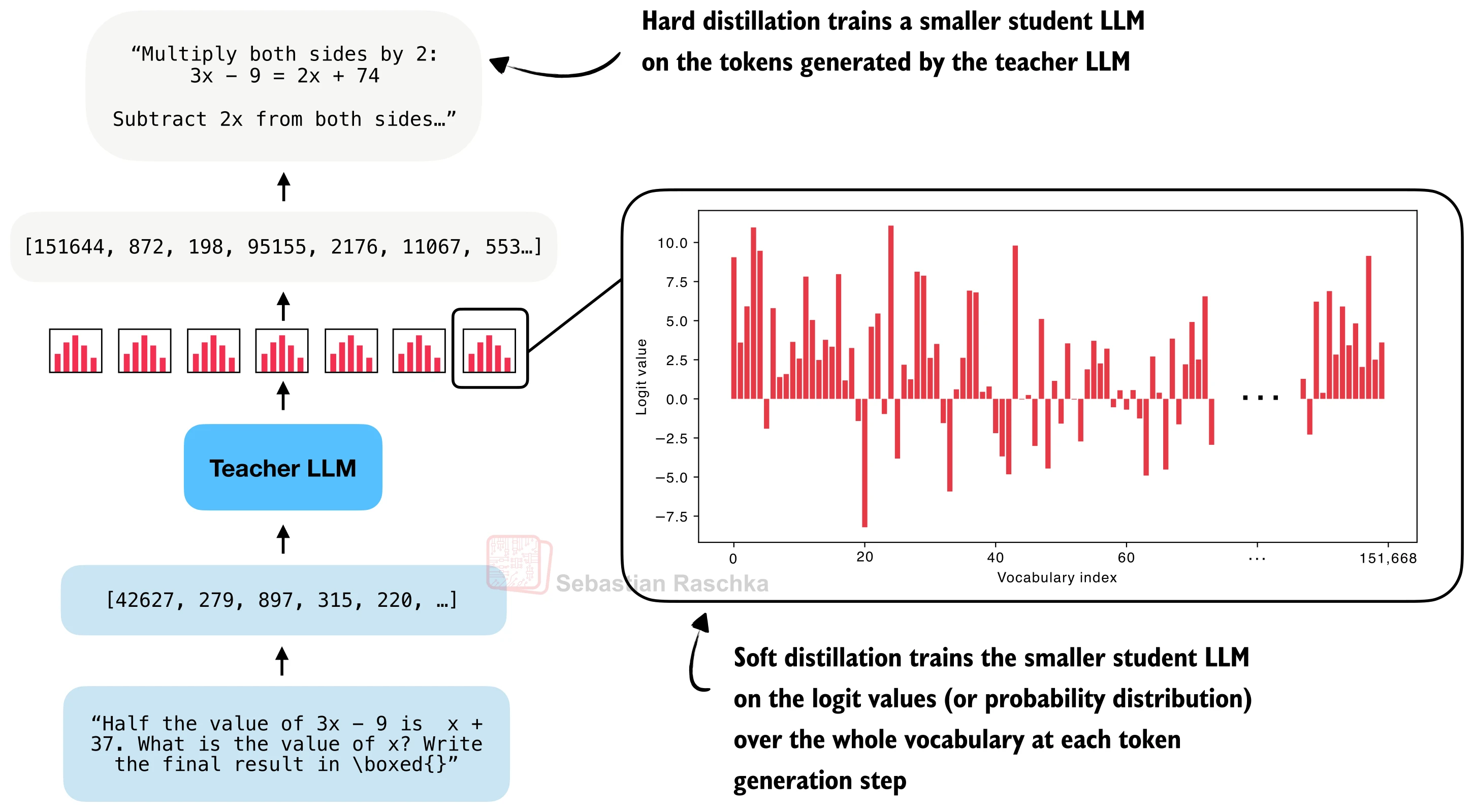
1. 硬蒸馏(Hard Distillation):学生模型直接在教师生成的文本上进行监督微调,将教师的输出 token 视为"标准答案"。损失函数为:
从技术上讲,这等价于在合成数据上做标准的监督微调(SFT)。不需要访问教师模型的内部 logits——只要能拿到教师的文本输出即可。DeepSeek-R1 对小模型的蒸馏正是采用了这一方式。
2. 软蒸馏(Soft Distillation):学生模型学习匹配教师的概率分布,而非离散的 token 序列。损失函数通常采用 KL 散度:
这要求在训练时能获取教师模型在每个位置上对整个词表的 logits 或对数概率。
3. 混合蒸馏:结合以上两者,这是 Hinton 等人 (2015) 在 Distilling the Knowledge in a Neural Network 中提出的经典知识蒸馏方法。损失函数为:
其中
为什么硬蒸馏在 LLM 场景中更常用? 原因有四:
- Logits 不可得:OpenAI、Anthropic 等闭源模型不暴露词表级别的 logits,软蒸馏无从下手。
- 词表不匹配:软蒸馏要求教师和学生使用相同的分词器,否则概率分布无法对齐。跨模型家族蒸馏时(如用 DeepSeek R1 蒸馏 Qwen3),这一条件通常不满足。
- 存储开销巨大:即使 logits 可得,为长序列存储完整的词表概率分布(词表大小可达 150K+)在带宽和磁盘上都代价高昂。
- 效果并非碾压:有研究表明数据生成策略可能比软硬蒸馏的选择本身更重要 (Agarwal et al., 2024)。
因此,本节聚焦硬蒸馏——这也是当前工业界最主流的做法。
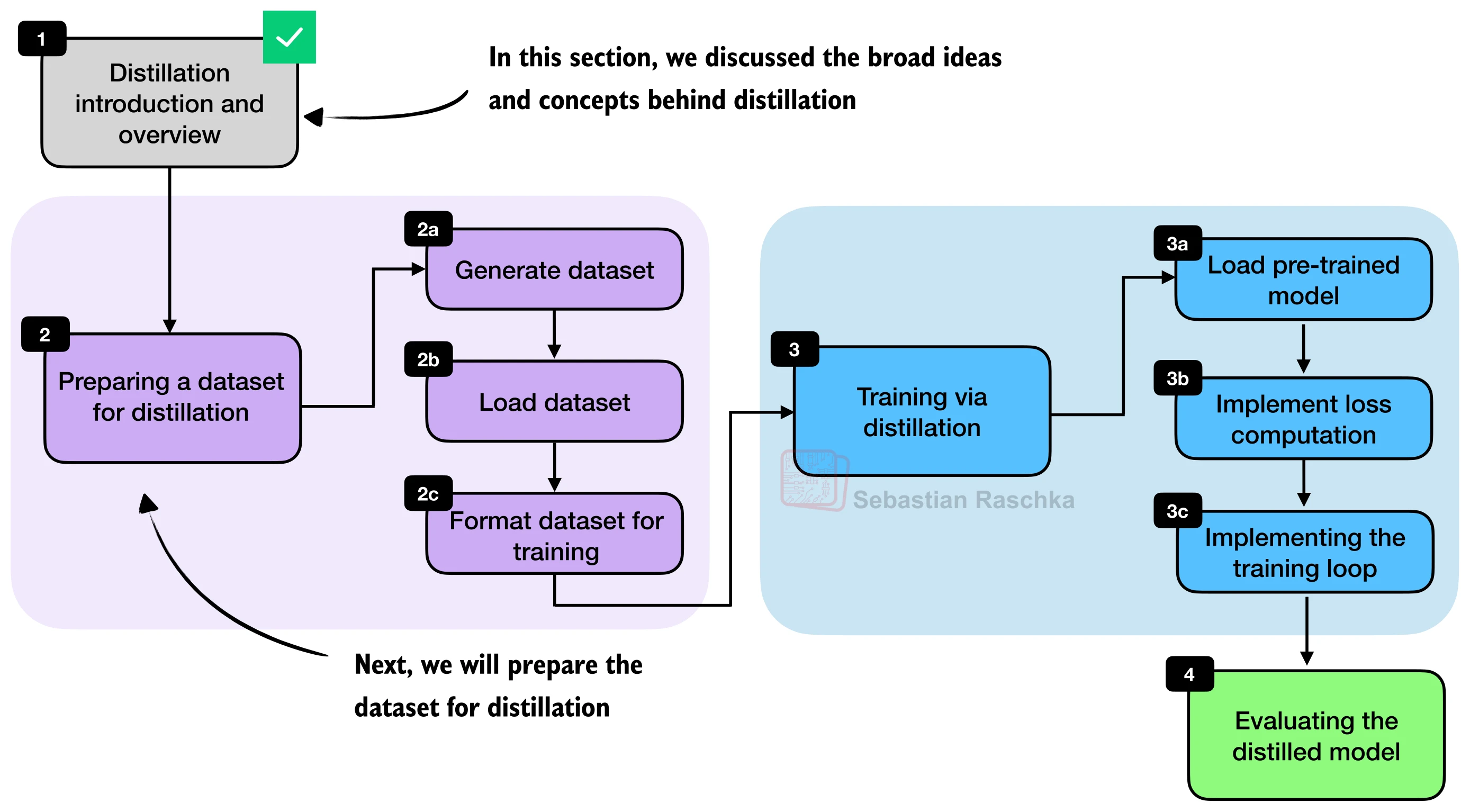
二、教师数据生成
蒸馏的第一步是生成教师数据集:将数学问题输入教师模型,收集其推理轨迹和最终答案。
与 RLVR 训练中模型"自行摸索"不同,蒸馏中学生模型直接学习教师"写好的解题过程"——这类似于学生抄优秀学长的作业来学习解题思路,而非自己反复试错。
2.1 数据格式
教师生成的每条数据包含四个字段:
{
"problem": "Sam is hired for a 20-day period...",
"gtruth_answer": "6",
"message_thinking": "Okay, let's see. Sam was hired for 20 days...",
"message_content": "Sam worked x days and did not work y days... \\boxed{6}"
}problem:原始数学题目gtruth_answer:标准答案(用于验证教师的正确率)message_thinking:教师的推理过程(thinking trace)message_content:教师的最终回答
训练时,message_thinking 和 message_content 会被拼接为完整的回答序列,用 <think>...</think> 标签包裹推理过程:
def format_distilled_answer(entry):
"""将教师的推理轨迹和最终答案格式化为训练目标"""
content = str(entry["message_content"]).strip()
thinking = str(entry["message_thinking"]).strip()
return f"<think>{thinking}</think>\n\n{content}"
# 示例输出:
# <think>Okay, let's see. Sam was hired for 20 days...</think>
#
# Sam worked x days and did not work y days... \boxed{6}2.2 数据生成方式
根据教师模型的规模,可以选择两种生成方式:
本地生成(适合较小教师模型):使用 Ollama 在本地运行模型。例如使用 DeepSeek-R1 的 8B 蒸馏版本:
import requests
import json
def query_teacher_local(problem, model="deepseek-r1:8b", max_tokens=8192):
"""通过 Ollama API 查询本地运行的教师模型"""
prompt = (
"You are a helpful math assistant.\n"
"Answer the question and write the final result on a new line as:\n"
"\\boxed{ANSWER}\n\n"
f"Question:\n{problem}\n\nAnswer:"
)
response = requests.post(
"http://localhost:11434/api/chat",
json={
"model": model,
"messages": [{"role": "user", "content": prompt}],
"stream": False,
"options": {"num_predict": max_tokens, "temperature": 0.0}
},
timeout=300
)
result = response.json()
message = result["message"]
return {
"message_thinking": message.get("thinking", ""),
"message_content": message.get("content", "")
}云端 API 生成(适合大型教师模型):对于 671B 参数的 DeepSeek R1 等无法本地运行的模型,可以使用 OpenRouter 等云端 API。成本估算:以平均输入长度 11 token、平均输出长度 1524 token 计算,使用 DeepSeek R1 生成 1,000 条数据的费用约为 3.82 美元(输入 0.70 美元/M tokens,输出 2.50 美元/M tokens)。
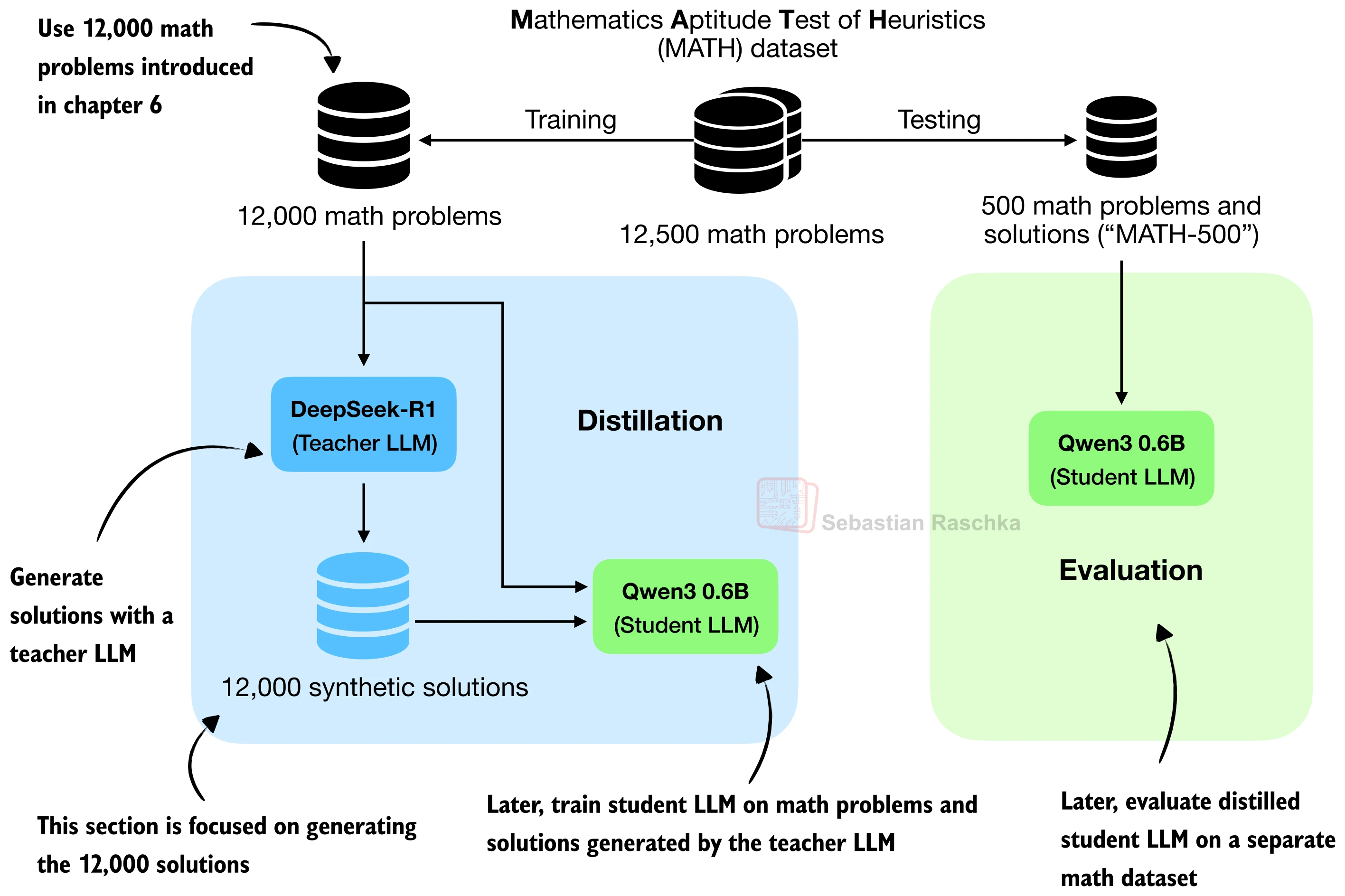
在实际实验中,使用 671B 参数的 DeepSeek R1 作为教师,对 MATH 训练集中 12,000 道数学题生成答案。教师在训练集上的正确率约为 90.6%(10,871/12,000)——这意味着约 9.4% 的训练样本包含错误答案,学生模型将不可避免地从中学到一些错误。这是蒸馏的一个固有限制:学生的上限取决于教师的质量。
2.3 教师选择的影响
不同教师模型的质量直接决定了蒸馏效果。后续实验将对比两位"教师":
- DeepSeek R1(671B):参数量巨大,推理能力强,但推理过程较长
- Qwen3 235B A22B:采用 MoE 架构(总参数 235B,激活参数 22B),推理效率更高
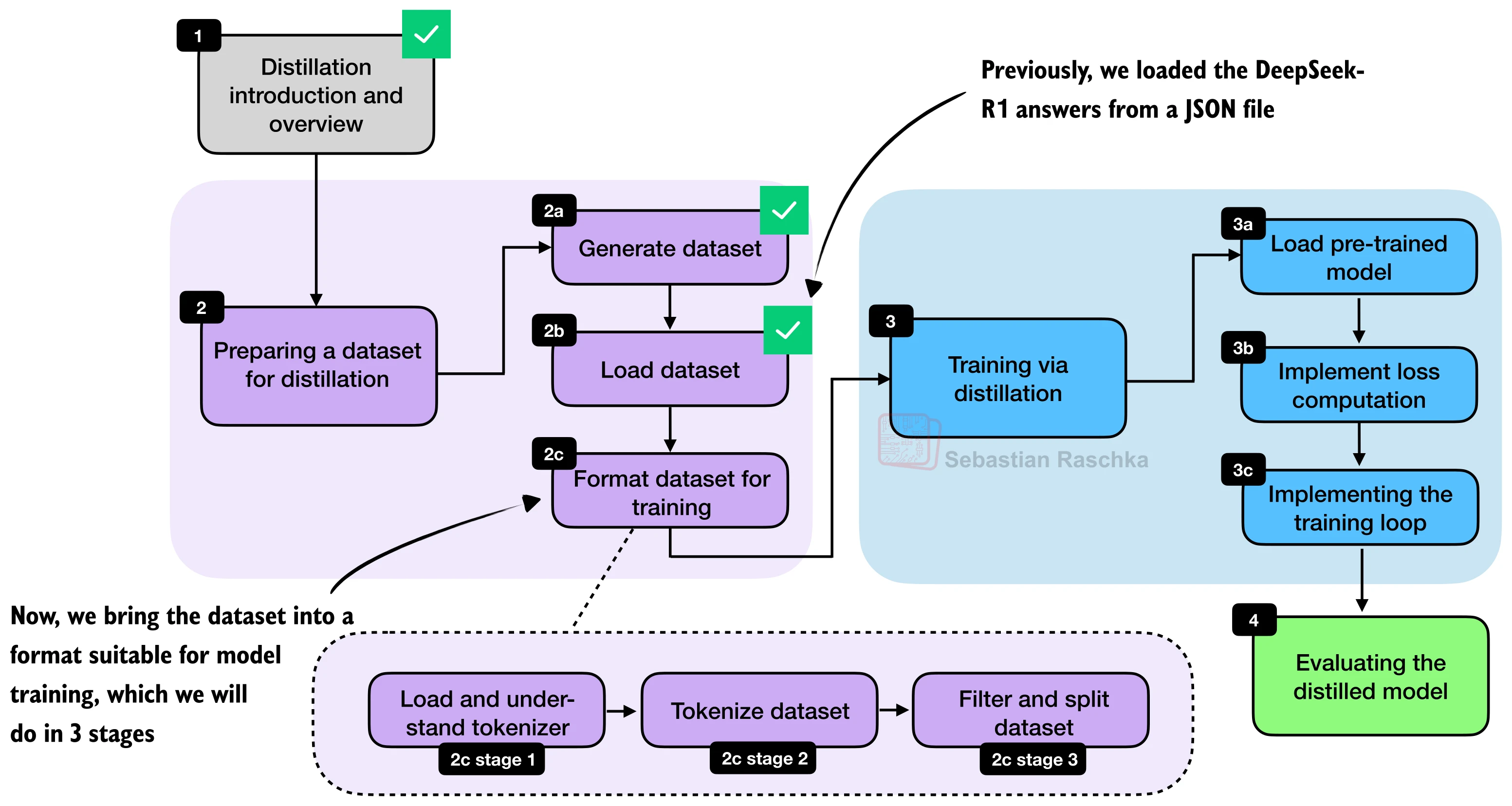
三、数据预处理与训练样本构建
拿到教师数据后,需要经过格式化、分词、过滤和划分四个步骤才能送入训练。
3.1 格式化与分词
每条训练样本由提示词(prompt) 和回答(answer) 两部分拼接而成。提示词使用聊天模板(chat template)包裹,回答部分包含教师的推理过程和最终答案:
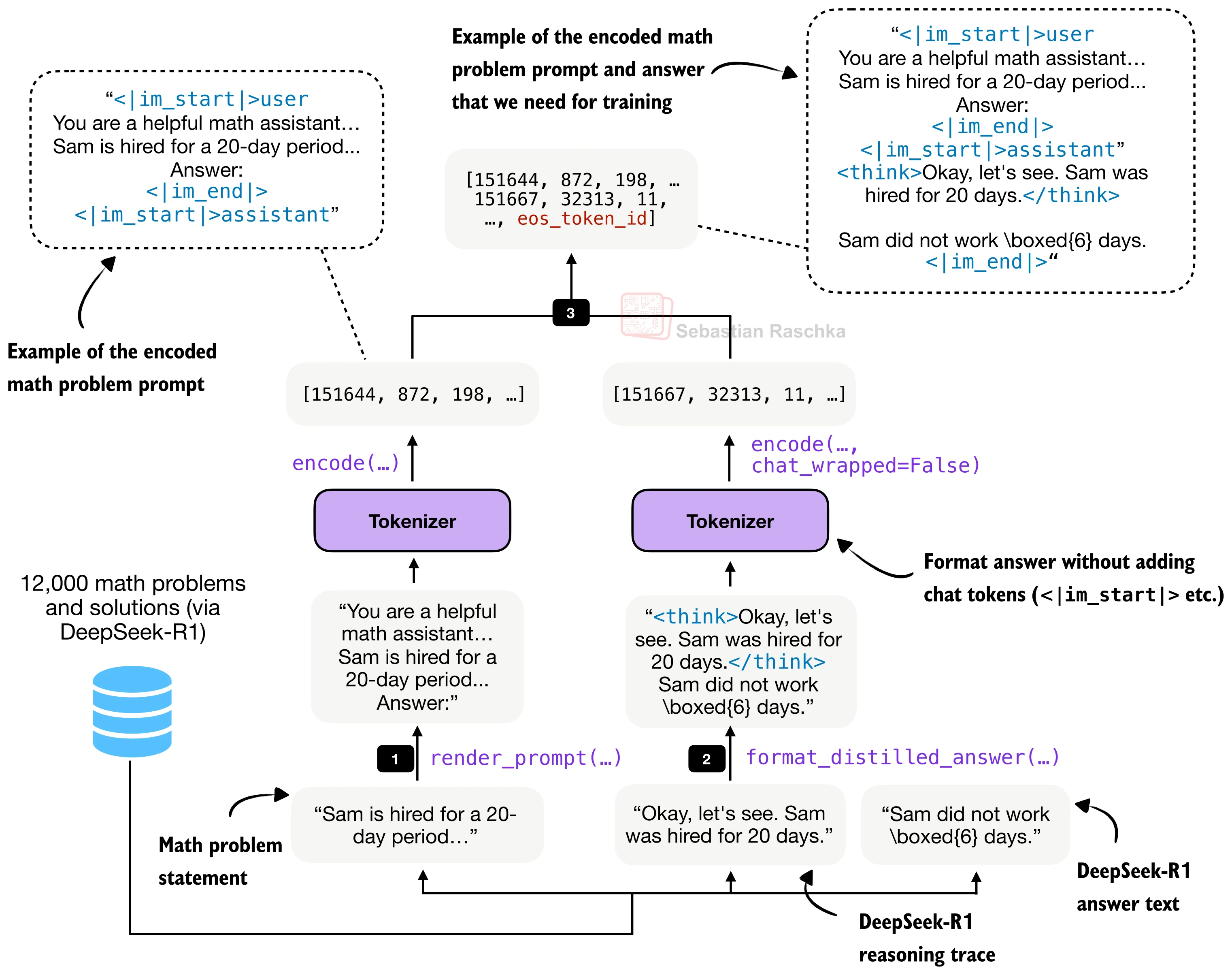
分词后的完整序列结构如下:
<|im_start|>user
You are a helpful math assistant.
Answer the question and write the final result on a new line as:
\boxed{ANSWER}
Question:
[数学题目]
Answer:<|im_end|>
<|im_start|>assistant
<think>[教师的推理过程]</think>
[教师的最终答案]<|im_end|>构建训练样本的核心代码:
def build_examples(data, tokenizer):
"""将原始数据转化为 token ID 序列"""
examples = []
skipped = 0
for entry in data:
try:
# 1. 编码提示词(自动添加聊天模板)
prompt = render_prompt(entry["problem"])
prompt_ids = tokenizer.encode(prompt)
# 2. 编码回答(不添加额外包裹)
target_answer = format_distilled_answer(entry)
answer_ids = tokenizer.encode(target_answer, chat_wrapped=False)
# 3. 拼接并添加结束符
token_ids = prompt_ids + answer_ids + [tokenizer.eos_token_id]
if len(token_ids) < 2:
skipped += 1
continue
examples.append({
"token_ids": token_ids,
"prompt_len": len(prompt_ids), # 记录提示词长度,训练时只计算回答部分的损失
})
except (KeyError, TypeError, ValueError):
skipped += 1
return examples, skipped其中 prompt_len 的作用至关重要:训练时只对回答部分计算损失,提示词部分不参与梯度计算。这与标准 SFT 的做法一致——模型不需要"学会提问",只需要学会"回答"。
3.2 长度过滤与数据划分
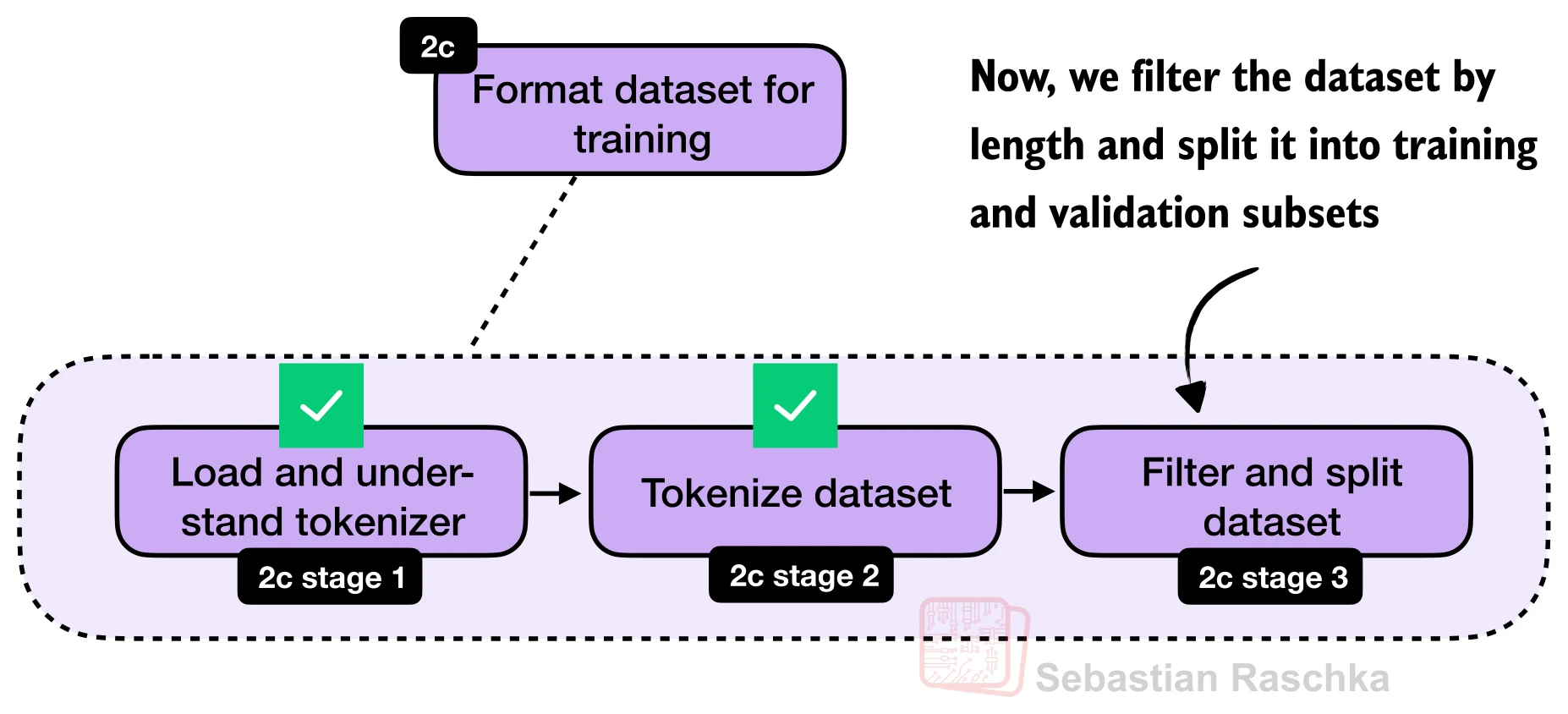
教师模型的推理轨迹长度差异很大(最短 236 token,最长超过 42,000 token),直接训练会导致显存溢出。因此需要设置最大序列长度进行过滤:
def filter_examples_by_max_len(examples, max_len=2048):
"""过滤超过最大长度的样本"""
filtered = [ex for ex in examples if len(ex["token_ids"]) <= max_len]
print(f"过滤前: {len(examples)} 条, 过滤后: {len(filtered)} 条, "
f"移除: {len(examples) - len(filtered)} 条")
return filtered以 max_len=2048 为例,12,000 条数据中有 5,305 条因超长被过滤,剩余 6,695 条。过滤后的平均长度约 1,180 token。然后随机划分出 25 条作为验证集,其余约 6,670 条用于训练。
权衡提示:
max_len越大保留的数据越多,但显存需求也越高。max_len=2048时训练需要约 15 GB 显存;如果资源有限,可以降到 1024 或 512,但会损失更多长推理轨迹的样本。
四、蒸馏训练
4.1 损失函数:交叉熵
蒸馏训练的损失函数就是标准的交叉熵损失(Cross-Entropy Loss),衡量学生模型对"下一个 token"的预测与教师给出的"正确 token"之间的差距:
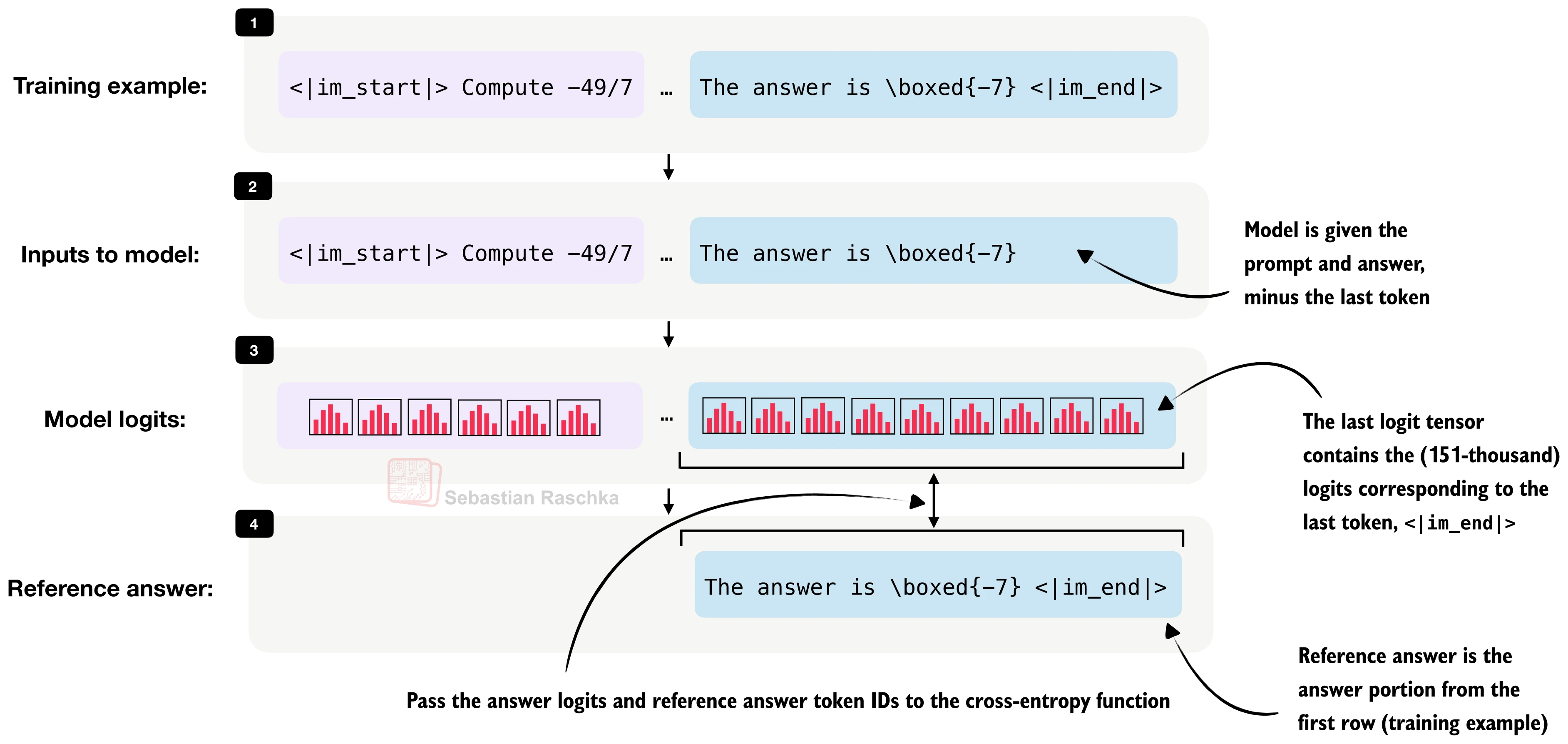
具体实现中,我们将输入序列右移一位得到目标序列,然后只取回答部分的 logits 与目标计算损失:
def compute_example_loss(model, example, device):
"""计算单个样本的交叉熵损失(仅回答部分)"""
token_ids = example["token_ids"]
prompt_len = example["prompt_len"]
# 输入是完整序列去掉最后一个 token
input_ids = torch.tensor(
token_ids[:-1], dtype=torch.long, device=device
).unsqueeze(0)
# 目标是完整序列去掉第一个 token(右移一位)
target_ids = torch.tensor(
token_ids[1:], dtype=torch.long, device=device
)
logits = model(input_ids).squeeze(0)
# 只取回答部分的 logits 和 targets
answer_start = max(prompt_len - 1, 0)
answer_logits = logits[answer_start:]
answer_targets = target_ids[answer_start:]
loss = torch.nn.functional.cross_entropy(
answer_logits, answer_targets
)
return loss这里 cross_entropy 内部执行的操作等价于计算回答 token 的平均负对数概率——损失越低,表示学生模型对教师输出的预测越准确。
4.2 训练循环
蒸馏的训练循环与标准 SFT 几乎相同:逐样本前向传播、计算损失、反向传播、更新参数。与 RLVR 相比,这里多了多个 epoch 的遍历——同一条训练样本会被看到多次:
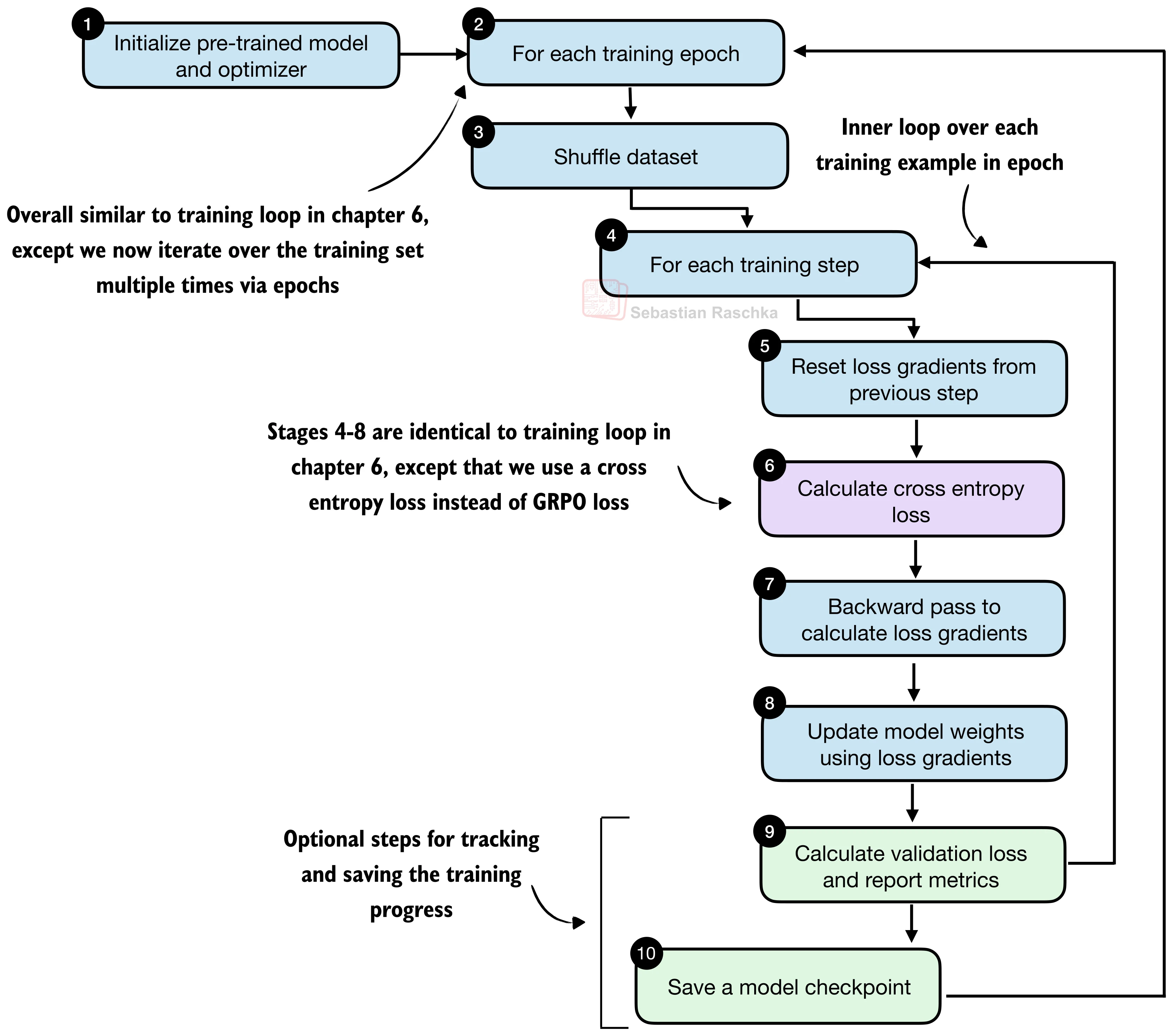
def train_distillation(
model, train_examples, val_examples, device,
epochs=2, lr=5e-6, grad_clip_norm=1.0, log_every=50
):
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
model.train()
total_steps = epochs * len(train_examples)
global_step = 0
for epoch in range(1, epochs + 1):
# 每个 epoch 开始时随机打乱训练集
random.shuffle(train_examples)
for example in train_examples:
global_step += 1
optimizer.zero_grad()
# 计算交叉熵损失
loss = compute_example_loss(model, example, device)
# 反向传播
loss.backward()
# 梯度裁剪(稳定训练)
if grad_clip_norm is not None:
torch.nn.utils.clip_grad_norm_(
model.parameters(), grad_clip_norm
)
# 更新参数
optimizer.step()
# 定期在验证集上评估
if global_step % log_every == 0:
val_loss = evaluate_examples(model, val_examples, device)
print(f"[Epoch {epoch}/{epochs} "
f"Step {global_step}/{total_steps}] "
f"train_loss={loss.item():.4f} "
f"val_loss={val_loss:.4f}")
# 每个 epoch 结束保存检查点
torch.save(model.state_dict(),
f"qwen3-0.6B-distill-epoch{epoch}.pth")关键超参数:
| 超参数 | 推荐值 | 说明 |
|---|---|---|
学习率 lr | 1e-5 | AdamW 优化器学习率 |
梯度裁剪 grad_clip_norm | 1.0 | 防止梯度爆炸 |
最大序列长度 max_seq_len | 2048 | 过滤超长样本 |
训练轮数 epochs | 1~3 | 更多轮次不一定更好 |
| 验证集大小 | 25 | 用于监控过拟合 |
训练过程中,验证损失会在前几百步内快速下降,随后趋于平稳——这是典型的 SFT 损失曲线形态。单个训练样本的损失波动较大(因为每步只看一条样本),验证损失则更加平滑。
五、评估与实验结果
训练完成后,使用 MATH-500 测试集评估蒸馏模型的数学推理准确率。评估时需要注意使用与训练一致的分词器变体(如训练时使用了 <think> 标签,评估时应选择 reasoning 分词器)。
以 Qwen3 0.6B 为学生模型,对比不同设置的实验结果:
| 序号 | 教师数据 | Epoch | MATH-500 准确率 | 最终验证损失 |
|---|---|---|---|---|
| 1 | 无(Base 模型) | - | 15.2% | - |
| 2 | 无(Reasoning 模型) | - | 48.2% | - |
| 3 | DeepSeek R1 蒸馏 | 1 | 30.6% | 0.5436 |
| 4 | DeepSeek R1 蒸馏 | 2 | 32.4% | 0.5349 |
| 5 | DeepSeek R1 蒸馏 | 3 | 33.6% | 0.5343 |
| 6 | Qwen3 235B A22B 蒸馏 | 1 | 45.0% | 0.4043 |
| 7 | Qwen3 235B A22B 蒸馏 | 2 | 43.8% | 0.3963 |
| 8 | Qwen3 235B A22B 蒸馏 | 3 | 44.2% | 0.3948 |
从这张结果表中可以读出几个重要结论:
1. 蒸馏显著提升了基座模型的推理能力。基座模型(Row 1)仅有 15.2% 的准确率,而经过 DeepSeek R1 蒸馏 3 个 epoch 后提升到 33.6%——翻了一倍多。使用 Qwen3 235B A22B 蒸馏后更是达到了 45.0%,接近 Reasoning 模型(48.2%)的水平。
2. 教师模型的质量至关重要。Qwen3 235B A22B 蒸馏(Row 6-8)的准确率远高于 DeepSeek R1 蒸馏(Row 3-5),差距达到 10+ 个百分点。这与两者的训练数据质量直接相关——验证损失也低了很多(0.40 vs 0.54),说明 Qwen3 235B A22B 生成的推理轨迹对学生模型而言更"可学"。
3. 更多 epoch 并非总是更好。DeepSeek R1 蒸馏中准确率随 epoch 稳步上升(30.6% -> 32.4% -> 33.6%),但 Qwen3 235B A22B 蒸馏在 Epoch 1 就达到了最佳的 45.0%,后续 epoch 反而略有下降。这提示我们在实际训练中需要密切监控验证指标,避免过拟合。
4. 蒸馏 vs RLVR 的定位。蒸馏是一种"站在巨人肩膀上"的策略——快速将大模型的能力压缩到小模型中。但它的上限受制于教师模型的水平。RLVR 则是让模型从零探索,理论上可以发现教师没有发现的解题路径。在实际工程中,两者常被结合使用:先蒸馏获得一个不错的起点,再用 RLVR 进一步提升。
六、小结
本节完整展示了推理模型蒸馏的端到端流程。硬蒸馏本质上是一种特殊的监督微调——训练目标是教师模型的生成文本而非人工标注,训练过程则与标准 SFT 完全一致(交叉熵损失 + AdamW 优化器)。蒸馏的核心竞争力在于低成本获取高质量训练数据:只需调用教师模型的 API 就能大规模生成训练样本,无需复杂的奖励建模和在线采样。选择合适的教师模型、控制训练轮数以避免过拟合、以及与 RLVR 互补使用,是蒸馏实践中最值得关注的三个要点。