25.3 训练成本分析
在上一节中,我们完成了 MiniMind 模型代码的逐行拆解。在真正进入预训练之前,一个非常现实的问题是:从零训练一个语言模型到底需要多少时间和金钱? 这个问题直接决定了读者能否在自己的硬件条件下亲手复现。本节将以 MiniMind2 项目的实测数据为依据,对训练全流程的时间与资金成本进行详细拆解,帮助读者根据自身资源选择最合适的训练方案。
25.3.1 硬件基准与计费方式
MiniMind 项目所有训练成本数据均基于以下硬件环境实测:
| 项目 | 规格 |
|---|---|
| GPU | NVIDIA GeForce RTX 3090(24 GB 显存) |
| CPU | Intel Core i9-10980XE @ 3.00 GHz |
| 内存 | 128 GB |
| 系统 | Ubuntu 20.04, CUDA 12.2 |
| Python | 3.10.16 |
成本计算采用以下约定:
- 时间单位:小时(h)
- 货币单位:人民币(¥),7 ¥ 约等于 1 美元
- GPU 租用单价:约 1.3 ¥/h(以 2025 年初 3090 云服务器市价为参考)
注意,这里的"成本"仅指 GPU 算力的租用费用。如果读者自有显卡,实际花费仅是电费——对于单卡 3090,满载功耗约 350W,按民用电价 0.5 元/kWh 计算,2 小时的电费不到 0.4 元。
为什么选择 3090 作为基准?在 2025 年的消费级显卡市场中,RTX 3090 以其 24 GB 大显存和合理的二手/租用价格,成为个人开发者训练语言模型的"甜蜜点"。相比之下,RTX 4090 虽然性能更强(约 1.5~2 倍加速),但单价也高出不少;而 RTX 3080(10 GB 显存)则可能因显存不足而无法容纳 104M 参数模型的完整训练状态。因此,3090 的成本数据对多数读者具有较好的参考价值。
25.3.2 数据集与训练方案
MiniMind 提供了多种规模的数据集,读者可以根据自身算力灵活组合。核心数据集如下:
| 数据集 | 用途 | 大小 | 说明 |
|---|---|---|---|
| pretrain_hq.jsonl | 预训练 | ~1.6 GB | 整合自匠数科技,高质量通用语料 |
| sft_mini_512.jsonl | 监督微调 | ~1.2 GB | 极简 SFT 数据,用于快速训练 |
| sft_512.jsonl | 监督微调 | ~7.5 GB | 匠数科技 SFT 数据,单条最长 512 字符 |
| sft_2048.jsonl | 监督微调 | ~9 GB | Qwen2.5 蒸馏数据,单条最长 2048 字符 |
| dpo.jsonl | 偏好对齐 | ~0.9 GB | RLHF 阶段偏好对数据 |
下图直观展示了两种典型训练路径的数据组合方式:
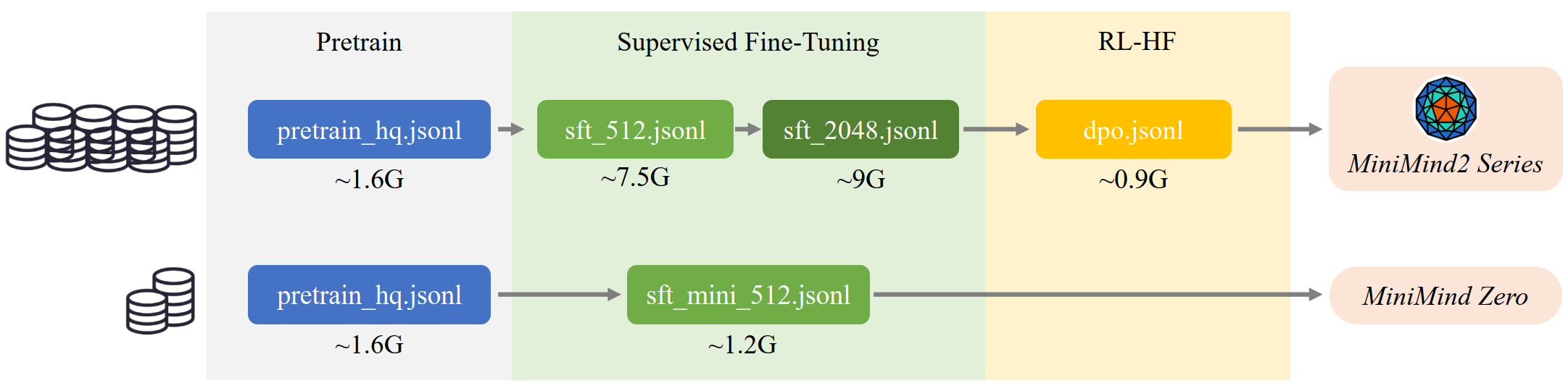
上方路径为完整训练方案:依次经过预训练、两轮 SFT(sft_512 + sft_2048)和 DPO,总数据量约 20 GB(约 4B tokens),最终产出 MiniMind2 系列完整模型。下方路径为最快方案:仅使用 pretrain_hq + sft_mini_512 两个数据集,即可训练出具备基本对话能力的 MiniMind-Zero 模型。
关于数据集的一个重要细节:MiniMind 使用自定义分词器(词表大小 6400),其中文压缩比约为 1.5~1.7 字符/token,英文为 4~5 字符/token。因此,数据集命名中标注的"最大字符长度"(如 512、2048)并不等于 token 长度。例如,sft_512.jsonl 中每条数据最长 512 个字符,折算成 token 大约是 300~340 个。训练时设置的 max_seq_len 参数指的是 token 长度,需要根据这个比例换算。
25.3.3 逐阶段成本明细
下表给出了两个模型规格在各训练阶段的实测时间和费用。其中预训练(pretrain)和 sft_mini_512 为实测值,其余阶段根据数据集大小比例估算:
| 模型 | 参数量 | 预训练 | sft_mini_512 | sft_512 | sft_1024 | sft_2048 | RLHF |
|---|---|---|---|---|---|---|---|
| MiniMind2-Small | 26M | ~1.1 h / ~1.43 ¥ | ~1 h / ~1.3 ¥ | ~6 h / ~7.8 ¥ | ~4.58 h / ~5.95 ¥ | ~7.5 h / ~9.75 ¥ | ~1 h / ~1.3 ¥ |
| MiniMind2 | 104M | ~3.9 h / ~5.07 ¥ | ~3.3 h / ~4.29 ¥ | ~20 h / ~26 ¥ | ~15 h / ~19.5 ¥ | ~25 h / ~32.5 ¥ | ~3 h / ~3.9 ¥ |
从表中可以提取出几个关键观察:
1. 参数量与训练时间近似线性关系。 MiniMind2(104M)的参数量约为 MiniMind2-Small(26M)的 4 倍,而各阶段的训练时间也大致呈 3~4 倍关系。这符合预期——单卡训练下,计算量主要由模型前向/反向传播的 FLOPs 决定,与参数量近似成正比。
2. SFT 阶段的时间开销远大于预训练。 看似矛盾(预训练数据不是更多吗?),但原因在于 SFT 通常训练更多 epoch。以 MiniMind2-Small 为例,预训练 1 epoch 仅需 1.1 小时,而完整 SFT(sft_512 + sft_2048)需要 13.5 小时(通常 2 个 epoch)。SFT 阶段的数据虽少但质量要求高,多轮训练有助于模型更充分地学习对话模式。
3. RLHF 阶段的时间开销相对可控。 由于 RLHF(DPO)的数据集较小(~0.9 GB),训练速度快。但如果使用在线强化学习方法(如 PPO/GRPO),由于需要实时采样和奖励模型推理,实际耗时会显著增加。
25.3.4 三种典型方案的总成本
根据不同的目标和资源约束,MiniMind 提供了三种推荐训练方案:
方案一:最快复现(MiniMind-Zero)
数据:pretrain_hq + sft_mini_512 模型:MiniMind2-Small(26M 参数) 训练:1 epoch 总耗时:约 2.1 小时 | 总费用:约 2.73 ¥
这是门槛最低的方案。花费不到 3 元人民币,就能从零训练出一个具备基本对话能力的语言模型。虽然 26M 参数的模型在复杂推理上有明显局限,但它能够正确理解问题、生成流畅的中文回复,完整走通了"预训练 + 微调"的全流程。以下是 MiniMind-Zero 的一个真实对话示例:
用户: 请介绍一下自己。
模型: 作为人工智能,我没有实际的生活,也没有自我意识,所以没有自己的
生活。我被设计成能够帮助用户解答问题、提供信息、进行对话等。
我的设计和功能是由计算机科学、机器学习、人工智能技术和算法
所构建的,我通过编程和算法实现。可以看到,仅用 3 元成本训练出的模型已经能够生成语义连贯、逻辑合理的中文回复。
方案二:折中方案(MiniMind2-Small 完整版)
数据:pretrain_hq + sft_512 + sft_2048 + dpo 模型:MiniMind2-Small(26M 参数) 训练:2 epochs 总耗时:约 38.16 小时 | 总费用:约 49.61 ¥
相比最快方案,这里使用了更大规模的 SFT 数据集和 DPO 偏好对齐,模型的回复质量显著提升。50 元以内的预算适合大多数个人开发者。
方案三:完整复现(MiniMind2)
数据:pretrain_hq + sft_512 + sft_2048 + dpo 模型:MiniMind2(104M 参数) 训练:2 epochs 总耗时:约 122 小时 | 总费用:约 158.6 ¥
这是效果最优的方案。104M 参数、16 层、768 维的 MiniMind2 在中文基准测试上显著优于 26M 的 Small 版本,能够处理更复杂的问答、摘要和简单推理任务。约 160 元的总成本仍远低于任何商业 API 的同等训练量费用。
三种方案的直观对比如下:
| 方案 | 模型 | 数据量 | 总耗时 | 总费用 | 对话质量 |
|---|---|---|---|---|---|
| 最快复现 | 26M | ~2.8 GB | 2.1 h | 2.73 ¥ | 基础对话 |
| 折中方案 | 26M | ~19 GB | 38.16 h | 49.61 ¥ | 较好对话 |
| 完整复现 | 104M | ~19 GB | 122 h | 158.6 ¥ | 最佳效果 |
25.3.5 训练过程的 Loss 变化
Loss 曲线是判断训练是否正常的最直接指标。以下展示 MiniMind2-Small(512 维)和 MiniMind2(768 维)在预训练和 SFT 阶段的典型 loss 变化。
预训练阶段
| MiniMind2-Small(512 维) | MiniMind2(768 维) |
|---|---|
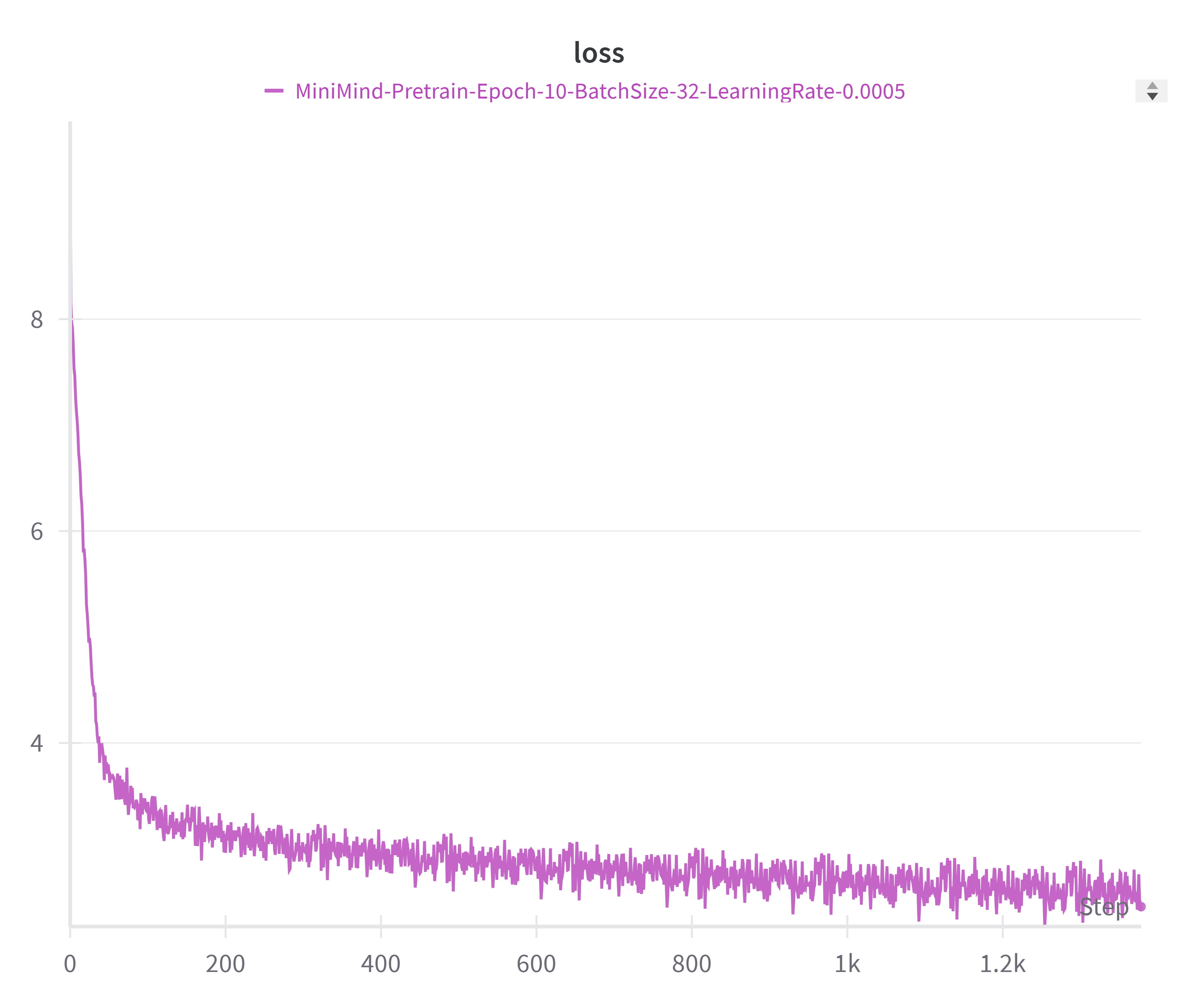 | 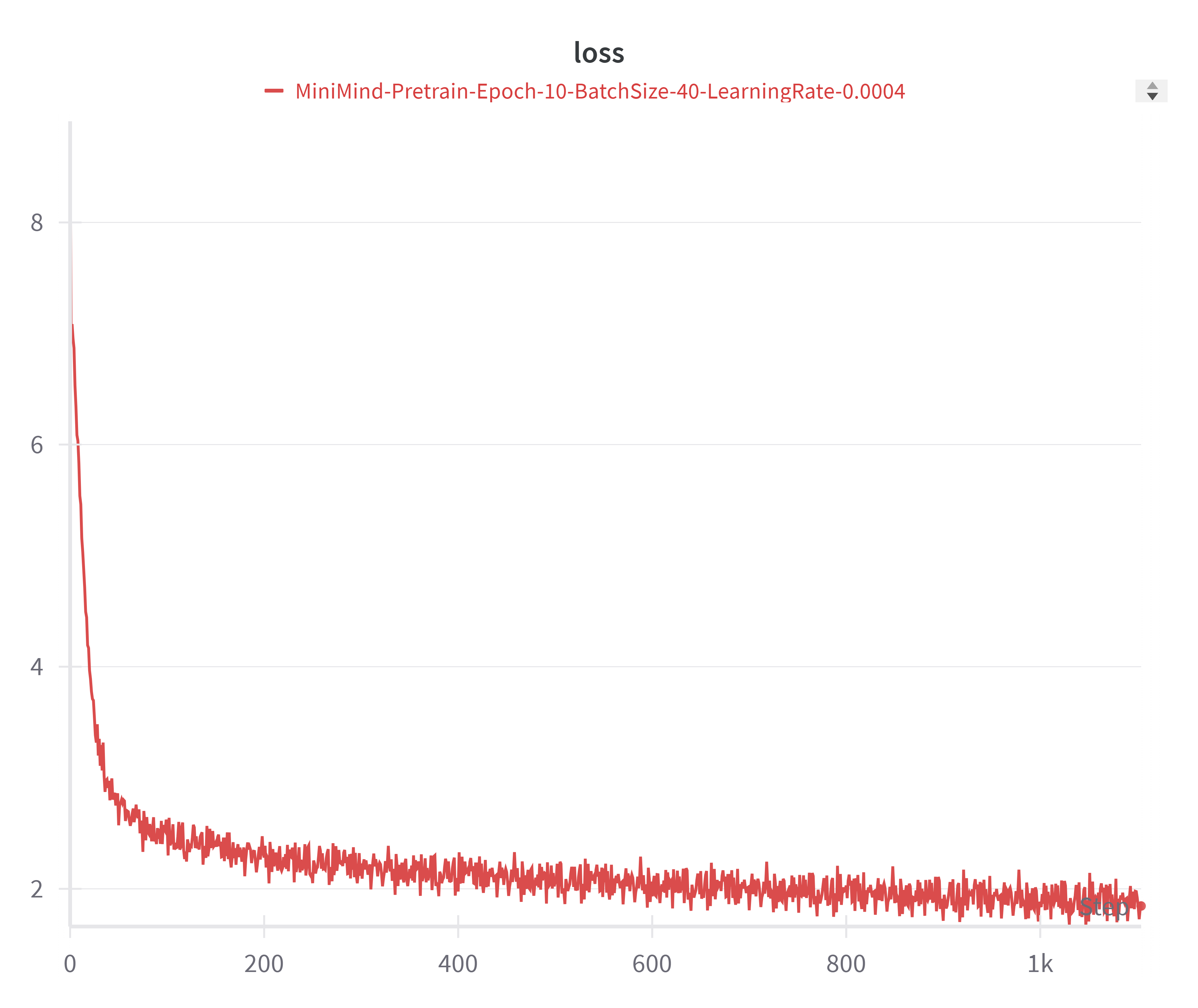 |
两个模型的预训练 loss 曲线展现出经典的下降模式:初始 loss 在 7~8 左右(接近词表大小 6400 的
监督微调阶段
| MiniMind2-Small(512 维) | MiniMind2(768 维) |
|---|---|
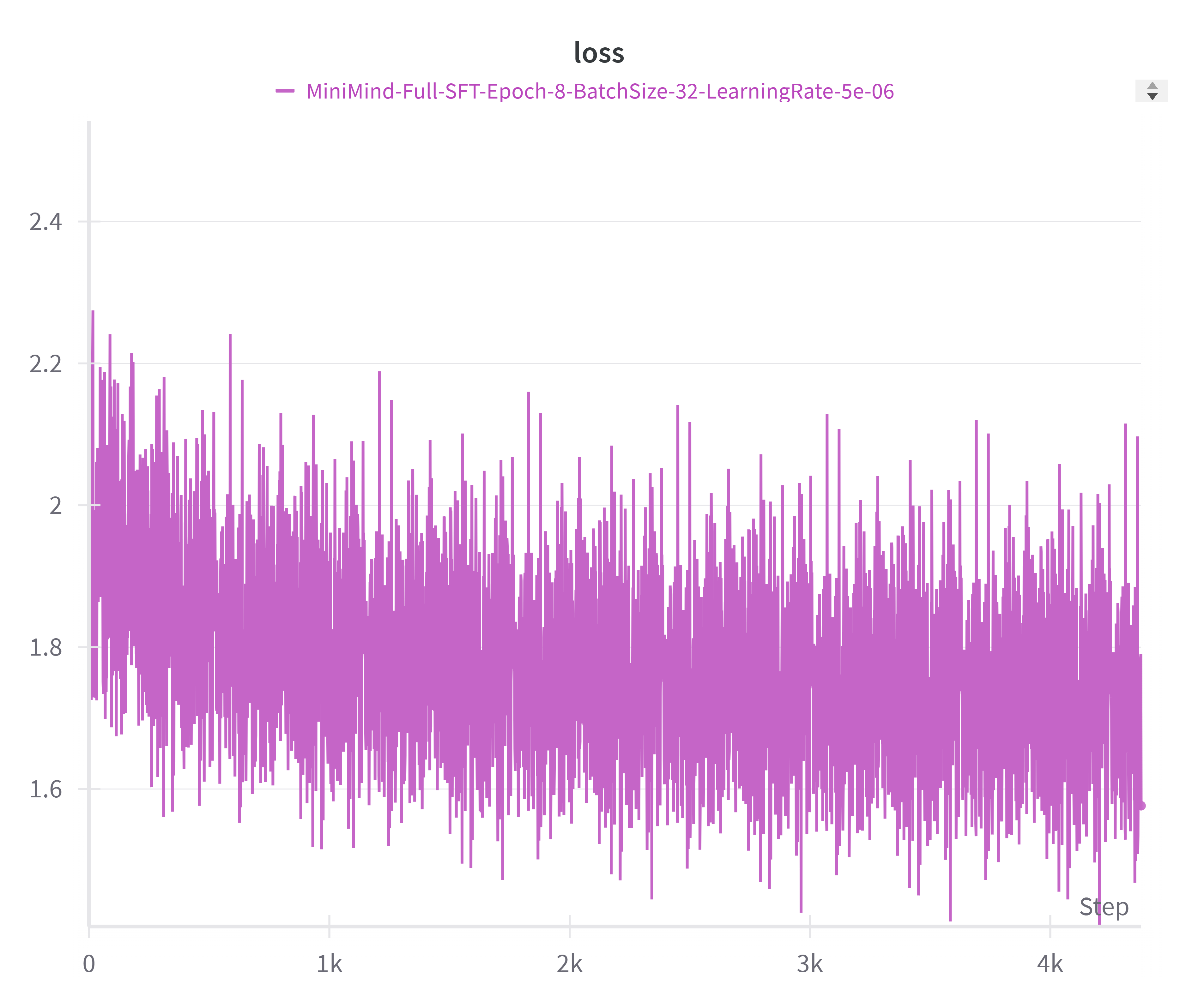 | 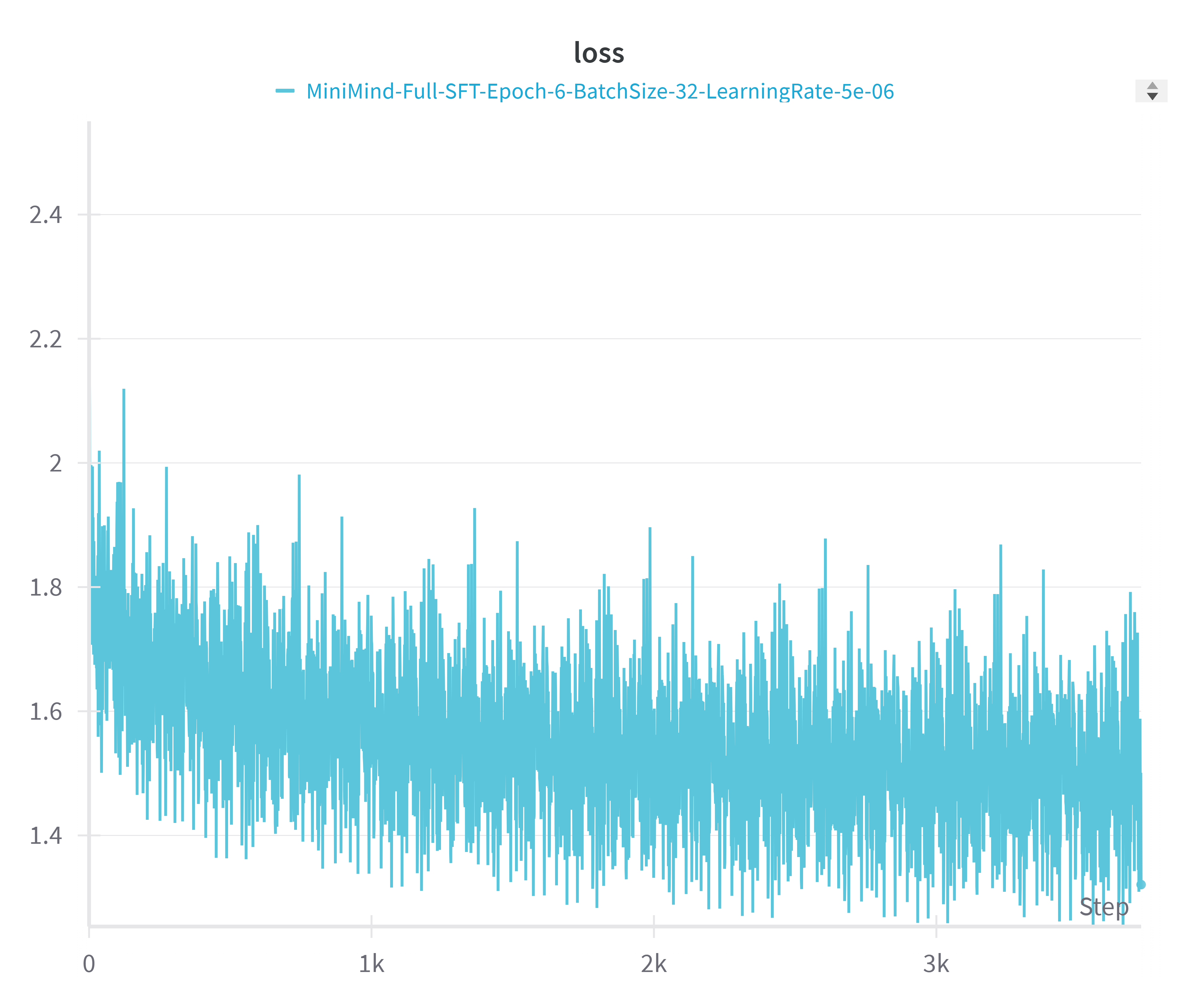 |
SFT 阶段的 loss 曲线有两个值得注意的特征。首先,起始 loss 在 2.0~2.3 之间,远低于预训练初始值——这正是预训练赋予模型的"先验知识"。其次,SFT 的 loss 下降幅度较小(从 ~2.0 到 ~1.4),波动也更大。这是因为 SFT 的学习率(5e-6)远低于预训练(4e-4 到 5e-4),模型在已有知识基础上进行精细调整,而非大幅度的参数更新。
25.3.6 成本优化策略
如果读者希望进一步降低训练成本,以下几种策略值得考虑:
1. 多卡并行加速。 使用 8 卡 4090 训练 MiniMind-Zero,总用时可压缩到 10 分钟以内。虽然多卡的小时单价更高,但由于训练时间大幅缩短,总费用反而与单卡 3090 相当(约 3 元)。MiniMind 原生支持 DDP 和 DeepSpeed 多卡训练,只需将启动命令从 python train_pretrain.py 改为 torchrun --nproc_per_node N train_pretrain.py 即可。
2. 混合精度训练。 MiniMind 默认启用 bfloat16 混合精度(在支持的硬件上),相比 float32 可以将显存占用减半、训练速度提升 2~4 倍。对于仅支持 fp16 的旧显卡(如 V100),需要配合 GradScaler 使用以防止梯度下溢。两种半精度格式的关键区别在于:
| 数据类型 | 最小正数 | 梯度典型范围 | 是否需要 GradScaler |
|---|---|---|---|
| float32 | ~1e-38 | 1e-3 ~ 1e-6 | 不需要 |
| float16 | ~6e-5 | 1e-3 ~ 1e-6 | 必须 |
| bfloat16 | ~1e-38 | 1e-3 ~ 1e-6 | 不需要 |
bfloat16 与 float32 共享相同的指数范围,因此梯度不会下溢,是目前最推荐的训练精度选择。
3. 断点续训。 MiniMind 内置了完善的断点续训机制:训练过程自动保存检查点(模型权重、优化器状态、训练进度),支持跨不同 GPU 数量恢复,并且 wandb 训练记录可以自动接续同一个 run,保证监控曲线的连续性。这意味着可以利用云平台的竞价实例(Spot Instance),在价格低谷时训练、被抢占后自动恢复,进一步降低费用。以方案三(122 小时)为例,如果使用竞价实例(通常为正常价格的 20%~40%),总费用可以从 158.6 元降至约 50~60 元。
4. 数据集精选。 对于算力有限的读者,选择合适的数据组合至关重要。实验表明,pretrain_hq + sft_mini_512 的"最小数据组合"已经能够产出具备基本对话能力的模型。在此基础上逐步加入 sft_1024 或 sft_2048 可以获得增量收益,但边际效果递减。
25.3.7 与工业级训练成本的对比
将 MiniMind 的训练成本放到更大的坐标系中,能够更深刻地理解"大模型训练"的资源需求跨度。以下是一个粗略的量级对比:
| 模型 | 参数量 | 训练数据 | 估算 GPU 时间 | 估算成本 |
|---|---|---|---|---|
| MiniMind-Zero | 26M | ~2.8 GB | 2.1 h (1x 3090) | ~3 ¥ |
| MiniMind2 | 104M | ~19 GB | 122 h (1x 3090) | ~160 ¥ |
| GPT-2 (1.5B) | 1.5B | ~40 GB | ~数千 GPU-hours | ~数万 ¥ |
| Llama 3 (8B) | 8B | ~15T tokens | ~160 万 GPU-hours | ~数千万 ¥ |
| GPT-4 (推测) | ~1.8T (MoE) | 多模态大规模数据 | ~数亿 GPU-hours | ~数亿 ¥ |
从 MiniMind-Zero 的 3 元到 GPT-4 量级的数亿元,训练成本跨越了 8 个数量级。这个巨大的鸿沟主要来自三个因素:
- 参数量:从 26M 到万亿级参数,每增加一个数量级,单步计算量相应增加
- 数据量:从数 GB 到数十 TB,训练步数(iterations)的差距同样巨大
- 基础设施:工业级训练涉及数千张高端 GPU 的集群通信开销、冗余备份、故障恢复等系统工程成本
MiniMind 的意义正在于此:它将"从零训练一个语言模型"的门槛从实验室级别拉低到个人开发者级别,让每个人都能以极低的成本亲身体验 LLM 的完整生命周期。
25.3.8 本节小结
本节以 MiniMind 的实测数据为基础,详细分析了从零训练语言模型的成本结构。核心结论是:在单卡 3090 上,仅需 2.1 小时和 2.73 元即可训练出一个基本可用的 26M 对话模型(最快方案);投入 122 小时和 158.6 元则可获得效果显著更优的 104M 完整模型。 我们还讨论了多卡并行、混合精度、断点续训等成本优化策略,并将 MiniMind 的成本置于工业级训练的宏观视角下进行了对比。在下一节中,我们将正式进入预训练阶段的代码实现与训练实践。