13.3 PEFT 扩展方法
前两节介绍了 LoRA 的数学原理和工程实践。标准 LoRA 虽然极其高效,但在实际部署中仍面临三方面挑战:显存仍然是瓶颈(基模型以 16 位精度加载,70B 模型至少需要 140GB 显存)、秩分配缺乏灵活性(所有层统一的
本节将深入剖析四类核心扩展:QLoRA 的量化工程细节、DoRA 与 AdaLoRA 的实现原理与配置要点、LoRA+ 的学习率校正策略,然后聚焦工程实战——Adapter 合并策略的取舍,以及 trl + PEFT 的集成配置。
13.3.1 QLoRA:量化 + LoRA 的深度实现
13.1 节已经介绍了 QLoRA 的核心思想:将基模型量化到 4-bit 精度,再叠加 16-bit 的 LoRA 适配器。本节重点展开其量化工程细节——NF4 数据类型的设计动机、双重量化的内存计算,以及完整的配置代码。
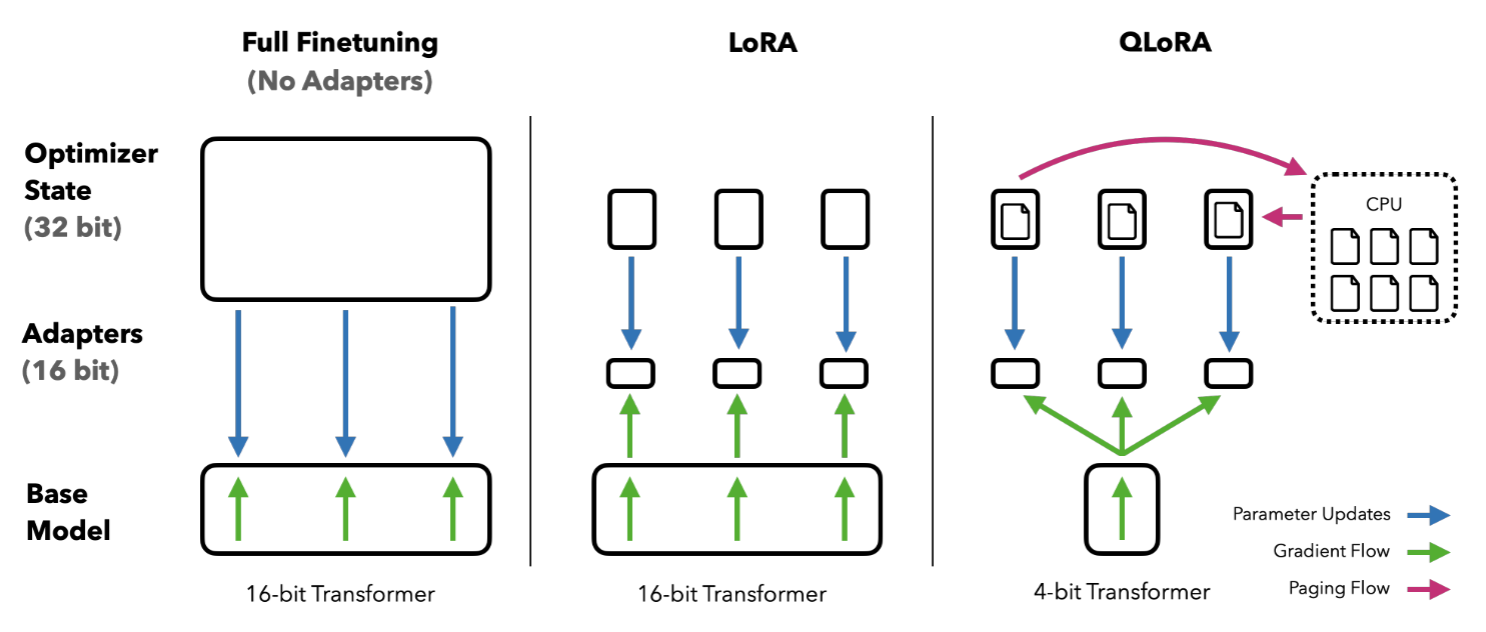
图 13-8:Full Finetuning、LoRA 与 QLoRA 的对比。QLoRA 将冻结的基模型权重压缩至 4-bit NF4 格式,仅 LoRA 适配器以 BF16 精度参与梯度计算。
NF4 量化的核心:从等步长到等概率。 传统量化(如 Int8)将数值范围等距划分为若干刻度,但这种均匀分割在面对神经网络权重的正态分布特性时效率低下——大量刻度浪费在稀疏的尾部区域,而密集的零点附近反而精度不足。NF4(4-bit NormalFloat)观察到预训练模型的权重近似服从标准正态分布
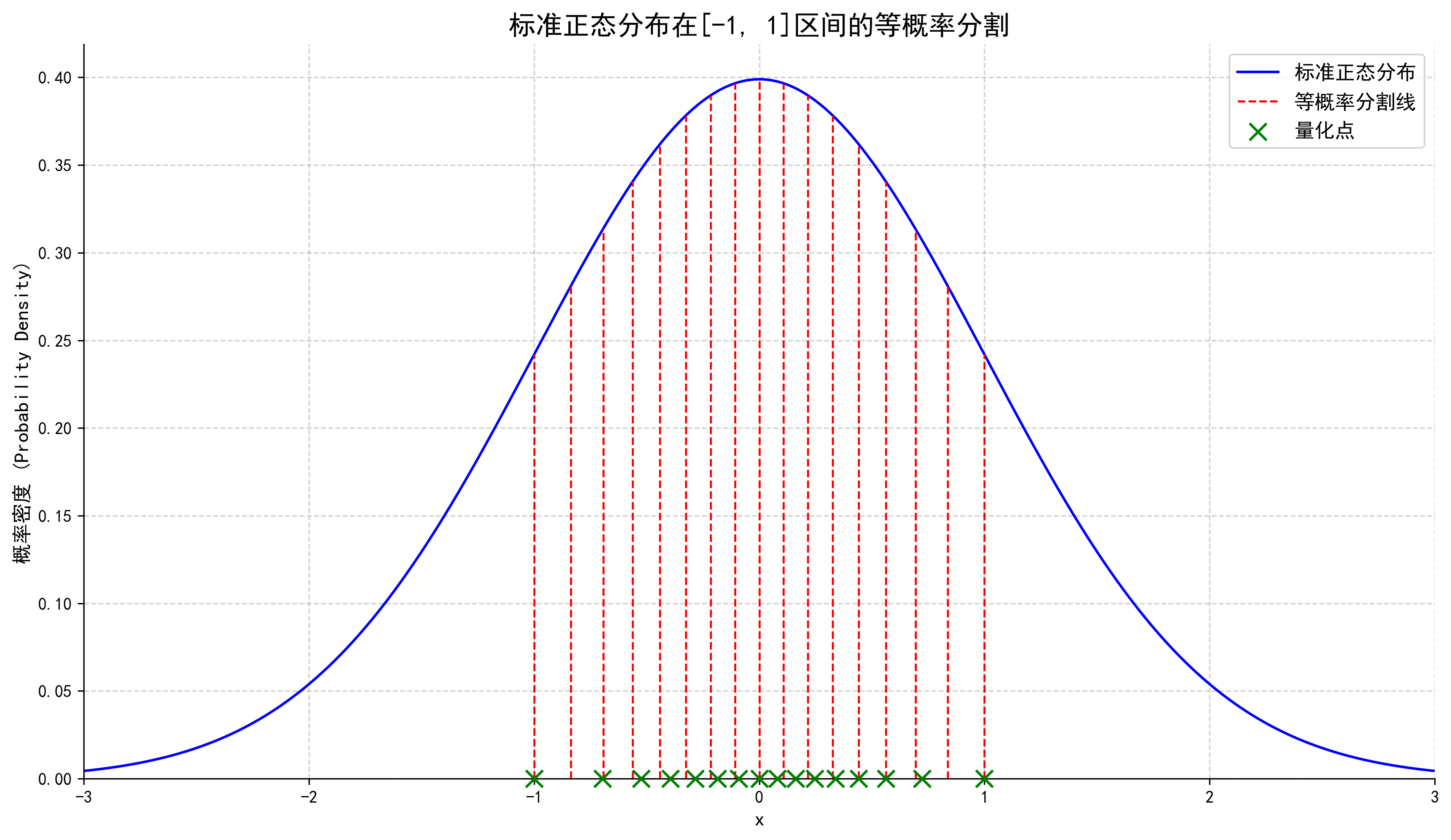
图 13-9:NF4 的量化点分布示意。在数据密集的零点附近,量化点极为密集;在尾部区域则稀疏分布,实现了信息论意义上的最优表示。
这 16 个量化点构成一个固定的码本(Codebook),限定在

图 13-10:NF4 码本的 16 个量化点数值。这些值是基于标准正态分布的等概率分割预计算得到的。
双重量化的内存精算。 每个 64 元素的块需要一个 FP32 缩放因子
分页优化器。 微调过程中,Adam 优化器为每个可训练参数维护两份状态(一阶矩和二阶矩)。QLoRA 利用 NVIDIA 统一内存(Unified Memory)的特性,将暂时不需要的优化器状态自动分页到 CPU 内存,在需要时再调回 GPU,避免显存溢出。
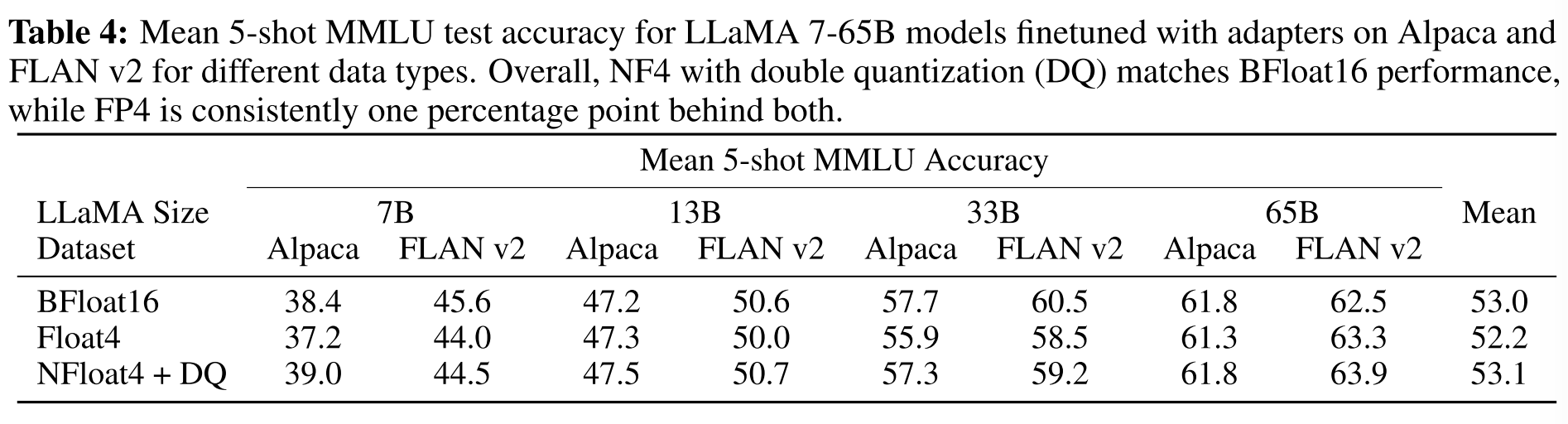
图 13-11:QLoRA 的微调实验结果。在单张 48GB GPU 上成功微调 65B 参数模型,且几乎保留了 16-bit 微调的性能。
完整的 QLoRA 配置代码。 以下代码展示了如何用 bitsandbytes 和 peft 库配置一个完整的 QLoRA 微调流程:
import torch
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
# 第一步:配置 4-bit 量化参数
bnb_config = BitsAndBytesConfig(
load_in_4bit=True, # 启用 4-bit 量化
bnb_4bit_quant_type="nf4", # 使用 NF4 数据类型
bnb_4bit_compute_dtype=torch.bfloat16,# 计算时反量化到 BF16
bnb_4bit_use_double_quant=True, # 启用双重量化
)
# 第二步:加载量化后的基模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
quantization_config=bnb_config,
device_map="auto", # 自动分配设备
)
# 第三步:配置 LoRA 适配器
lora_config = LoraConfig(
r=16, # 低秩矩阵的秩
lora_alpha=32, # 缩放因子 alpha
lora_dropout=0.05, # Dropout 防止过拟合
bias="none", # 不训练 bias
task_type="CAUSAL_LM", # 因果语言模型
target_modules="all-linear", # 注入所有线性层
)
# 第四步:注入 LoRA 并打印参数统计
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()
# 输出示例:trainable params: 4,194,304 || all params: 3,504,607,232 || trainable%: 0.12%关键配置参数解读:bnb_4bit_quant_type 选择 "nf4" 而非 "fp4",因为 NF4 针对权重的正态分布特性做了优化,信息损失更小;bnb_4bit_compute_dtype 建议使用 torch.bfloat16 以获得更好的训练稳定性(相比 float16,BF16 具有更大的指数范围,不易上溢);bnb_4bit_use_double_quant 几乎没有精度损失但能节省约 0.4 bit/参数的内存。
13.3.2 DoRA:解耦量级与方向的详细实现
13.1 节介绍了 DoRA 的核心洞察——LoRA 的量级变化与方向变化呈正相关"捆绑"更新,而全参数微调二者呈负相关、可独立调整。本节深入其实现细节。

图 13-12:权重更新的量级变化
DoRA 的前向传播公式。 对于预训练权重
其中
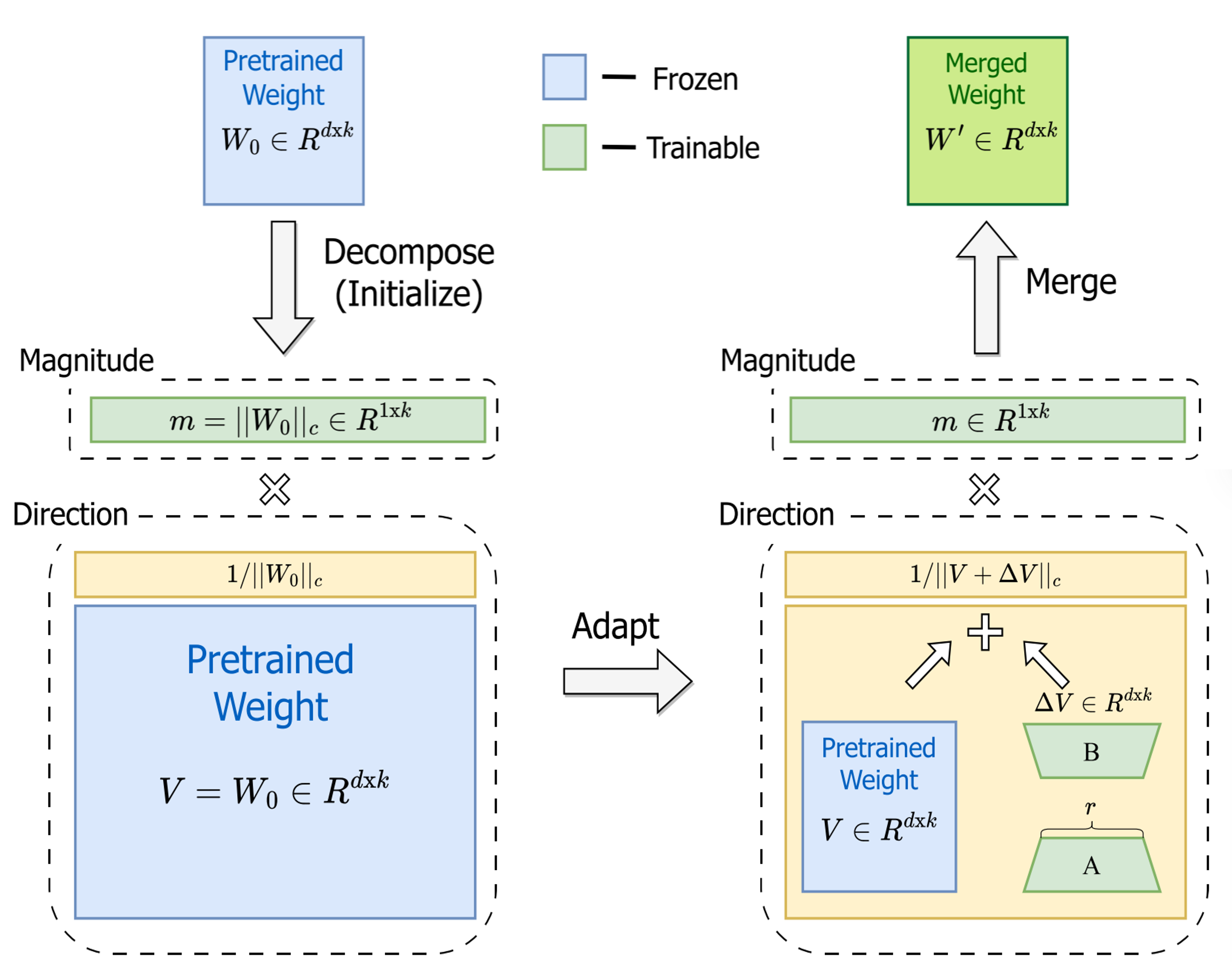
图 13-13:DoRA 的工作流程。预训练权重被分解为量级向量
工程配置。 在 HuggingFace PEFT 中启用 DoRA 极为简单——只需在 LoraConfig 中设置 use_dora=True:
from peft import LoraConfig
dora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear",
use_dora=True, # 启用 DoRA:解耦量级与方向
)DoRA 的额外开销。 相比标准 LoRA,DoRA 额外引入的可训练参数仅为一个量级向量
13.3.3 AdaLoRA:自适应秩分配的工程实践
标准 LoRA 的"一刀切"秩分配忽略了不同层的重要性差异。研究表明,前馈网络(FFN)层通常比注意力层对微调更敏感,顶层比底层更重要。
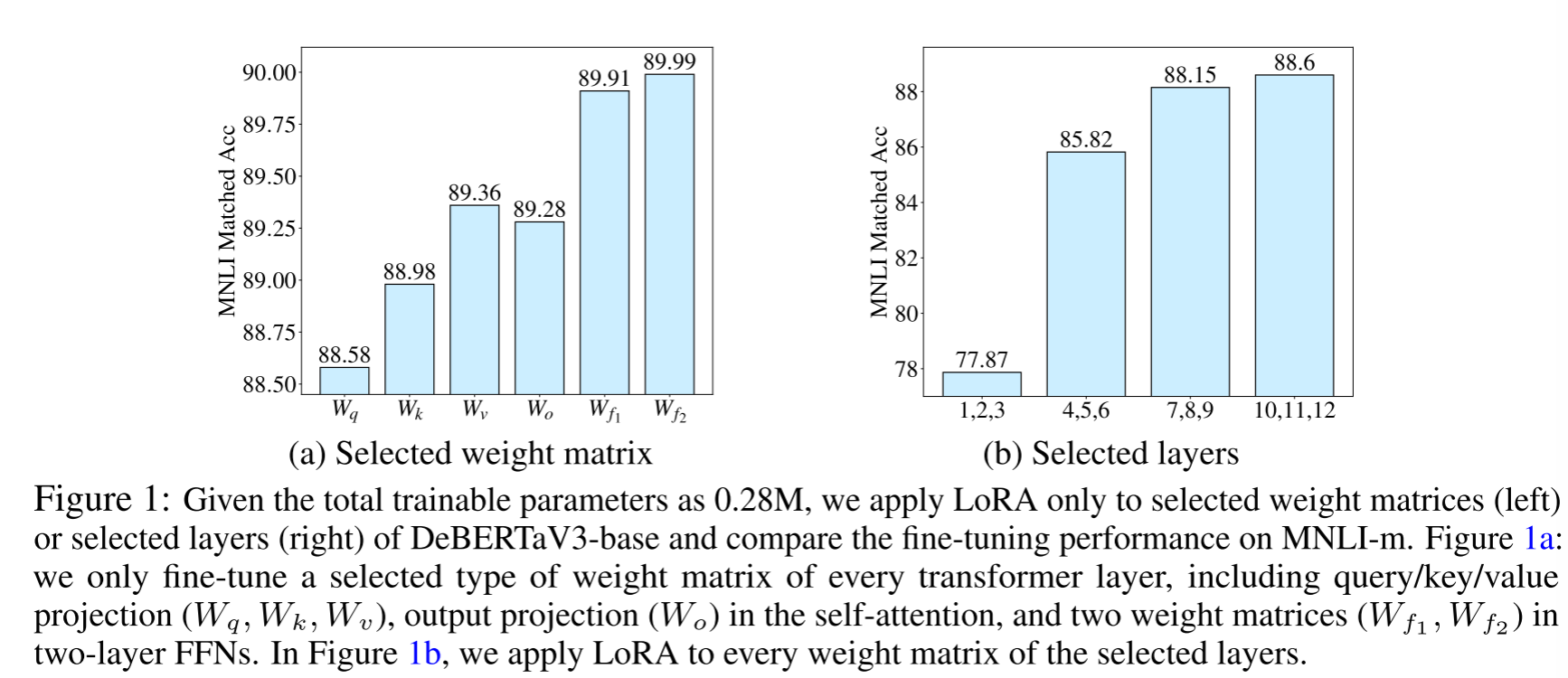
图 13-14:微调不同权重矩阵或不同层时 LoRA 的性能差异。FFN 层(左图)优于注意力层,顶层(右图)优于底层,证明了均匀分配秩的低效。
AdaLoRA 的三大核心技术。
SVD 参数化:将增量
分解为正交矩阵 、 和对角矩阵 。秩的调整只需将对角线上的奇异值置零,对应的奇异向量仍保留在模型中,可在后续训练中"复活"——这是比标准 LoRA 的结构性剪枝更"温和"的方式。 重要性评分:对每个 SVD 分量(三元组
),计算综合重要性分数 ,考虑权重-梯度乘积的指数移动平均(EMA)和不确定性。持续重要且学习尚不稳定的参数获得最高保护优先级。 全局预算调度:训练分为热身(高预算探索)、削减(三次函数平滑降低)和微调(固定预算收敛)三阶段,避免过早误剪关键分量。

图 13-15:AdaLoRA 的整体算法流程。从 SVD 参数化到重要性评估、再到预算调度,形成一个完整的自适应秩管理闭环。
PEFT 中的 AdaLoRA 配置:
from peft import AdaLoraConfig
adalora_config = AdaLoraConfig(
init_r=12, # 初始秩(热身阶段的高预算)
target_r=4, # 目标秩(最终预算)
beta1=0.85, # EMA 的一阶矩系数
beta2=0.85, # EMA 的二阶矩系数
tinit=200, # 热身步数:前 200 步不剪枝
tfinal=1000, # 在第 1000 步达到目标预算
deltaT=10, # 每隔 10 步更新一次秩分配
lora_alpha=32,
lora_dropout=0.05,
task_type="CAUSAL_LM",
target_modules=["q_proj", "v_proj", "k_proj", "o_proj"],
)关键参数解读:init_r 和 target_r 定义了秩的动态范围;tinit 和 tfinal 控制剪枝窗口;deltaT 决定重要性评估的频率。AdaLoRA 的代价是额外的 SVD 参数化和重要性计算开销,因此更适合参数预算极为紧张的场景(例如需要在极少参数量下榨取最大性能)。
13.3.4 LoRA+:零成本的学习率校正
LoRA+ 的改进极为精巧:它不改变模型结构,仅通过为矩阵
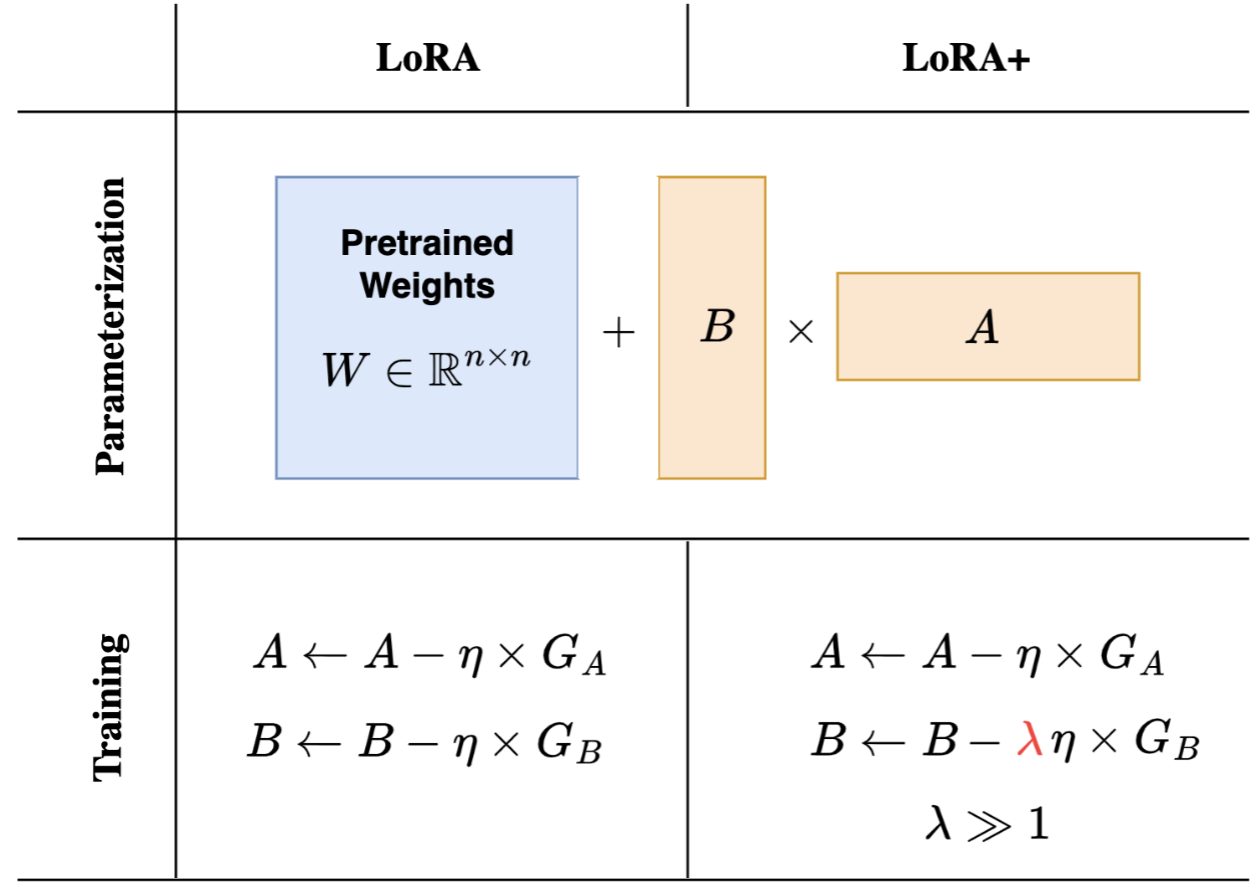
图 13-16:LoRA+ 的理论分析。由于矩阵维度不对称,
问题的本质。 在反向传播中,矩阵
解决方案。 LoRA+ 引入比率超参数
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import torch.optim as optim
def get_loraplus_optimizer(model, lr_A=1e-4, lr_ratio=16.0):
"""为 LoRA 矩阵 A 和 B 设置不同学习率"""
params_A, params_B = [], []
for name, param in model.named_parameters():
if not param.requires_grad:
continue
if "lora_A" in name:
params_A.append(param)
elif "lora_B" in name:
params_B.append(param)
optimizer = optim.AdamW([
{"params": params_A, "lr": lr_A},
{"params": params_B, "lr": lr_A * lr_ratio}, # B 的学习率放大
])
return optimizer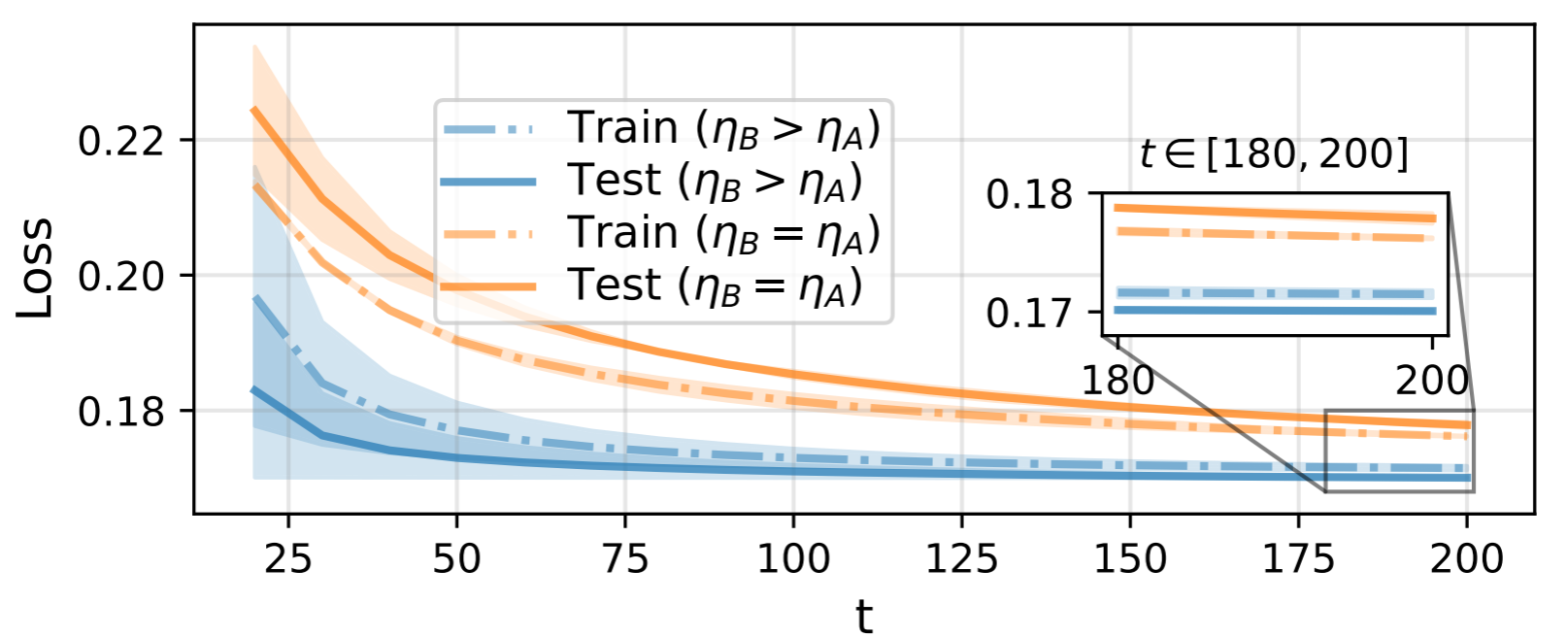
图 13-17:LoRA+ 的收敛速度对比。蓝色线条(LoRA+)仅需约一半的训练步数即可达到甚至超过标准 LoRA(黄色线条)的收敛水平。
LoRA+ 的优势在于零额外计算成本——不改变模型架构、不增加参数量,仅调整优化器配置即可获得更快的收敛速度和更优的最终性能。
13.3.5 Adapter 合并策略:从训练到部署
当微调完成后,如何将 LoRA 适配器的权重合并回基模型是部署的关键环节。不同的合并策略在精度、灵活性和工程复杂度之间存在不同的取舍。
策略一:直接合并(Merge and Unload)。 将
from peft import PeftModel
from transformers import AutoModelForCausalLM
# 加载基模型和 LoRA 适配器
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
model = PeftModel.from_pretrained(base_model, "path/to/lora-adapter")
# 合并权重并卸载 LoRA 结构
merged_model = model.merge_and_unload()
# 保存合并后的完整模型
merged_model.save_pretrained("path/to/merged-model")优点是推理时与原始模型完全一致,无任何额外开销;缺点是不可逆——合并后无法再单独调整或切换 LoRA。
策略二:多 Adapter 动态切换。 保留 LoRA 结构不合并,通过 PEFT 的 Adapter 管理接口在推理时动态切换。适用于同一基模型服务多个任务的场景:
from peft import PeftModel
# 加载基模型
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
model = PeftModel.from_pretrained(base_model, "path/to/adapter-A", adapter_name="task_A")
# 加载第二个 Adapter
model.load_adapter("path/to/adapter-B", adapter_name="task_B")
# 动态切换
model.set_adapter("task_A") # 激活任务 A 的适配器
output_a = model.generate(...)
model.set_adapter("task_B") # 切换到任务 B
output_b = model.generate(...)优点是灵活性极高,基模型只需加载一次,每个 Adapter 仅占数 MB 内存;缺点是推理时需要额外计算 LoRA 旁路。
策略三:Adapter 线性组合。 将多个 Adapter 的权重进行加权合并,创造出融合多种能力的复合模型:
from peft import PeftModel
model = PeftModel.from_pretrained(base_model, "path/to/adapter-A", adapter_name="A")
model.load_adapter("path/to/adapter-B", adapter_name="B")
# 加权组合:70% 任务 A 的能力 + 30% 任务 B 的能力
model.add_weighted_adapter(
adapters=["A", "B"],
weights=[0.7, 0.3],
adapter_name="merged_AB",
combination_type="linear", # 线性加权
)
model.set_adapter("merged_AB")该策略适用于需要融合多种微调能力(例如"风格 A + 知识 B")的场景。但正如 13.1 节所述的 MoE-LoRA 研究所指出的,简单线性组合可能导致特征稀释——当组合的 Adapter 数量增多时,每个 Adapter 的有效贡献被稀释,效果可能不如预期。
合并策略选择指南:
| 场景 | 推荐策略 | 理由 |
|---|---|---|
| 单任务部署、追求极致推理速度 | 直接合并 | 零额外开销,最简单 |
| 多任务服务、需要动态切换 | 多 Adapter 切换 | 灵活性高,基模型共享 |
| 融合多种微调能力 | 线性组合后合并 | 一次合并即可部署 |
| 需要精细控制组合权重 | MoE-LoRA 门控网络 | 自适应权重,保留各 Adapter 特征 |
13.3.6 trl + PEFT 集成实战
HuggingFace 的 trl(Transformer Reinforcement Learning)库原生支持 PEFT,为 SFT、DPO、GRPO 等主流训练范式提供了统一的 PEFT 集成接口。
SFT + LoRA 配置。 以 SFT(Supervised Fine-Tuning,监督微调)为例,只需将 peft_config 传入 SFTTrainer:
from datasets import load_dataset
from peft import LoraConfig
from trl import SFTConfig, SFTTrainer
# 准备数据集
dataset = load_dataset("trl-lib/Capybara", split="train")
# 配置 LoRA
peft_config = LoraConfig(
r=32,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules="all-linear", # 注入所有线性层
)
# 配置训练参数(注意:LoRA 需要更高的学习率)
training_args = SFTConfig(
output_dir="./sft-lora-output",
learning_rate=2e-4, # 约为全参数微调的 10 倍
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
num_train_epochs=1,
bf16=True,
)
# 创建训练器
trainer = SFTTrainer(
model="Qwen/Qwen2-0.5B",
args=training_args,
train_dataset=dataset,
peft_config=peft_config,
)
trainer.train()学习率的 10 倍法则。 使用 LoRA 时,推荐的学习率约为全参数微调的 10 倍。这是因为 LoRA 仅训练极少量参数(通常不到模型总量的 1%),需要更大的学习率来确保有效更新。下表总结了不同训练范式的推荐学习率:
| 训练范式 | 全参数微调学习率 | LoRA 学习率 (约 10x) |
|---|---|---|
| SFT | ||
| DPO | ||
| GRPO |
QLoRA + SFT 完整配置。 将 4-bit 量化与 LoRA 结合,是在消费级 GPU 上微调大模型的主流方案:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
import torch
from peft import LoraConfig
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
from trl import SFTConfig, SFTTrainer
# 4-bit 量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
# 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
quantization_config=bnb_config,
device_map="auto",
)
# LoRA 配置
peft_config = LoraConfig(
r=32, lora_alpha=16, lora_dropout=0.05,
bias="none", task_type="CAUSAL_LM",
target_modules="all-linear",
)
# 训练配置
training_args = SFTConfig(
output_dir="./qlora-output",
learning_rate=2e-4,
per_device_train_batch_size=1,
gradient_accumulation_steps=16,
num_train_epochs=1,
bf16=True,
)
# 创建训练器并开始训练
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset,
peft_config=peft_config,
)
trainer.train()DPO + LoRA 配置。 使用 PEFT 进行 DPO(Direct Preference Optimization,直接偏好优化)训练时,一个重要的工程细节是不需要单独提供参考模型——trl 会自动将冻结的基模型作为参考:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
from peft import LoraConfig
from trl import DPOConfig, DPOTrainer
peft_config = LoraConfig(
r=32, lora_alpha=16, lora_dropout=0.05,
bias="none", task_type="CAUSAL_LM",
)
training_args = DPOConfig(
output_dir="./dpo-lora-output",
learning_rate=5e-6, # DPO 的学习率通常更低
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
)
trainer = DPOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
args=training_args,
train_dataset=dataset,
peft_config=peft_config,
# 注意:无需传入 ref_model,冻结的基模型自动充当参考
)
trainer.train()LoRA 最佳实践总结。 近期 Thinking Machines Lab 的系统研究表明,合理配置的 LoRA 可以完全匹配全参数微调的性能,同时节省约 33% 的计算量。核心发现包括:
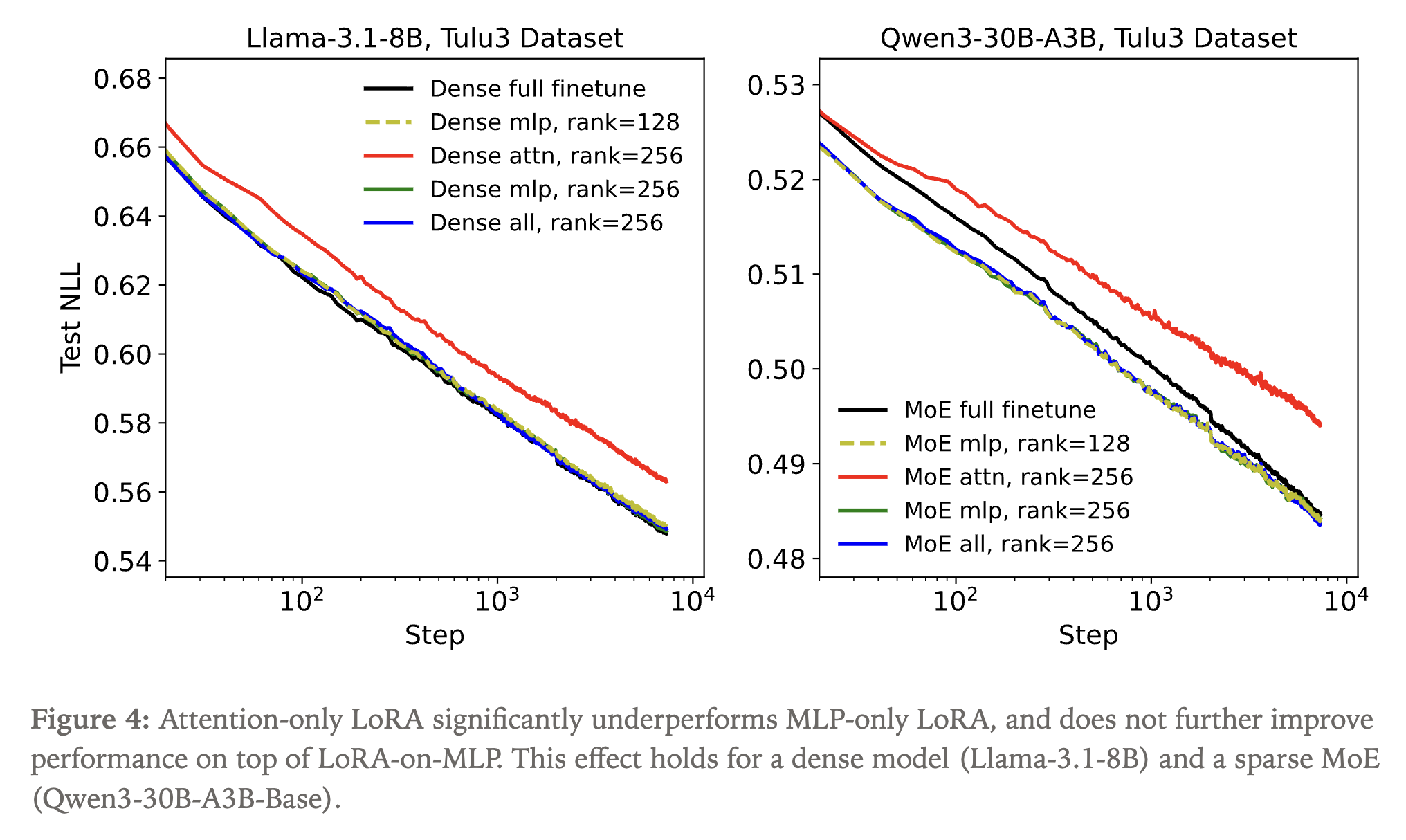
图 13-18:LoRA 应用到所有线性层(all-linear)的效果显著优于仅应用到注意力层,且增大秩无法弥补"仅注入注意力层"的损失。
- 注入所有线性层(
target_modules="all-linear")显著优于仅注入注意力层,且增大秩无法弥补这一差距 - SFT 推荐
(高容量),RL 推荐 (策略梯度信息量有限) - 有效批次大小不宜过大——LoRA 对大 batch size 的容忍度低于全参数微调,建议 effective batch size < 32
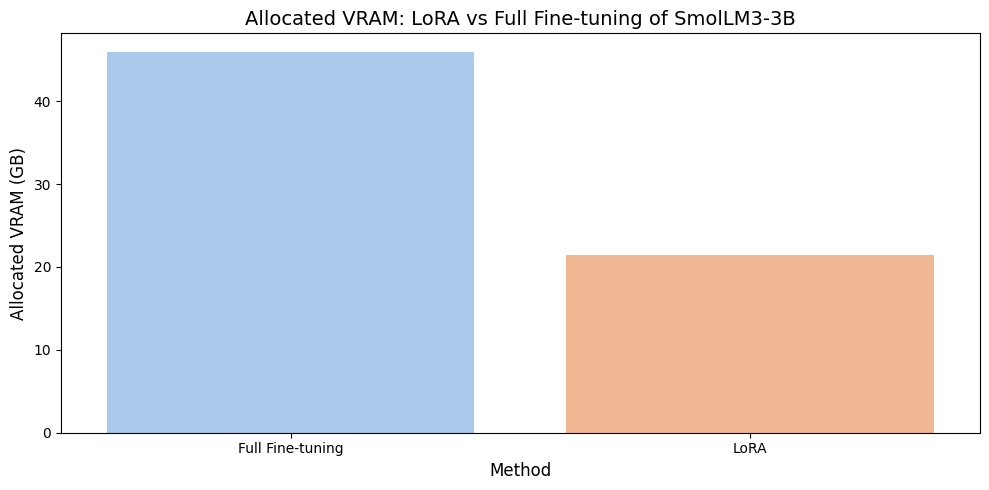
图 13-19:LoRA 与全参数微调的显存占用对比。LoRA 在达到相同训练效果的同时,显著降低了 GPU 显存消耗。
本节小结
- QLoRA 通过 NF4 量化 + 双重量化 + 分页优化器三项技术,将基模型压缩至 4-bit 精度,使得消费级 GPU 也能微调数十亿参数的模型。配置核心:
BitsAndBytesConfig的四个关键参数。 - DoRA 将权重更新解耦为独立的量级和方向两个分量,通过
use_dora=True一行配置即可启用,在多数任务上缩小了与全参数微调的差距。 - AdaLoRA 用 SVD 参数化 + 重要性评分 + 预算调度实现自适应秩分配,适合参数预算极为紧张的场景。
- LoRA+ 以零额外成本修正了矩阵
、 之间的梯度尺度不对称问题,通过差异化学习率加速收敛。 - Adapter 合并有三种主流策略:直接合并(部署最简)、多 Adapter 切换(灵活性最高)、线性组合(融合多能力)。
- trl + PEFT 为 SFT、DPO、GRPO 等训练范式提供了统一的集成接口,核心要点是学习率需提升至全参数微调的 10 倍左右,以及将 LoRA 注入所有线性层。