23.1 视觉-语言模型
在本书前面的章节中,我们分别讨论了语言模型和视觉模型:Transformer 为文本理解与生成提供了统一范式(§3.1–§3.4),而 Vision Transformer(ViT)则将同一架构迁移到了图像领域(§3.7)。然而,人类理解世界的方式本质上是多模态的——我们在阅读一段图文并茂的新闻时,同时处理文字语义和图像内容,并自然地在两个模态之间建立关联。如何让模型也具备这种跨模态能力?这正是视觉-语言模型(Vision-Language Model, VLM)要解决的核心问题。
本节将从三个层次递进展开:首先介绍 CLIP 如何通过对比学习实现图文对齐,奠定 VLM 的基础范式;然后剖析 BLIP 家族如何统一理解与生成能力,突破 CLIP 的架构局限;最后深入 DeepSeek 的 Janus 系列,看最新研究如何通过解耦视觉编码在单一模型中同时实现高质量的多模态理解与图像生成。
23.1.1 CLIP:对比学习驱动的图文对齐
为什么需要 CLIP?
在 CLIP 之前,计算机视觉模型的训练严重依赖人工标注:ImageNet 用 1400 万张图配上 2 万多个类别标签,每个标签都需要人工逐一核对。这种范式有两个根本问题。第一,标注成本高昂——要覆盖人类视觉能识别的所有概念,所需的类别数量几乎是无限的。第二,泛化能力受限——模型只能识别训练集中出现过的类别,遇到新类别就束手无策。
能否像人类一样,仅通过"看图读文"就学会视觉概念的语义?2021 年,OpenAI 发布的 CLIP(Contrastive Language-Image Pre-training, Radford et al., 2021)给出了肯定的回答。CLIP 的核心思路极其直接:从互联网上收集 4 亿个图像-文本对,训练模型判断"哪张图和哪段文字是匹配的"。这一范式彻底绕开了人工标注,让模型在海量噪声数据中自监督地学习跨模态语义。
双塔结构与对比学习
CLIP 的架构被称为双塔结构(Dual-Encoder),由两个独立的编码器组成:
- 图像编码器(Image Encoder):可以是 ResNet 或 ViT(实验表明 ViT 在大规模数据上更具优势)。给定输入图像,编码器将其映射为一个
维向量 。对于 ViT,编码器取 [CLS]token 的最终输出,再经过一个线性投影层和 L2 归一化得到单位向量。 - 文本编码器(Text Encoder):基于 Transformer 的编码器(类似 GPT 架构),将文本序列编码为一个
维向量 。具体取 [EOS]token 位置的输出,同样经过线性投影和 L2 归一化。
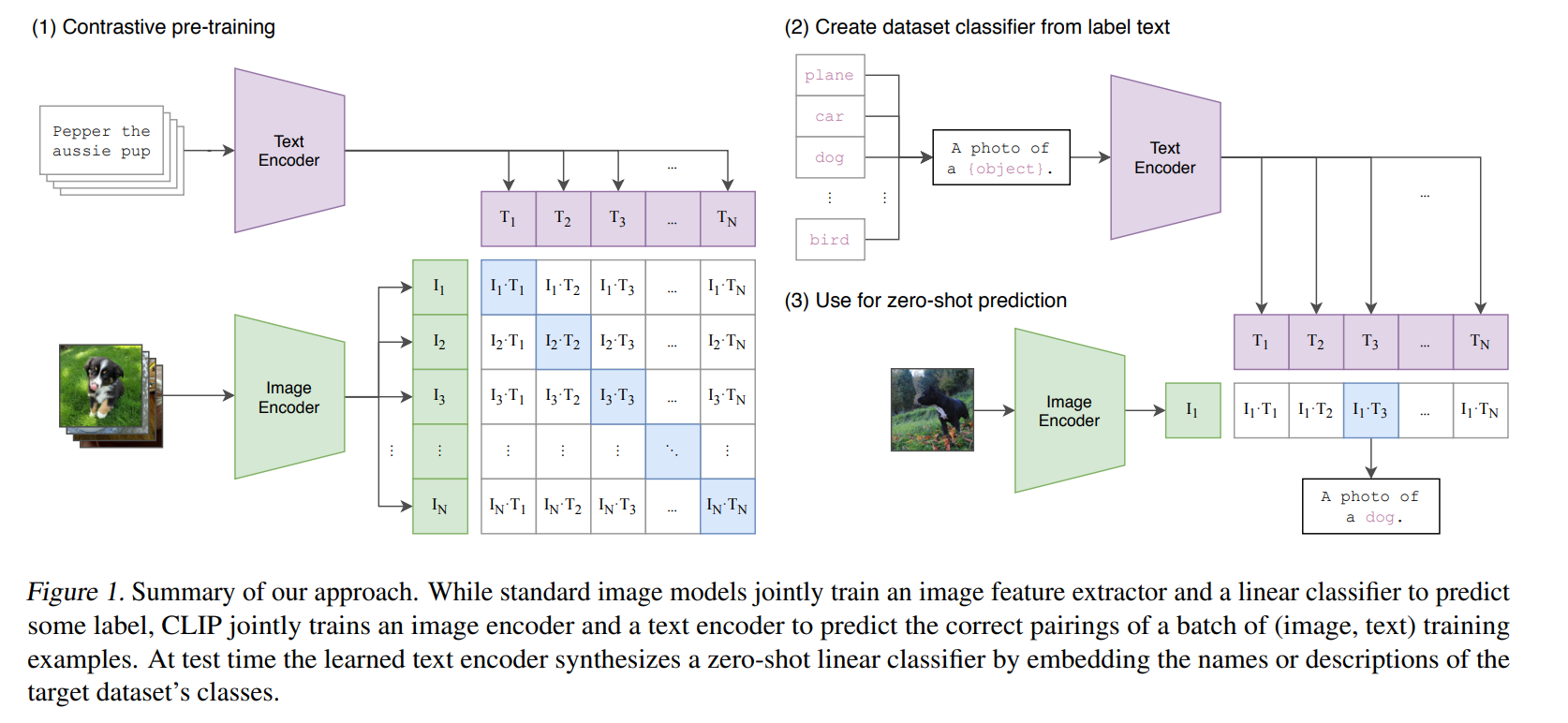
图 23-1:CLIP 的整体流程(来源:Radford et al., 2021)。左上:对比预训练阶段,图像编码器和文本编码器分别将图像和文本映射到共享语义空间,通过对比损失对齐匹配对。右上:基于类别标签文本构建零样本分类器。下方:零样本推理时,计算图像特征与所有类别文本特征的余弦相似度,取最大者为预测类别。
两个编码器将图像和文本分别投影到同一个
CLIP 使用对称交叉熵损失(Symmetric Cross-Entropy Loss)来优化两个方向的对齐:
其中
为什么用
[EOS]而非[CLS]? CLIP 的文本编码器采用类 GPT 的因果注意力架构,[EOS]位于序列末尾,天然聚合了整个序列的语义信息——这与 BERT 系编码器使用[CLS]的设计思路异曲同工,只是适配了不同的注意力模式。
零样本推理:Prompt 模板的巧妙设计
CLIP 训练完成后,模型从未在任何分类任务上微调过,却可以直接用于图像分类——这就是零样本(Zero-Shot)迁移的能力。其原理非常巧妙:
- 将分类数据集中的所有类别名嵌入到提示模板中,例如
"a photo of a {class_name}." - 将每个模板通过文本编码器生成类别文本特征
- 将待分类图像通过图像编码器生成图像特征
- 计算图像特征与所有类别文本特征的余弦相似度,取最大者为预测类别
这一流程不需要任何额外的分类头或参数调整。CLIP 在 ImageNet 上的零样本分类准确率达到 76.2%,与全监督训练的 ResNet-50 持平——要知道 ResNet-50 使用了 ImageNet 的全部 128 万张标注训练图像。
CLIP 的典型应用与局限性
CLIP 的影响力远超图像分类。它奠定了多模态 AI 的基础范式,成为后续众多模型的核心组件:
- 图像检索:给定文本描述,在海量图库中找到最匹配的图像
- 开放域目标检测:与检测框架结合,实现对任意类别的检测(如 OWL-ViT)
- 生成模型的语义引导:DALL-E 2、Stable Diffusion 等图像生成模型都依赖 CLIP 提供语义对齐信号
然而,CLIP 也存在明显的局限性:
- 仅支持全局对齐:CLIP 将整张图像压缩为一个向量,无法捕捉细粒度的局部特征(如特定部位的颜色、纹理),在细粒度分类任务上表现不佳
- 缺乏生成能力:CLIP 只能从预设类别中选择,无法生成文本描述或图像
- 文本长度受限:文本编码器最大支持 77 个 token,无法处理复杂的长文本描述
- 抽象推理缺失:无法进行物体计数、空间关系判断等需要逻辑推理的任务
以下是一个使用 CLIP 进行零样本图像分类的简化实现:
import torch
import torch.nn.functional as F
def clip_zero_shot_classify(image_features, text_features, temperature=0.07):
"""
CLIP 零样本分类的核心逻辑。
Args:
image_features: 图像编码器输出, shape (batch_size, embed_dim)
text_features: 各类别文本编码器输出, shape (num_classes, embed_dim)
temperature: 温度参数
Returns:
预测类别索引
"""
# L2 归一化
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
# 计算余弦相似度
# shape: (batch_size, num_classes)
similarity = image_features @ text_features.T / temperature
# 返回最大相似度对应的类别
return similarity.argmax(dim=-1)
def clip_contrastive_loss(image_features, text_features, temperature):
"""
CLIP 对比损失的对称实现。
Args:
image_features: shape (N, d), L2 归一化后
text_features: shape (N, d), L2 归一化后
temperature: 可学习的温度参数
"""
# 计算相似度矩阵 (N, N)
logits = image_features @ text_features.T / temperature
# 标签为对角线索引 [0, 1, 2, ..., N-1]
labels = torch.arange(len(logits), device=logits.device)
# 图像到文本 + 文本到图像的对称损失
loss_i2t = F.cross_entropy(logits, labels)
loss_t2i = F.cross_entropy(logits.T, labels)
return (loss_i2t + loss_t2i) / 223.1.2 BLIP 家族:统一理解与生成
CLIP 虽然在图文对齐上取得了突破,但它本质上是一个纯理解模型——只能做匹配和检索,无法生成文本描述。现实中的多模态任务远比图文匹配复杂:给一张图片生成描述(Image Captioning)、基于图片回答问题(VQA)、判断图文是否真正匹配(Image-Text Matching)……这些任务对模型的能力提出了不同的要求。
2022 年,Salesforce 的 Li et al. 提出 BLIP(Bootstrapping Language-Image Pre-training),首次在一个模型中统一了视觉-语言的理解与生成能力,并通过数据自举机制(CapFilt)从噪声数据中提炼高质量训练样本。
MED 架构:一套参数,三种模式
BLIP 的核心架构称为 MED(Multimodal Mixture of Encoder-Decoder),其设计思路是将一个模型拆分为四个功能模块,通过参数共享实现三种不同的预训练任务:
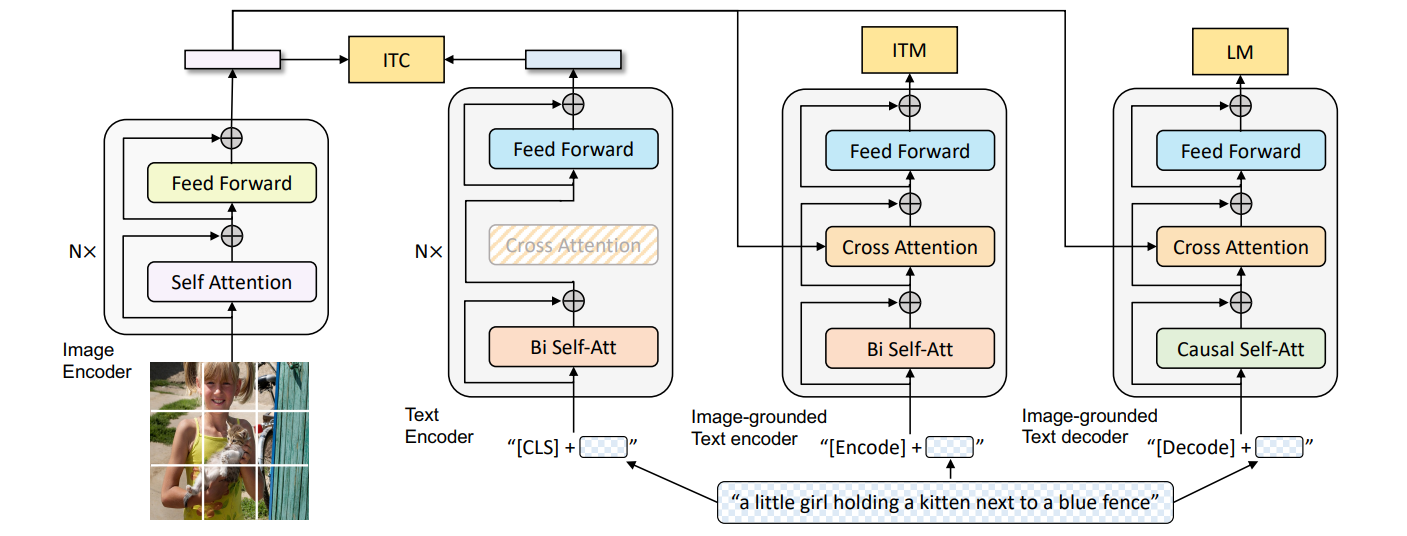
图 23-2:BLIP 的 MED 架构(来源:Li et al., 2022)。从左到右依次为:图像编码器(ViT + Self Attention)、单模态文本编码器(Bi Self-Att + [CLS],用于 ITC 对比学习)、基于图像的跨模态文本编码器(含 Cross Attention 层 + [Encode] token,用于 ITM 匹配判断)、基于图像的文本解码器(Causal Self-Att + Cross Attention + [Decode] token,用于 LM 语言生成)。
- 图像编码器(ViT):将输入图像编码为视觉特征序列,添加
[CLS]token 捕捉全局信息 - 单模态文本编码器(类 BERT):对文本进行双向编码,输出
[CLS]处的全局文本特征 - 基于图像的跨模态文本编码器:在标准 Transformer 块的自注意力层和前馈网络之间插入交叉注意力层(Cross-Attention),将图像特征注入文本表示。使用
[Encode]特殊标记汇聚多模态表示 - 基于图像的文本解码器:将双向自注意力替换为因果掩码自注意力,保留交叉注意力层,使用
[Decode]标记启动自回归生成
三种预训练任务及其损失函数:
| 任务 | 使用模块 | 目标 | 损失类型 |
|---|---|---|---|
| ITC(图文对比) | 图像编码器 + 文本编码器 | 对齐全局特征空间 | 对称交叉熵 |
| ITM(图文匹配) | 图像编码器 + 跨模态文本编码器 | 细粒度匹配判断 | 二分类交叉熵 |
| LM(语言建模) | 图像编码器 + 文本解码器 | 基于图像生成描述 | 自回归交叉熵 |
联合训练目标为三项损失的加权和:
CapFilt:数据自举的闭环
BLIP 的另一创新是 CapFilt(Captioning and Filtering)数据清洗机制。从网络爬取的图文对往往质量参差不齐——图片可能配了无关的广告文案,或者文本描述与图像内容只有松散的关联。CapFilt 用预训练好的 MED 模型自身来解决这个问题:
- Captioner(基于文本解码器):为每张图像重新生成高质量描述
- Filter(基于跨模态文本编码器):对原始网络文本和合成文本进行质量过滤,剔除与图像不匹配的样本
- 将过滤后的数据与人工标注数据合并,重新训练模型
这种"生成→过滤→重训"的自举循环让 BLIP 在 COCO 等数据集上的检索精度提升了 10%–15%,图像描述生成的 CIDEr 得分提升了 8%–12%。
BLIP-2:用 Q-Former 桥接冻结模型
BLIP 的端到端训练虽然效果好,但计算代价高昂——每次迭代需要同时训练图像编码器和语言模型。2023 年,同一团队推出 BLIP-2(Li et al., 2023),核心思想是冻结预训练好的视觉编码器和 LLM,仅训练一个轻量级桥梁模块 Q-Former。
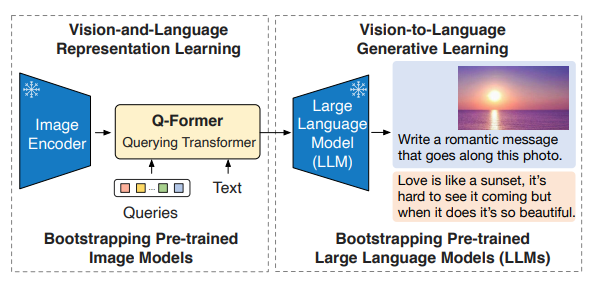
图 23-3:BLIP-2 的两阶段预训练概览(来源:Li et al., 2023)。第一阶段(左):冻结图像编码器,用 Q-Former(Querying Transformer)从可学习查询向量和输入文本中提取与视觉相关的表示;第二阶段(右):将 Q-Former 的输出桥接到冻结的 LLM,实现视觉到语言的生成。
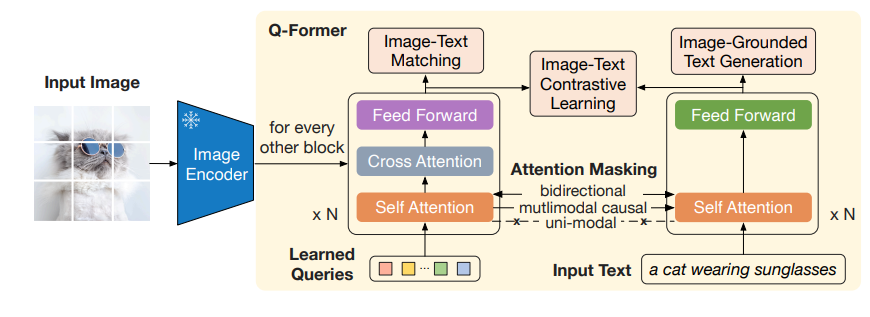
图 23-4:Q-Former 的内部结构(来源:Li et al., 2023)。左侧图像分支输入 32 个可学习查询向量(Learned Queries),通过交叉注意力与冻结图像编码器交互。右侧文本分支处理输入文本。两个分支共享自注意力层,通过三种不同的注意力掩码策略(单模态/双向/因果)分别支持 ITC、ITM 和 Image-Grounded Text Generation 三种任务。
Q-Former(Querying Transformer)包含两个共享自注意力层的 Transformer 分支:
- 图像分支:输入 32 个可学习的查询向量(Learned Queries),通过交叉注意力与冻结图像编码器的输出交互,提取视觉特征。这 32 个查询形成了一个信息瓶颈,迫使模型只保留与文本最相关的视觉信息
- 文本分支:处理文本输入,与图像分支共享自注意力层
Q-Former 仅有约 1.88 亿参数,远小于冻结的图像编码器和 LLM。通过两阶段预训练,BLIP-2 用极低的计算成本(相比端到端训练节省了 54 倍的可训练参数)实现了与全参数训练可比的性能。
InstructBLIP 进一步将指令微调引入 BLIP-2 框架:Q-Former 不仅接收图像特征,还接收用户指令,从而提取与当前任务相关的视觉特征。这使得同一模型可以根据不同指令(描述图片、回答问题、识别文字等)灵活调整视觉特征提取策略。
从 CLIP 到 BLIP 的演进逻辑
回顾这条技术路线,我们可以看到清晰的递进关系:
| 维度 | CLIP | BLIP | BLIP-2 |
|---|---|---|---|
| 对齐方式 | 全局对比 | 全局对比 + 细粒度匹配 | 查询驱动的特征提取 |
| 生成能力 | 无 | 有(自回归解码器) | 有(借助冻结 LLM) |
| 训练成本 | 高(双塔全参数训练) | 高(四模块联合训练) | 低(仅训练 Q-Former) |
| 核心创新 | 对比学习范式 | MED 架构 + CapFilt | 冻结大模型 + 轻量桥梁 |
23.1.3 Janus:解耦视觉编码的统一框架
上一节介绍的 BLIP 系列虽然在理解与生成上都取得了不错的效果,但它们将图像理解和图像生成视为两个相对独立的下游任务。一个更具雄心的目标是:在同一个模型中,用同一个 LLM 骨干同时完成多模态理解和图像生成,而不是依赖外挂的扩散模型。
2024 年 10 月,DeepSeek 团队发布了 Janus(Wu et al., 2024),提出了一个关键洞察:多模态理解和图像生成对视觉编码的需求是截然不同的,不应该共用同一个视觉编码器。
为什么需要解耦?
以 Chameleon(Meta, 2024)为代表的早期统一模型使用单一的 VQ Tokenizer 同时处理理解和生成任务。但这两个任务对视觉表示的要求有本质差异:
- 多模态理解需要高维语义特征:模型要识别"这是一只猫"、"图中有三个人"、"这张图的情感是积极的"——这些判断依赖对图像高层语义的抽象理解
- 图像生成需要低维空间细节:模型要精确重建像素级的纹理、色彩和空间结构——这需要保留大量底层视觉信息
用单一编码器同时满足这两个需求,势必在两者之间做出妥协。Janus 的消融实验清楚地证实了这一点:使用单一 VQ Tokenizer 的统一模型(Exp-A)在 POPE 基准上仅得 60.1 分,而解耦后的 Janus(Exp-D)达到 87.0 分——理解性能提升了约 45%。
Janus 的架构设计
Janus 的核心设计是视觉编码解耦——用两条独立的视觉通路分别服务理解和生成任务,而后端由一个统一的自回归 Transformer(LLM)处理所有模态:
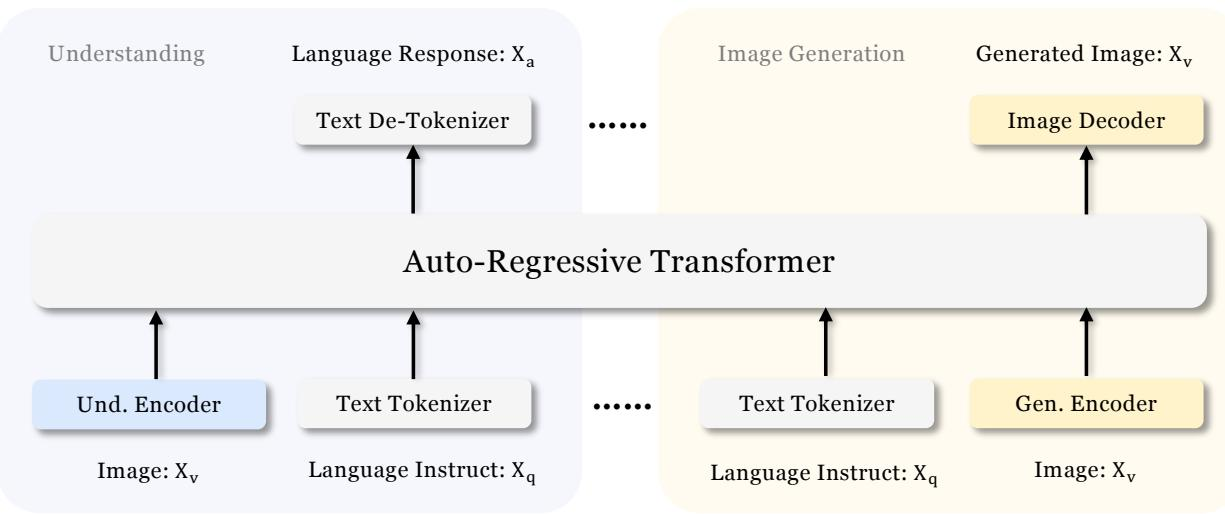
图 23-5:Janus 的架构设计(来源:Wu et al., 2024)。左侧理解通路:图像经 Understanding Encoder(SigLIP)编码后与文本 token 一起送入自回归 Transformer,输出语言响应。右侧生成通路:文本指令经 Text Tokenizer 编码后,LLM 自回归预测图像 token,由 Image Decoder 重建为生成图像。两条通路共享同一个 Auto-Regressive Transformer。
具体而言:
- 理解通路:使用预训练的 SigLIP-Large-Patch16-384 作为视觉编码器,提取 384×384 输入图像的高维语义特征。特征经展平和线性投影后,通过 Understanding Adaptor(两层 MLP)映射到 LLM 的嵌入空间
- 生成通路:使用 VQ Tokenizer(来自 LlamaGen,码本大小 16,384,下采样因子 16)将图像转化为离散 token 序列。每个 token 的码本嵌入通过 Generation Adaptor(同为两层 MLP)映射到 LLM 输入空间
- 统一 LLM:基于 DeepSeek-LLM(1.3B),使用标准的因果注意力掩码(causal attention mask)和 next-token prediction 目标。对理解任务,loss 计算在文本 token 上;对生成任务,loss 计算在图像 token 上
训练损失就是标准的自回归交叉熵:
注意,Janus 没有为不同任务分配不同的损失权重——保持设计的极简性。
三阶段训练策略
Janus 的训练分为三个阶段,逐步解锁模型参数:
| 阶段 | 可训练模块 | 冻结模块 | 训练数据 | 目标 |
|---|---|---|---|---|
| Stage I | Adaptors + Image Head | 视觉编码器 + LLM | Image Caption + ImageNet | 建立跨模态概念连接 |
| Stage II | LLM + Adaptors + Image Head | 视觉编码器 | 纯文本 + 图文理解 + 文生图 | 统一预训练 |
| Stage III | LLM + Und. Encoder + Adaptors + Image Head | Gen. Encoder | 指令微调数据 | 对话与指令遵循 |
Stage II 中有一个重要的训练技巧:先在 ImageNet 数据上训练 120K 步,让模型学习基本的像素依赖关系,再切换到通用文生图数据学习复杂场景生成。
Janus 的推理流程
对于多模态理解任务(如 VQA),推理流程与标准 VLM 一致:将图像经 SigLIP 编码后与文本 token 拼接送入 LLM,自回归生成文本回答。
对于图像生成任务,Janus 采用 next-token prediction 结合 Classifier-Free Guidance(CFG):
其中
23.1.4 Janus-Pro 与 JanusFlow:进阶演化
Janus 在 1.3B 参数规模上验证了视觉编码解耦的有效性,但也暴露了一些不足:短提示生成的图像质量不稳定,生成分辨率受限于 384×384。DeepSeek 团队随后推出了两个改进版本——JanusFlow 和 Janus-Pro,分别从生成方法和工程优化两个方向进行升级。
JanusFlow:用 Rectified Flow 替代离散 token 生成
Janus 将图像生成建模为离散 token 的自回归预测,而 JanusFlow(Ma et al., 2024)提出了一个大胆的替代方案:在 LLM 框架内直接集成 Rectified Flow——一种基于常微分方程(ODE)的连续生成模型。
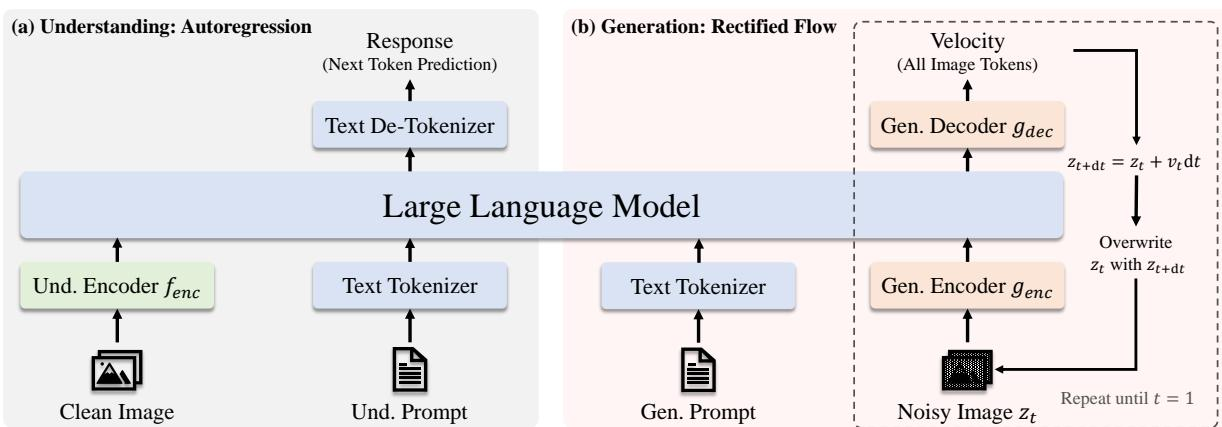
图 23-6:JanusFlow 的架构(来源:Ma et al., 2024)。(a) 理解通路与 Janus 相同,使用 Und. Encoder(SigLIP)编码图像,LLM 自回归生成文本响应。(b) 生成通路不再使用 VQ Tokenizer,而是从高斯噪声出发,经 Gen. Encoder 编码后送入 LLM 预测速度场(Velocity),通过 Gen. Decoder 输出更新量,迭代执行
Rectified Flow 的核心思想是学习一个速度场
训练目标是最小化预测速度与真实方向之间的
推理时,从高斯噪声出发,用 Euler 积分器逐步更新:
JanusFlow 的一个关键创新是表示对齐正则化(Representation Alignment Regularization, REPA):在生成任务中,将 LLM 中间层的特征与 SigLIP 编码器的语义特征进行对齐:
这一正则化项利用了解耦编码器的优势——理解编码器的高层语义特征为生成过程提供了额外的语义约束,帮助 LLM 的内部表示空间与语义空间对齐,从而提升生成图像的语义一致性。
Janus-Pro:数据与模型的规模化
2025 年 1 月,Janus-Pro(Chen et al., 2025)回到了 Janus 的离散 token 路线,但在三个维度上进行了系统性改进:
训练策略优化:
- Stage I 增加训练步数(10K→20K),在 ImageNet 上充分学习像素依赖
- Stage II 不再混入 ImageNet,直接使用通用文生图数据进行高效训练
- Stage III 调整数据配比:从 7:3:10(理解:文本:生成)改为 5:1:4,在保持生成能力的同时提升理解性能
数据规模扩展:
- 多模态理解:增加约 9000 万样本(包括 YFCC 图像描述、DocMatrix 文档理解等)
- 图像生成:加入约 7200 万合成美学数据,真实与合成数据比例 1:1,显著改善了生成稳定性和美学质量
模型规模扩展:从 1.3B LLM 扩展到 7B,收敛速度显著加快
Janus-Pro-7B 在多项基准上达到了统一模型的最优水平:
| 基准 | Janus (1.3B) | Janus-Pro-7B | 对比模型 |
|---|---|---|---|
| MMBench | 69.4 | 79.2 | TokenFlow-XL (13B): 68.9 |
| GenEval | 0.61 | 0.80 | DALL-E 3: 0.67, SD3-Medium: 0.74 |
| DPG-Bench | 79.68 | 84.19 | SD3-Medium: 84.08 |

图 23-7:Janus 与 Janus-Pro-7B 的图像生成对比(来源:Chen et al., 2025)。每组左侧为 Janus 生成结果,右侧为 Janus-Pro-7B。可以明显看到 Janus-Pro 在人脸细节、物体纹理、文字渲染等方面的生成质量都有显著提升,且对短提示(如"The face of a beautiful girl")的生成稳定性更好。
以下示意代码展示了 Janus 风格的多任务推理逻辑:
import torch
import torch.nn as nn
class JanusStyleModel(nn.Module):
"""Janus 风格的统一多模态模型(简化示意)。"""
def __init__(self, llm, und_encoder, gen_encoder,
und_adaptor, gen_adaptor, image_head):
super().__init__()
self.llm = llm # 统一的自回归 Transformer
self.und_encoder = und_encoder # 理解编码器 (如 SigLIP)
self.gen_encoder = gen_encoder # 生成编码器 (如 VQ Tokenizer)
self.und_adaptor = und_adaptor # 理解特征适配器
self.gen_adaptor = gen_adaptor # 生成特征适配器
self.image_head = image_head # 图像 token 预测头
def forward_understanding(self, image, text_tokens):
"""多模态理解:图像 + 文本 → 文本回答"""
# 理解通路:SigLIP 编码 → adaptor 映射
img_features = self.und_encoder(image) # (B, N_patches, D_enc)
img_embeds = self.und_adaptor(img_features) # (B, N_patches, D_llm)
# 获取文本嵌入
text_embeds = self.llm.get_input_embeddings()(text_tokens)
# 拼接图像和文本嵌入
inputs = torch.cat([img_embeds, text_embeds], dim=1)
# LLM 自回归生成文本回答
outputs = self.llm(inputs_embeds=inputs)
return outputs # 文本 logits
def forward_generation(self, text_tokens, image_tokens):
"""图像生成:文本 → 图像 token 序列"""
# 获取文本嵌入
text_embeds = self.llm.get_input_embeddings()(text_tokens)
# 生成通路:VQ 码本嵌入 → adaptor 映射
gen_embeds = self.gen_adaptor(
self.gen_encoder.get_codebook_embeddings(image_tokens)
)
# 拼接文本和图像 token 嵌入
inputs = torch.cat([text_embeds, gen_embeds], dim=1)
# LLM 处理,用专用 image_head 预测下一个图像 token
hidden = self.llm(inputs_embeds=inputs).last_hidden_state
image_logits = self.image_head(hidden[:, len(text_tokens):])
return image_logits # 图像 token 的预测分布Janus 家族的演进脉络
三个版本形成了一条清晰的技术演进路线:
| 模型 | 发布时间 | 生成方式 | LLM 规模 | 关键创新 |
|---|---|---|---|---|
| Janus | 2024.10 | VQ 离散 token | 1.3B | 视觉编码解耦 |
| JanusFlow | 2024.11 | Rectified Flow 连续生成 | 1.3B | LLM + Flow 融合,REPA 对齐 |
| Janus-Pro | 2025.01 | VQ 离散 token | 1.5B / 7B | 训练策略 + 数据 + 模型规模化 |
一个值得思考的问题是:离散 token vs 连续 latent,哪条路线更有前途? JanusFlow 采用连续表示,理论上保留了更多视觉细节;而 Janus-Pro 回到离散 token,因为离散表示与 causal attention 的硬件友好性更好。DeepSeek 团队同时探索两条路线,表明这一问题尚无定论——连续表示的上限可能更高,但离散 token 的工程效率更具吸引力。
23.1.5 VLM 技术全景:从对齐到统一
回顾本节的内容,VLM 的发展可以概括为三个阶段的递进:
第一阶段:对比对齐(CLIP)。通过对比学习在共享语义空间中对齐图像和文本的全局表示。优势是简洁高效、零样本泛化能力强;局限是只能做匹配、无法生成。
第二阶段:统一理解与生成(BLIP 系列)。通过多任务架构同时训练对比对齐、细粒度匹配和文本生成。BLIP-2 的 Q-Former 进一步将预训练成本降到极低。但图像生成仍需外挂扩散模型。
第三阶段:单模型全统一(Janus 系列)。通过视觉编码解耦,在同一个 LLM 中同时完成多模态理解和图像生成,不依赖外部生成模型。Janus-Pro-7B 在理解和生成基准上同时超越了许多专用模型。
这条演进路线背后有一个核心原则:视觉理解和视觉生成需要不同粒度的信息表示。CLIP 只处理全局语义;BLIP 增加了细粒度对齐但仍共享编码器;Janus 首次明确地解耦了两种表示需求——理解用高维语义编码器(SigLIP),生成用低维空间编码器(VQ Tokenizer 或 VAE + Flow)。这一解耦思想不仅在 Janus 上验证有效,也为未来容纳更多模态(如 3D 点云、音频、EEG 信号)提供了灵活的架构扩展空间。
本节要点总结
- CLIP 通过对比学习和双塔结构实现了图文的全局语义对齐,奠定了 VLM 的基础范式。其对称交叉熵损失和可学习温度参数的设计被广泛沿用。零样本推理通过 Prompt 模板将分类问题转化为图文匹配问题。
- BLIP 家族通过 MED 架构统一了理解(ITC + ITM)与生成(LM)能力,并用 CapFilt 数据自举机制从噪声数据中提炼高质量样本。BLIP-2 的 Q-Former 以极少的可训练参数桥接了冻结的视觉编码器和 LLM。
- Janus 系列的核心贡献是视觉编码解耦:用独立的编码器分别处理理解(高维语义)和生成(低维空间)需求,用统一的 LLM 骨干进行自回归处理。JanusFlow 探索了 Rectified Flow 连续生成路线,Janus-Pro 通过数据和模型规模化将性能推向新高度。
- VLM 的演进方向是从"对齐"走向"统一":在单一模型中无缝融合多模态理解与生成,同时保持各任务的最优性能。