25.1 项目总览与架构设计
构建一个大语言模型(LLM)听起来遥不可及——动辄数百亿参数、成千上万张 GPU、以 PB 为单位的训练数据。然而,理解 LLM 的核心原理,并不需要这般庞大的规模。本章将以 MiniMind 项目为蓝本,带领读者从零开始搭建一个仅有 26M 到 145M 参数的"麻雀虽小、五脏俱全"的语言模型。MiniMind 覆盖了分词器训练、预训练、监督微调(SFT)、LoRA、DPO、PPO/GRPO 强化学习、模型蒸馏等完整流程,并同时提供 Dense 和 MoE(Mixture of Experts)两种架构变体。
本节聚焦于 MiniMind 的整体设计哲学、模型架构和参数配置,为后续章节逐一拆解各训练阶段奠定全局视角。
25.1.1 设计哲学:为什么要造一个"极小"模型
MiniMind 的核心理念可以概括为一句话:用最小的成本,走完大模型的全流程。具体而言,它追求三个目标:
极低训练门槛:最小的 MiniMind2-Small(26M 参数)在单张 NVIDIA 3090 上仅需约 2 小时即可完成预训练 + 监督微调,GPU 租用成本约 3 元人民币。这意味着任何拥有消费级显卡的开发者都能亲手走完 LLM 的诞生全过程。
代码全部自包含:所有核心算法——从 RoPE 位置编码到 PPO/GRPO 强化学习——均使用 PyTorch 原生实现,不依赖第三方库的高度封装接口。每一行代码都是"可触摸"的。
架构对齐主流:尽管参数量极小,MiniMind 的架构设计严格对齐 Llama 3 / DeepSeek-V2 等工业级模型,包括 RMSNorm、RoPE、SwiGLU、GQA、MoE 等关键技术。学习 MiniMind 所获得的架构理解,可以直接迁移到任何主流 LLM 上。
25.1.2 模型家族总览
MiniMind 共有两代主要版本,本书以更成熟的第二代(MiniMind2 系列)为主要讲解对象。下表列出了核心型号:
| 型号 | 参数量 | 词表大小 | 层数 | 隐藏维度 | Q 头数 | KV 头数 | 专家配置 |
|---|---|---|---|---|---|---|---|
| MiniMind2-Small | 26M | 6400 | 8 | 512 | 8 | 2 | - |
| MiniMind2-MoE | 145M | 6400 | 8 | 640 | 8 | 2 | 1 共享 + 4 路由 |
| MiniMind2 | 104M | 6400 | 16 | 768 | 8 | 2 | - |
三个型号的核心差异在于:
- MiniMind2-Small:最轻量的版本,8 层、512 维。体积仅为 GPT-3 的
,适合快速实验和教学演示。推理时仅占用约 0.5 GB 显存。 - MiniMind2:16 层、768 维的"标准版",参数量约 104M,与 GPT-3 Small(125M)同量级。更深的网络带来了更强的抽象能力。
- MiniMind2-MoE:在 MiniMind2-Small 的基础上引入混合专家机制,每层包含 1 个共享专家和 4 个路由专家,每个 token 激活 Top-2 路由专家。总参数 145M,但每个 token 实际激活的参数量远小于此。
所有型号共享同一套自定义分词器(词表大小 6400),这是 MiniMind 控制模型体积的关键决策之一——相比 Qwen2 的 151K、Llama 3 的 128K 词表,6400 的词表使得 Embedding 层参数量极低,避免了小模型中常见的"头重脚轻"问题。
25.1.3 Dense 模型架构
MiniMind-Dense 采用标准的 Transformer Decoder-Only 架构,与 Llama 3.1 高度对齐。整体结构如下图所示:
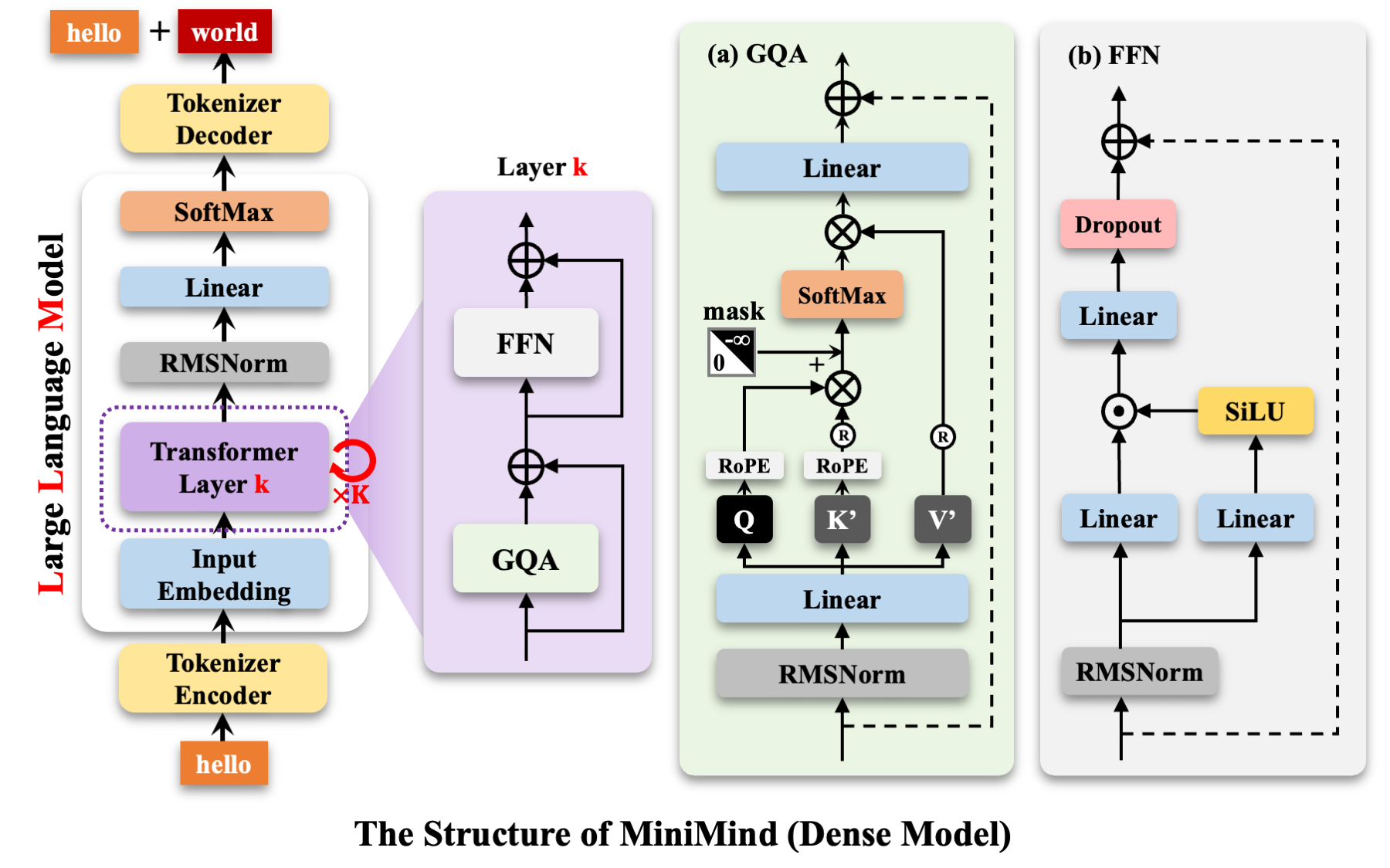
从输入到输出,数据流经以下组件:
1. 输入层:Token Embedding + 权重绑定
输入 token ID 经过 Embedding 层映射为隐藏向量。MiniMind 采用了**权重绑定(Weight Tying)**策略——Embedding 层与输出的 LM Head 共享同一个权重矩阵:
这在小模型中尤为重要。对于 MiniMind2-Small,词表大小 6400、隐藏维度 512,Embedding 矩阵包含
2. Transformer Block:Pre-Norm + GQA + SwiGLU
每个 Transformer Block 包含两个子层,均采用**预归一化(Pre-Norm)**范式——先归一化、再计算、最后残差连接:
这与 GPT-2 时代的 Post-Norm(先计算、再归一化)相比,训练更加稳定,已成为现代 LLM 的标准做法。
归一化层:RMSNorm
MiniMind 使用 RMSNorm(Root Mean Square Normalization)替代传统的 LayerNorm。两者的区别在于:
其中均方根计算为:
RMSNorm 省略了均值中心化和偏置项,计算量更小,且在深层网络中训练效果不逊于 LayerNorm。以下是其 PyTorch 实现:
import torch
import torch.nn as nn
class RMSNorm(nn.Module):
def __init__(self, dim: int, eps: float = 1e-5):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def forward(self, x):
# 转为 float32 计算以保证数值精度
norm = x.float().pow(2).mean(-1, keepdim=True).add(self.eps).rsqrt()
return self.weight * (x.float() * norm).type_as(x)注意力层:Grouped Query Attention(GQA)
MiniMind 的注意力层使用 GQA(Grouped Query Attention),这是 MHA(Multi-Head Attention)和 MQA(Multi-Query Attention)的折中方案。以 MiniMind2-Small 为例,它配置了 8 个 Query 头但仅有 2 个 KV 头,每 4 个 Query 头共享一组 KV:
GQA 的优势在推理阶段尤为明显:KV Cache 的显存占用与 KV 头数成正比,2 个 KV 头相比 8 个头节省了 75% 的缓存空间,从而支持更长的上下文或更大的批次。
位置编码:RoPE(Rotary Positional Embedding)
MiniMind 摒弃了绝对位置嵌入,采用 RoPE(旋转位置编码)将位置信息注入 Query 和 Key 向量。RoPE 的核心思想是将位置
其中
RoPE 的一个重要性质是,两个位置
此外,MiniMind 还集成了 YaRN(Yet Another RoPE Extension)算法,用于在推理时将上下文窗口从训练长度(2048)扩展至最高 32K。YaRN 的核心思想是对不同频率的维度采取差异化策略——高频维度(负责局部关注)保持不变,低频维度(负责全局关注)进行线性插值,中间部分平滑过渡。
前馈网络:SwiGLU
前馈网络采用 SwiGLU(SiLU-Gated Linear Unit)结构,包含三个线性变换:
其中 SiLU(也称 Swish)激活函数为
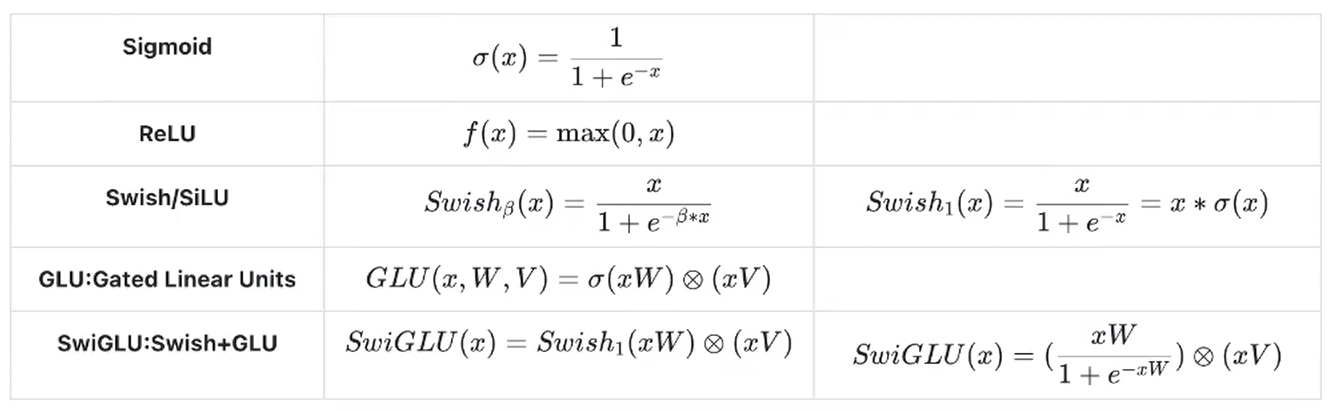
中间层维度的计算遵循 Llama 的约定:
其中
3. 输出层:LM Head
最终的隐藏状态经过一层 RMSNorm 后,通过与 Embedding 层共享权重的线性层映射回词表维度,再经过 Softmax 得到下一个 token 的概率分布:
25.1.4 MoE 模型架构
MiniMind-MoE 在 Dense 架构的基础上,将每个 Transformer Block 中的 FFN 层替换为混合专家前馈网络(MoE FFN)。其设计参考了 DeepSeek-V2 的 Shared + Routed Experts 策略。
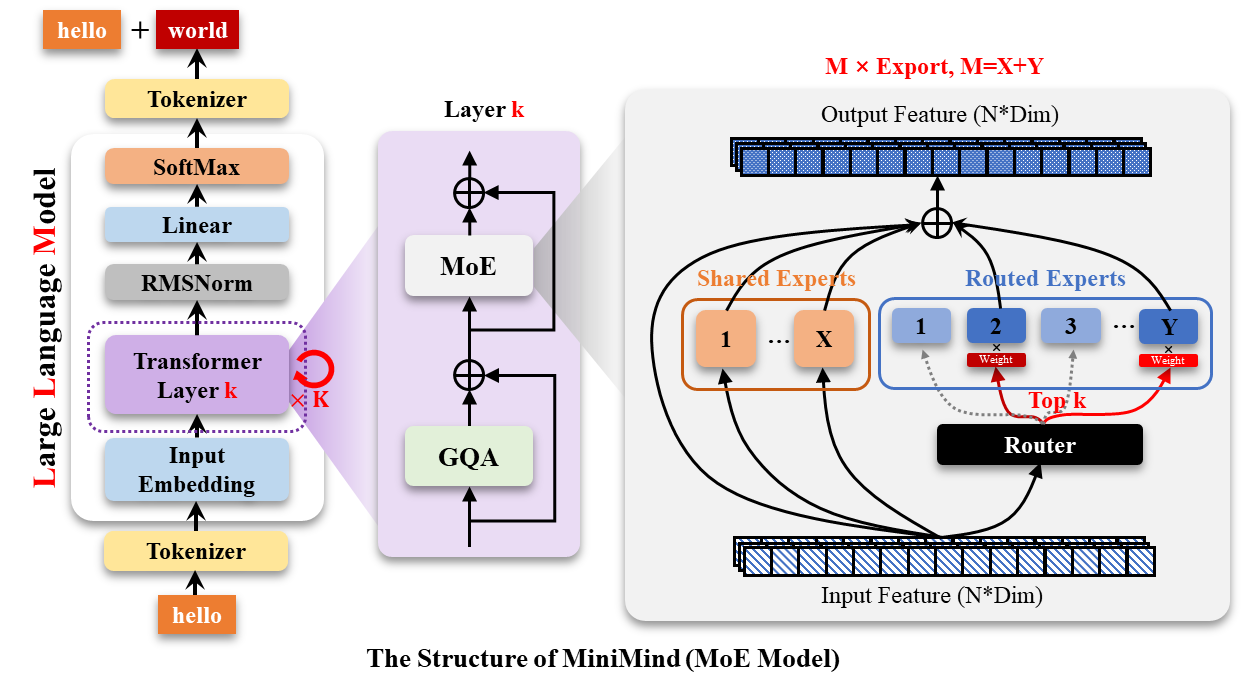
MoE 的核心组件
MoE FFN 由三部分组成:
- 路由专家(Routed Experts):多个独立的 SwiGLU FFN 网络。MiniMind2-MoE 配置了 4 个路由专家。
- 共享专家(Shared Experts):1 个始终被激活的 FFN 网络,所有 token 都会经过它。共享专家保证了基础知识的连续性。
- 门控网络(Router / Gate):决定每个 token 分配给哪些路由专家。
门控机制(MoEGate)
门控网络是 MoE 的"交通指挥官"。对于输入的每个 token 向量
第一步:计算亲和度分数。 通过一个线性层将隐藏向量映射到专家维度,再用 Softmax 归一化:
第二步:Top-K 选择。 从
选中的权重会重新归一化,使其和为 1:
第三步:加权融合。 最终输出为共享专家与路由专家结果的加权和:
辅助损失:防止专家负载不均
MoE 训练中一个经典问题是专家坍塌(Expert Collapse)——门控网络倾向于将所有 token 都发送给少数几个"明星"专家,导致其他专家得不到训练。MiniMind 通过在总损失中加入一个**辅助损失(Auxiliary Loss)**来惩罚负载不均:
其中
25.1.5 参数配置的设计考量
小模型的参数配置并非简单地缩小大模型——研究表明,Scaling Law 在小模型上有其独特的规律。MobileLLM(Meta, 2024)的研究发现,对于参数量在 100M 量级的模型,"深而窄"优于"宽而浅"。
作为参考,GPT-3 系列的参数配置如下:
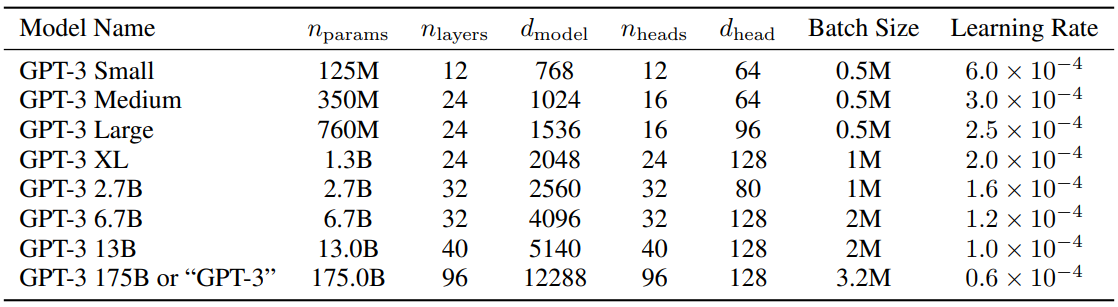
可以看到,GPT-3 Small(125M)使用 12 层、768 维。MiniMind2(104M)采用了 16 层、768 维,层数更多但减少了注意力头数(8 vs 12),体现了"深度优先"的策略。
MiniMind 在实验中观察到的关键规律:
时:词嵌入维度过低导致每个注意力头的 不足,增加层数也难以弥补。512 是 small 模型的"甜蜜点"。 时:增加层数的边际收益超过增加宽度,更符合"性价比"原则。 - GQA 的必要性:在 26M 参数预算下,使用 8 个 Q 头 + 2 个 KV 头(GQA),比 8 个 Q 头 + 8 个 KV 头(MHA)节省了大量参数,留给 FFN 层更多空间。
25.1.6 训练全流程概览
MiniMind 的训练流程覆盖了 LLM 的完整生命周期。下图展示了从数据到最终模型的全流程:
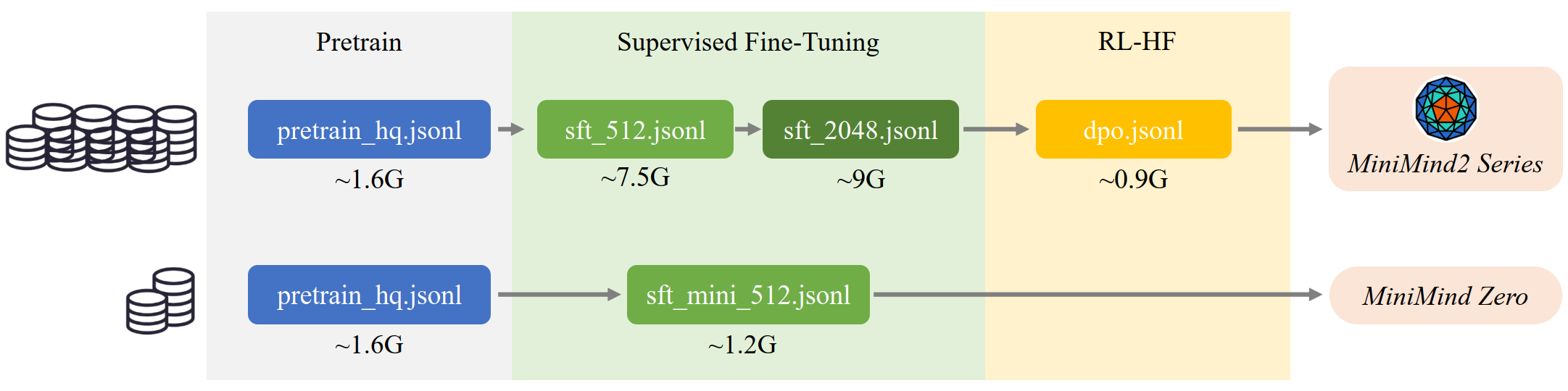
整个训练分为以下阶段:
| 阶段 | 目标 | 数据 | 输出 |
|---|---|---|---|
| 预训练(Pretrain) | 学习世界知识,掌握"词语接龙"能力 | pretrain_hq.jsonl (~1.6 GB) | pretrain_*.pth |
| 监督微调(SFT) | 学习对话格式,从"接龙"变为"对话" | sft_mini_512.jsonl (~1.2 GB) | full_sft_*.pth |
| 强化学习(RLHF/RLAIF) | 对齐人类偏好,提升回复质量 | dpo.jsonl / rlaif-mini.jsonl | dpo_*.pth 等 |
快速复现路径:仅使用 pretrain_hq.jsonl + sft_mini_512.jsonl,单卡 3090 约 2 小时即可训练出一个具备基本对话能力的 MiniMind-Zero 模型。
完整训练路径:依次经过预训练、SFT(sft_512 + sft_2048)、DPO,总数据量约 20 GB(~4B tokens),可以获得 MiniMind2 系列的完整效果。
此外,MiniMind 还支持 LoRA 微调(用于领域适配)、白盒蒸馏(教师-学生知识迁移)、推理模型蒸馏(DeepSeek-R1 风格的 CoT 训练)等进阶训练方式,将在后续章节详细展开。
25.1.7 评测与基线对比
尽管参数量极小,MiniMind 在多个中文基准测试上展现了合理的性能。下图是 MiniMind2 系列与同量级开源模型在 C-Eval、CMMLU、A-CLUE、TMMLU+ 等榜单上的雷达图对比:
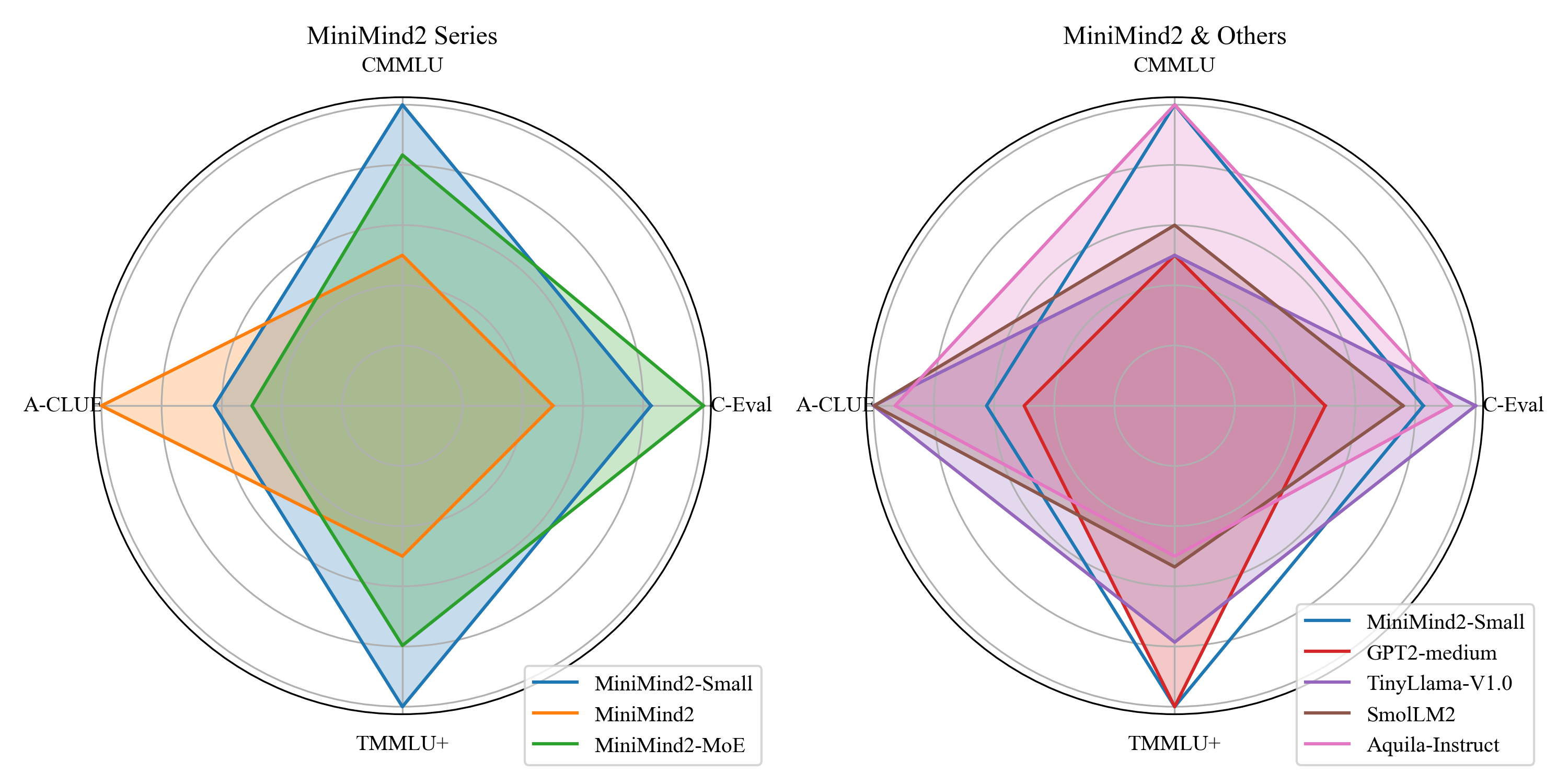
左图展示了 MiniMind 内部三个型号的对比:MiniMind2(104M)总体表现最优,MoE 版本在部分维度上接近 Dense 版本但总参数利用率更高。右图与 GPT2-medium、TinyLlama-V1.0、SmolLM2 等同量级模型的对比表明,MiniMind2-Small 在仅有 26M 参数的情况下,仍能保持有竞争力的表现。
需要注意的是,这些评测结果应审慎解读:26M 参数的模型在复杂推理、长文本理解等任务上存在固有的能力上限,评测数据更多用于验证训练流程的有效性,而非追求 SOTA 性能。
25.1.8 本节小结
本节从设计哲学、模型家族、Dense 与 MoE 两种架构、参数配置策略、训练流程和评测结果六个维度,对 MiniMind 项目进行了全景式的总览。MiniMind 的核心价值在于:它用极低的成本和极简的代码,完整复现了一个现代 LLM 从出生到成熟的全流程,涵盖了 RMSNorm、RoPE、GQA、SwiGLU、MoE 等当前主流技术。在后续章节中,我们将逐一深入每个模块的实现细节——从分词器的训练(25.2)、模型代码的逐行拆解(25.3),到预训练(25.4)、SFT(25.5)等各阶段的训练实践。