15.5 PO 算法统一框架
前几节分别介绍了 PPO、DPO 和 GRPO 三种核心对齐算法。回顾它们的目标函数,你会发现一个有趣的共性:每种算法都在策略更新、优势估计和正则约束三个维度上做出了不同的设计选择,但整体目标函数的骨架是相似的。本节将从一个统一的视角出发,构建 PO(Policy Optimization)算法的通用框架,然后逐一拆解各算法在三个核心组件上的选择差异,最后梳理 PO 算法家族的继承与演化关系。
15.5.1 统一目标函数
观察 PPO、GRPO、DAPO、GSPO 等算法的目标函数,可以抽象出一个三项式结构:
其中:
- 策略项
:对新旧策略概率比(importance ratio) 的处理方式,决定了策略更新的幅度控制; - 优势项
:优势函数(Advantage)的估计方式,决定了"哪些回答该被强化、哪些该被抑制"; - 正则项
:KL 散度惩罚,防止策略偏离参考模型过远。
不同的 PO 算法,就是在这三个"插槽"中填入不同的函数。下面我们将这个框架展开。
15.5.2 策略项
策略项的核心任务是利用重要性采样(Importance Sampling)复用旧策略数据,同时限制更新幅度以保证训练稳定。
重要性采样的基本原理。 策略梯度的原始形式要求从当前策略
然而,当
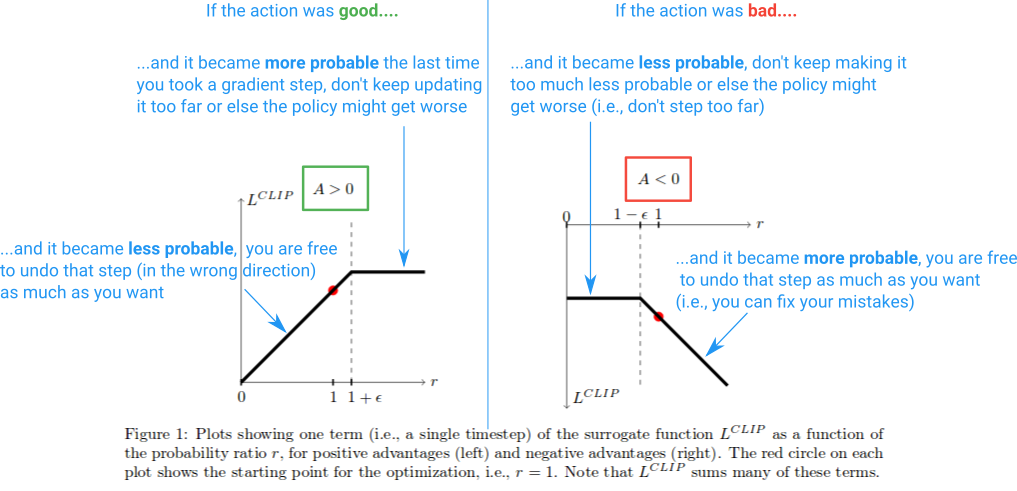
图 15-14:PPO 裁剪机制示意图。对正优势动作,
PPO-Clip:对称裁剪。 PPO 对
这里
DAPO 的非对称裁剪(Clip-Higher)。 GRPO/PPO 的对称裁剪存在一个微妙问题:熵崩溃(Entropy Collapse)。考虑正优势情况,若某个 token 原本概率
DAPO 将裁剪上下界解耦为
GSPO 的序列级策略项。 GRPO 在每个 token 位置独立计算
GSPO 的核心洞察是:优化目标的粒度应与奖励的粒度匹配。既然奖励是授予整个序列的,就应该在序列级别计算重要性比率:
其中
下表汇总了各算法在策略项上的设计选择:
| 算法 | 策略项形式 | 粒度 | 裁剪方式 |
|---|---|---|---|
| PPO | token | 对称 | |
| GRPO | 同 PPO | token | 对称 |
| DAPO | token | 非对称 | |
| GSPO | 序列 | 对称 | |
| GMPO | 几何平均聚合 token 级 clip 项 | token→序列 | 对称 |
15.5.3 优势项
优势函数(Advantage Function)回答的核心问题是:这个动作(或这段回答)比平均水平好多少? 不同算法用截然不同的方式来回答这个问题。
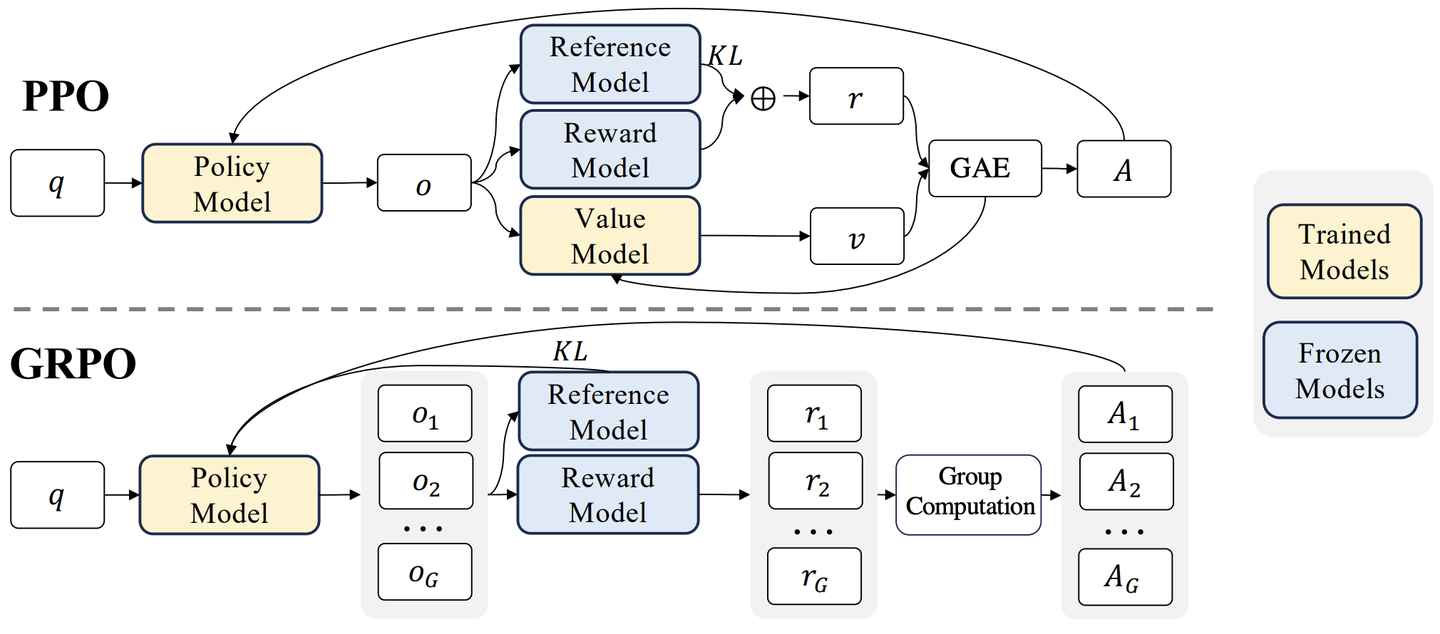
图 15-15:PPO 与 GRPO 的架构对比。上方的 PPO 需要 4 个模型协同,通过价值模型 V 和 GAE 估计每个 token 的优势;下方的 GRPO 去掉了价值模型,对同一 prompt 采样 G 个回答,用组内奖励的均值和标准差计算优势。
PPO:基于价值模型的 GAE。 PPO 使用广义优势估计(Generalized Advantage Estimation, GAE),通过一个专门的价值模型(Critic)
其递归形式为
def compute_gae(rewards, values, gamma=0.99, lam=0.95):
"""
计算广义优势估计(GAE)。
Args:
rewards: 每步奖励,形状 [T]
values: 价值模型预测,形状 [T+1](含终态 V(s_{T+1}))
gamma: 折扣因子
lam: GAE 平滑因子
Returns:
advantages: 优势估计,形状 [T]
"""
T = len(rewards)
advantages = [0.0] * T
gae = 0.0
# 从序列末尾反向递推:delta 为 TD 误差,gae 为累积优势
for t in reversed(range(T)):
delta = rewards[t] + gamma * values[t + 1] - values[t]
gae = delta + gamma * lam * gae
advantages[t] = gae
return advantagesGAE 通过
GAE 的优势在于 token 级的细粒度信用分配——它能告诉模型"错在哪一步"。但代价是需要额外训练一个与策略模型同等规模的价值模型,显存开销翻倍。
GRPO:组内相对优势。 GRPO 的核心创新是完全去掉价值模型,用同一 prompt 下多个回答的统计量替代。对每个 prompt
import torch
def compute_group_advantages(rewards, eps=1e-4):
"""
GRPO 组内相对优势计算。
Args:
rewards: 形状 [batch_size, group_size],每个 prompt 的 G 个回答的奖励
eps: 防止除零的小常数
Returns:
advantages: 形状 [batch_size, group_size],归一化后的优势
"""
mean = rewards.mean(dim=1, keepdim=True) # [B, 1]
std = rewards.std(dim=1, keepdim=True) # [B, 1]
advantages = (rewards - mean) / (std + eps) # [B, G]
return advantages
# 示例:2 个 prompt,每个采样 4 个回答
rewards = torch.tensor([
[1.0, 2.0, 0.5, 1.5], # prompt 1
[5.0, 6.0, 5.5, 7.0], # prompt 2
])
adv = compute_group_advantages(rewards)
print(adv)
# prompt 1: [-0.42, 1.27, -1.27, 0.42] (2.0 最好,0.5 最差)
# prompt 2: [-1.18, 0.17, -0.50, 1.51] (7.0 最好,5.0 最差)组相对优势有两个重要特性:(1)对奖励的绝对尺度不敏感——只关心组内排名;(2)期望为零——好回答和差回答在梯度上自然平衡,无需显式基线。
DPO:隐式优势。 DPO 走了一条完全不同的路——它既不需要价值模型,也不需要显式奖励模型。通过推导 Bradley-Terry 偏好模型下的最优策略闭式解:
DPO 将策略模型本身当作隐式奖励函数,直接用偏好对
| 算法 | 优势估计方式 | 是否需要价值模型 | 信用分配粒度 |
|---|---|---|---|
| PPO | GAE(基于 Critic) | 需要 | token 级 |
| GRPO | 组内标准化(基于采样) | 不需要 | 序列级 |
| DPO | 隐式(策略即奖励) | 不需要 | 偏好对级 |
| VAPO | 增强 GAE(价值偏差修正) | 需要 | token 级 |
15.5.4 正则项
KL 散度惩罚项的目的是约束策略模型不要偏离参考模型太远,防止 reward hacking(奖励作弊)和模型崩溃。
token 级 KL 惩罚(PPO/GRPO)。 最直接的方式是在每个 token 位置计算策略与参考模型的 KL 散度,作为"即时惩罚"加入奖励中。GRPO 采用 Schulman 提出的 KL 近似器:
该近似基于泰勒展开:当
PPO 的 KL 作为奖励塑形。 在 PPO 的 RLHF 实现中,KL 惩罚通常被融入奖励信号而非作为独立正则项:
即每个 token 都受到 KL 惩罚(稠密信号),而奖励模型的打分仅在序列结尾给出(稀疏信号)。
DPO 的隐式 KL。 DPO 不显式计算 KL,但其损失函数中的
DAPO 的去 KL 设计。 在推理任务(如数学竞赛)的长思维链场景中,DAPO 选择完全移除 KL 惩罚,让模型自由探索更长、更复杂的推理路径,不被参考模型的分布所束缚。
| 算法 | KL 处理方式 | 参考模型 |
|---|---|---|
| PPO | 融入奖励(每 token KL 惩罚) | 需要,冻结 |
| GRPO | 独立正则项(Schulman 近似) | 需要,冻结 |
| DPO | 隐式包含在损失中 | 需要,冻结 |
| DAPO | 移除 KL 惩罚 | 不需要 |
15.5.5 具体算法的统一视角
有了三个组件的分析,我们可以将各算法的目标函数统一到
PPO 的完整目标:
GRPO 的完整目标:
GSPO 的完整目标:
DPO 的目标(偏好优化形式):
下面的代码展示了如何用统一接口实现多种 PO 算法的策略损失计算:
import torch
import torch.nn.functional as F
def po_loss(log_probs, old_log_probs, advantages, ref_log_probs=None,
method="grpo", eps_low=0.2, eps_high=0.2, beta=0.01):
"""
PO 算法统一策略损失计算。
Args:
log_probs: 当前策略的 token 级 log 概率,形状 [B, T]
old_log_probs: 旧策略的 token 级 log 概率,形状 [B, T]
advantages: 优势值(PPO: token 级 [B,T];GRPO: 序列级 [B])
ref_log_probs: 参考模型的 log 概率,形状 [B, T](可选)
method: 算法名 ("ppo" / "grpo" / "dapo" / "gspo")
eps_low: 裁剪下界
eps_high: 裁剪上界
beta: KL 惩罚系数
Returns:
loss: 标量损失
"""
if method == "gspo":
# 序列级重要性比率(几何平均)
seq_len = log_probs.shape[1]
log_ratio = (log_probs - old_log_probs).mean(dim=1) # [B]
ratio = torch.exp(log_ratio) # s_i
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1 - eps_low, 1 + eps_high) * advantages
loss = -torch.min(surr1, surr2).mean()
else:
# token 级重要性比率
ratio = torch.exp(log_probs - old_log_probs) # [B, T]
if method == "grpo" or method == "dapo":
adv = advantages.unsqueeze(1).expand_as(ratio) # [B] -> [B, T]
else: # ppo: advantages 已经是 [B, T]
adv = advantages
surr1 = ratio * adv
surr2 = torch.clamp(ratio, 1 - eps_low, 1 + eps_high) * adv
policy_loss = -torch.min(surr1, surr2).mean()
# KL 惩罚(GRPO/PPO 使用,DAPO 不使用)
kl_loss = 0.0
if ref_log_probs is not None and method != "dapo":
# Schulman KL 近似
log_r = ref_log_probs - log_probs
kl = torch.exp(log_r) - log_r - 1
kl_loss = beta * kl.mean()
loss = policy_loss + kl_loss
return loss15.5.6 PO 家族的工程改进
在 GRPO 的基础上,一系列后续工作针对具体的工程痛点做出了改进。这些改进本质上都是在统一框架的某个组件上做微调。
Dr.GRPO:修正长度偏差。 GRPO 对每个回答按
DAPO 的动态采样。 当某个 prompt 的所有回答全对(
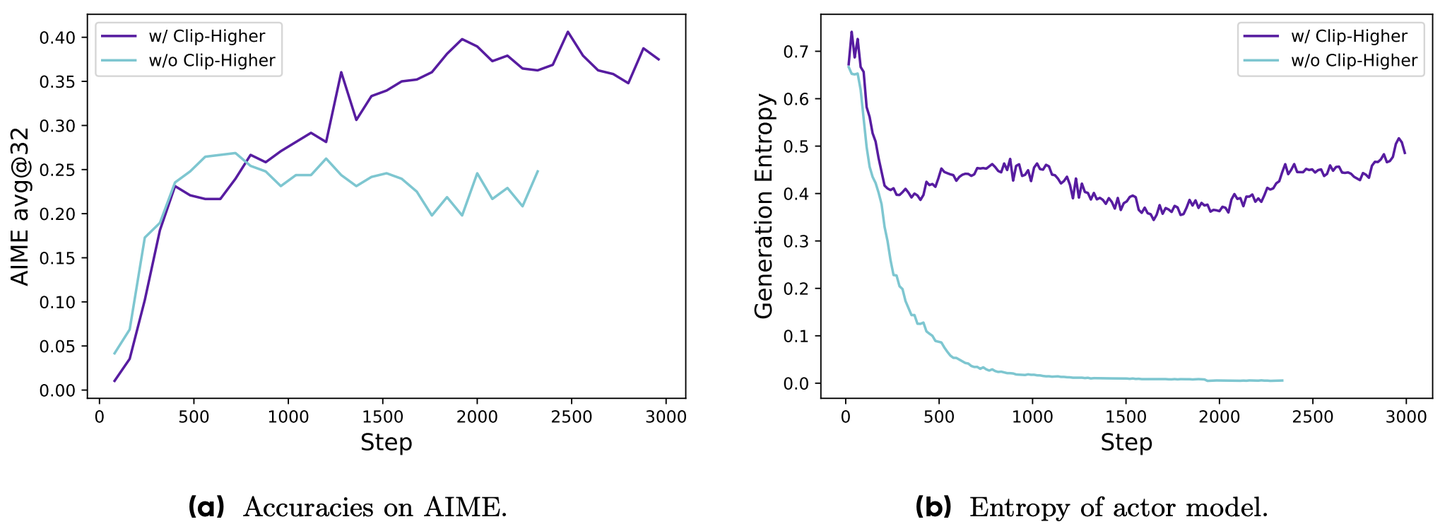
图 15-16:DAPO 的 Clip-Higher 实验对比。不使用 Clip-Higher 时(浅蓝色),策略熵快速下降至接近零,模型丧失探索能力,准确率停滞;使用 Clip-Higher 后(紫色),熵维持在较高水平,准确率持续提升。
CISPO:让越界 token 继续贡献梯度。 在 PPO/GRPO/DAPO 中,当
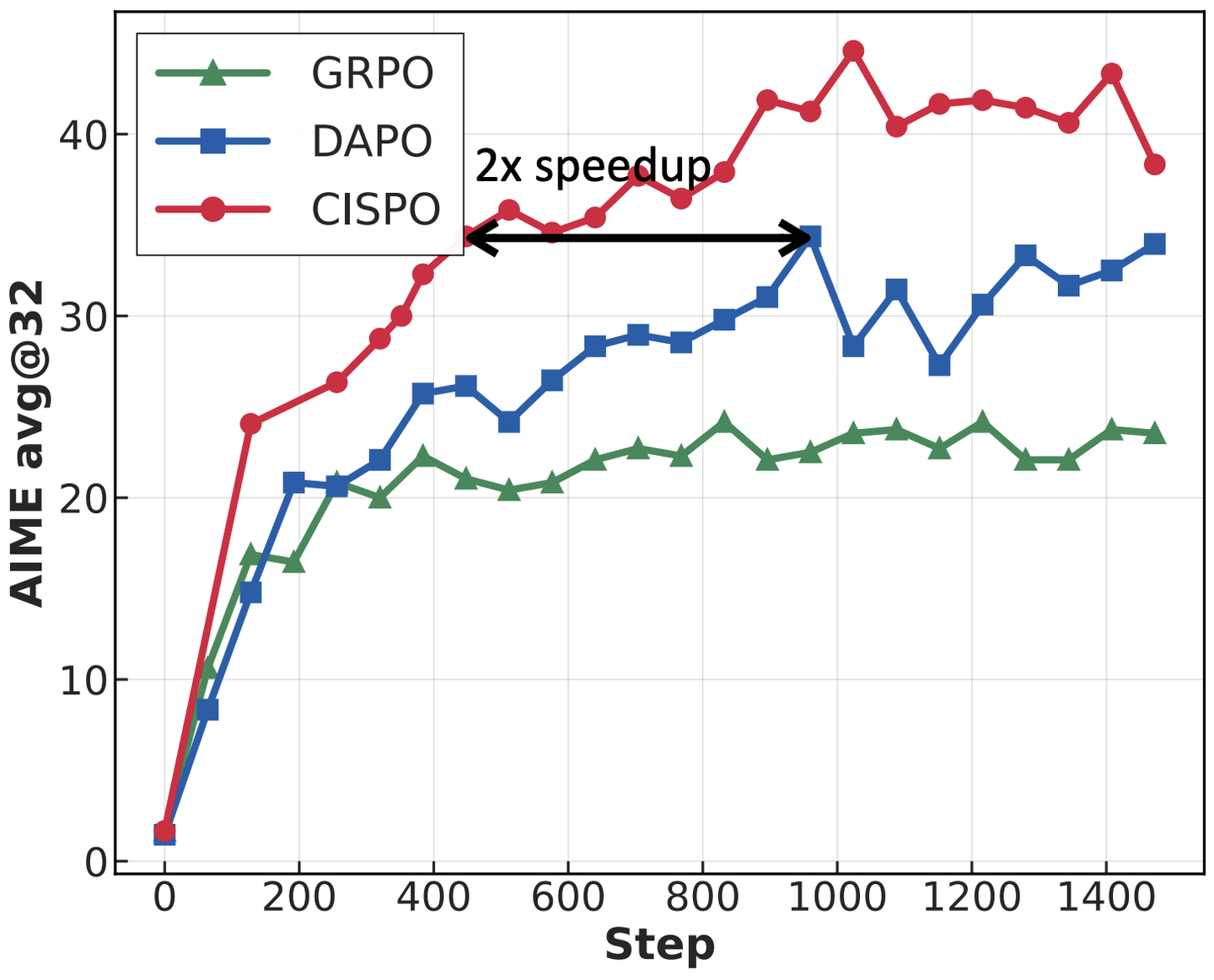
图 15-17:PO 家族算法在 AIME 2024 上的性能对比。CISPO 通过保留越界 token 的梯度贡献,在相同训练步数下显著优于 GRPO 和 DAPO。
GMPO:几何平均聚合。 GRPO 用算术平均
15.5.7 继承与演化关系
回顾整个 PO 算法家族,可以画出清晰的继承树:
策略梯度 / Actor-Critic
│
├── PPO(clip + GAE,稳定的基石)
│ ├── VAPO(增强价值模型,推理 SOTA)
│ └── GRPO(去掉价值模型,组相对优势)
│ ├── DAPO(非对称 clip + 动态采样 + token 归一化)
│ ├── Dr.GRPO(修正长度归一化偏差)
│ ├── GMPO(几何平均,抑制 outlier)
│ ├── GSPO(序列级策略项,降方差)
│ ├── GFPO(采样过滤,控制输出长度)
│ └── CISPO(越界 token 有界梯度)
│
└── DPO(独立分支:无 RM/RL,Bradley-Terry 偏好优化)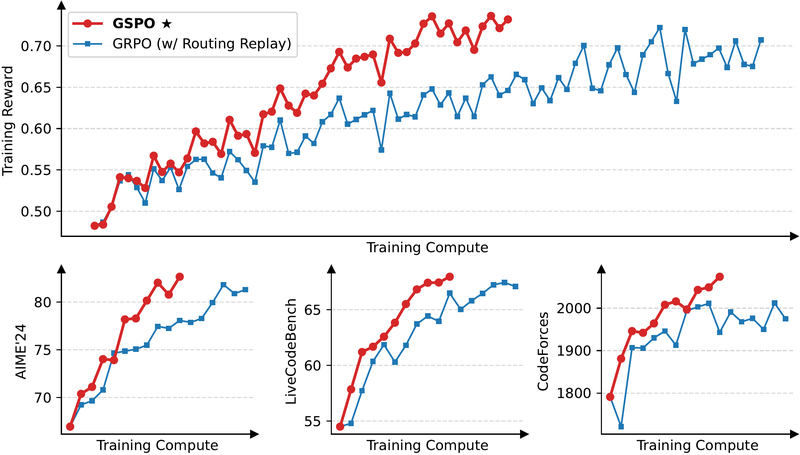
图 15-18:GSPO 与 GRPO 在 Qwen3-30B-A3B 上的训练对比。GSPO(红色)在训练奖励和下游任务表现上全面领先 GRPO(蓝色),且无需路由回放即可稳定训练 MoE 模型。
下表从统一框架的视角汇总各算法的核心设计选择:
| 算法 | 策略项粒度 | 优势估计 | KL 正则 | 是否需要 Critic | 核心改进 |
|---|---|---|---|---|---|
| PPO | token | GAE(价值模型) | 融入奖励 | 是 | clip 限制更新 |
| DPO | 偏好对 | 隐式(策略即奖励) | 隐式 | 否 | 直接偏好优化 |
| GRPO | token | 组内标准化 | Schulman 近似 | 否 | 去掉 Critic |
| DAPO | token | 组内标准化 | 移除 | 否 | 非对称 clip + 动态采样 |
| GSPO | 序列 | 组内标准化 | 可选 | 否 | 序列级 clip |
| GMPO | token→序列 | 组内标准化 | 同 GRPO | 否 | 几何平均聚合 |
| Dr.GRPO | token | 组内标准化 | 同 GRPO | 否 | 修正长度偏差 |
| CISPO | token | 组内标准化 | 同 DAPO | 否 | 越界 token 有界梯度 |
小结
本节构建了 PO 算法的统一三项式框架