11.1 计算集群架构
当大语言模型的参数量从千万级增长到万亿级,训练所需的算力也从单张 GPU 的 TFLOPS 量级飙升到整个集群的 EFLOPS 量级。这意味着,我们不能再把"一台服务器"作为思考训练的基本单位——整个数据中心才是新的计算单元。理解 AI 集群的整体架构,是掌握大规模训练工程实践的第一步。
在过去十章中,我们从模型架构到训练算法再到并行策略,已经讨论了大量"怎么训"的问题。但所有这些算法和策略最终都要落地到具体的硬件基础设施上——没有足够的 GPU 算力、没有足够快的网络互连、没有足够大的存储系统,再精巧的并行策略也只是纸上谈兵。从本章开始,我们将视角从"单机上的算法"切换到"集群上的系统",系统地讨论支撑大模型训练的基础设施——这个领域被称为 AI Infra(AI 基础设施)。
本节将从三个维度展开:首先厘清 HPC 集群、AI 集群与云数据中心这三类计算集群的本质差异;然后介绍 AI Infra 的 L0-L4 分层架构,建立系统性的认知框架;最后梳理硬件与软件两条技术路线的发展趋势,为后续章节的深入讨论奠定基础。
11.1.1 三类计算集群:HPC、AI 集群与云数据中心
虽然 HPC 高性能计算中心、AI 计算中心和云数据中心都是由大量服务器节点通过高速网络互联而成的集群系统,但它们在应用目标、计算特征和系统设计上有着本质的不同。搞清楚这三者的区别,是理解 AI 集群为何需要"专用化设计"的起点。

高性能计算中心(HPC) 面向国防科研等需要极高精度的科学计算场景,如气候模拟、核爆仿真、分子动力学、地震波反演等。HPC 是衡量国家科技核心竞争力的重要标志,科研三大范式(理论、实验、计算)中,计算已成为不可或缺的支柱。其核心特征是采用 FP64 双精度 浮点运算——因为科学计算对精度有极苛刻的要求,一个天气预报模型中微小的舍入误差经过数百万步迭代就可能导致预测结果完全偏离现实。HPC 的通信模式复杂多样:有些应用(如 FFT 变换)需要大规模的 All-to-All 通信,有些(如有限元分析)以近邻交换为主,还有些(如蒙特卡洛模拟)几乎不需要通信。这种流量特征的多样性对网络拓扑的灵活性要求极高。存储方面,HPC 通常需要处理密集且复杂的 I/O 模式,科学数据集动辄 PB 级别,全球 Top 100 超算中约 70% 使用 Lustre 分布式文件系统。
AI 计算中心(智算中心) 专注于大模型的训练与推理任务。由于 AI 大模型的运算本质是大规模矩阵乘法,其对精度的要求远低于科学计算——研究表明,FP16 甚至 FP8 格式足以完成高质量的模型训练。因此 AI 训练广泛使用 混合精度计算(FP16/BF16/FP8 甚至 FP4),在可接受的精度损失范围内将吞吐量提升数倍。AI 集群的通信模式相比 HPC 更加规律:训练过程中的梯度同步(All-Reduce)、参数收集(All-Gather)和流水线激活传递是三种主要通信原语。更重要的是,这些通信操作可以与 GPU 计算重叠执行——当 GPU 在计算第
云数据中心 面向通用互联网服务,通过虚拟化技术(KVM、容器等)将物理资源池化,按需弹性分配给用户。其计算以 INT32 整型和 FP32 全精度为主,强调的是 高并发 而非单任务的极致算力——一个云数据中心可能同时服务数百万用户的 Web 请求、数据库查询和视频转码任务。云数据中心的网络通信相对分散,服务间调用以东西向流量为主;它通过 IaaS(基础设施即服务,提供虚拟机/存储/网络等原始资源)、PaaS(平台即服务,提供开发和部署环境)和 SaaS(软件即服务,提供开箱即用的应用程序)三种服务模式向用户交付能力。云数据中心对可靠性、可用性和可服务性(RAS)有极高要求,采用多可用区(AZ)容灾架构保障服务连续性。
谷歌在这一领域的贡献值得特别提及。2009 年,谷歌工程师 Luiz Barroso 和 Urs Hölzle 提出了"仓储级计算机(Warehouse-Scale Computer)"的概念,将整个数据中心视为一台巨型计算机进行全栈协同设计。谷歌在全球自建了 23 个超大规模数据中心,并在其中部署了自研的 TPU(Tensor Processing Unit)AI 加速芯片,开创性地实现了数据中心级的异构计算。这一"数据中心即计算机"的理念,深刻影响了后来 AI 集群的设计哲学。
下表系统对比了三者的核心差异:
| 维度 | HPC 高性能计算中心 | AI 计算中心 | 云数据中心 |
|---|---|---|---|
| 应用目标 | 国防科研、科学计算 | AI 大模型训练与推理 | 互联网服务、云计算 |
| 数据精度 | FP64 双精度 | FP16/BF16/FP8 混合精度 | INT32/FP32 |
| 计算特征 | 密集计算、高并行 | 密集计算、高并行 | 通用计算、高并发 |
| 通信模式 | 复杂多样、流量特征各异 | 规律性强、部分可与计算重叠 | 相对分散、东西向为主 |
| 存储模式 | 密集复杂 I/O | 密集 I/O、按迭代周期 | 分散/密集混合 |
| 典型规模 | 数万 CPU 核心 | 数千至数万 GPU/NPU | 数十万通用服务器 |
| 关键指标 | FLOPS(FP64) | FLOPS(FP16/FP8)+ 通信带宽 | QPS/TPS + 可用性 |
表 11-1:三类计算集群对比。
理解这些差异至关重要。AI 集群并非简单地在 HPC 集群上换一批 GPU——它需要围绕混合精度计算、规律性通信模式和周期性存储访问等特征进行全栈的专用化设计。从芯片架构(Tensor Core 针对矩阵乘法优化)、网络互连(NVLink 针对 All-Reduce 优化)、到存储系统(按迭代节奏预取数据)、再到软件栈(NCCL 针对 GPU 集体通信优化),每一层都需要为 AI 工作负载量身定制。
从历史演进来看,计算集群经历了四个时代:奠基时代(1945-1970) 以电子管和晶体管为核心器件,ENIAC、CDC 6600 等开创了集中式计算的先河;通用架构时代(1971-1995) 随着大规模集成电路爆发,Cray-1 等超算推动算力突破,个人电脑的普及让计算从专用走向通用;互联网云计算时代(1995-2020) 催生了数据中心形态,谷歌、Facebook 等公司将仓储级计算机的理念推向极致,云服务(IaaS/PaaS/SaaS)让算力成为按需获取的公共基础设施;AI 集群时代(2020-至今) 则因大模型训练的算力需求爆发,推动集群向集约化、异构化、全栈优化方向演进。今天的 AI 集群是这八十年计算基础设施演进的最新产物,但它也正在催生全新的设计范式——面向 AI 工作负载的"原生"基础设施,而非在传统架构上的改良。正如 1961 年 AI 之父 John McCarthy 所预言的:"算力服务将成为未来的公共基础设施",AI 集群正在让这一愿景以更极致的形式变为现实。
展望 2030 年,计算集群将呈现六大特征:柔性资源(全池化、柔计算、泛协作)、安全智慧(高安全、高可靠、高智能)、多样泛在(大集群、新形态、融算力)、对等互联(超融合、高性能、光内生)、负载亲和(大小芯、新算力、新存储)和零碳节能(绿供电、新风冷、新液冷)。
11.1.2 数据中心作为计算单元:规模阈值与架构挑战
在 CS336 课程中,Percy Liang 教授提出了一个发人深省的观点:当我们训练真正的大模型时,应该将整个数据中心视为一台计算机。这不仅是一种思维方式的转变,更反映了模型规模增长带来的工程范式迁移。

从参数规模的演进可以清晰看到这种转变的三个阶段:
- 万级参数时代(2015-2018):以 ResNet-50(2500 万参数)为代表,一张 GPU 卡提供的 TFLOPS 级算力就足以完成训练,训练时间在数小时到数天量级。
- 亿级参数时代(2018-2022):以 GPT-1(1.7 亿参数)到 GPT-3(1750 亿参数)为代表,需要单服务器 8 卡甚至多台服务器提供的 PFLOPS 级算力。计算需求相比上一时代增长了约 10 倍。
- 万亿参数时代(2023-至今):以 DeepSeek-V3(6710 亿参数)等为代表,训练已经需要整个 AI 集群的万卡规模提供 EFLOPS 级算力。计算需求相比亿级时代又增长了约 1000 倍。
这种规模跃迁引发了一个关键的 规模阈值(Scale Threshold) 问题。在典型的 GPU 集群中,硬件的连接结构并非同质,而是呈现出明显的层级特征:
- 节点内(Intra-node):8 张 GPU 通过 NVLink/NVSwitch 以数百 GB/s 的双向带宽实现全连接通信。NVSwitch 充当节点内的"全连接交换机",任意两张 GPU 之间可以无带宽衰减地直接通信。
- 机架内(Intra-rack):约 32 个节点(256 张 GPU)通过叶交换机(Leaf Switch)实现全带宽的 InfiniBand 互连。在这个范围内,跨节点通信虽然比节点内慢(约 50GB/s vs 数百 GB/s),但仍然是高带宽的。
- 跨机架(Inter-rack):当集群规模超过约 256 张 GPU 时,通信需要经过多层交换机(Leaf-Spine 架构甚至三层 Clos 网络)。每增加一层交换机,可用带宽就可能因为**超额订阅(Oversubscription)**而下降,延迟也会增加。
这种"近快远慢"的层级结构,在根本上决定了大规模训练的并行策略部署方式。正如第 10 章所讨论的:
- 张量并行(TP)在每一层都需要 All-Reduce 同步,通信频率极高、对带宽要求极强,因此通常限制在节点内 8 卡范围,利用 NVLink 的高带宽;
- 流水线并行(PP)只在 stage 边界传递激活值,通信量相对较小,适合部署在节点间较慢的连接上;
- 数据并行(DP/FSDP)通过 All-Reduce/Reduce-Scatter 同步梯度,通信量与参数量成正比,但可以与计算重叠,因此适合在所有剩余 GPU 上扩展吞吐量。
从更高的视角来看,在整个数据中心尺度上进行训练,本质上就是在不同层级的网络拓扑约束下,找到计算、通信和显存三者的最优平衡点。这也是为什么理解集群架构对于掌握分布式训练至关重要——并行策略的选择从来不是一个纯算法问题,而是一个深度耦合硬件拓扑的系统工程问题。
我们可以通过一个具体的例子来感受这种规模阈值的影响。假设我们要训练一个 700 亿参数的模型,使用 8 路张量并行 + 8 路流水线并行 + 数据并行的 3D 并行策略。张量并行需要 8 张 GPU 在节点内通过 NVLink 连接(带宽要求 > 300 GB/s),流水线并行需要 8 个节点通过 InfiniBand 连接(带宽要求约 50 GB/s),这就构成了一个 64 卡的"并行组"。如果我们有 1024 张 GPU,就可以运行 16 路数据并行,每路独立地通过 All-Reduce 同步梯度。这 1024 张 GPU 分布在约 128 台服务器上,占满 4 个机架——恰好在"全带宽"的阈值附近。一旦扩展到 2048 卡或更多,跨机架通信就会成为数据并行梯度同步的瓶颈,需要更精细的通信调度策略(如梯度压缩、异步通信等)来缓解。
值得一提的是,GPU 集群与 Google TPU 集群采用了截然不同的网络拓扑设计哲学。GPU 集群通常采用胖树/Clos 网络架构,在一定规模内(约 256 卡)提供任意设备间的全带宽通信,适合需要大量任意通信的张量并行,但超过阈值后跨机架带宽会显著下降。Google TPU 则采用**环形网格(Toroidal Mesh)**拓扑,每个 TPU 芯片只与在 2D/3D 网格中的直接邻居进行超高速点对点连接,不依赖中心化网络交换机,扩展到数万芯片时通信性能衰减较小,特别适合 Ring All-Reduce 等集体通信操作。这两种不同的硬件设计哲学,导致了在选择和组合并行策略时的不同考量和最佳实践。谷歌团队声称,由于 TPU 间的高速环形互联,他们可以减少对流水线并行的依赖,更多地采用张量并行和数据并行的组合。而 NVIDIA GPU 集群则通常需要在节点内使用张量并行、节点间使用流水线并行的混合策略来应对异构的网络带宽。
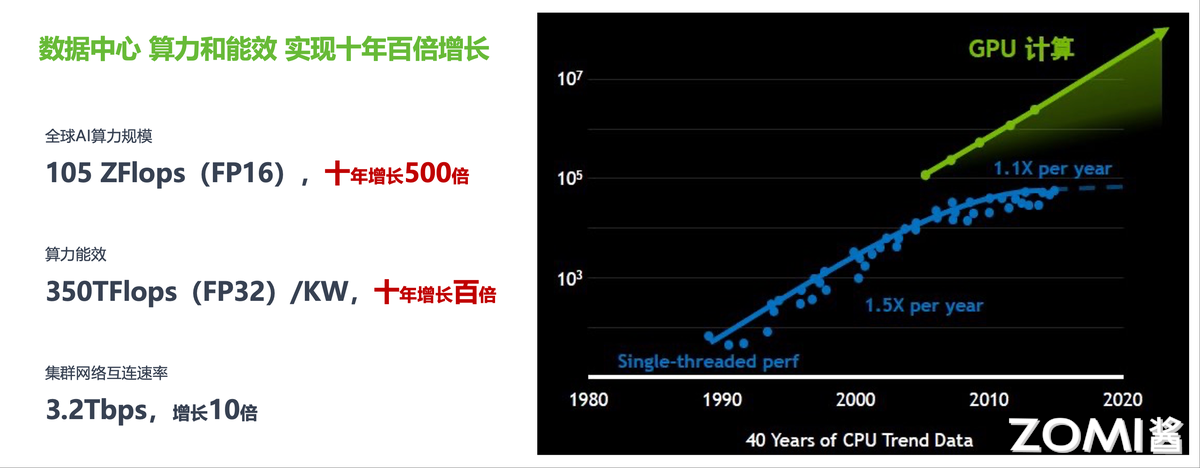
从数据中心的算力增长趋势来看,过去 40 年间 CPU 单线程性能增长已经从每年 1.5 倍放缓到每年 1.1 倍,但 GPU 计算带来了新的增长曲线。全球 AI 算力规模(FP16)已达 105 ZFlops,十年间增长了约 500 倍;算力能效达到 350 TFlops(FP32)/KW,十年间增长了约 100 倍;集群网络互连速率达到 3.2Tbps,十年间增长了约 10 倍。这三个指标共同描绘了数据中心作为"超级计算机"的能力演进轨迹。
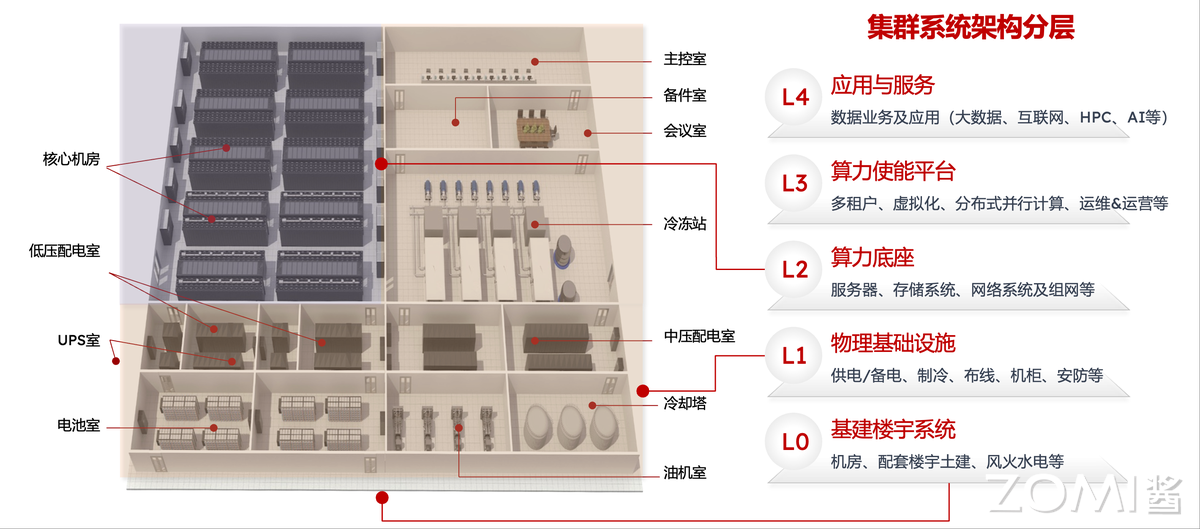
11.1.3 AI Infra 分层架构(L0-L4)
面对如此复杂的系统,我们需要一个清晰的分层框架来组织认知。业界通常将 AI 集群的基础设施划分为 L0 到 L4 五个层次,从物理基建到上层应用逐层递进。这个分层模型类似于计算机网络中的 OSI 七层模型——每一层有明确的职责边界,层与层之间通过标准化接口交互。
之所以需要这样的分层框架,是因为 AI 集群的复杂度已经远超任何单一团队所能掌控。建设一个万卡规模的 AI 集群涉及土建工程、电力工程、暖通工程、网络工程、服务器硬件、系统软件、分布式计算、AI 算法等至少八个专业领域的协作。分层架构让每个团队可以聚焦自己的专业域,同时通过明确的接口规范保证跨团队的协同效率。
L0:基建楼宇系统。 这是最底层的物理基础,包括机房选址与土建工程、供电系统(变电站、UPS 不间断电源、高低压配电柜)、制冷系统(冷冻水系统、冷却塔、精密空调)、消防与安防设施等。L0 层虽然距离 AI 算法最远,却直接决定了集群的总功率容量和能效水平。业界常用 PUE(Power Usage Effectiveness,电源使用效率)来衡量数据中心的能效:
理想值为 1.0(意味着所有电力都用于 IT 计算),但实际中制冷、供配电等辅助设施的能耗使 PUE 总是大于 1。传统风冷数据中心 PUE 通常在 1.3-1.5 之间,而先进的液冷 AI 集群可以将 PUE 控制在 1.04-1.1。
以 NVIDIA DGX H100 为例,单台 8 卡服务器的功耗约 10kW,一个万卡集群(约 1250 台服务器)的 IT 设备功耗就超过 12MW,加上制冷等辅助设施后总功耗可达 15-20MW——这相当于一座小型发电厂的输出,或约 2 万户家庭的用电量。选址时需要考虑电力供给是否充足、电价是否合理、气候条件是否有利于自然散热等因素。这也是为什么全球大型 AI 集群越来越多地建设在电力廉价、气候凉爽的地区(如北欧、中国西部)。
L1:物理基础设施。 包括供电/备电设备、制冷方案、布线系统(光纤/铜缆)、机柜布局与安防等。AI 集群与传统数据中心在 L1 层最大的差异在于功率密度。下表对比了两者的关键指标:
| 指标 | 传统云数据中心 | 新型 AI 智算中心 |
|---|---|---|
| 机房供电 | 8-12kW/柜 | 数十到数百 kW/柜 |
| 机房制冷 | 风冷 + 列间空调 | 液冷 + 风液混合部署 |
| 网络布线 | 管理 + 业务 + 数据 三平面 | 管理 + 业务 + 参数 + 数据 四平面 |
| 运维管理 | 分散管理 | 智能统一管理 |
表 11-2:传统云数据中心与 AI 智算中心 L1 层对比。
传统云数据中心单机柜功率通常为 8-12kW,风冷足以应对;而 AI 智算中心的单机柜功率已飙升至 20-60kW 甚至更高(如 NVIDIA GB200 NVL72 超节点单柜功率可达 120kW),如此高的功率密度使得传统风冷散热方案力不从心,液冷技术(冷板液冷和浸没式液冷)已成为 AI 集群的标配。此外,AI 集群的布线复杂度也远超传统数据中心——除了管理网络和业务网络外,还需要独立的高速计算网络(InfiniBand/RoCE)用于 GPU 间通信,以及参数同步网络,形成"四网分离"的布线格局,万卡集群需要铺设数万根光纤。
L2:算力底座。 这是集群的核心计算层,包含三大子系统:
- 计算子系统:AI 服务器通常配备 8 张高端 GPU/NPU(如 NVIDIA H100/H200、华为昇腾 910B),通过 NVLink 实现卡间高速互连。CPU(如 AMD EPYC、Intel Xeon、NVIDIA Grace)作为主机端处理器负责数据预处理、任务调度和系统管理。以 NVIDIA DGX H100 为例,单节点配备 8 张 H100 GPU(总计 640GB HBM3 显存),通过第四代 NVSwitch 实现 900GB/s 的全连接互连。
- 网络子系统:高速计算网络是 AI 集群的"血管系统"。当前主流方案为 InfiniBand(NDR 400Gbps 单端口带宽、<1μs 延迟),由 NVIDIA(前 Mellanox)主导。国内厂商则积极发展基于 RoCE v2 + 智能网卡(DPU/IPU)的以太网方案作为替代路径,以突破 InfiniBand 的供应链垄断。网络拓扑通常采用 Fat-Tree(胖树)或 Dragonfly(蜻蜓)架构,在带宽、延迟和成本之间取得平衡。
- 存储子系统:训练数据的加载、checkpoint 的保存和模型参数的读写都依赖高性能存储。分布式并行文件系统(如 Lustre、GPFS、BeeGFS)和全闪存储方案是主流选择。存储系统需要提供 TB/s 级的聚合吞吐量,以确保数千张 GPU 在数据加载阶段不会因存储瓶颈而空闲。
一次典型的训练迭代中,数据在 L2 层的三个子系统间流动的路径如下:存储系统将训练数据(如 Token 化后的文本序列)通过网络加载到各计算节点的 CPU 内存;CPU 完成数据预处理后将 mini-batch 传输到 GPU 显存;GPU 执行前向传播和反向传播,产生梯度;梯度通过高速计算网络在 GPU 间进行 All-Reduce 同步;同步后的梯度用于更新本地参数;每隔数千步,模型参数通过网络写回存储系统作为 checkpoint。理解这个数据流对于定位性能瓶颈至关重要。
L3:算力使能平台。 这一层负责将底层硬件资源转化为可用的计算服务,是连接硬件与应用的软件桥梁。包括:
- 异构计算架构:NVIDIA CUDA 及其配套库(cuDNN、cuBLAS、cuFFT、NCCL)提供 GPU 的编程接口和高度优化的算子库。华为 Ascend CANN 为昇腾 NPU 提供了对应的异构计算架构。
- 操作系统与驱动:Ubuntu、openEuler 等 Linux 发行版提供底层系统支持,GPU 驱动和 CUDA Toolkit 提供硬件抽象层。
- 容器与集群调度:Kubernetes (K8s) 配合 GPU Device Plugin 和 Volcano 等批处理调度插件,实现计算资源的弹性调度与作业管理。Slurm 在超算场景中仍是主流调度器,全球 TOP500 超算中约 60% 使用 Slurm。
- 分布式训练框架:PyTorch (DDP/FSDP)、Megatron-LM、DeepSpeed 等框架封装了第 10 章所讨论的各种并行策略,用户通过相对简洁的配置即可实现多维并行训练。
- 推理服务框架:vLLM、SGLang、TensorRT-LLM 等负责模型的高效推理部署,通过 PagedAttention、连续批处理等技术最大化推理吞吐。
L4:应用与服务。 最上层是面向用户的 AI 应用和服务,包括大语言模型(LLM)、图像生成模型、多模态大模型等。这一层还包括性能分析与开发调试工具:NVIDIA Nsight Systems 用于可视化分析 GPU 利用率、通信开销和内核执行时间线;NVIDIA Nsight Compute 深入分析单个 CUDA 内核的性能指标;华为 MindStudio 为昇腾生态提供对应的开发和调试环境。这些工具是定位训练和推理中性能瓶颈的"显微镜"——例如,通过 Nsight Systems 的时间线视图,工程师可以直观看到 GPU 计算和通信之间是否存在不必要的等待,从而针对性地优化并行策略。
下图展示了 L0-L4 各层的详细技术组件:

分层架构的核心价值在于关注点分离:硬件工程师专注于 L0-L2 的设计与运维,系统软件工程师负责 L3 的框架开发与调优,算法研究员在 L4 层设计模型和训练策略。但同时需要注意,真实的 AI 集群性能优化往往需要跨层协同——例如,通信拓扑的选择(L2)会影响并行策略的配置(L3),功率预算(L1)会限制集群的最大规模(L2),GPU 的 Tensor Core 架构(L2)决定了最优的数值精度格式(L4)。这种全栈优化的思维是 AI Infra 区别于传统 IT 基础设施的关键特征。
传统数据中心的建设思路是分层堆叠——先把每层做好,再拼在一起。但 AI 集群要求的是全栈协同设计——从芯片架构到网络拓扑到软件栈,每一层的设计都需要考虑对其他层的影响。例如,NVIDIA 的 SuperPOD 解决方案就是这种全栈思维的产物:它预定义了从 GPU 服务器(L2)到 InfiniBand 网络拓扑(L2)到液冷散热(L1)到机房布局(L0)的完整规格,确保各层之间的最优匹配。华为昇腾 384 超节点也是类似思路,将 12 个计算柜和 4 个总线柜组成一个紧耦合的计算单元,384 颗昇腾 NPU 通过 MatrixLink 互联,实现 300 PFLOPS 的峰值算力。
11.1.4 硬件趋势:处理器、网络、存储与散热
AI 集群的硬件演进围绕 性能突破、能效优化、场景适配 三条主线展开。过去十年间,AI 算力的增长速度远超摩尔定律的预测:GPU 的 AI 算力(以 FP16 TFLOPS 计)平均每 2 年增长约 4 倍,而传统 CPU 性能每 2 年仅增长约 1.5 倍。这种"超摩尔定律"的增速主要来自架构创新(Tensor Core)、先进制程和封装技术的叠加效应。下面从处理器、网络、存储和散热四个方向梳理关键趋势。
算力衡量单位简注:HPC 场景以 FP64 FLOPS 为主要衡量指标,AI 场景则以 FP16/BF16/FP8 FLOPS 为主。常见数量级包括 TFLOPS(
)、PFLOPS( )、EFLOPS( )。例如,单张 H100 的 FP16 算力约 2 PFLOPS,一个万卡集群的聚合 FP16 算力约 20 EFLOPS。
处理器:从通用 CPU 到异构加速。 传统 HPC 依赖 CPU 集群,通过"提升主频、增加核心数、优化指令集"三条路径提升算力。其中主频提升遵循了近 30 年的"登纳德缩放定律"(Dennard Scaling)——晶体管尺寸缩小时功率密度保持恒定。但到了 2000 年代初,CPU 主频在试图突破 4GHz 时撞上了功耗墙——Intel Prescott 核心在 90nm 工艺下功耗突破 100W,出现了"高频低效"问题,单纯的频率提升不再可行。此后 CPU 转向多核架构,如今 AMD EPYC 9004 系列已达 96 核,Intel Xeon Platinum 达 64 核。
但对于 AI 训练而言,CPU 的通用架构本身就不是最优选择。2010 年后,GPU 的大规模并行架构被证明更适合矩阵运算密集的深度学习任务——一张现代 GPU 拥有数千个计算核心,虽然单核性能远不如 CPU,但在大量数据并行的矩阵乘法中可以实现远超 CPU 的吞吐量。NVIDIA 从 Tesla 架构(2006)起步,到 Volta 架构(2017)引入了革命性的 Tensor Core(专门为矩阵乘加运算设计的硬件单元,每个时钟周期可完成一个 4x4 矩阵乘加),此后 Ampere(2020)、Hopper(2022)、Blackwell(2024)持续迭代。以 Hopper 架构的 H100 为标杆:FP16 算力达 1979 TFLOPS,显存带宽 3.35TB/s,相比上一代 A100 提升约 3 倍。
下表展示了 NVIDIA GPU 架构的代际演进,可以直观感受算力提升的速度:
| 架构 | 代表型号 | 发布年份 | FP16 算力 | 显存 | 显存带宽 | TDP |
|---|---|---|---|---|---|---|
| Pascal | P100 | 2016 | 21.2 TFLOPS | 16GB HBM2 | 732 GB/s | 250W |
| Volta | V100 | 2017 | 125 TFLOPS | 32GB HBM2 | 900 GB/s | 300W |
| Ampere | A100 | 2020 | 312 TFLOPS | 80GB HBM2e | 2.0 TB/s | 400W |
| Hopper | H100 | 2022 | 1979 TFLOPS | 80GB HBM3 | 3.35 TB/s | 700W |
表 11-3:NVIDIA GPU 架构代际演进(FP16 含 Tensor Core 算力)。
从 P100 到 H100,FP16 算力提升了约 93 倍,而 TDP 仅增长了 2.8 倍,单位功耗算力提升了约 33 倍——这正是 Tensor Core 架构创新带来的能效红利。表中 Volta 架构引入的 Tensor Core 是一个分水岭:它专门为矩阵乘加(MMA)运算设计了硬件单元,使得 FP16 算力相比 Pascal 架构一举提升了近 6 倍。这也解释了为什么 AI 训练几乎全面拥抱了混合精度——硬件为此提供了巨大的性能激励。
与此同时,ARM 架构凭借低功耗和高能效比在服务器领域崛起。NVIDIA Grace CPU 基于 ARMv9 指令集,通过 NVLink-C2C 直连 GPU,消除了传统 PCIe 的带宽瓶颈。华为鲲鹏 920 基于 ARMv8.2 架构,为昇腾 AI 集群提供了国产主机处理器。Chiplet(小芯粒)封装技术将不同功能的裸片(如计算核心、缓存、I/O 控制器)用适配的工艺分别制造再封装集成,突破了单芯片面积的物理限制。例如,计算核心可以用最先进的 5nm 工艺追求性能,而 I/O 控制器用成熟的 12nm 工艺降低成本,两者通过先进封装(如台积电 CoWoS、Intel EMIB)集成在一起。AMD EPYC 和 Intel Xeon 已普遍采用这一技术,NVIDIA 的 Blackwell 架构 B200 更是将两个 GPU 裸片通过 10TB/s 的芯片间互连封装为一个统一的处理器。
网络:从降低延迟到极致带宽。 AI 集群的网络需求远超传统数据中心。GPU 间通信的带宽决定了并行效率的上限。节点内,NVIDIA NVLink 已发展到第四代(NVLink 4.0),8 卡间通过 NVSwitch 实现每个方向 900GB/s 的双向带宽。节点间,InfiniBand NDR 提供 400Gbps(约 50GB/s)的单端口速率,下一代 XDR 将达到 800Gbps。NVIDIA 还推出了 NVLink Network(前身为 NVLink Switch),将 NVLink 的高带宽从节点内扩展到跨节点甚至跨机架,实现更大范围的高速互连。
国内厂商则积极发展基于 RoCE v2(RDMA over Converged Ethernet)+ 智能网卡(DPU/IPU)的以太网方案。RoCE v2 在标准以太网基础上实现 RDMA(远程直接内存访问),延迟约 10-20μs,虽不及 InfiniBand 的亚微秒级,但成本更低且兼容现有以太网基础设施。华为还自主研发了灵渠总线,专为 CPU-NPU、NPU-NPU 通信优化。更长远来看,硅光子技术(Silicon Photonics)有望以光信号替代铜缆传输,Intel 已展示了 4Tbps 双向全集成光连接小芯片,能效低于 3pJ/bit,覆盖范围超 100 米。
存储:从容量扩展到存算协同。 AI 训练对存储系统的要求可归纳为"大、快、稳"三个字:训练数据集通常为 TB 到 PB 级别(大),数据加载速度要跟上 GPU 的消费速率以避免 GPU 空转(快),checkpoint 写入在万卡规模的集群中必须可靠完成、不能丢失训练进度(稳)。
在芯片级存储方面,传统的 GDDR 显存因带宽有限已无法满足 AI 加速芯片的需求。HBM(High Bandwidth Memory,高带宽内存)应运而生,它通过硅通孔(TSV, Through Silicon Via)垂直堆叠多层 DRAM Die 并与 GPU/NPU 进行封装集成,利用极宽的总线位宽实现 TB/s 级的显存带宽。HBM 的发展历程清晰地展示了存储技术如何被 AI 需求驱动:
- HBM1(2013,SK 海力士):4 层堆叠,128GB/s 带宽
- HBM2(2016):8 层堆叠,256GB/s 带宽,用于 NVIDIA V100
- HBM2e(2020):8 层堆叠,460GB/s 带宽,用于 NVIDIA A100
- HBM3(2022):12 层堆叠,819GB/s 带宽,用于 NVIDIA H100
NVIDIA H100 配备 80GB HBM3 显存,聚合带宽达 3.35TB/s。下一代 HBM3e 带宽将突破 1TB/s,HBM4 还将进一步优化 3D 堆叠工艺。
在集群级存储方面,分布式并行文件系统是主流方案。Lustre 仍是超算领域的主力,支持 EB 级容量和 TB/s 级聚合带宽,全球 Top 100 超算中约 70% 使用 Lustre。Ceph 和 GlusterFS 作为 Red Hat 旗下的开源存储方案,也在中小规模集群中广泛部署。值得关注的新兴力量是 DeepSeek 开源的 3FS(Fire-Flyer File System),它基于 RDMA 网络和 NVMe SSD,利用 RDMA 绕过 CPU 直接读取远端存储数据的特性,在 180 个存储节点上实现了 6.6TiB/s 的惊人吞吐,客户端节点 KV Cache 查找峰值吞吐量超过 40GiB/s,为大规模 MoE 模型训练和推理提供了高效的数据加载能力。
散热:从风冷到液冷的必然转型。 GPU 芯片的 TDP(Thermal Design Power,热设计功耗)从 2016 年 P100 的 250W 飙升到 H100 的 700W,下一代 B200 更高。单机柜的平均功率密度从 2016 年的 3-4kW 跃升到 2022-2025 年的 20-60kW。传统风冷方案在功率密度超过 15kW/柜时就已力不从心(PUE > 1.5),而 AI 集群要求 PUE 尽可能接近 1.0。散热不仅仅是一个"配套"问题——芯片温度每降低 5-10°C,器件失效率就能下降约 xx%,直接影响万卡集群的稳定训练能力。
当前主流的液冷方案有两种:
- 冷板液冷(Cold Plate Liquid Cooling):通过紧贴芯片表面的液冷板将热量传递给循环冷却液,液冷管路与服务器主板不直接接触,对现有服务器改动较小,部署成本相对可控。曙光数创 C8000 系列 PUE 可低至 1.04。
- 浸没式液冷(Immersion Cooling):将整个服务器主板直接浸入绝缘冷却液(如氟化液)中,散热效率比风冷高约 1000 倍,且完全无噪音。分为单相浸没(冷却液不发生相变)和相变浸没(冷却液蒸发吸热后冷凝回流)两种。阿里云"麒麟"系统采用此技术,PUE 约 1.09,节省 75% 的物理空间。
全球能效法规趋严(如欧盟 2030 年要求 PUE 不超过 1.3,中国"东数西算"枢纽节点 PUE 不超过 1.3),液冷已从"可选项"变为"必选项"。以一个万卡 H100 集群为例,若采用传统风冷(PUE 约 1.5),制冷本身就需要消耗约 6MW 的电力;若升级为冷板液冷(PUE 约 1.1),制冷功耗降至约 1.2MW,每年可节省近 4000 万度电——这既是经济问题,也是可持续发展的问题。
11.1.5 软件趋势:从碎片化到全栈统一
AI 集群的软件栈同样在经历深刻的变革。如果说硬件决定了集群的"天花板",软件则决定了能触达天花板的多少比例。当前 AI 集群的一个突出矛盾是:硬件的多样化(NVIDIA GPU、AMD GPU、Google TPU、华为昇腾、Intel Gaudi 等)使得软件生态面临严重的碎片化挑战——为一种硬件编写的优化代码往往无法移植到另一种硬件上。行业正努力通过标准化和抽象化来应对这一困境。
编译器与算子库:异构编程生态的竞争。 NVIDIA CUDA 凭借 2007 年的先发优势和长达十余年的持续投入,建立了包括 cuDNN(深度学习算子库)、cuBLAS(矩阵运算库)、cuFFT(快速傅里叶变换库)、NCCL(集体通信库)等在内的完整工具链,形成了强大的生态壁垒。但"一家独大"带来了厂商锁定问题。为打破这一垄断,多条技术路线并行发展:
- oneAPI/SYCL:Intel 发起的开放编程模型,基于 C++ 标准的 SYCL 语言实现跨 CPU、GPU、FPGA 等硬件的统一编程;
- MLIR(Multi-Level Intermediate Representation):Google 2018 年开源的多层中间表示框架,通过层次化的 IR 设计实现从高级语言到底层硬件指令的逐步转换,支持自定义方言适配不同硬件后端;
- Triton:OpenAI 主导的开源 GPU 编程语言,让开发者仅用不到 25 行 Python 代码就能编写出性能媲美 cuBLAS 的矩阵乘法内核,大幅降低 GPU 编程门槛;
- 华为毕昇编译器 + CANN:基于 LLVM 框架为鲲鹏 CPU 和昇腾 NPU 提供国产异构编程方案,支持自动向量化和跨算力融合编译。毕昇 C++ 语言还实现了鲲鹏与昇腾 AI 算力的协同编程,让开发者用一种语言即可对多样性算力编程。
这些技术路线之间并非完全对立,而是呈现出一定的融合趋势。例如,Triton 底层可以通过 MLIR 生成不同硬件后端的代码;oneAPI 的 DPC++ 编译器也支持 NVIDIA GPU 作为后端目标。长期来看,AI 编译器的发展方向是"高层语言统一 + 底层后端多样",让开发者用一套代码在多种硬件上获得接近手写优化的性能。
分布式训练框架:从手工并行到自动化。 早期的分布式训练需要用户手动编写 MPI 通信代码、管理 GPU 显存分配和进程同步,工程门槛极高。如今,PyTorch FSDP、Megatron-LM、DeepSpeed 等框架已将数据并行、张量并行、流水线并行等策略封装为高层 API。以 DeepSpeed 的 ZeRO 系列为例,用户只需在配置文件中指定 "zero_optimization": {"stage": 3} 就能将优化器状态、梯度和参数进行分片,将显存占用降低到原来的 1/N(N 为 GPU 数量),而通信开销几乎与朴素数据并行相当。Megatron-LM 则专注于张量并行和流水线并行的高效实现,通过精心设计的通信-计算重叠策略,在千卡规模上实现了接近线性的扩展效率。未来的趋势是更高程度的自动化——根据模型结构、集群拓扑和显存约束自动搜索最优的并行配置,让用户只需定义模型和数据,系统自动处理所有分布式训练的复杂性。
集群调度系统:从 HPC 到云原生的融合。 传统 HPC 以 Slurm 为主流调度器,它通过全局资源视图和作业队列实现高效的批处理调度,支持网络拓扑感知的任务分配(如希尔伯特曲线调度或胖树拓扑的最佳拟合算法),能够将通信密集的 GPU 进程分配到网络距离最近的节点上。云原生阵营则以 Kubernetes 为核心,通过 Device Plugin 机制将 GPU、FPGA 等异构设备纳入统一的资源管理框架,支持秒级的容器化部署和弹性伸缩。
两种调度范式各有优劣:Slurm 擅长大规模批处理作业的高效调度和拓扑感知放置,但缺乏弹性伸缩和微服务编排能力;K8s 擅长容器化工作负载的灵活管理,但原生缺乏对批处理作业(如 gang scheduling——要求一组 Pod 同时启动或全部不启动)的支持。当前的趋势是两者融合——Volcano 和 Kueue 等项目将 HPC 的批处理调度能力、公平共享和抢占式调度引入 K8s 生态,而 Slurm 也在适配容器化工作负载和云环境部署。
通信库与中间件:多协议协同。 底层通信已从 MPI(Message Passing Interface)一统天下演变为多协议共存的格局:
- NCCL(NVIDIA Collective Communications Library):GPU 集群通信的事实标准,针对 NVLink、NVSwitch 和 InfiniBand 等硬件深度优化了 All-Reduce、All-Gather、Reduce-Scatter 等集体通信原语。PyTorch 的
torch.distributed后端默认使用 NCCL。 - UCX(Unified Communication X):高性能开源通信库,提供跨 RDMA、TCP、GPU、共享内存等传输层的统一 API,底层 UCT 层适配多种通信设备,上层 UCP 层封装 Active Message、RMA、Tag Matching 等抽象通信接口。
- MPI(如 Open MPI、Intel MPI):HPC 领域的经典通信标准,支持点对点和集体通信,仍在科学计算场景广泛使用。
- RDMA:通过 InfiniBand 或 RoCE 实现的远程直接内存访问技术,绕过操作系统协议栈和 CPU,实现微秒级延迟和极高吞吐量。
- HCCL:华为为昇腾 NPU 集群开发的集体通信库,功能对标 NCCL。
存储系统软件:智能化与分级化。 训练数据的管理正变得越来越智能。基于机器学习的 I/O 预测可以提前预取即将被访问的数据块,减少 GPU 等待存储的空闲时间——例如,在 epoch 切换时提前将下一个 epoch 的数据从分布式存储预加载到本地 NVMe SSD 缓存中。冷热数据分级存储根据访问频率将数据自动在 NVMe SSD(热数据,如当前训练集的活跃分片)、SATA SSD(温数据,如近期的 checkpoint)和 HDD/磁带库(冷数据,如历史 checkpoint 和归档数据集)之间迁移,在性能与成本之间取得平衡。CXL(Compute Express Link)3.0 协议则有望实现跨 CPU/GPU/FPGA 的内存资源池化,打破传统"内存墙"限制,让不同处理器可以动态共享存储级内存(SCM)资源。
完整的训练工作流视角。 将以上五个方向串联起来,一次典型的大规模训练任务的软件流程如下:
- 作业提交与调度:用户通过 Slurm 或 K8s 提交训练作业,指定所需的 GPU 数量、内存、训练时长等资源需求。调度系统根据集群拓扑和资源可用性分配节点,尽量将通信密集的进程放置在网络距离最近的节点上。
- 环境初始化:训练框架(Megatron-LM/DeepSpeed)在分配到的节点上初始化进程组,根据集群拓扑配置 3D 并行策略,建立 NCCL 通信上下文。
- 数据加载:DataLoader 从分布式存储系统异步读取训练数据,经过 CPU 预处理(Token 化、填充、打包等)后传输到 GPU 显存。
- 前向与反向传播:异构计算架构(CUDA/CANN)调用 Tensor Core 等高度优化的硬件单元执行矩阵乘法、注意力计算等核心操作。
- 梯度同步:底层通信库(NCCL/HCCL)通过 RDMA 网络执行 All-Reduce/Reduce-Scatter 等集体通信操作,同步各 GPU 上的梯度。
- 参数更新与 checkpoint:优化器更新模型参数;每隔数千步,模型状态异步写入分布式存储作为 checkpoint。
这个流程中任何一个环节的低效都会导致整体吞吐量下降。例如,数据加载速度跟不上 GPU 消费速率会造成 GPU 空闲(数据饥饿),通信延迟过高会降低并行效率,checkpoint 写入时间过长会阻塞训练进度。因此全栈软件的协同优化至关重要。
11.1.6 小结
本节围绕"计算集群架构"这一主题,建立了理解 AI Infra 的基本框架。以下是五个核心要点:
- 三类集群各有侧重:HPC 追求 FP64 极致精度和灵活通信,AI 集群围绕混合精度和规律性通信进行全栈专用化设计,云数据中心面向通用高并发服务。AI 集群不是"加了 GPU 的 HPC",它在计算精度、通信模式、存储访问等维度都有独特的需求。
- 数据中心即计算机:万亿参数时代的训练需要将整个数据中心作为计算单元来思考和设计。节点内(NVLink 高速互连)、机架内(全带宽 InfiniBand)、跨机架(带宽可能超额订阅)的网络层级结构,决定了张量并行(节点内)、流水线并行(节点间)和数据并行(全局)的部署方式。
- L0-L4 分层架构:从基建楼宇(L0)、物理基础设施(L1)、算力底座(L2)、算力使能平台(L3)到应用与服务(L4),五层架构实现关注点分离,但真正的性能优化需要跨层协同——全栈思维是 AI Infra 工程师的核心素养。
- 硬件四大趋势:处理器走向异构加速(GPU + Tensor Core + Chiplet),网络追求极致带宽(NVLink + InfiniBand + 硅光互连),存储实现存算协同(HBM + NVMe + RDMA 文件系统),散热从风冷全面转向液冷。
- 软件五大趋势:编译器生态打破 CUDA 垄断(MLIR/Triton/oneAPI),训练框架走向自动化并行配置,调度系统 HPC 与云原生融合(Slurm + K8s),通信库多协议协同(NCCL + UCX + RDMA),存储系统走向智能预取与冷热分级。
回顾全节内容,一个有用的思维模型是将 AI 集群类比为一个"超级处理器":GPU 是它的运算核心,NVLink/InfiniBand 是它的总线,分布式存储是它的内存层次,K8s/Slurm 是它的操作系统,PyTorch/Megatron-LM 是它的编程语言。与单机处理器一样,这个"超级处理器"的性能瓶颈往往不在运算核心本身,而在于数据搬运——GPU 的算力增长速度远超网络带宽和存储吞吐的增长速度,这就是 AI 集群版本的"内存墙"问题。理解并解决这个问题,是后续章节的核心主题。
在后续章节中,我们将深入每一层的关键技术。§11.2 将聚焦网络互连与通信拓扑,详细分析 InfiniBand、NVLink、RoCE 等技术的原理与性能特征,以及 Fat-Tree、Dragonfly 等网络拓扑对分布式训练的影响。§11.3 将讨论集群存储系统的设计,包括分布式文件系统、全闪存储和训练数据管线的优化。§11.4 将探讨集群调度与资源管理,涵盖 Slurm 和 Kubernetes 在 AI 训练场景下的最佳实践。这些章节将把本节建立的宏观框架逐步细化为可操作的工程知识。