19.2 KV Cache 系统化管理
在 §6.1 中,我们从零实现了 KV Cache 的基础张量结构——将每一层的 Key 和 Value 缓存下来,供 Decode 阶段逐 Token 复用。那种实现方式概念清晰,但在真实的推理引擎中远远不够。当数十乃至数百个请求并发到达、每个请求的序列长度各不相同且不可预知时,如何在 GPU 显存中高效地分配、回收和共享 KV Cache,就成了决定系统吞吐量的关键问题。
本节将从推理引擎的视角出发,讨论 KV Cache 管理面临的核心挑战,然后深入介绍 PagedAttention 这一里程碑式的解决方案,最后简述 KV Cache 量化压缩和前缀共享等互补技术。
19.2.1 KV Cache 的显存困境
KV Cache 的显存占用与序列长度呈线性增长。回顾 §19.1 中给出的显存公式:
其中

图 19-3:典型推理场景下 GPU 显存的分配情况。模型参数占据约 65% 的显存,KV Cache 占比超过 30%,是仅次于模型权重的最大显存消耗者。
然而显存总量只是问题的一面。更棘手的是显存碎片化。传统推理框架对 KV Cache 采用连续内存静态预分配:为每个请求预留一块 [max_seq_len, hidden_dim] 大小的连续显存。这种方式会造成三种浪费:

图 19-4:连续内存分配的三类浪费。Internal Fragmentation(内部碎片):实际序列远短于预留长度,大量槽位永远不会被使用。External Fragmentation(外部碎片):不同请求之间的空闲内存碎片无法被新请求利用。Reserved(预留):为尚未生成的 Token 提前占位。
- 内部碎片(Internal Fragmentation)。预留的最大序列长度(如 2048)与实际使用长度(如 150)之间的差距全部浪费。研究表明,这种浪费在真实工作负载中可达 60%--80%。
- 外部碎片(External Fragmentation)。频繁分配和释放不同大小的连续块后,空闲显存变成无法拼合的小碎片。
- 预留浪费(Reserved)。输出长度不可预知,系统被迫按最坏情况预留,实际大部分空间空置。
这三重浪费使得同一块 GPU 能同时服务的请求数远低于理论上限,系统吞吐量被严重拖累。
19.2.2 PagedAttention:虚拟化 KV Cache 管理
PagedAttention 是 vLLM 项目提出的 KV Cache 管理算法,其核心灵感来自操作系统的虚拟内存与分页机制。它彻底抛弃了"每个请求占用一块连续显存"的假设,转而将 KV Cache 拆分为固定大小的物理块(Physical Block),通过块表(Block Table) 维护逻辑地址到物理地址的映射——正如操作系统用页表管理进程的虚拟地址空间一样。
核心类比。 下表对照了操作系统虚拟内存与 PagedAttention 的关键概念:
| 操作系统概念 | PagedAttention 对应 |
|---|---|
| 进程 | 推理请求(Request) |
| 虚拟页面 | 逻辑块(Logical Block) |
| 物理页面 | 物理块(Physical Block) |
| 页表 | 块表(Block Table) |
| 页面大小 | 块大小(Block Size,如 16 Token) |
| 换入/换出(Swap) | GPU-CPU 间 KV Cache 搬运 |
| 写时复制(CoW) | 共享前缀的延迟复制 |
块划分与块表映射
PagedAttention 将 GPU 显存中的 KV Cache 区域划分为大量等大的物理块,每个物理块可存放固定数量 Token 的 Key 和 Value 向量(典型值为 16 或 32 个 Token)。所有物理块由一个全局的块管理器(Block Manager) 统一管理,类似操作系统的物理内存分配器。
每个推理请求拥有独立的块表,将该请求的逻辑块(按 Token 顺序编号)映射到实际的物理块。逻辑块 0 对应序列最前面的若干 Token,逻辑块 1 对应接下来的 Token,以此类推。关键在于:逻辑上连续的块,在物理显存中可以完全不连续。
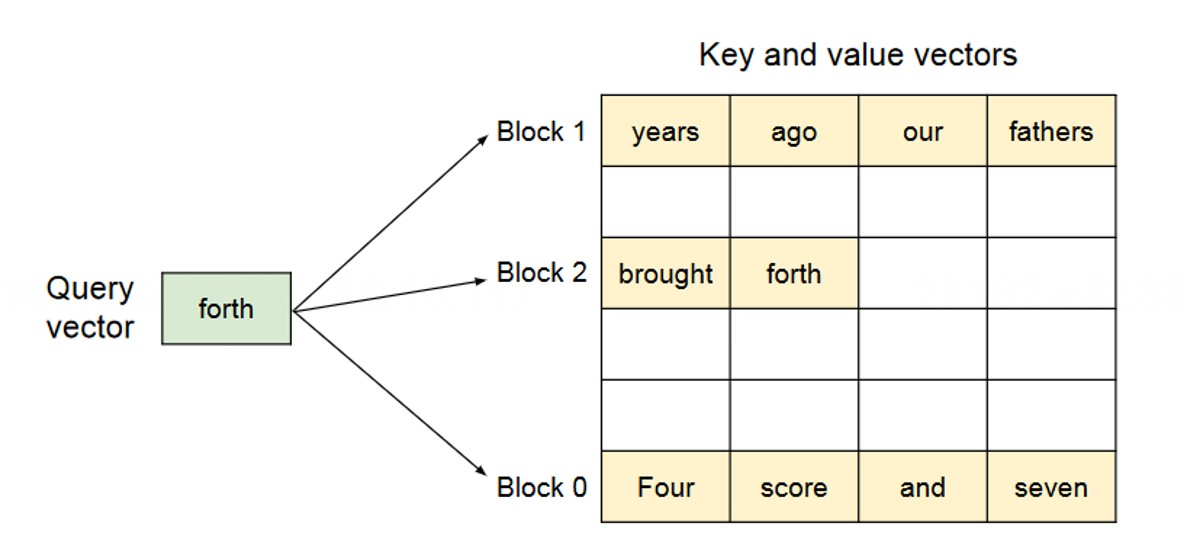
图 19-5:PagedAttention 的注意力计算示意。Query 向量需要与散落在不同物理块中的 Key/Value 进行注意力运算。通过块表查找物理块位置,算子按块迭代计算并累加结果。
单请求的完整生命周期
以一个包含 prompt "Four score and seven years ago our" 的请求为例,完整流程如下:
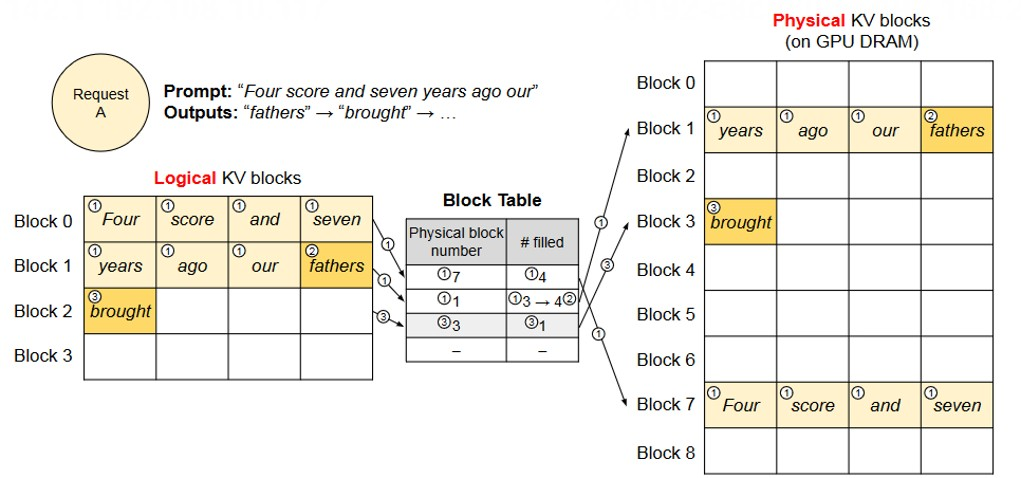
图 19-6:PagedAttention 处理单个请求的过程。左侧为逻辑块视图,中间为块表,右侧为物理块在 GPU 显存中的实际位置。
- Prefill 阶段:将 prompt 的 Token 按块大小(此例为 4)划分为逻辑块 0、1。块管理器分配两个物理块(如物理块 7 和物理块 1),块表记录映射关系和每个物理块的填充量(
# filled)。 - Decode 阶段:模型生成第一个新 Token "fathers",其 KV 向量追加到逻辑块 1 对应的物理块中(物理块 1 仍有空闲槽位)。当物理块被填满后,生成下一个 Token "brought" 时,块管理器分配新的物理块(如物理块 3),块表增加一条新映射。
- 请求完成:生成结束后,该请求占用的所有物理块被立即释放回空闲池,供新请求复用。
多请求并发
当多个请求同时在系统中运行时,每个请求的块表独立管理,物理块在显存中交叉分布:
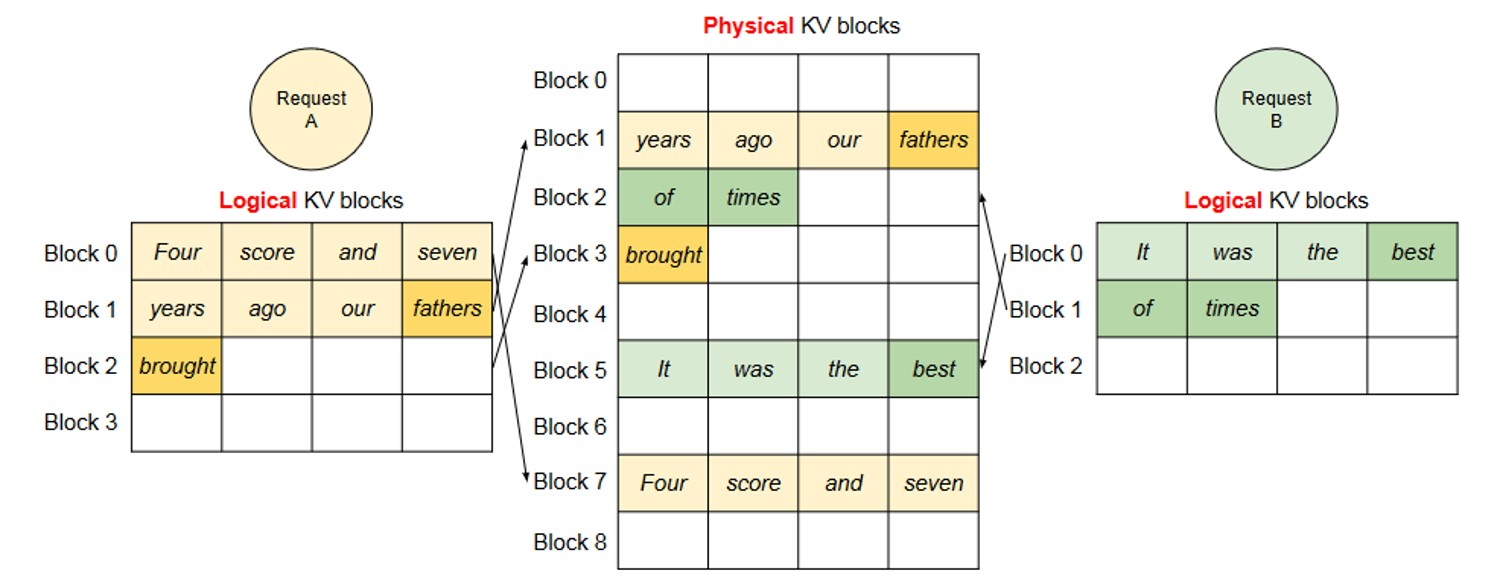
图 19-7:两个请求的物理块交叉存储。Request A 和 Request B 的逻辑块分别映射到不同的物理块,互不干扰。请求结束后物理块回收,零碎片。
这种设计从根本上消除了外部碎片——只要总空闲物理块数量够用,新请求就能被接纳,不存在"空闲显存足够但找不到连续大块"的问题。内部碎片也被大幅降低——只有每个请求的最后一个物理块可能有少量空闲槽位(最多 block_size - 1 个)。
写时复制与前缀共享
在并行采样(Parallel Sampling)等场景中,同一个 prompt 会产生多个输出序列。这些序列共享完全相同的 prompt KV Cache,传统方案需要为每个序列复制一份,而 PagedAttention 通过写时复制(Copy-on-Write, CoW) 实现零开销共享:
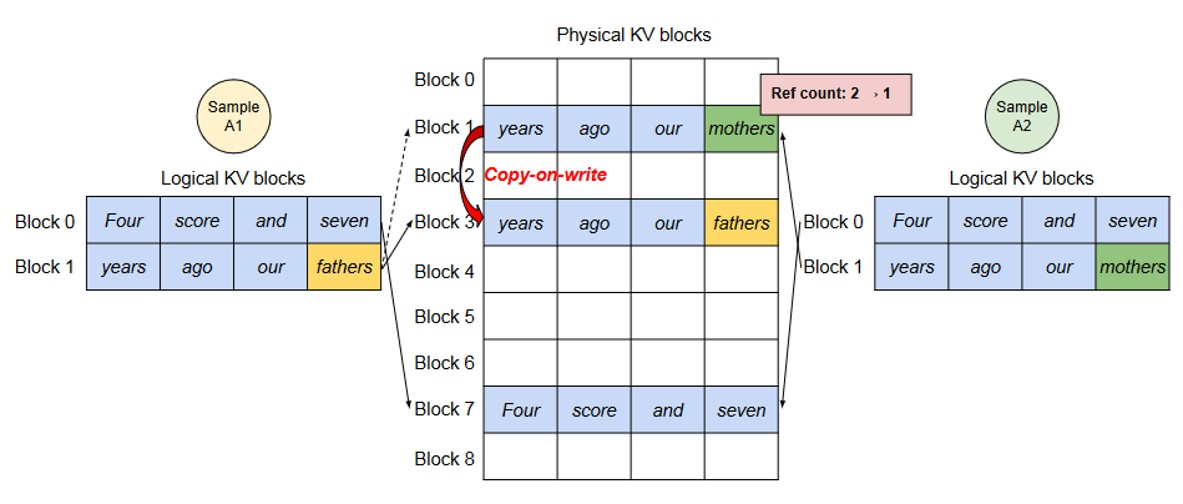
图 19-8:写时复制示意。Sample A1 和 A2 共享 prompt 部分的物理块(引用计数 = 2)。当 A1 需要向共享块写入新 Token 时,系统才复制该块,分离两个序列的缓存。
- 共享阶段:所有输出序列的块表指向同一组物理块,每个物理块维护一个引用计数(Reference Count)。
- 分裂阶段:当某个序列需要修改共享物理块时(写入不同的 Token),系统检测到引用计数 > 1,触发 CoW——分配新物理块、复制原内容、更新块表映射、原块引用计数减 1。
- 独立进行:此后各序列的 KV Cache 完全独立演化。
这种机制在 Beam Search(束搜索)和 Shared Prefix(共享前缀,如系统提示语)场景中同样适用,显存节省效果极为显著。
19.2.3 PagedAttention 的简化实现
理解了原理后,让我们通过一个自包含的 Python 实现来具体感受 PagedAttention 的工作方式。以下代码实现了物理块管理、块表映射和分页注意力计算三个核心模块。
import torch
import math
class PhysicalBlockPool:
"""物理块池:管理 GPU 显存中的 KV Cache 物理块分配与回收"""
def __init__(self, num_blocks: int, block_size: int,
num_heads: int, head_dim: int):
self.block_size = block_size
# 预分配所有物理块的 Key/Value 存储空间
# 形状: [num_blocks, block_size, num_heads, head_dim]
self.key_pool = torch.zeros(num_blocks, block_size, num_heads, head_dim)
self.val_pool = torch.zeros(num_blocks, block_size, num_heads, head_dim)
self.ref_counts = [0] * num_blocks # 每个物理块的引用计数
self.free_list = list(range(num_blocks)) # 空闲块索引
def allocate(self) -> int:
"""分配一个空闲物理块,返回块索引"""
if not self.free_list:
raise RuntimeError("物理块耗尽!需要驱逐或扩容。")
block_id = self.free_list.pop()
self.ref_counts[block_id] = 1
return block_id
def release(self, block_id: int):
"""释放物理块(引用计数减 1,归零时回收)"""
self.ref_counts[block_id] -= 1
if self.ref_counts[block_id] == 0:
self.free_list.append(block_id)
def write_slot(self, block_id: int, slot: int,
key: torch.Tensor, value: torch.Tensor):
"""向指定物理块的指定槽位写入一个 Token 的 Key/Value"""
self.key_pool[block_id, slot] = key
self.val_pool[block_id, slot] = value
class BlockTable:
"""块表:维护单个请求的逻辑块 -> 物理块映射"""
def __init__(self, pool: PhysicalBlockPool):
self.pool = pool
self.mapping: list[int] = [] # mapping[i] = 逻辑块 i 的物理块 ID
self.num_filled = 0 # 当前已写入的 Token 总数
def append_token(self, key: torch.Tensor, value: torch.Tensor):
"""追加一个 Token 的 KV 到缓存中"""
logical_block = self.num_filled // self.pool.block_size
slot_in_block = self.num_filled % self.pool.block_size
# 如果需要新的逻辑块,分配一个物理块
if logical_block >= len(self.mapping):
new_block = self.pool.allocate()
self.mapping.append(new_block)
# 写入 KV
physical_block = self.mapping[logical_block]
self.pool.write_slot(physical_block, slot_in_block, key, value)
self.num_filled += 1
def release_all(self):
"""释放该请求占用的所有物理块"""
for block_id in self.mapping:
self.pool.release(block_id)
self.mapping.clear()
self.num_filled = 0
def paged_attention(query: torch.Tensor, block_table: BlockTable) -> torch.Tensor:
"""
分页注意力计算:按块迭代,使用在线 Softmax 避免存储完整分数矩阵。
Args:
query: 当前 Token 的 Query 向量, 形状 [num_heads, head_dim]
block_table: 当前请求的块表
Returns:
注意力输出, 形状 [num_heads, head_dim]
"""
pool = block_table.pool
num_heads, head_dim = query.shape
scale = 1.0 / math.sqrt(head_dim)
# 在线 Softmax 的状态变量(逐块更新)
max_score = torch.full((num_heads,), float('-inf')) # 累计最大分数
sum_exp = torch.zeros(num_heads) # 累计指数和
output = torch.zeros(num_heads, head_dim) # 累计加权输出
tokens_remaining = block_table.num_filled
for i, physical_id in enumerate(block_table.mapping):
# 确定当前块中有效的 Token 数
valid = min(pool.block_size, tokens_remaining)
tokens_remaining -= valid
# 从物理块中取出 Key 和 Value
keys = pool.key_pool[physical_id, :valid] # [valid, num_heads, head_dim]
vals = pool.val_pool[physical_id, :valid] # [valid, num_heads, head_dim]
# 计算注意力分数: query @ key^T, 逐头处理
# query: [num_heads, head_dim], keys: [valid, num_heads, head_dim]
# 转为 [num_heads, 1, head_dim] @ [num_heads, head_dim, valid]
scores = torch.einsum('hd,vhd->hv', query, keys) * scale # [num_heads, valid]
# --- 在线 Softmax 更新 ---
block_max = scores.max(dim=-1).values # [num_heads]
new_max = torch.maximum(max_score, block_max) # [num_heads]
# 重缩放历史统计量
old_scale = torch.exp(max_score - new_max) # [num_heads]
new_scale = torch.exp(scores - new_max.unsqueeze(-1)) # [num_heads, valid]
sum_exp = sum_exp * old_scale + new_scale.sum(dim=-1)
output = output * old_scale.unsqueeze(-1) + torch.einsum(
'hv,vhd->hd', new_scale, vals
)
max_score = new_max
# 最终归一化
return output / sum_exp.unsqueeze(-1)下面验证这个实现的正确性——与标准的全量注意力计算对比结果:
# 教学示例:展示核心逻辑,省略了部分 import 和辅助函数定义
def verify_paged_attention():
"""验证分页注意力与标准注意力结果一致"""
num_blocks, block_size, num_heads, head_dim = 16, 4, 8, 32
pool = PhysicalBlockPool(num_blocks, block_size, num_heads, head_dim)
table = BlockTable(pool)
# 模拟写入 10 个 Token 的 KV(横跨 3 个物理块)
seq_len = 10
all_keys, all_values = [], []
for t in range(seq_len):
k = torch.randn(num_heads, head_dim)
v = torch.randn(num_heads, head_dim)
table.append_token(k, v)
all_keys.append(k)
all_values.append(v)
query = torch.randn(num_heads, head_dim)
# 分页注意力
paged_out = paged_attention(query, table)
# 标准注意力(用于对比)
K = torch.stack(all_keys) # [seq_len, num_heads, head_dim]
V = torch.stack(all_values)
scale = 1.0 / math.sqrt(head_dim)
scores = torch.einsum('hd,shd->hs', query, K) * scale # [num_heads, seq_len]
weights = torch.softmax(scores, dim=-1)
standard_out = torch.einsum('hs,shd->hd', weights, V)
# 验证误差
max_error = (paged_out - standard_out).abs().max().item()
print(f"分页注意力 vs 标准注意力 最大误差: {max_error:.2e}")
print(f"使用的物理块数: {len(table.mapping)}(block_size={block_size})")
assert max_error < 1e-5, "误差过大!"
print("验证通过:分页注意力与标准注意力结果一致。")
table.release_all()
print(f"释放后空闲物理块数: {len(pool.free_list)}/{num_blocks}")
verify_paged_attention()
# 输出:
# 分页注意力 vs 标准注意力 最大误差: 2.38e-07
# 使用的物理块数: 3(block_size=4)
# 验证通过:分页注意力与标准注意力结果一致。
# 释放后空闲物理块数: 16/16这段实现虽然是简化的 Python 版本,但完整展示了 PagedAttention 的三个核心机制:(1)物理块的池化分配与引用计数回收;(2)块表维护的逻辑-物理映射;(3)基于在线 Softmax 的逐块注意力计算。真实的 vLLM 实现中,这些操作会被融合为高效的 CUDA Kernel,并辅以 CUDA Graph 捕获来消除 Kernel 启动开销。
19.2.4 KV Cache 量化压缩
PagedAttention 解决了显存碎片化问题,但 KV Cache 的绝对体积仍然巨大。KV Cache 量化(KV Quantization) 从另一个角度入手——通过降低 KV Cache 的数值精度来直接缩减体积。
基本思路。 标准推理中 KV Cache 通常以 FP16(每元素 2 字节)存储。将其量化为 INT8(1 字节)可将 KV Cache 体积减半,量化为 INT4(0.5 字节)则缩减至原来的四分之一。以下是各精度下的显存对比:
| 精度 | 每元素字节数 | 相对 FP16 体积 | 典型精度损失 |
|---|---|---|---|
| FP16/BF16 | 2 | 1.0x | 无 |
| FP8 | 1 | 0.5x | 极小 |
| INT8 | 1 | 0.5x | 很小 |
| INT4 | 0.5 | 0.25x | 可控但需校准 |
KV Cache 量化的一个重要特性是与模型权重量化解耦:即使模型权重以 FP16 运行,KV Cache 也可以独立量化为 INT8,反之亦然。vLLM 等推理框架通过 kv_cache_dtype 参数直接支持这种独立配置。
逐 Token 量化示例。 每个 Token 的 KV 向量独立进行缩放量化:
反量化时乘回 scale 即可近似还原。由于注意力计算对 Key 的精度需求(用于计算
19.2.5 多请求前缀共享
在许多实际部署场景中,大量请求共享相同的系统提示(System Prompt) 或少样本示例(Few-shot Examples)。例如,一个客服助手的系统提示可能长达数千 Token,而所有用户请求都以这段相同的文本开头。传统方案为每个请求独立存储这段 KV Cache,造成大量冗余。
前缀缓存(Prefix Caching) 通过预先计算并持久化公共前缀的 KV Cache,让后续请求直接复用,无需重复 Prefill。其工作流程如下:
- 首次计算:第一个使用该前缀的请求正常执行 Prefill,生成前缀部分的 KV Cache。
- 缓存保留:前缀对应的物理块不随请求完成而释放,而是标记为"共享前缀块",保留在显存中。
- 后续复用:新请求到达时,如果其 Prompt 以已缓存的前缀开头,直接将块表指向已有的物理块,仅对前缀之后的新内容执行 Prefill。
这与 PagedAttention 的写时复制机制天然配合:共享前缀的物理块引用计数等于当前复用它的请求数,只有当所有引用都释放后才回收。vLLM 的 enable_prefix_caching=True 选项即启用了这一功能。
在大规模部署中,前缀缓存可以将 TTFT 降低数倍——用户感受到的首 Token 延迟从"完整 Prefill 时间"缩短为"仅处理用户输入部分的时间"。
19.2.6 调度与抢占
显存资源始终有限,当并发请求过多、物理块耗尽时,推理引擎需要做出取舍。vLLM 采用先到先服务 + 后到先抢占(FCFS + Latecomer Preemption) 的混合调度策略:
- 正常运行:按请求到达顺序处理,优先保证先到请求的服务质量。
- 显存不足:暂停后到达的请求,释放其物理块(all-or-nothing,一次性释放该请求的全部物理块,避免残留碎片)。
- 恢复机制:被暂停的请求可以通过两种方式恢复:
- Swap(交换):将 KV Cache 搬运到 CPU 内存暂存,显存充足时搬回。适合物理块较大的场景,能充分利用 PCIe 带宽。
- Recompute(重计算):直接丢弃 KV Cache,恢复时从 Prompt 重新 Prefill。适合物理块较小或序列较短的场景,避免频繁小数据搬运。
小结
本节系统讨论了推理引擎层面的 KV Cache 管理技术。核心要点包括:
- 传统的连续内存静态预分配会造成严重的内部碎片、外部碎片和预留浪费,是限制推理吞吐量的关键瓶颈。
- PagedAttention 借鉴操作系统虚拟内存的分页思想,将 KV Cache 拆分为固定大小的物理块,通过块表管理逻辑-物理映射,彻底消除了外部碎片,并通过写时复制机制实现了多请求间的高效缓存共享。
- KV Cache 量化通过降低数值精度(FP16 -> INT8/INT4)直接缩减 KV Cache 体积,与 PagedAttention 正交互补。
- 前缀缓存利用多请求共享的公共前缀,避免重复 Prefill 计算,在大规模部署中显著降低首 Token 延迟。
- 完善的调度与抢占机制(Swap/Recompute)确保系统在显存压力下仍能优雅降级而非崩溃。
这些技术共同构成了现代推理引擎(如 vLLM、SGLang)的 KV Cache 管理栈,使得同一块 GPU 能够服务数倍于传统方案的并发请求。