附录A:数学与传统 ML 工具箱
定位:本附录是一份精炼的数学速查手册。当你在正文中遇到陌生的数学概念时,可以随时回跳到本附录查阅。每个概念包含直觉解释→形式化定义→关键公式→本书应用回跳四个层次,帮助你快速建立理解。
A.1 线性代数
线性代数是深度学习的骨架——从参数矩阵到注意力机制,从低秩适应到数据降维,几乎每一个核心操作都可以用矩阵语言来表达。本节聚焦于深度学习中最常用的线性代数工具。
A.1.1 特征值与特征向量(Eigenvalues & Eigenvectors)
直觉 一个矩阵
形式化定义 [必读] 对于
则称
求解方法 由
解出所有
关键性质
| 性质 | 公式 |
|---|---|
| 特征值之和 = 迹 | |
| 特征值之积 = 行列式 | |
| 矩阵可逆 ⟺ 无零特征值 | |
| 矩阵幂的特征值 |
本书应用 特征值分解在神经网络权重初始化中至关重要——如果随机矩阵的最大特征值大于 1,经过多层传播后信号会指数爆炸(梯度爆炸);小于 1 则会衰减到零(梯度消失)。 → 详见§1.3 优化基础
A.1.2 对角化(Diagonalization)
直觉 对角化就是找到一个"特征向量坐标系",在这个坐标系下矩阵变成了对角矩阵——每个轴独立缩放,没有方向间的耦合。
形式化定义 [必读] 若
对称矩阵的特殊性 实对称矩阵
这就是谱分解(spectral decomposition),其中
对角化的实用价值 一旦完成对角化,矩阵幂、指数、逆等运算都变得简单:
A.1.3 二次型与正定性(Quadratic Forms & Positive Definiteness)
直觉 将一个对称矩阵
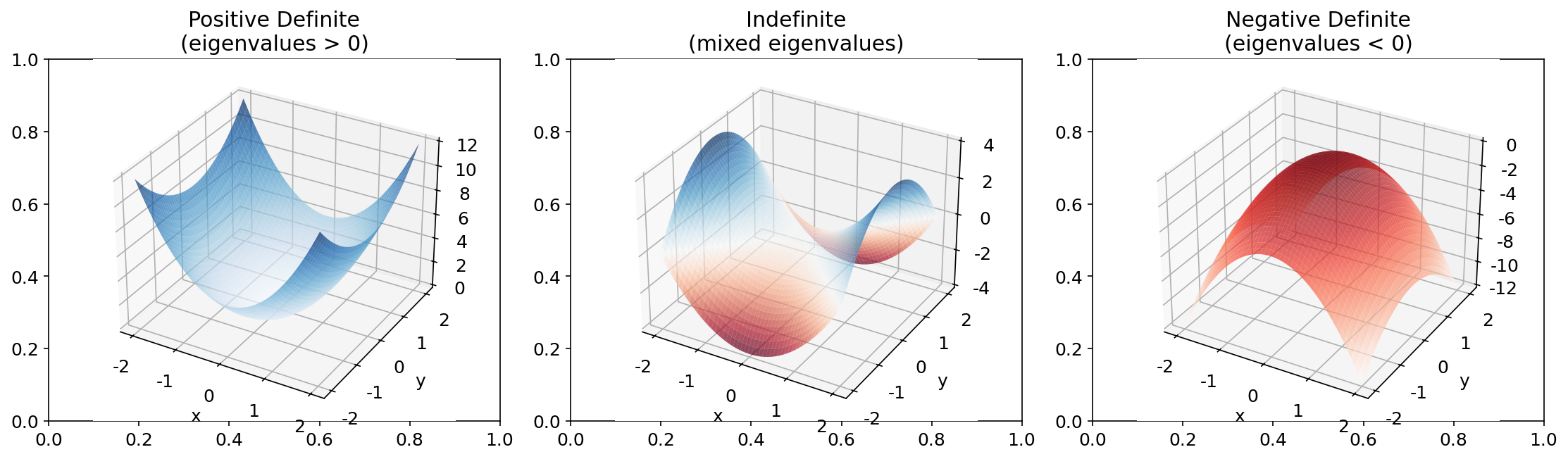
形式化定义 [必读] 对称矩阵
| 分类 | 条件 | 特征值 | 几何含义 |
|---|---|---|---|
| 正定(positive definite) | 碗形曲面,有唯一极小值 | ||
| 半正定(positive semi-definite) | 平底碗 | ||
| 不定(indefinite) | 符号不确定 | 正负均有 | 马鞍面 |
| 负定(negative definite) | 倒碗 |
本书应用 Hessian 矩阵的正定性决定了损失函数的局部形状:正定对应局部最小值,不定对应鞍点。 → 详见§1.3 优化基础
A.1.4 秩与矩阵分解(Rank & Matrix Decomposition)
秩(Rank) 矩阵
低秩的意义 如果一个
常见矩阵分解
| 分解方法 | 分解形式 | 适用条件 | 典型应用 |
|---|---|---|---|
| 特征分解 | 方阵, | 理论分析 | |
| 奇异值分解(SVD) | 任意矩阵 | 降维、压缩、LoRA | |
| LU 分解 | 方阵 | 线性方程组求解 | |
| QR 分解 | 任意矩阵 | 最小二乘、正交化 | |
| Cholesky 分解 | 正定矩阵 | 采样、协方差矩阵 |
A.1.5 奇异值分解(Singular Value Decomposition, SVD)
直觉 特征分解只适用于方阵,而 SVD 是对任意形状矩阵的"全面体检":它告诉我们矩阵在每个方向上的拉伸程度。
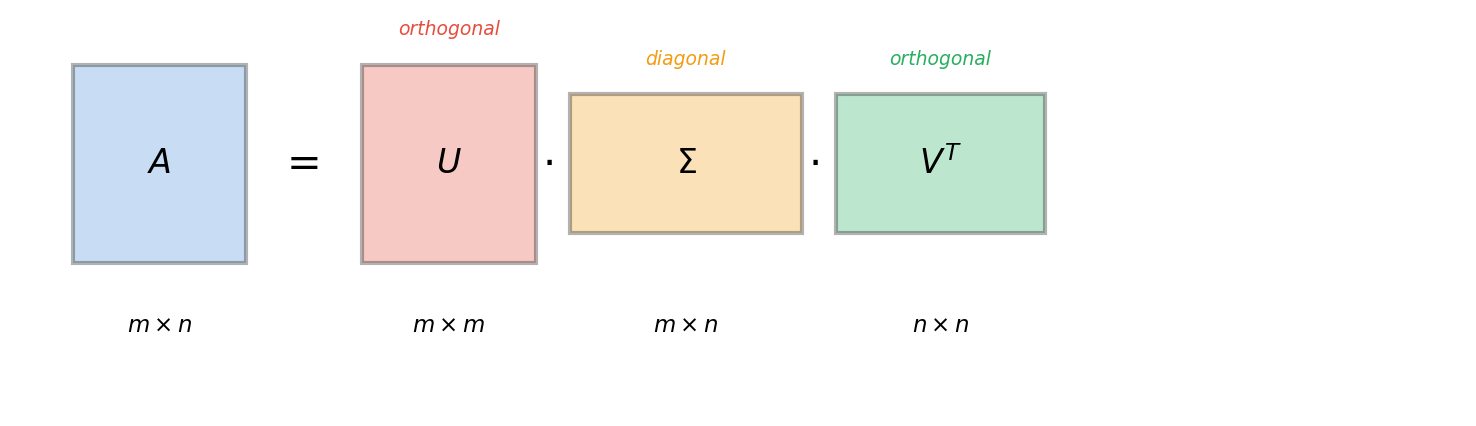
形式化定义 [必读] 对任意
其中:
是正交矩阵(左奇异向量), 是正交矩阵(右奇异向量), 是对角矩阵,对角元素 为奇异值
与特征分解的关系
截断 SVD 与低秩近似 [必读] 只保留前
Eckart-Young 定理保证这是 Frobenius 范数下的最优秩
本书应用
- → 详见§3.4 MLA 中的低秩投影
- → 详见§13.1 LoRA 原理
A.2 微积分
微积分是优化的语言——梯度告诉我们参数应该往哪个方向调整,链式法则让反向传播成为可能。
A.2.1 偏导数(Partial Derivatives)
直觉 对于多变量函数
形式化定义 [必读]
多变量的线性近似 当每个变量各自发生微小变化
本书应用 反向传播的每一步都在计算偏导数。 → 详见§1.2 反向传播
A.2.2 方向导数与梯度(Directional Derivative & Gradient)
直觉 偏导数只沿坐标轴方向考察变化率。方向导数则沿任意方向考察。而梯度就是使方向导数取最大值的那个方向。
方向导数 [必读] 函数
其中
梯度 [必读] 梯度是所有偏导数组成的向量:
关键性质:
- 梯度方向是函数值增长最快的方向
- 负梯度方向是函数值下降最快的方向
- 梯度的模长
表示最大变化率 - 梯度垂直于等值面(等高线)
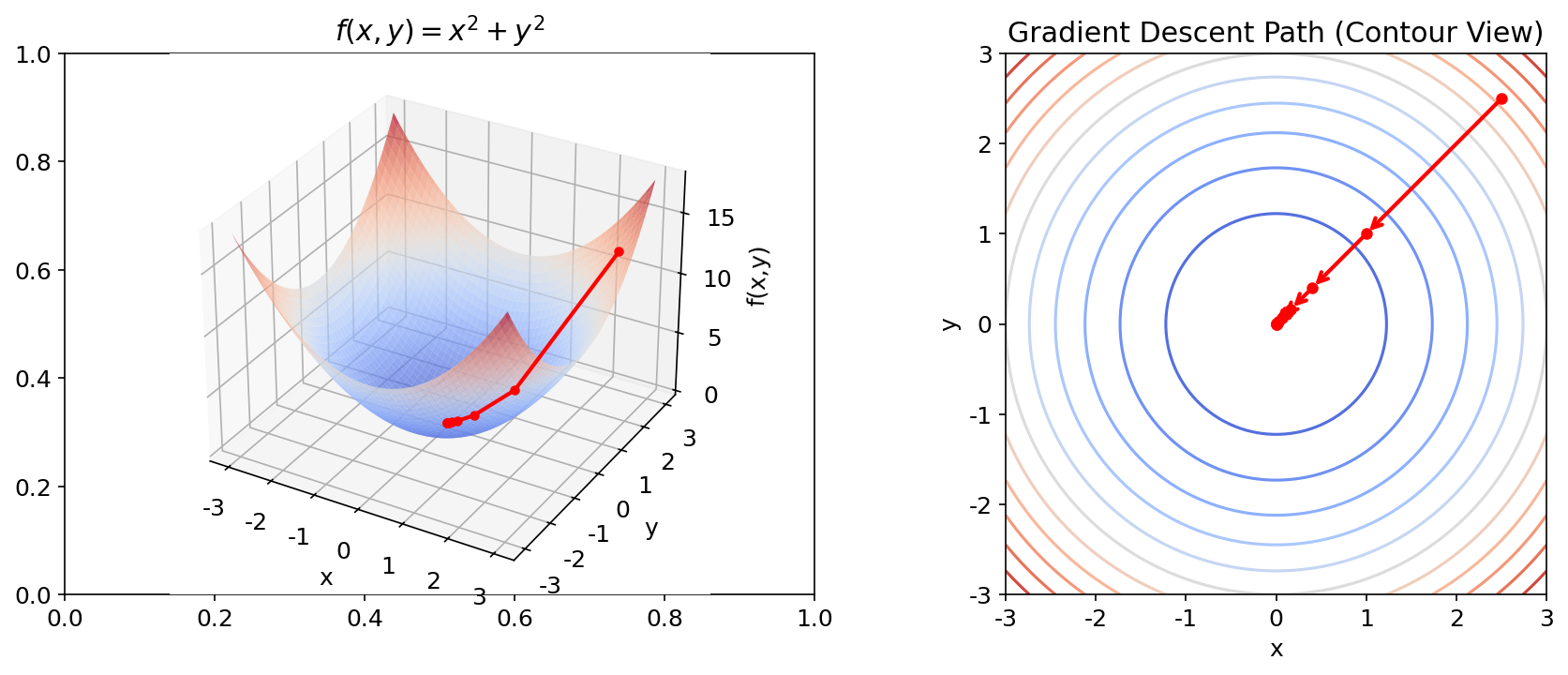
梯度下降 [必读] 这是深度学习最核心的优化算法:
其中
本书应用 → 详见§1.3 优化基础
A.2.3 链式法则与反向传播(Chain Rule & Backpropagation)
直觉 神经网络是层层嵌套的复合函数。链式法则告诉我们如何把复合函数的导数拆成各层导数的乘积。反向传播就是链式法则的高效实现。
单变量链式法则 [必读] 若
多变量链式法则 [必读] 若
反向传播的核心思想 从输出层开始,逐层向输入方向计算梯度。关键在于避免重复计算——每个中间节点的梯度只需计算一次,然后传递给所有需要它的上游节点。
前向传播 vs 反向传播
| 阶段 | 方向 | 计算内容 |
|---|---|---|
| 前向传播 | 输入 → 输出 | 计算每层的激活值和损失 |
| 反向传播 | 输出 → 输入 | 计算损失对每个参数的梯度 |
本书应用 → 详见§1.2 反向传播
A.2.4 定积分(Definite Integral)
直觉 定积分计算的是曲线下的面积。在概率论中,概率密度函数在某区间上的积分就是落在该区间的概率。
形式化定义 [选读]
微积分基本定理 若
在概率论中的应用 连续随机变量
概率密度函数的归一化条件:
A.3 概率论
概率论为我们提供了处理不确定性的数学框架。从训练数据的采样到模型输出的概率解释,从损失函数的设计到 Scaling Law 的理论分析,概率论无处不在。
A.3.1 条件概率与贝叶斯定理(Conditional Probability & Bayes' Theorem)
条件概率 [必读] 在事件
直觉:条件概率的本质是"缩小样本空间"。知道
乘法公式
全概率公式 [必读] 若事件组
贝叶斯定理 [必读]
| 术语 | 含义 | 类比 |
|---|---|---|
| 观察数据之前对 | 初始假设 | |
| 数据对假设的支持度 | ||
| 观察到 | 更新后的假设 |
本书应用 贝叶斯思想贯穿整个机器学习:从变分推断到扩散模型的去噪过程,从语言模型的条件生成到 RLHF 中的奖励建模。
A.3.2 随机变量与分布(Random Variables & Distributions)
随机变量 将随机实验的结果映射到实数的函数。分为离散型(取有限或可数无穷个值)和连续型(取某区间上的任意值)。
离散型随机变量 由概率质量函数(PMF)描述:
连续型随机变量 由概率密度函数(PDF)描述:
常见分布速查
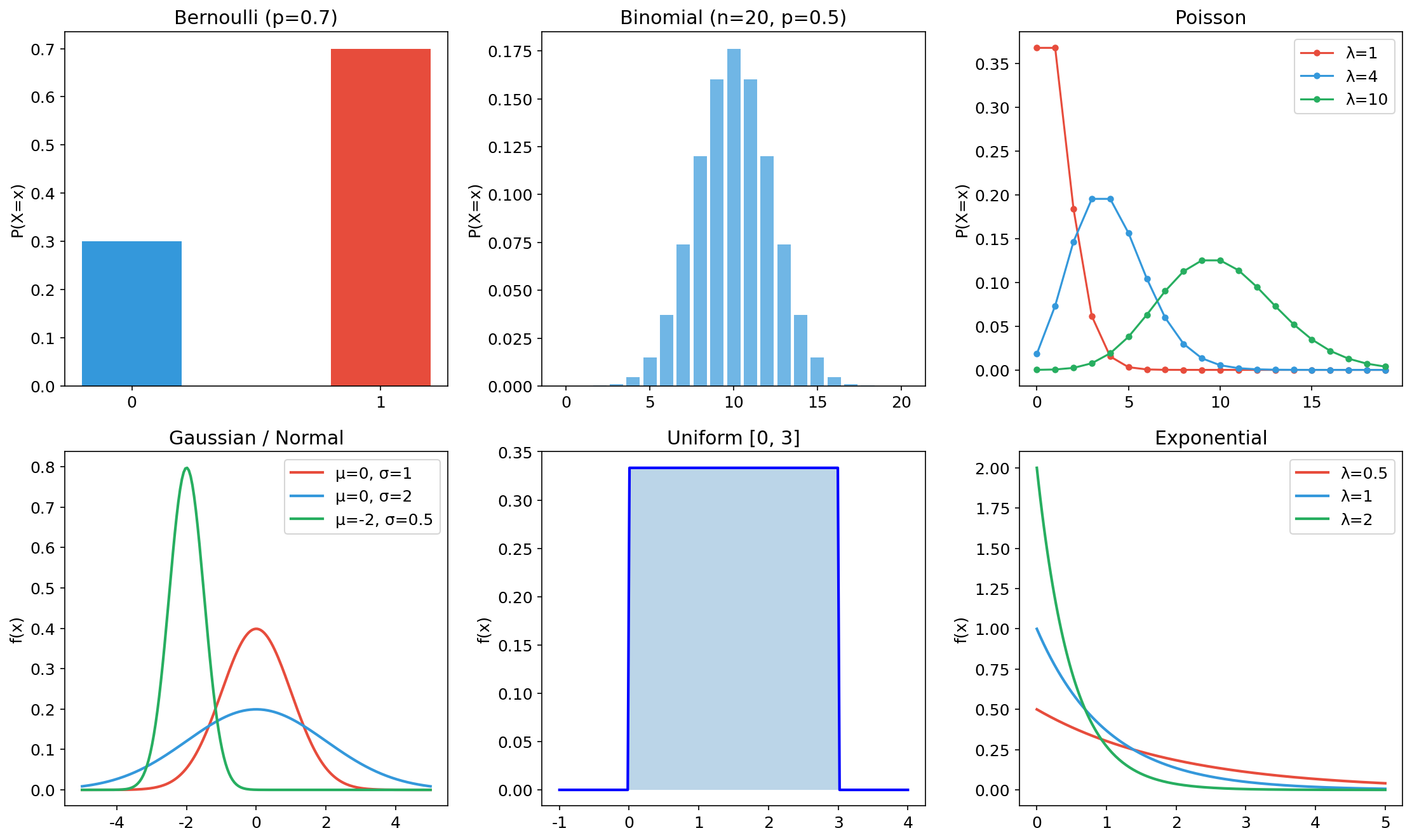
| 分布 | 参数 | PMF / PDF | 均值 | 方差 | 应用场景 |
|---|---|---|---|---|---|
| Bernoulli | 二分类 | ||||
| Binomial | |||||
| Poisson | 稀有事件计数 | ||||
| Gaussian | 误差建模、初始化 | ||||
| Uniform | 随机采样 | ||||
| Exponential | 等待时间 | ||||
| Categorical | — | — | 多分类 softmax 输出 |
A.3.3 期望、方差与协方差(Expectation, Variance & Covariance)
期望(Expectation) [必读] 随机变量的"加权平均":
期望的线性性(无论是否独立):
方差(Variance) [必读] 衡量随机变量偏离其期望的程度:
方差的性质:
- 若
独立: - 标准差
,与原始数据单位相同,更直观
协方差(Covariance) [选读] 衡量两个随机变量的线性相关程度:
相关系数将协方差归一化到
| 含义 | |
|---|---|
| 完全正线性相关 | |
| 完全负线性相关 | |
| 线性不相关(不等于独立) |
A.3.4 大数定律与中心极限定理(LLN & CLT)
这两个定理是统计学的基石,也是许多深度学习实践的理论保障。
大数定律(Law of Large Numbers) [必读]
设
深度学习中的意义:
- 随机梯度下降中,mini-batch 梯度是全量梯度的无偏估计,batch 越大估计越准确
- 训练集越大,经验风险越接近真实风险
中心极限定理(Central Limit Theorem, CLT) [必读]
无论原始分布是什么形状,只要随机变量独立同分布且有有限的均值
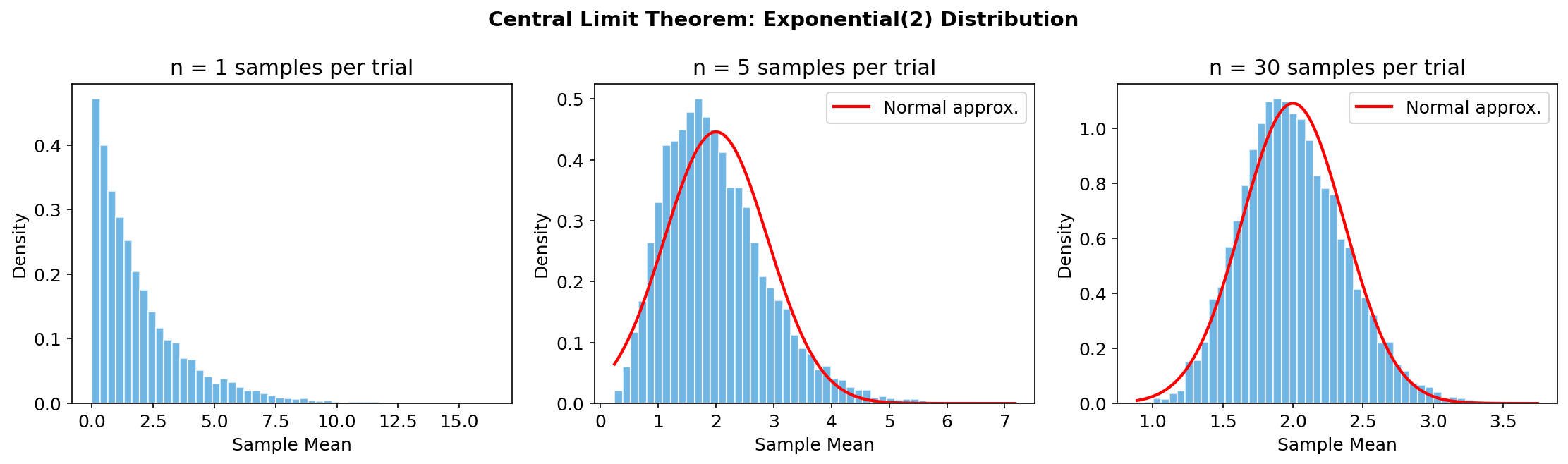
深度学习中的意义:
- 大量独立小因素叠加的结果近似正态分布,这解释了为什么高斯初始化对神经网络有效
- Batch Normalization 利用了 mini-batch 统计量近似正态的性质
本书应用
- → 详见§5.3 采样策略
- → 详见§5.5 Scaling Law
A.4 信息论
信息论提供了一套度量"不确定性"的精确语言。深度学习中的交叉熵损失、KL 散度正则化、扩散模型的变分下界,都根植于信息论。
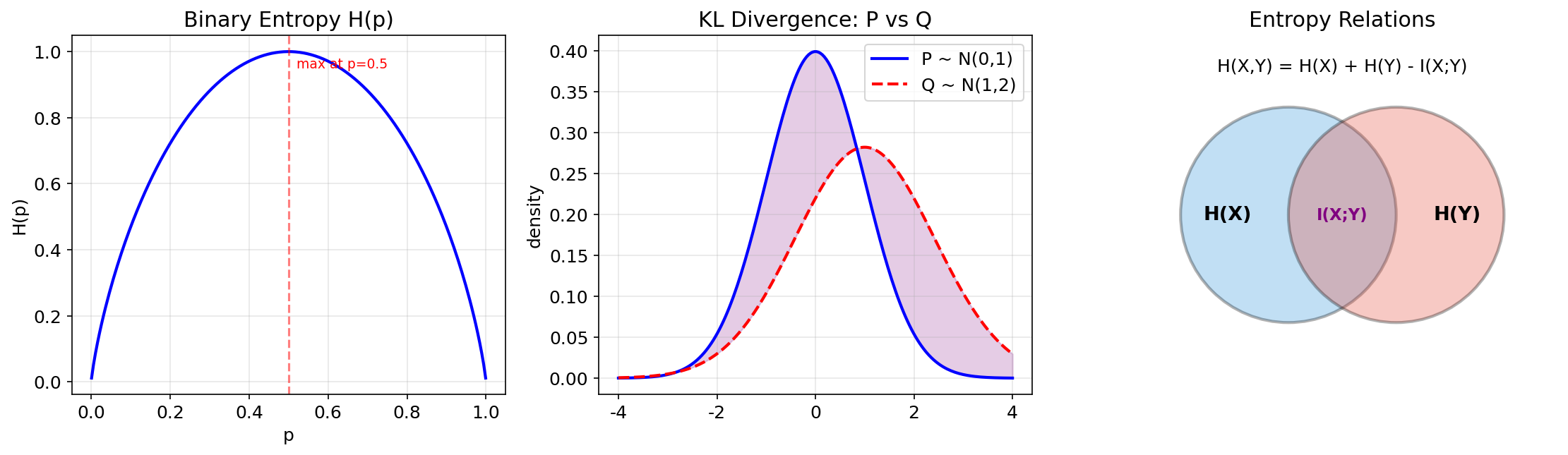
A.4.1 熵(Entropy)
直觉 熵衡量的是随机变量的"不确定性"或"信息量"。越随机(均匀)的分布,熵越高;完全确定的事件,熵为零。
形式化定义 [必读] 离散随机变量
连续情形(微分熵):
关键性质:
(离散情形) - 均匀分布取最大熵:
( 类等概率时取等号) - 独立随机变量的联合熵等于各自熵之和:
(若独立)
二元熵函数 对 Bernoulli(
在
A.4.2 交叉熵(Cross-Entropy)
直觉 如果真实分布是
形式化定义 [必读]
关键关系:
由于
交叉熵作为损失函数 [必读]
在分类任务中,真实标签
其中
本书应用 → 详见§5.1 损失函数
A.4.3 KL 散度(Kullback-Leibler Divergence)
直觉 KL 散度衡量用分布
形式化定义 [必读]
高斯分布间的 KL 散度 [选读] 两个单变量高斯分布之间的 KL 散度有解析解:
关键性质:
- 非负性:
,等号当且仅当 - 不对称性:
- 当
而 时,
本书应用
- → 详见§15.6 KL 散度分析(RLHF 中新旧策略的 KL 约束)
- → 详见§23.3 扩散模型中的变分下界
A.4.4 MLE 与交叉熵的等价性
最大似然估计(Maximum Likelihood Estimation, MLE) [必读]
给定观测数据
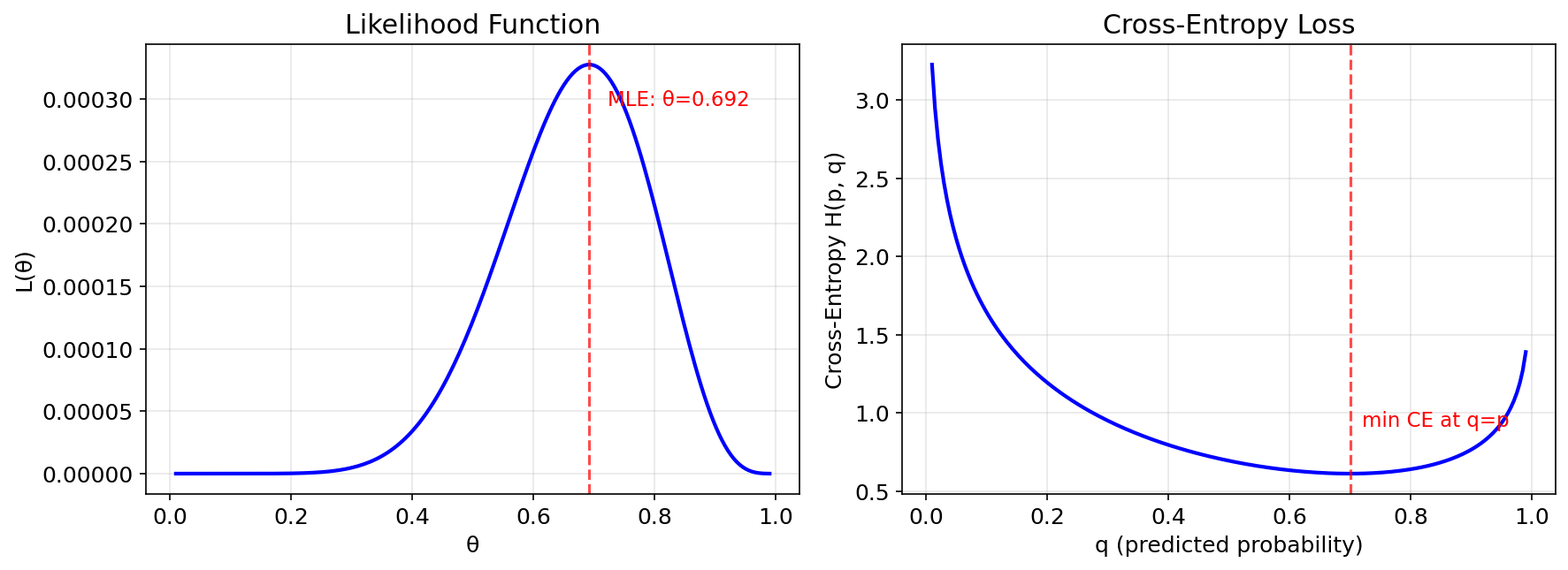
等价性证明 [必读] 最大化对数似然:
等价于最小化负对数似然,即最小化经验交叉熵:
其中
这一等价关系解释了为什么交叉熵是分类问题中最常用的损失函数——它等价于在做最大似然估计。
A.5 随机过程前置
扩散模型是近年大模型领域的重要进展,其理论根基在随机过程。本节提供必要的前置知识。
A.5.1 马尔可夫链(Markov Chain)
直觉 马尔可夫链是一种"无记忆"的随机过程:系统下一步的状态只取决于当前状态,与过去的历史无关。
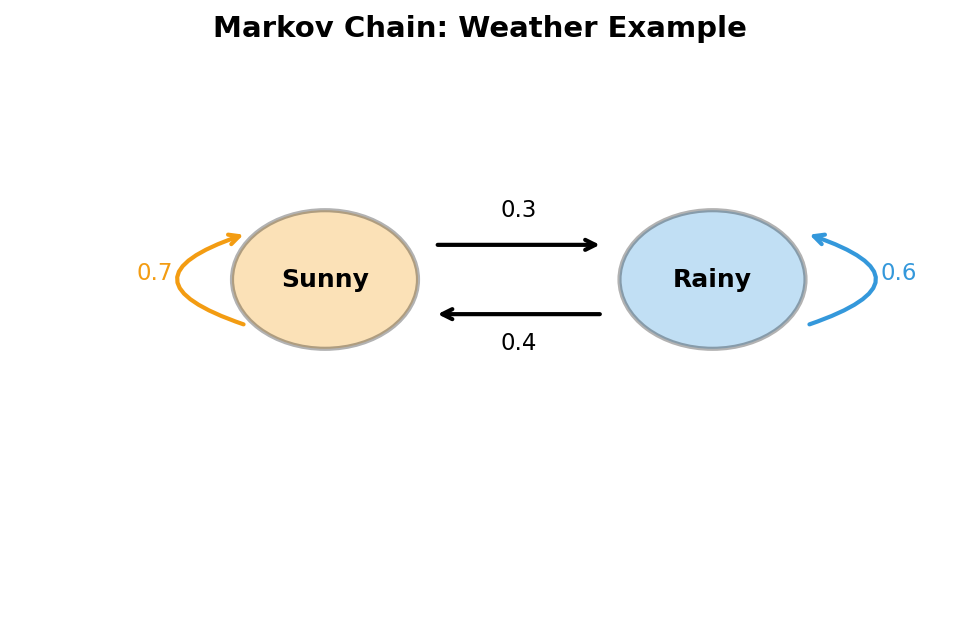
形式化定义 [必读] 一个随机过程
转移矩阵 对有限状态空间
平稳分布 [选读] 若存在概率向量
本书应用 语言模型的自回归生成本质上是一个马尔可夫过程(Transformer 虽然看整个上下文,但生成过程仍是逐 token 条件概率的乘积)。
A.5.2 布朗运动(Brownian Motion)
直觉 布朗运动是连续时间版的随机游走——每一瞬间都受到微小的随机扰动,形成一条连续但处处不可微的随机轨迹。
形式化定义 [选读] 标准布朗运动(Wiener 过程)
- 增量独立:
与 独立( ) - 增量服从正态分布:
- 样本路径几乎处处连续
A.5.3 SDE/ODE 直觉(Stochastic/Ordinary Differential Equations)
ODE(常微分方程) 描述确定性的演化过程:
给定初始值
SDE(随机微分方程) 在 ODE 的基础上加入随机噪声项:
其中
与扩散模型的联系 [选读]
扩散模型的核心思想可以用 SDE 框架统一描述:
- 前向过程(加噪):从数据分布
出发,按照一个特定的 SDE 逐步加噪,直到变成纯噪声 - 反向过程(去噪):学习反向 SDE 的漂移项,从噪声逐步恢复数据
Anderson (1982) 证明了每个前向 SDE 都有一个对应的反向 SDE,其漂移项包含得分函数
本书应用 → 详见§23.3 扩散模型
A.6 传统机器学习速查
深度学习并非凭空出现,它站在传统机器学习的肩膀上。理解这些经典方法有助于在合适的场景中选择合适的工具。
A.6.1 线性回归(Linear Regression)
模型
损失函数 均方误差(MSE):
闭式解(正规方程):
| 优点 | 局限 |
|---|---|
| 简单、可解释、有闭式解 | 只能拟合线性关系 |
| 训练和预测极快 | 对异常值敏感 |
A.6.2 逻辑回归(Logistic Regression)
模型 在线性回归基础上加 sigmoid 函数,输出概率:
损失函数 二元交叉熵(即负对数似然):
与神经网络的关系 逻辑回归等价于没有隐藏层的单层神经网络——它是深度学习的起点。 → 详见§1.1
A.6.3 决策树与随机森林(Decision Tree & Random Forest)
决策树
| 概念 | 说明 |
|---|---|
| 核心思想 | 通过递归二分特征空间来做预测 |
| 分裂准则 | 信息增益(ID3)、信息增益率(C4.5)、基尼不纯度(CART) |
| 优点 | 可解释性强、无需特征缩放 |
| 缺点 | 容易过拟合、不稳定(对数据微小变化敏感) |
基尼不纯度:
随机森林(Random Forest) 通过装袋法(Bagging)+ 随机特征选择构建多棵决策树,最终投票或平均:
| 关键设计 | 作用 |
|---|---|
| Bootstrap 采样 | 每棵树使用不同的训练子集,增加多样性 |
| 随机特征子集 | 每次分裂只考虑随机选取的 |
| 多数投票/平均 | 集成降低方差,减少过拟合 |
A.6.4 聚类与异常检测(Clustering & Anomaly Detection)
K-Means 聚类
算法流程:
1. 随机初始化 K 个中心点 μ₁, ..., μ_K
2. 重复直到收敛:
a. 分配步骤:将每个样本分配到最近的中心点
b. 更新步骤:重新计算每个簇的中心点为簇内均值目标函数:
异常检测常用方法
| 方法 | 核心思想 | 适用场景 |
|---|---|---|
| 孤立森林(Isolation Forest) | 异常点更容易被随机分割孤立 | 高维数据 |
| LOF(局部离群因子) | 比较样本与邻居的密度差异 | 密度不均匀 |
| 自编码器(Autoencoder) | 正常数据重构误差小,异常数据误差大 | 大规模数据 |
A.6.5 推荐系统基础(Recommendation Systems)
协同过滤(Collaborative Filtering)
- 基于用户:找到与目标用户行为相似的用户,推荐他们喜欢的物品
- 基于物品:找到与用户已喜欢物品相似的物品来推荐
矩阵分解方法 将用户-物品评分矩阵
其中
目标函数(含正则化):
其中
A.7 速查表:常用数学公式
矩阵求导速查
| 函数 | 导数 |
|---|---|
常用恒等式
概率论常用公式
| 公式 | 表达式 |
|---|---|
| 贝叶斯定理 | |
| 条件独立 | |
| 期望的线性性 | |
| 方差分解 | |
| 条件期望法则 | |
| Jensen 不等式 |
本附录小结
本附录覆盖了大模型全栈学习所需的核心数学工具:
- 线性代数提供了表达和操纵高维数据的语言,SVD 和低秩近似直接支撑了 LoRA、MLA 等关键技术
- 微积分通过梯度和链式法则使得模型优化成为可能,反向传播算法是其工程化实现
- 概率论为处理不确定性提供了严格框架,从采样策略到 Scaling Law 都离不开概率工具
- 信息论将 MLE、交叉熵、KL 散度统一在一个优美的框架下,解释了为什么交叉熵是最自然的损失函数
- 随机过程为扩散模型等前沿技术提供了理论基础
- 传统 ML 方法是深度学习的起点和补充,在许多场景下仍然是最佳选择
建议读者在阅读正文时遇到不熟悉的概念,随时回跳本附录查阅对应小节。数学理解不必一步到位,但每一次回顾都会加深你对核心技术的理解。