1.1 张量运算与自动求导
深度学习的一切计算,归根到底都发生在张量之上。无论是输入数据的表示、模型参数的存储,还是梯度的流动与更新,张量(Tensor)都是那个承载一切的基本容器。如果说数学为深度学习提供了理论骨架,那么张量运算就是让这副骨架运动起来的肌肉与关节。
本节将从张量的基本概念与内存模型出发,逐步引入计算图(Computation Graph)的思想,最终深入 PyTorch 的 autograd 引擎,理解自动微分如何让反向传播变得透明。这三者构成了一条完整的链条:张量是数据的载体,计算图是运算的蓝图,autograd 则是沿蓝图自动计算梯度的引擎。掌握这条链条,是后续理解所有大模型训练技术的前提。
1.1.1 张量:从标量到高维数组
**张量(Tensor)**是标量、向量、矩阵的自然推广——标量是 0 阶张量,向量是 1 阶张量,矩阵是 2 阶张量,以此类推。在 PyTorch 中,torch.Tensor 是最核心的数据结构,它本质上是一个包含单一数据类型元素的多维数组。深度学习中的一切——输入样本、模型权重、激活值、梯度——都以张量的形式存在。
import torch
# 标量(0阶张量)
scalar = torch.tensor(3.14)
print(f"标量: {scalar}, 维度: {scalar.dim()}")
# 向量(1阶张量)
vector = torch.tensor([1.0, 2.0, 3.0])
print(f"向量: {vector}, 形状: {vector.shape}")
# 矩阵(2阶张量)
matrix = torch.tensor([[1.0, 2.0], [3.0, 4.0]])
print(f"矩阵:\n{matrix}, 形状: {matrix.shape}")
# 3阶张量(例如一个 batch 的灰度图像)
tensor_3d = torch.randn(2, 3, 4) # (batch_size, height, width)
print(f"3阶张量形状: {tensor_3d.shape}")一个 PyTorch 张量携带三个最关键的属性:
shape(形状):描述张量在每个维度上的大小。例如(32, 128, 768)表示一个 batch 内有 32 条序列,每条 128 个 token,每个 token 用 768 维向量表示。dtype(数据类型):存储元素的精度,常见的有torch.float32(全精度,默认)、torch.float16/torch.bfloat16(半精度,混合精度训练常用)、torch.int64(整数,常用于 token ID)。device(设备):张量所在的计算设备,'cpu'或'cuda:0'等。GPU 上的矩阵乘法可以比 CPU 快一到两个数量级。
1.1.2 内存视图与步长
理解张量的内存模型,是写出高效 PyTorch 代码的关键。一个 PyTorch 张量对象本身并不直接持有数据——它更像一个"视图",指向一块底层的一维连续内存(称为 storage),同时携带 shape、stride(步长)等元数据来解释如何从这块一维内存中映射到多维数组的元素。
**步长(Stride)**定义了在每个维度上移动一步所需跳过的元素个数。例如,一个形状为
这种设计带来了极高的效率:transpose()、permute()、view() 等操作通常不会复制数据,而只是创建一个共享同一块 storage 但具有不同 shape 和 stride 的新张量对象,即零拷贝视图(zero-copy view)。
x = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.float32)
print(f"x 的步长: {x.stride()}") # (3, 1)
# 转置是一个视图操作,不复制数据
y = x.T
print(f"y 的步长: {y.stride()}") # (1, 3)
print(f"共享存储: {x.storage().data_ptr() == y.storage().data_ptr()}") # True
# 视图共享存储,修改一方会影响另一方
y[0, 0] = 99
print(f"修改 y 后的 x:\n{x}") # x[0,0] 也变成了 99零拷贝视图带来了一个重要的后果:转置后的张量在内存中可能不再连续(contiguous)。所谓连续,是指张量的元素在底层 storage 中的物理排列顺序与按行优先遍历多维数组时的逻辑顺序一致。某些操作(如 view())要求张量连续,此时需要显式调用 .contiguous() 来创建一份连续的副本。
print(f"y 是否连续: {y.is_contiguous()}") # False
# y.view(6) 会报错,因为 y 不连续
y_contig = y.contiguous() # 创建一份连续副本
print(f"连续化后可以 view: {y_contig.view(6)}")1.1.3 核心运算:形状变换、广播与矩阵乘法
张量运算大致分为三类:逐元素运算(加减乘除、激活函数)、归约运算(求和、均值、最大值)和矩阵运算(矩阵乘法、外积)。其中有几个概念值得特别关注。
广播机制(Broadcasting)。 当两个形状不完全相同的张量进行逐元素运算时,PyTorch 会尝试自动"广播"使其兼容。规则是:从最后一个维度开始逐维对齐,维度大小为 1 的维度会被虚拟扩展(不实际复制数据)以匹配另一个张量。
# 形状 (3, 4) 和 (4,) 的加法
a = torch.ones(3, 4)
b = torch.tensor([1.0, 2.0, 3.0, 4.0]) # 形状 (4,)
c = a + b # b 被广播为 (3, 4)
print(f"广播结果:\n{c}")
# 形状 (3, 1) 和 (1, 4) 的乘法
x = torch.tensor([[1.0], [2.0], [3.0]]) # (3, 1)
y = torch.tensor([[10.0, 20.0, 30.0, 40.0]]) # (1, 4)
z = x * y # 结果形状 (3, 4)
print(f"双向广播结果:\n{z}")广播规则的核心约束是:对应维度的大小要么相等,要么其中一个为 1,否则广播失败。这个规则虽然简单,但在实际编码中是 shape 相关 bug 的高发区,需要时刻留意。
维度归约的直觉。 dim 参数指定的是"要消灭的维度",而非"沿着哪个方向保留"。例如,对一个形状为 mean(dim=0),结果形状为
t = torch.tensor([[1.0, 3.0], [1.0, 3.0], [1.0, 3.0]])
print(f"dim=0 均值: {t.mean(dim=0)}") # tensor([1., 3.]) 消灭行
print(f"dim=1 均值: {t.mean(dim=1)}") # tensor([2., 2., 2.]) 消灭列
print(f"keepdim: {t.mean(dim=0, keepdim=True).shape}") # (1, 2)矩阵乘法。 在深度学习中,矩阵乘法(@ 运算符或 torch.matmul)是最核心的运算。线性层 torch.matmul 会对最后两个维度做矩阵乘法,前面的维度按广播规则处理——这在处理 batch 化的注意力计算时非常常用。
1.1.4 计算图:运算的蓝图
有了张量运算的基础,我们来看一个更深层的问题:当我们写出一系列张量运算时,这些运算之间的依赖关系如何被表示和追踪?答案是计算图(Computation Graph)。
计算图是一个有向无环图(Directed Acyclic Graph, DAG),其中节点代表变量(张量)或运算(函数),边代表数据的流向和依赖关系。考虑一个简单的例子:
其计算图可以表示为:
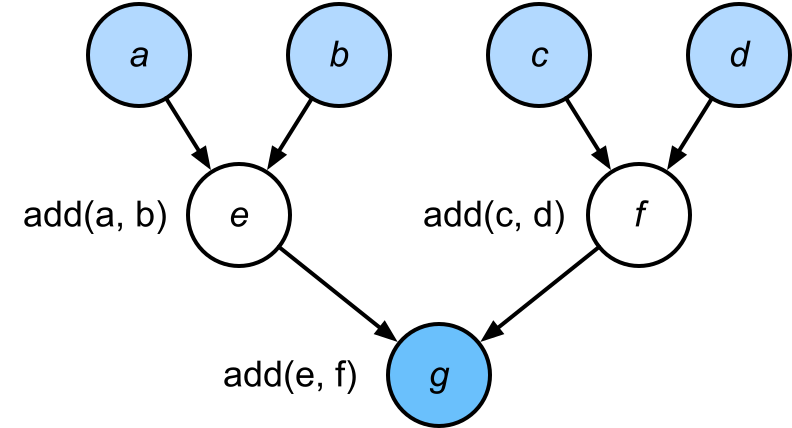
图 1-1:一个简单的加法计算图。叶子节点
计算图的价值在于,它将一个复杂的计算过程分解为一系列原子操作(primitive operations),并以拓扑结构清晰地记录了它们之间的依赖关系。这为两个关键过程奠定了基础:
- 前向传播(Forward Propagation):从叶子节点(输入、参数)出发,沿着箭头方向逐层计算,最终得到输出值。
- 反向传播(Backward Propagation / Backpropagation):从根节点(损失函数)出发,沿着箭头的反方向,利用链式法则逐层计算每个节点的梯度。
以一个单隐层 MLP(多层感知机)为例,其前向传播的计算图如下:
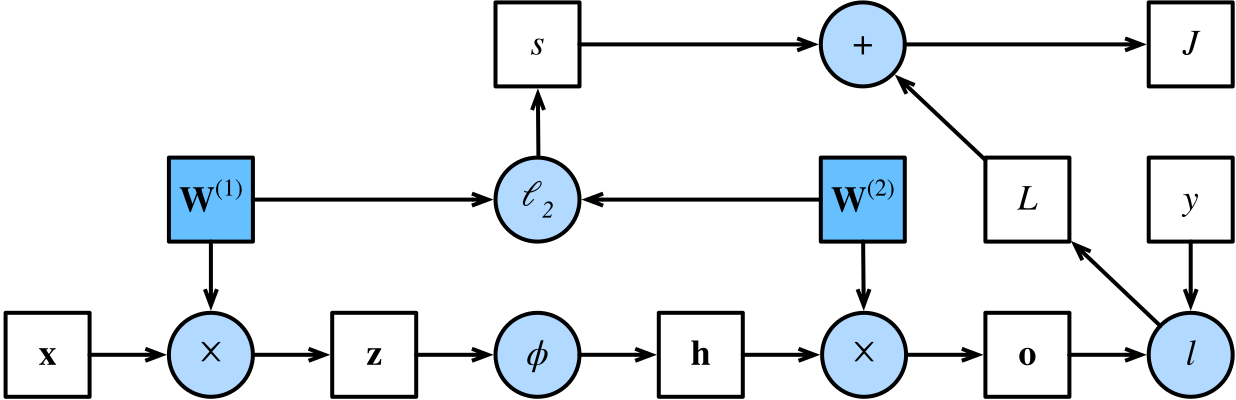
图 1-2:单隐层 MLP 的前向传播计算图。方块表示变量,圆圈表示运算。从输入
用数学公式来描述这一过程:
前向传播的每一步都会计算并存储中间变量(
1.1.5 反向传播与链式法则
**反向传播(Backpropagation)**是沿计算图反向遍历、利用链式法则逐层计算梯度的算法。它的数学核心极为简洁:若
这就是链式法则——复合函数的导数等于各层导数的乘积。在计算图中,这意味着我们可以从根节点开始,把梯度像"接力棒"一样沿着边一层一层向回传递。
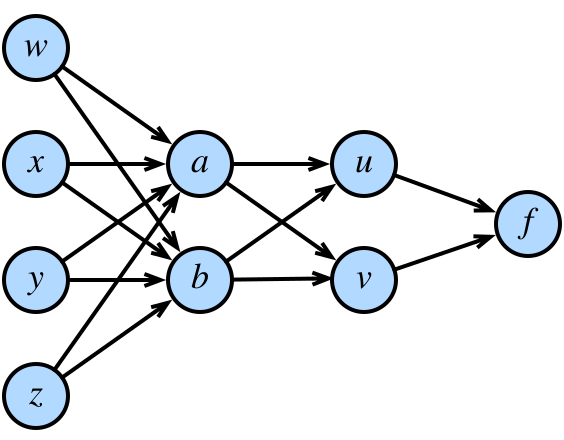
图 1-3:一个多层计算图。输入变量
以上述 MLP 为例 [选读],反向传播的具体过程如下。首先,
其中
1.1.6 PyTorch autograd:让反向传播自动化
理解了链式法则和计算图之后,一个自然的问题是:我们真的需要手动推导并编写这些梯度表达式吗?答案是不需要。Autograd(自动微分引擎)是 PyTorch 的核心组件之一,它能在前向传播时自动构建计算图,并在反向传播时自动计算梯度。
Autograd 的工作机制基于动态计算图(Define-by-Run):每次执行前向传播时,引擎会实时记录施加在张量上的每个操作,构建出一个全新的 DAG。这与早期框架(如 TensorFlow 1.x)的静态图截然不同——动态图允许你在模型中自由使用 Python 的 if、for、函数调用等控制流,极大地提升了灵活性和调试便利性。
具体来说,当一个张量的 requires_grad 属性为 True 时,所有施加在它上面的运算都会被 autograd 记录。运算结果张量的 .grad_fn 属性指向创建它的 Function 对象——这就是进入反向图的入口。当我们对最终输出(通常是一个标量损失)调用 .backward() 时,引擎从这个根节点出发,沿 DAG 反向遍历,调用每个 Function 的反向计算方法,将梯度逐层传递并累积到叶子节点的 .grad 属性中。
import torch
# 创建叶子节点,启用梯度追踪
x = torch.tensor(1.0, requires_grad=True)
y = torch.tensor(1.0, requires_grad=True)
# 前向传播:z = log((3x + 4y)^2)
v = 3 * x + 4 * y
u = v ** 2
z = torch.log(u)
# 反向传播:自动计算 dz/dx 和 dz/dy
z.backward()
# 解析解:dz/dx = 2*3/(3x+4y) = 6/7 ≈ 0.8571
# 解析解:dz/dy = 2*4/(3x+4y) = 8/7 ≈ 1.1429
print(f"dz/dx = {x.grad:.4f}") # 0.8571
print(f"dz/dy = {y.grad:.4f}") # 1.1429一个更贴近实际训练的例子,展示 autograd 如何与向量化运算配合:
import torch
# 模拟一个简单的线性回归训练步
torch.manual_seed(42)
X = torch.randn(100, 3) # 100 个样本,3 个特征
y_true = X @ torch.tensor([2.0, -1.0, 0.5]) + 0.1 * torch.randn(100)
# 可学习参数
w = torch.randn(3, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# 前向传播
y_pred = X @ w + b
loss = ((y_pred - y_true) ** 2).mean() # MSE 损失
# 反向传播
loss.backward()
# 梯度已自动计算完毕
print(f"w 的梯度: {w.grad}")
print(f"b 的梯度: {b.grad}")
print(f"loss 值: {loss.item():.4f}")
图 1-4:计算图中的梯度反向流动示意。反向传播时,梯度从输出
1.1.7 autograd 的控制与注意事项
在实际工程中,我们经常需要精细控制 autograd 的行为。以下是几个关键的控制机制。
梯度累积与清零。 PyTorch 的梯度默认是累积的,即多次调用 .backward() 后,.grad 中的值会叠加而非覆盖。这个设计在梯度累积(gradient accumulation,用小 batch 模拟大 batch 训练)时非常有用,但在常规训练循环中,必须在每次迭代开始时手动清零:
# 标准训练循环片段
optimizer = torch.optim.SGD([w, b], lr=0.01)
for epoch in range(3):
y_pred = X @ w + b
loss = ((y_pred - y_true) ** 2).mean()
optimizer.zero_grad() # 清零梯度,等价于 w.grad.zero_(); b.grad.zero_()
loss.backward() # 计算新梯度
optimizer.step() # 更新参数:w = w - lr * w.grad
print(f"Epoch {epoch}: loss = {loss.item():.4f}")禁用梯度追踪。 在推理或评估阶段,我们不需要计算梯度。此时应使用 torch.no_grad() 上下文管理器来禁用 autograd,以节省内存并加速计算。PyTorch 1.9 之后推荐使用更高效的 torch.inference_mode():
# 推理阶段
with torch.no_grad():
y_eval = X @ w + b
# 此上下文中的运算不会构建计算图,不会追踪梯度
# 更推荐的写法(PyTorch >= 1.9)
with torch.inference_mode():
y_eval = X @ w + b.detach() 切断计算图。 有时我们希望某个中间结果参与后续计算,但不希望梯度通过它流回更早的节点。.detach() 会返回一个与原张量共享数据但脱离计算图的新张量:
x = torch.tensor([2.0, 3.0], requires_grad=True)
y = x ** 2
u = y.detach() # u 的值等于 y,但切断了与 x 的梯度联系
z = u * x # z 对 x 求导时,u 被视为常量
z.sum().backward()
print(f"x.grad = {x.grad}") # tensor([4., 9.]),即 u = [4, 9]
# 如果不 detach,梯度应该是 3*x^2 = [12, 27]动态图与控制流。 PyTorch 的动态计算图意味着你可以在前向传播中使用任意 Python 控制流,autograd 会正确处理:
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
# 无论 while 循环执行了多少次,if 走了哪个分支,梯度都能正确计算
print(f"a.grad == d/a: {(a.grad == d / a).item()}") # True这种灵活性是 PyTorch 在研究社区广受欢迎的重要原因。每次前向传播都会构建一张新的计算图,不同的输入可能产生完全不同的图结构——这对于处理变长序列、条件计算等场景至关重要。
1.1.8 本节小结
本节围绕"张量 — 计算图 — autograd"这条主线,建立了深度学习计算的基础认知框架。张量是数据的统一表示,其底层的 storage/stride 机制实现了高效的零拷贝视图操作。计算图将复杂的前向传播分解为原子操作的 DAG,为反向传播提供了结构化的路径。链式法则使得梯度可以沿计算图逐层反向传递,而 PyTorch 的 autograd 引擎将这一过程完全自动化——开发者只需编写前向逻辑,梯度计算由框架在动态构建的计算图上自动完成。
在后续章节中,我们将在这个基础上构建更复杂的模型结构(注意力机制、Transformer 架构),并讨论大规模训练中的工程优化技术(混合精度训练、梯度检查点、分布式训练)。这些高级主题都以本节的张量运算与自动求导机制为底层支撑。